As a part of internal company deep edge talks, I did a demo session on how to build and run inference on a neural network model on raspberry pi and NodeMCU.
the model • Show it running on computer & raspberry pi • Converting Model for tiny devices • Loading it onto microcontroller • Trade o ff s & Application fi ts • Questions & Discussion
model That can run on devices running DSPs continuously listening for OK Google. On the phone, this program needs to consume as little battery power as possible. https://learning.oreilly.com/library/view/tinyml/9781492052036/ch01.html
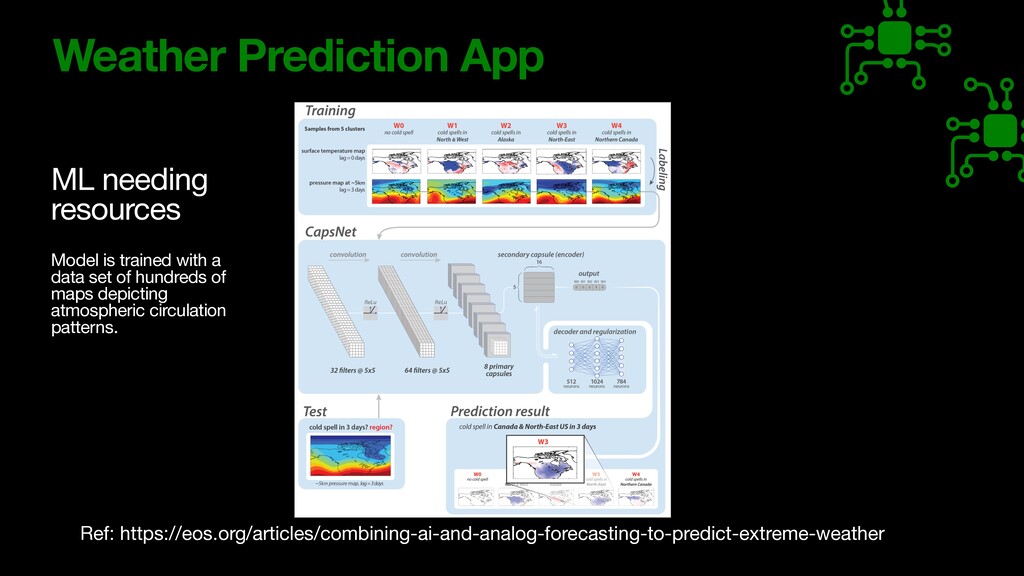
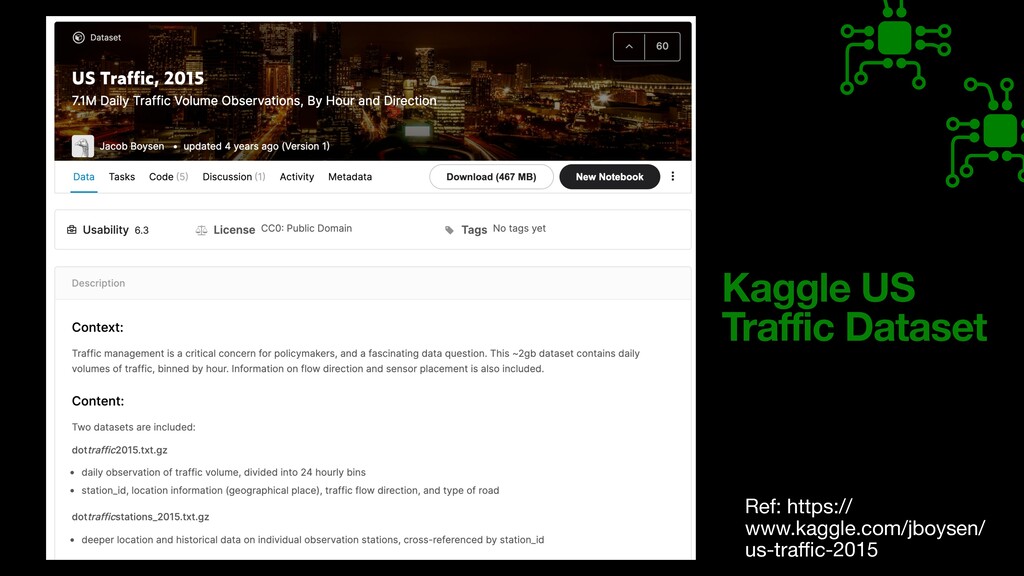
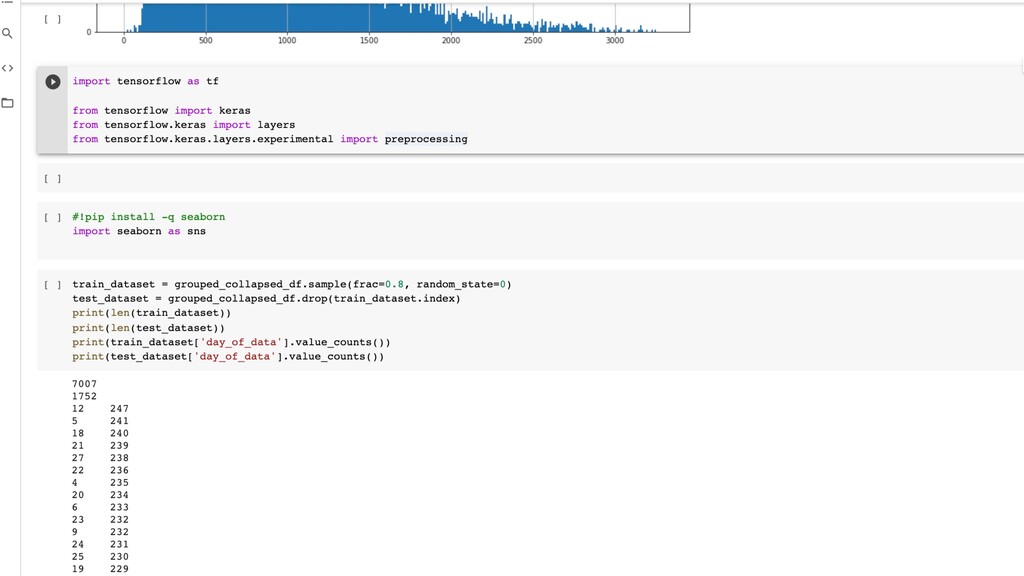
i c volume using neural network model • Smart tra ff i c lights which can know the future volume and adjust the timing of lights for lanes • Currently there are local sensors in the road to know current situation but they are not predicting. Inductive-Loop Sensors, Infrared Sensors, Microwave sensors, Video sensor s , Microwave Sensor s https://elteccorp.com/news/other/are-there-sensors-at-traf fi c-lights /
1GB RAM • BCM43438 wireless LAN & BLE • 100 Base Ethernet • 40-pin extended GPIO • 4 USB 2 ports • Full size HDMI • CSI camera port • DSI display port for connecting a Raspberry Pi touchscreen display
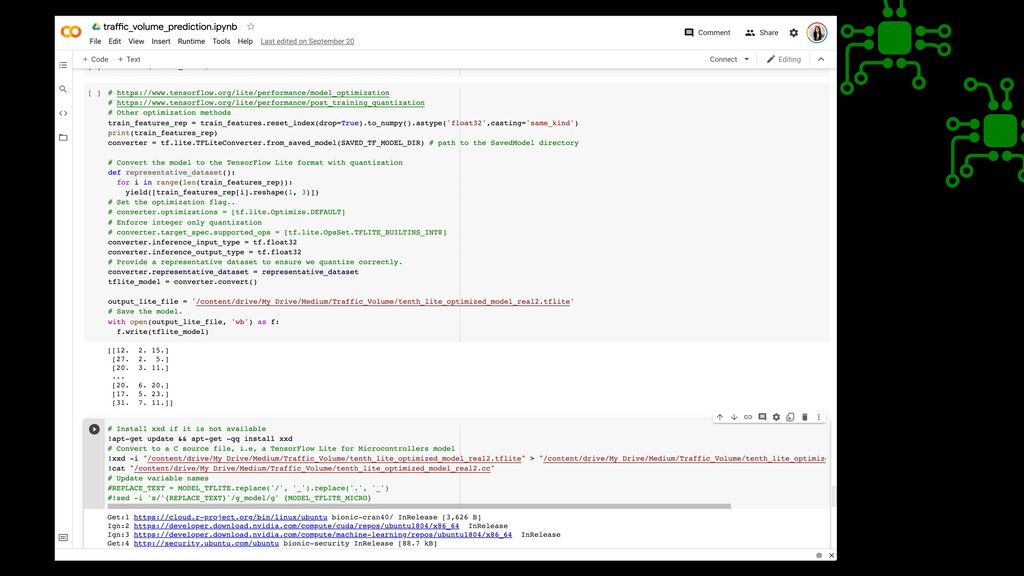
tools which enables on-device ML by helping developers run their models on mobile, embedded, and IoT devices. • Optimized for on-device ML ( Reduced Model and binary size) • Multi-platform support : Android, iOS, embedded linux and microcontrollers • Hardware acceleration is done using Delegates in TFLite by leveraging on-device accelerators such as GPU and DSP (Digital Signal Processor). • Model optimization that makes it easy to make the model optimized for smaller storage size, download size and less memory usage when they are running. Quantization can be used to reduce the size of the models & reduced latency for model inference. Ref : https://www.tensor fl ow.org/lite/guide https://www.tensor fl ow.org/lite/performance/delegates tensor fl ow.org/lite/performance/model_optimization
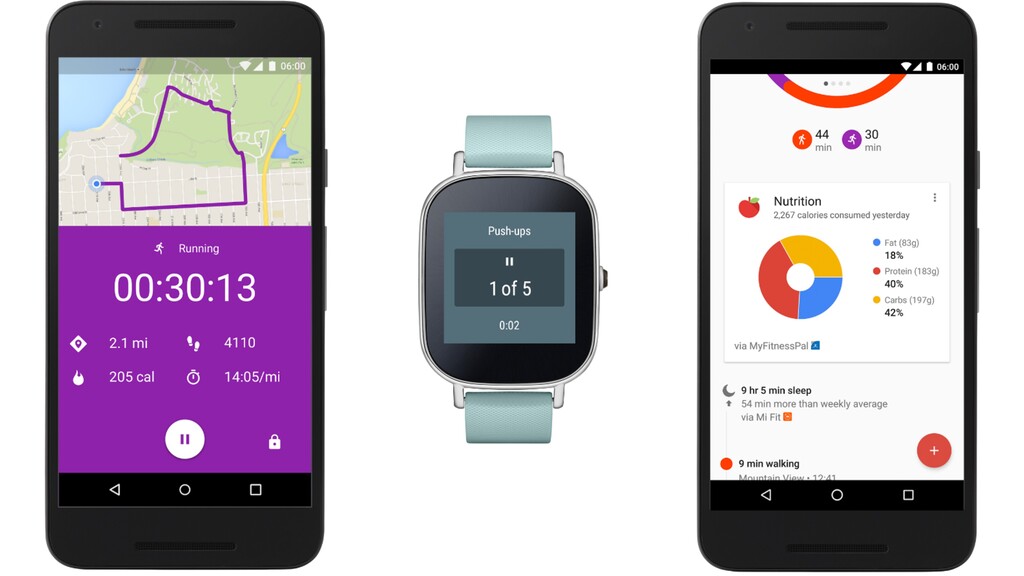
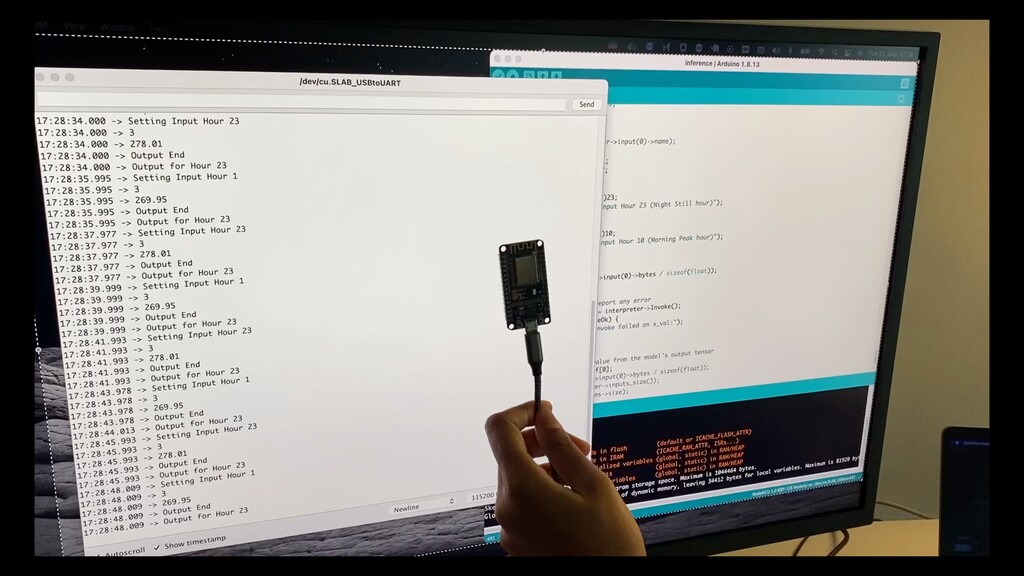
AI/ML models on devices having tens of KBs of RAM and fl ash memory. • Running e ff i ciently so it doesn’t take lot of power. • This means you can use the sensor data locally and make predictions or choose actions to do locally on the device • Making smart & new products that fi t into small space, use minimal energy, RAM, CPU and use the data locally instead of forwarding to servers. • Fun to work on as this fi eld is quite young :)
reduction damages accuracy of the model a little bit. • More secure and less power consuming applications as the data is local and not sent to servers. Gives more privacy to users. • ML is not limited to running only in cloud/big servers with complex pipeline to serve the requests. • Predictive maintenance, Magic Wand, Safety monitoring with audio recognitions, etc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}