Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
David Sottimano - Data Driven SEO
Search
Distilled
November 29, 2014
Technology
720
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
David Sottimano - Data Driven SEO
Distilled
November 29, 2014
More Decks by Distilled
See All by Distilled
Wil Reynolds — Paid Search Strategies SEOs will Love
distilled
0
170
Rand Fishkin — Search Ranking Factors in 2015 What Data, Opinions, and Testing Reveal
distilled
0
230
Larry Kim — The Top 10 Facebook & Twitter Advertising Hacks of All Time
distilled
0
200
Will Critchlow - Practical Tips for the Future of Search II
distilled
0
310
Tom Anthony - New Paradigms: Five Fundamental Changes in Search II
distilled
0
360
Aaron Friedman — ‘Google's Predictable Content Preference’
distilled
0
330
Aleyda Solis — ‘Unlocking Growth Opportunities with Search Analytics’
distilled
0
270
Anum Hussain — ‘Topics Over Keywords: An SEO-Driven Approach to Content Marketing’
distilled
0
320
Casie Gillette — ‘21 Must-Have PR Tools and Tactics’
distilled
0
210
Other Decks in Technology
See All in Technology
脱Jenkins、インターン生が挑んだCIツールGitHubActions移行
mixi_engineers
PRO
1
280
人依存からAIネイティブの体制へ:バックエンド開発の裏側【SORACOM Discovery 2026】
soracom
PRO
0
140
AI Agent を本番環境へ―― Microsoft Foundry × Azure Serverless で作る Enterprise-Ready な基盤
shibayan
PRO
1
910
AI エージェント時代のデジタルアイデンティティ
fujie
1
1.2k
Webの技術とガジェットで子どもも大人も楽しめるワクワク体験を提供する / Qiita Tech Festa Day 2026
you
PRO
1
320
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
270
ウォーターフォール開発案件のPMとしてAI活用を模索している話
hatahata021
2
230
reFACToring
moznion
1
1k
QAタスクをスキル化したいときに考えること
aomoriringo
0
130
AIがAPIを書く時代に、私たちは何を設計すべきか
nagix
0
170
『モンスターストライク』 の運営に伴走する! データ民主化への 解析グループの3つのアプローチ
mixi_engineers
PRO
0
180
新しい SLO が良い感じにハマっている話
z63d
1
1.2k
Featured
See All Featured
Leo the Paperboy
mayatellez
8
2k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
780
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
240
Building AI with AI
inesmontani
PRO
1
1.1k
Raft: Consensus for Rubyists
vanstee
141
7.6k
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
Rails Girls Zürich Keynote
gr2m
96
14k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
The Curious Case for Waylosing
cassininazir
1
440
Measuring & Analyzing Core Web Vitals
bluesmoon
9
940
Designing for humans not robots
tammielis
254
26k
Transcript
Data driven SEO David Sottimano Searchlove 2014
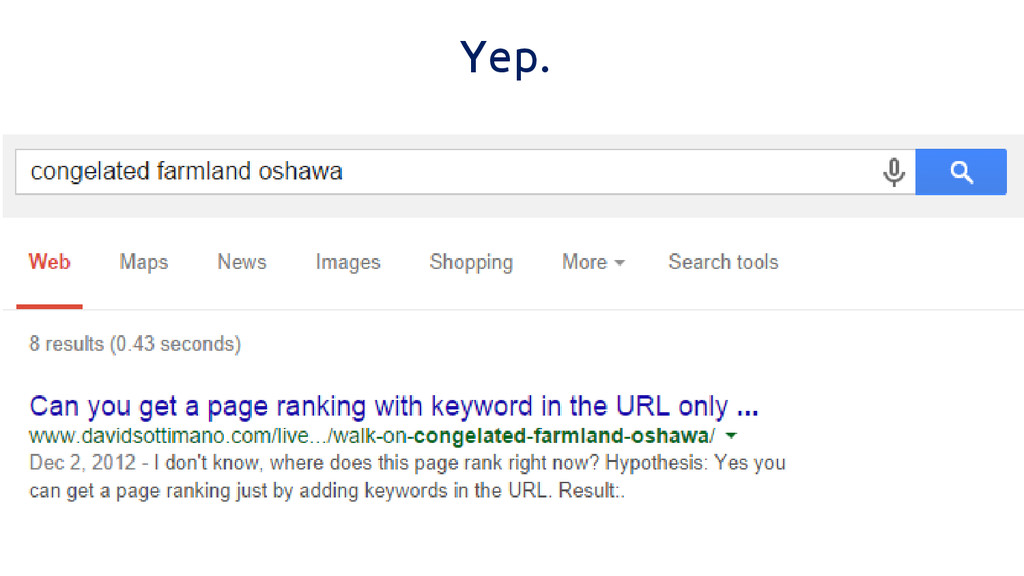
Can a post rank solely by having keywords in the
URL?
Yep.
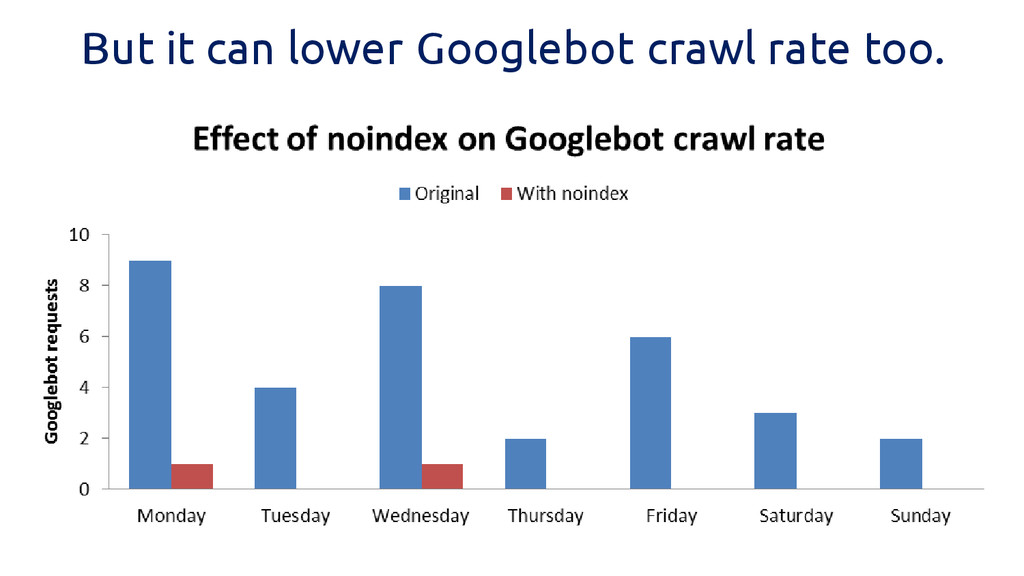
What does meta NOINDEX do?
Removes a page from the index..
But it can lower Googlebot crawl rate too.
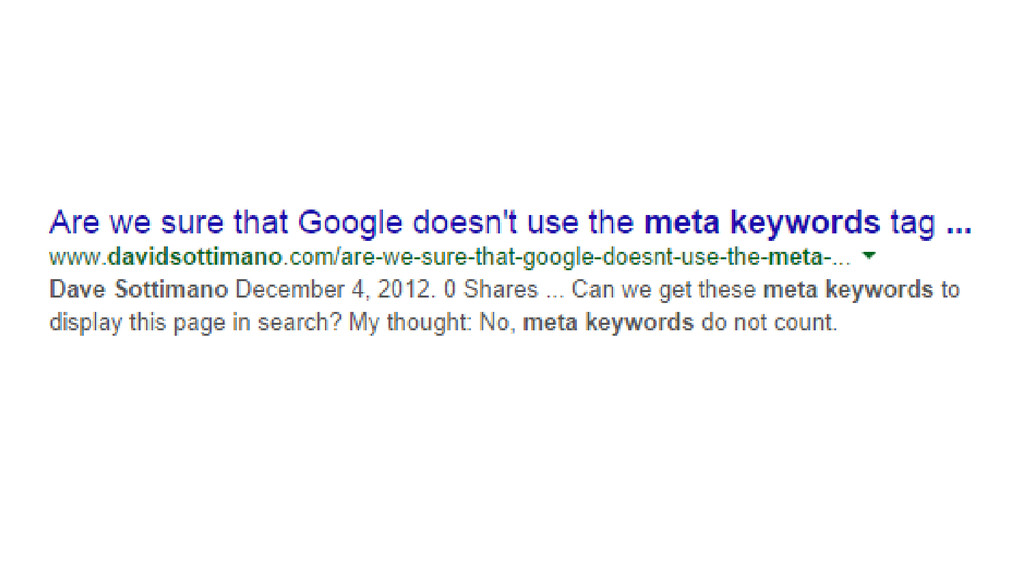
Are meta keywords actually useful?
None
Don’t be silly.
Data driven SEO Using data to win arguments David Sottimano
Searchlove 2014
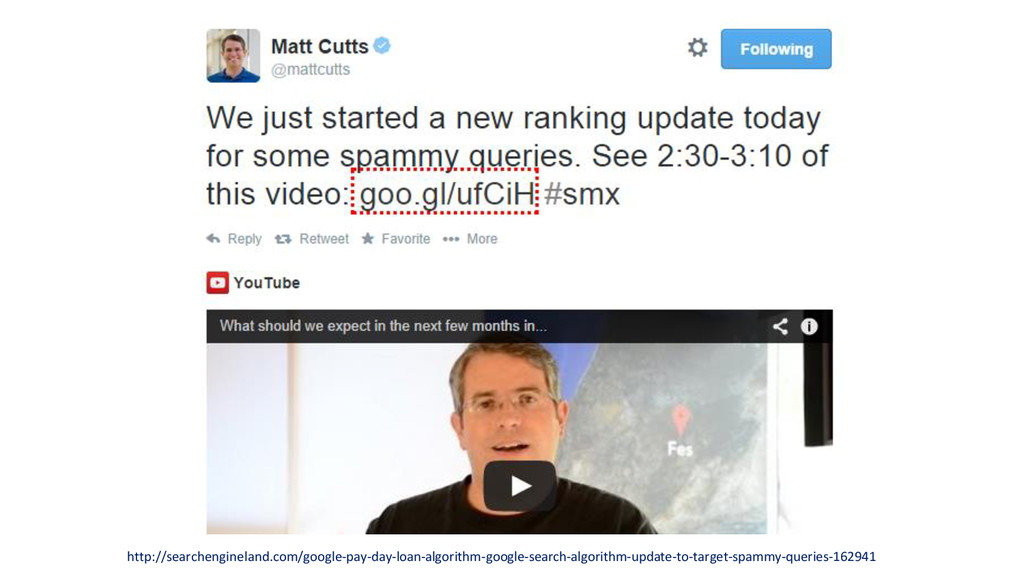
Do this. Because. {Insert Matt Cutts video link}
Caveat, caveat, caveat….
Meaningful, conclusive data is hard to come by.
Algorithms can be specific to queries.
http://searchengineland.com/google-pay-day-loan-algorithm-google-search-algorithm-update-to-target-spammy-queries-162941
Data we need is out of reach.
Actual click through rates? Actual bounces back to search results?
Our “good” isn’t Google’s “good”
None
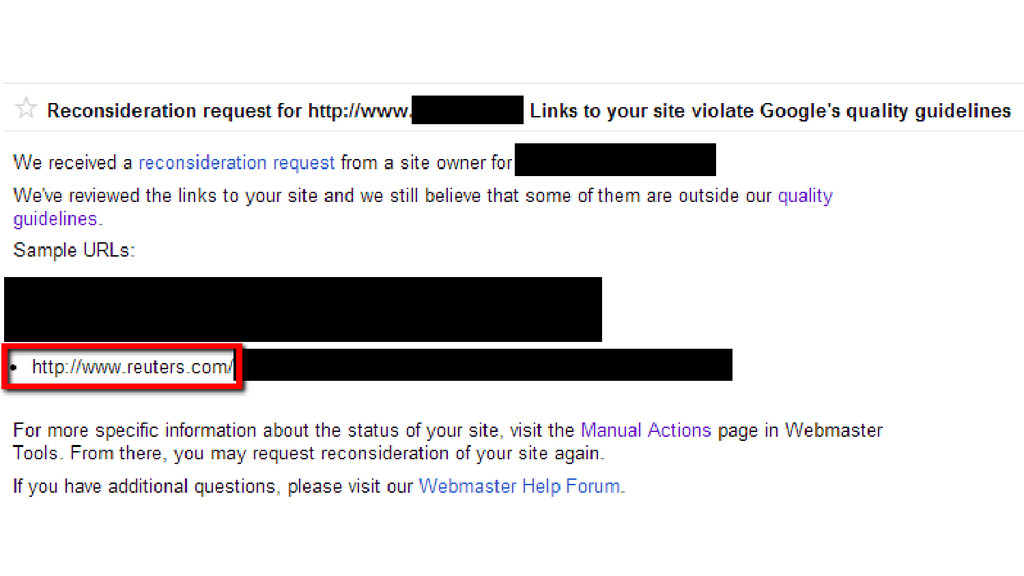
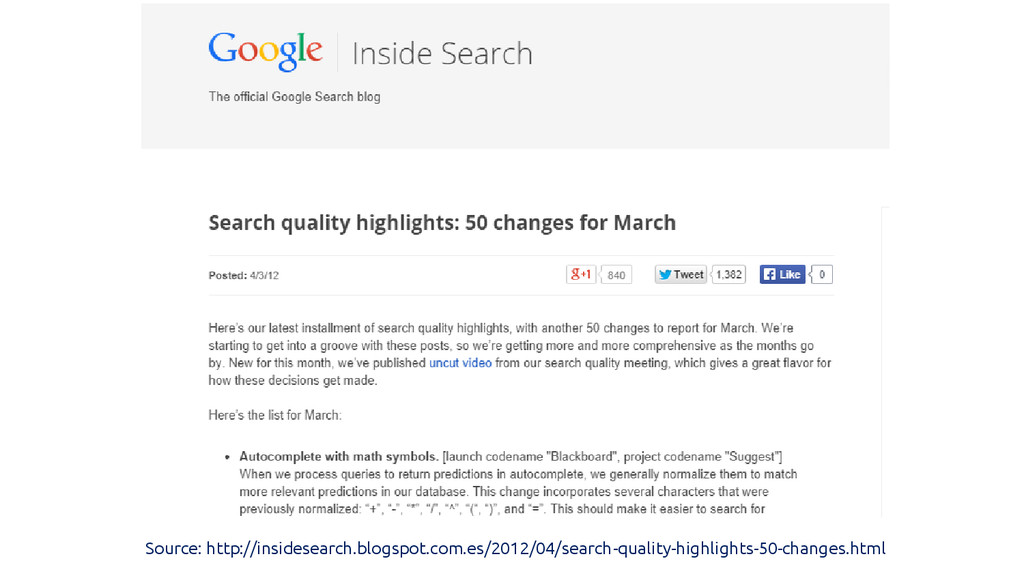
Clues are scarce, and often vague.
Source: http://insidesearch.blogspot.com.es/2012/04/search-quality-highlights-50-changes.html
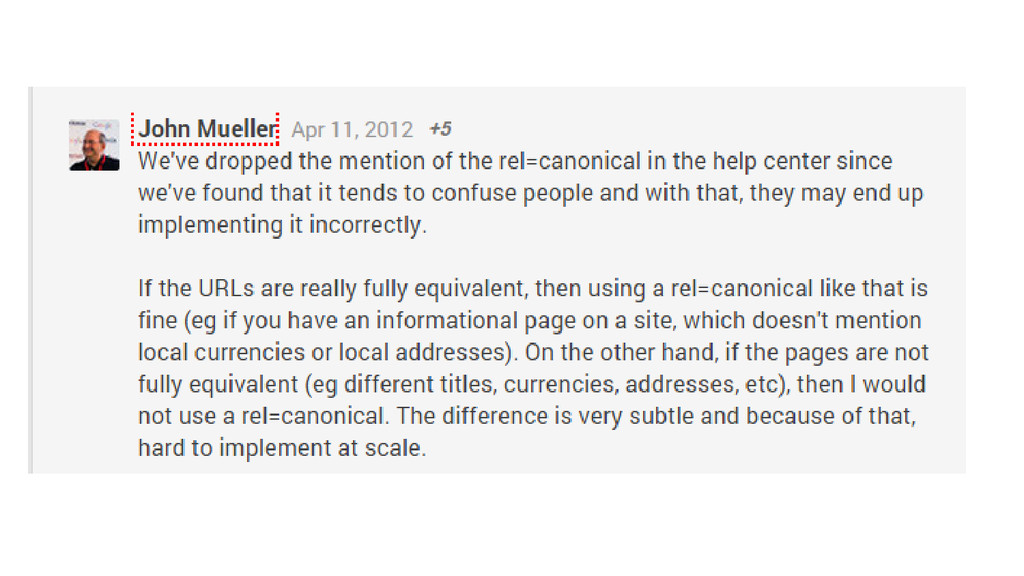
Would you trust the information presented in this article? http://googlewebmastercentral.blogspot.co.uk/2011/05/more-guidance-on-building-high-quality.html
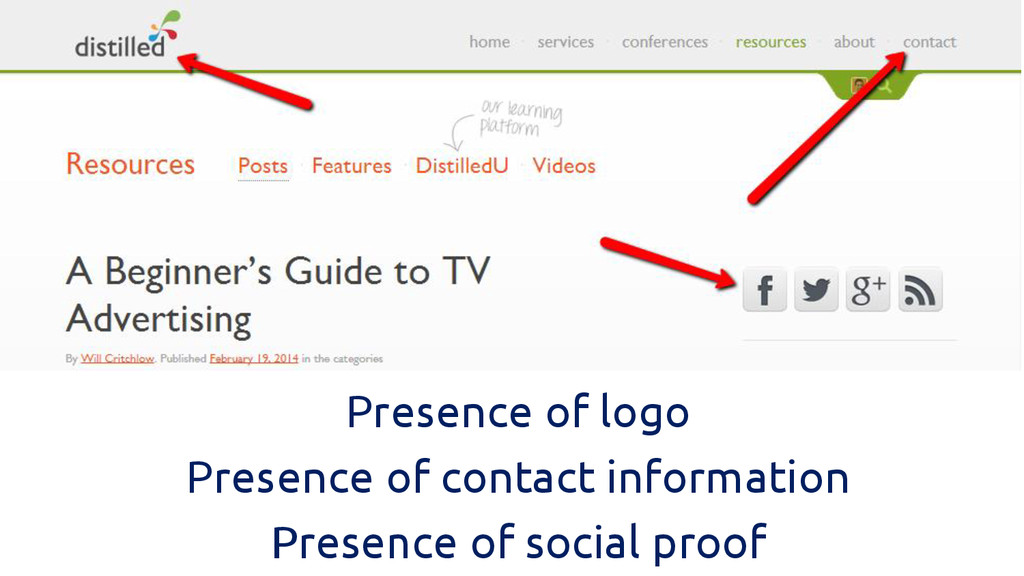
Presence of author Presence of author information Presence of author
image
Presence of logo Presence of contact information Presence of social
proof
This is why we need a data driven approach.
Because “best practice” isn’t a good enough answer.
Throwing stuff against the wall doesn’t make us any wiser!
Be curious! Question everything!
More input, less valuable output
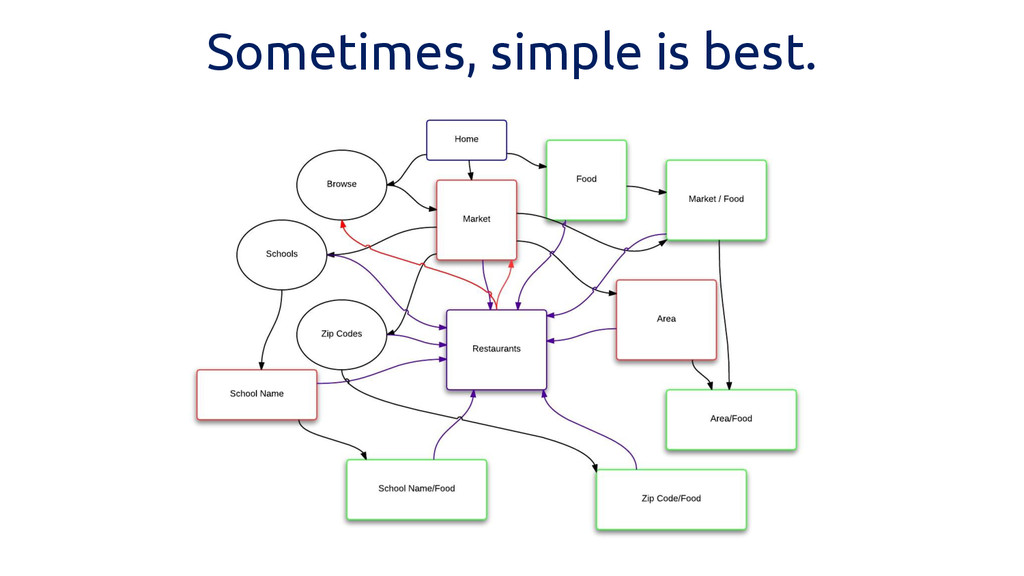
Sometimes, simple is best.
How’s this idea guys?
It’s pretty shit. *not actually what they said
How I completely failed* to win arguments before. *pretty much
all the time
None
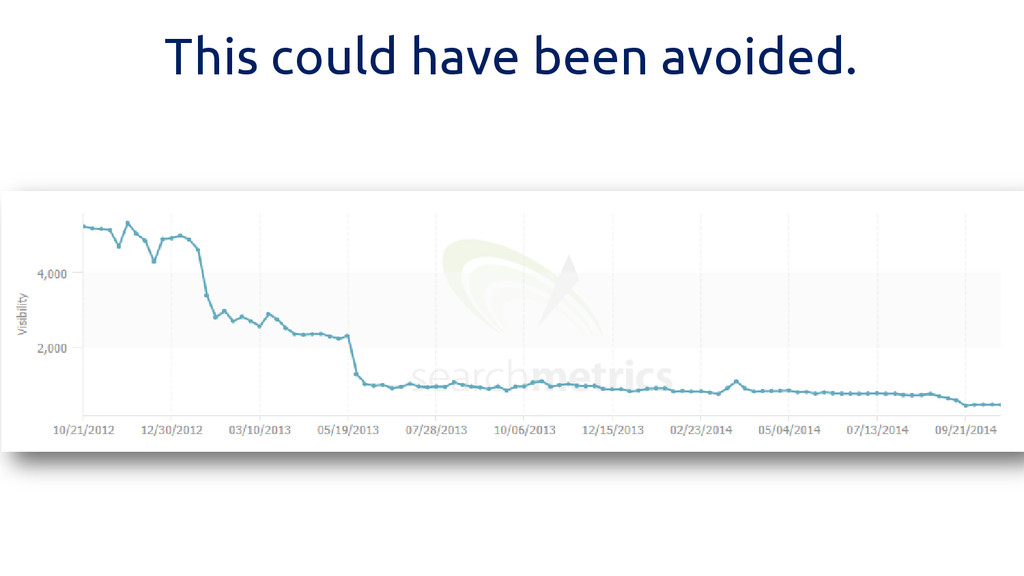
This could have been avoided.
If I had done this… Keyword If you move off
page 1 Money you will lose Keyword 1 -3,000 visits -$10,000 Keyword 2 -2,000 visits -$7,500 -5,000 visits per month -$17,500 per month
My first time.
“We’re going International, what do we do with hreflang?”
Get the right people to the right pages in search
& Don’t screw up rankings / traffic Hreflang, canonical or both?
None
Okay, test it.
> 2 Analytics WMT Rank tracking Logs Testing configuration
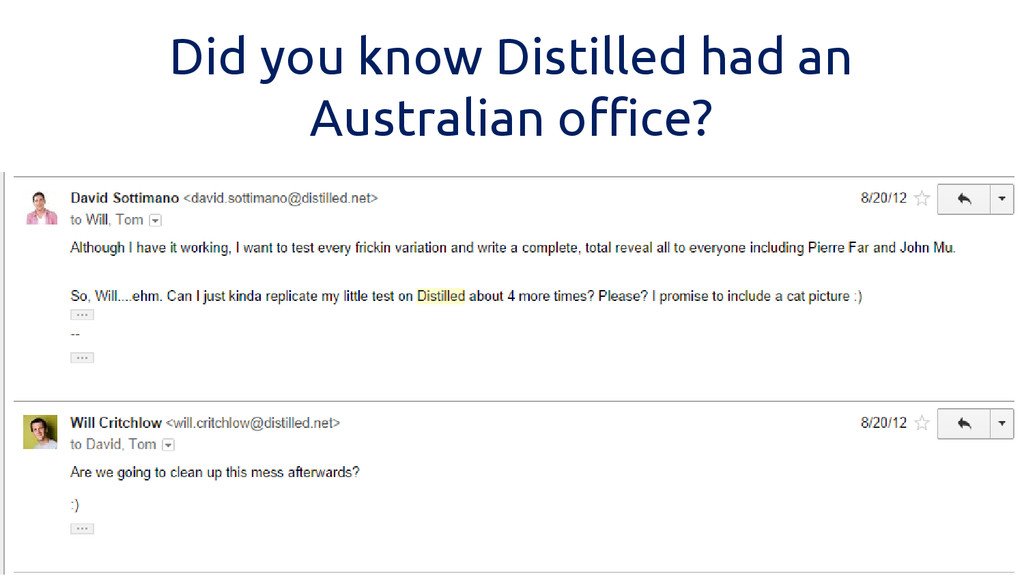
Did you know Distilled had an Australian office?
Think about all the variants you want to test first
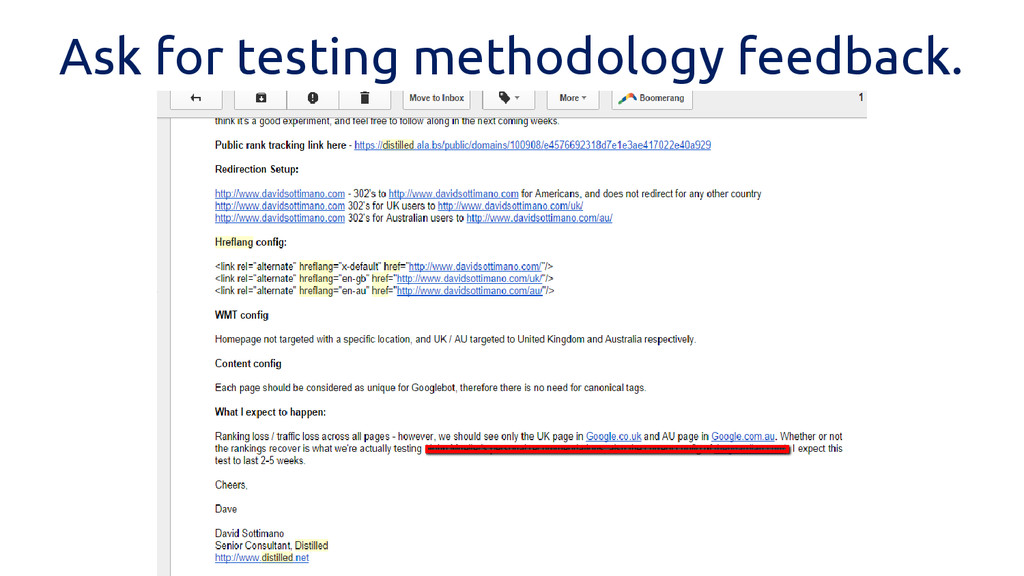
Ask for testing methodology feedback.
Wait. How will I know if it worked or not?
1) Rankings 2) Organic traffic 3) The right pages display
in the right countries
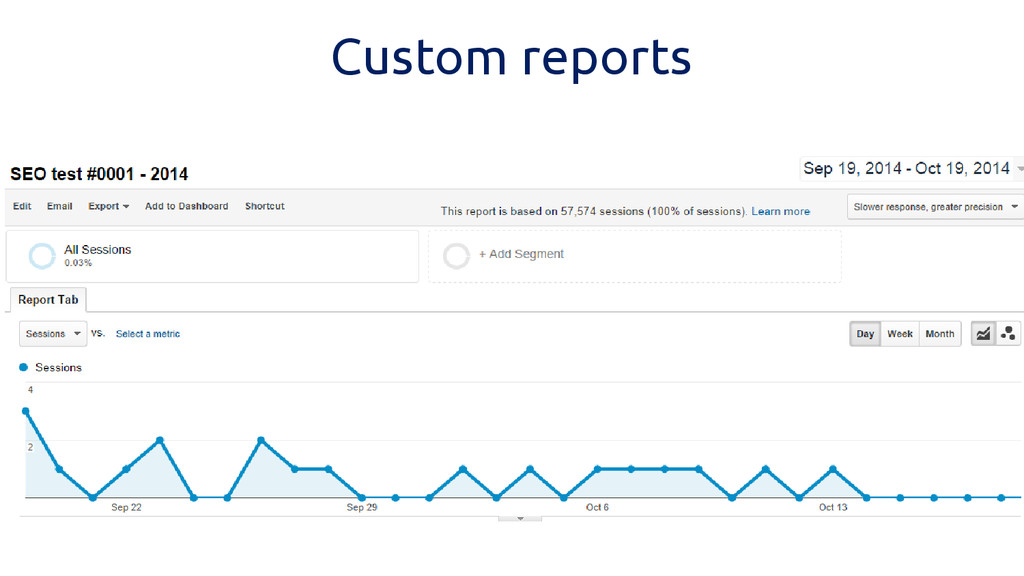
Custom reports
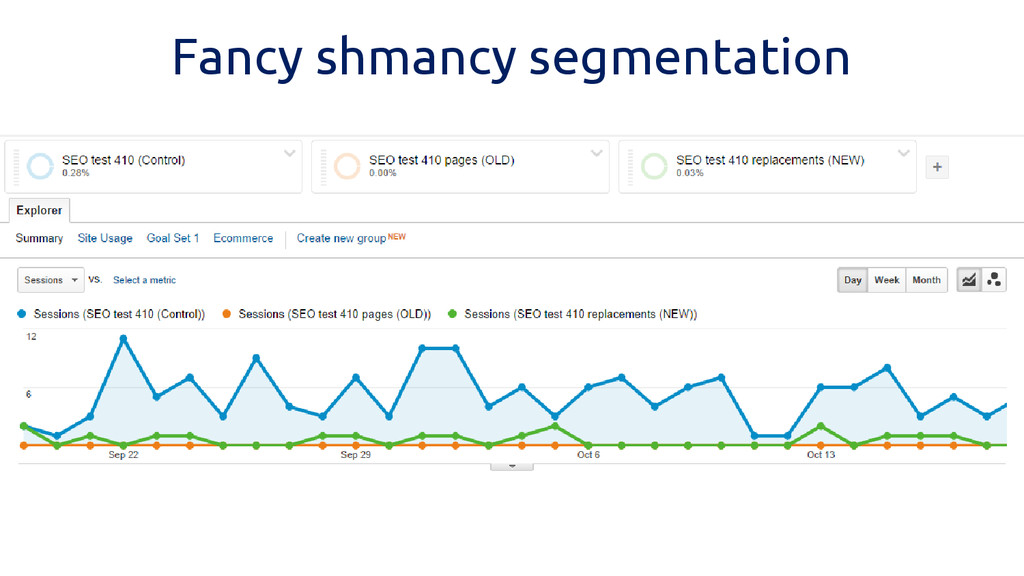
Fancy shmancy segmentation
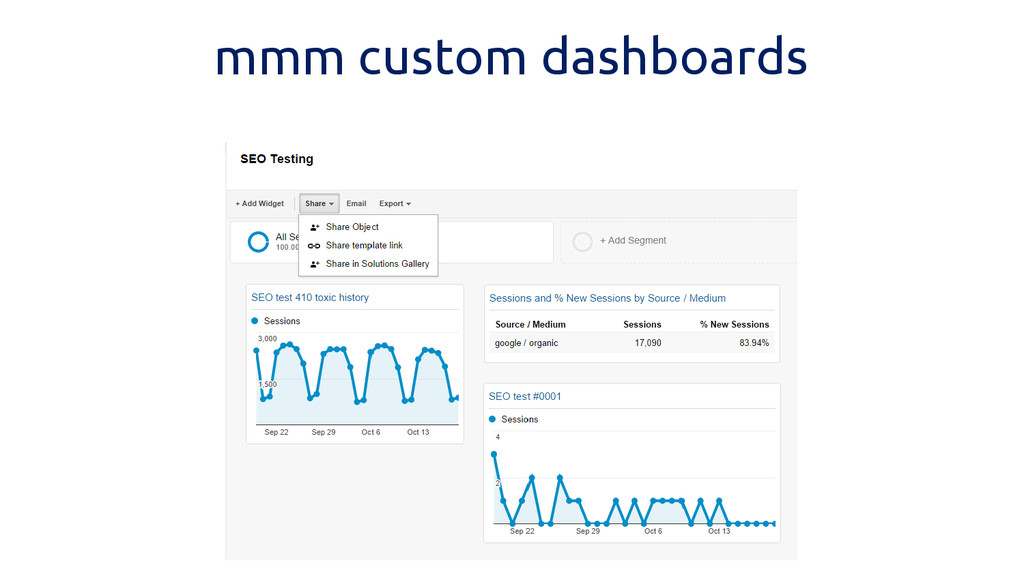
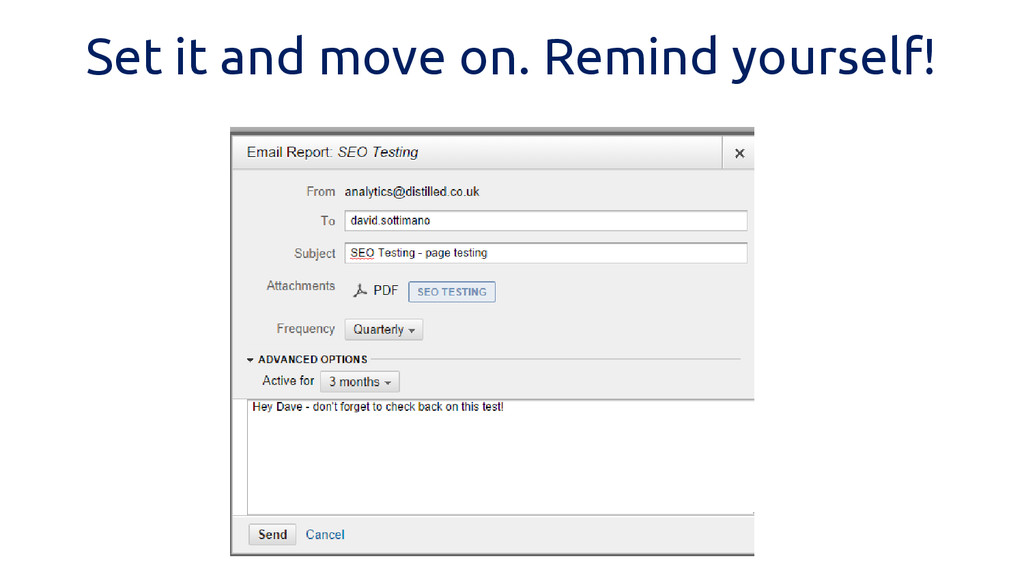
mmm custom dashboards
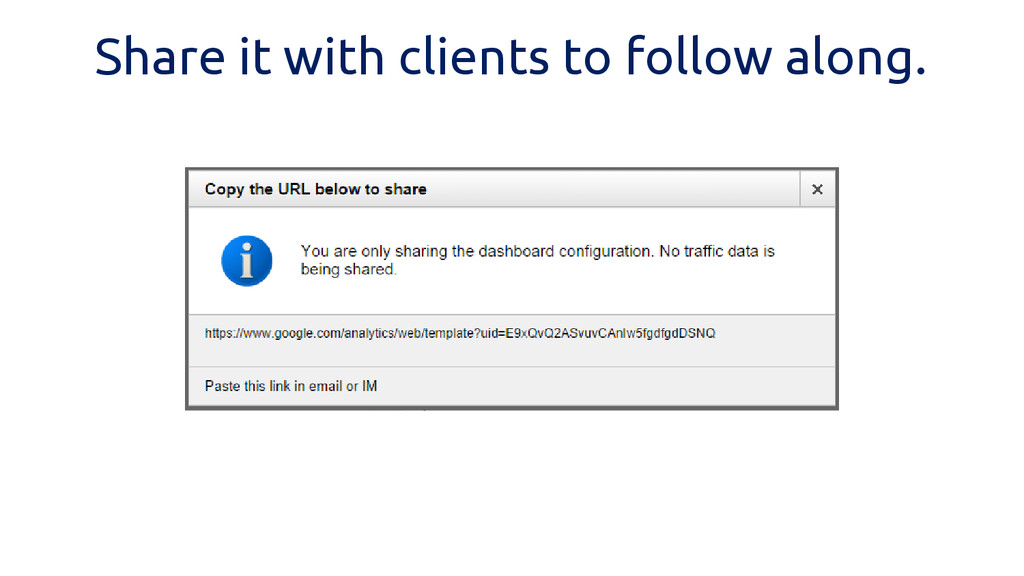
Share it with clients to follow along.
Set it and move on. Remind yourself!
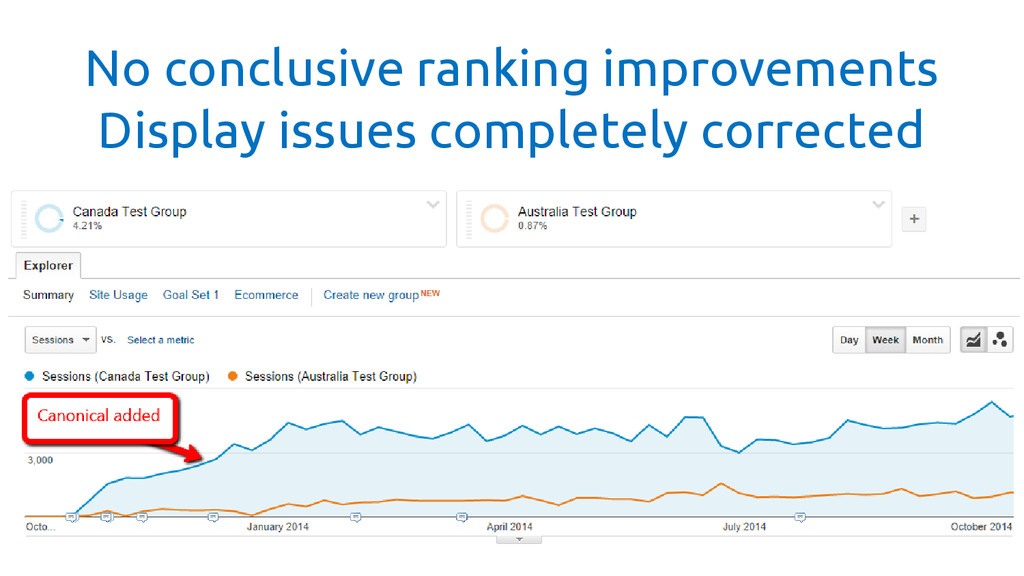
So, what happened with the hreflang project?
No conclusive ranking improvements Display issues completely corrected
A few tips.
Scenario1: I forgot to track the data.
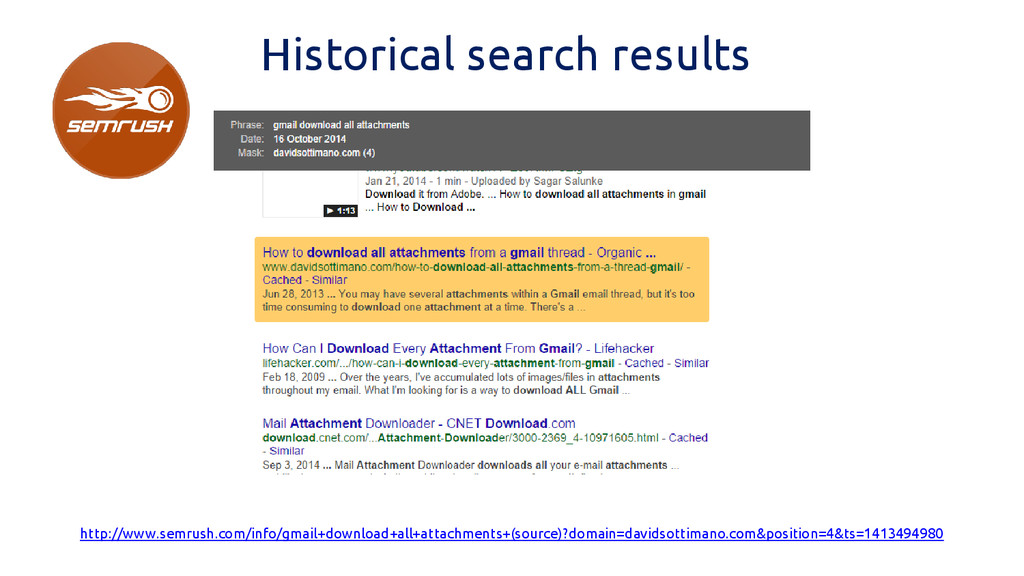
Historical search results http://www.semrush.com/info/gmail+download+all+attachments+(source)?domain=davidsottimano.com&position=4&ts=1413494980
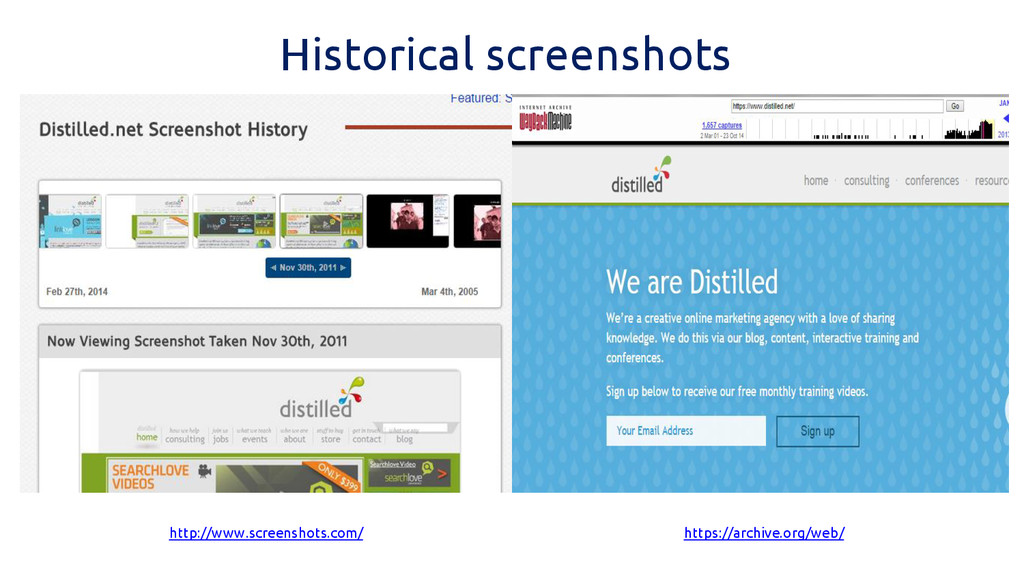
Historical screenshots http://www.screenshots.com/ https://archive.org/web/
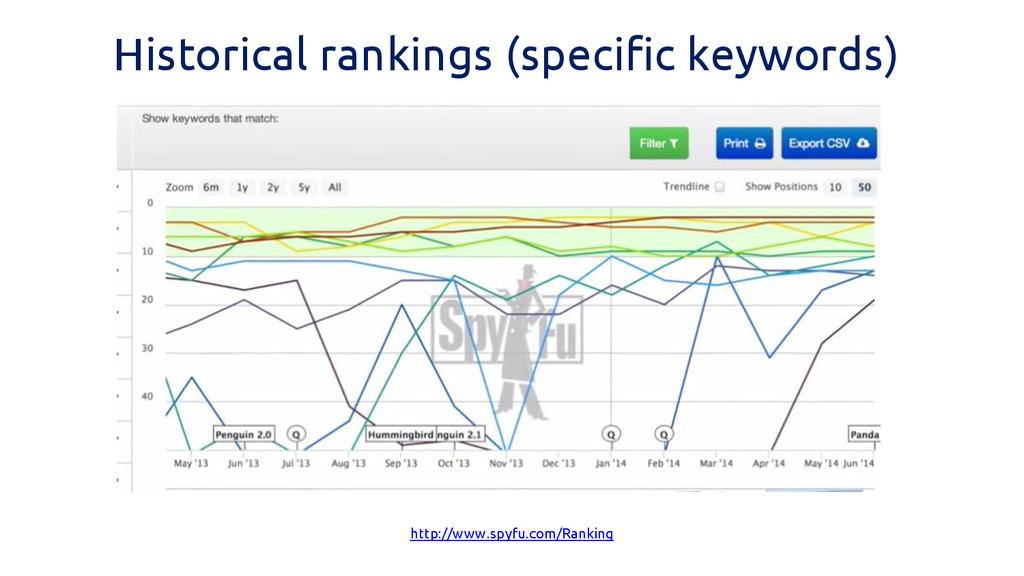
Historical rankings (specific keywords) http://www.spyfu.com/Ranking
Scenario 2: How do I find examples around the web?
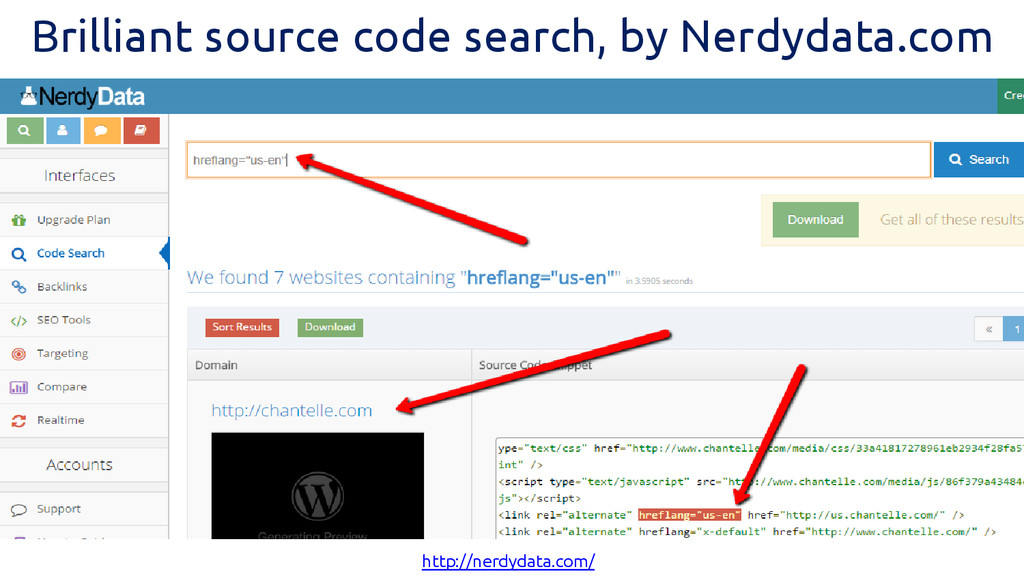
Brilliant source code search, by Nerdydata.com http://nerdydata.com/
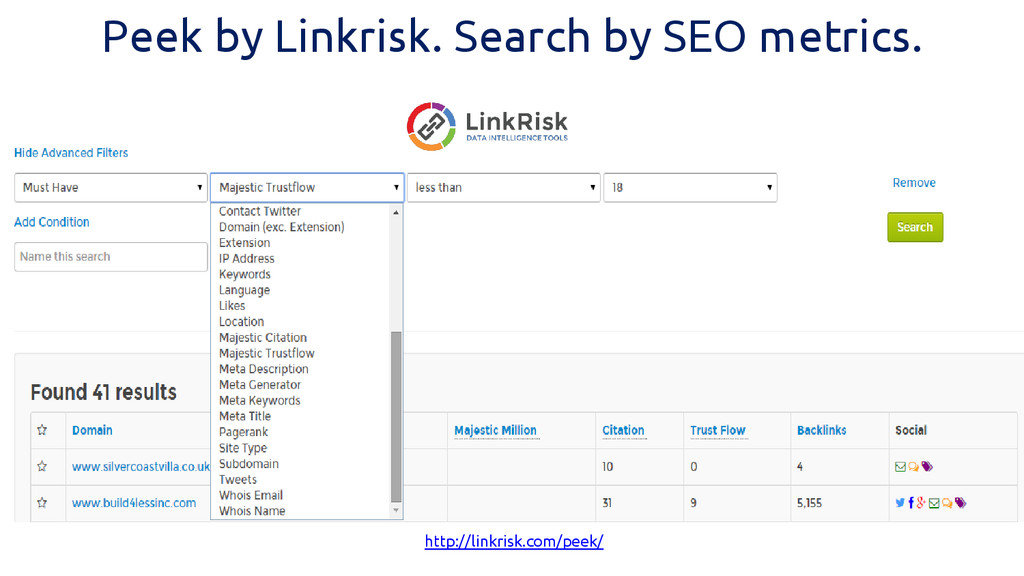
Peek by Linkrisk. Search by SEO metrics. http://linkrisk.com/peek/
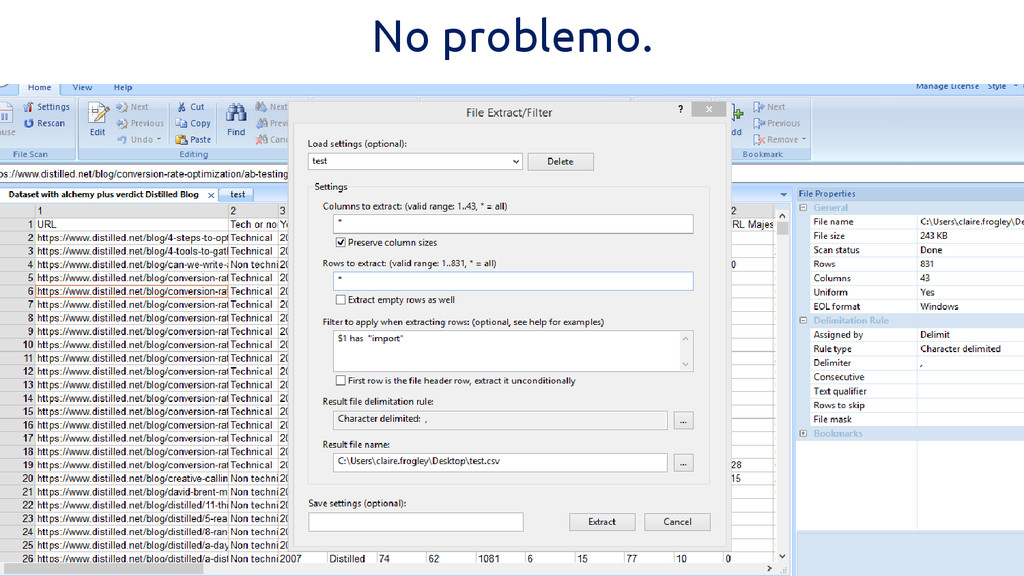
Scenario 3: I can’t open the entire CSV in Excel.
No, I don’t know how to code.
No problemo.
Use one of these. http://delimitware.com/ *windows 7 > http://recsveditor.sourceforge.net/c sv02.htm
*independent
Scenario 4: I need to gather data from webpages. I
don’t know how to code.
Scraping is fun, really fun. https://import.io/ http://scrapinghub.com/scrapy-cloud
The (highly experimental) future
Search is becoming too complex.
Why are we trying to analyse vast amounts of machine
data? Why not fight fire with fire?
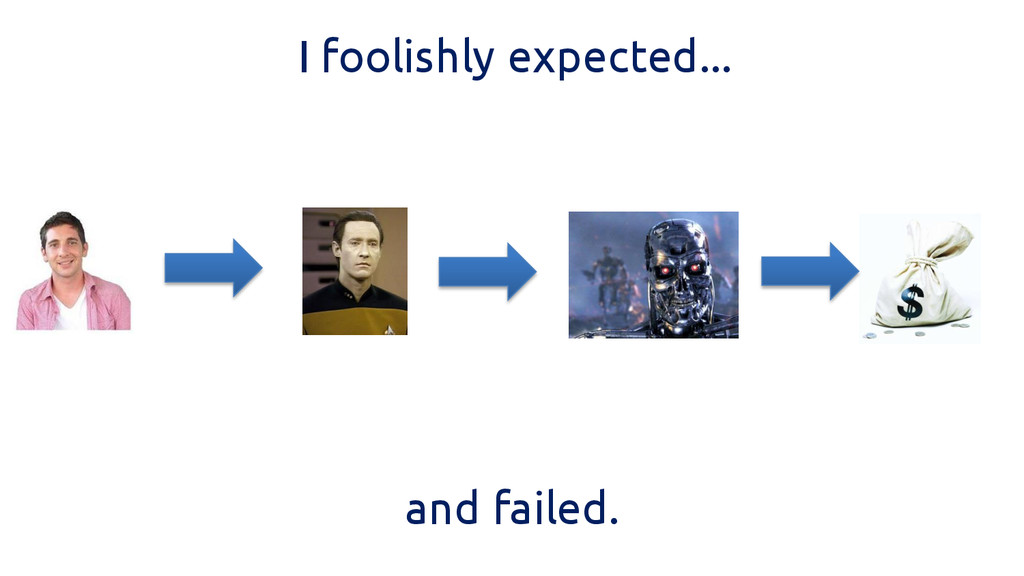
I had goals… Reverse engineer why Distilled blog posts do
well in search. And predict how successful new blog posts would be (organic traffic)
I foolishly expected... and failed.
None
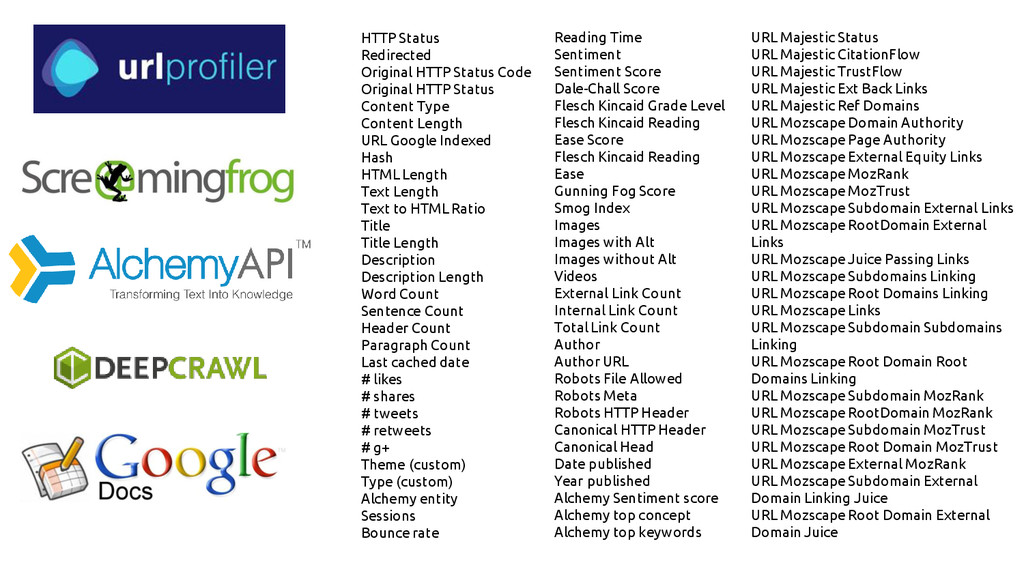
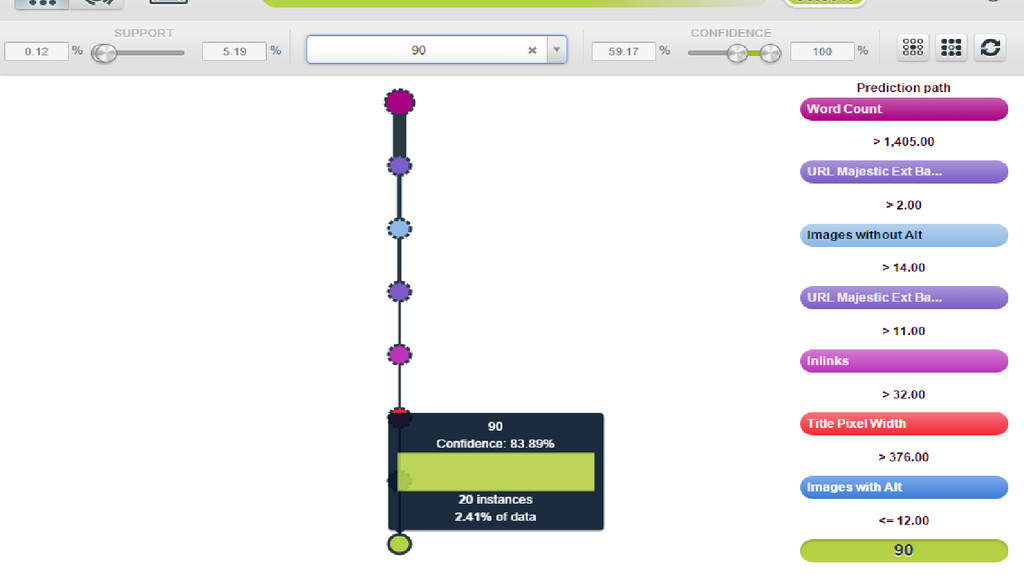
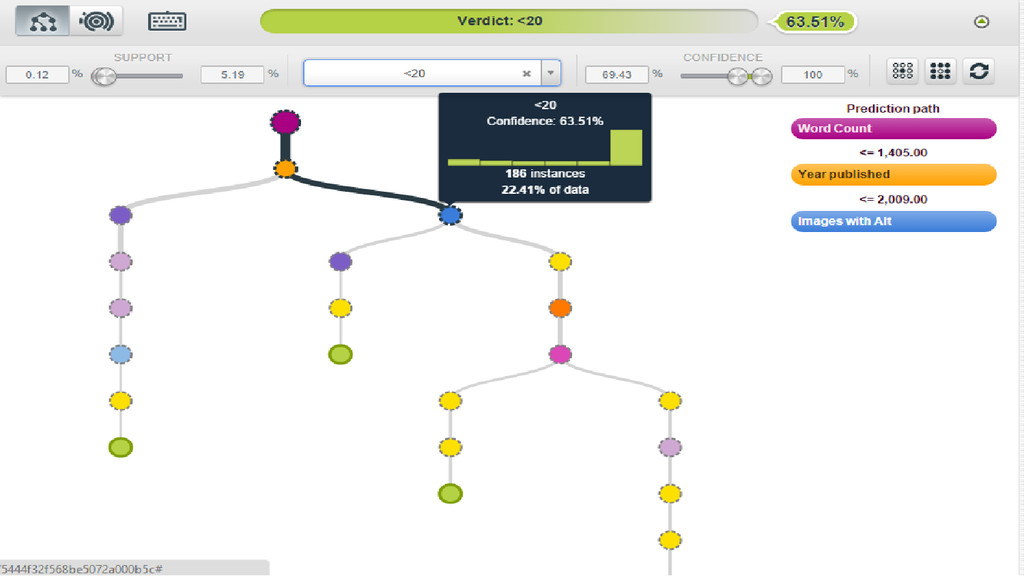
URL Majestic Status URL Majestic CitationFlow URL Majestic TrustFlow URL
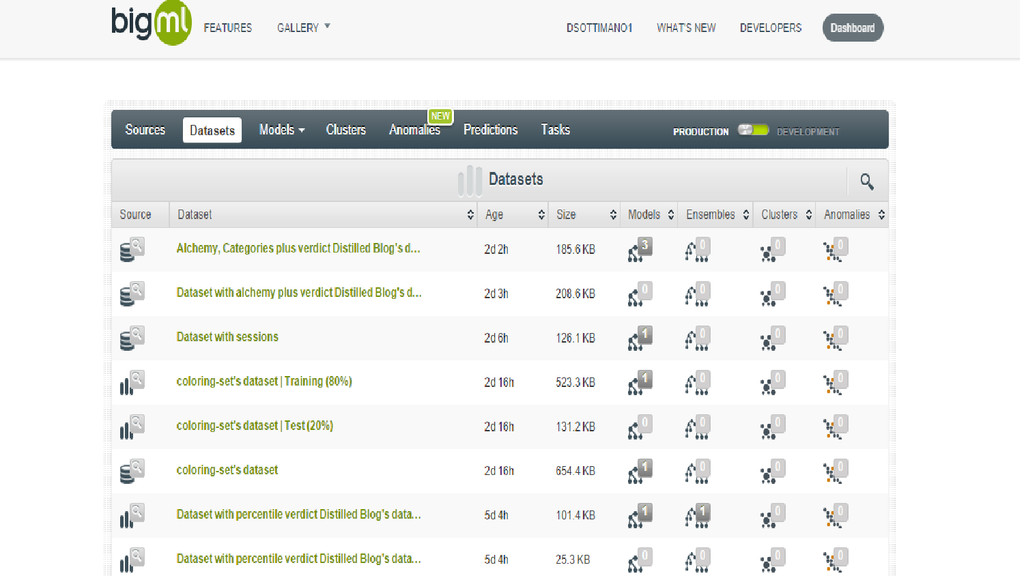
Majestic Ext Back Links URL Majestic Ref Domains URL Mozscape Domain Authority URL Mozscape Page Authority URL Mozscape External Equity Links URL Mozscape MozRank URL Mozscape MozTrust URL Mozscape Subdomain External Links URL Mozscape RootDomain External Links URL Mozscape Juice Passing Links URL Mozscape Subdomains Linking URL Mozscape Root Domains Linking URL Mozscape Links URL Mozscape Subdomain Subdomains Linking URL Mozscape Root Domain Root Domains Linking URL Mozscape Subdomain MozRank URL Mozscape RootDomain MozRank URL Mozscape Subdomain MozTrust URL Mozscape Root Domain MozTrust URL Mozscape External MozRank URL Mozscape Subdomain External Domain Linking Juice URL Mozscape Root Domain External Domain Juice Reading Time Sentiment Sentiment Score Dale-Chall Score Flesch Kincaid Grade Level Flesch Kincaid Reading Ease Score Flesch Kincaid Reading Ease Gunning Fog Score Smog Index Images Images with Alt Images without Alt Videos External Link Count Internal Link Count Total Link Count Author Author URL Robots File Allowed Robots Meta Robots HTTP Header Canonical HTTP Header Canonical Head Date published Year published Alchemy Sentiment score Alchemy top concept Alchemy top keywords HTTP Status Redirected Original HTTP Status Code Original HTTP Status Content Type Content Length URL Google Indexed Hash HTML Length Text Length Text to HTML Ratio Title Title Length Description Description Length Word Count Sentence Count Header Count Paragraph Count Last cached date # likes # shares # tweets # retweets # g+ Theme (custom) Type (custom) Alchemy entity Sessions Bounce rate
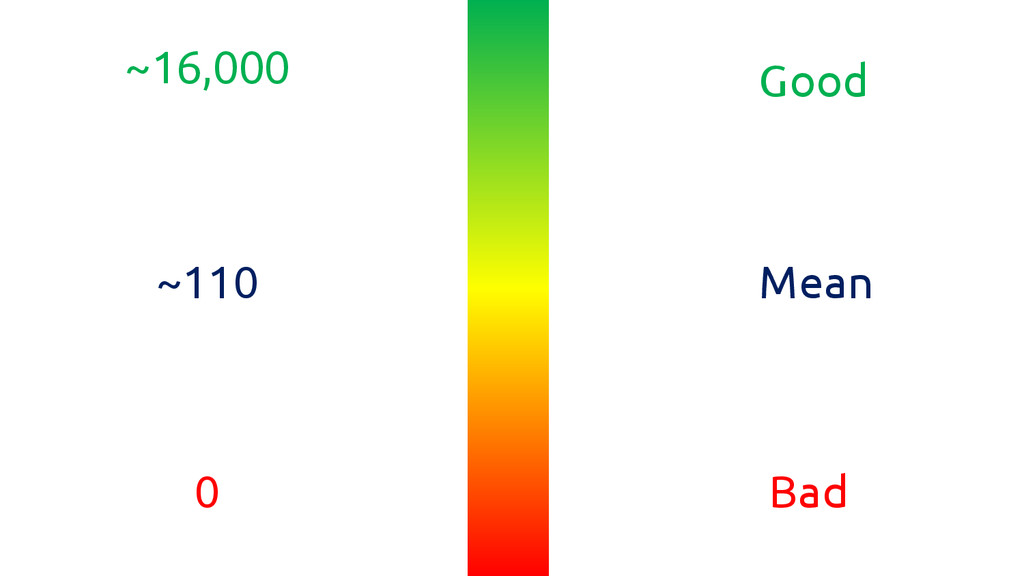
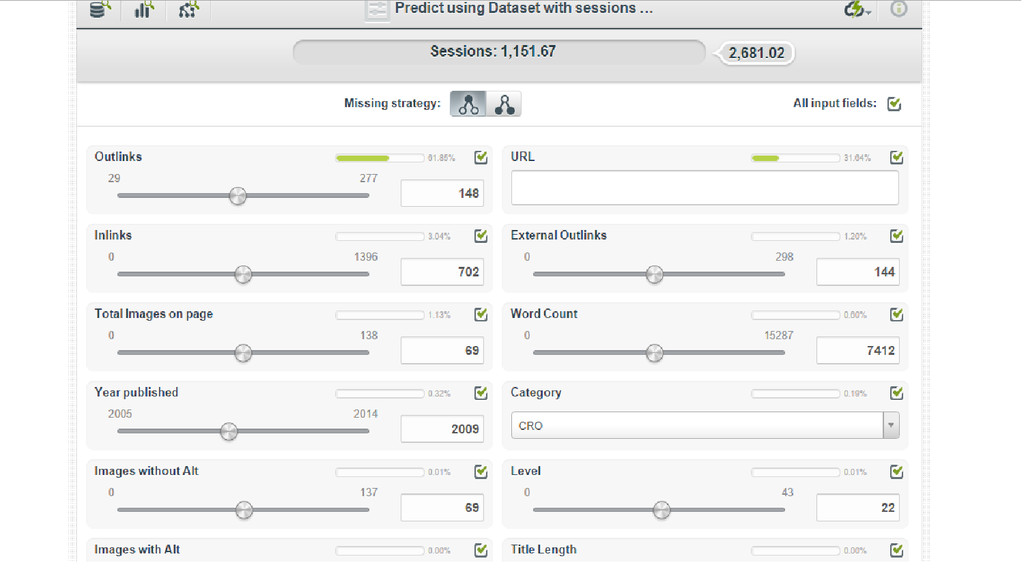
I used organic sessions as my objective field, to classify
what was good/bad.
Mean Good Bad 0 ~16,000 ~110
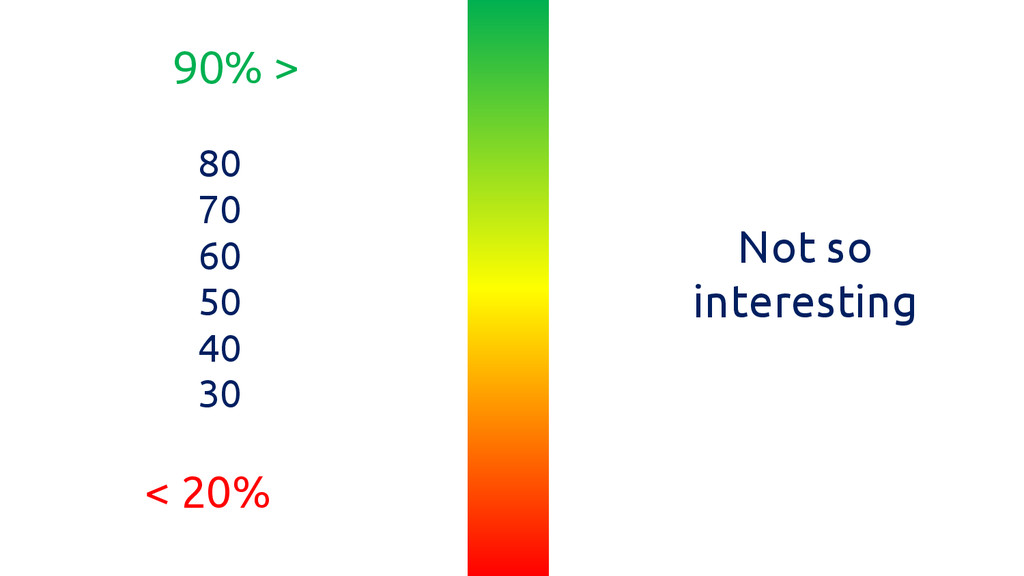
< 20% 90% > 80 70 60 50 40 30
Not so interesting
None
None
So, longer posts = profit?
None
None
None
None
I fed garbage in, and got garbage out. Tip! Don’t
use metrics that are well correlated with rankings.
There’s so much opportunity here. So what can you do
about it?
Get better at defining “great content”.
If it gets links, shares, converts, we usually class it
as “good”. But what made it “good” ?
Tutorial Technical > contains code Controversial Breaking news Funny Serious
Off topic Controversial List post > top 5,10, checklist Tool review
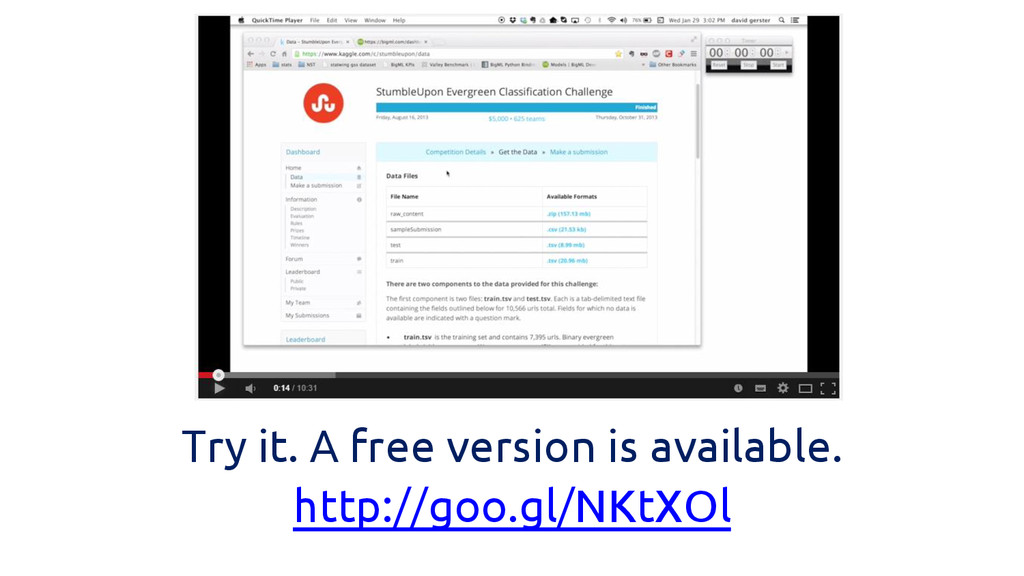
Try it. A free version is available. http://goo.gl/NKtXOl
Two little things I want you to remember.
Build a better practice by binning best practice
Prove it. Data or it didn’t happen
Thanks @dsottimano
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}