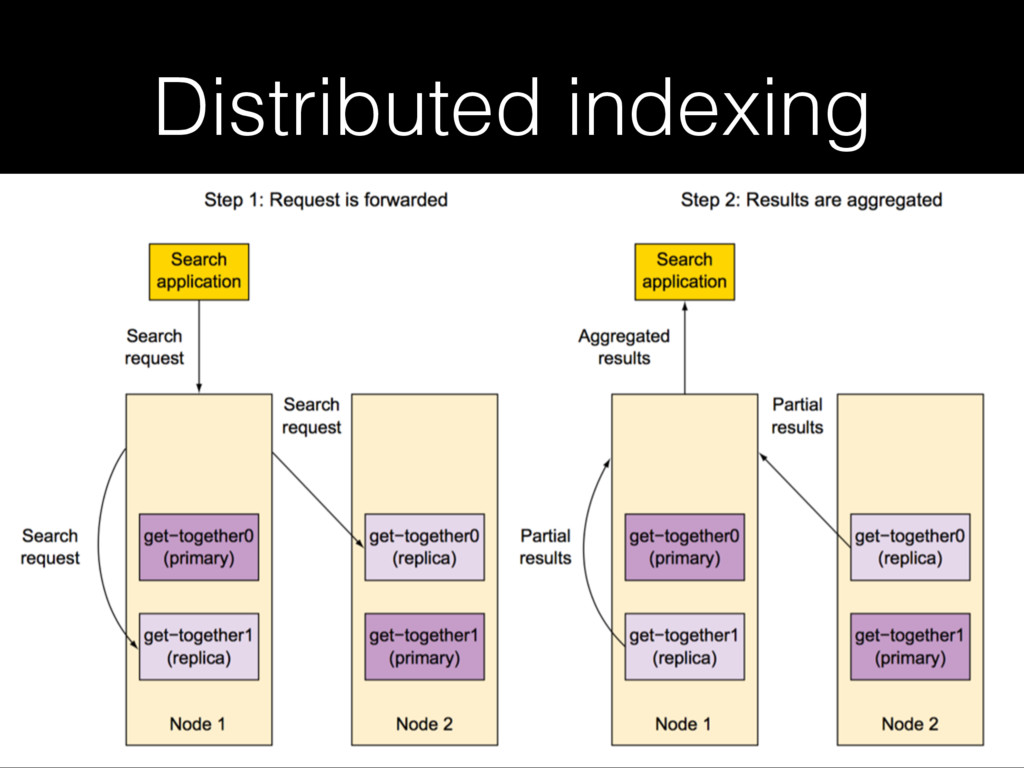
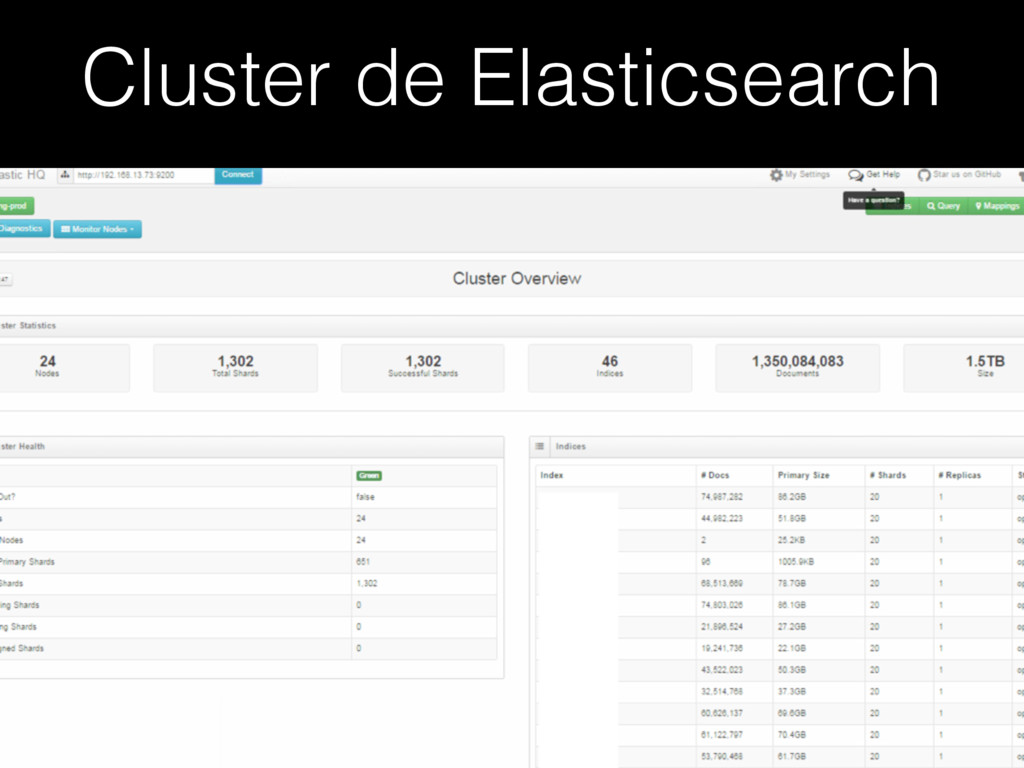
En esta sesión analizaremos el caso de un proyecto que se realizó para una institución financiera para manejar el almacenamiento y búsqueda de grandes cantidades de datos. La implementación utiliza un cluster de 24 nodos distribuidos para manejar y buscar miles de millones de documentos que representan cientos de terabytes. Entre las tecnologías que se utilizaron están #StorageGrid y #Elasticsearch.
En esta plática compartiremos algunos de los principales retos técnicos del proyecto, y cómo se resolvieron
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
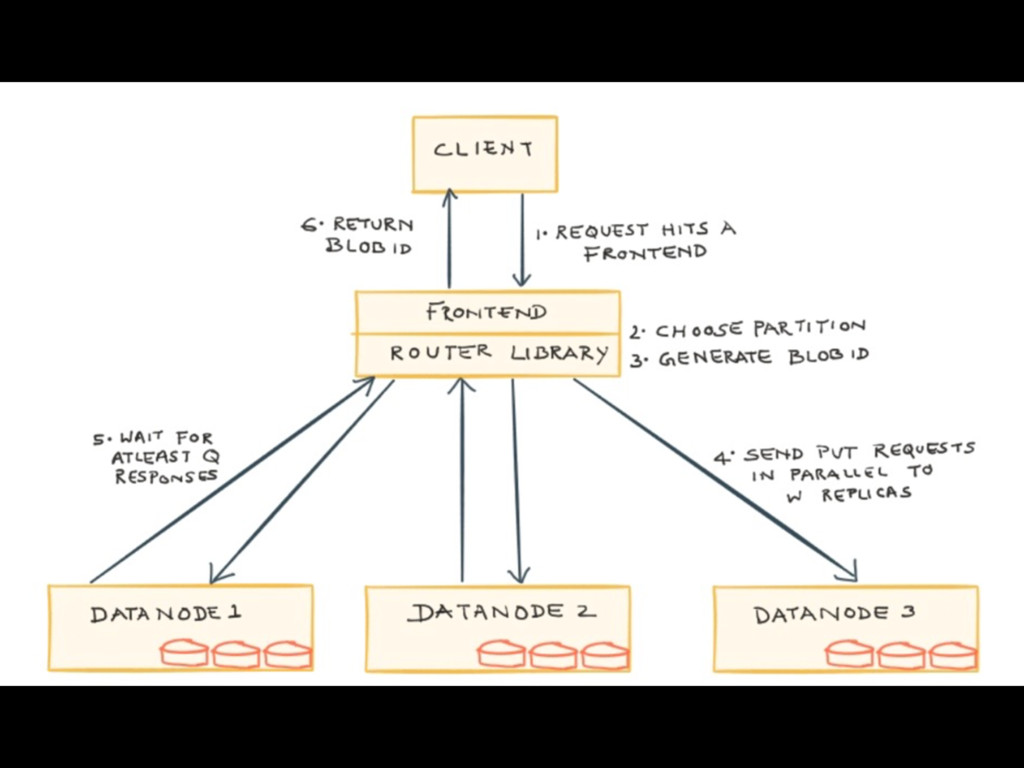{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
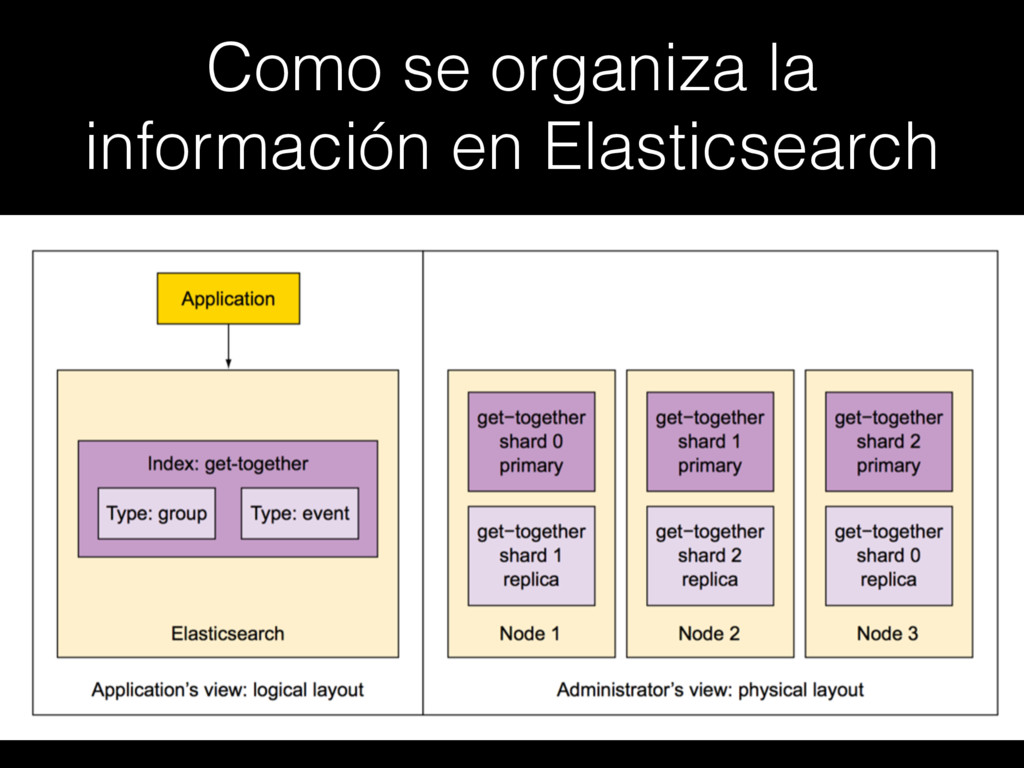{kind=link}
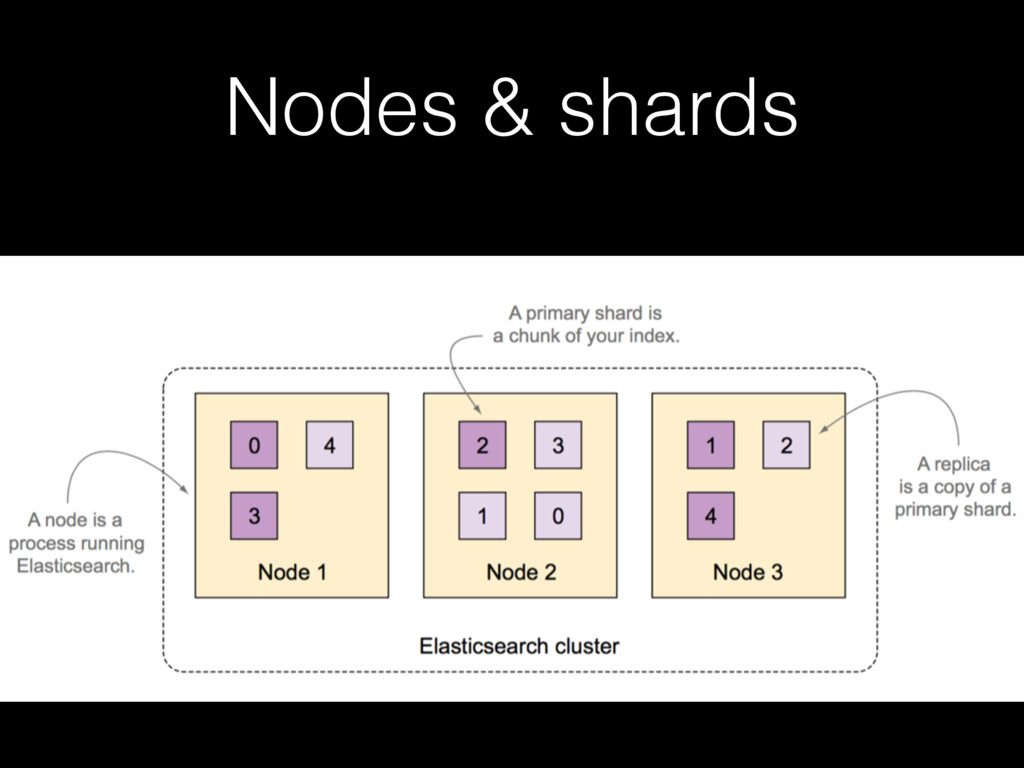{kind=link}
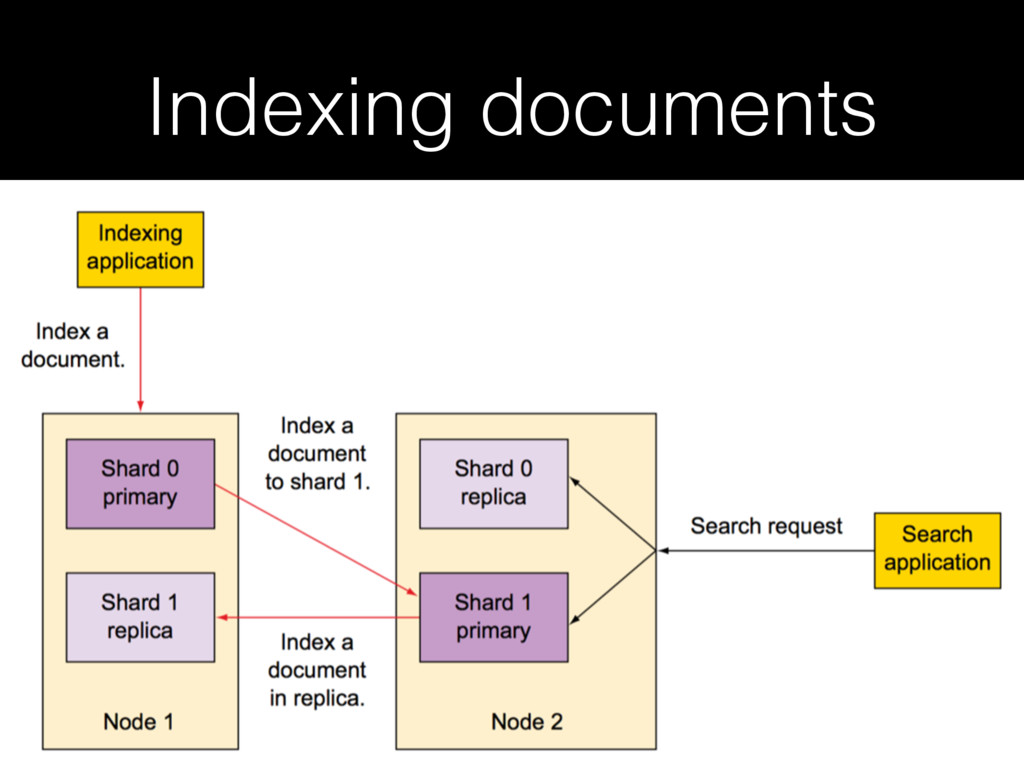{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}