Мониторинг - это множество возможностей, но надо уметь с ним обращаться в сложной распределенной системе. Во время доклада будет показано, как это делается в .NET.
Что слушатели вынесут из доклада:
- поймут разные аспекты мониторинга системы;
- узнают конкретные примеры использования технологий мониторинга;
- узнают, зачем мониторинг нужен с разных сторон;
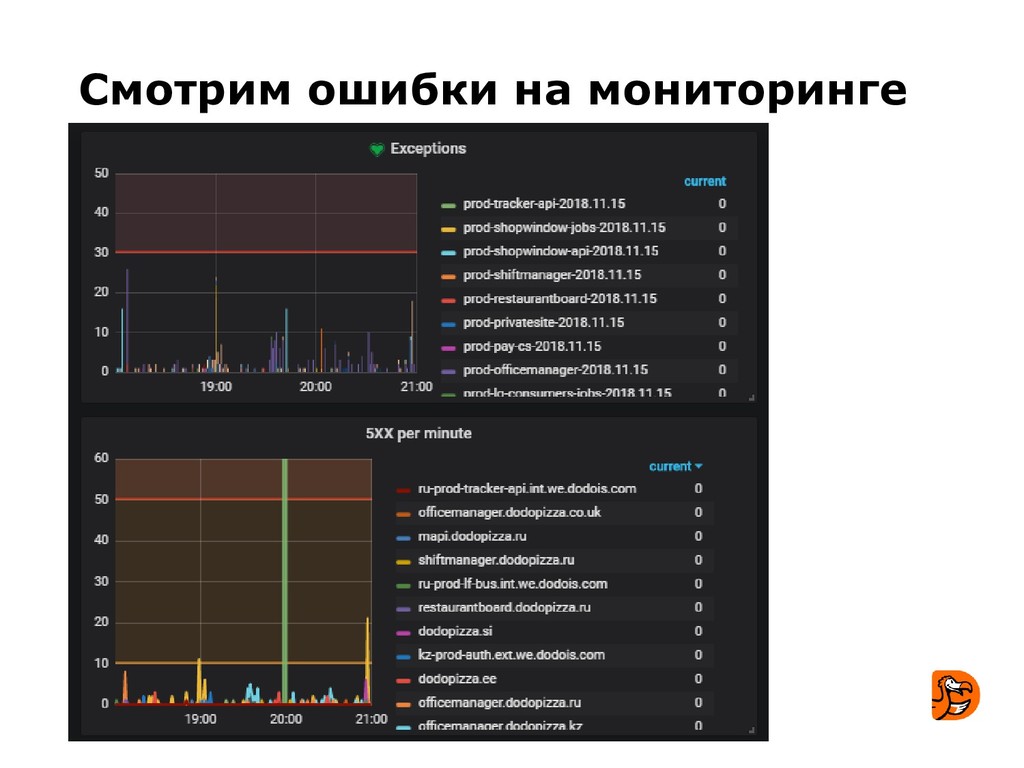
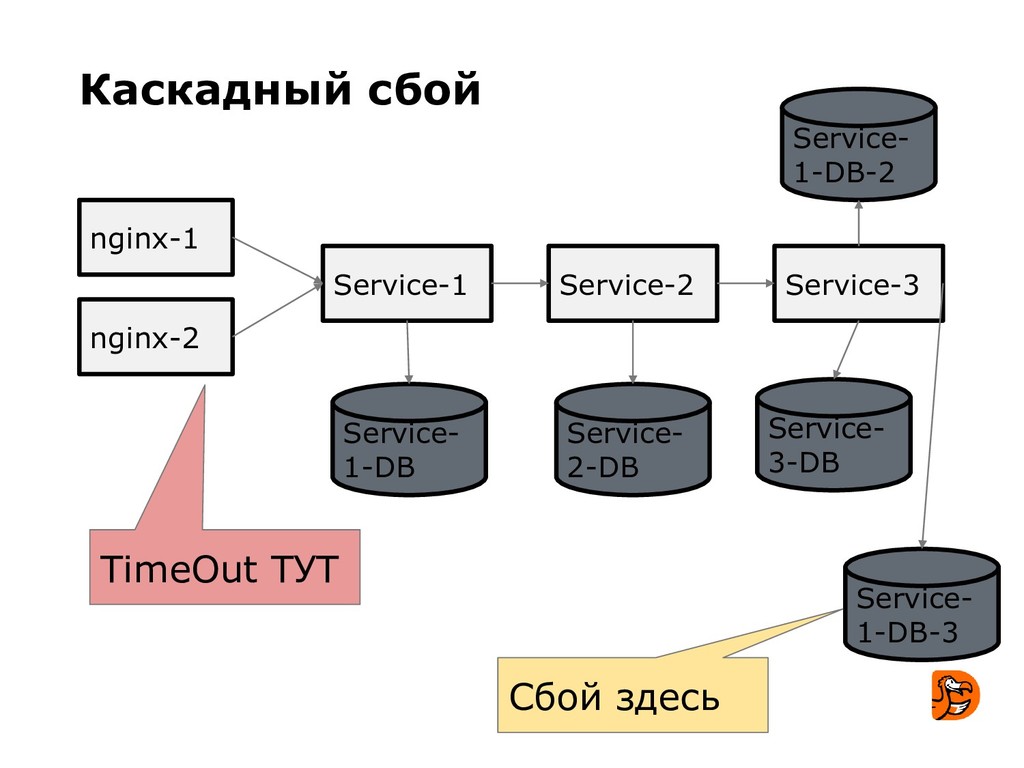
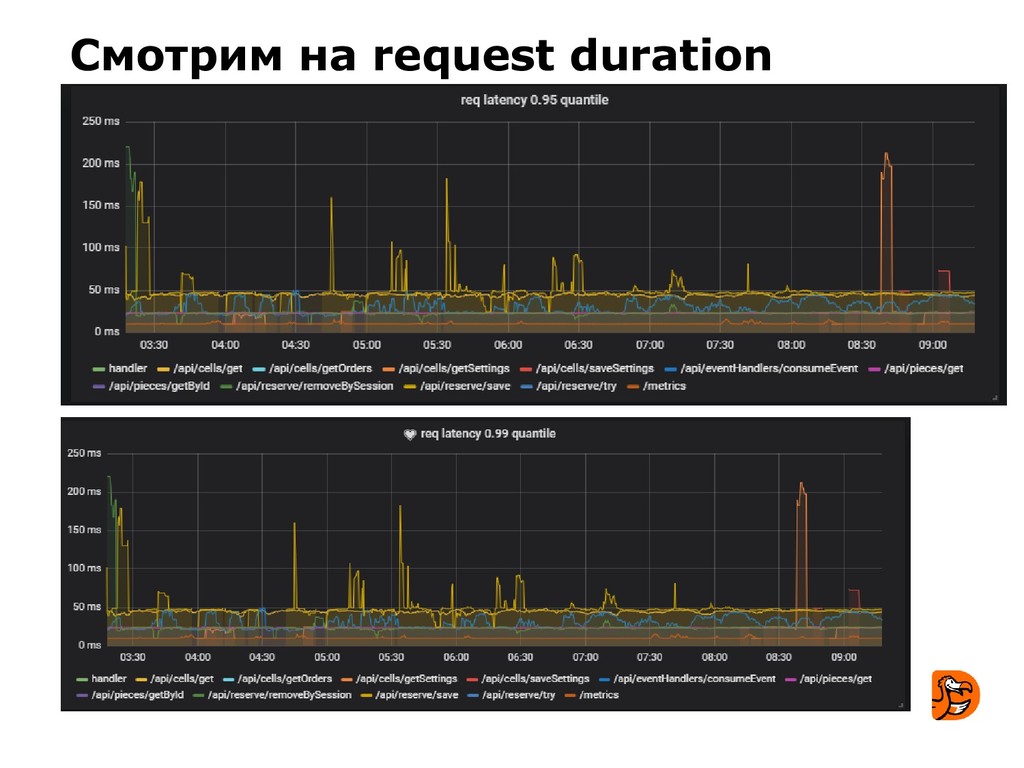
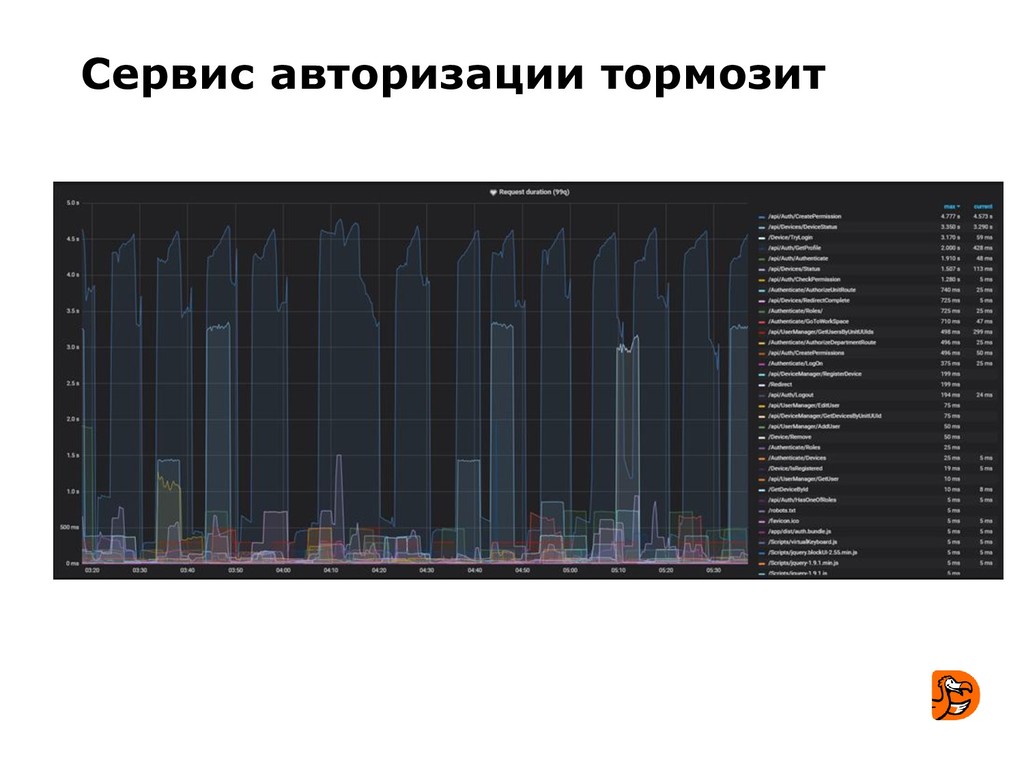
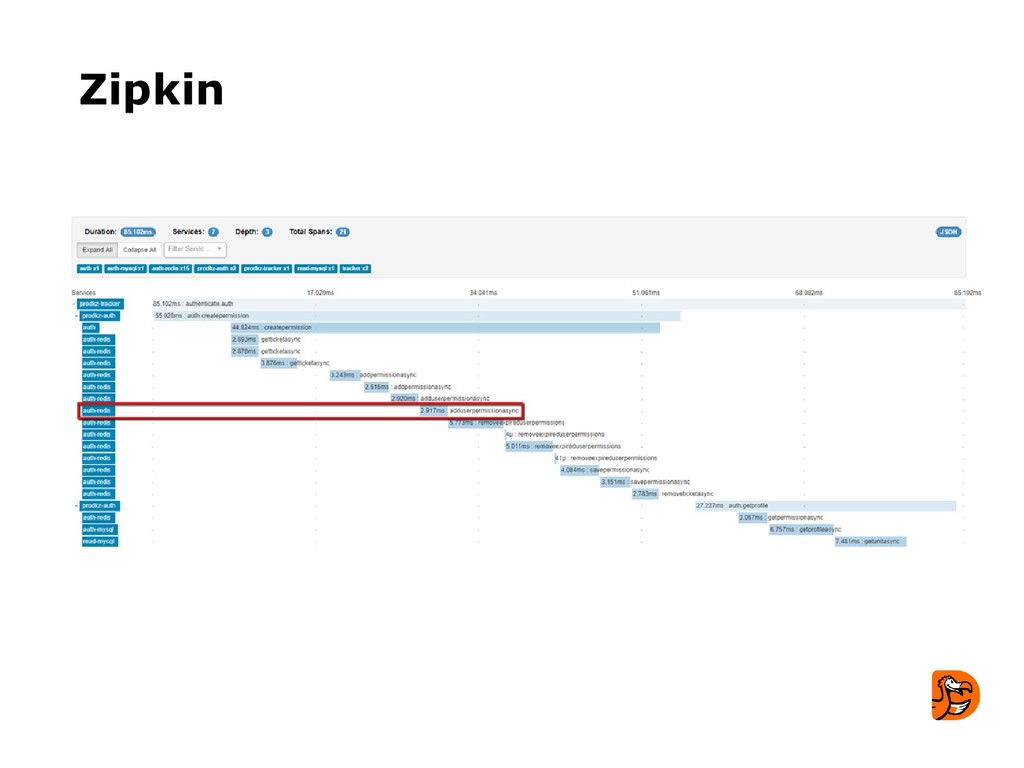
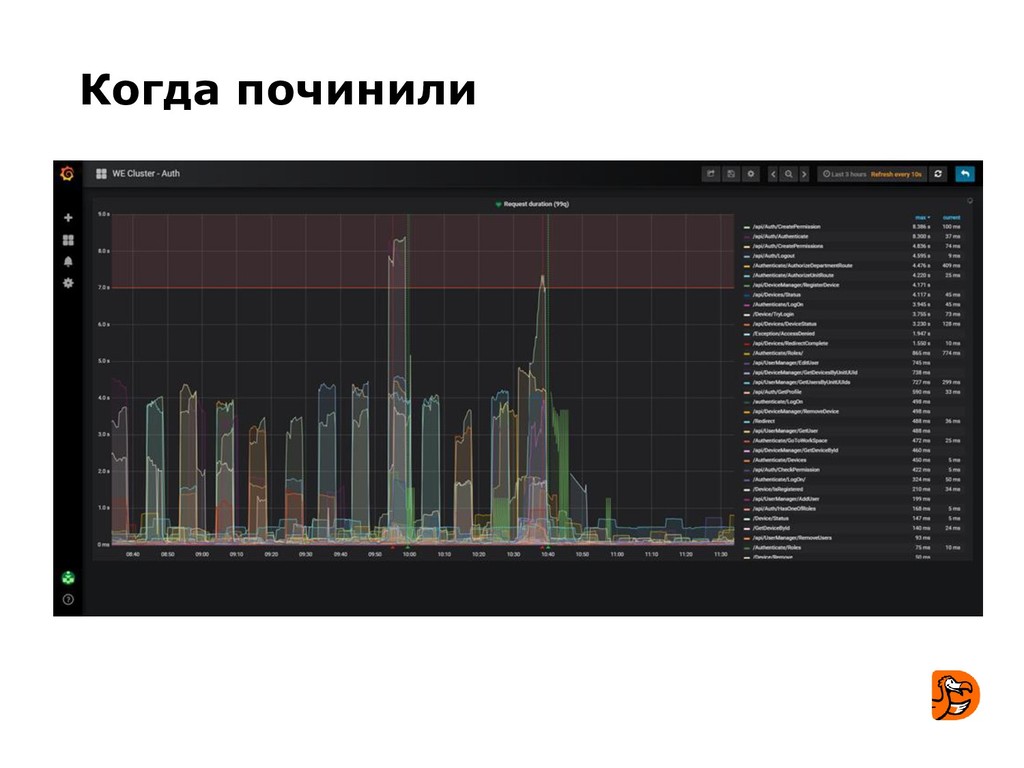
- узнают несколько примеров сбоев, которые имели место в Додо.
Для кого данный доклад: для разработчиков, которые хотят сами следить за своей системой в боевых условиях, понимать ее работу.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Вопросы Павел Притчин Dodo Pizza, Dodo IS Core Team [email protected]](https://files.speakerdeck.com/presentations/0f6dc5c5f7ac4670b50afd48e6798cd8/slide_57.jpg){kind=link}