Greenplum — ведущая массивно-параллельная СУБД с открытым исходным кодом. Горизонтальная расширяемость до десятков петабайт, понятный пользователям синтаксис ANSI SQL, транзакционность, совместимость с PostgreSQL, возможность обучать и применять модели машинного обучения — всё это сделало «зелёную сливу» популярнейшим решением для масштабных аналитических систем и в небольших стартапах, и в огромных корпорациях.
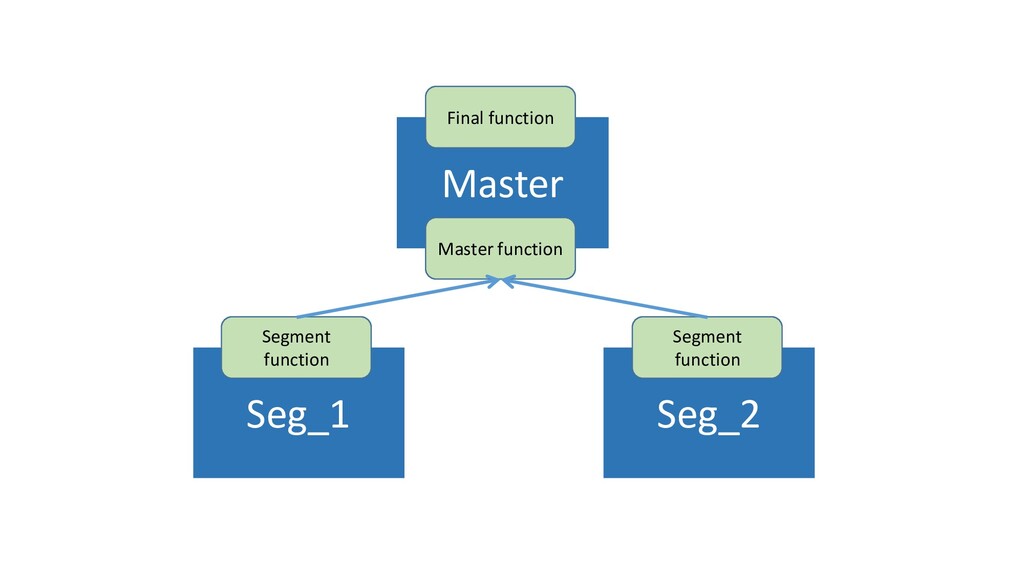
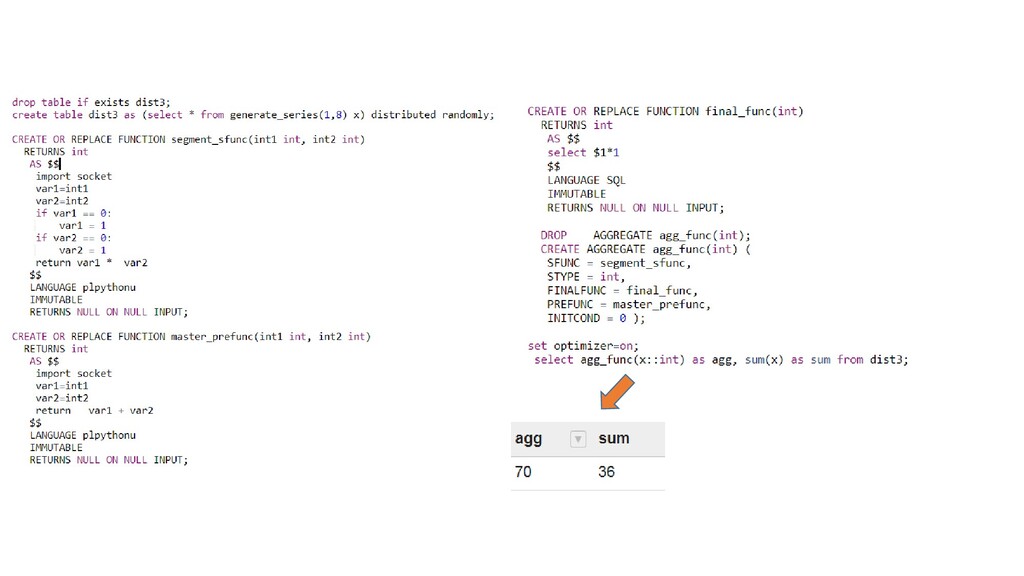
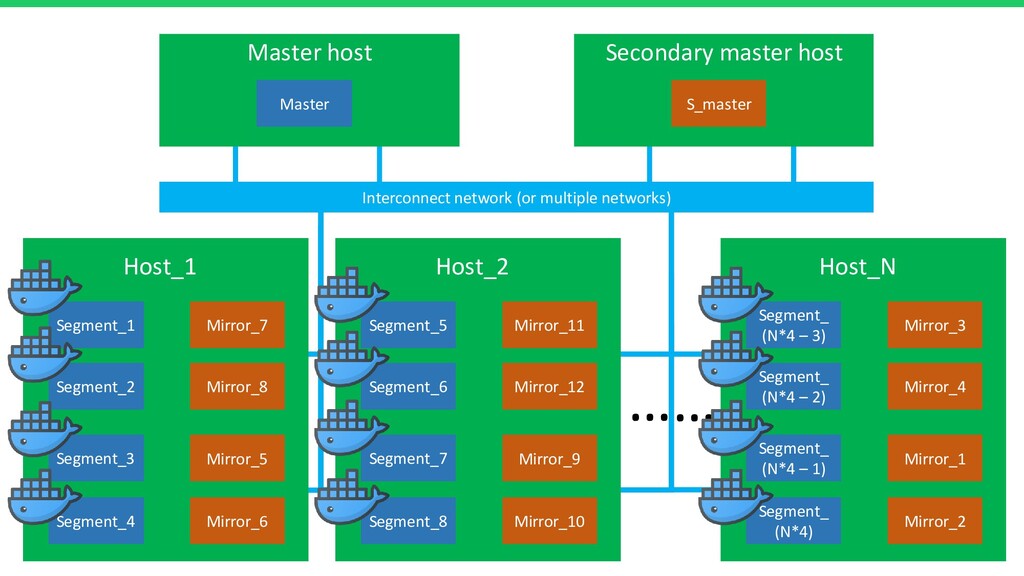
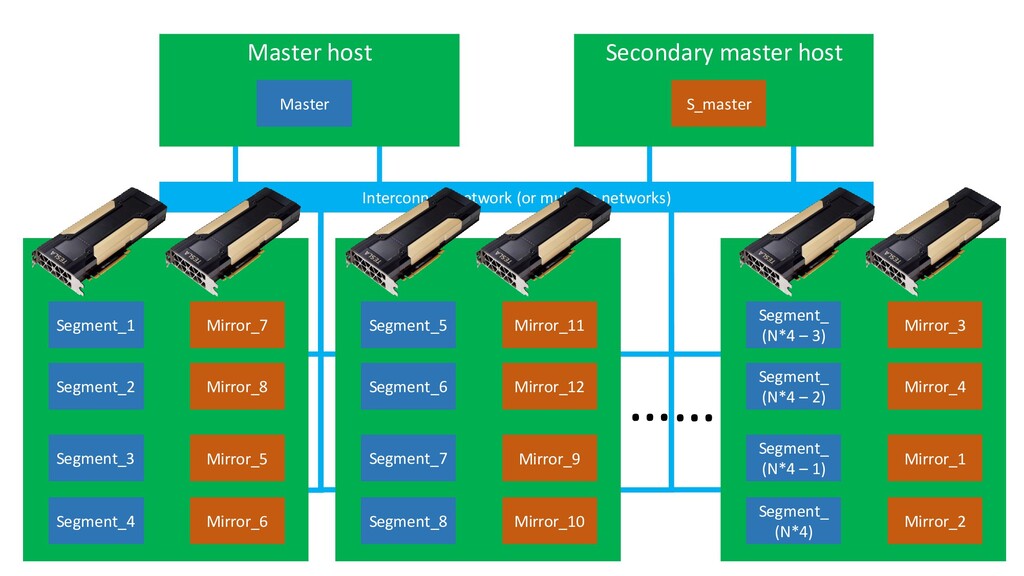
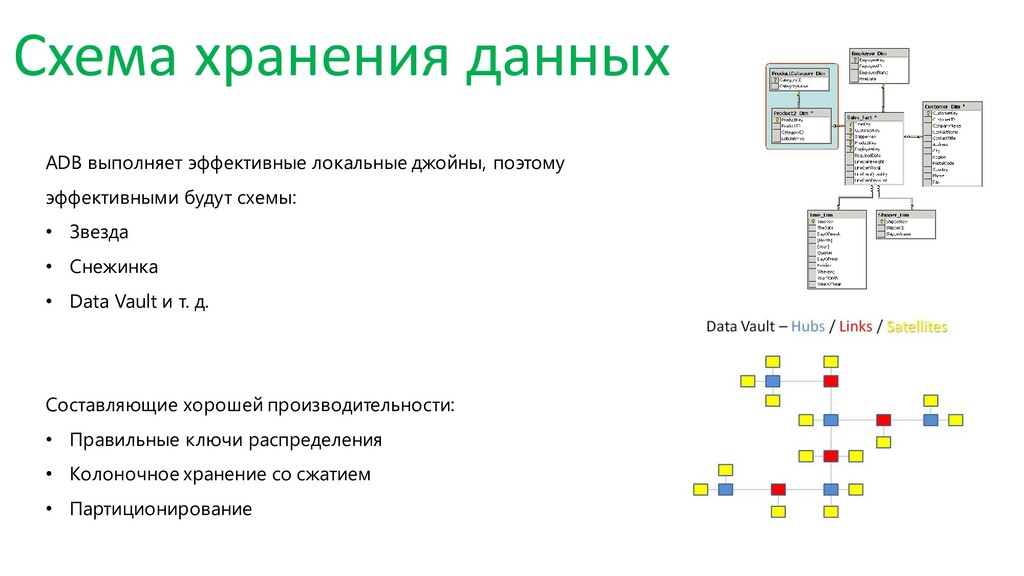
В докладе я детально расскажу про устройство СУБД, архитектуру, консистентность, резервирование и шардирование. А также затрону темы:
Параллельная транзакционная интеграция с другими кластерными системами
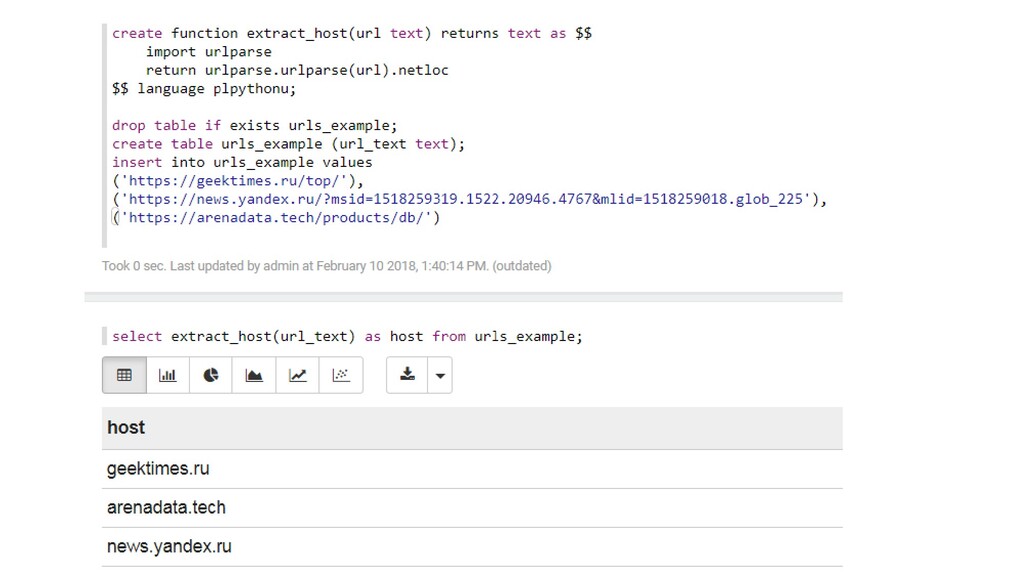
Использование ML-моделей как SQL-функций в распределенной СУБД
Разграничение ресурсов в аналитической СУБД
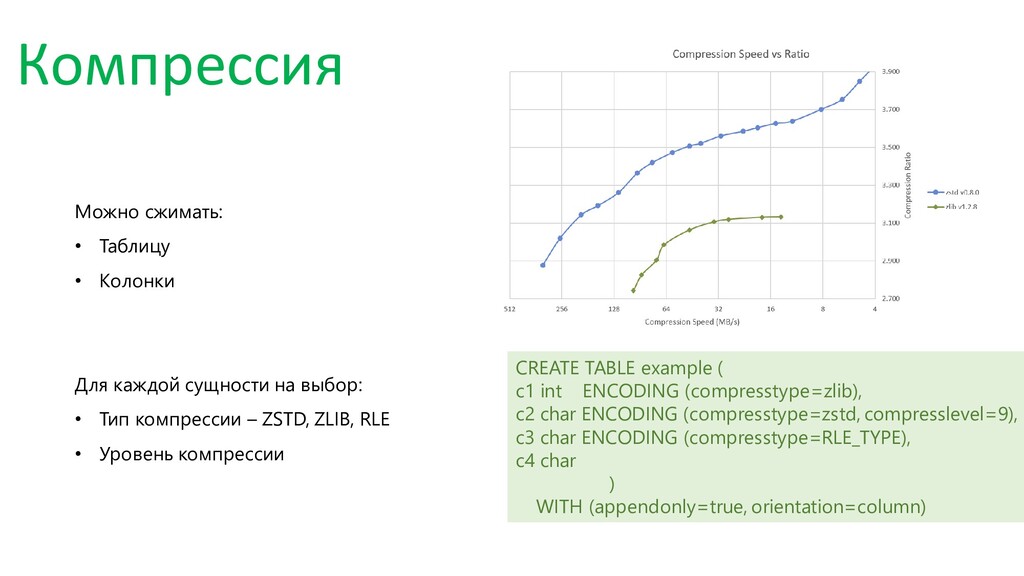
Компрессия — почему это так важно в аналитике
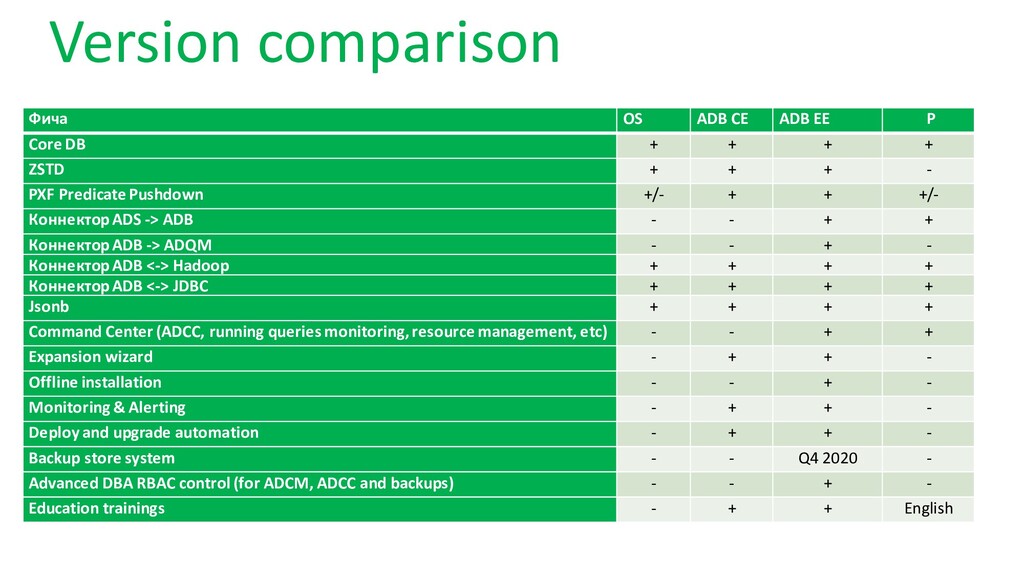
Какие дистрибутивы СУБД Greenplum доступны для использования в России
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}