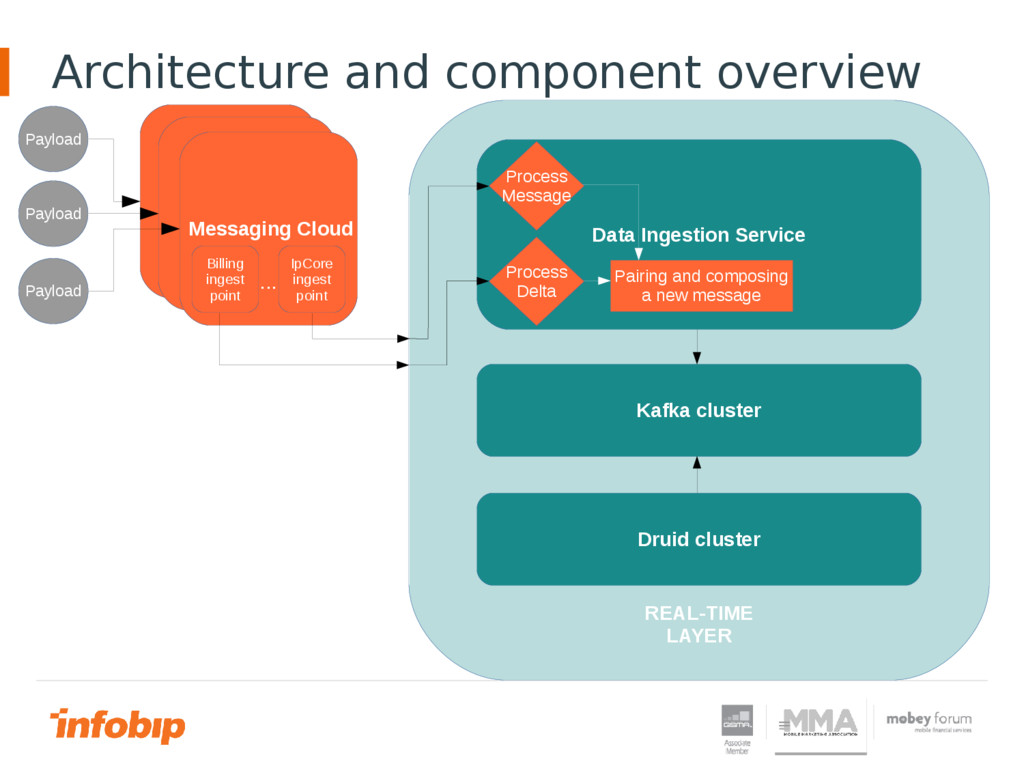
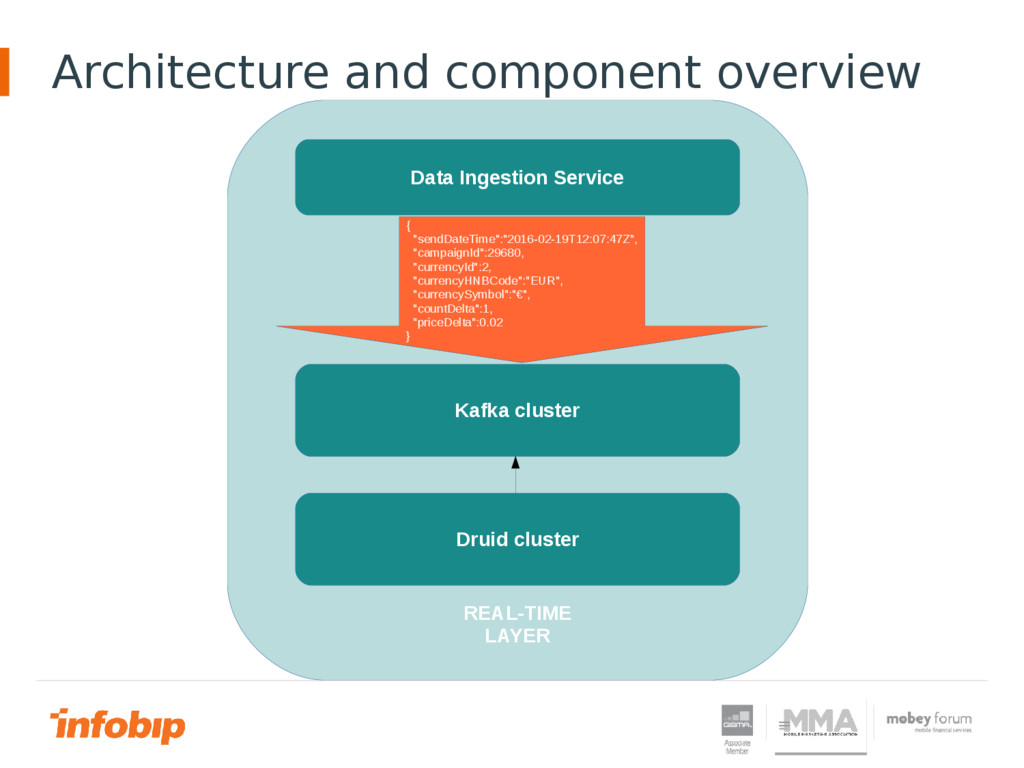
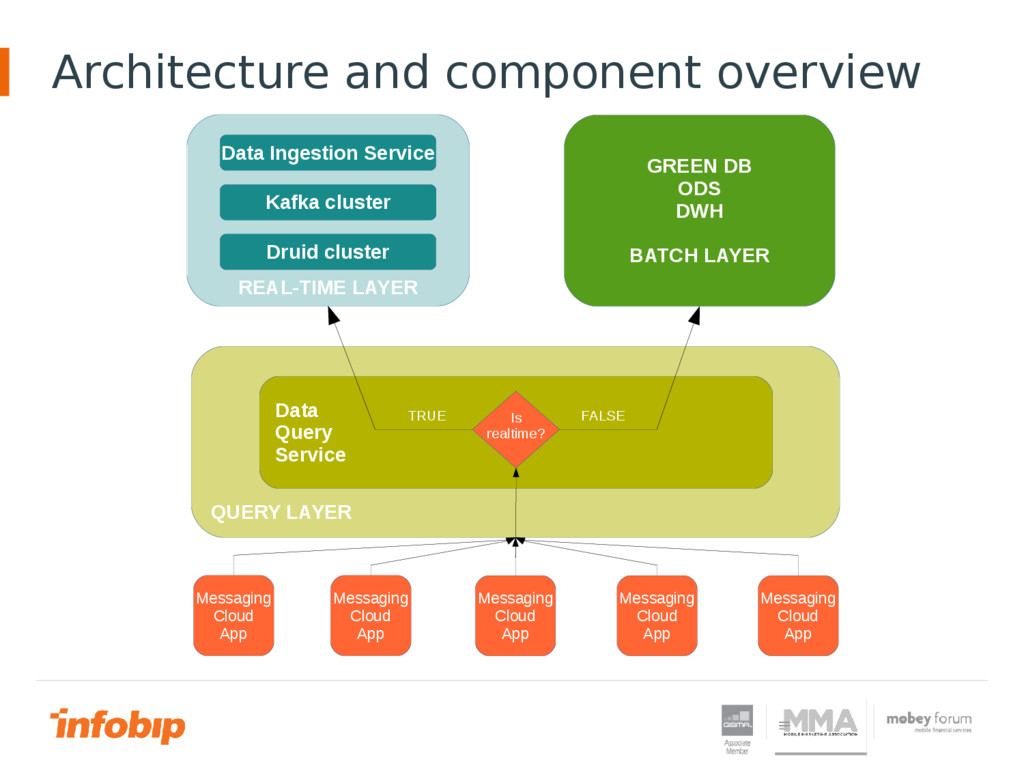
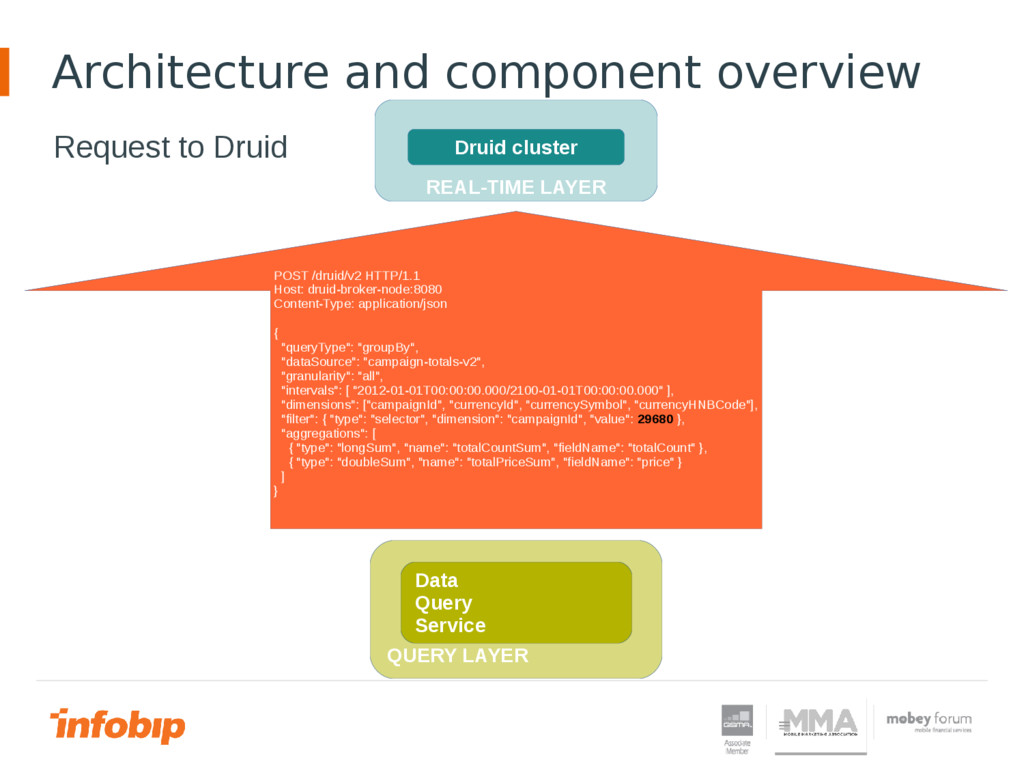
View data in real time in Big Data environment is becoming more and more challenging. Classical transactional systems and data replication encounter more obstacles in Big Data environment. One of those obstacles is large latency between time when data entered in the system and time when data is ready for querying. In this presentation will be shown the path that Infobip has chosen to try to achieve real time in Big Data environment.
Keywords: Lambda architecture, Redis.io, Apache Kafka, druid.io
http://www.infobip.com/en/dev-days
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![www.infobip.com Q/A Davor Poldrugo software engineer [email protected] REAL-TIME BIG DATA](https://files.speakerdeck.com/presentations/7f10f9bb54654cd2a341c295bd199e20/slide_30.jpg){kind=link}