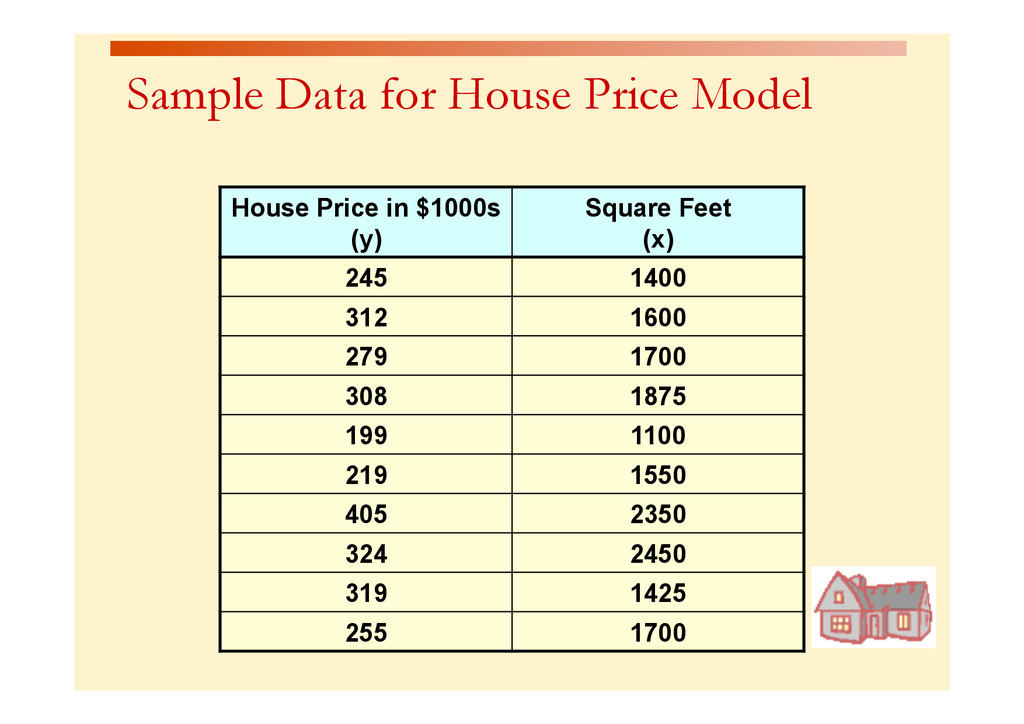
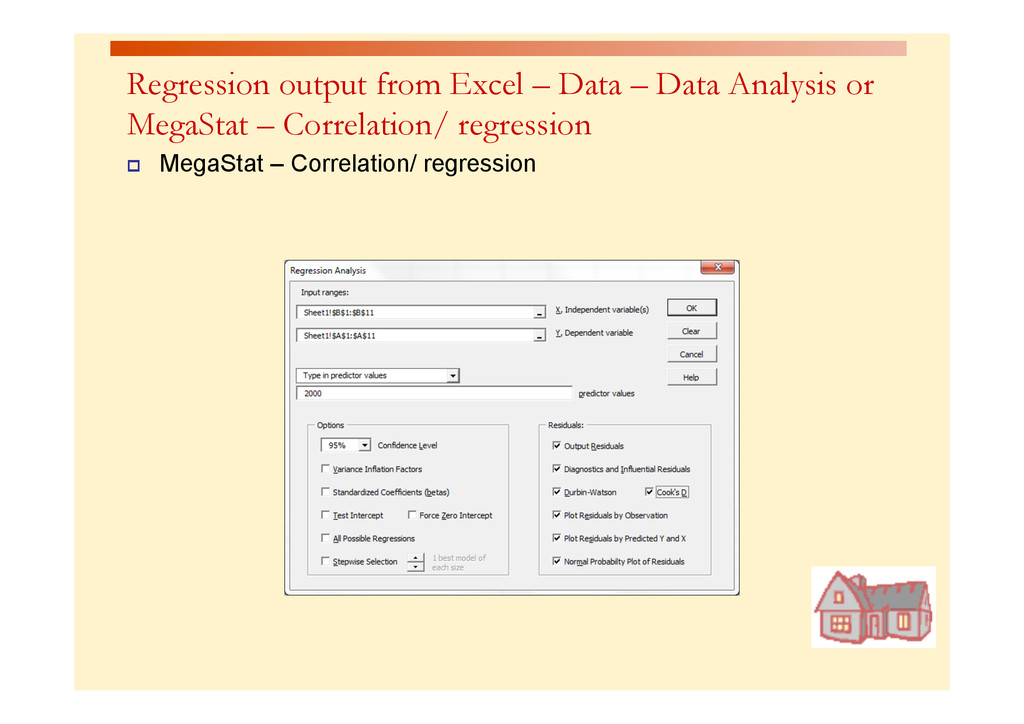
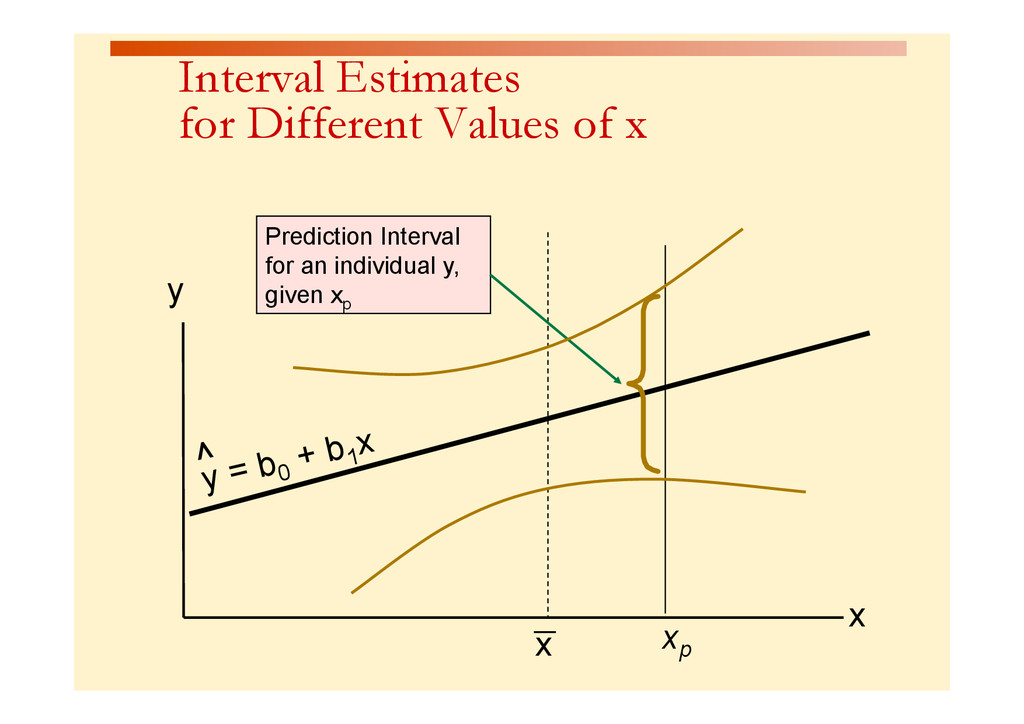
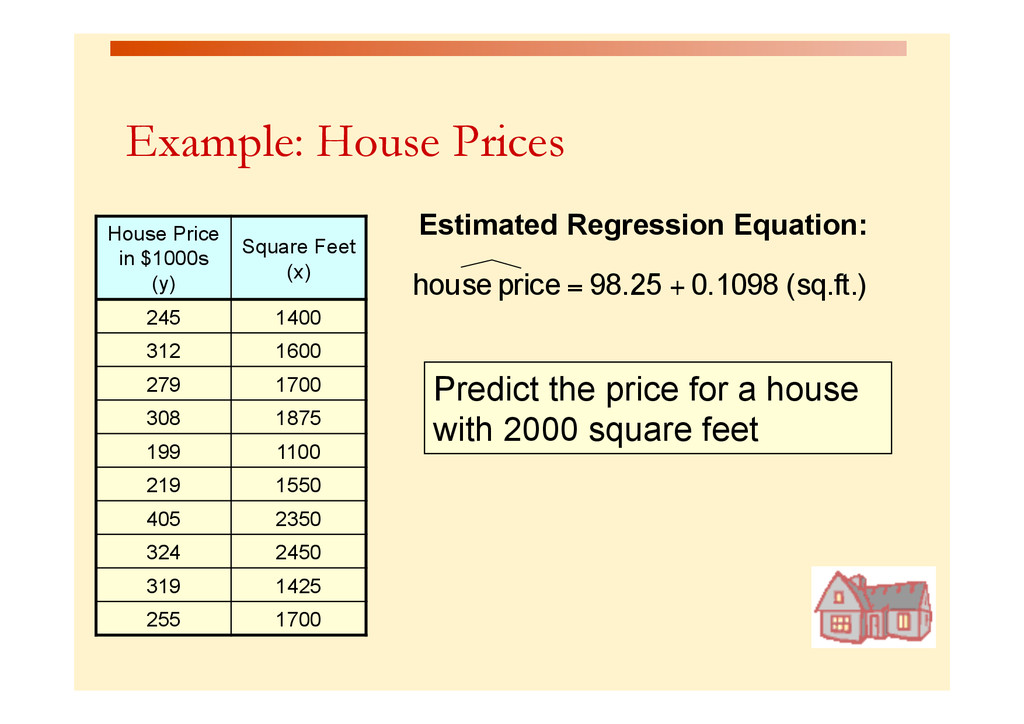
for an individual house with 2,000 square feet Predicted Price Yi = 317.85 ($1,000s) = $317, 850 MegaStat will give both the predicted value as well as the lower and upper limits Prediction Interval Estimate for y|xp The prediction interval endpoints are from $215,503 to $420,065. We can be 95% confident that the price of a 2000 ft2 home will fall within those limits. Predicted values for: Price($000) 95% Confidence Interval 95% Prediction Interval Square feet Predicted lower upper lower upper 2,000 317.784 280.664 354.903 215.503 420.065
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
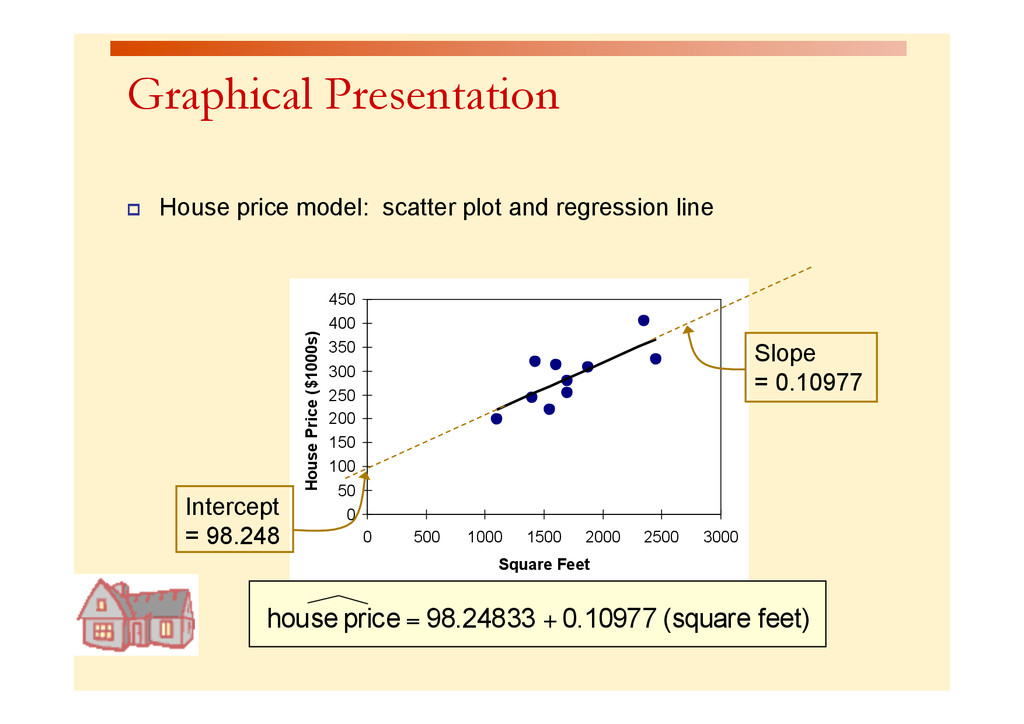{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
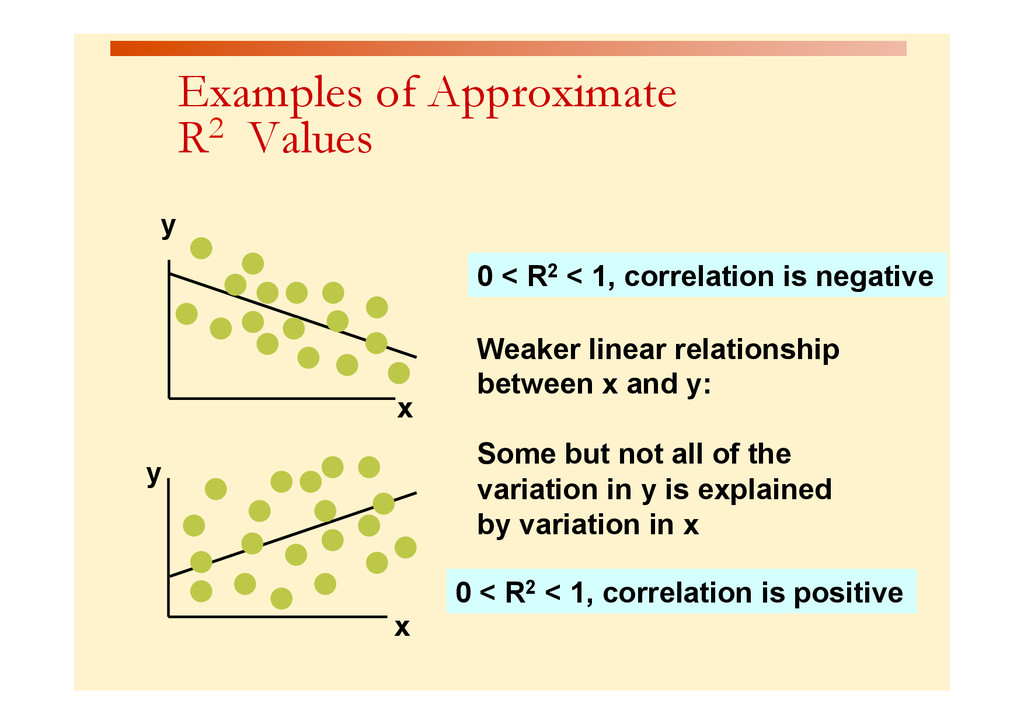{kind=link}
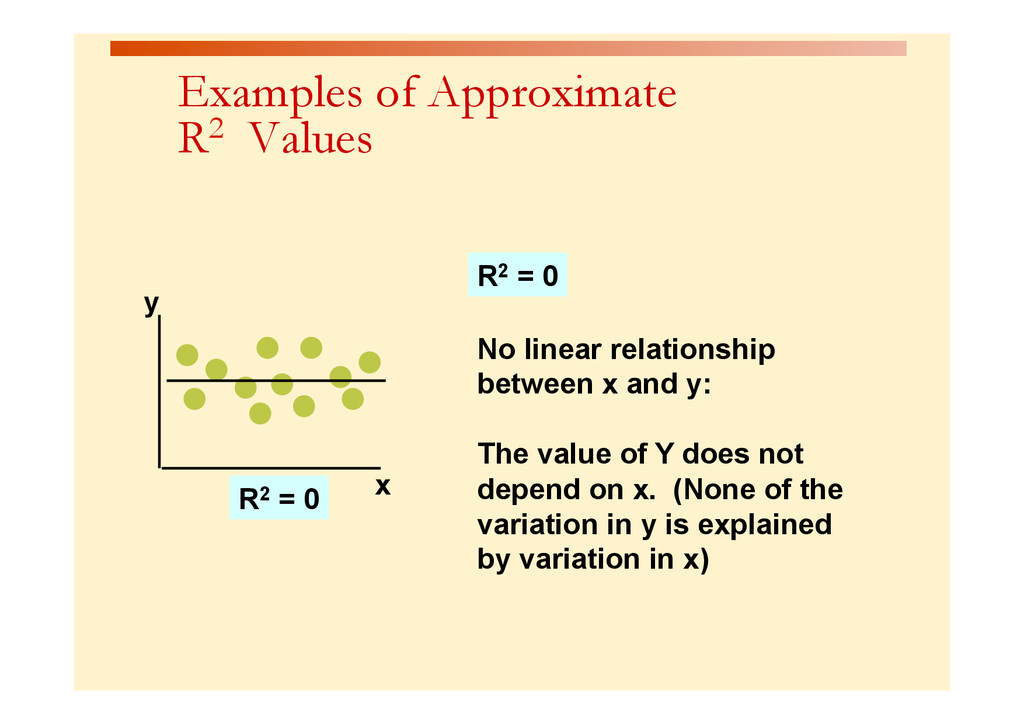{kind=link}
{kind=link}
{kind=link}
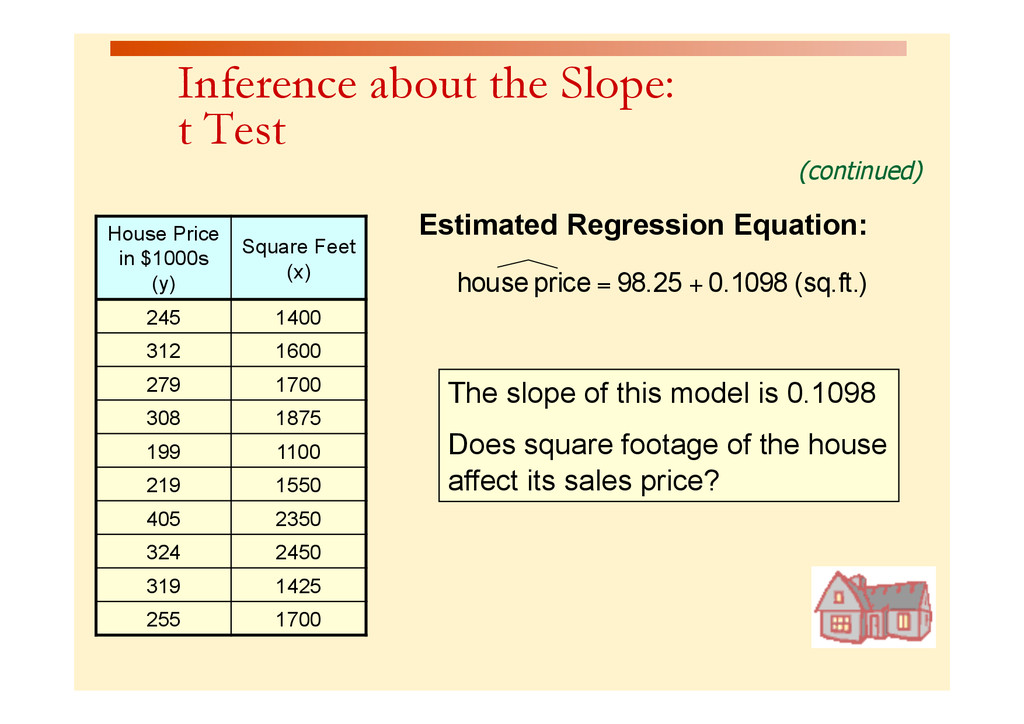{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}