Random) — случайное формирование пропусков • MAR (Missing At Random) — пропуски зависят от другой информации, например пола, возраста и т.д., которая есть в наборе данных • MNAR (Missing Not At Random) — пропуски зависят от другой информации, которой нет в наборе данных
Listwise Deletion Method) — удаление пропусков (полностью столбцов или строк) • + Очень простой • + MCAR — не даст «сильных» искажений в данных • – MAR и MNAR — сильные искажения в данных • Available-case analysis (или Pairwise Deletion) — учёт только не пропущенных значений • + Даёт больше данных чем Listwise Deletion Method • + MCAR — не даст «сильных» искажений в данных • – MAR и MNAR — сильные искажения в данных, в т.ч. допустим выход для ограниченных статистик, например коэффициентов корреляции x y z 1 2 ? 1 2 3 2 ? 1 x y z 1 2 ? 1 2 3 2 ? 1 Listwise vs Pairwise
заполнение средними значениями (ноль, медиана, среднее, мода и др.) • + Очень простой • – Сильное смещение по заполняемому значению • LOCF (Last observation carried forward) — заполнение по последнему значению • + Хороший вариант для временных рядов • – Не лучший для других данных (например, может дублировать выбросы etc) • Indicator Method — замена пропущенных значений нулями и добавление индикаторной колонки со значениями 0 и 1 • + Репрезентативность выборки не ухудшается • + Явное использование информации о пропусках • – Может привести к искажению результатов
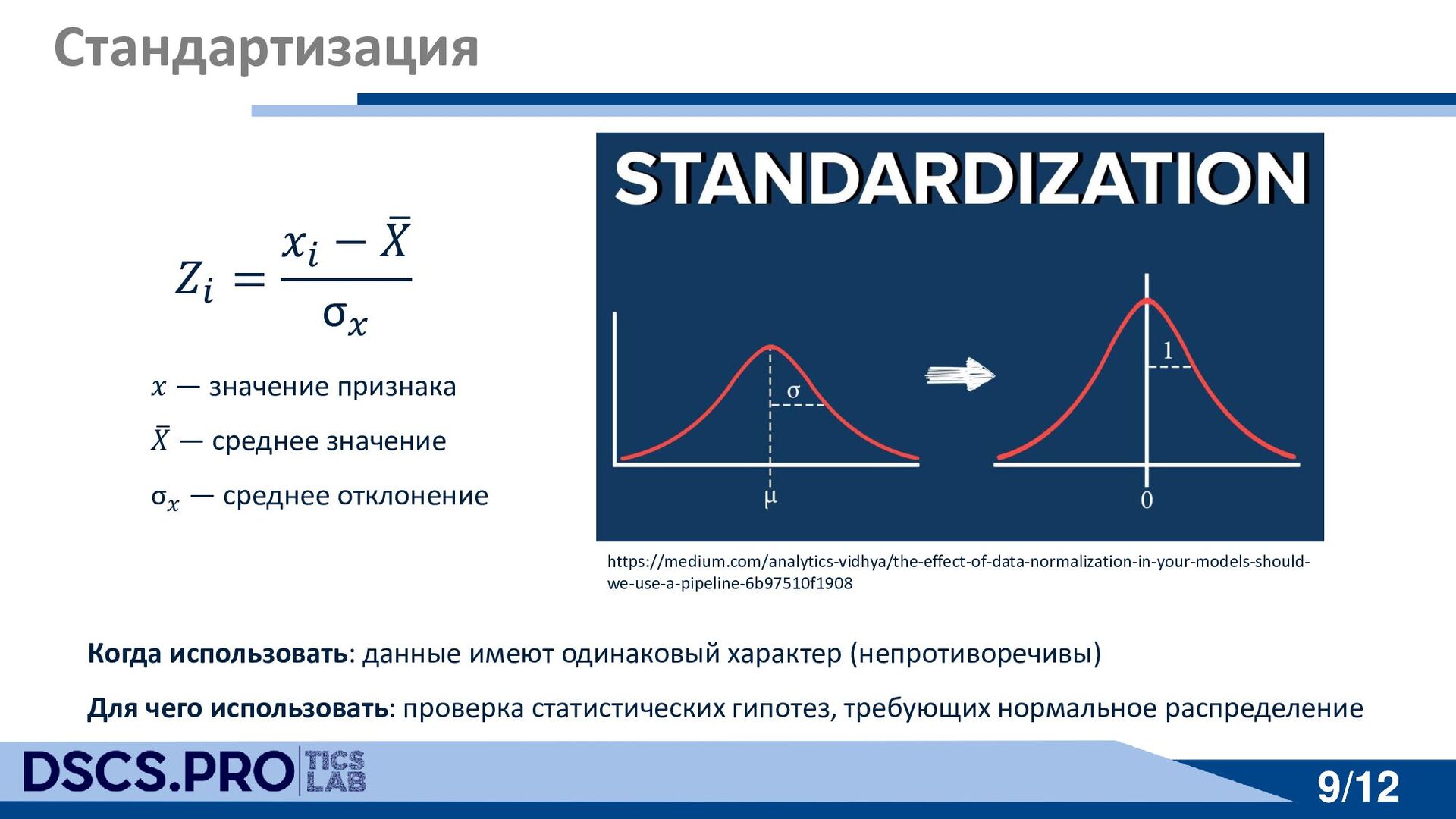
среднее значение σ𝑥 — среднее отклонение Когда использовать: данные имеют одинаковый характер (непротиворечивы) Для чего использовать: проверка статистических гипотез, требующих нормальное распределение https://medium.com/analytics-vidhya/the-effect-of-data-normalization-in-your-models-should- we-use-a-pipeline-6b97510f1908 𝑍𝑖 = 𝑥𝑖 − ത 𝑋 σ𝑥
нормализации и стандартизации данных в машинном обучении • https://social.hse.ru/soc/randan/news/413940344.html — о исследованиях в области работы с пропусками в данных • https://towardsdatascience.com/feature-engineering-for-machine- learning-3a5e293a5114 — о Feature Engineering
![14 апреля 2022 [email protected] Валерий Дмитриевич Олисеенко Ассистент кафедры информатики](https://files.speakerdeck.com/presentations/35a4e0c760eb4698a4d767039e85d917/slide_0.jpg){kind=link}
{kind=link}
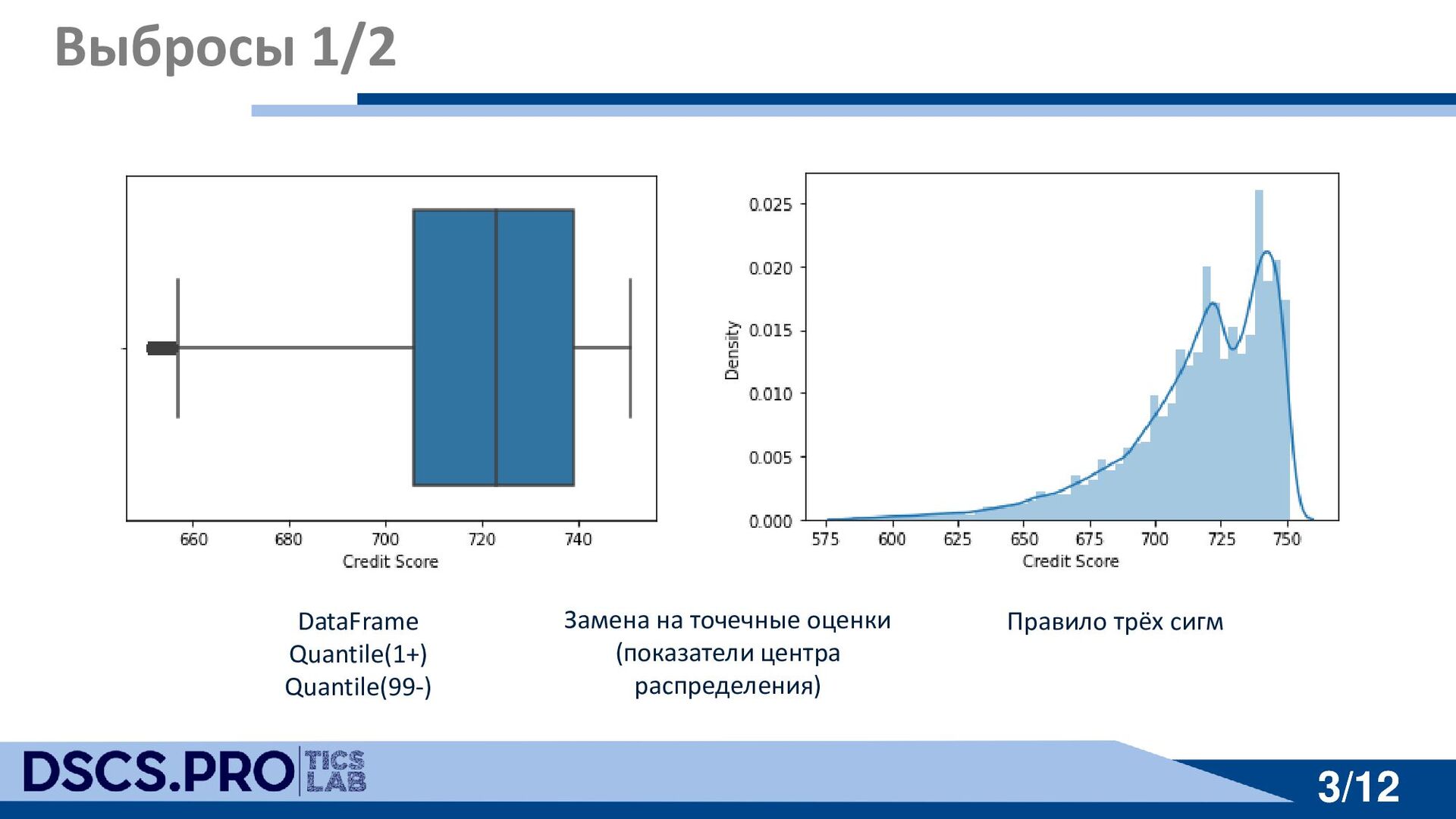{kind=link}
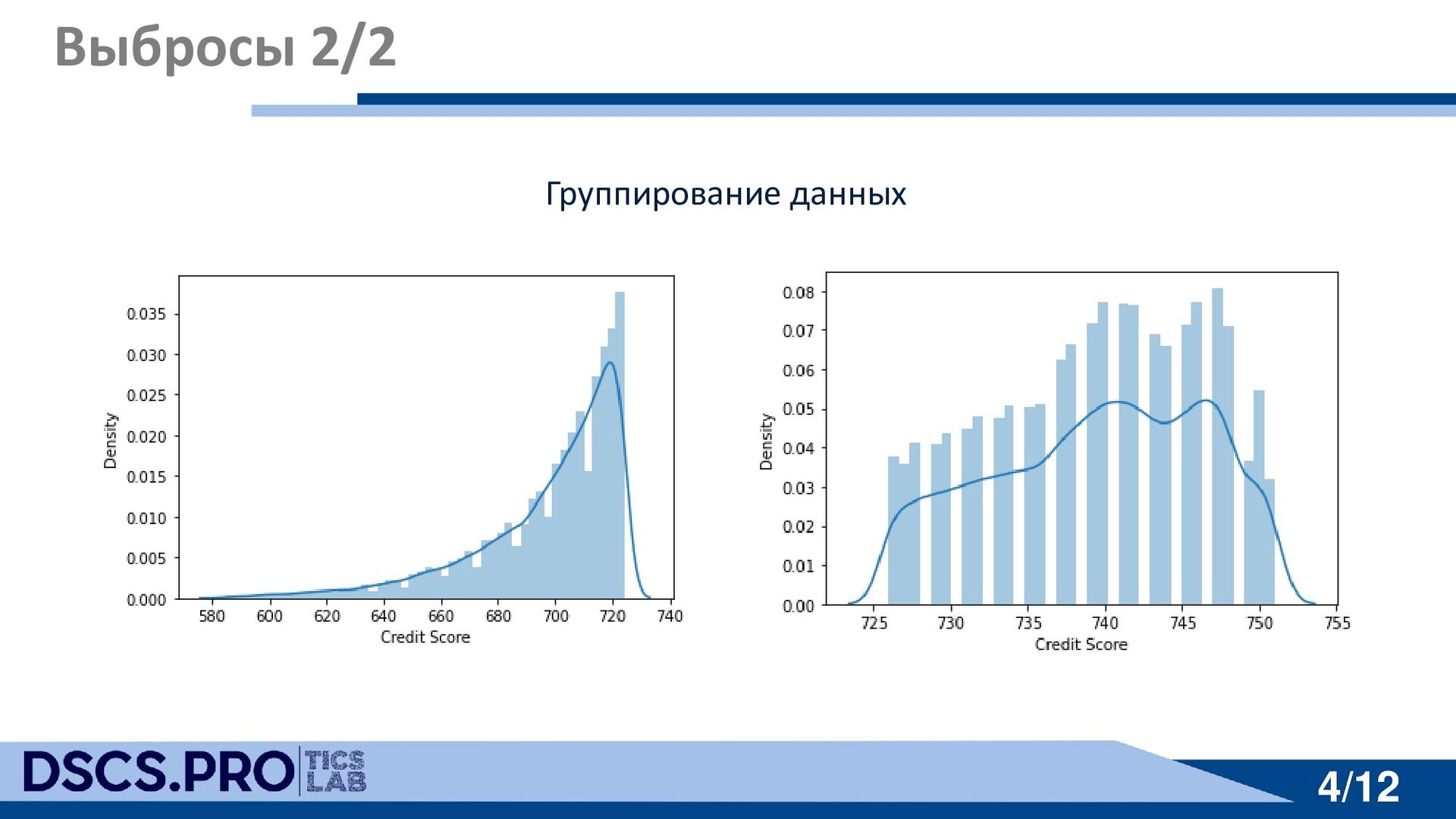{kind=link}
{kind=link}
{kind=link}
{kind=link}
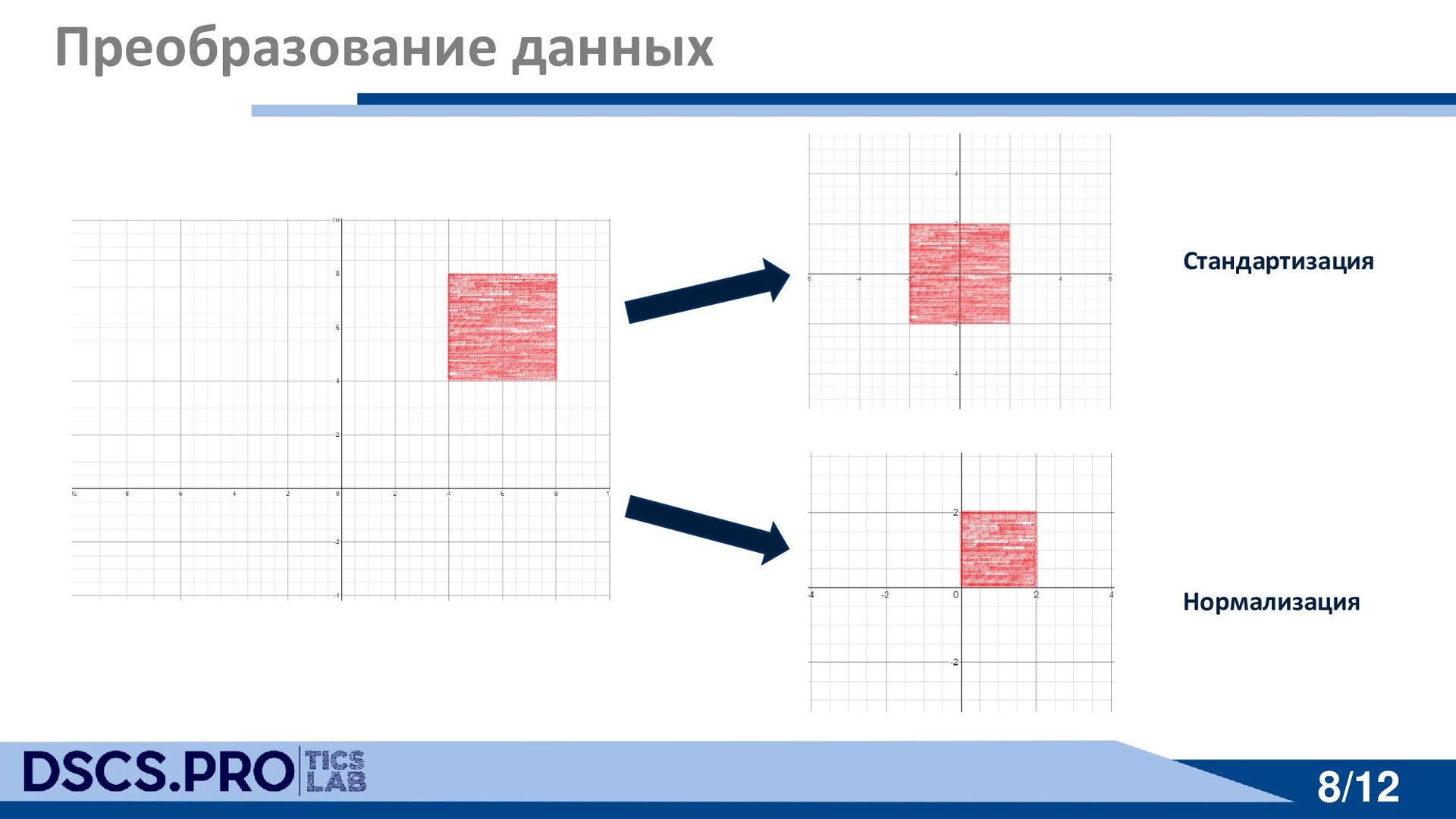{kind=link}
{kind=link}
{kind=link}
{kind=link}
![14 апреля 2022 [email protected] Валерий Дмитриевич Олисеенко Ассистент кафедры информатики](https://files.speakerdeck.com/presentations/35a4e0c760eb4698a4d767039e85d917/slide_11.jpg){kind=link}