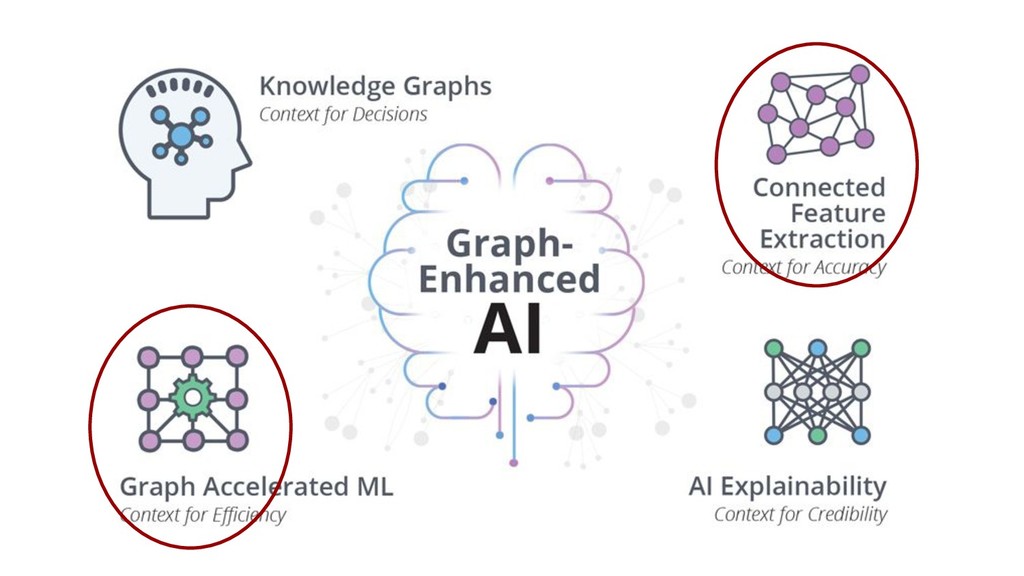
• ML process efficiencies • Connected feature extraction • Connected feature selection • Link prediction 2 Next 30 Mins Amy E. Hodler Graph Analytics & AI Program Manager, Neo4j [email protected] @amyhodler #Neo4j
learning that you can make better predictions about people by getting all the information from their friends and their friends’ friends than you can from the information you have about the person themselves” — Dr. James Fowler
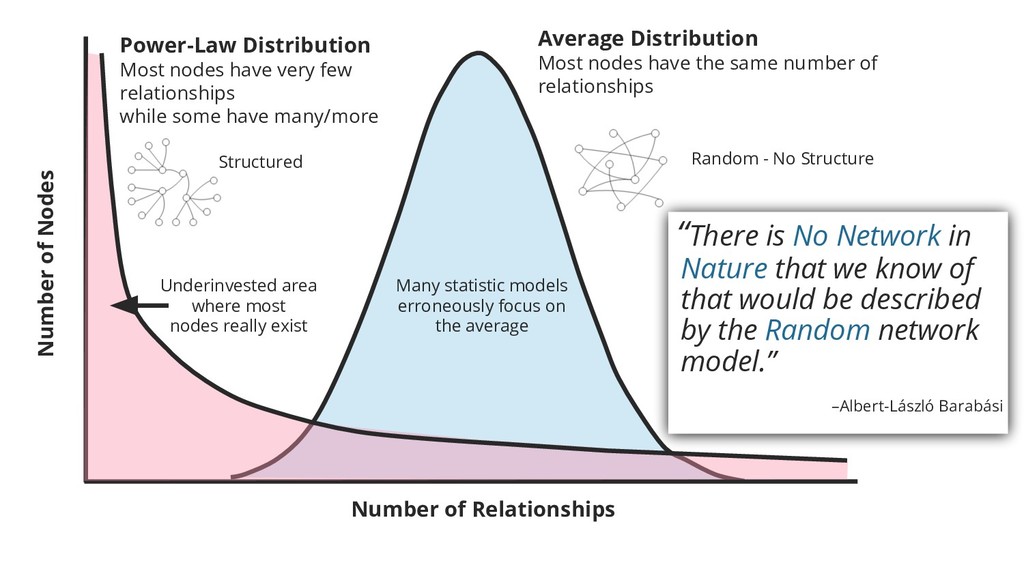
Number of Nodes Number of Relationships Structured Many statistic models erroneously focus on the average Underinvested area where most nodes really exist Power-Law Distribution Most nodes have very few relationships while some have many/more Random - No Structure “There is No Network in Nature that we know of that would be described by the Random network model.” –Albert-László Barabási
modules and large-scale structure in networks“ - Mark Newman Source: “Hierarchical structure and the prediction of missing links in networks”; ”Structure and inference in annotated networks” - A. Clauset, C. Moore, and M.E.J. Newman.
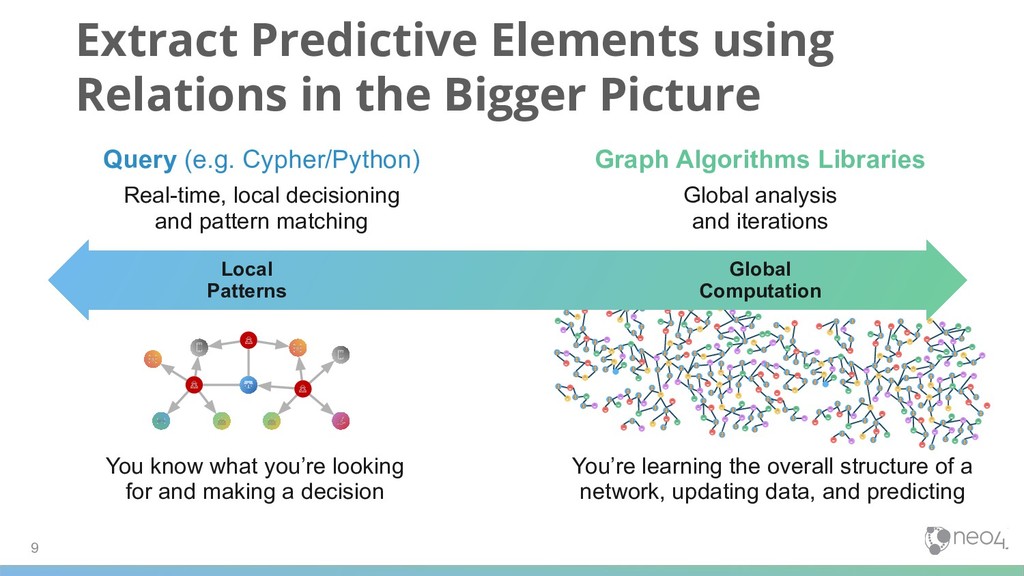
Query (e.g. Cypher/Python) Real-time, local decisioning and pattern matching Graph Algorithms Libraries Global analysis and iterations You know what you’re looking for and making a decision You’re learning the overall structure of a network, updating data, and predicting Local Patterns Global Computation
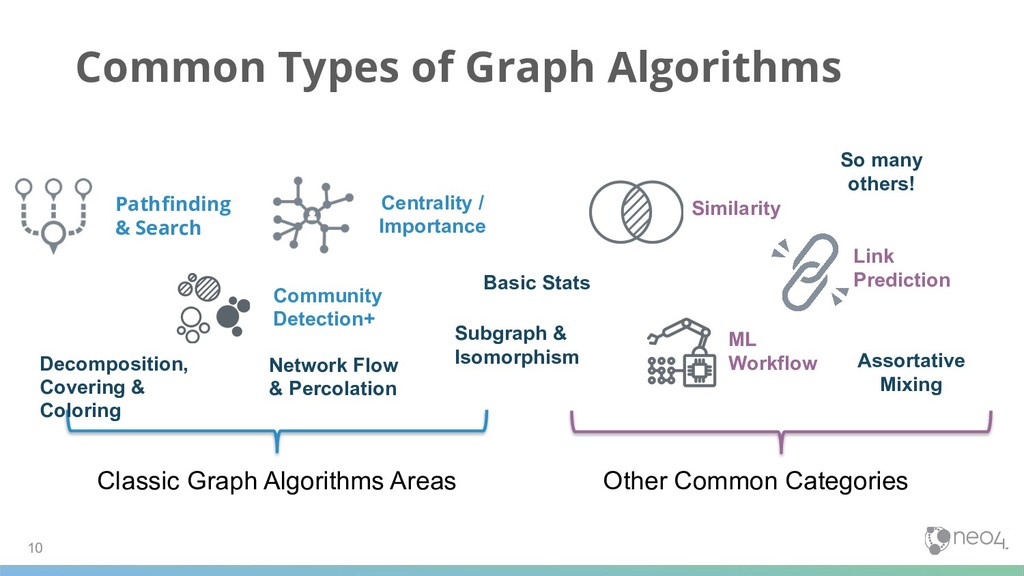
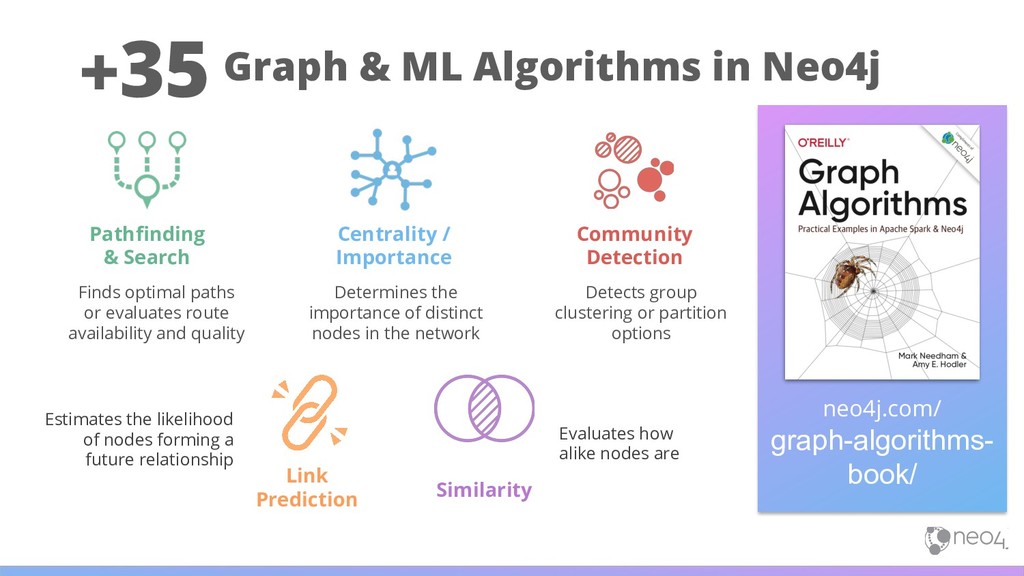
Other Common Categories Pathfinding & Search Centrality / Importance Community Detection+ Similarity Link Prediction ML Workflow Network Flow & Percolation Decomposition, Covering & Coloring Subgraph & Isomorphism Basic Stats Assortative Mixing So many others!
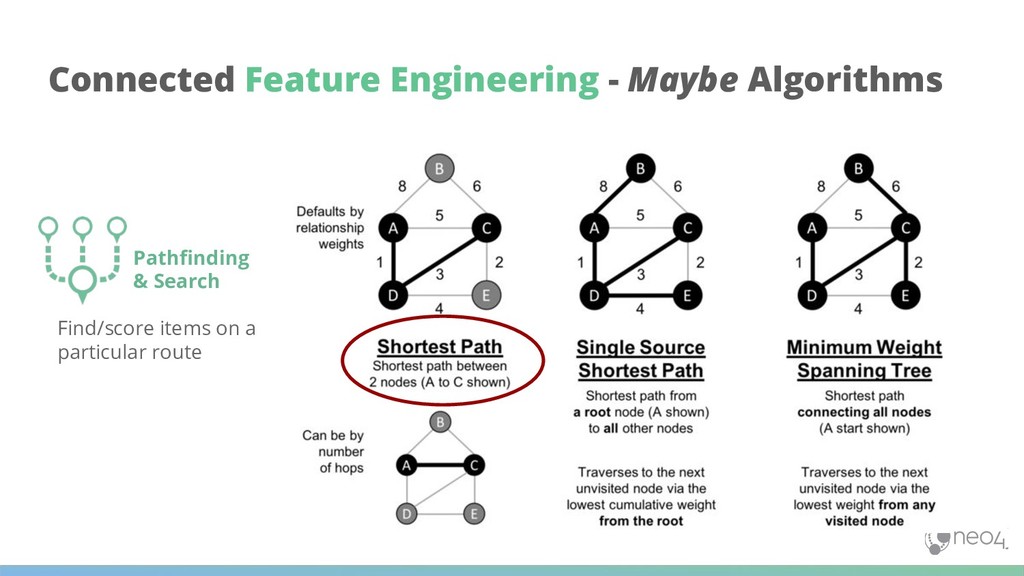
Pathfinding & Search Centrality / Importance Community Detection Link Prediction Finds optimal paths or evaluates route availability and quality Determines the importance of distinct nodes in the network Detects group clustering or partition options Evaluates how alike nodes are Estimates the likelihood of nodes forming a future relationship Similarity
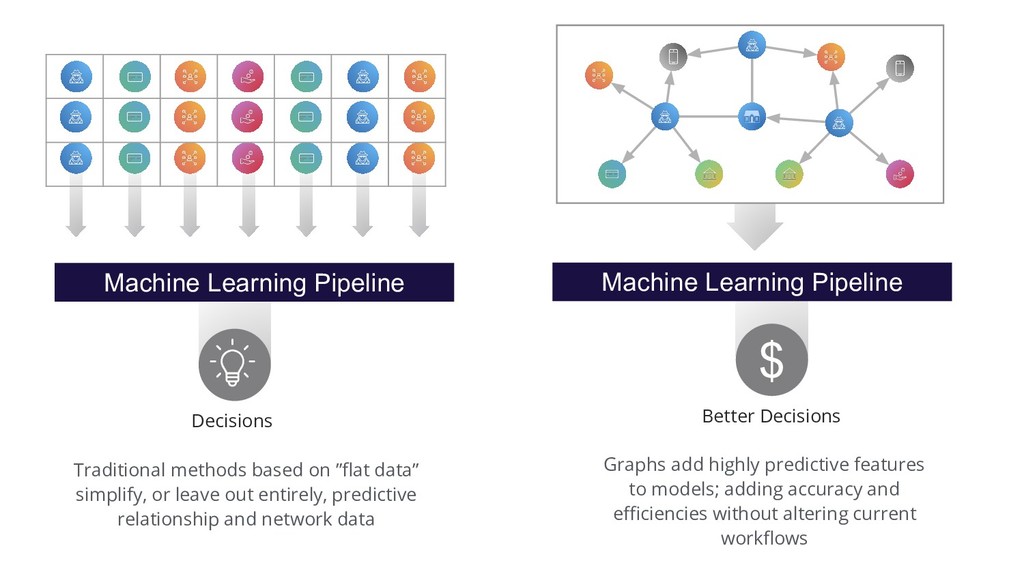
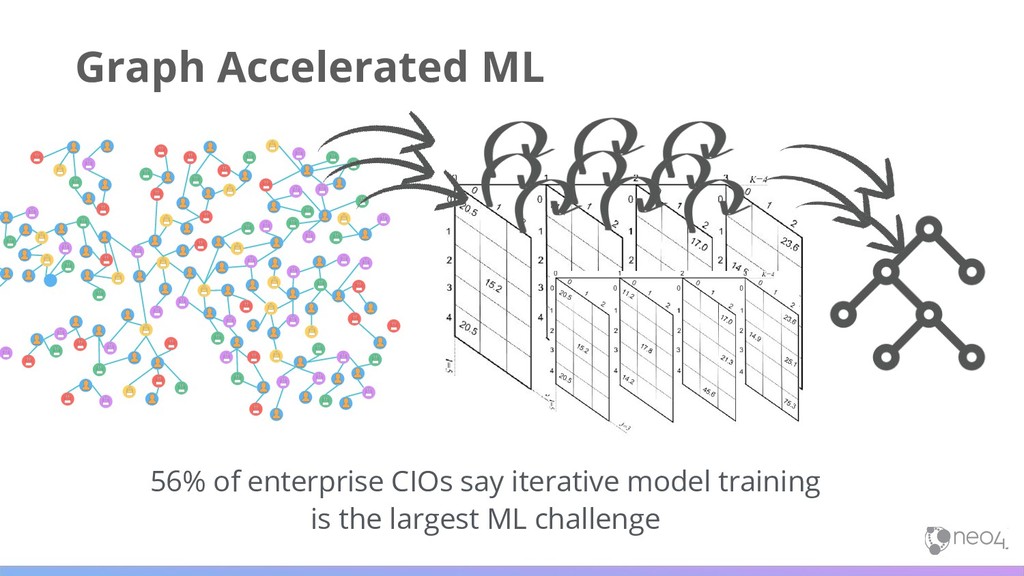
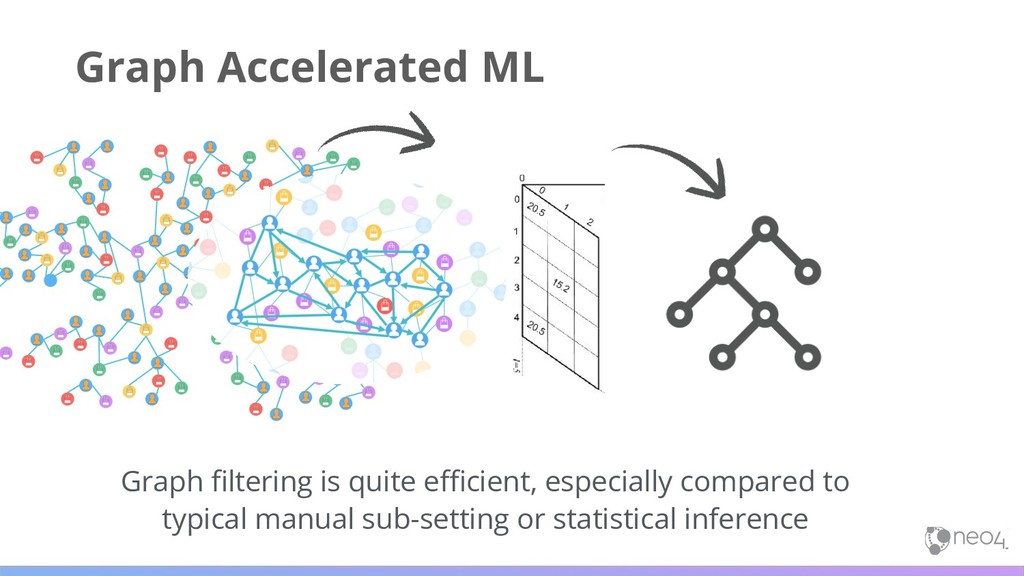
models; adding accuracy and efficiencies without altering current workflows Machine Learning Pipeline Machine Learning Pipeline Traditional methods based on ”flat data” simplify, or leave out entirely, predictive relationship and network data
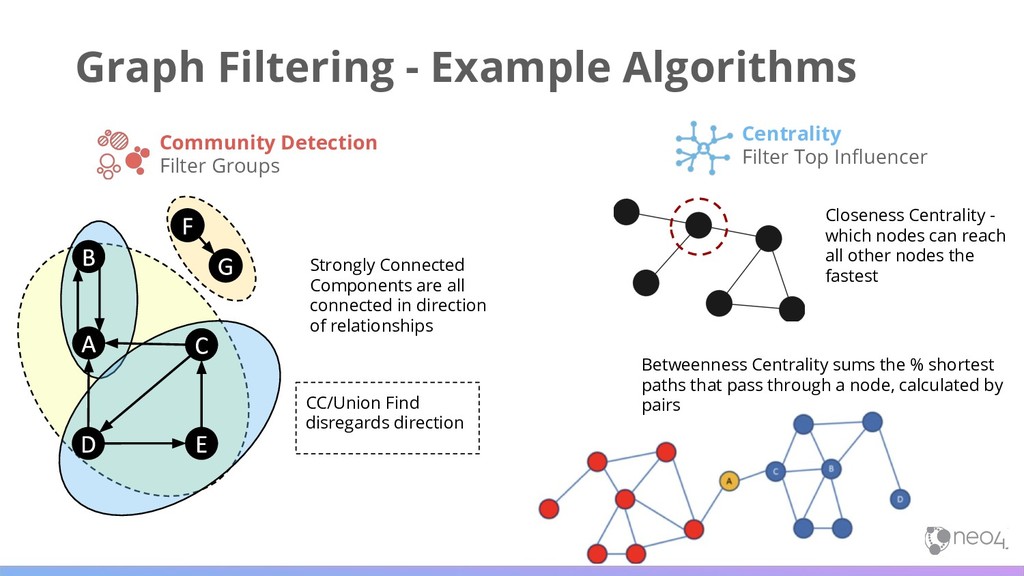
a node, calculated by pairs Graph Filtering - Example Algorithms Community Detection Filter Groups Centrality Filter Top Influencer Strongly Connected Components are all connected in direction of relationships CC/Union Find disregards direction Closeness Centrality - which nodes can reach all other nodes the fastest
• Credit Fraud • Compliance and investigation 21 Improve the Predictive Power of ML Example in Fighting Financial Crimes Machine Learning Pipeline Data Machine Learning can help uncover & learn common traits so we can build more predictive models Unfortunately many machine learning methods rely on flat data structures and tables
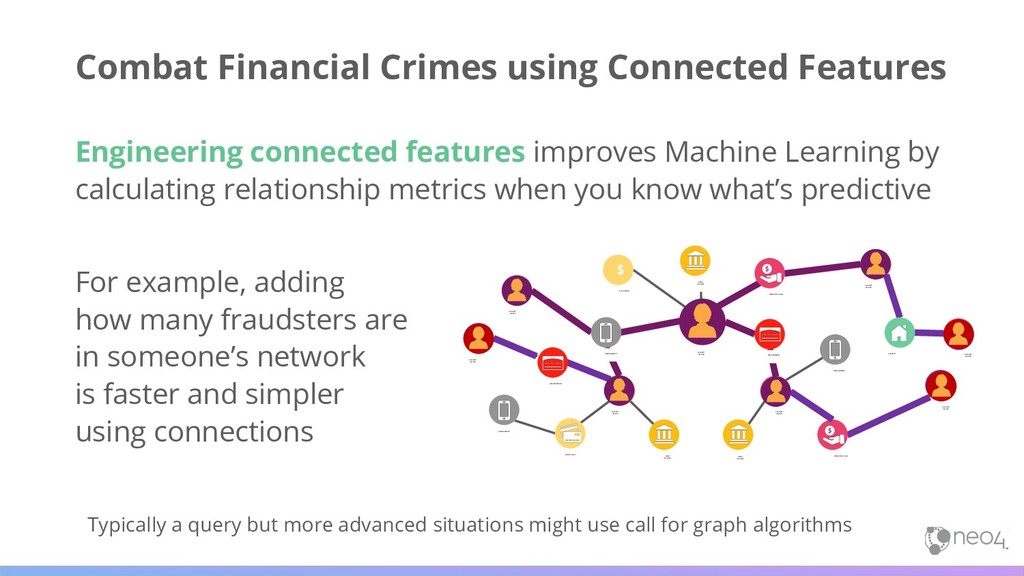
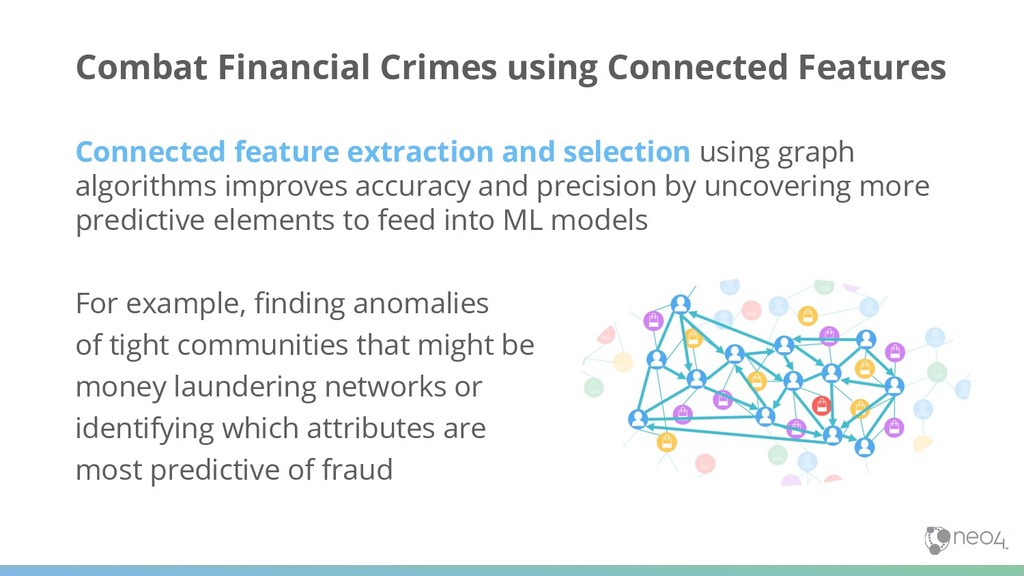
when you know what’s predictive For example, adding how many fraudsters are in someone’s network is faster and simpler using connections Combat Financial Crimes using Connected Features ACCOUNT HOLDER ACCOUNT HOLDER ACCOUNT HOLDER ACCOUNT HOLDER ACCOUNT HOLDER BANK ACCOUNT SSN/ ID NUMBER UNSECURED LOAN BANK ACCOUNT BANK ACCOUNT UNSECURED LOAN PHONE NUMBER CREDIT CARD SSN/ ID NUMBER PHONE NUMBER ACCOUNT HOLDER ACCOUNT HOLDER ACCOUNT HOLDER ADDRESS PHONE NUMBER $ APPLICATION Typically a query but more advanced situations might use call for graph algorithms
and precision by uncovering more predictive elements to feed into ML models For example, finding anomalies of tight communities that might be money laundering networks or identifying which attributes are most predictive of fraud Combat Financial Crimes using Connected Features
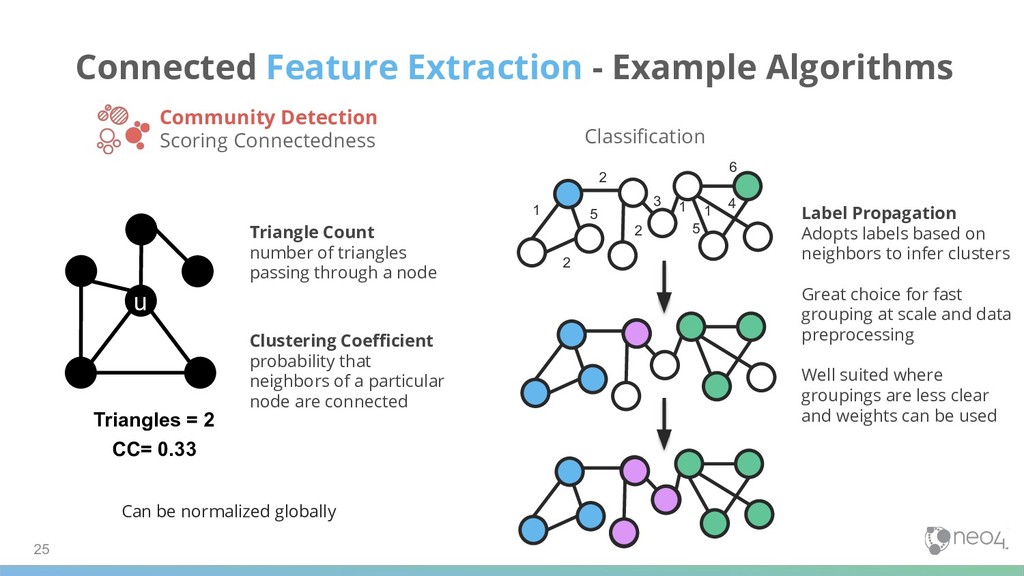
Connectedness u Triangles = 2 CC= 0.33 Triangle Count number of triangles passing through a node Clustering Coefficient probability that neighbors of a particular node are connected Can be normalized globally 1 2 2 5 3 2 1 6 1 5 4 Classification Label Propagation Adopts labels based on neighbors to infer clusters Great choice for fast grouping at scale and data preprocessing Well suited where groupings are less clear and weights can be used
2 0.5 2.5 ADDRESSES PHONE S: 3 LOANS SSN/ IDs PHONES e.g. Graph centrality algorithms can identify influential features in our models so we can eliminate less important features and reduce overfitting Centrality Cut-out less predictive features PageRank - Measures the transitive (directional) influence of nodes and considers the influence of neighbors and their neighbors Personalized PR works well for contextual ranking
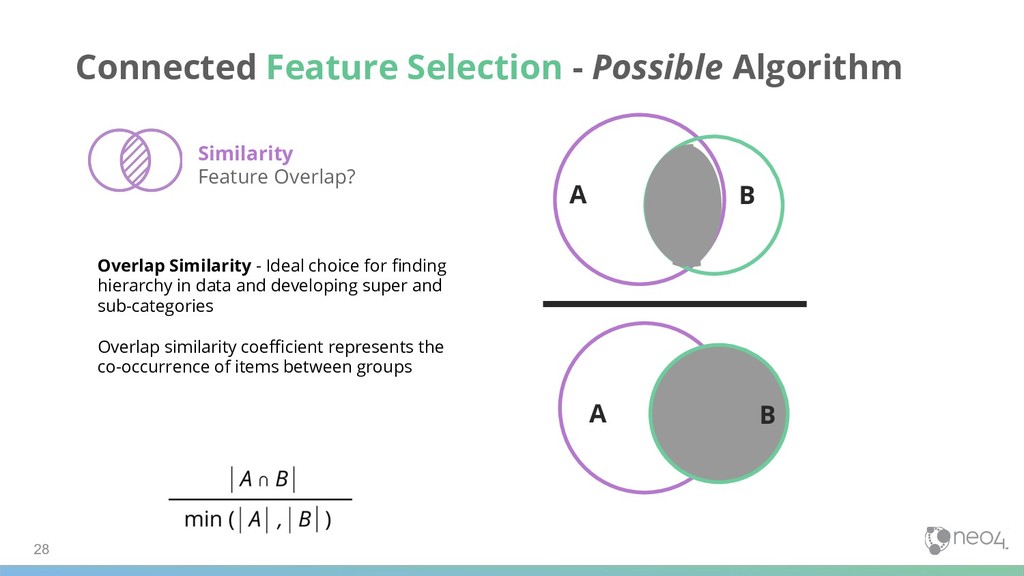
Ideal choice for finding hierarchy in data and developing super and sub-categories Overlap similarity coefficient represents the co-occurrence of items between groups Similarity Feature Overlap? A B A B
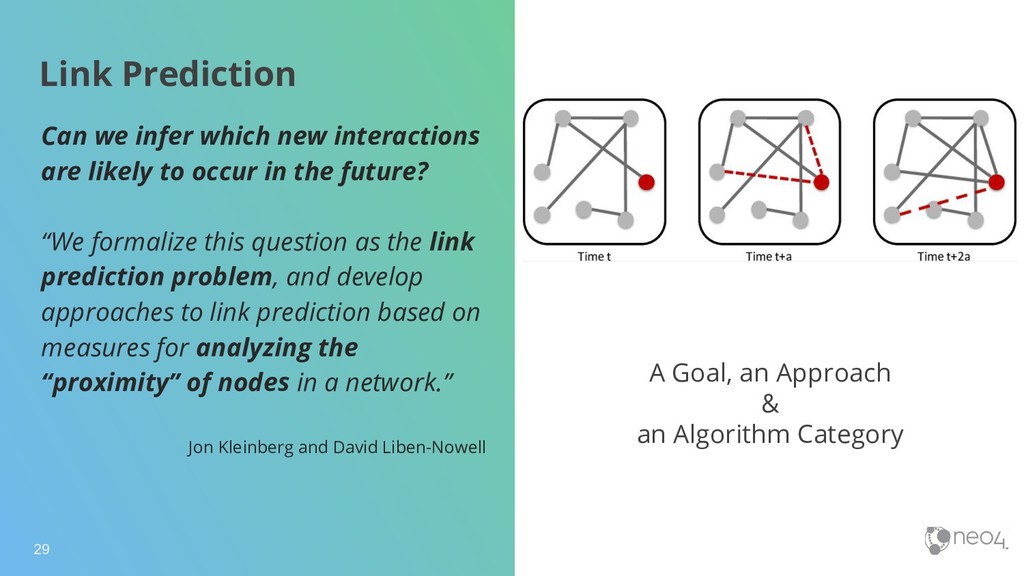
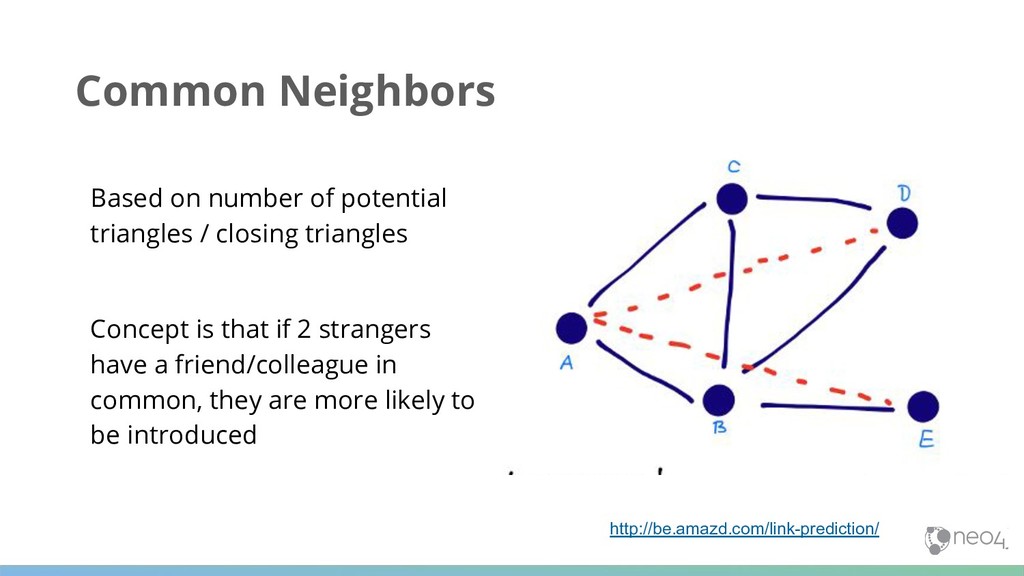
likely to occur in the future? “We formalize this question as the link prediction problem, and develop approaches to link prediction based on measures for analyzing the “proximity” of nodes in a network.” Jon Kleinberg and David Liben-Nowell A Goal, an Approach & an Algorithm Category
behaviour or an unobserved fact. For example, in a citation network, we’re actually predicting the action of two people collaborating on a paper. What's common across all these use cases?
be considered a measure of proximity or “similarity” between those nodes based on the graph topology Graph Algorithms used with Link Prediction Link Prediction Other Algorithms Community Detection It’s common when our goal is link prediction to use a variety of algorithm types to extract features and use them together in a machine learning model Similarity
common features by weighting rarer features more heavily. Formalizes the intuitive notion that rare features are more telling; if we both like GoT that’s less predictive than a preference for 16th century poetry http://be.amazd.com/link-prediction/
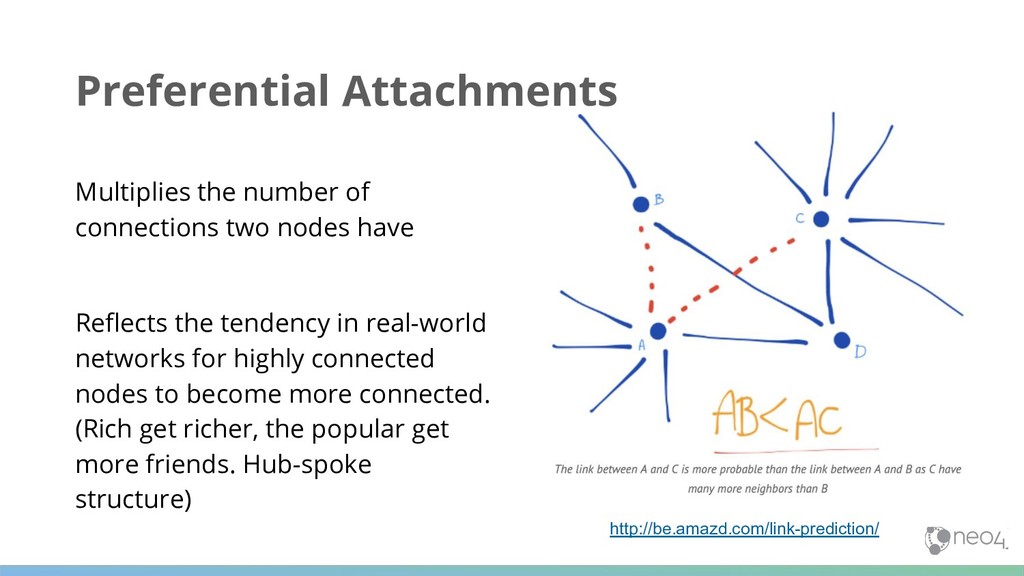
Reflects the tendency in real-world networks for highly connected nodes to become more connected. (Rich get richer, the popular get more friends. Hub-spoke structure) http://be.amazd.com/link-prediction/
used to predict a link between nodes • Use the measures as features to train a ML model ◦ e.g. A binary classifier that predicts which nodes will be linked What to do with algorithm scores? node1 node2 commonNeighbors preferentialAttachment label 1 2 4 15 1 3 4 7 12 1 5 6 1 1 0
Careful of data Leakage in graphy data, especially when we randomly split the dataset. This can easily happen when working with graphs because pairs of nodes in our training set may be connected to those in the test set. Train and Test Datasets
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}