This 2014 Bay Area Search Meetup presentations discusses LinkedIn's challenges in delivering high quality search results to 277M+ members. Results are highly personalized, requiring machine-learned relevance models that combine document, query, and user features. And emphasis on entities (names, companies, job titles, etc.) affects query processing and understanding. This presentation discusses these challenges in detail and describes some of the solutions to address them.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
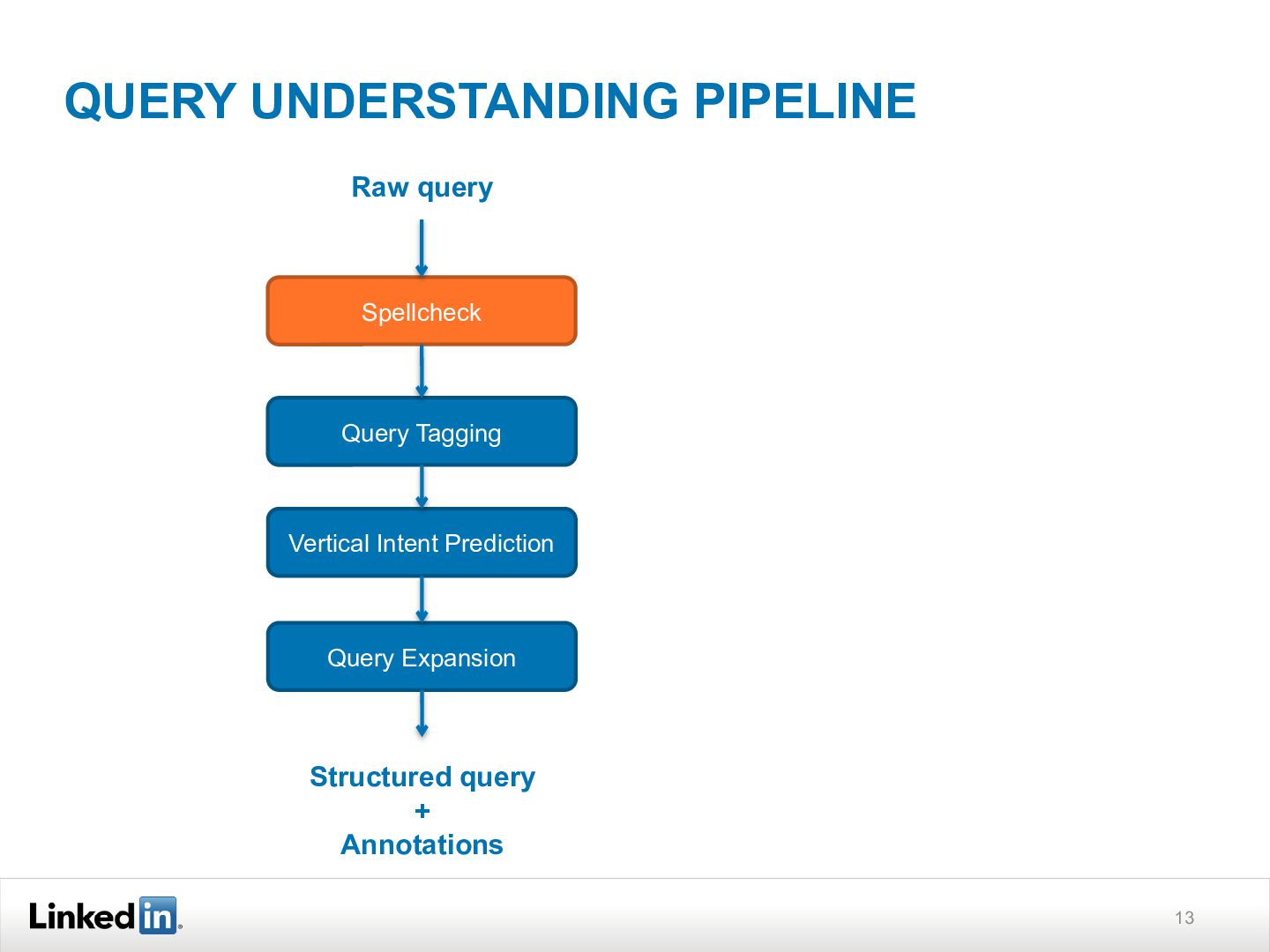{kind=link}
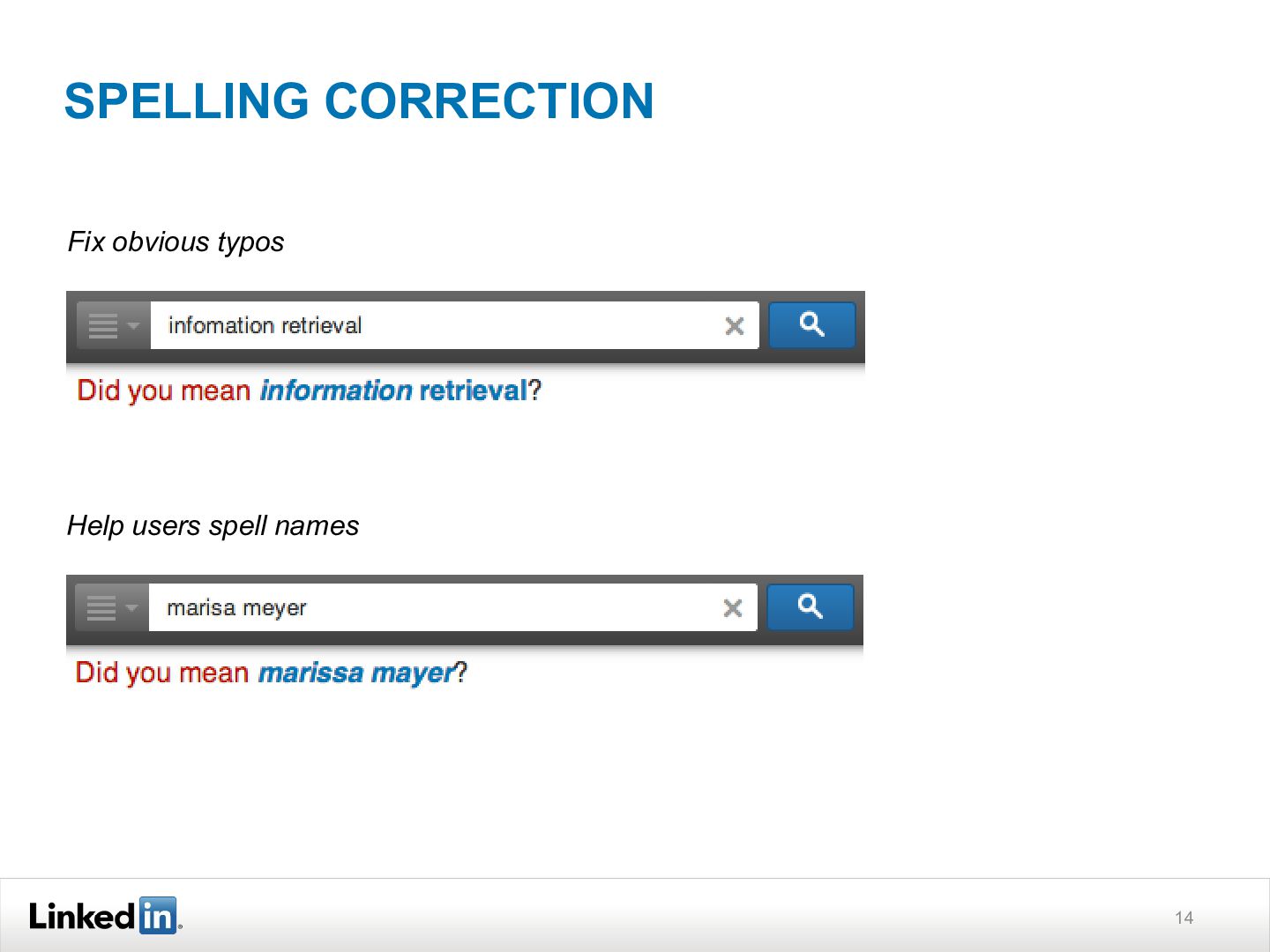{kind=link}
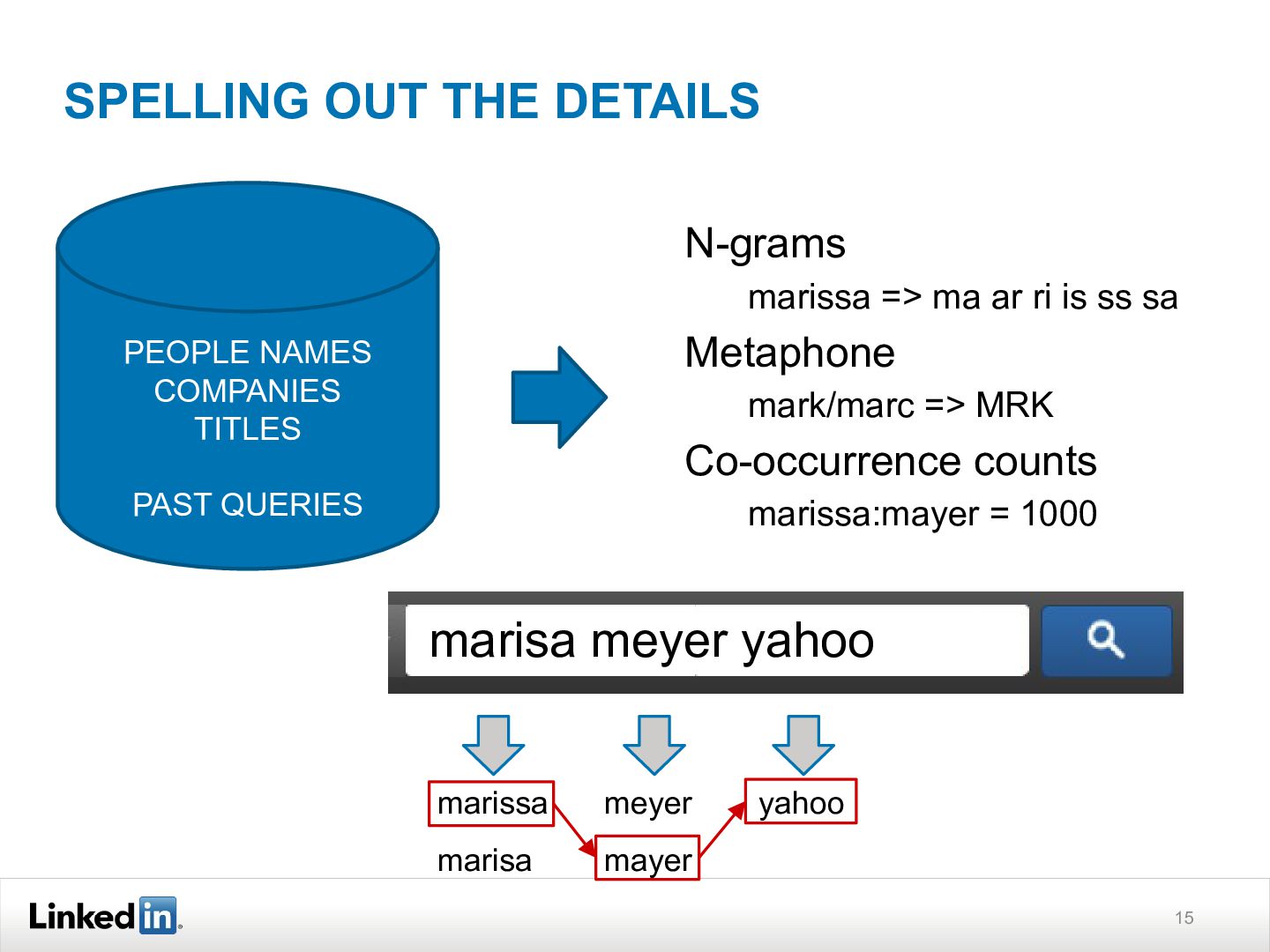{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
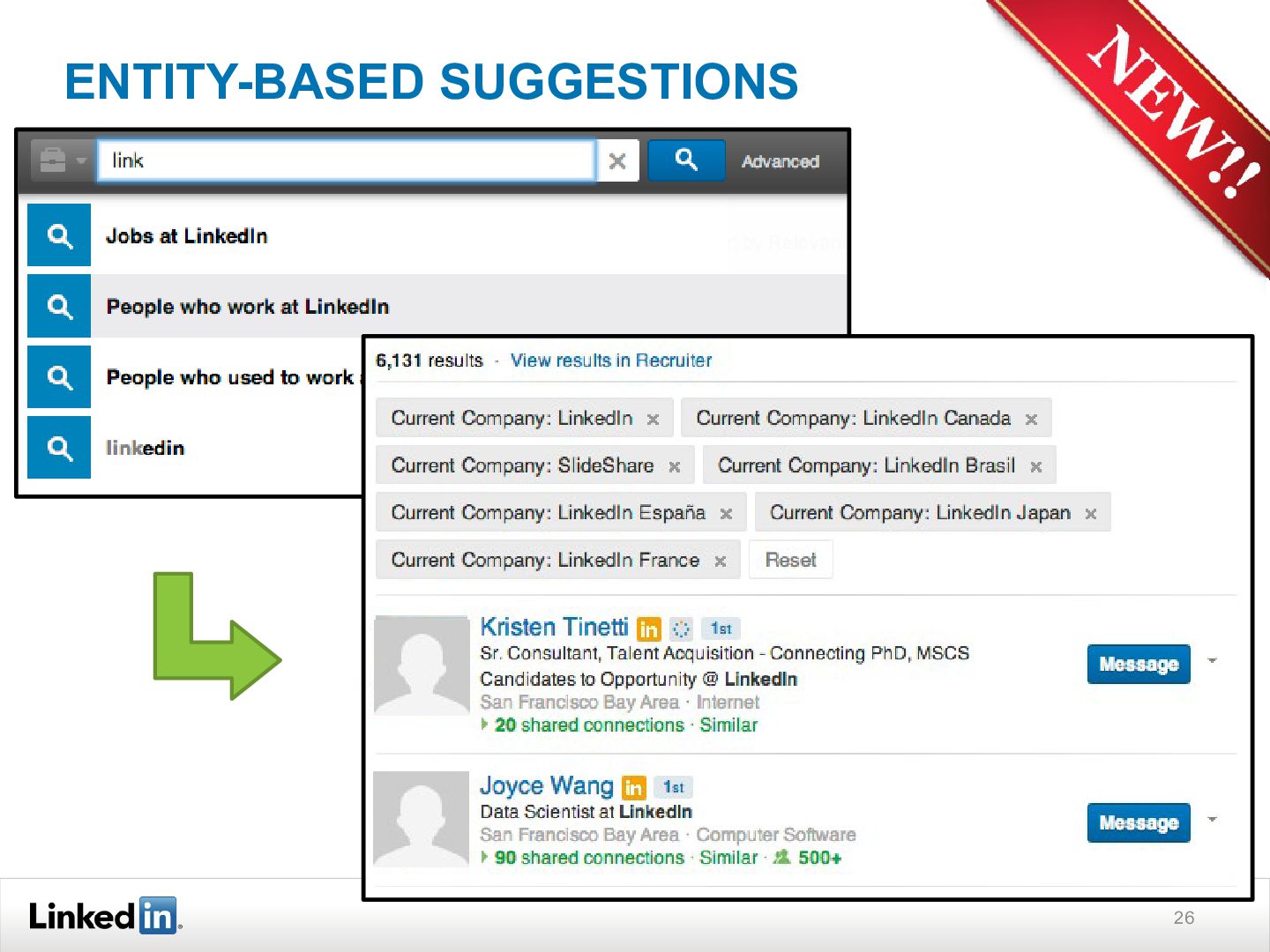{kind=link}
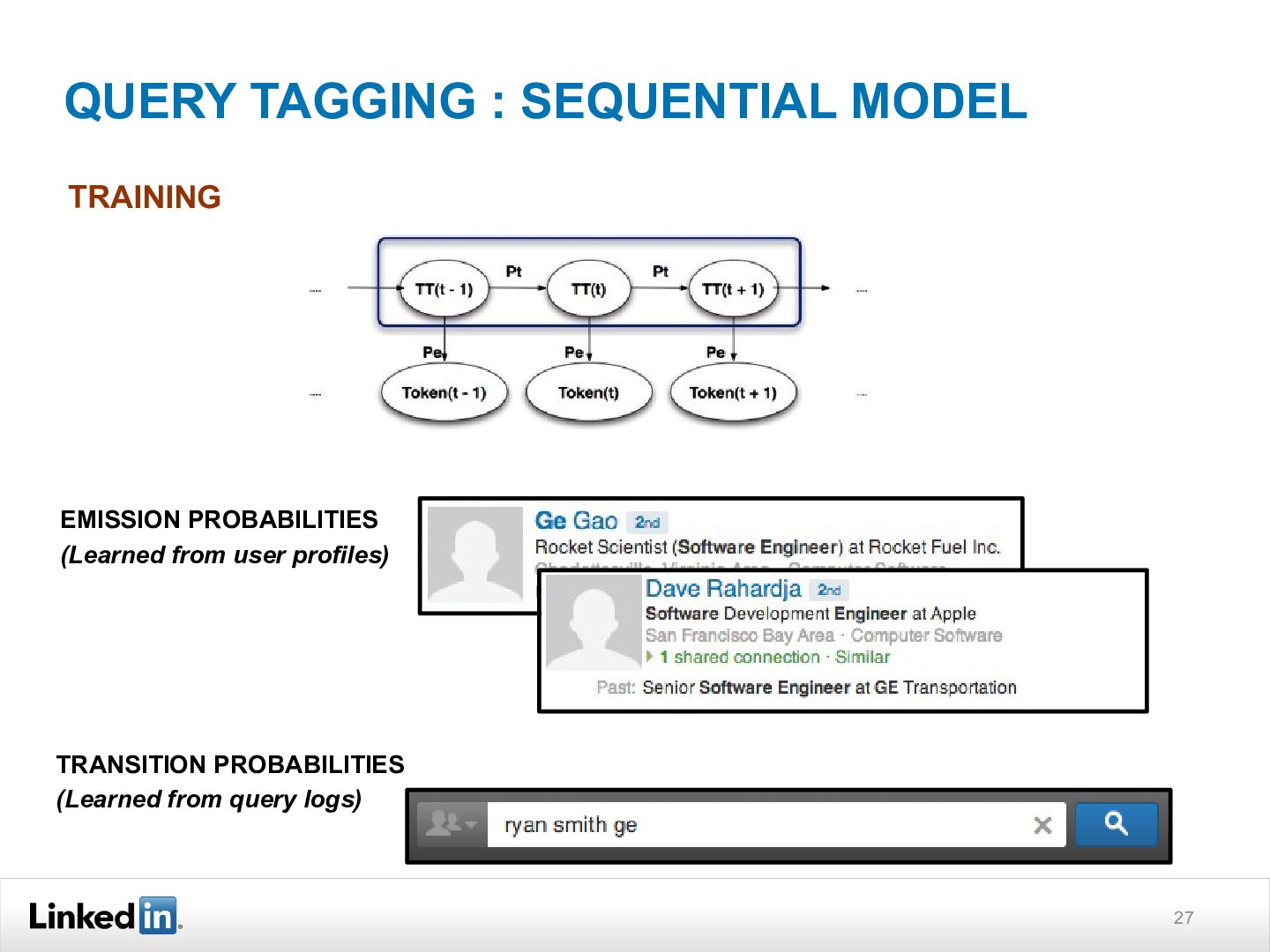{kind=link}
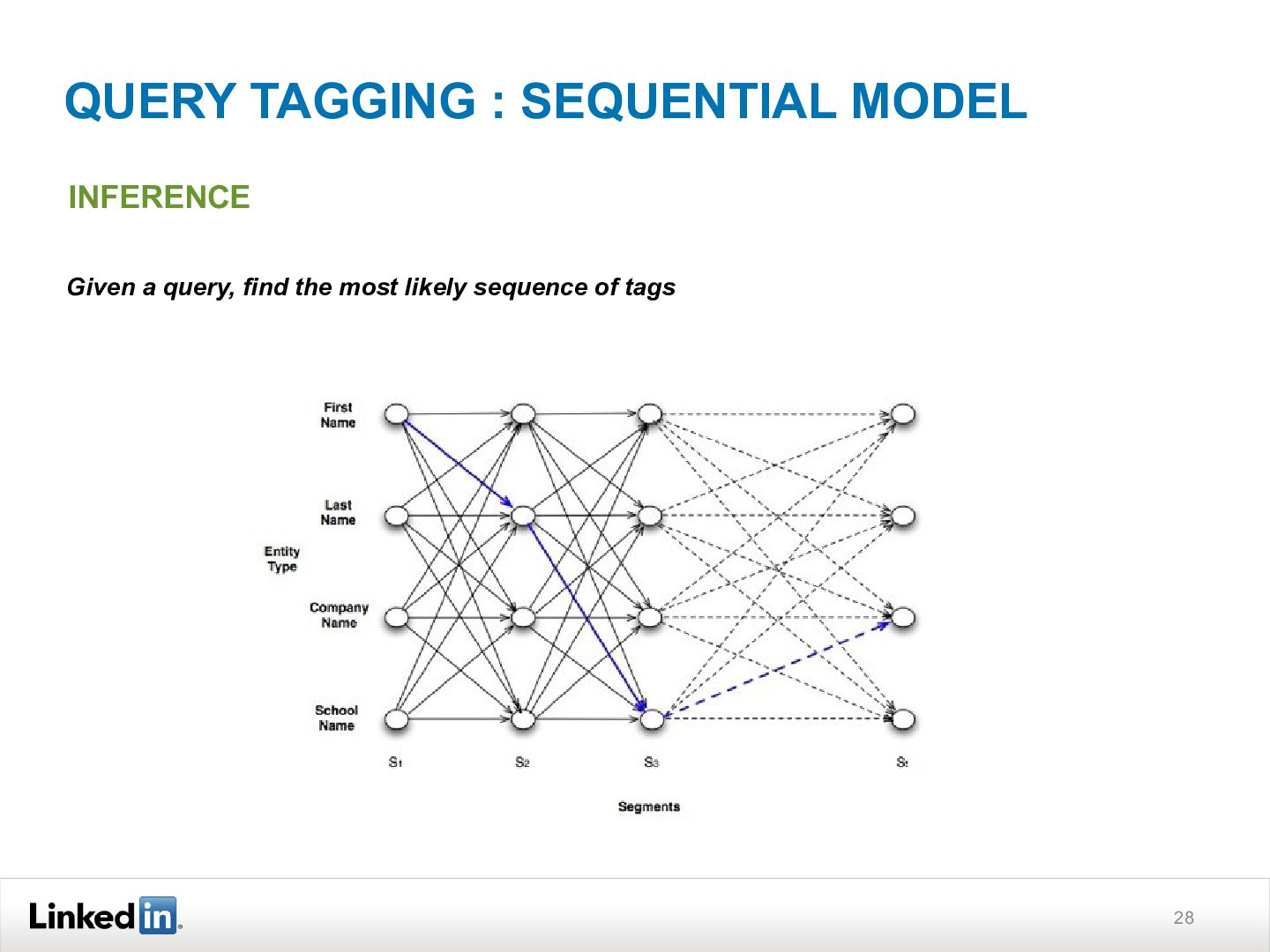{kind=link}
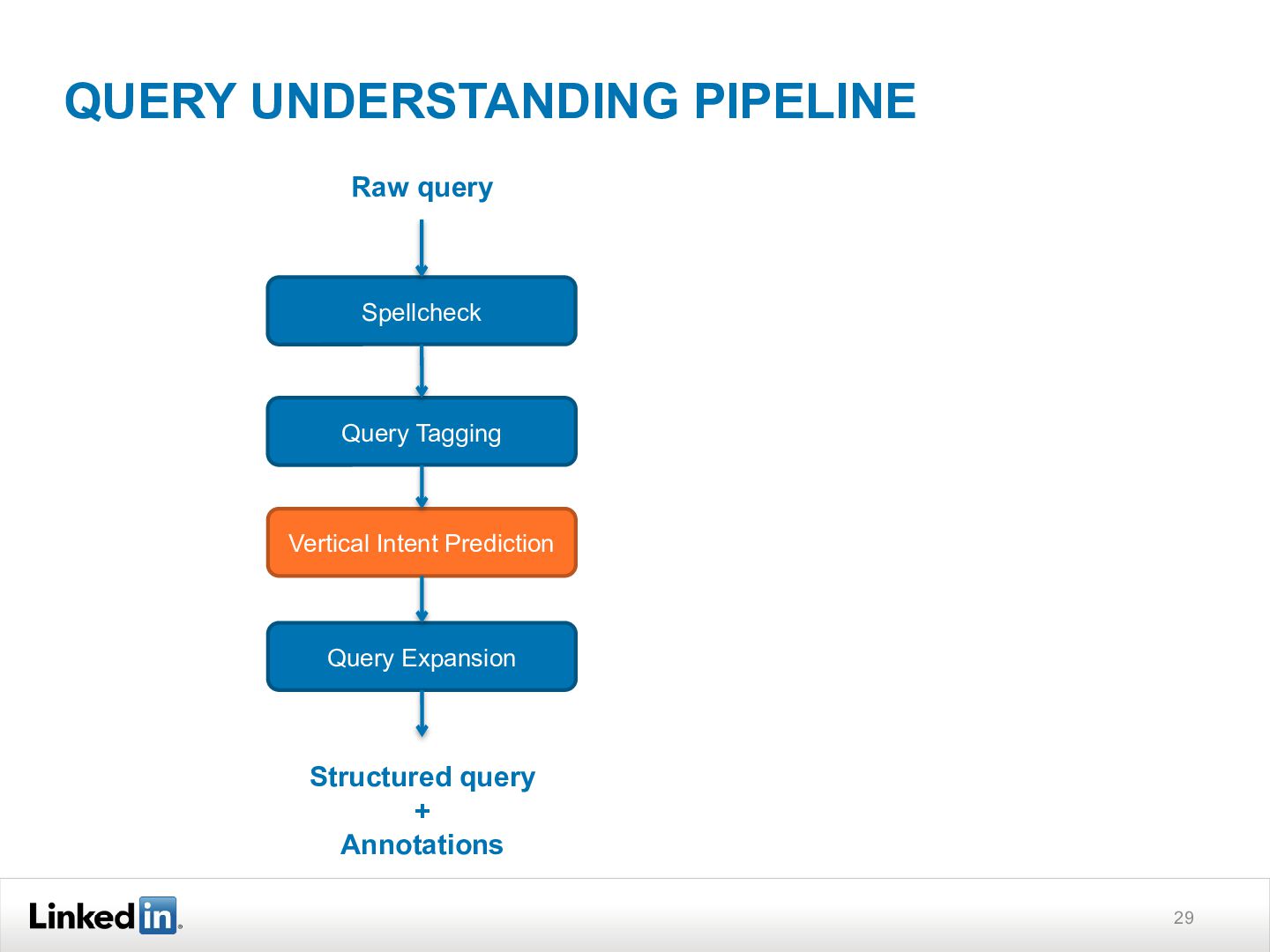{kind=link}
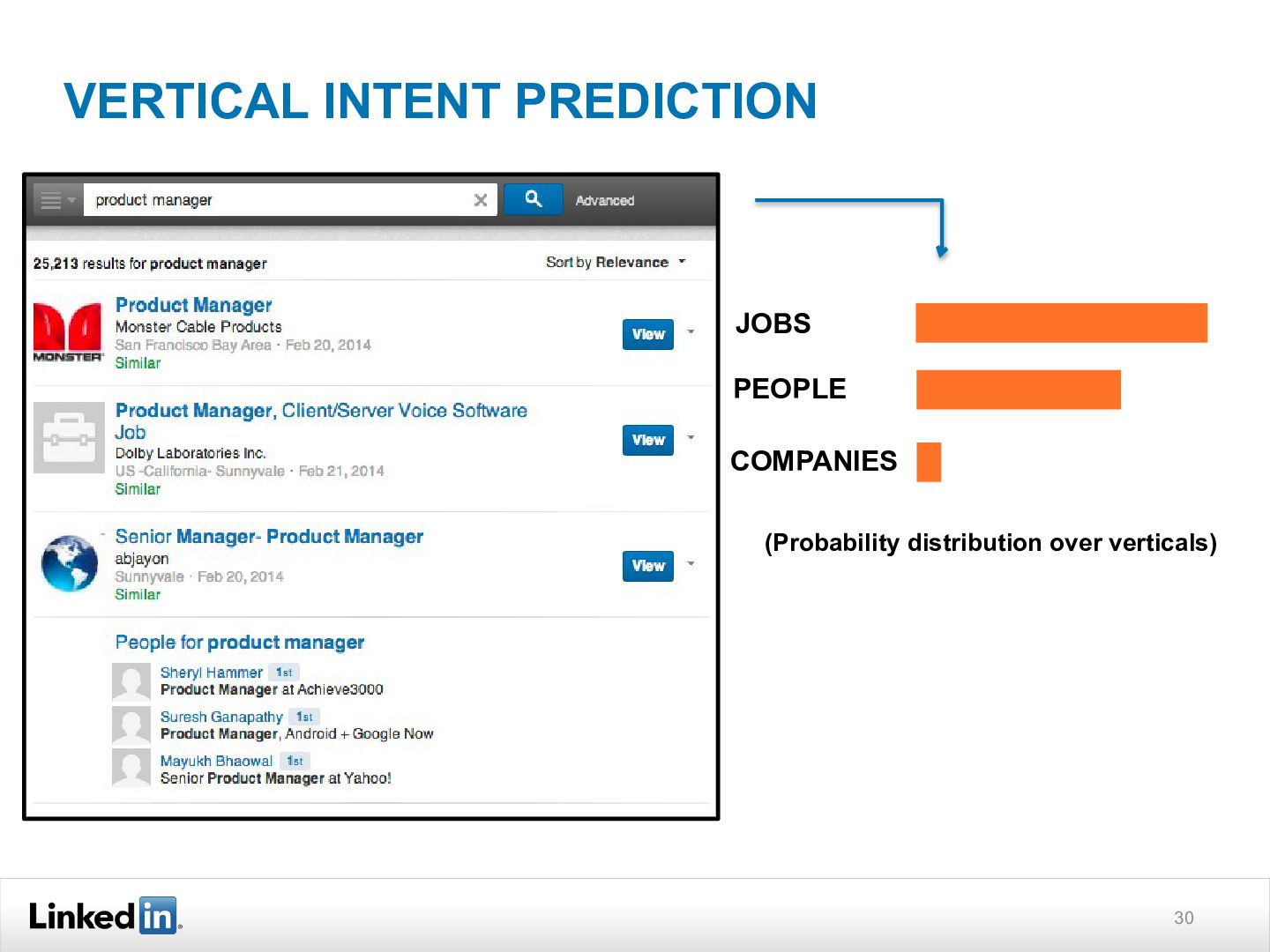{kind=link}
![31 VERTICAL INTENT PREDICTION : SIGNALS [Company] 1. Past query](https://files.speakerdeck.com/presentations/722f497c8a734d369114f1192f27be58/slide_30.jpg){kind=link}
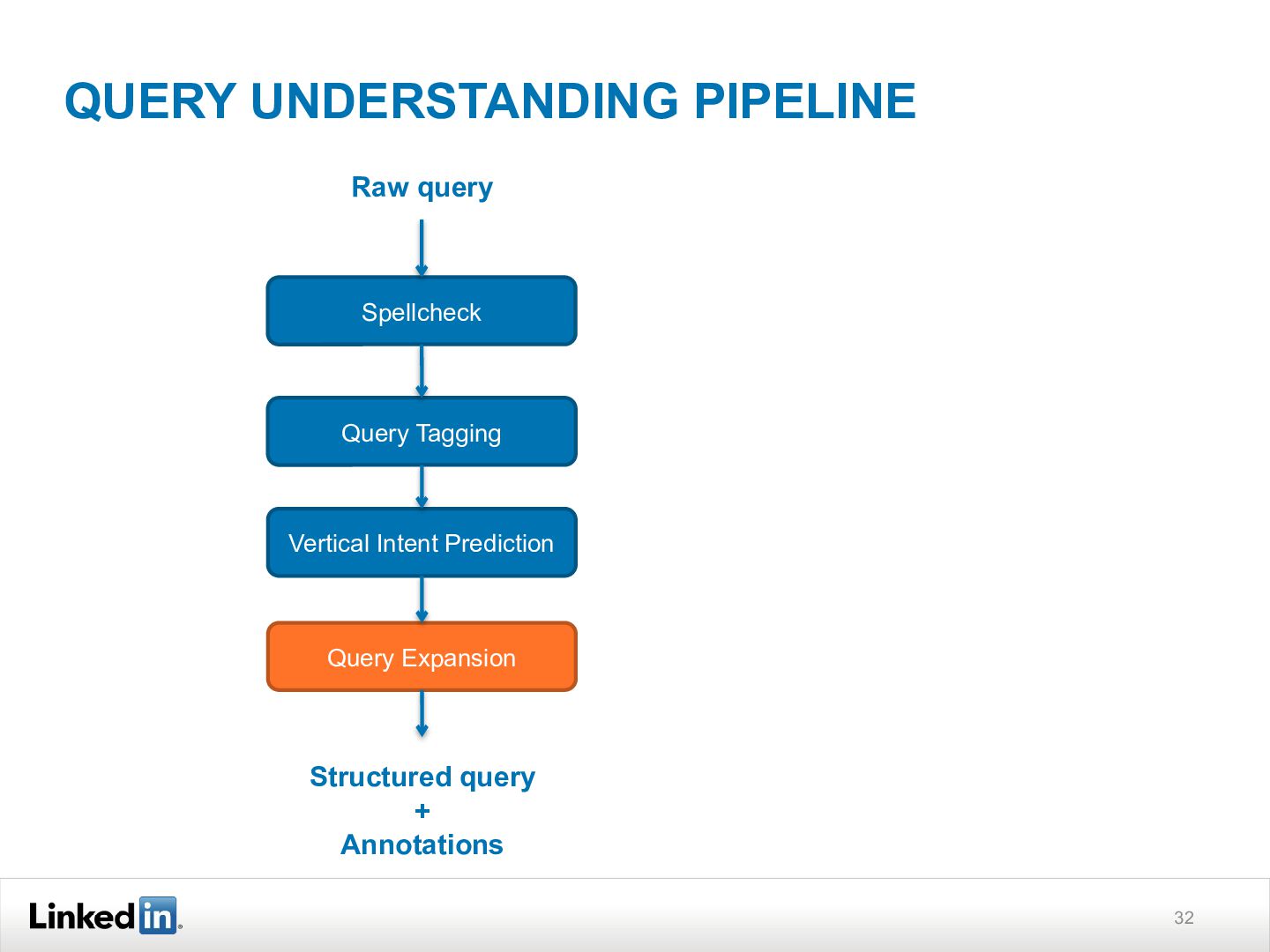{kind=link}
{kind=link}
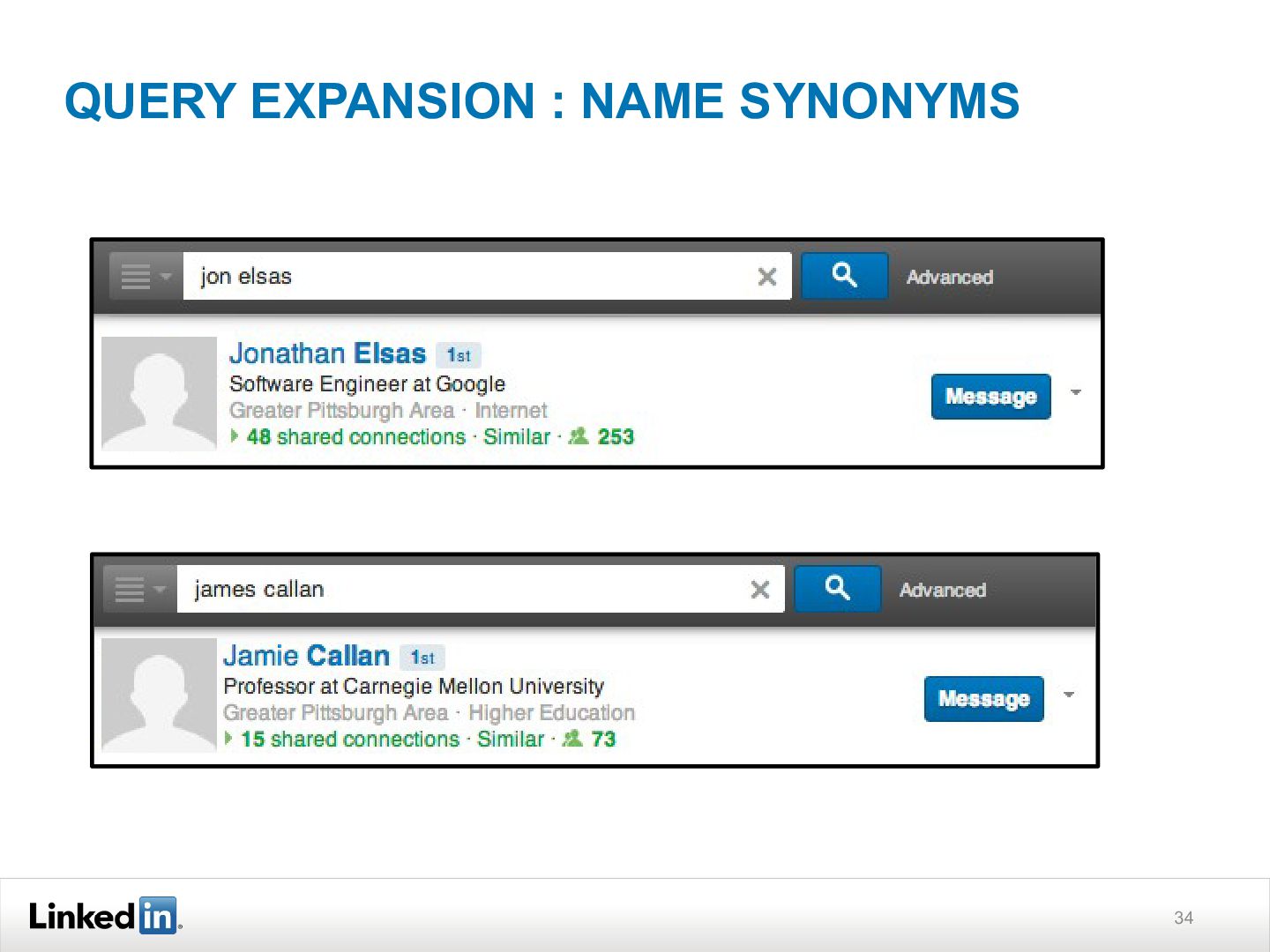{kind=link}
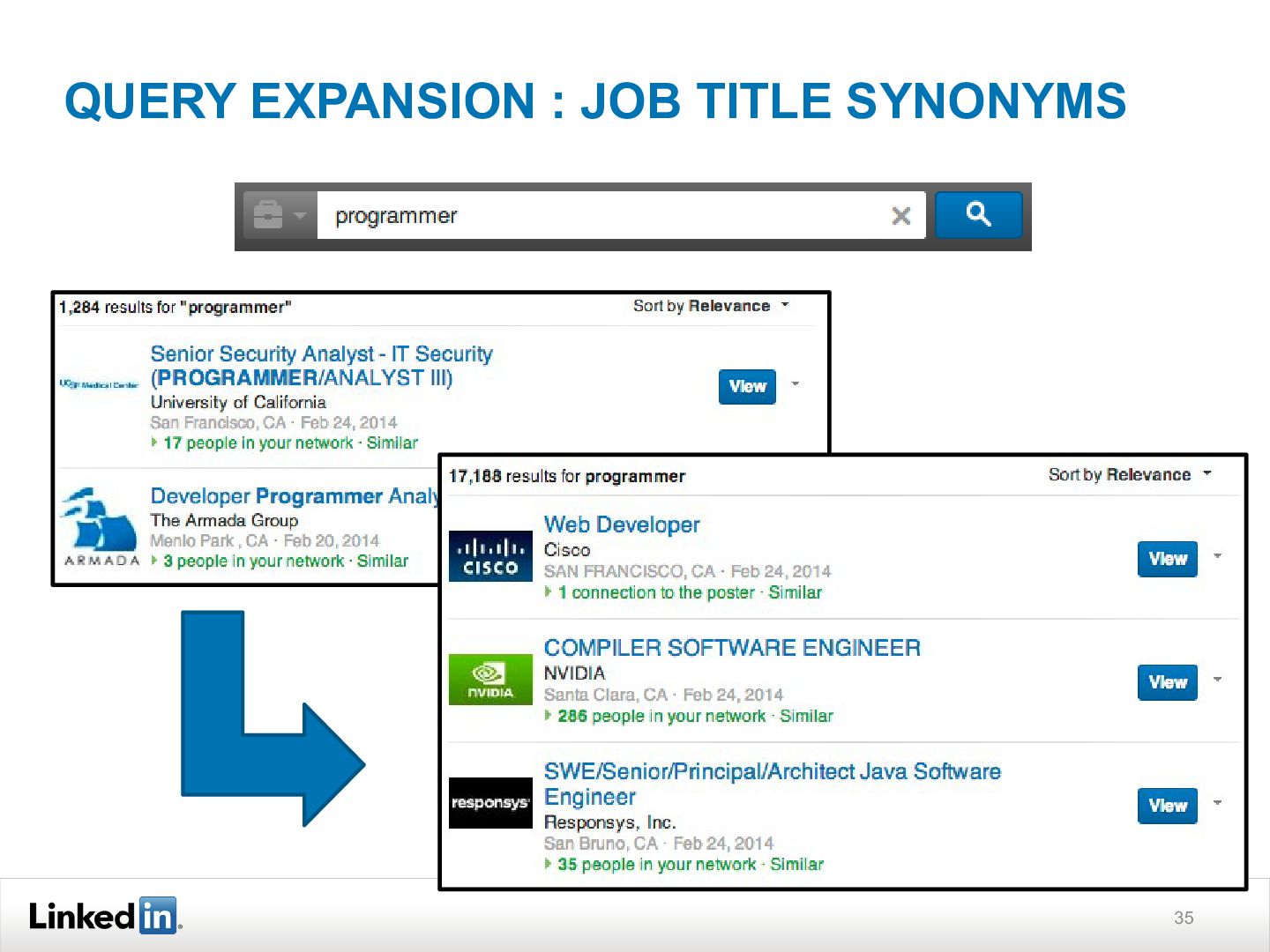{kind=link}
![36 QUERY EXPANSION : SIGNALS [jon] [jonathan] CLICK Trained using](https://files.speakerdeck.com/presentations/722f497c8a734d369114f1192f27be58/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
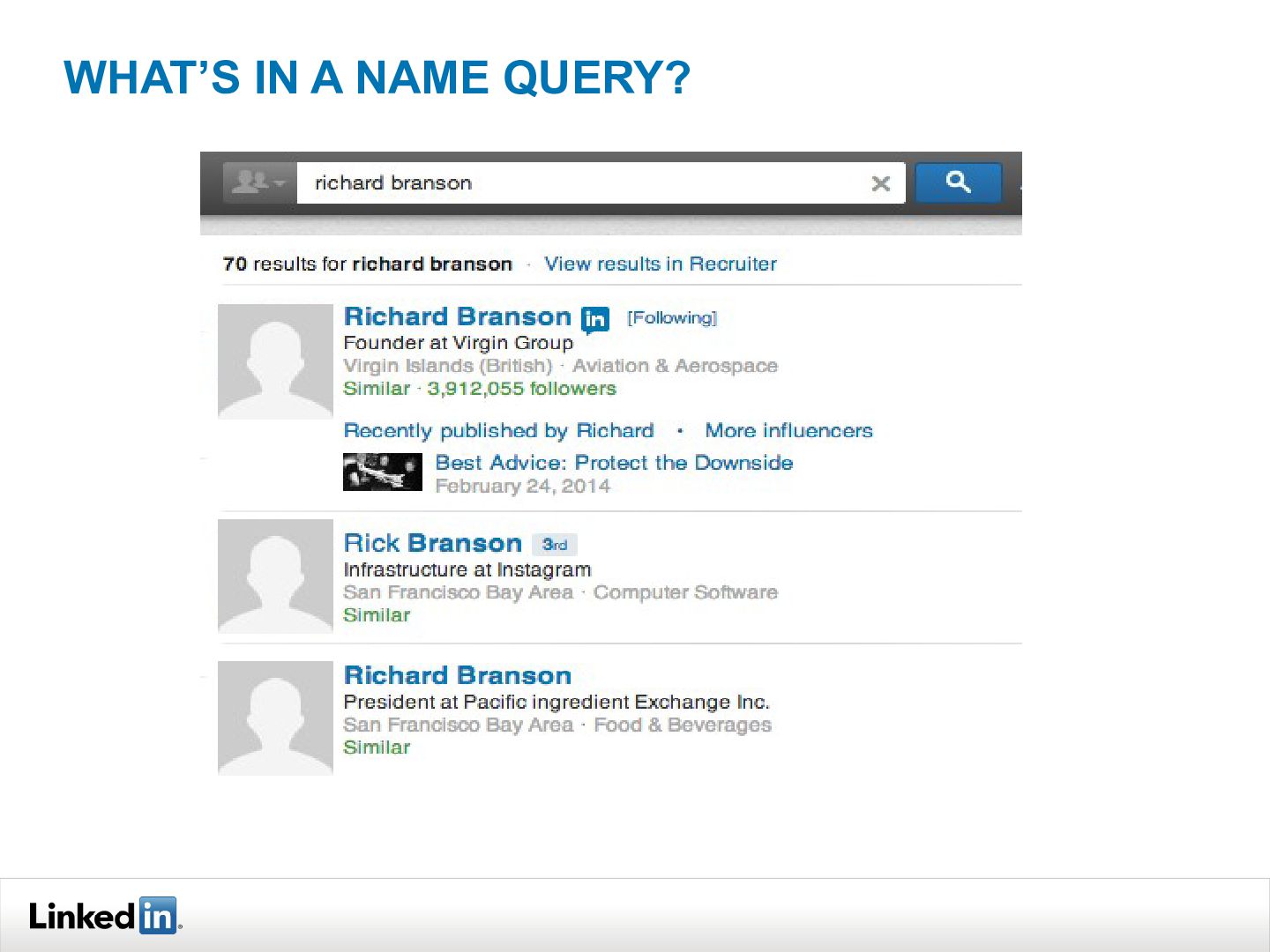{kind=link}
{kind=link}
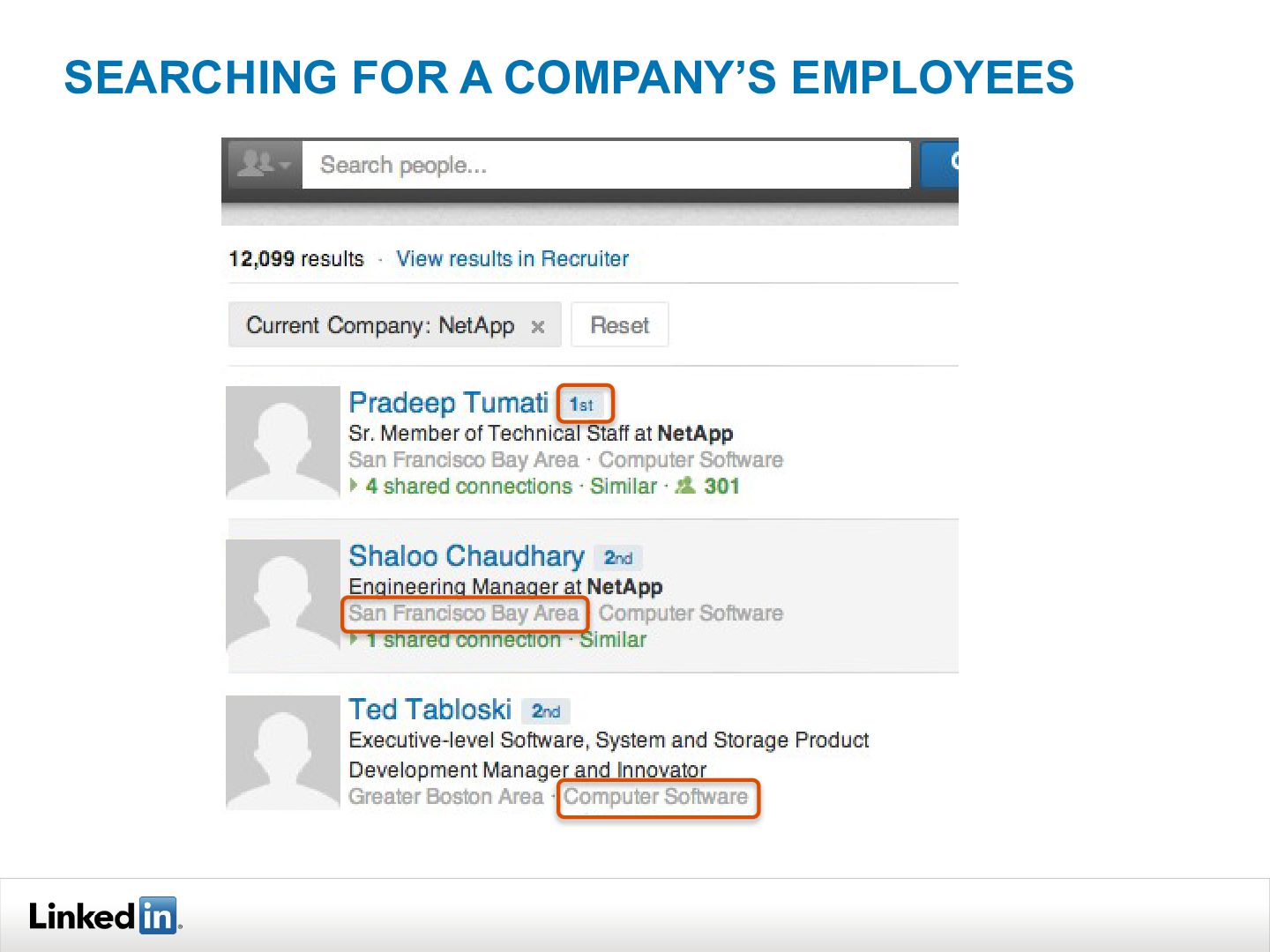{kind=link}
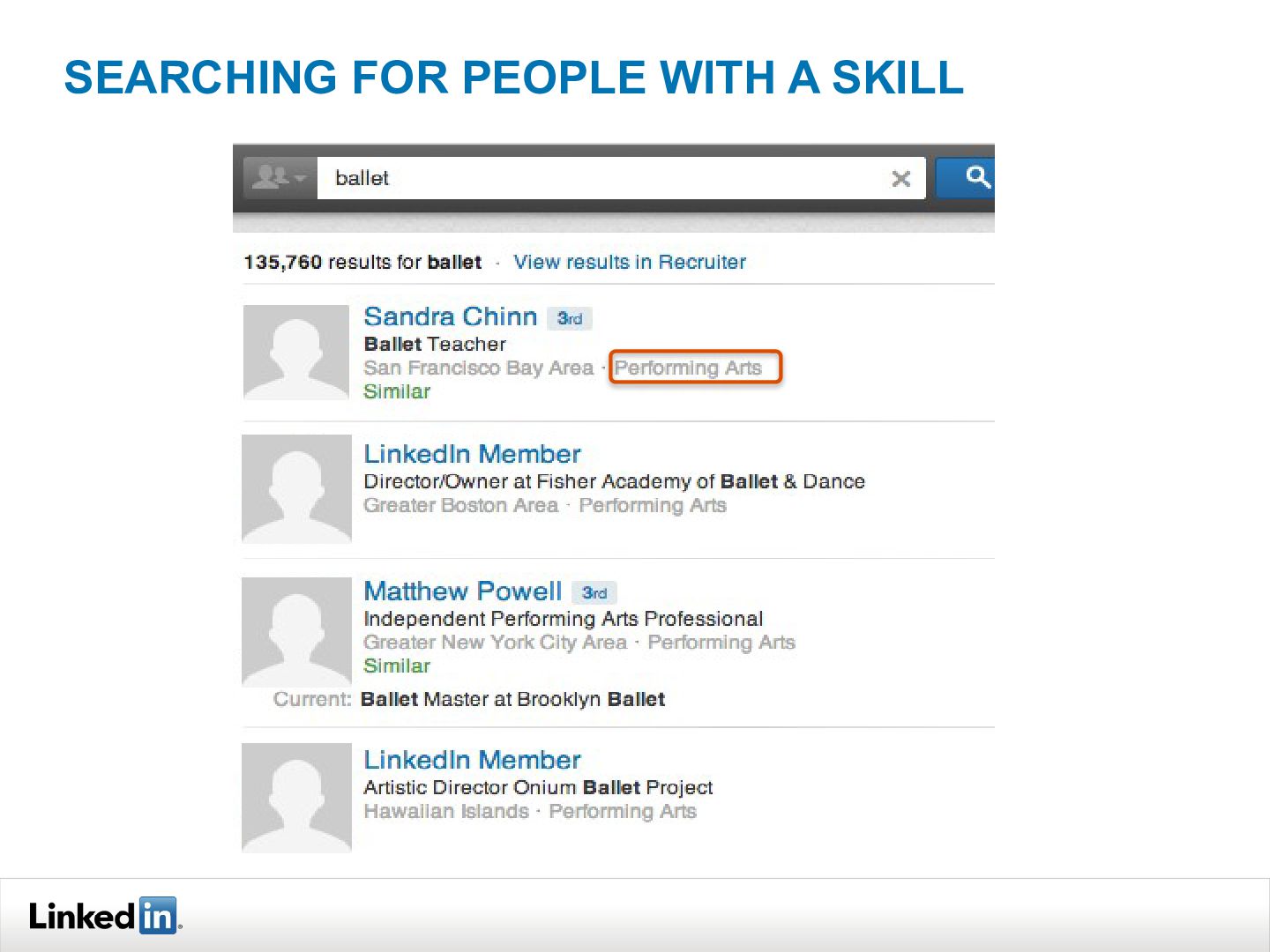{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
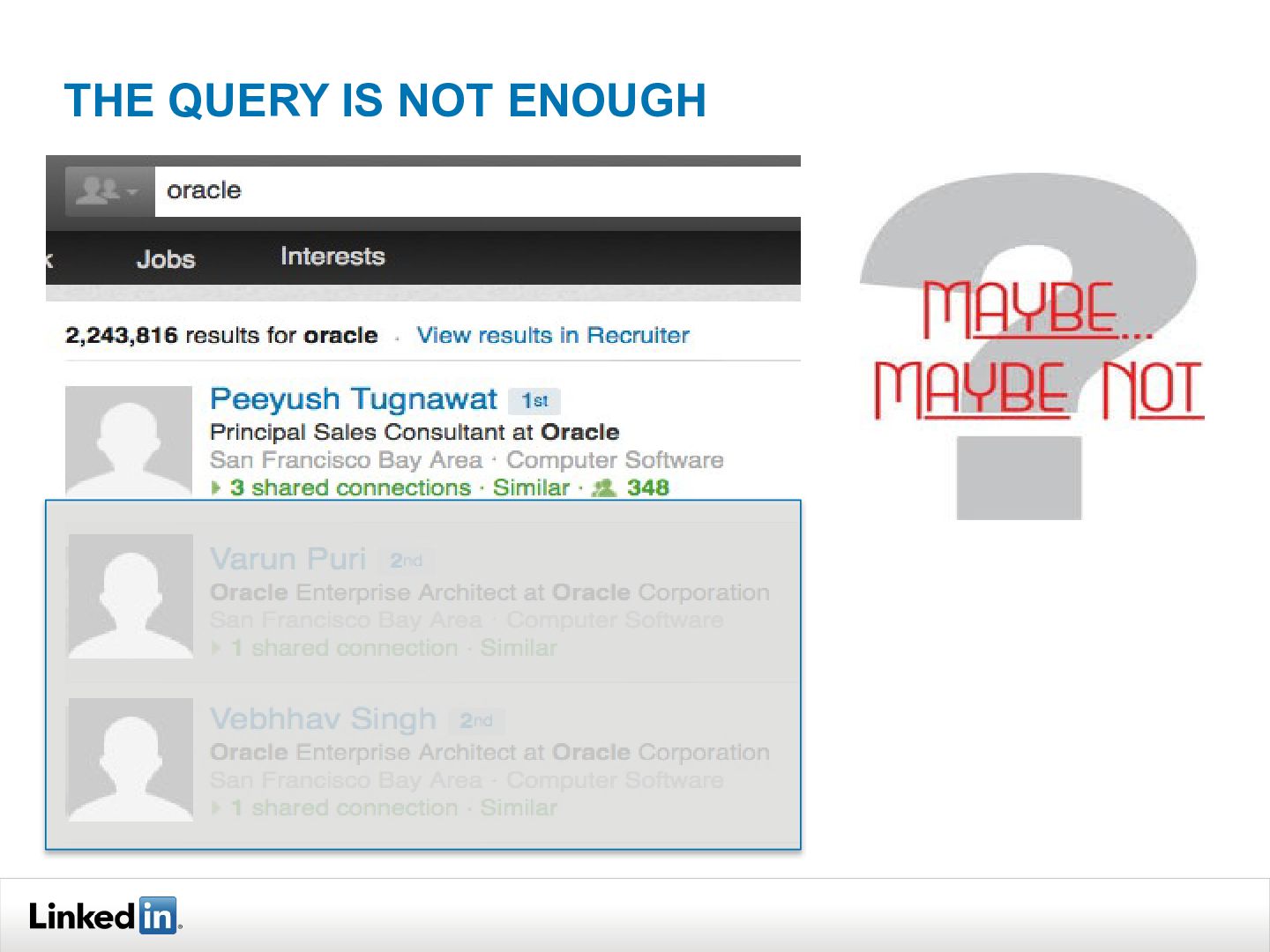{kind=link}
{kind=link}
{kind=link}
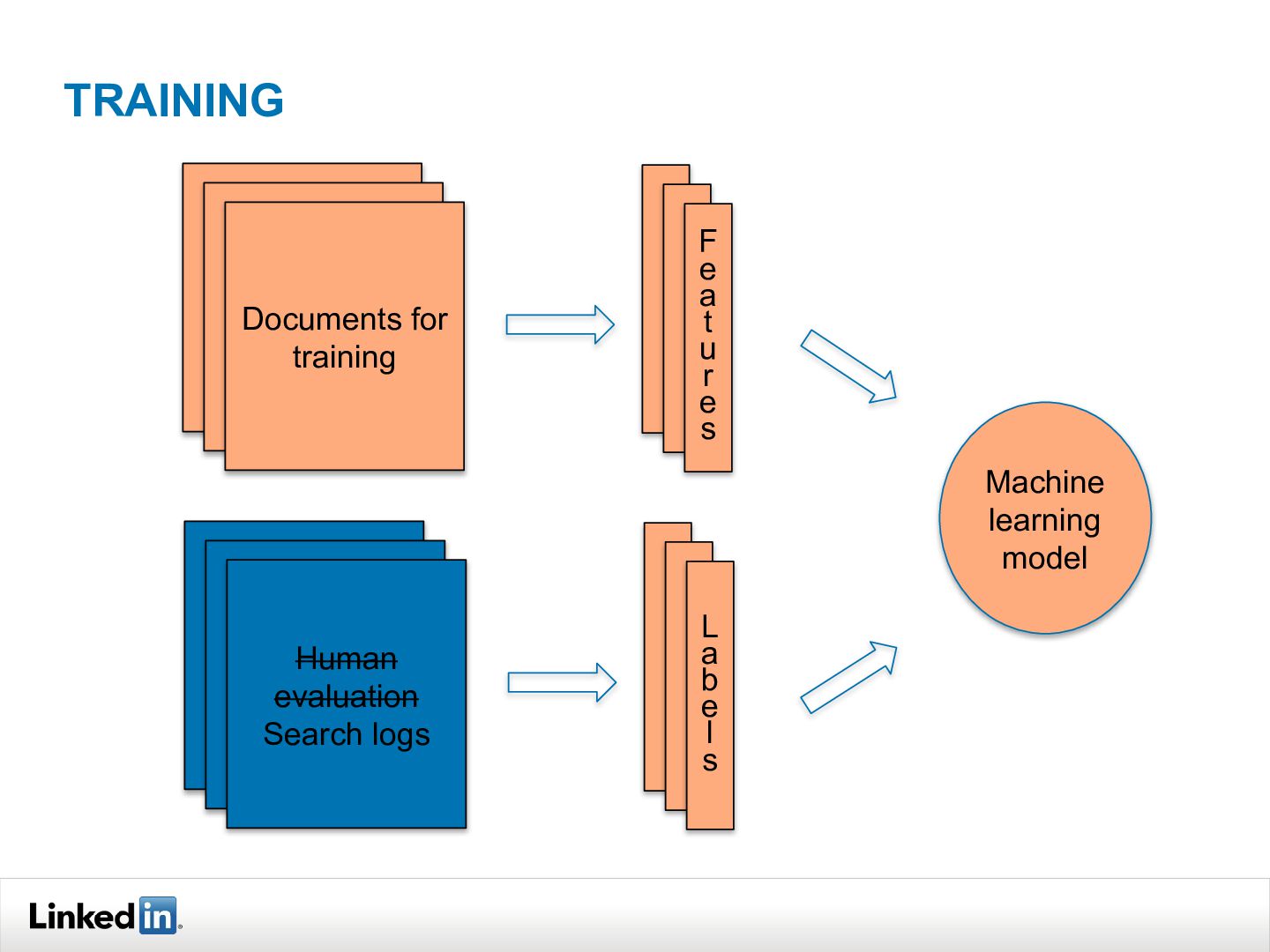{kind=link}
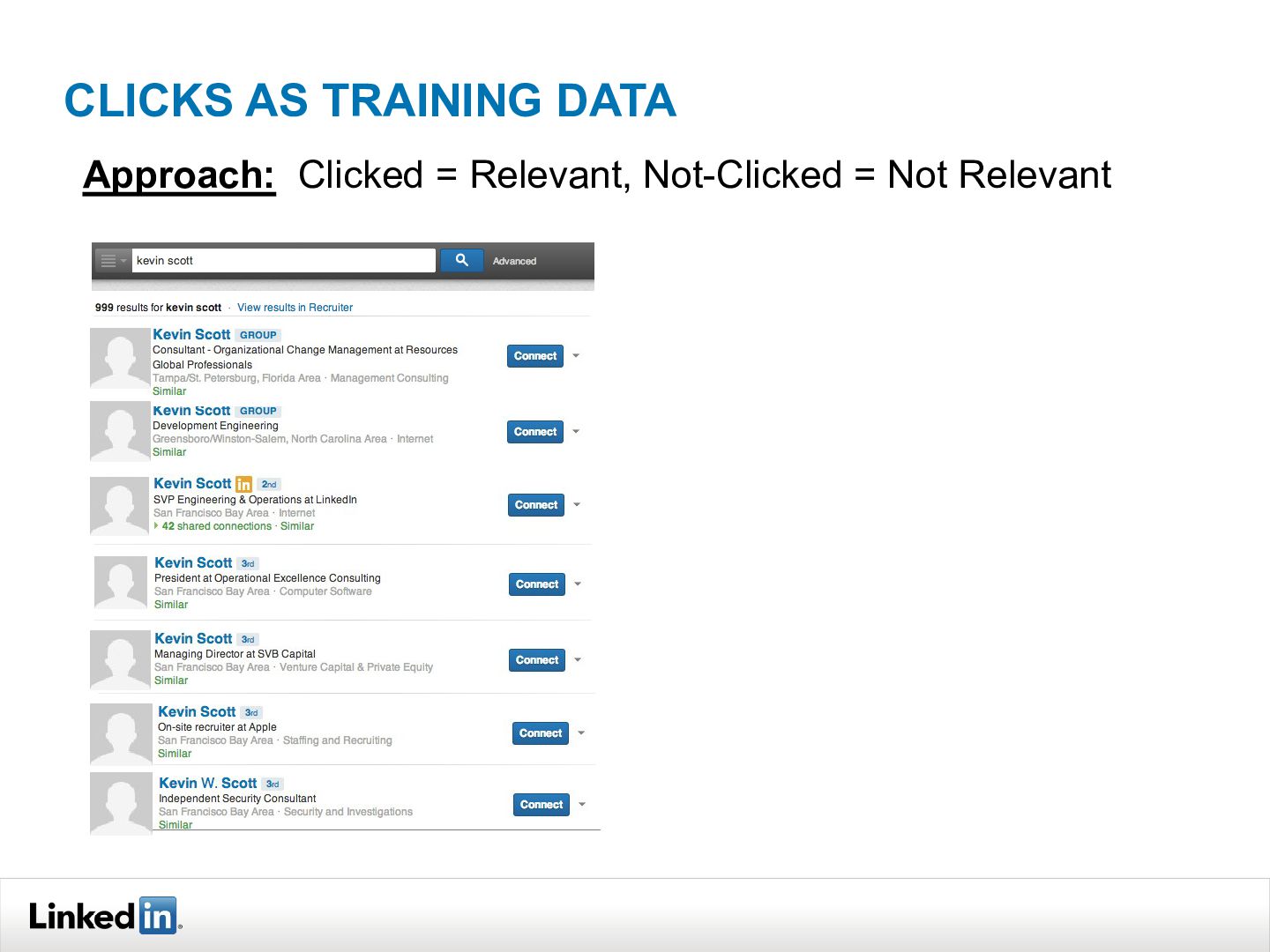{kind=link}
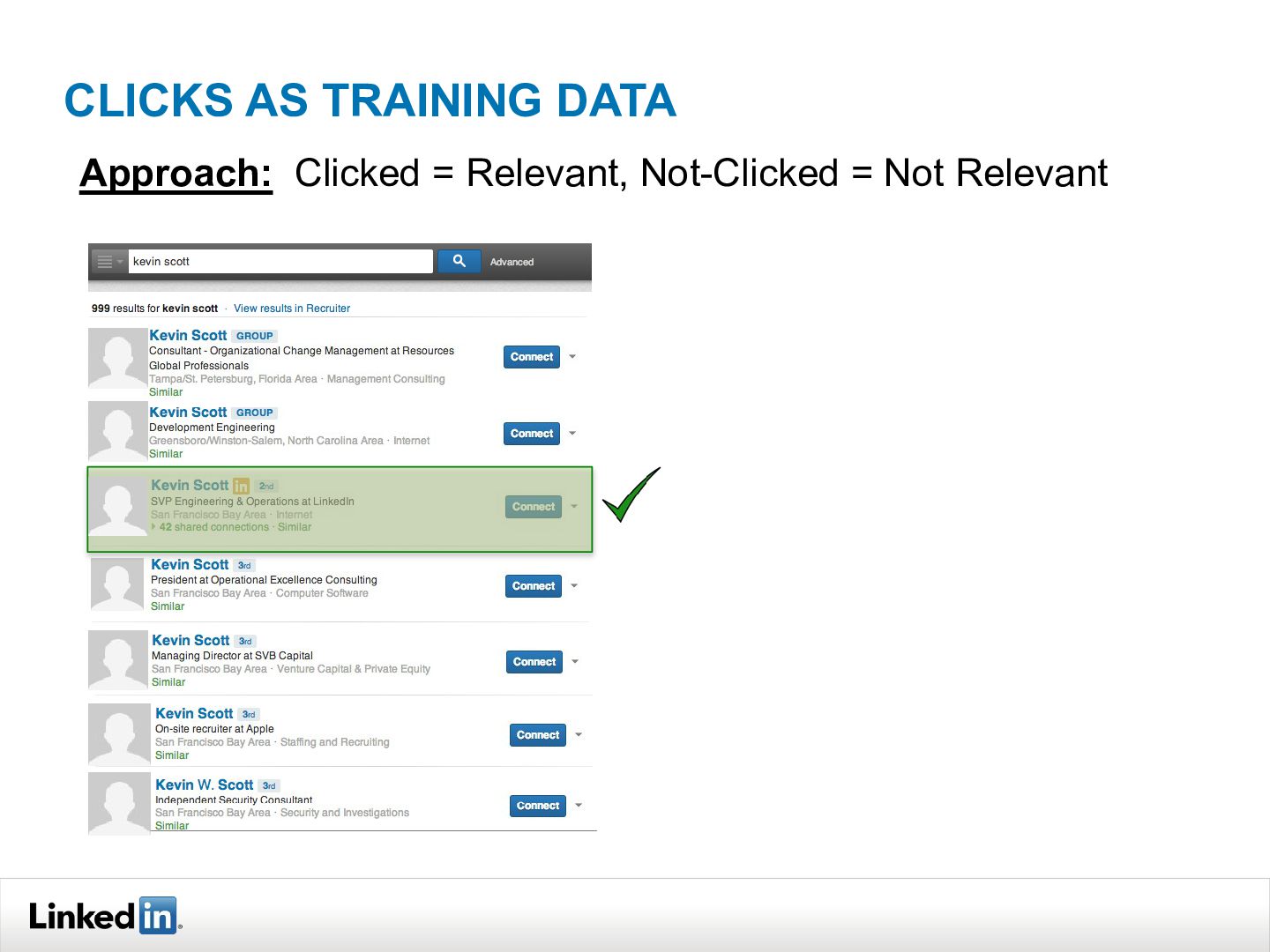{kind=link}
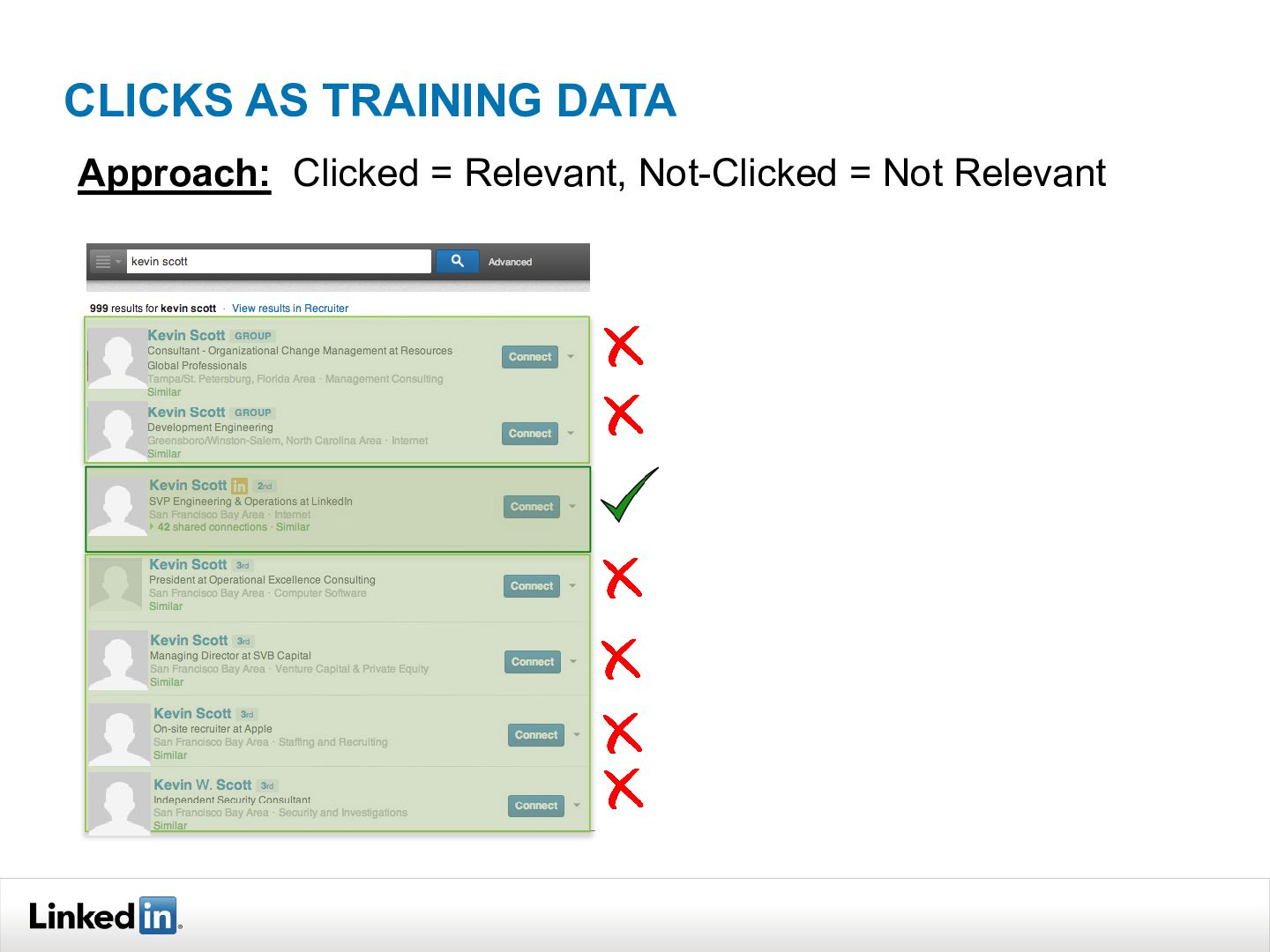{kind=link}
{kind=link}
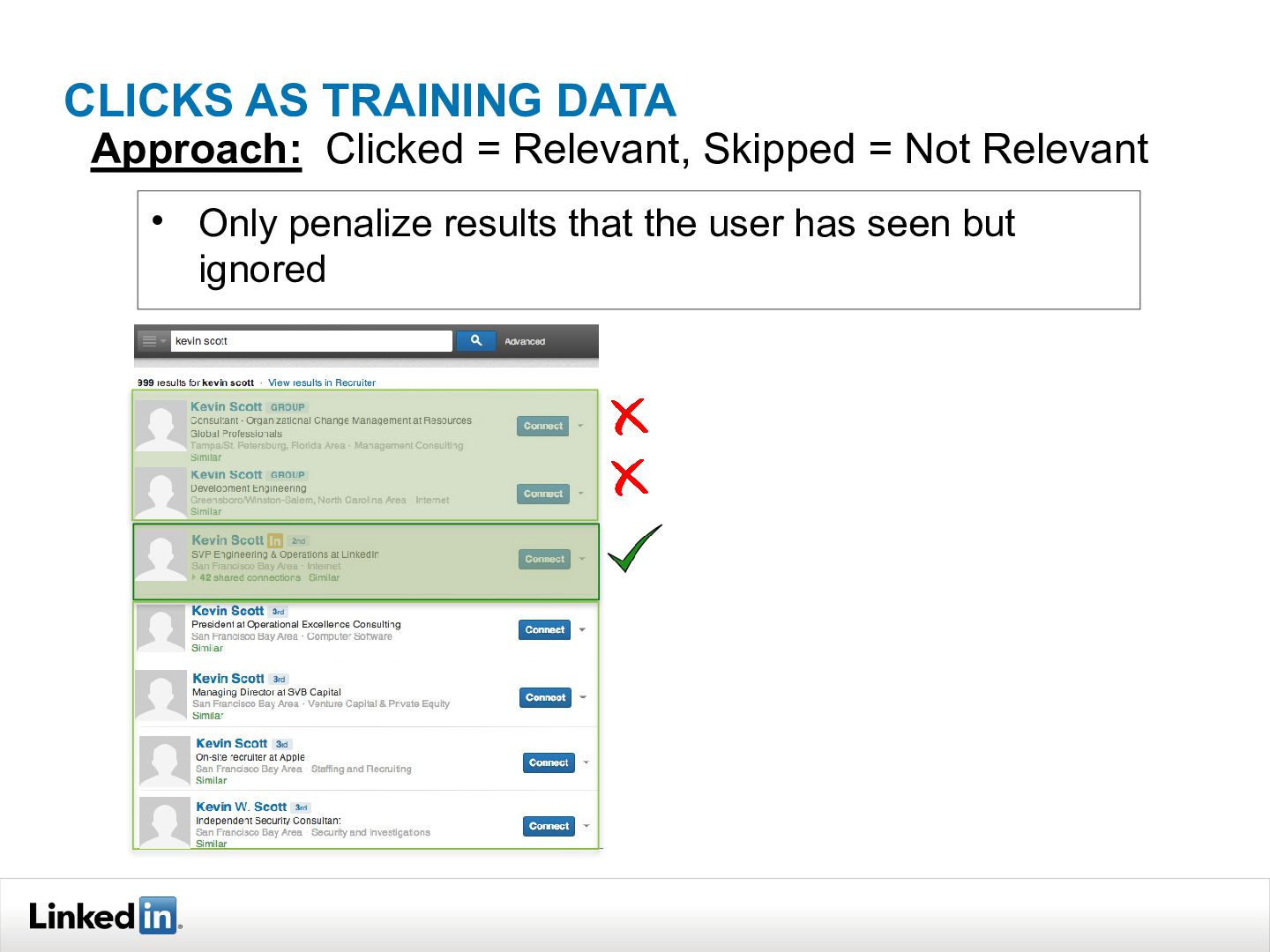{kind=link}
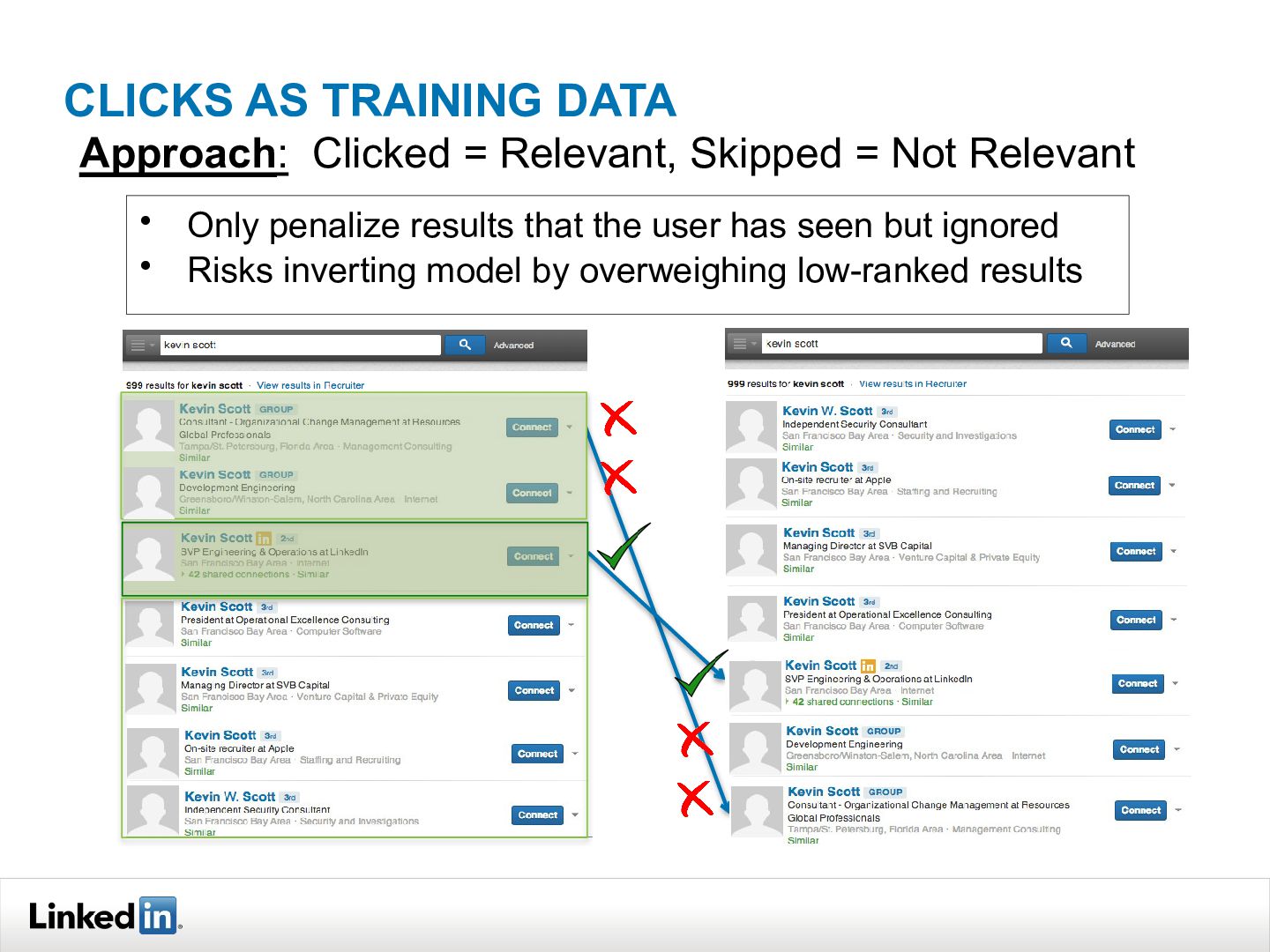{kind=link}
![FAIR PAIRS [Radlinski and Joachims, AAAI’06] • Fair Pairs: •](https://files.speakerdeck.com/presentations/722f497c8a734d369114f1192f27be58/slide_59.jpg){kind=link}
![FAIR PAIRS Flippe d [Radlinski and Joachims, AAAI’06] • Fair](https://files.speakerdeck.com/presentations/722f497c8a734d369114f1192f27be58/slide_60.jpg){kind=link}
![FAIR PAIRS Flippe d [Radlinski and Joachims, AAAI’06] • Fair](https://files.speakerdeck.com/presentations/722f497c8a734d369114f1192f27be58/slide_61.jpg){kind=link}
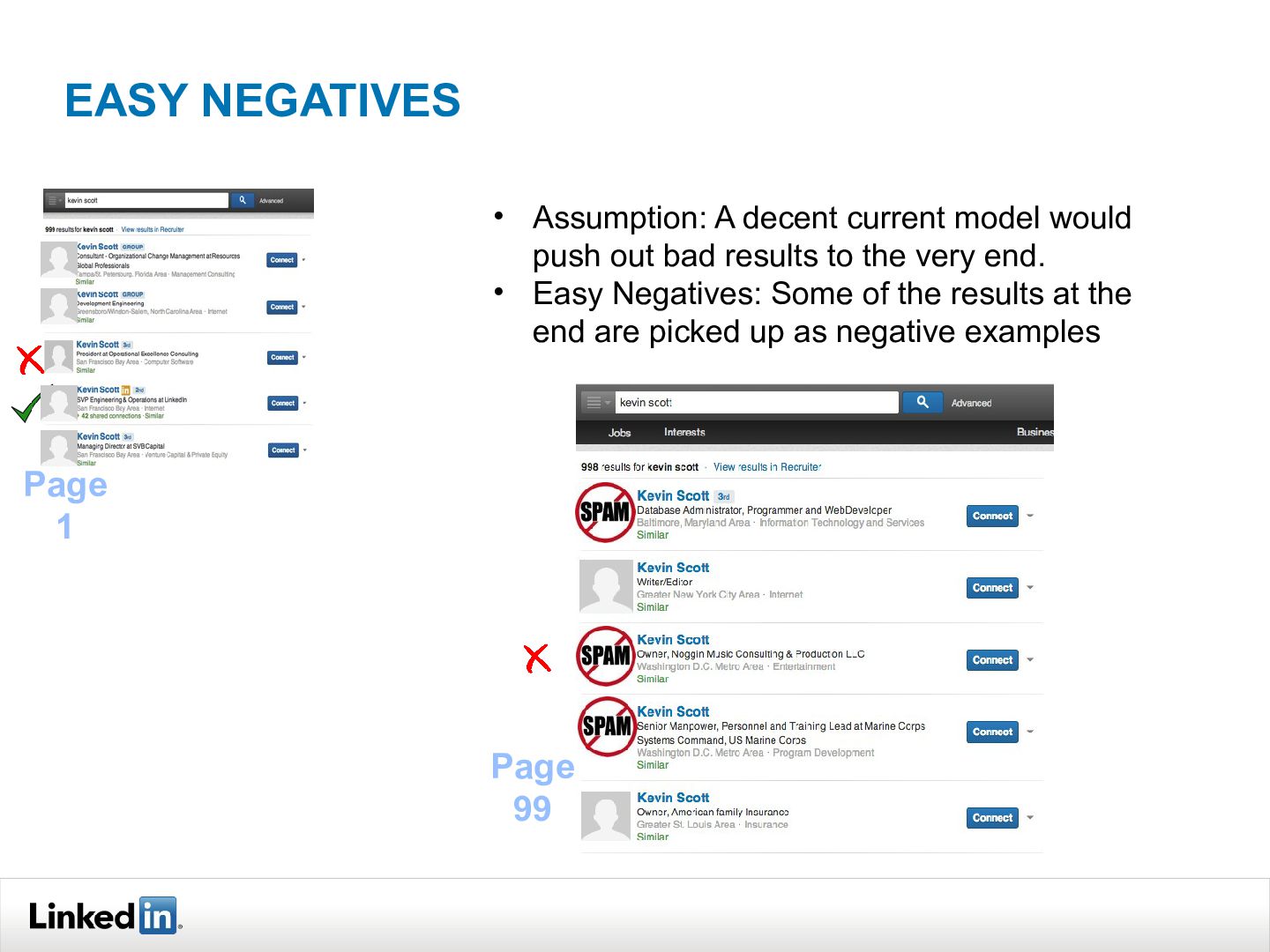{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![71 Abhimanyu Lad Satya Kanduri [email protected] [email protected] https://linkedin.com/in/abhilad https://linkedin.com/in/skanduri](https://files.speakerdeck.com/presentations/722f497c8a734d369114f1192f27be58/slide_70.jpg){kind=link}