This 2014 O'Reilly Strata presentation discusses LinkedIn's approach to search.
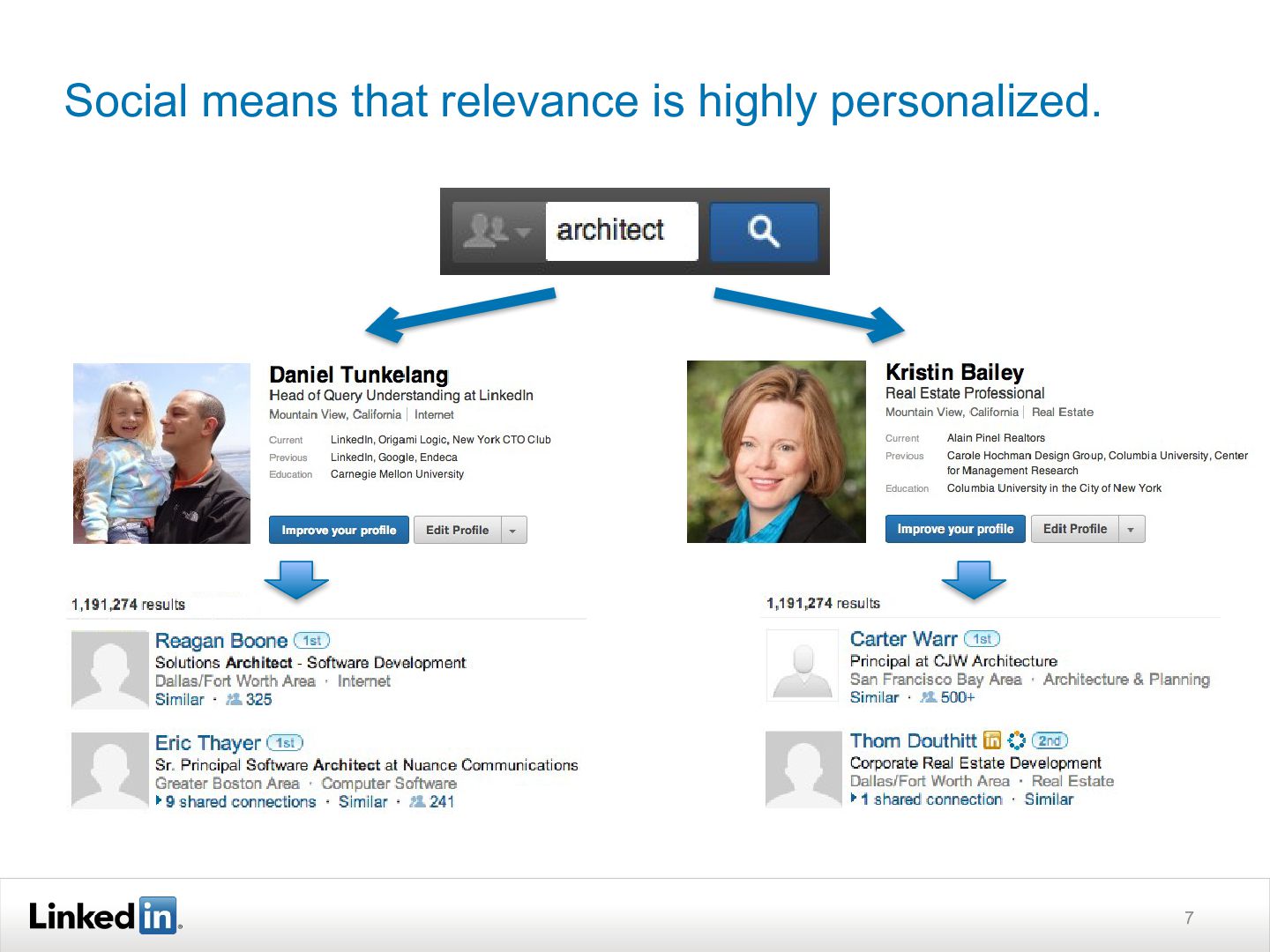
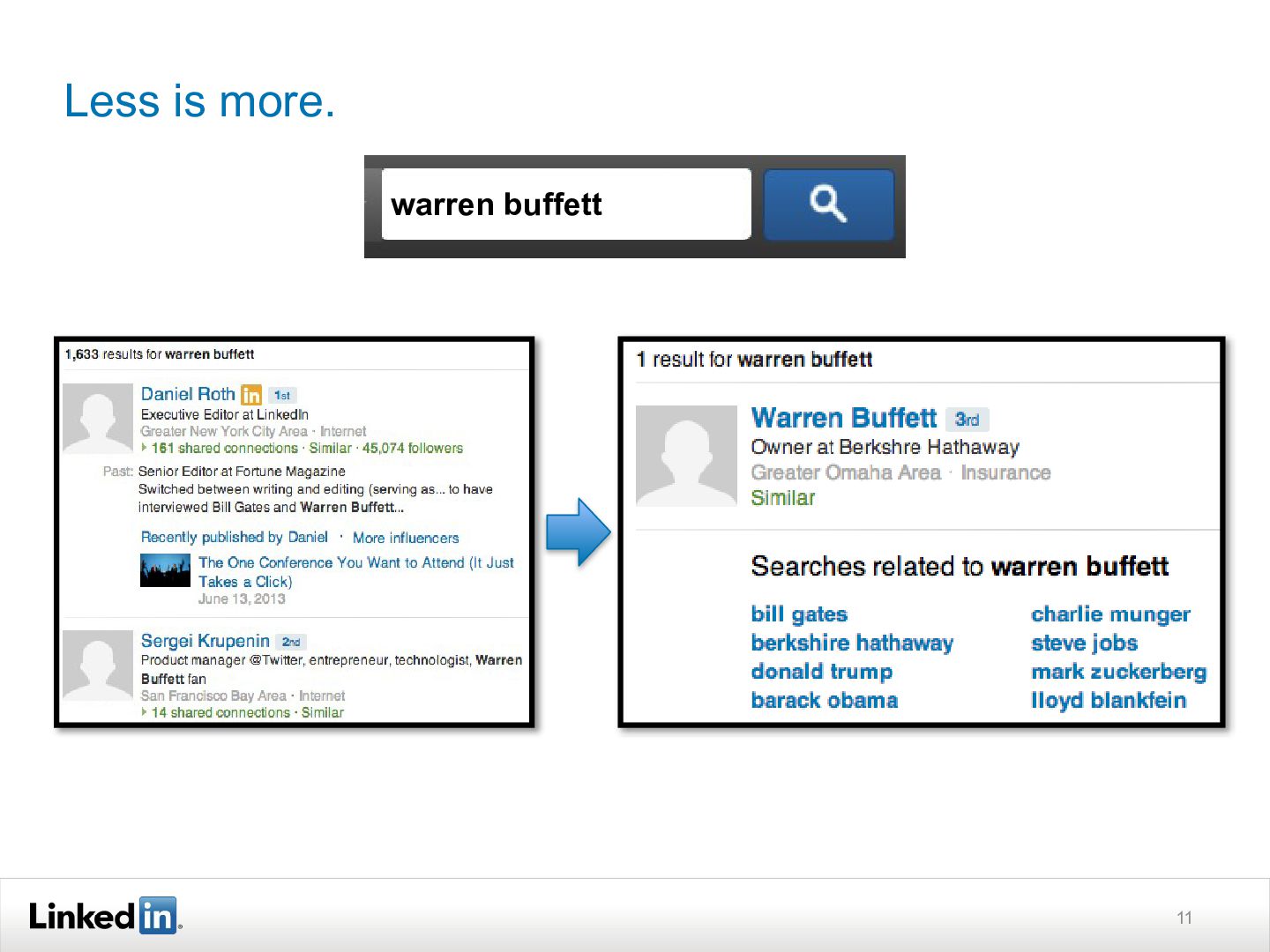
LinkedIn has a unique data collection: the 277M+ members who use LinkedIn are also the most valuable entities in its corpus, which consists of people, companies, jobs, and a rich content ecosystem. Its members use LinkedIn to satisfy a diverse set of navigational and exploratory information needs, which it addresses by leveraging semi-structured and social content to understanding their query intent and deliver a personalized search experience.
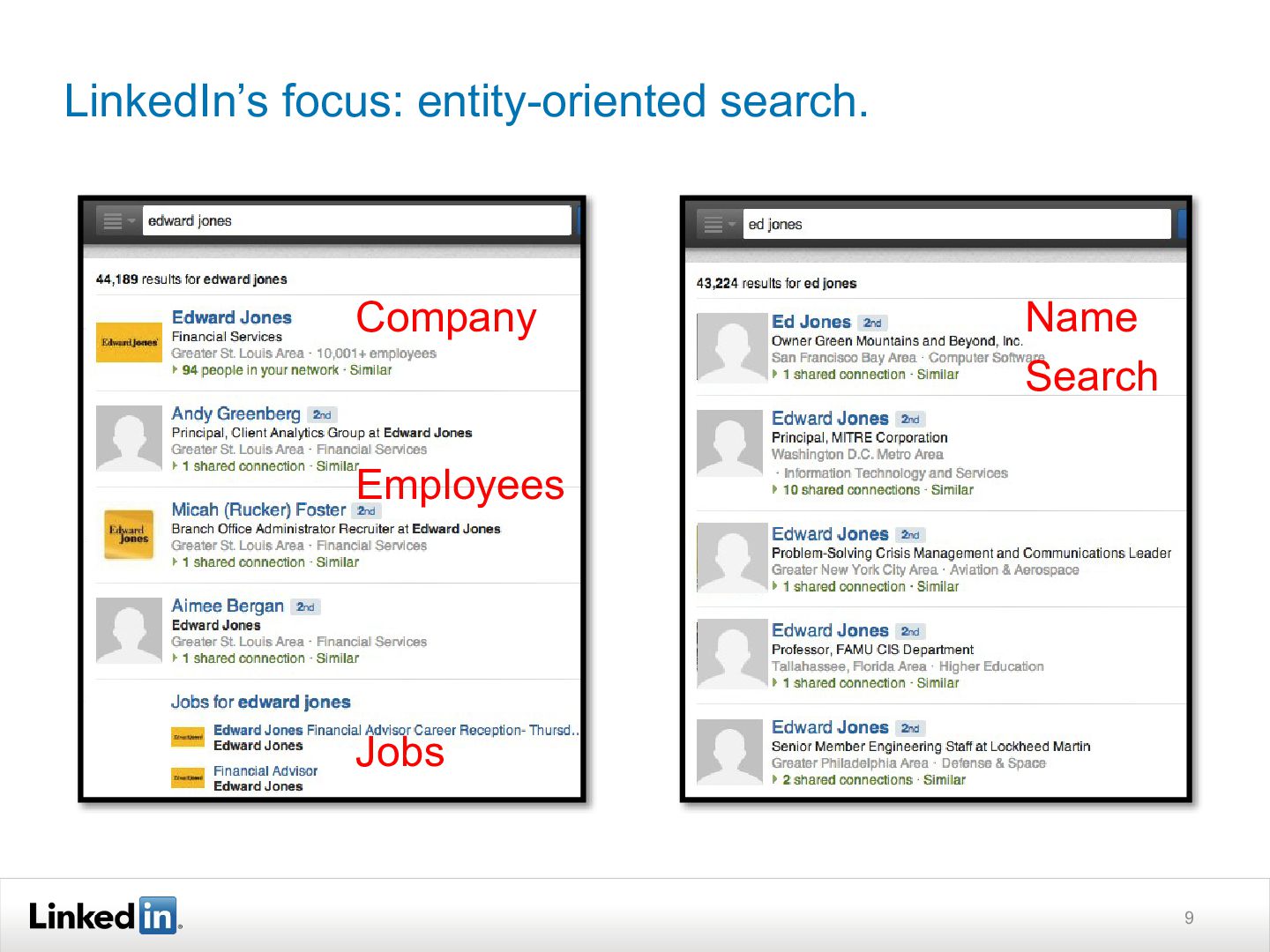
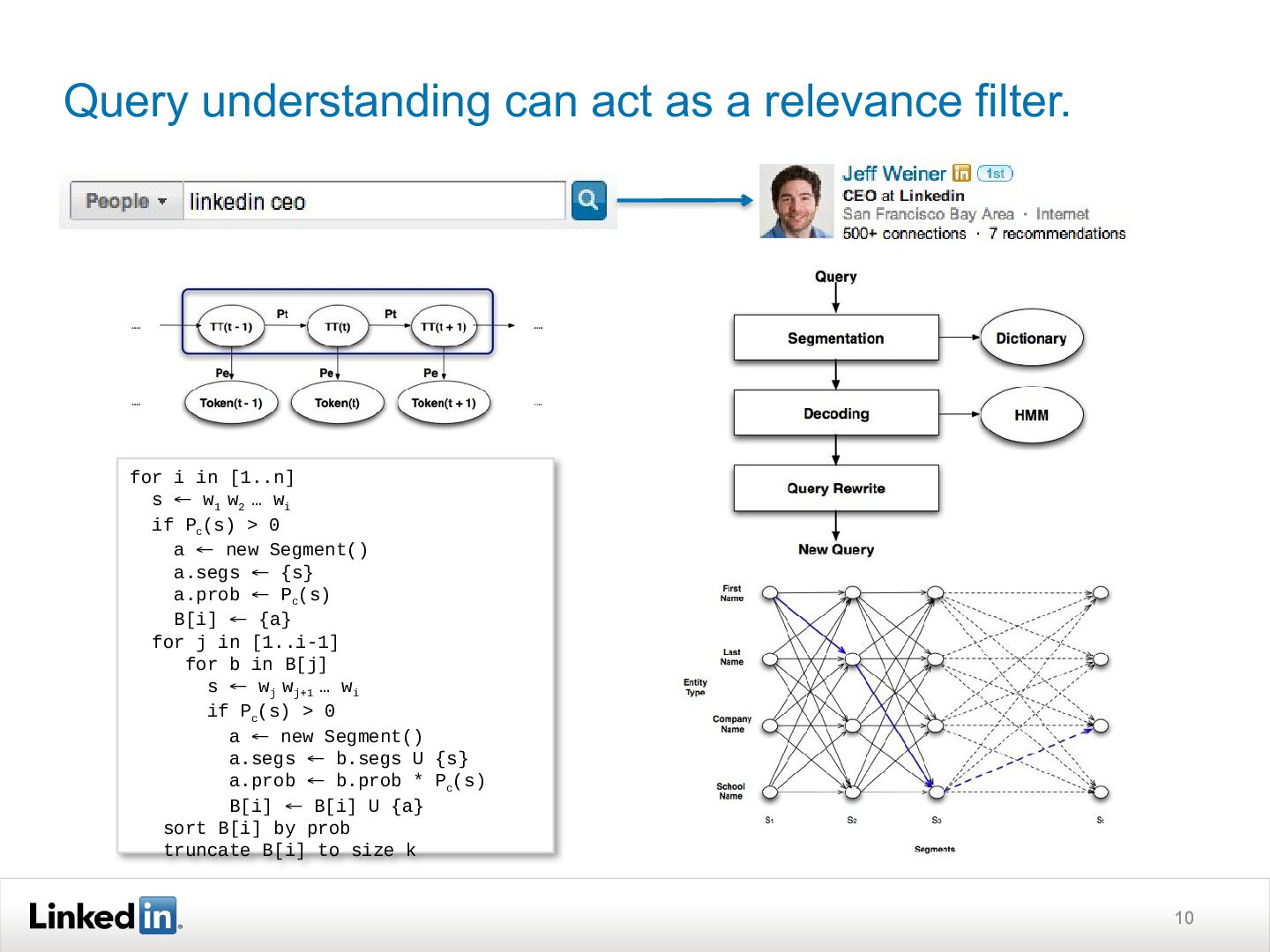
As a result, it has built a system quite different from those used for web or enterprise search. This talk discusses how it has addressed the unique scalability, performance, and search quality challenges in order to deliver billions of deeply personalized searches to our members. Although many of the challenges are unique to LinkedIn, the ideas should prove useful to other folks thinking about entity-oriented search or working with large-scale social network data.
{kind=link}
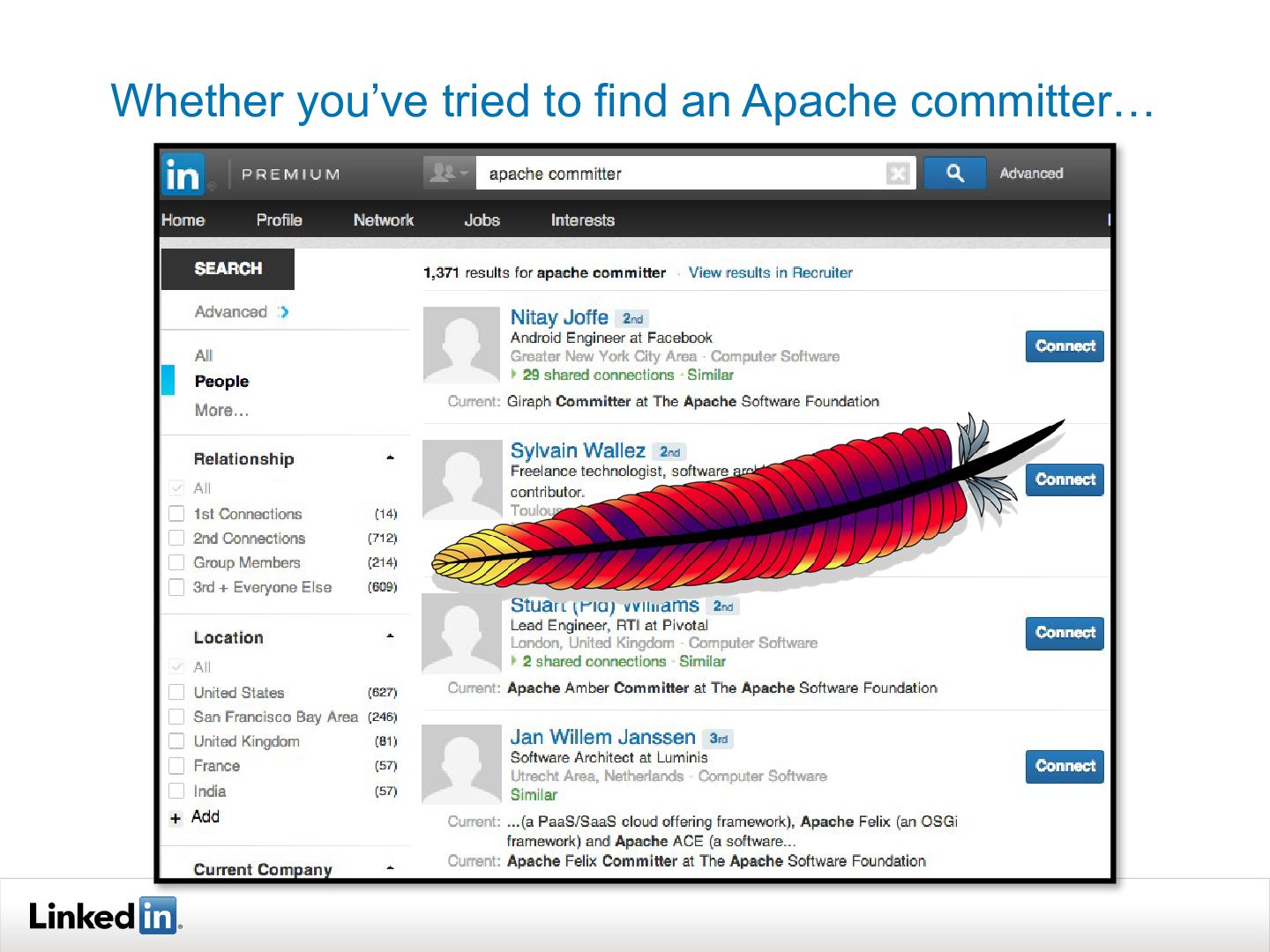{kind=link}
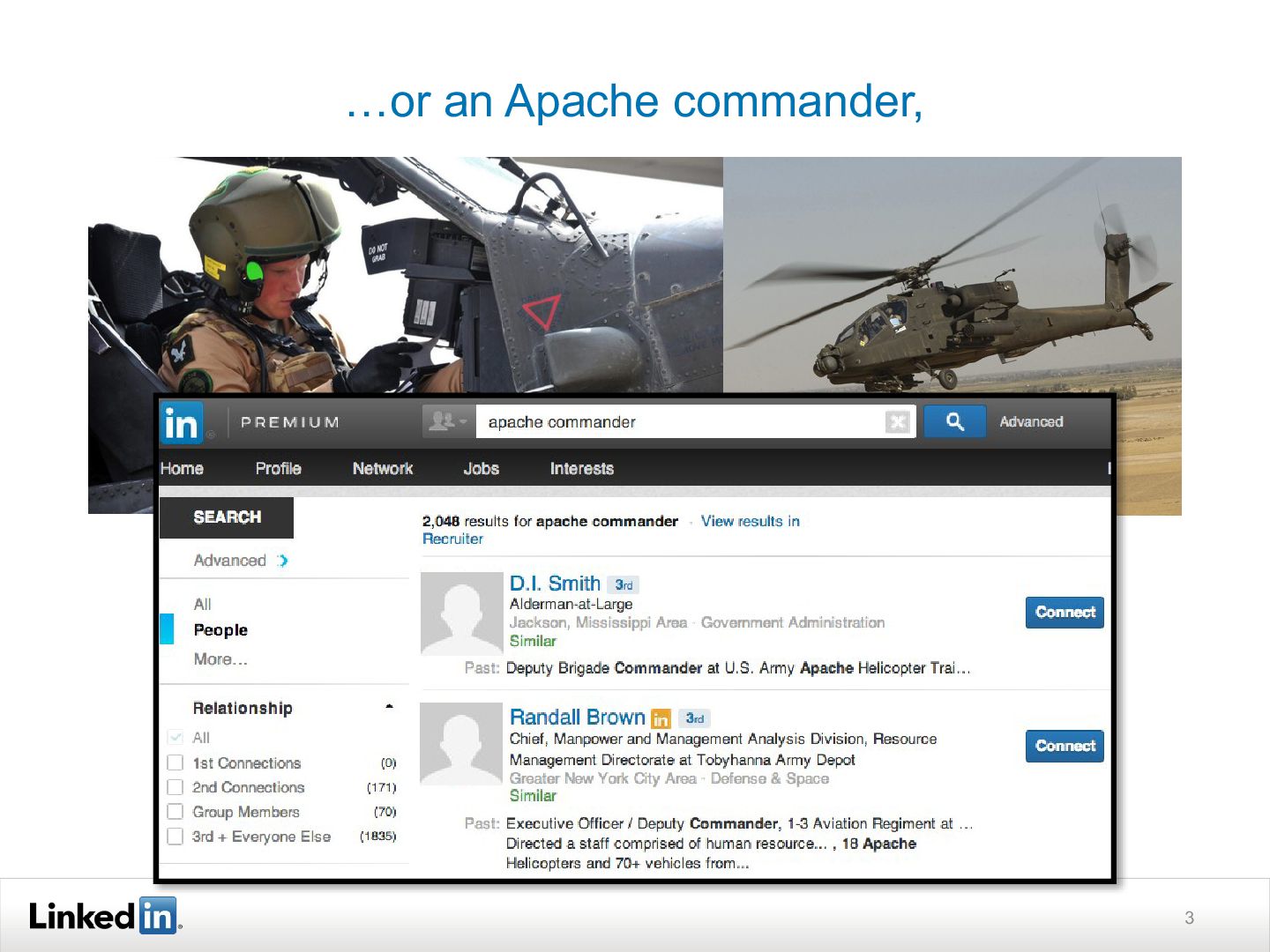{kind=link}
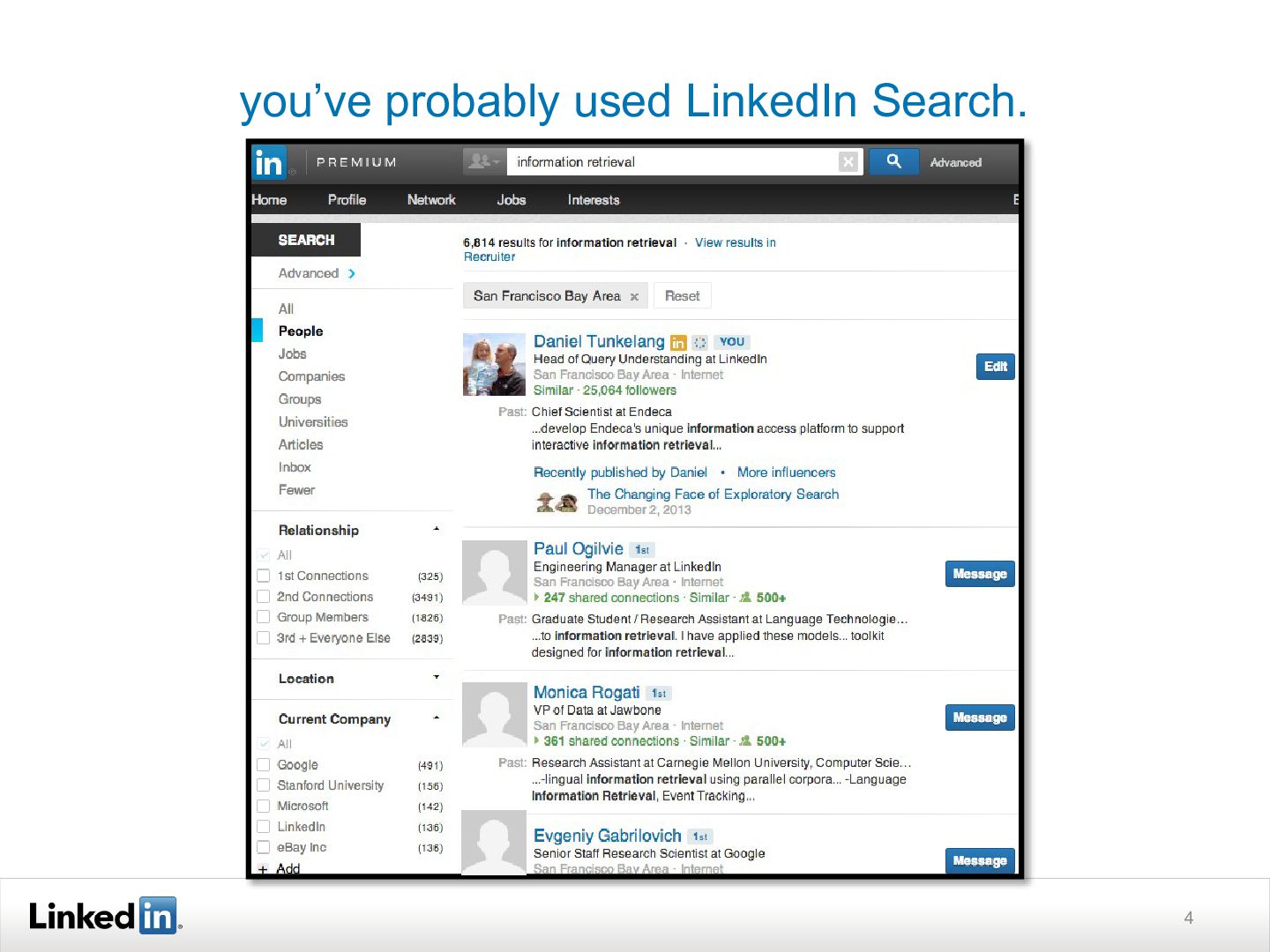{kind=link}
{kind=link}
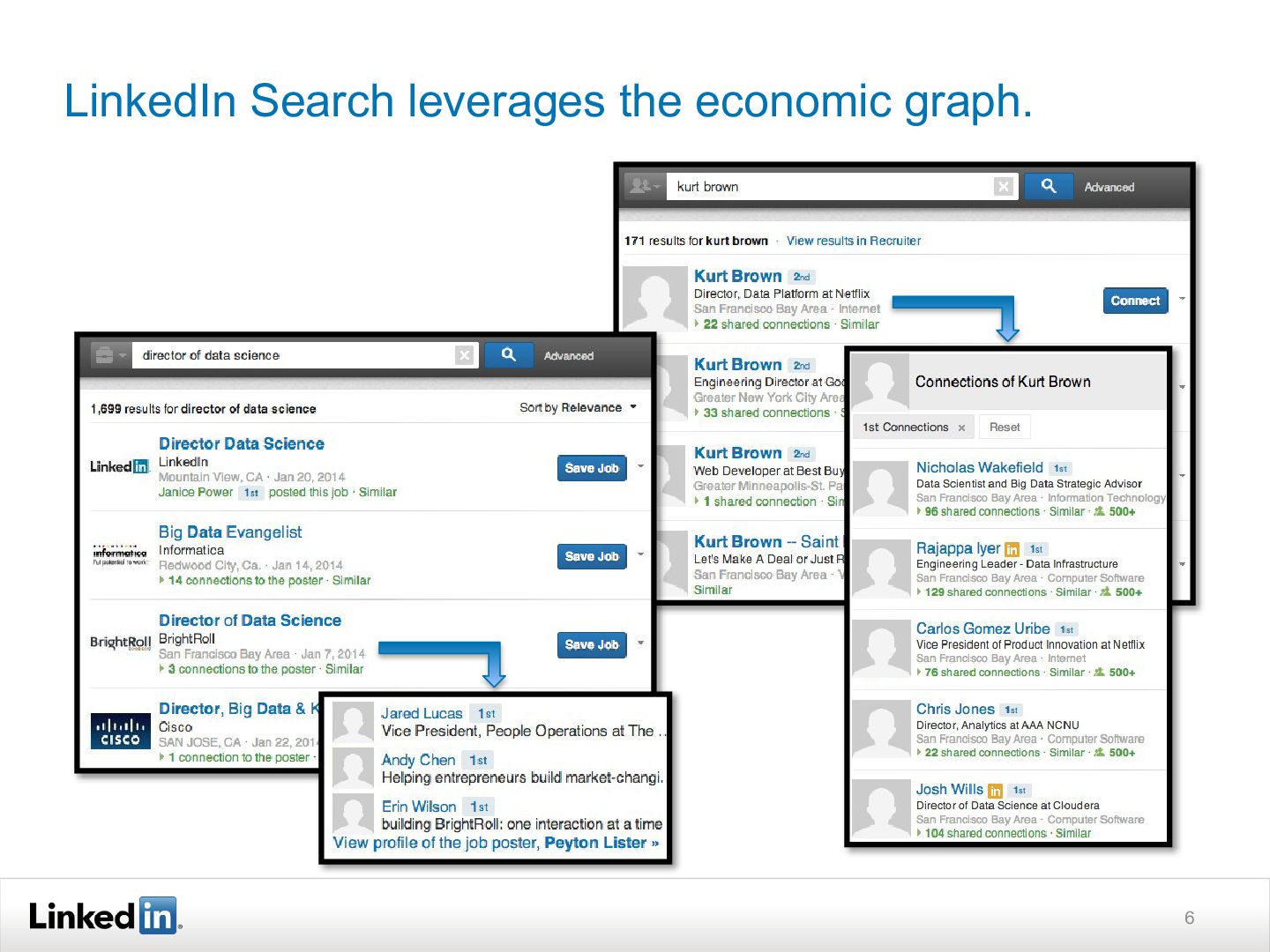{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
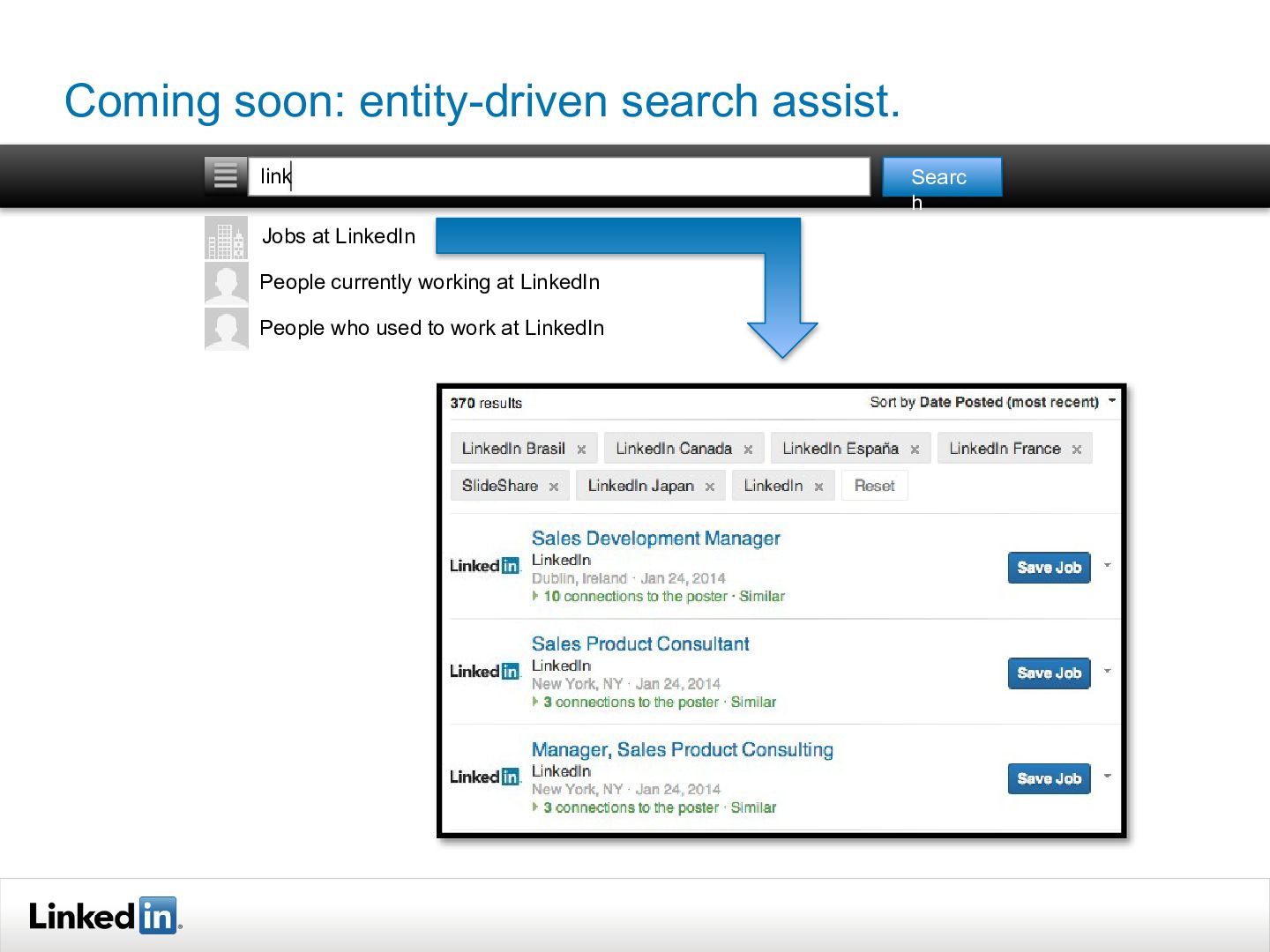{kind=link}
{kind=link}
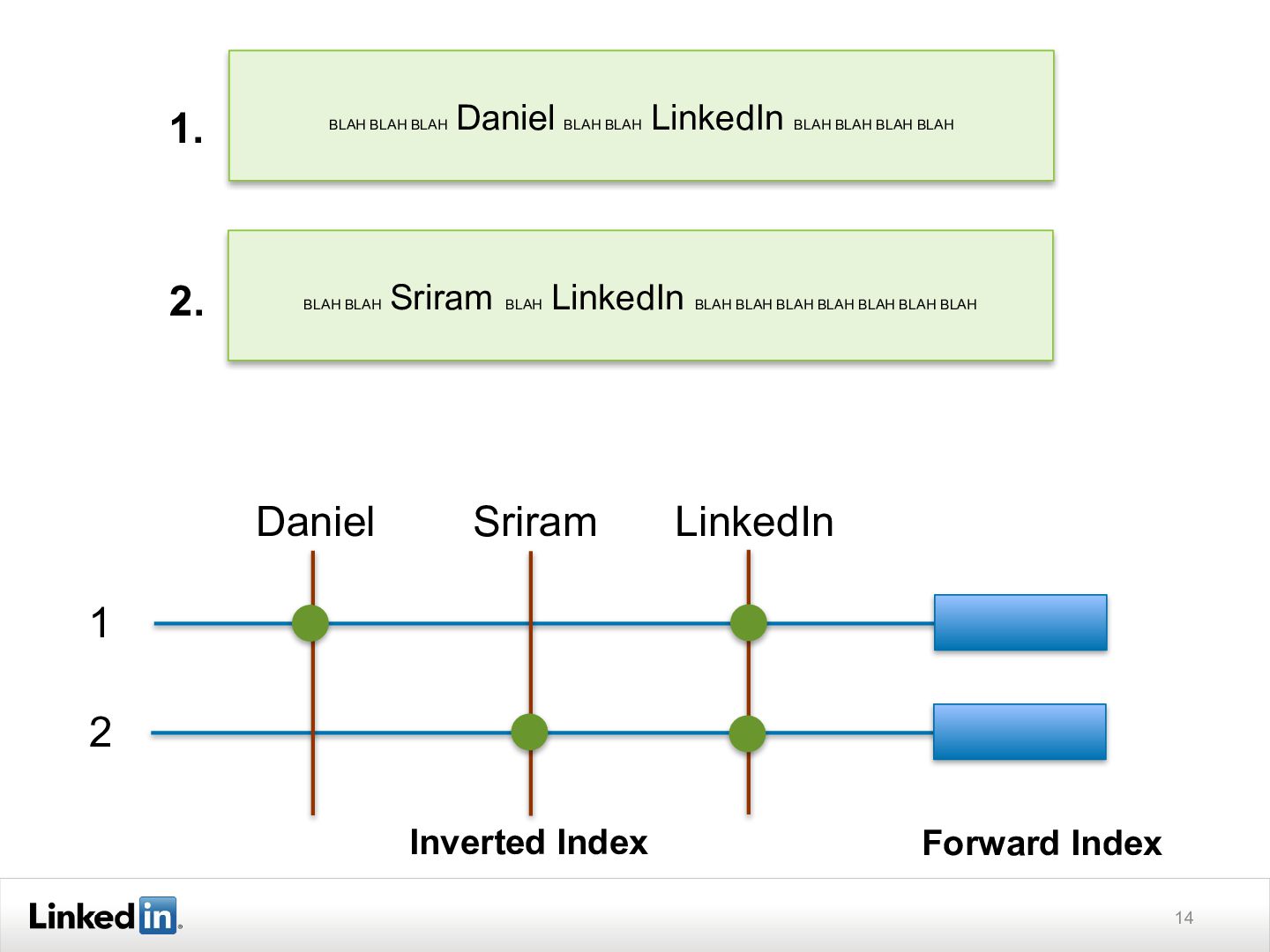{kind=link}
{kind=link}
{kind=link}
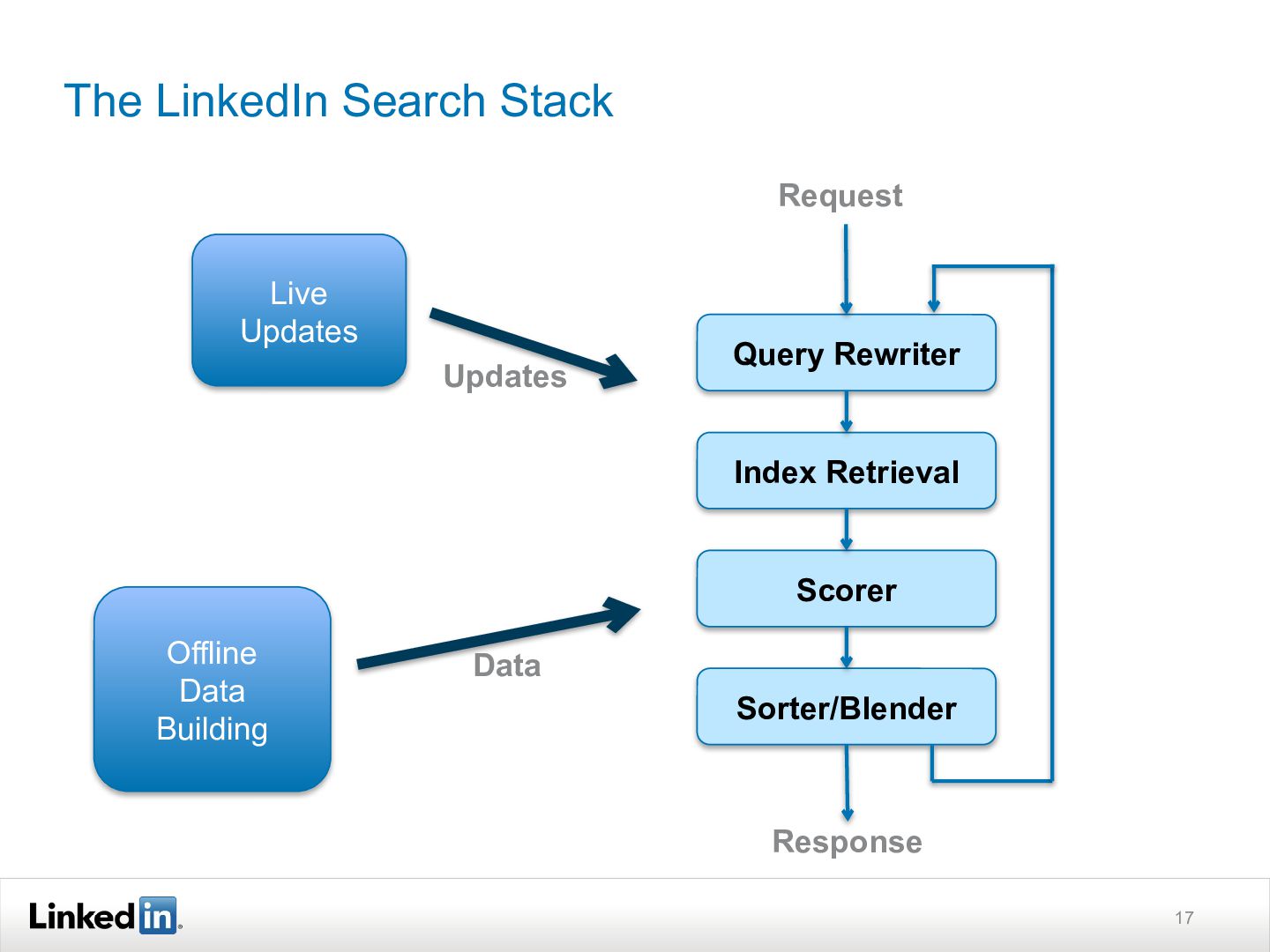{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![25 Sriram Sankar Daniel Tunkelang [email protected] [email protected] https://linkedin.com/in/sriramxsankar https://linkedin.com/in/dtunkelang](https://files.speakerdeck.com/presentations/906ef2704703429bbc7b5915a3434cf7/slide_24.jpg){kind=link}