This 2014 QCon New York presentation discusses LinkedIn's search platform. Search at LinkedIn is different. Its corpus is a richly structured professional graph comprised of 300M+ people, 3M+ companies, 2M+ groups, and 1.5M+ publishers. Its members perform billions of searches (over 5.7B in 2012), and each of those searches is highly personalized based on the searcher's identity and relationships with other professional entities in LinkedIn's economic graph. And all this data is in constant flux as LinkedIn adds more than 2 members every second in over 200 countries (2/3 of its members are outside the United States). As a result, it has built a system quite different from those used for other search applications. This talk discusses some of the unique challenges it has faced to deliver highly personalized search over semi-structured data at massive scale.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
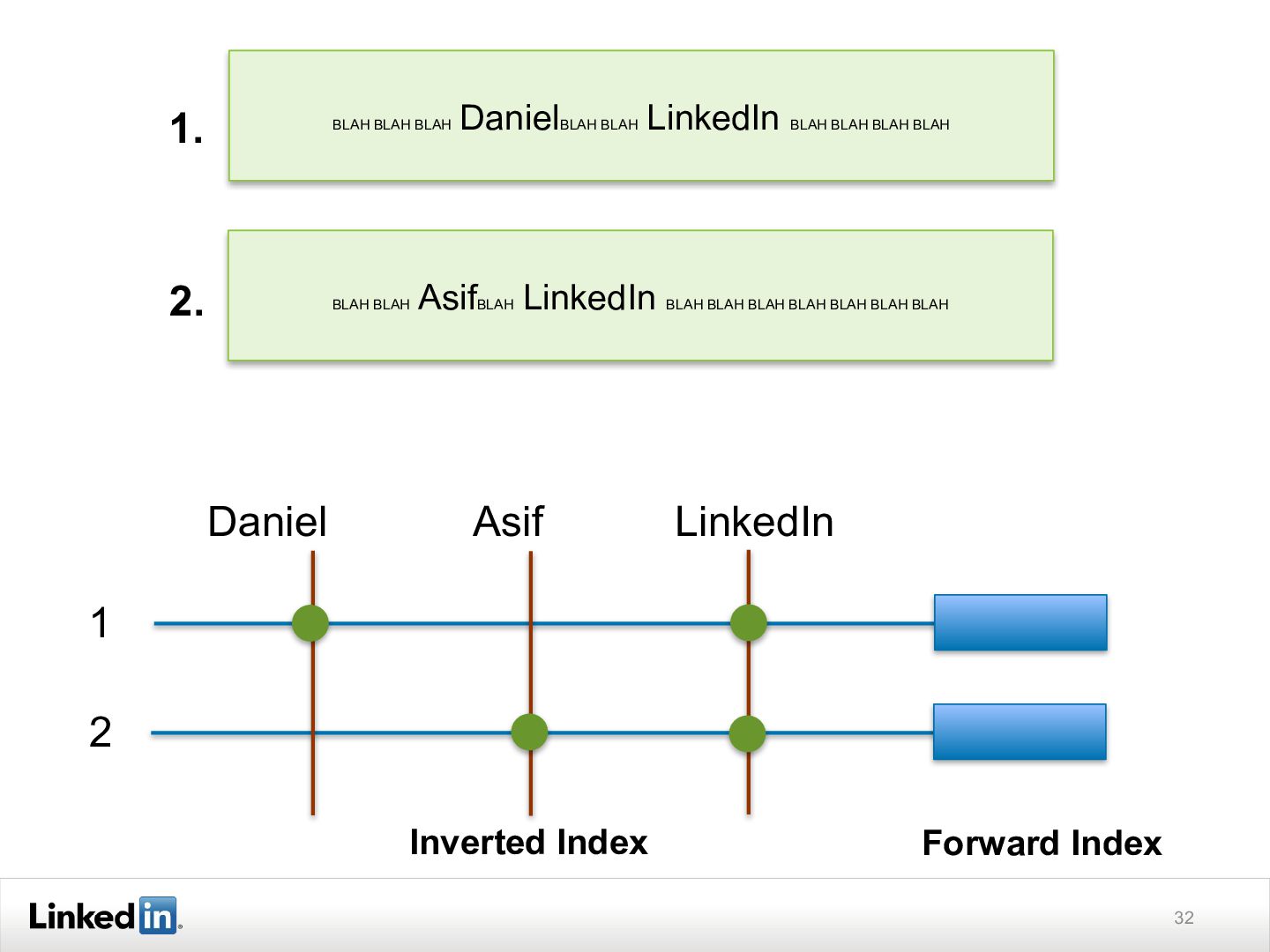{kind=link}
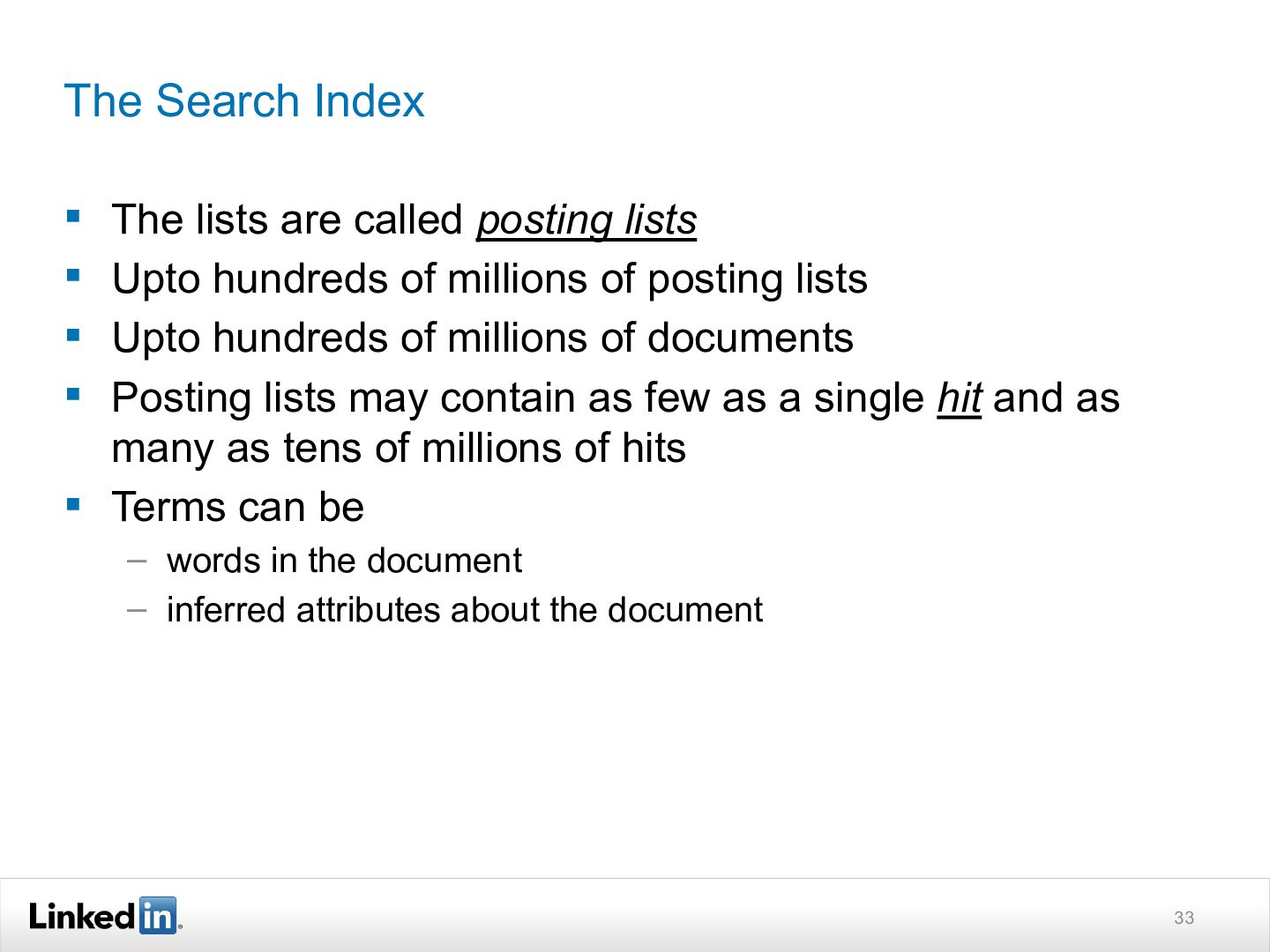{kind=link}
{kind=link}
{kind=link}
{kind=link}
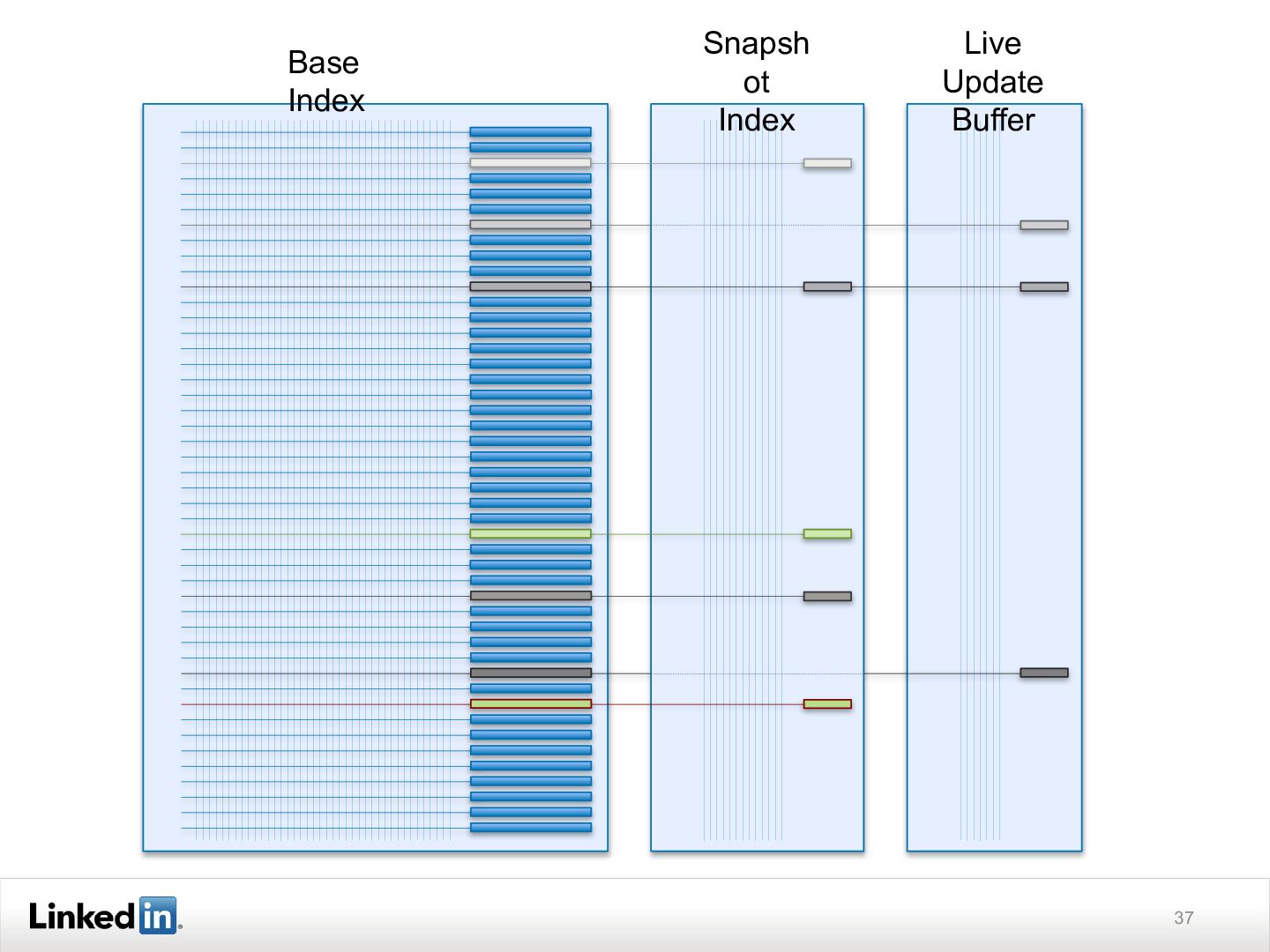{kind=link}
{kind=link}
{kind=link}
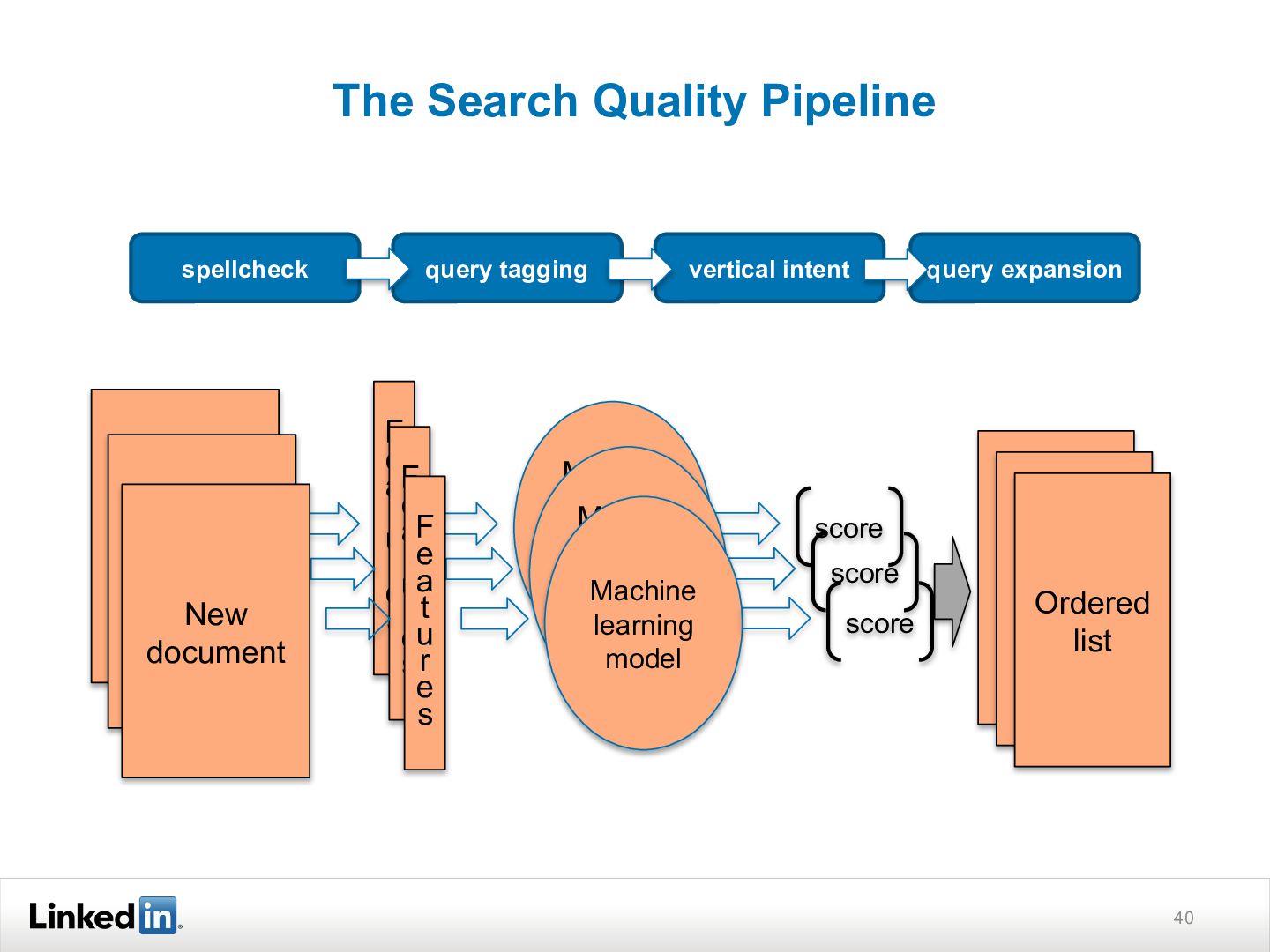{kind=link}
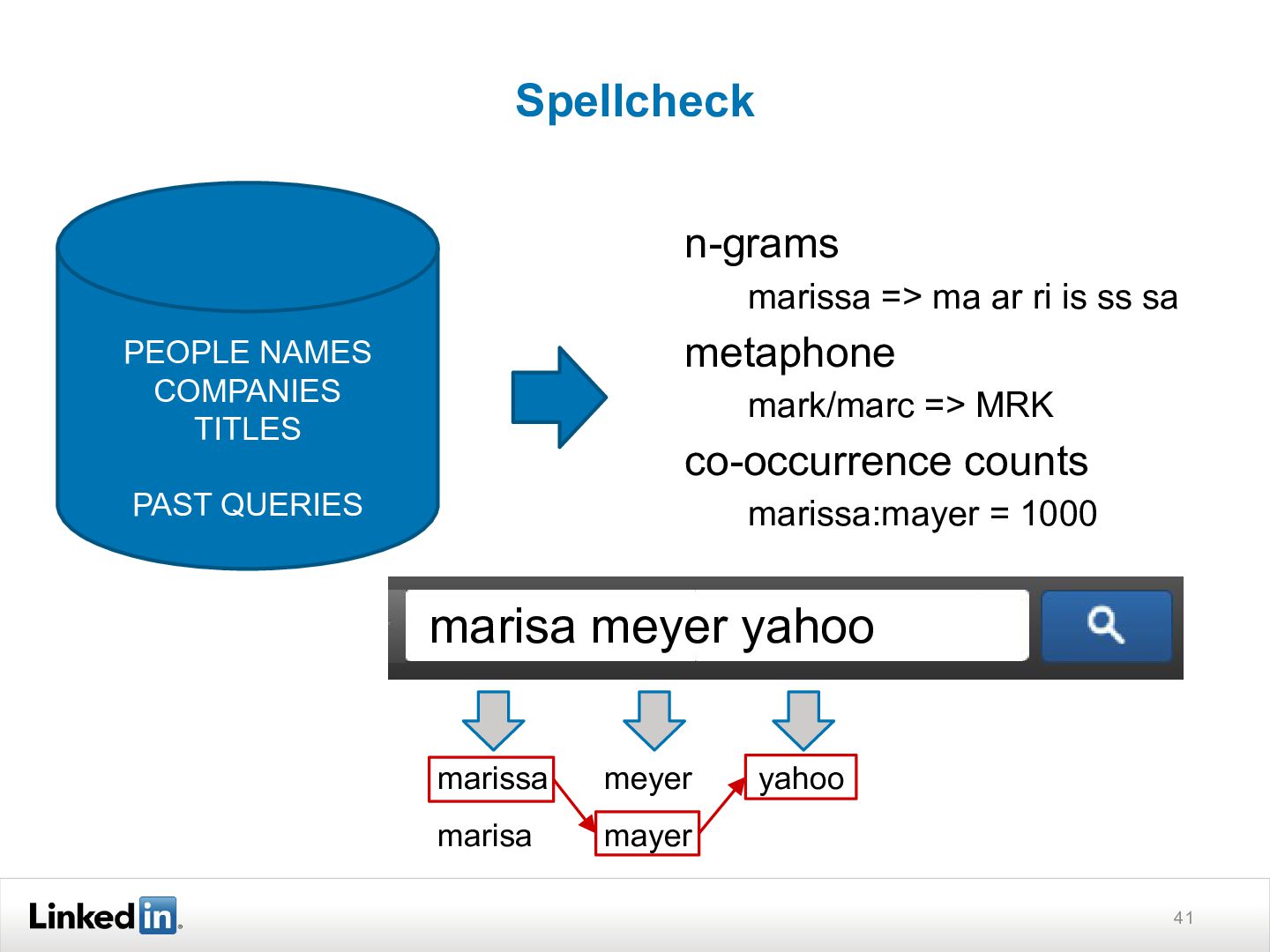{kind=link}
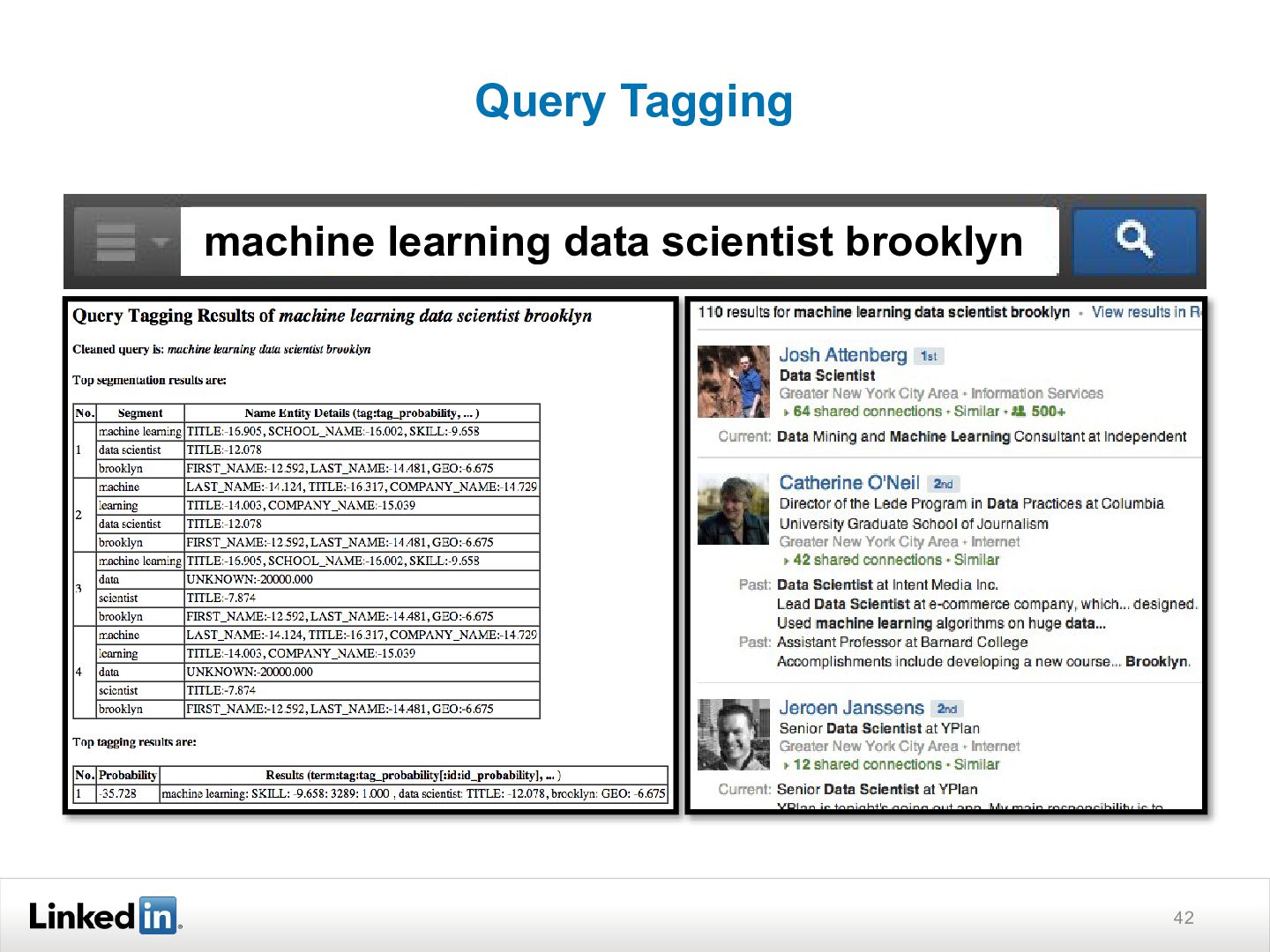{kind=link}
![43 Vertical Intent: Results Blending [company] [employees] [jobs] [name search]](https://files.speakerdeck.com/presentations/42d47df60968420795297b6c9a574ea2/slide_42.jpg){kind=link}
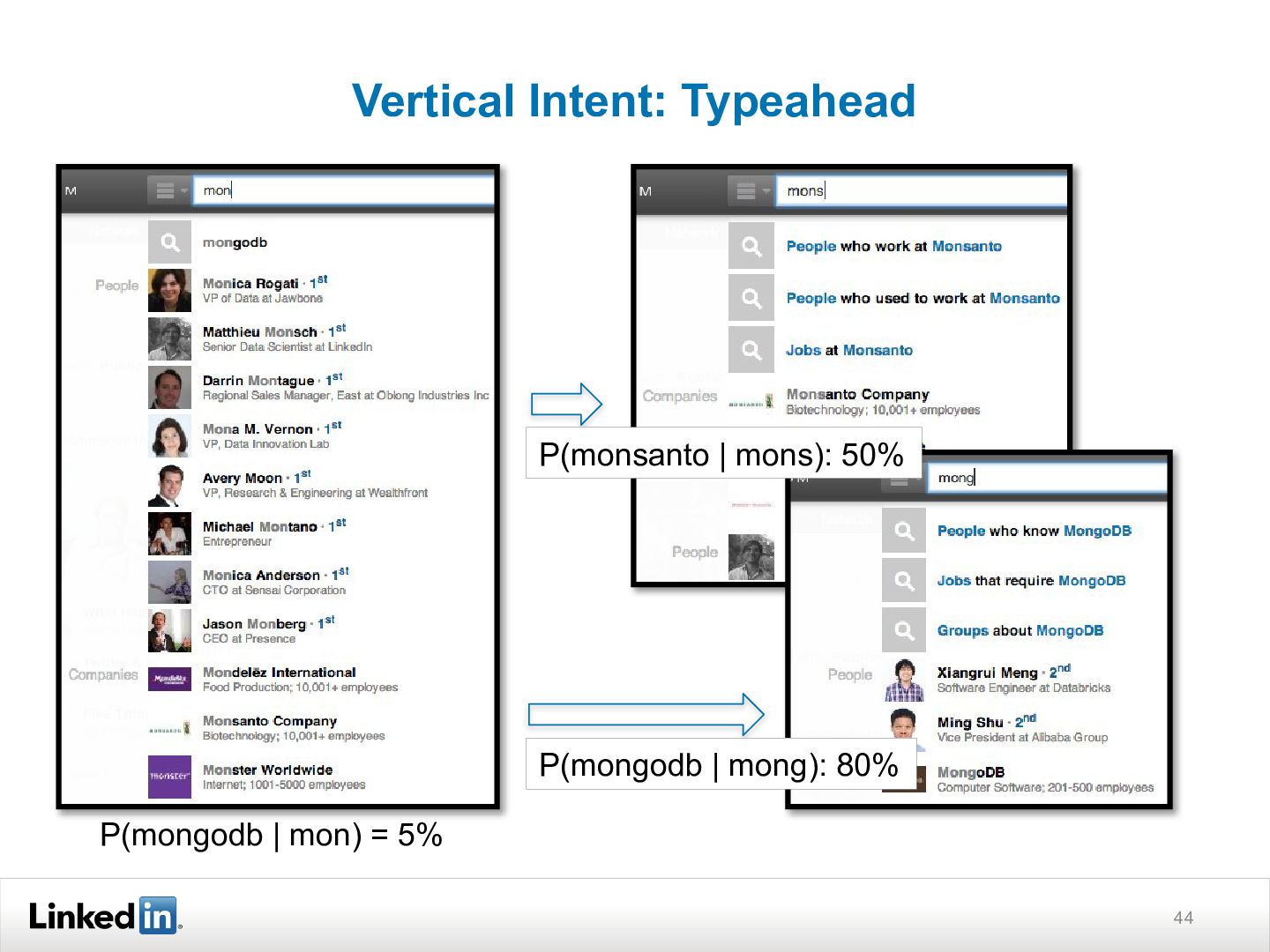{kind=link}
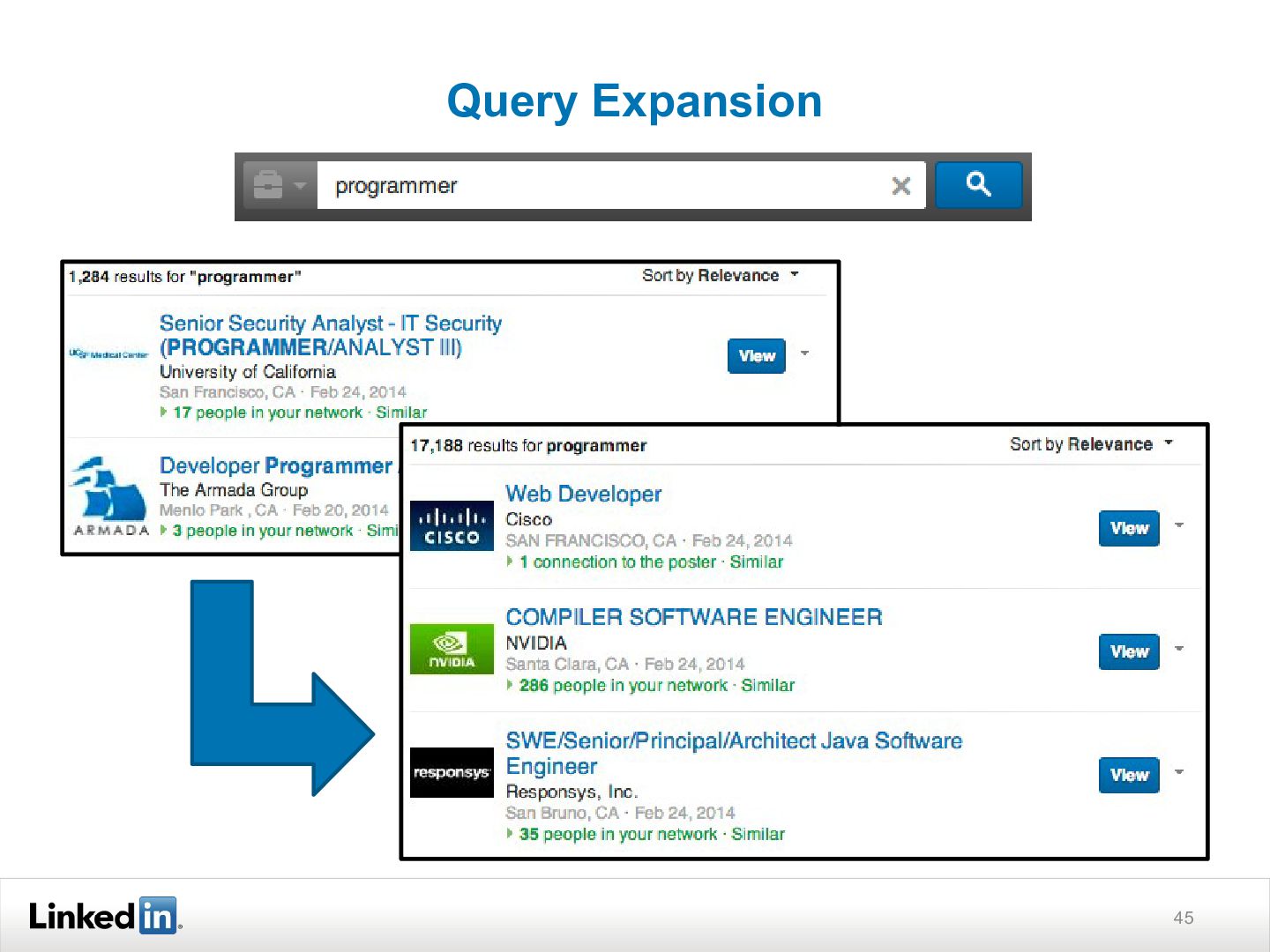{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
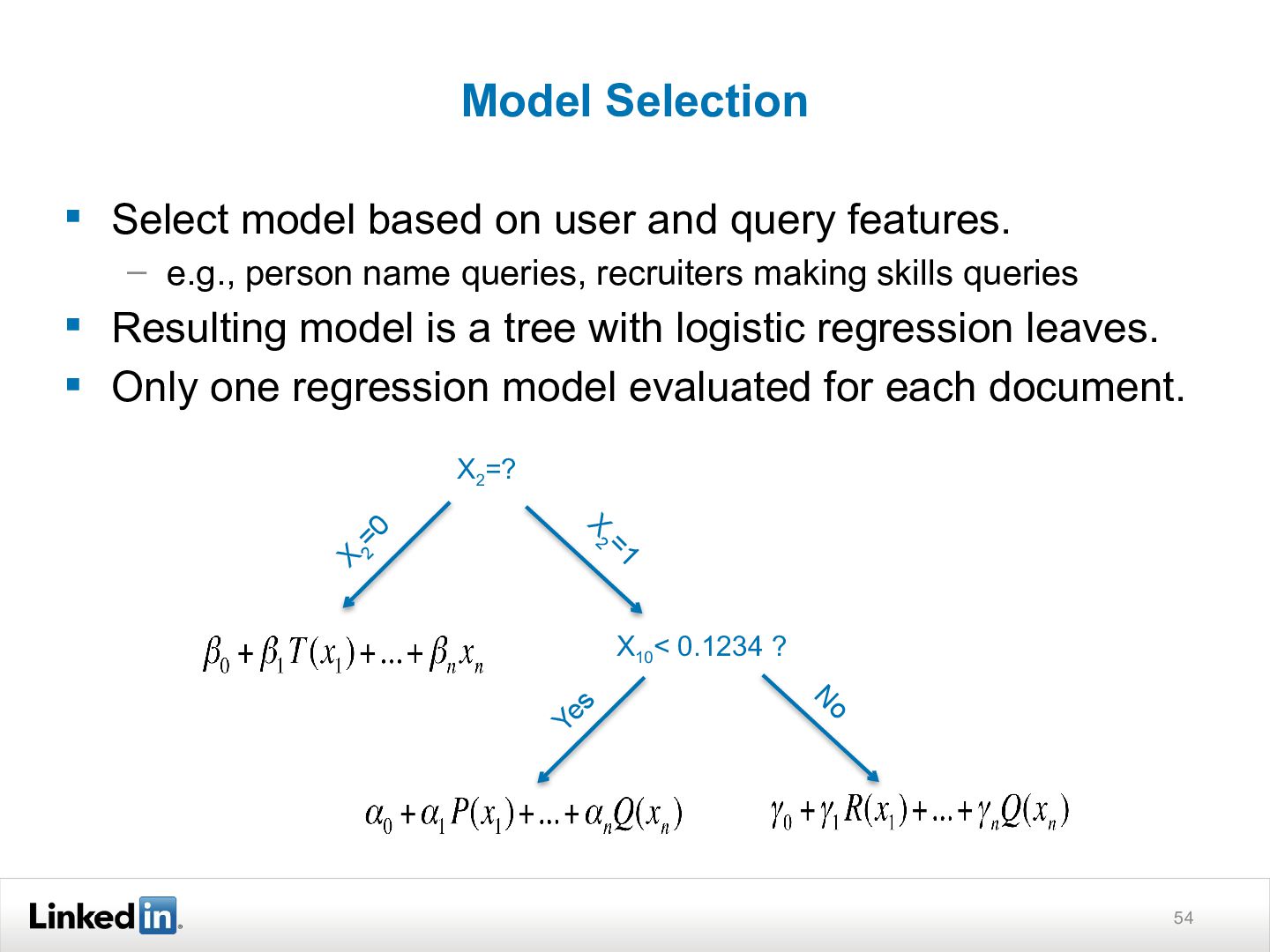{kind=link}
{kind=link}
![56 Asif Makhani Daniel Tunkelang [email protected] [email protected] https://linkedin.com/in/asifmakhani https://linkedin.com/in/dtunkelang](https://files.speakerdeck.com/presentations/42d47df60968420795297b6c9a574ea2/slide_55.jpg){kind=link}