Optimization of probabilistic argumentation with Markov processes
Talk @International Joint Conference on Artificial Intelligence (IJCAI15) and Journées Francophones sur la Planification, la Décision et l'Apprentissage pour la conduite de systèmes (JFPDA15) the 29/09/15.
Beynier1, N. Maudet1, P. Weng2 and A. Hunter3 Tue., Sept. 29th (1) Sorbonne Universités, UPMC Univ Paris 6, UMR 7606, LIP6, F-75005, Paris, France (2) SYSU-CMU Joint Institute of Engineering, Guangzhou, China SYSU-CMU Shunde International Joint Research Institute, Shunde, China (3) Department of Computer Science, University College London, Gower Street, London WC1E 6BT, UK
executable logic to improve expressivity ∙ New class of problems: Argumentation Problem with Probabilistic Strategies (APS) (Hunter, 2014) ∙ Purpose of this work: optimize the sequence of arguments of one agent 1
executable logic to improve expressivity ∙ New class of problems: Argumentation Problem with Probabilistic Strategies (APS) (Hunter, 2014) ∙ Purpose of this work: optimize the sequence of arguments of one agent There will be abuse of the word predicate! 1
agents ∙ Rules to fire in order to attack arguments of the opponent and revise knowledge Let us define a debate problem with: ∙ A, the set or arguments 3
agents ∙ Rules to fire in order to attack arguments of the opponent and revise knowledge Let us define a debate problem with: ∙ A, the set or arguments ∙ E, the set of attacks 3
agents ∙ Rules to fire in order to attack arguments of the opponent and revise knowledge Let us define a debate problem with: ∙ A, the set or arguments ∙ E, the set of attacks ∙ P = 2A × 2E, the public space gathering voiced arguments 3
agents ∙ Rules to fire in order to attack arguments of the opponent and revise knowledge Let us define a debate problem with: ∙ A, the set or arguments ∙ E, the set of attacks ∙ P = 2A × 2E, the public space gathering voiced arguments ∙ Two agents: agent 1 and agent 2 3
e(x, y) if x attacks y ∙ Args. in public (resp. private) space: a(x) (resp. hi(x)) ∙ Goals: ∧ k g(xk) (resp. g(¬xk)) if xk is (resp. is not) accepted in the public space (Dung, 1995) 4
e(x, y) if x attacks y ∙ Args. in public (resp. private) space: a(x) (resp. hi(x)) ∙ Goals: ∧ k g(xk) (resp. g(¬xk)) if xk is (resp. is not) accepted in the public space (Dung, 1995) ∙ Rules: prem ⇒ Pr(Acts) 4
e(x, y) if x attacks y ∙ Args. in public (resp. private) space: a(x) (resp. hi(x)) ∙ Goals: ∧ k g(xk) (resp. g(¬xk)) if xk is (resp. is not) accepted in the public space (Dung, 1995) ∙ Rules: prem ⇒ Pr(Acts) ∙ Premises: conjunctions of e(, ), a(), hi() 4
e(x, y) if x attacks y ∙ Args. in public (resp. private) space: a(x) (resp. hi(x)) ∙ Goals: ∧ k g(xk) (resp. g(¬xk)) if xk is (resp. is not) accepted in the public space (Dung, 1995) ∙ Rules: prem ⇒ Pr(Acts) ∙ Premises: conjunctions of e(, ), a(), hi() ∙ Acts: conjunctions of ⊞, ⊟ on e(, ), a() and ⊕, ⊖ on hi() 4
point of view of agent 1) by ⟨A, E, G, S1, g1, g2, S2, P, R1, R2⟩: ∙ A, E, P as specified above ∙ G, the set of all possible goals ∙ Si , the set of private states for agent i ∙ gi ∈ G, the given goal for agent i ∙ Ri , the set of rules for agent i 5
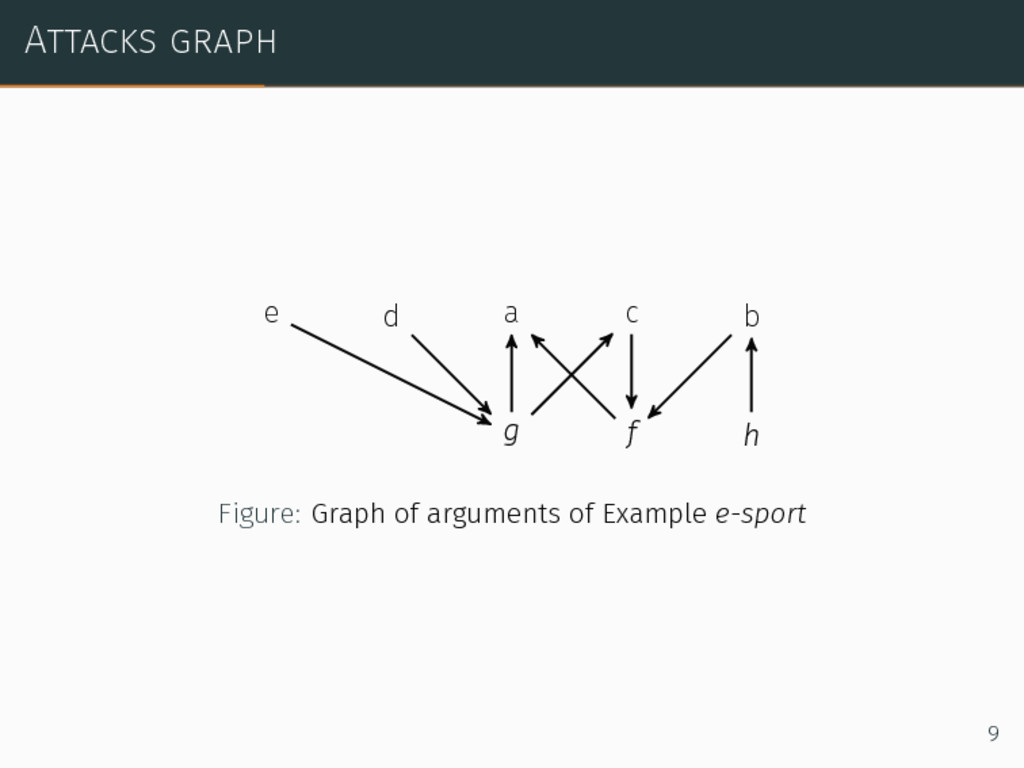
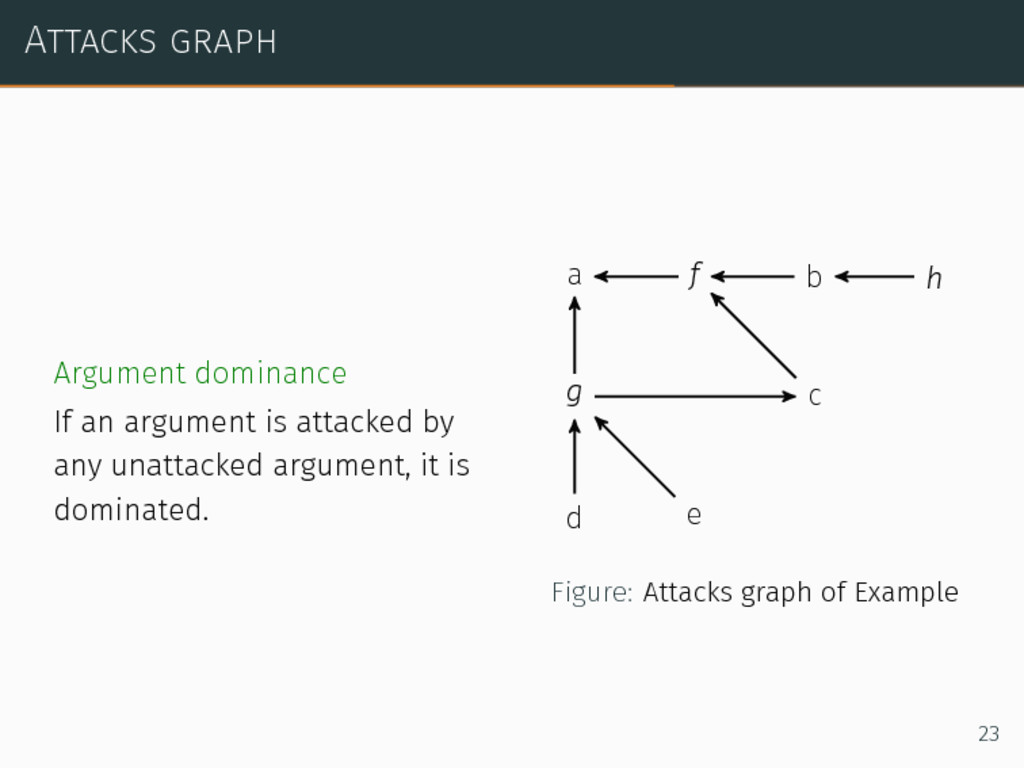
sport b E-sport requires focusing, precision and generates tiredness c Not all sports are physical d Sports not referenced by IOC exist e Chess is a sport f E-sport is not a physical activity g E-sport is not referenced by IOC h Working requires focusing and generates tiredness but is not a sport 6
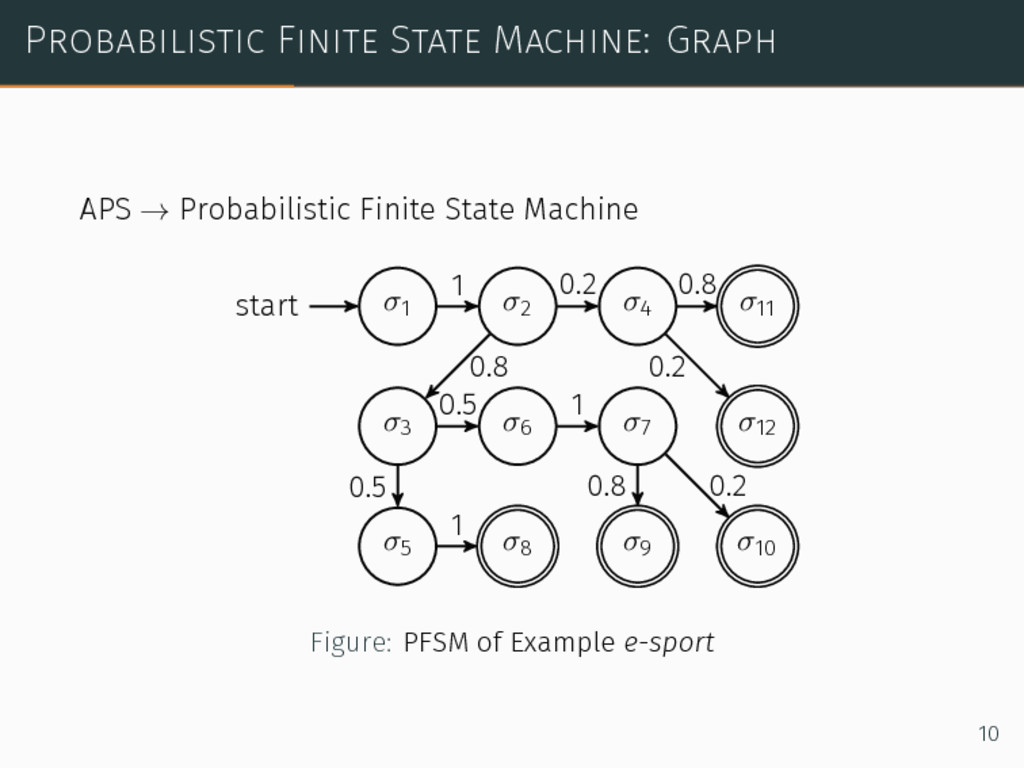
for agent 1, we could optimize the PFSM but: 1. depends of the initial state 2. requires knowledge of the private state of the opponent Using Markov models, we can relax assumptions 1 and 2. Moreover, the APS formalization can be modified in order to comply with the Markov assumption. 11
is characterized by a tuple ⟨S, A, T, R⟩: ∙ S, a set of states, ∙ A, a set of actions, ∙ T : S × A → Pr(S), a transition function, ∙ R : S × A → R, a reward function. 12
is characterized by a tuple ⟨S, A, T, R, O, Q⟩: ∙ S, a set of states, ∙ A, a set of actions, ∙ T : S × A → Pr(S), a transition function, ∙ R : S × A → R, a reward function, ∙ O, an observation set, ∙ Q : S × A → Pr(O), an observation function. 13
al., 2010) is characterized by a tuple ⟨Sv, Sh, A, T, R, Ov, Oh, Q⟩: ∙ Sv, Sh , a visible and hidden parts of the state, ∙ A, a set of actions, ∙ T : Sv × A × Sh → Pr(Sv × Sh), a transition function, ∙ R : Sv × A × Sh → R, a reward function, ∙ Ov = Sv, an observation set on the visible part of the state, ∙ Oh , an observation set on the hidden part of the state, ∙ Q : Sv × A × Sh → Pr(Ov × Oh), an observation function. 14
view of agent 1 can be transformed to a MOMDP: ∙ Sv = S1 × P, Sh = S2 ∙ A = {prem(r) ⇒ m|r ∈ R1 and m ∈ acts(r)} ∙ Ov = Sv and Oh = ∅ ∙ Q(⟨sv, sh⟩, a, ⟨sv⟩) = 1, otherwise 0 ∙ T, see after 16
be the set of rules of Ri that can be fired in state s. The application set Fr(m, s) is the set of predicates resulting from the application of act m of a rule r on s. If r cannot be fired in s, Fr(m, s) = s. ∙ s, a state and r : p ⇒ m, an action s.t. r ∈ A ∙ s′ = Fr(m, s) ∙ r′ ∈ Cs′ (R2) s.t. r′ : p′ ⇒ [π1/m1, . . . , πn/mn] ∙ s′′ i = Fr′ (mi, s′) ∙ T(s, r, s′′ i ) = πi 17
(Araya-López et al., 2010), IP of POMDP on MOMDP (exact method) ∙ MO-SARSOP (Ong et al., 2010), SARSOP of POMDP on MOMDP (approximate method albeit very efficient) Two kinds of optimizations: with or without dependencies on the initial state 21
the initial state changes. 1. For each predicate that is never modified but used as premises: 1.1 Remove all the rules that are not compatible with the value of this predicate in the initial state. 1.2 For all remaining rules, remove the predicate from the premises. 24
the initial state changes. 1. For each predicate that is never modified but used as premises: 1.1 Remove all the rules that are not compatible with the value of this predicate in the initial state. 1.2 For all remaining rules, remove the predicate from the premises. 2. For each remaining action of agent 1, track the rules of agent 2 compatible with the application of this action. If a rule of agent 2 is not compatible with any application of an action of agent 1, remove it. 24
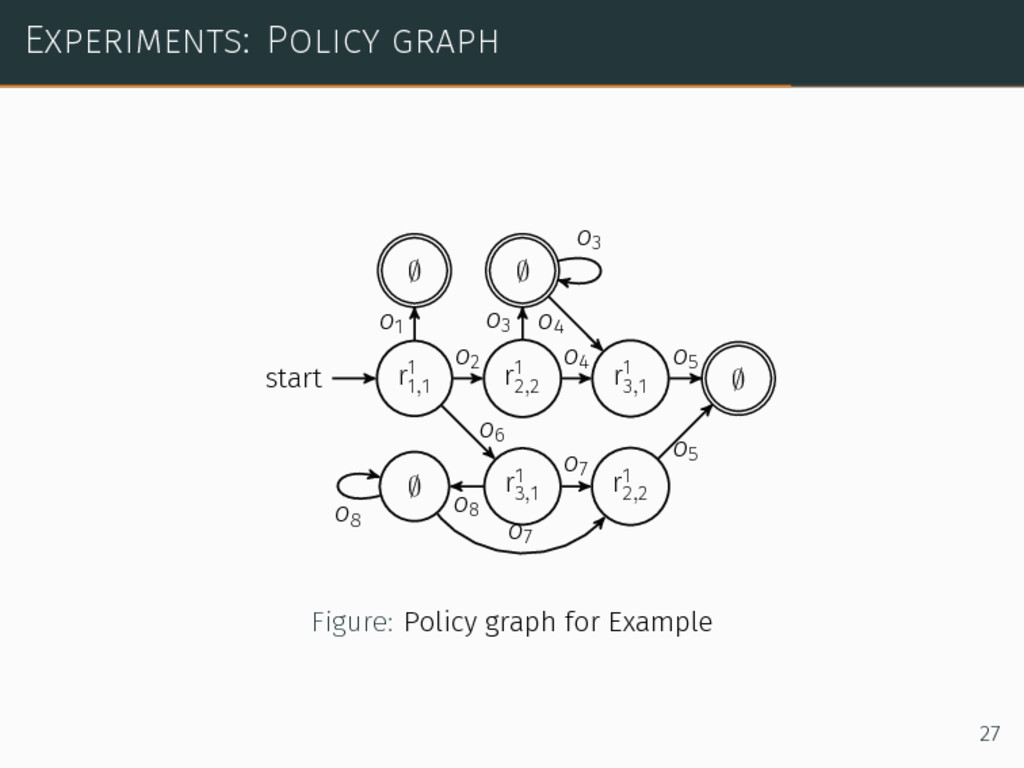
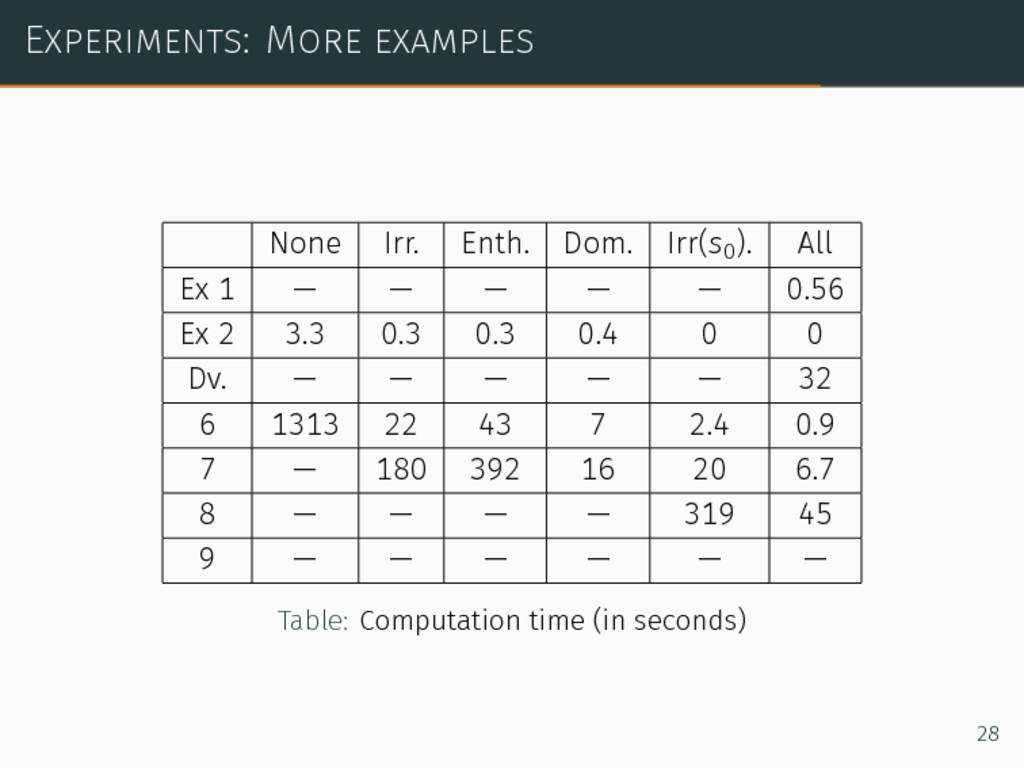
∙ MO-IP, which did not finish after tens of hours ∙ MO-SARSOP without optimizations, idem ∙ MO-SARSOP with optimizations, 4sec for the optimal solution 26
complex debate problems (APS) 2. A method to transform those problems to a MOMDP 3. Several optimizations that can be used outside of the context of MOMDP 4. A method to optimize actions of an agent in an APS 30
F. (2010). A closer look at MOMDPs. In 22nd IEEE International Conference on Tools with Artificial Intelligence (ICTAI). Cayrol, C. and Lagasquie-Schiex, M.-C. (2005). Graduality in argumentation. Journal of Artificial Intelligence Research (JAIR), 23:245–297. Dung, P. M. (1995). On the acceptability of arguments and its fundamental role in nonmonotonic reasoning, logic programming and n-person games. Artificial Intelligence, 77(2):321–358. 33
Solving Hidden-Semi-Markov-Mode Markov Decision Problems. In Straccia, U. and Calì, A., editors, Scalable Uncertainty Management, volume 8720 of Lecture Notes in Computer Science, pages 176–189. Springer International Publishing. Hunter, A. (2014). Probabilistic strategies in dialogical argumentation. In International Conference on Scalable Uncertainty Management (SUM’14) LNCS volume 8720. Ong, S. C., Png, S. W., Hsu, D., and Lee, W. S. (2010). Planning under uncertainty for robotic tasks with mixed observability. In The International Journal of Robotics Research. 34
stochastic dynamic programming. John Wiley & Sons. Silver, D. and Veness, J. (2010). Monte-Carlo planning in large POMDPs. In Proceedings of the 24th Conference on Neural Information Processing Systems (NIPS), pages 2164–2172. 35
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}