本資料はSatAI.challengeのサーベイメンバーと共に作成したものです。
SatAI.challengeは、リモートセンシング技術にAIを適用した論文の調査や、より俯瞰した技術トレンドの調査や国際学会のメタサーベイを行う研究グループです。speakerdeckではSatAI.challenge内での勉強会で使用した資料をWeb上で共有しています。
https://x.com/sataichallenge
紹介する論文は 「EarthMarker: A Visual Prompting Multimodal Large Language Model for Remote Sensing」 です。本研究では、Visual Prompting が可能な EarthMarker というマルチモーダル大規模言語モデル(MLLM)を構築し、image-level、region-level、point-level の各レベルで大規模言語モデルによる衛星画像の自動判読を実現しました。その結果、複数の下流タスクにおいて、従来の MLLM を大幅に上回る性能を達成しました。さらに、Visual Prompting MLLM を構築するためのフレームワークと、新しいデータセットも同時に提案しています。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
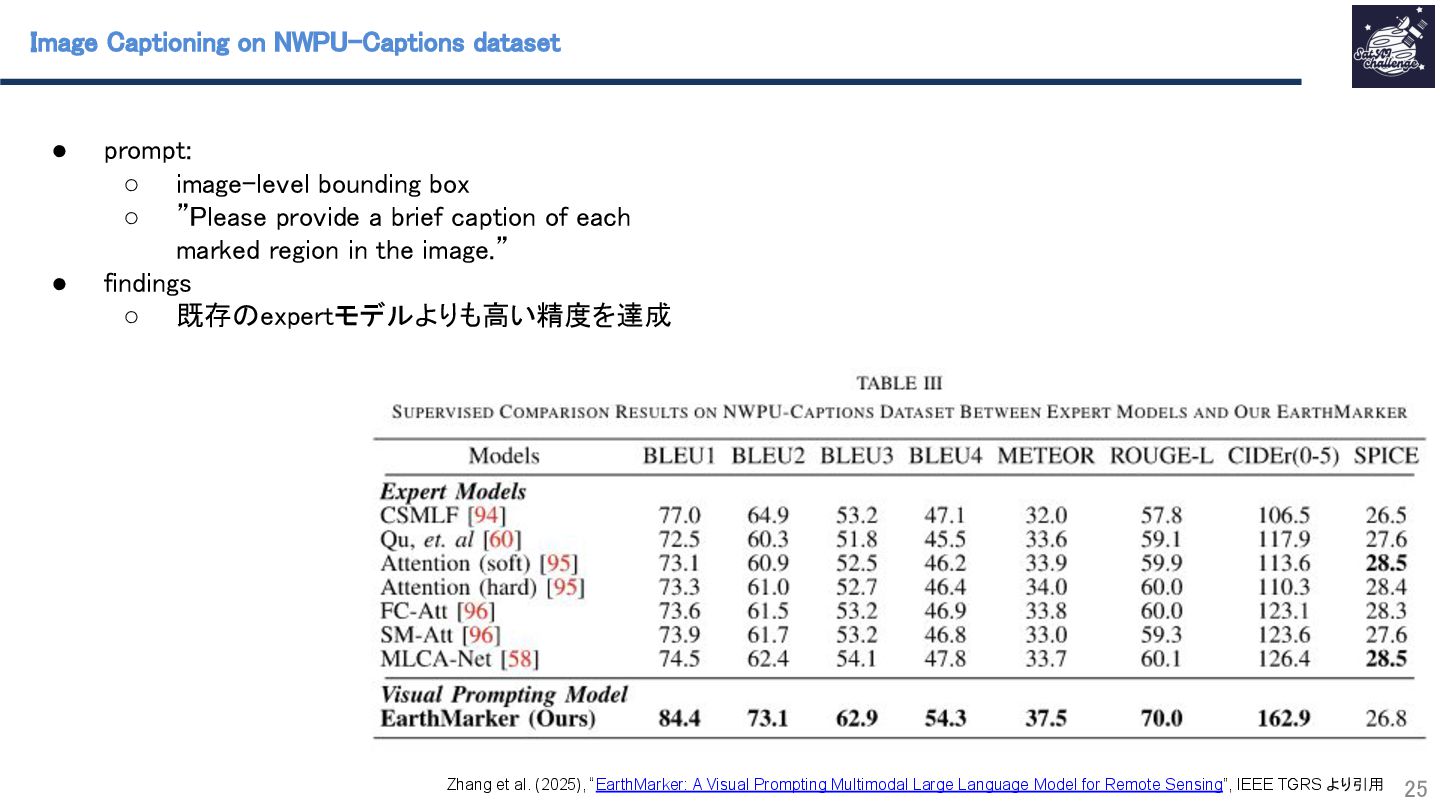{kind=link}
{kind=link}
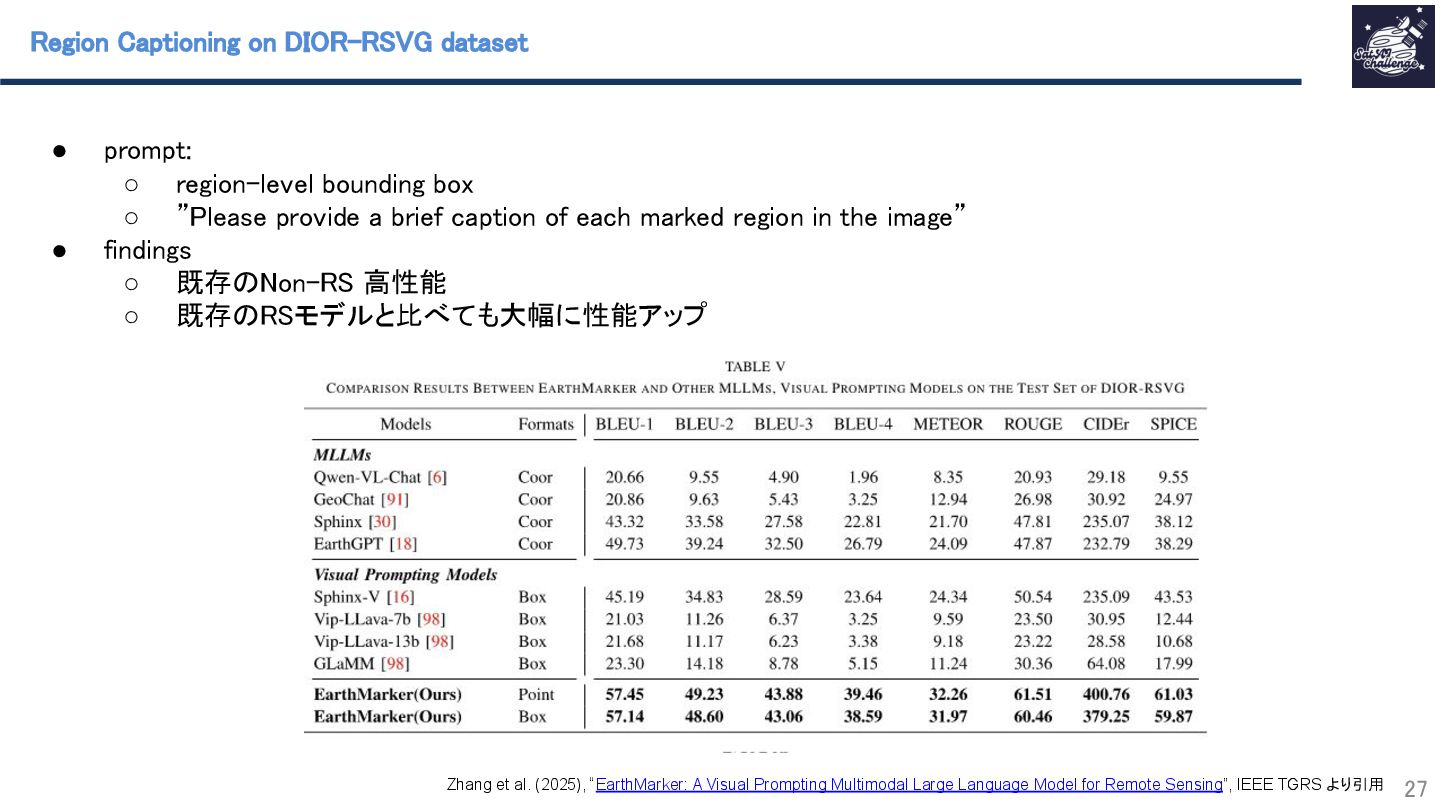{kind=link}
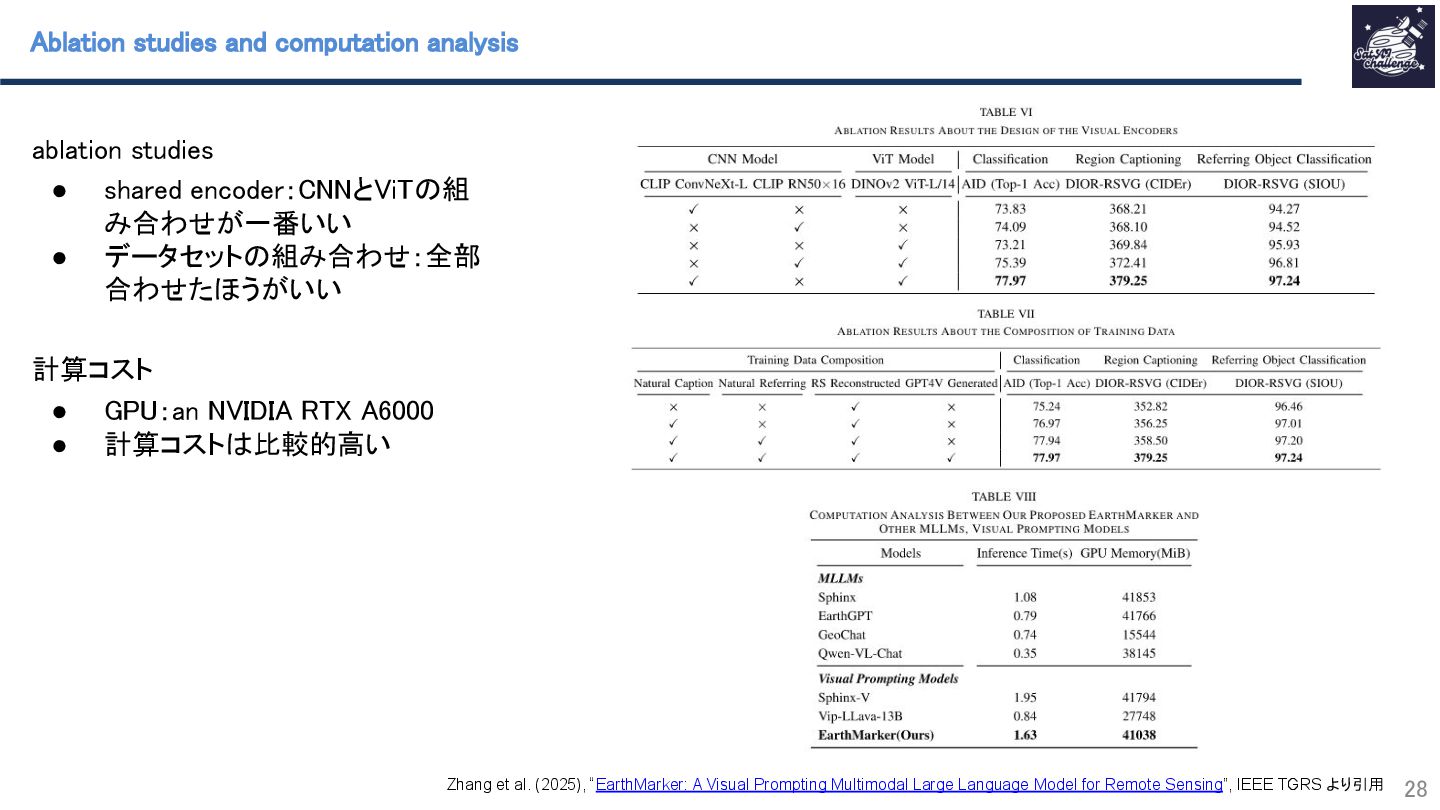{kind=link}
{kind=link}
{kind=link}
{kind=link}
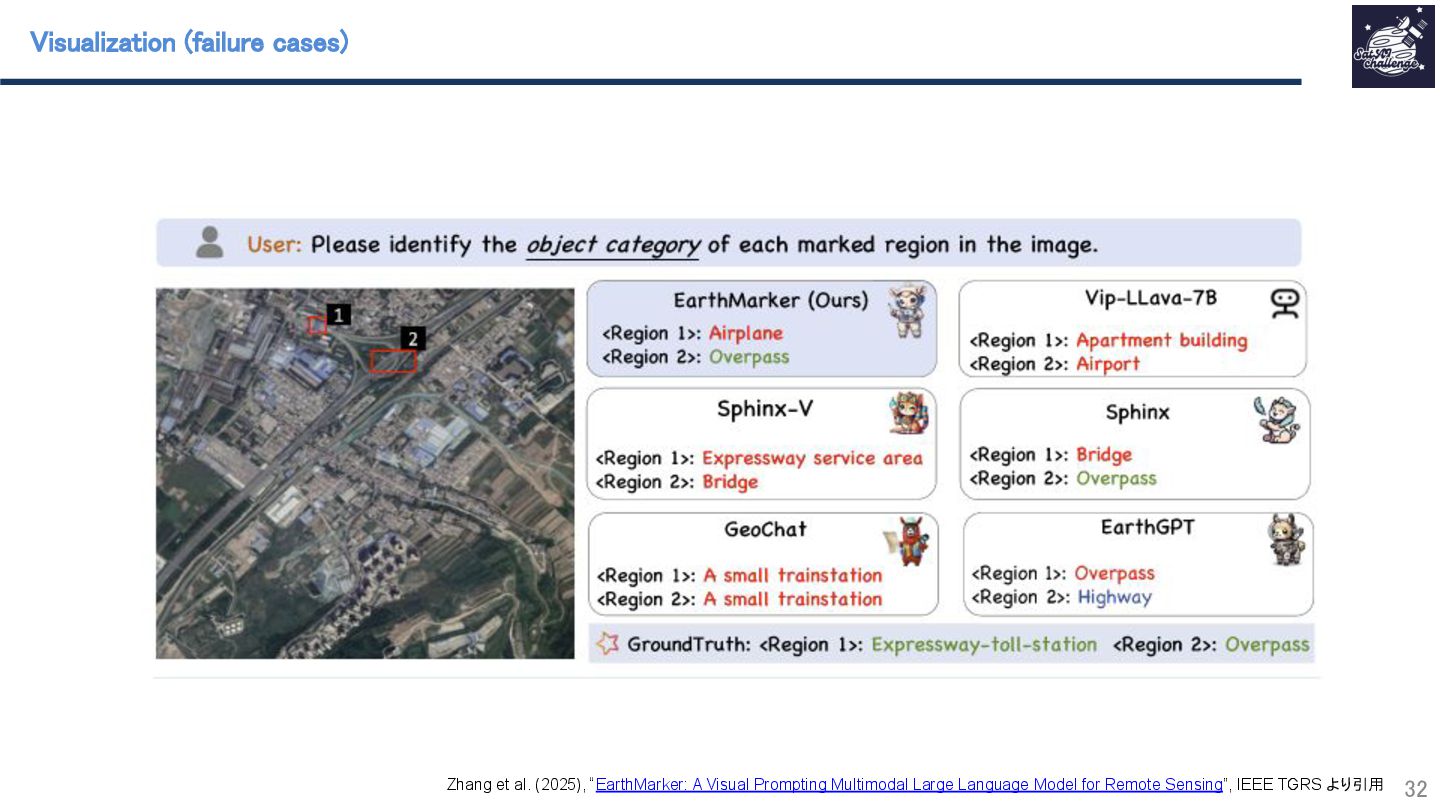{kind=link}
{kind=link}
{kind=link}