at consecutive timesteps Markov Decision Process (MDP) (< S, A, T, R >): S Set of states A Set of actions T Transition function over states (T : S × A → Pr(S)) R Reward function (R : S × A → R) Non-stationary ⇒ T and/or R E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 2 / 28
A Sail orientations T Position change R 1 at the goal, 0 otherwise Figure 1: sailboat problem [2] E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 3 / 28
unknown: Value or Policy iteration unusable Reinforcement learning ⇒ No convergence guarantee with non-stationarity E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 4 / 28
idea Non-stationary env. can be seen as a composition of stationary env. HM-MDP Stat. MDPs, linked by a transition function ⇒ M, C , ∀Mi ∈ M, Mi is an MDP S, A, Ti, Ri . M Set of modes C Transition function over modes (C : M → Pr(M)) The new mode is drawn after each decision. Figure 2: 3 modes, 4 states, 1 action HM-MDP [2]. E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 6 / 28
M = {Mi} Wind directions S Boat positions A Sail orientations Ti, ∀i Position change, according to the wind Ri, ∀i 1 at the goal, 0 otherwise C 0.5 same mode, 0.2 adjacent modes, 0.1 opposite mode Figure 3: sailboat problem [2] E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 7 / 28
a POMDP An HM-MDP can be reformulated into a partially observable MDP (POMDP). POMDP States cannot be directly observed. ⇒< S, A, O, T , R, Q > O Set of observations Q Observation function (Q : S × A → Pr(O)) In the derived POMDP, O is equivalent to the set of states (S) of the original HM-MDP. E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 8 / 28
Exact solving of the HM-MDP [2] More efficient than solving the derived POMDP How it works Inference of the current mode from the observation and the belief on the previous mode: µ (m ) ∝ m C(m, m )Tm(s, a, s )µ(m) (1) However, we cannot solve big instances this way. E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 9 / 28
[4] POMCP solves POMDPs It uses Monte-Carlo sampling to avoid the curse of dimensionality It uses a black-box simulator before acting in the real environment (online) It converges towards the optimal policy under some conditions It can solve instances unreachable with the other methods E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 10 / 28
[4] POMCP solves POMDPs It uses Monte-Carlo sampling to avoid the curse of dimensionality It uses a black-box simulator before acting in the real environment (online) It converges towards the optimal policy under some conditions It can solve instances unreachable with the other methods How it works 1 It maintains particles to approximate the belief function 2 It samples those particles to get the best action E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 10 / 28
do not change at each timestep. ⇒ hi: the environment stays hi timesteps in mi HS3MDP We add a duration function H = P(h |m, m , h) At each step: If hi > 0, hi+1 = hi − 1 and mi+1 = mi Else: 1 Draw mi+1 from C 2 Draw hi+1 from H Solving an HS3MDP is similar to solving HM-MDP. Indeed, they are equivalent but not as efficient. E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 12 / 28
with POMCP Original method: Lack of particles with big states space Adding more particles implies doing more simulations E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 13 / 28
with POMCP Original method: Lack of particles with big states space Adding more particles implies doing more simulations Our solution: Replace particles drawing by drawing a belief state from µ(m, h) E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 13 / 28
with POMCP Original method: Lack of particles with big states space Adding more particles implies doing more simulations Our solution: Replace particles drawing by drawing a belief state from µ(m, h) Modification of Equation (1): µ (m , h ) ∝ m,h µ(m, h)C(m, m )H(m, m , h, h )Tm(s, a, s ) (2) E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 13 / 28
with POMCP Original method: Lack of particles with big states space Adding more particles implies doing more simulations Our solution: Replace particles drawing by drawing a belief state from µ(m, h) Modification of Equation (1): µ (m , h ) ∝ m,h µ(m, h)C(m, m )H(m, m , h, h )Tm(s, a, s ) (2) Update the belief state with Equation (2) E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 13 / 28
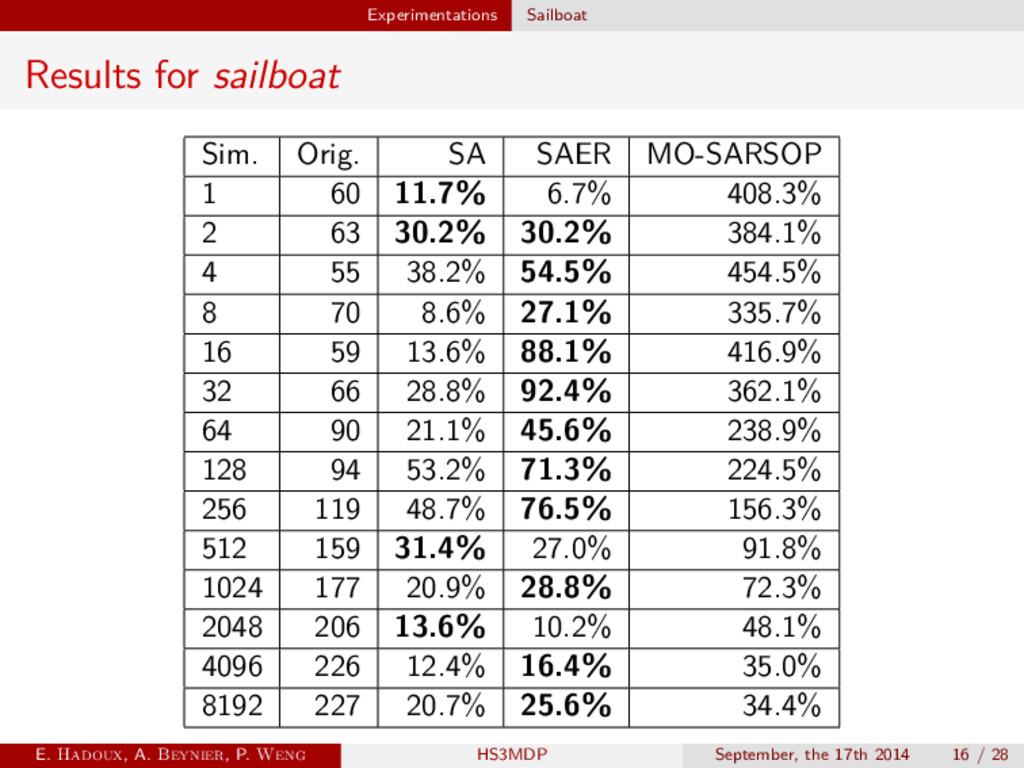
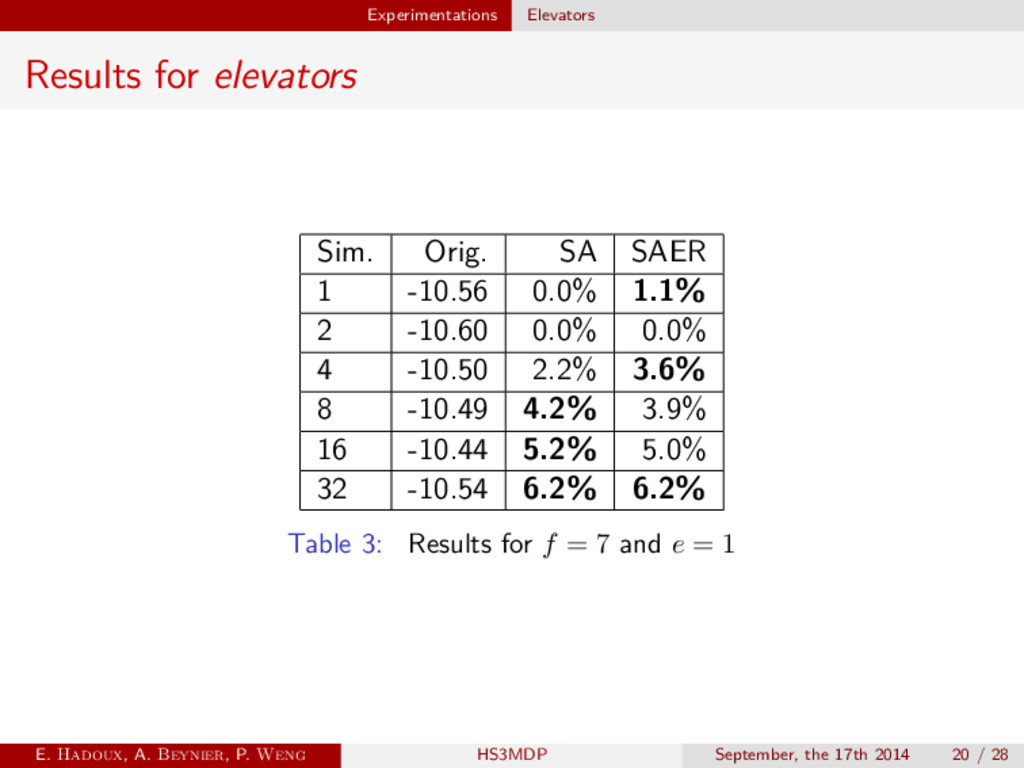
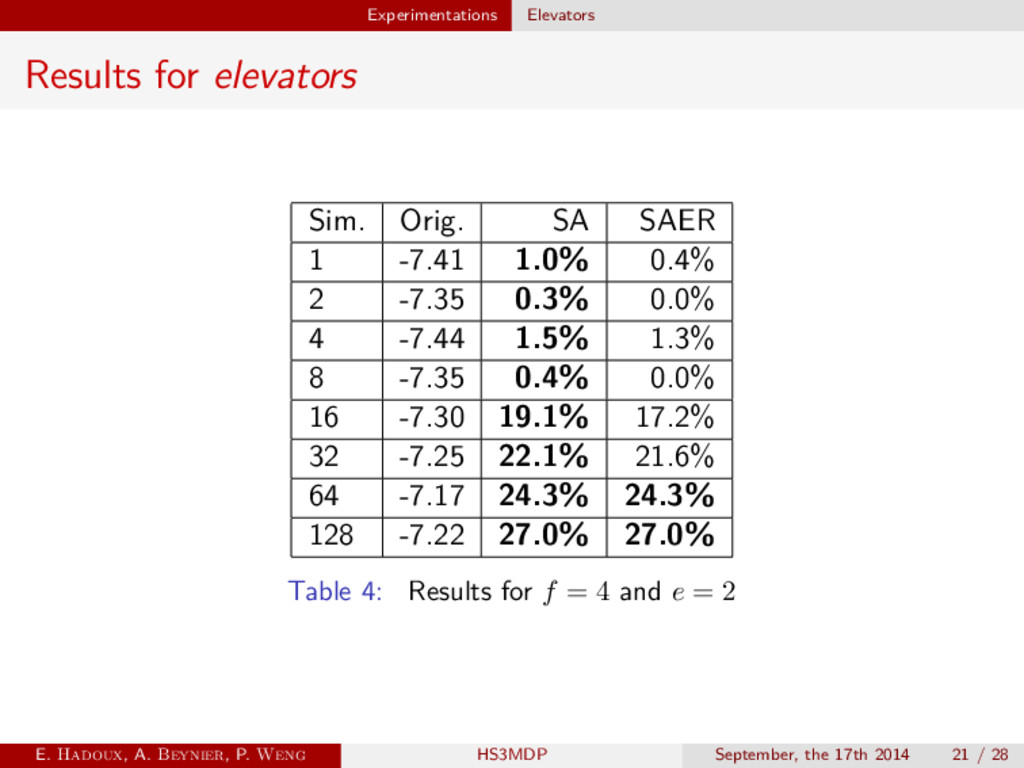
Structure adapted SAER Structure adapted and exact representation MO-SARSOP SARSOP on MO-MDP [3] Finite-Grid Best algorithm of Cassandra’s POMDP-Toolbox MO-IP [1] Incremental Pruning adapted for MO-MDP E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 15 / 28
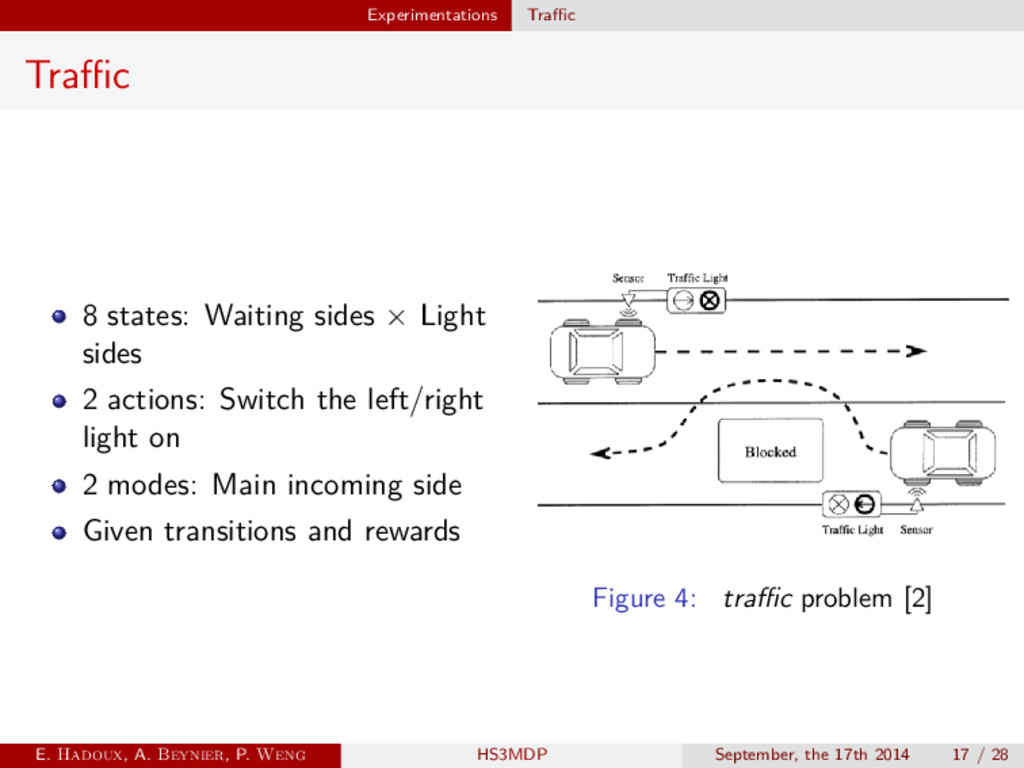
2 actions: Switch the left/right light on 2 modes: Main incoming side Given transitions and rewards Figure 4: traffic problem [2] E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 17 / 28
states 3e actions : Going up/down, open the doors 3 modes : Rush up/down/both Figure 5: Elevator control problem [2] E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 19 / 28
How to efficiently represent a subset of sequential decision-making problems in non-stationary environments (HM-MDP) A generalization of this model with sojourn time (HS3MDP) How to efficiently solve those problems on big instances by adapting POMCP E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 26 / 28
model → HSMM learning or context detection Adversarial case → bandits? Extend to multi-agents problems E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 27 / 28
and François Charpillet. A closer look at MOMDPs. In International Conference on Tools with Artificial Intelligence (ICTAI), 2010. Samuel Ping-Man Choi. Reinforcement learning in nonstationary environments. PhD thesis, Hong Kong University of Science and Technology, 2000. Sylvie C.W. Ong, Shao Wei Png, David Hsu, and Wee Sun Lee. POMDPs for robotic tasks with mixed observability. In Robotics: Science & Systems, 2009. David Silver and Joel Veness. Monte-Carlo planning in large POMDPs. In NIPS, pages 2164–2172, 2010. E. Hadoux, A. Beynier, P. Weng HS3MDP September, the 17th 2014 28 / 28
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Existing models and algorithms HM-MDP Hidden-Mode MDP (HM-MDP) [2] Key](https://files.speakerdeck.com/presentations/2fa1258b08ba40388781b9b228d1880b/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}