engineer + master research in statistics / machine learning. • Started at Drivy (car rental / sharing platform). 2 years. Started the data team with 8 people. Reporting, fraud, pricing, tracking, AB tests, monitoring, alterings, ops, security. • Currently software engineer @ Maritime Affairs under the EIG program: search and rescue operations. Data analytics, open data, communication, accidentology. Spy on me: antoine-augusti.fr / @AntoineAugusti
of tasks with dependencies (do B if A has been done, C after and D) • Executing workflows under a defined set of resources and across multiple machines • Monitoring workflows, alert on task executions anomalies, respect SLAs • Versioning workflows • Testing workflows • Rich web UI interface to manage workflows
Bash scripts and I know crontab -e. • Do you know when your CRON jobs fail? • How do you handle long running tasks and dependencies? • Can you spot when your tasks become 3x slower? • Can you distribute tasks across your new containers? • Do you version control your CRON tasks? • Can you visualize what's currently running? What's queued? • Do you have reusable components you can use across workflows?
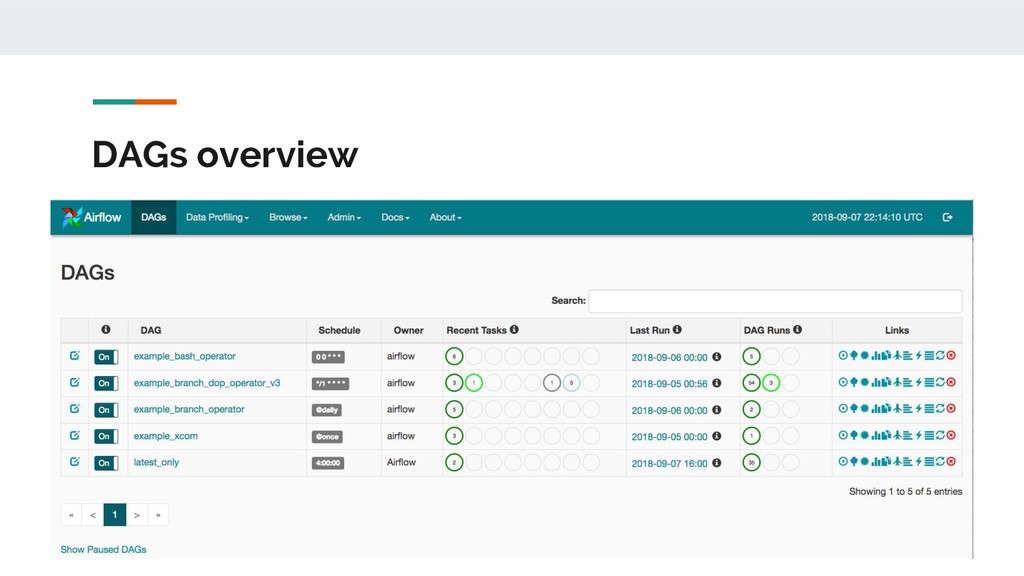
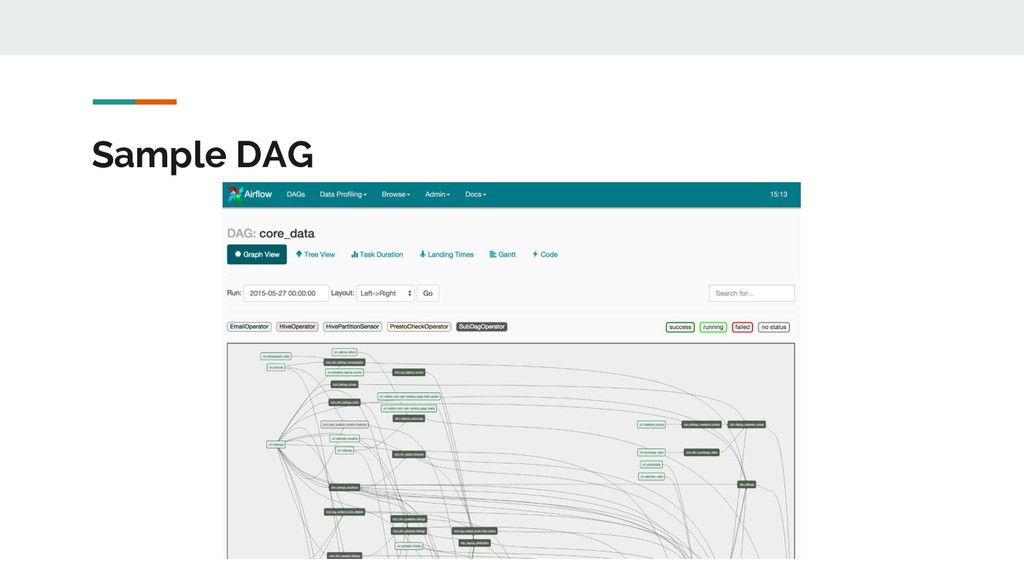
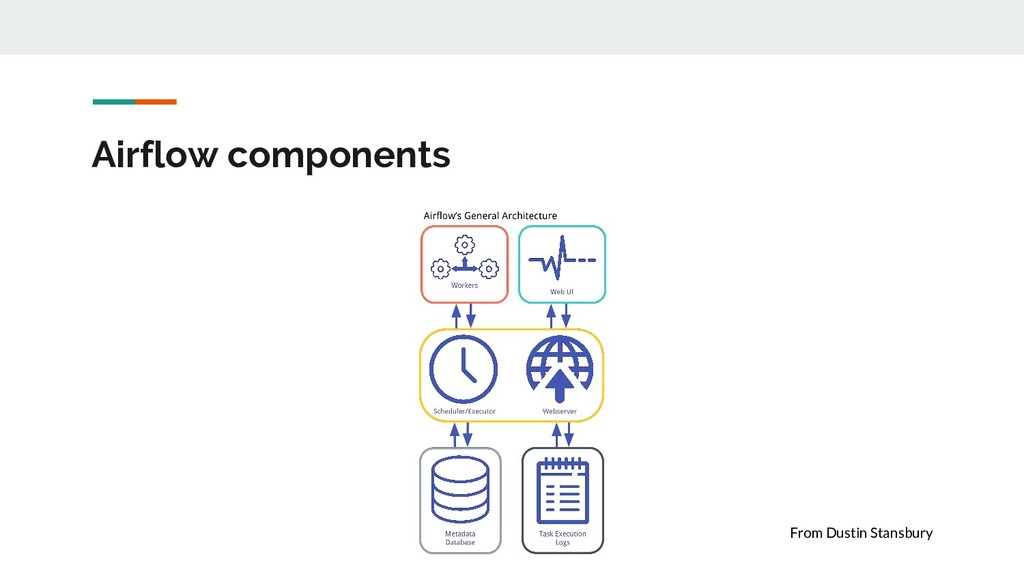
Airbnb. Joined the Apache Foundation in March 2016. Airflow is a platform to programmatically author, schedule and monitor workflows. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed. When workflows are defined as Python code, they become more maintainable, versionable, testable, and collaborative.
data streaming solution: data does not move from one task to another • A message queue: it does not replace RabbitMQ, Redis and is not suited for a large number of very short running tasks • Tied to a language. Workflows are defined in Python but Airflow is language and technology agnostic • Designed to have a very low number of long and complex tasks. You should embrace the power of DAGs and of small and reproducible tasks
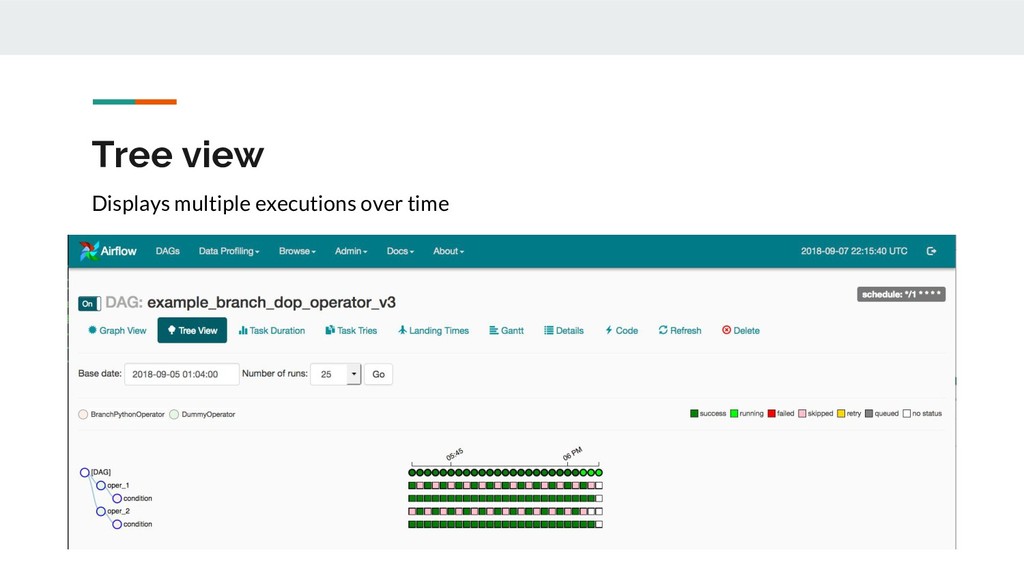
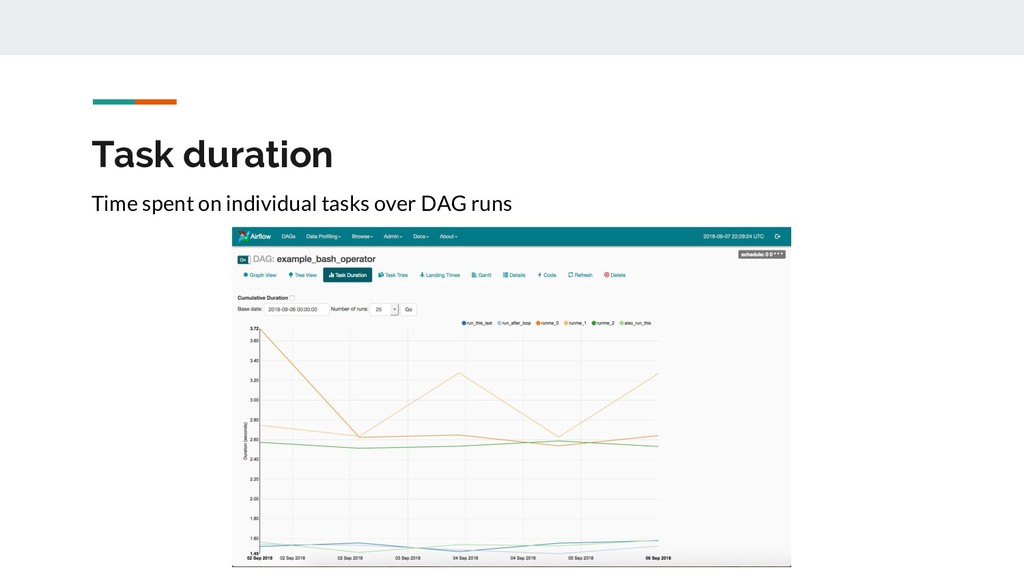
A sequence of tasks and how often they should run • Task: individual work units of a DAG. Tasks have dependencies between them. • Operators: operators define how tasks should be done. Examples: Bash command, SQL script, send an email, poll an API • DAG run: an executed instance of a DAG. When a DAG is triggered, Airflow orchestrates the execution of operators while respecting dependencies and allocated resources • Task instance: an executed operator inside a DAG run.
the DAG structure as code • DAGs don't do any data processing as such: only the actual execution will do • Tasks defined here will run in different contexts, different workers, different points in time • Tasks don't communicate between each other • DAG definition files should execute very quickly (hundreds of milliseconds) because they will be evaluated often by the Airflow scheduler • DAGs are defined in Python and you should take advantage of it: custom operators, tests, modules, factories etc.
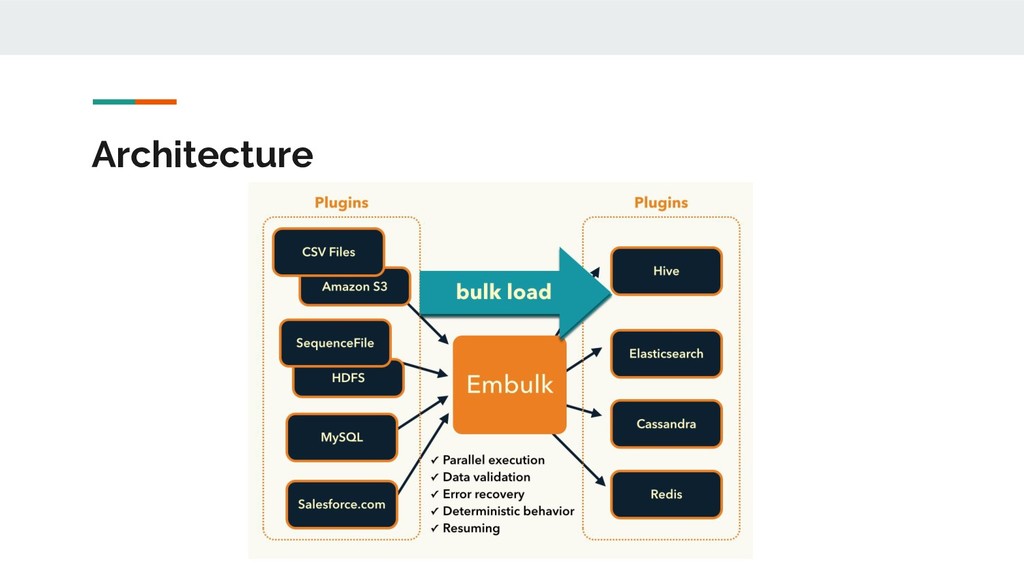
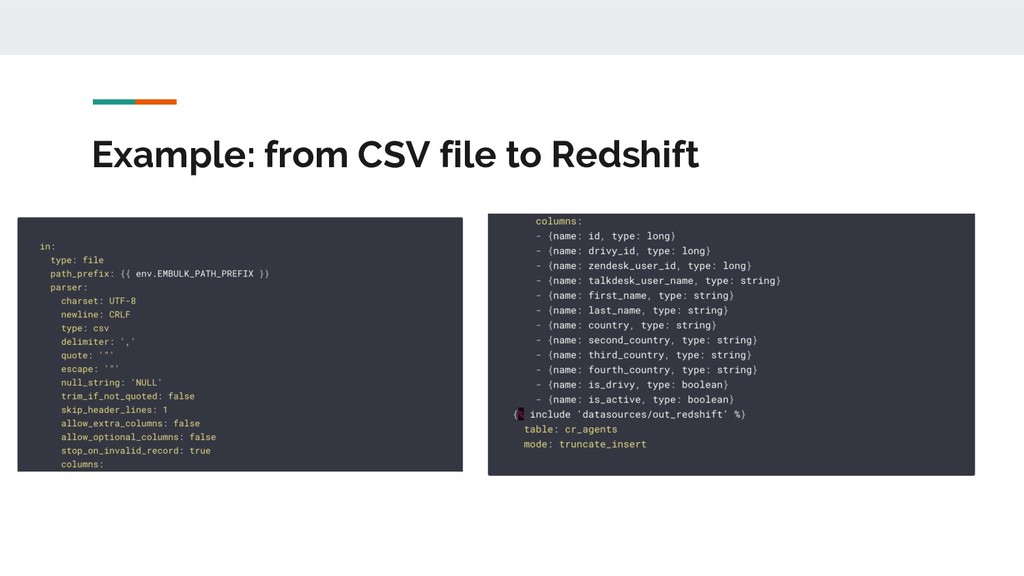
data transfer between various databases, storages, file formats, and cloud services. It can automatically guess file formats, distribute execution to deal with big datasets, offers transactions, can resume stuck tasks and is modular thanks to plugins. Embulk is written in JRuby and the configuration is specified in YAML. You then execute Embulk configuration files through the command line.
(MySQL, AWS S3, Jira, Mixpanel etc.) • Output: specify the destination of the data (BigQuery, Vertica, Redshift, CSV etc.) • File parser: to parse specific input files (JSON, Excel, Avro, XML etc.) • File decoder: to deal with compressed files • File formatter: to format specific output files (similar to parsers) • Filter: to keep only some rows from the input • File encoder: to compress output file (similar to decoders) • Executor: where do Embulk task are executed (locally or Hadoop)
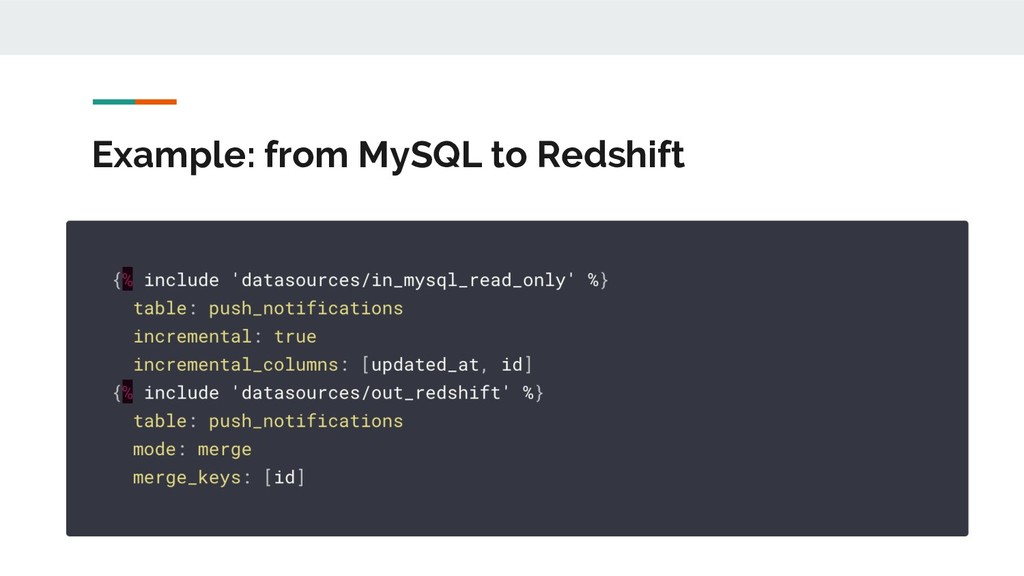
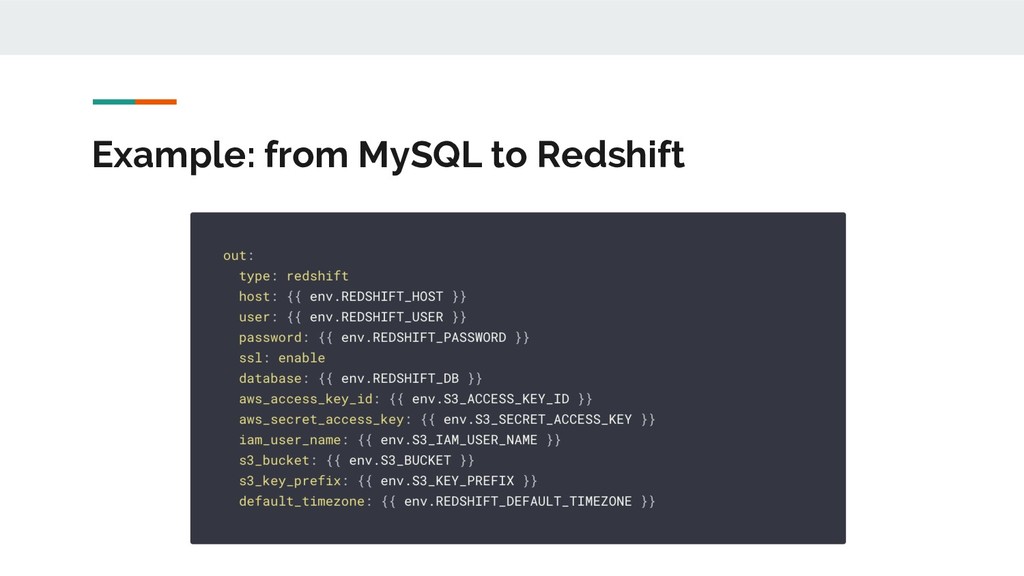
inserted (or updated) after the latest execution • Merging: load or update records according to the value of the latest updated_at and id columns • Templating: configurations for MySQL and Redshift are defined elsewhere
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}