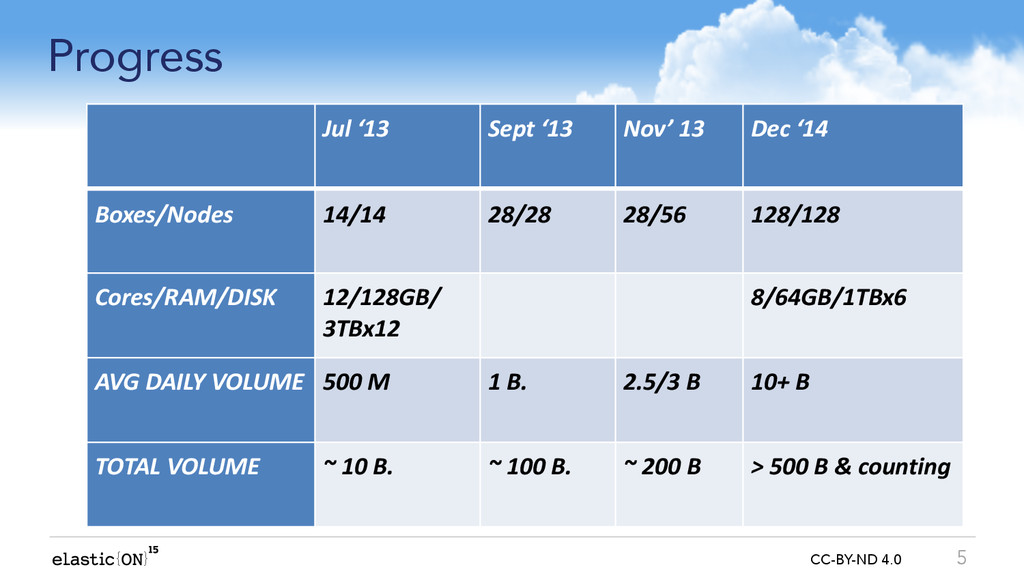
First deployed as a proof of concept in mid-2012, Verizon Business moved fully into production with Elasticsearch in mid-2013 and has continued to push forward ever since. Bhaskar will take you through this entire history - including a peek inside the architecture handling over 500 Billion documents - with a look forward at the next year for Verizon and Elasticsearch.
Presented by Bhaskar Karambelkar, Verizon Enterprise Solutions
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}