In spite of being close to 20 years old, the Lucene project keeps innovating. Hear stories of the latest features in Lucene 6, how they impacted Elasticsearch, and what to expect in Lucene 7.
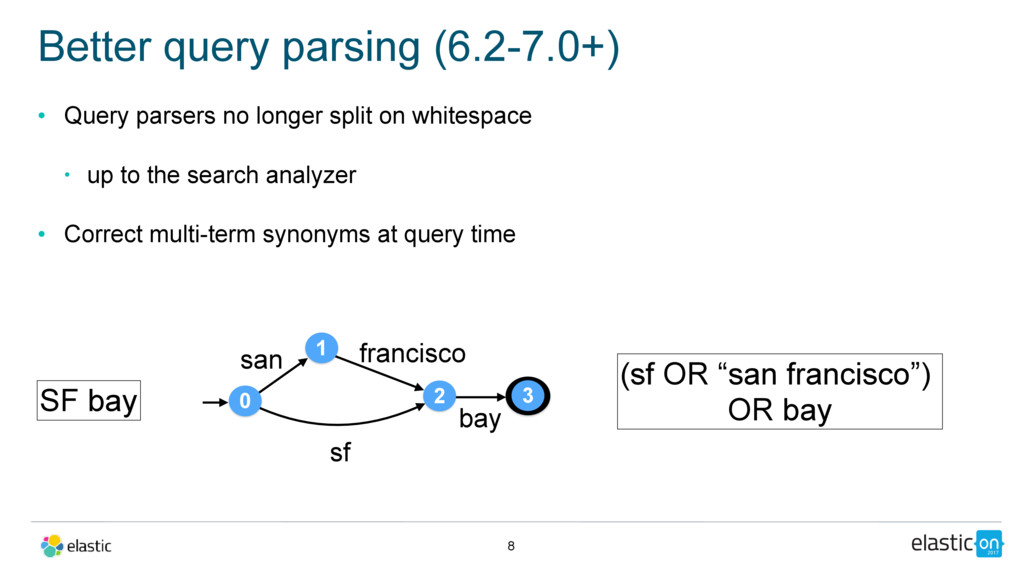
up to the search analyzer • Correct multi-term synonyms at query time Better query parsing (6.2-7.0+) 8 SF bay 0 1 san 2 sf francisco 3 bay (sf OR “san francisco”) OR bay
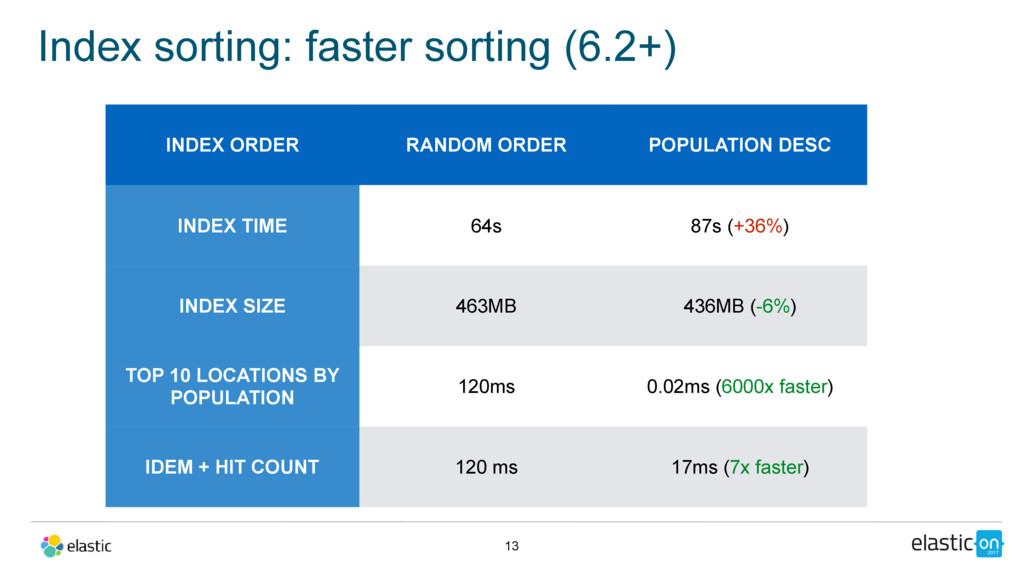
“population”: 310232863 } Index sorting (6.2+) 12 • Queries return documents in index order • Index sorting makes index order configurable • Benchmark on the geonames dataset • 8.5 M documents
POPULATION DESC INDEX TIME 64s 87s (+36%) INDEX SIZE 463MB 436MB (-6%) TOP 10 LOCATIONS BY POPULATION 120ms 0.02ms (6000x faster) IDEM + HIT COUNT 120 ms 17ms (7x faster)
TYPE ASC, COUNTRY_CODE ASC INDEX TIME 64s 136s (+112%) INDEX SIZE 463MB 374MB (-19%) TYPE:(CITY OR COUNTRY) 40ms 13ms (3x faster) TYPE:CITY AND COUNTRY_CODE:US 46ms 28ms (1.6x faster)
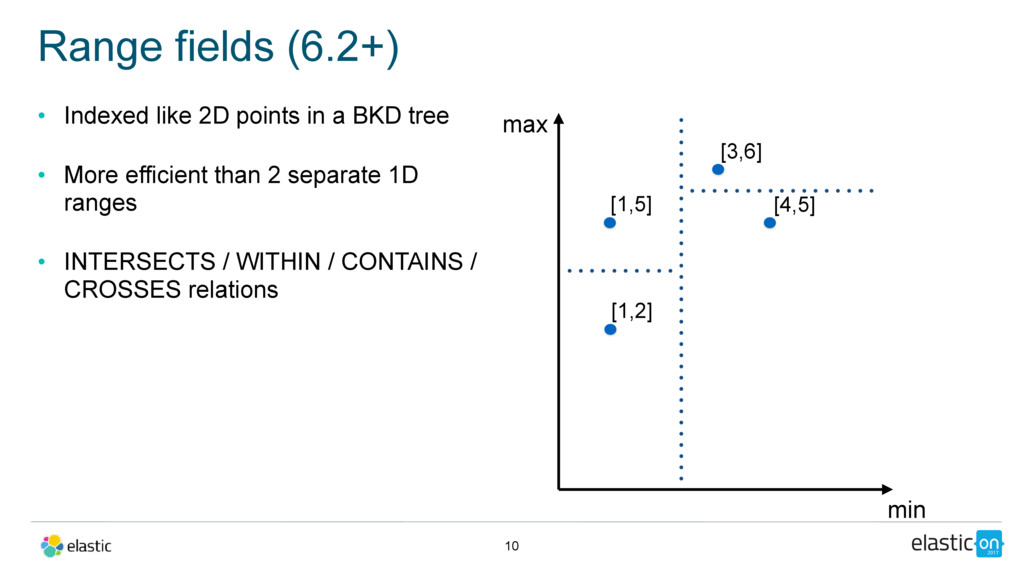
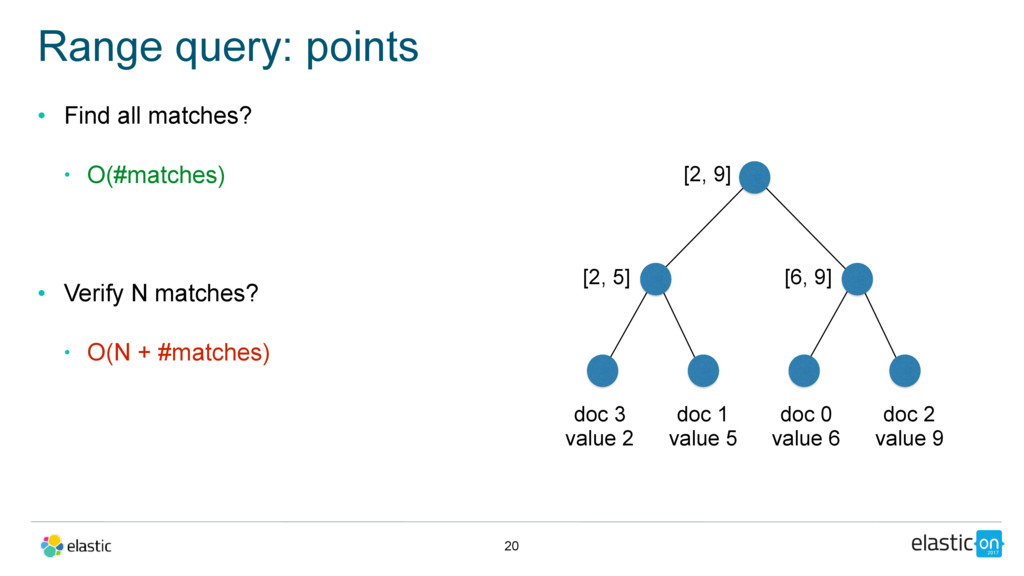
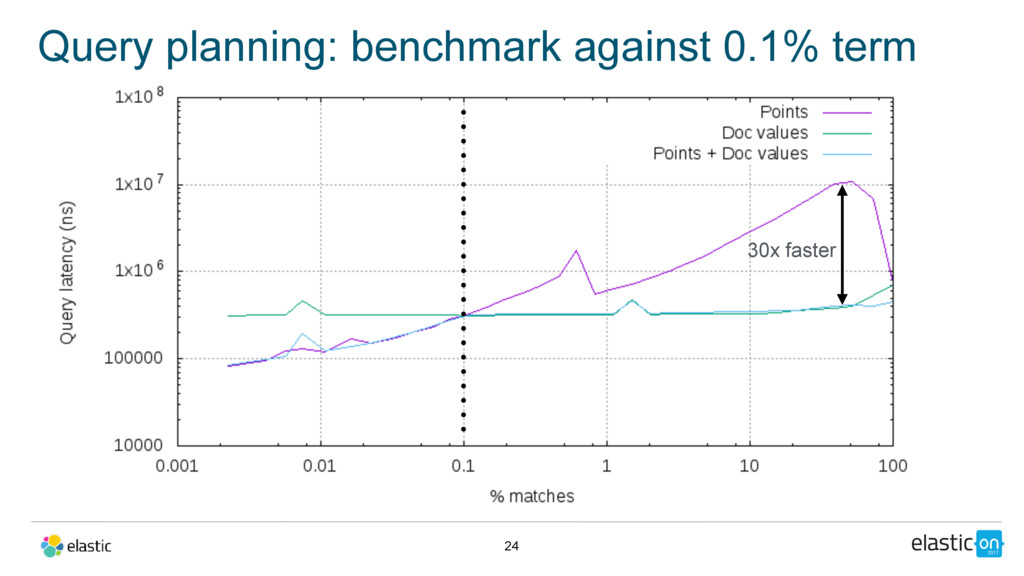
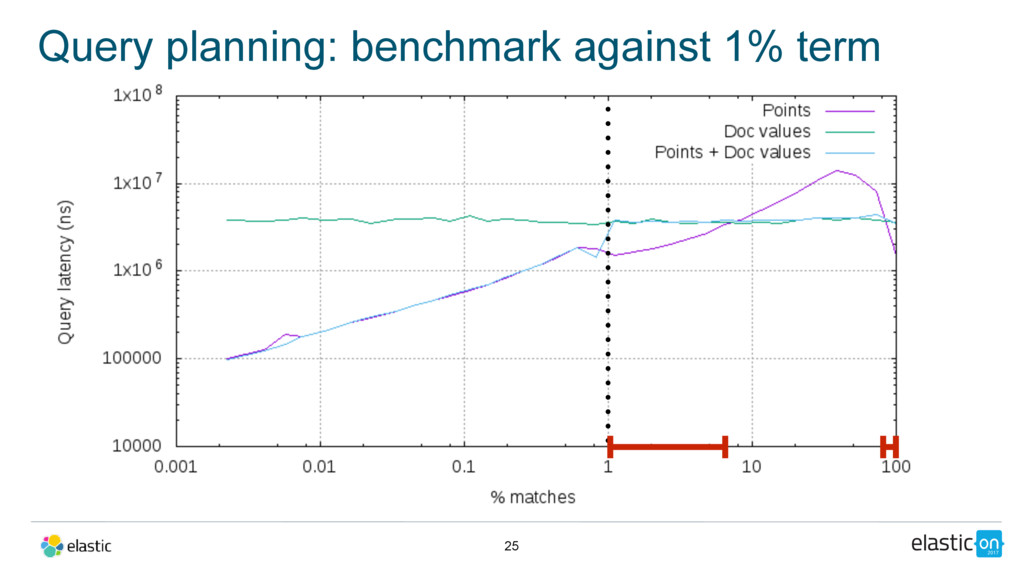
text • last edit: date • Query: full-text query on body, filtered by a date range on the last edit date • Query planning: • points if range is more selective • doc values otherwise
Creative Commons and the double C in a circle are registered trademarks of Creative Commons in the United States and other countries. Third party marks and brands are the property of their respective holders. 30 Please attribute Elastic with a link to elastic.co
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}