The challenge and success of using Elasticsearch to provide data visualization and targeting for personalizing utility customer messaging intended to maximize energy savings.
sustainable energy future! • Reduce energy usage by working with utilities to inform their customers about their energy usage and how to reduce it. • We send out reports, various alerts, and provide a web presence. • Since we started we have saved ~ 6 TeraWatt Hours! 3
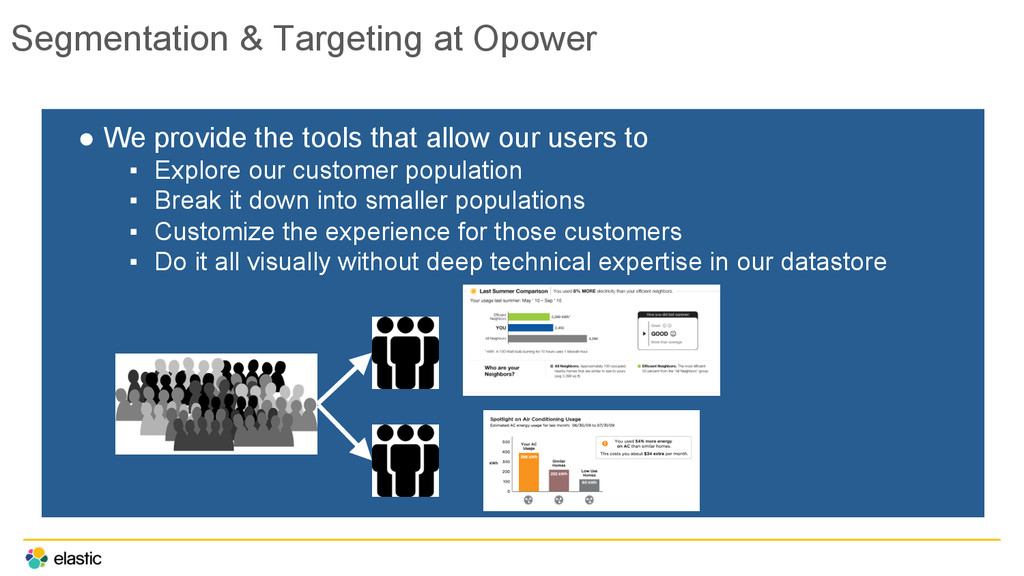
that allow our users to ▪ Explore our customer population ▪ Break it down into smaller populations ▪ Customize the experience for those customers ▪ Do it all visually without deep technical expertise in our datastore
Many attributes • Utilities Requirements ▪ Respect their structure • Prove our Savings ▪ Randomized Control Tests ▪ Verified by 3rd parties 6 • Customer ▪ Recipient ▪ Did not opt out ▪ Active Account ▪ Is a home owner • Has a larger house • Content Improve Insulation New Water Heater etc..
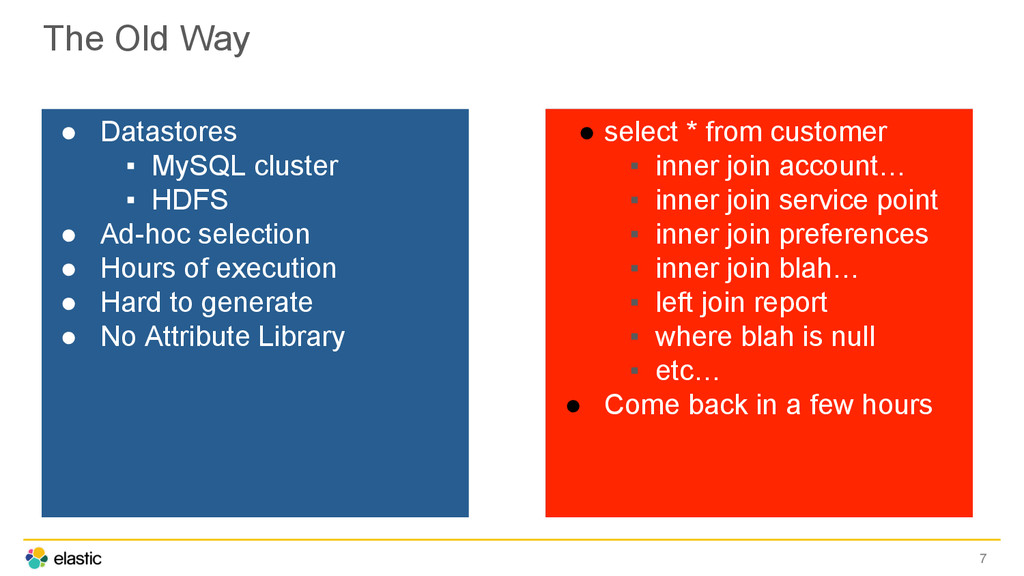
• Ad-hoc selection • Hours of execution • Hard to generate • No Attribute Library 7 • select * from customer ▪ inner join account… ▪ inner join service point ▪ inner join preferences ▪ inner join blah… ▪ left join report ▪ where blah is null ▪ etc… • Come back in a few hours
▪ Provide a place to fuse our data ▪ Query data quickly, on the order of seconds • Create a DSL to model the problem • Create a UI to visualze it • Why Elasticsearch? ▪ Easiest to set up ▪ Extensive documentation ▪ Good scaling story
get out data into Elasticsearch? • How do we support validating energy savings? • How do we represent and enforce our data schema? • How do we represent belonging to some group? • How do we represent the document hierarchy? • How does this DSL look? • How does the UI work? • How does Elasticsearch scale with our needs?
▪ Create don’t update ▪ Concurrency (r/w speed) • Map Reduce and batch ▪ Read elementary components ▪ Compose into hierarchy ▪ (Over)Write to ES ▪ Can also do minor transforms 11
savings is easier at the end. ▪ Must balance the variance of many attributes • What is “good enough” balance? • Solution ▪ Run many random splits (thousands) ▪ Index candidates (lists of customer ids) ▪ Query Elasticsearch for variance of each candidate ▪ Choose the best balanced candidate 12
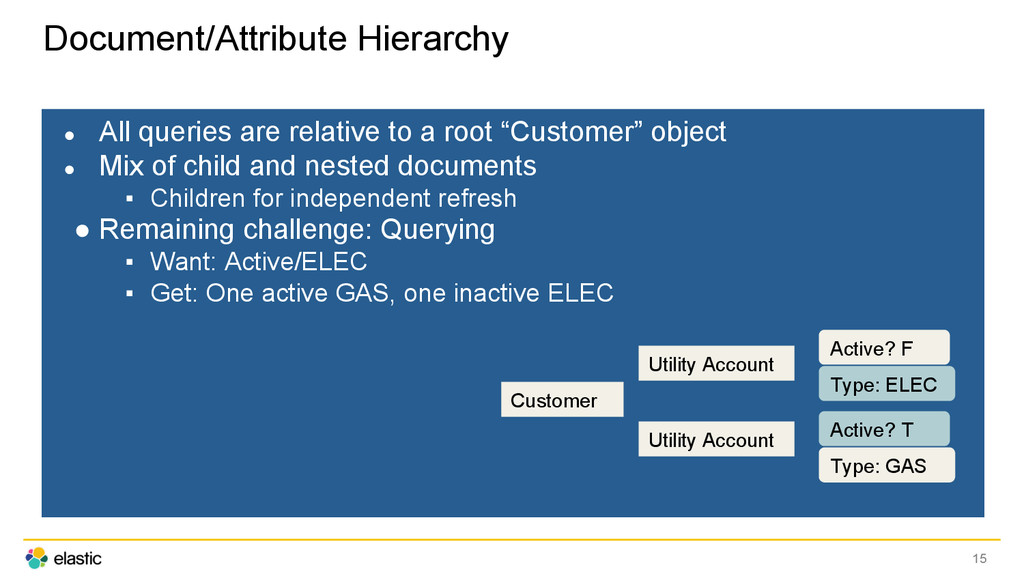
“Customer” object • Mix of child and nested documents ▪ Children for independent refresh • Remaining challenge: Querying ▪ Want: Active/ELEC ▪ Get: One active GAS, one inactive ELEC 15 Customer Utility Account Utility Account Active? F Active? T Type: ELEC Type: GAS
dataflow ▪ Encapsulate against future backwards incompatible changes. o Have done multiple Elasticsearch upgrades ▪ Easy to generate • Each population (node in the tree) ▪ Generate Elasticsearch filter to get counts or aggregations. • Function ▪ Split on Attribute ▪ Balanced Random Split ▪ Merges
Metrics • Some war stories ▪ Child document id cache (< 1.3.2) o The summer of manual cache clears ▪ The incredibly slow terms lookup query ▪ An endless cycle of garbage collection ▪ An incredible deep and foreboding search queue and UX implications ▪ Aliasing across all indexes can cause a field cache overflow 18
bringing our vision to life ▪ Currently used for selecting almost every utility with Opower ▪ Used daily by non-technical users ▪ Enabled difficult selections ▪ Met cost saving goals for operations ▪ Deliver unique campaigns to our customers ▪ Saved energy! • It’s been two years ▪ Planning on 2.0 upgrade ▪ Long term core technology
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}