Palestra a apresentar no encontro da comunidade PythonRio: http://pythonrio.python.org.br Atualizada em 15 Set 2016, para apresentação na Python Floripa
tuple unpacking ◦ APIs mais consistentes ◦ async/await ◦ sintaxe para tipagem gradual ◦ mais fácil para iniciantes • É o futuro do ecossistema ◦ seus usuários querem PY3
◦ para código com baixo risco 2. Fork para versão Python 3 ◦ para código estável, que receba poucas modificações 3. Python 2 & 3 com mesma base de código ◦ para código mantido e sendo usado por outros
ser 100%, mas é bom ter o suficiente para pegar regressões importantes • Rode os testes em Python 2 & Python 3 ◦ comece ignorando os que ainda não passam em Python 3, vá consertando aos poucos • Lembre que os testes podem estar incorretos em Python 3 e precisarem mudar também
2.6 ou anterior, migre primeiro para 2.7+ • Ignore 3.x menores que 3.3 ◦ não tinham suporte apropriado (sintático & stdlib) para fazer código compatível com 2 ◦ vendors (distros) em geral suportam 3.3+ • Dica para instalar várias versões de Python: ◦ http://saghul.github.io/pythonz (CPython, PyPy, etc)
3 no mesmo código* • Tudo em um arquivo, fácil de copiar e colar dentro do projeto se necessário • Funções utils, constantes, shims, aliases • Vocabulário para portar • Learn it, love it! <3
ser necessário quebrar ◦ unicode vs bytes força corrigir alguns problemas ◦ quando for bug mesmo, é aceitável quebrar • Prepare-se para fazer alguns ciclos de depreciação ◦ marcar código como obsoleto, emitindo warnings ◦ dica: DeprecationWarning é ignorada por default, crie uma nova class MyDeprecationWarning(Warning)
Todo Desenvolvedor De Software Absolutamente, Positivamente Precisa Saber Sobre Unicode E Conjuntos de Caracteres (Sem Desculpas!)” by Joel Spolsky Em inglês: http://www.joelonsoftware.com/articles/Unicode.html Tradução: http://local.joelonsoftware.com/wiki/O_M%C3%ADnimo_Absoluto_Que_Todo_Desenvolvedor_De_Soft ware_Absolutamente,_Positivamente_Precisa_Saber_Sobre_Unicode_E_Conjuntos_de_Caracteres_(S em_Desculpas!)
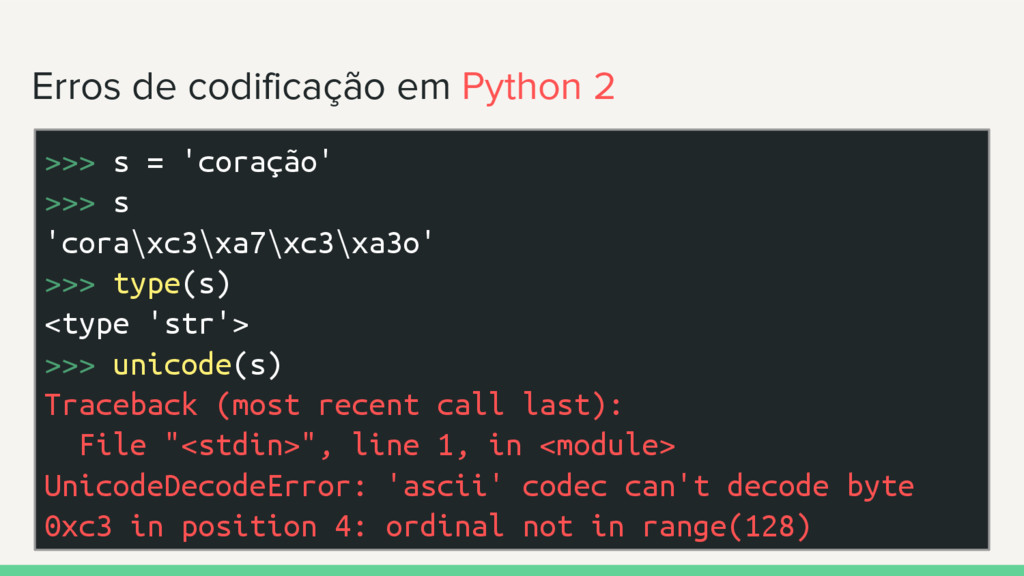
>>> s 'cora\xc3\xa7\xc3\xa3o' >>> type(s) <type 'str'> >>> unicode(s) Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 4: ordinal not in range(128)
decidir se: • deve ser só texto? (unicode em PY2, str em PY3) • deve ser só binário? (str/bytes em PY2, bytes em PY3) • deve ser string nativa? (str em PY2 & PY3) Fica mais simples quando se escolhe ou texto ou binário. É importante boa cobertura, e checar corretude dos testes também.
funções da stdlib em PY2 esperando bytes acabam recebendo um objeto unicode ◦ mais interessante quando portando de PY3 -> PY2 from __future__ import ( print_function, absolute_import, division )
as partes com menos dependências • Exemplo: ◦ escolha um módulo em utils ◦ revise o código e os testes ◦ corrija os testes, adicione mais alguns ◦ porte • É uma boa documentar decisões sobre bytes vs unicode ◦ Scrapy: começou com utils, depois Request/Response
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}