on the architecture pattern 3. Identify the infrastructure options and constraints IDENTIFYING THE TYPE OF DATA PIPELINE YOU NEED Source: https://www.reddit.com/r/dataengineering/comments/suvukx/rdataengineering_buzzwords_details_in_comments/
Aggregate sales data from all the stores in the supermarket chain 2. Who are the end users of your data? 1. National sales managers 2. Regional data warehouse managers 3. Which use cases do you want to address? 1. Daily revenue summary 2. Re-order soon-to-be out of stock products before they run out 4. What should be the functional focus of the pipeline? 1. First use case: Daily revenue summary for the national sales managers 2. Sales data from Nigeria 3. Start with the data from October 1, 2022 1. DECIDE ON THE SCOPE OF THE PROJECT
updated? (Real- time vs. hourly or less) - Streaming vs. Batch pipeline - We need: Daily (Batch) - Volume: Does the data fi t into the memory of one machine? - Single machine vs. distributed machines architecture - 30 supermarkets with ~500 transactions per day, 50 bytes per transaction => less than 1GB per day => fi ts into one machine - Source & Destination Connectors: - Type of data access? (API, storage, stream, …) - Data format? (JSON, CSV, Parquet, binary, …) 2. DECIDE ON AN ARCHITECTURE PATTERN
what data infrastructure is available there - Cloud: GCP - Identify security needs (private networks, data encryption at rest and in transit, access controls for the data, …) - VPN from the point of sale to GCP needed - Data encryption at rest and in transit needed - Only the C-level, and the fi nance and analytics departments may access the data IDENTIFY THE INFRASTRUCTURE OPTIONS AND CONSTRAINTS
End-to-end test: Compares source test data to destination test data - Simplest test case: Empty transaction fi le—> Aggregate to zero revenue per day 2. Set up your infrastructure to make the integration test case work 3. De fi ne your unit tests fi rst before you code each of your transformations - Unit test: Compares fi xed, fake input data to fi xed output data - Start with the „Happy Path“, then edge cases - Happy path: One transaction per day of 1 Naira -> Metric result: 1 NGN revenue/day - Edge cases: No sales, invalid products, sales returned the next day, negative sales price, discounts,… 1. TEST-FIRST PIPELINE DEVELOPMENT ?
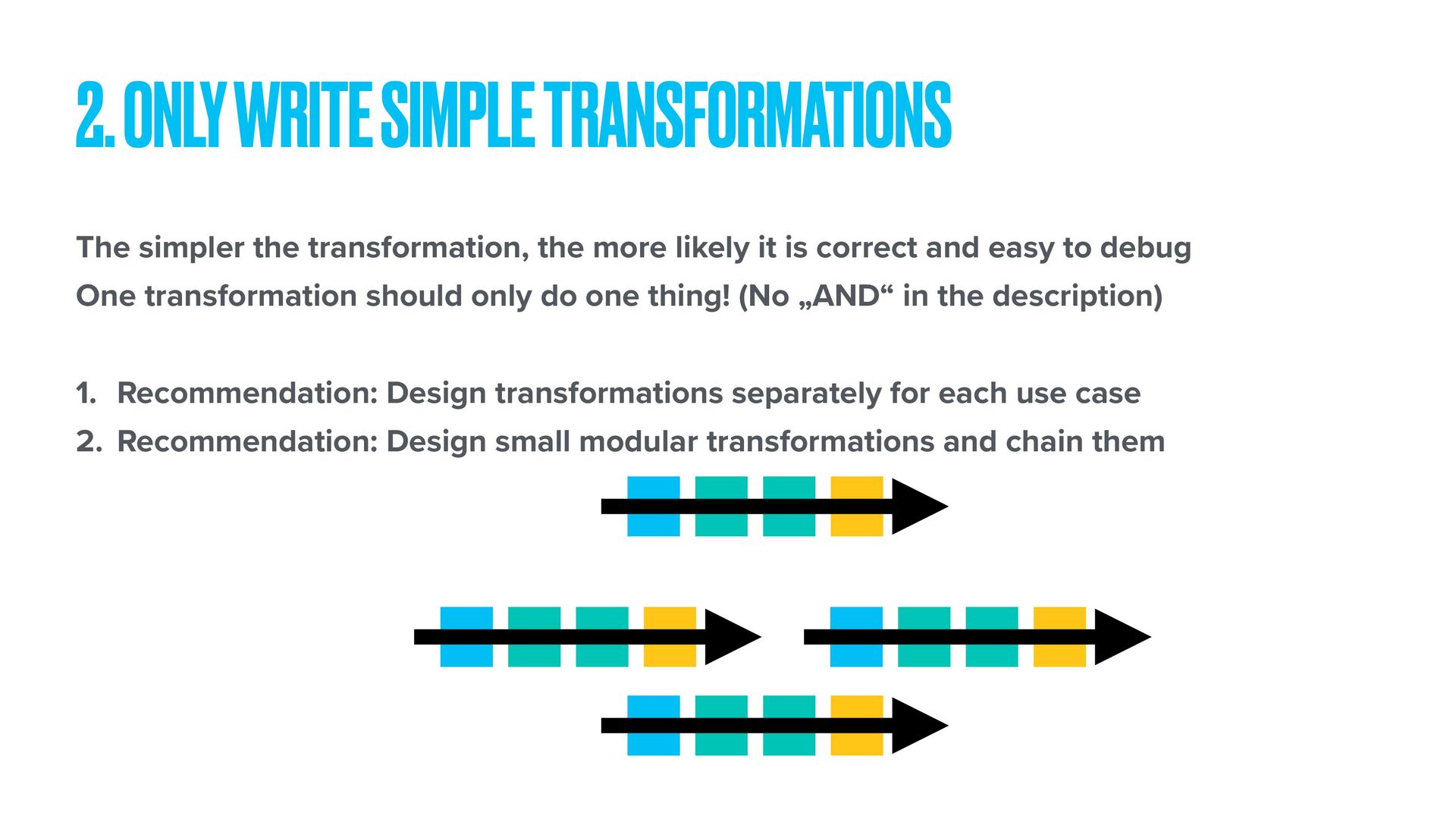
and easy to debug One transformation should only do one thing! (No „AND“ in the description) 1. Recommendation: Design transformations separately for each use case 2. Recommendation: Design small modular transformations and chain them 2. ONLY WRITE SIMPLE TRANSFORMATIONS
on the architecture pattern 3. Identify the infrastructure options and constraints IDENTIFYING THE TYPE OF DATA PIPELINE YOU NEED 1. Test- fi rst pipeline development 2. Only write simple transformations MAKING SURE YOUR DATA PIPELINE DOES NOT DISTORT THE DATA
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}