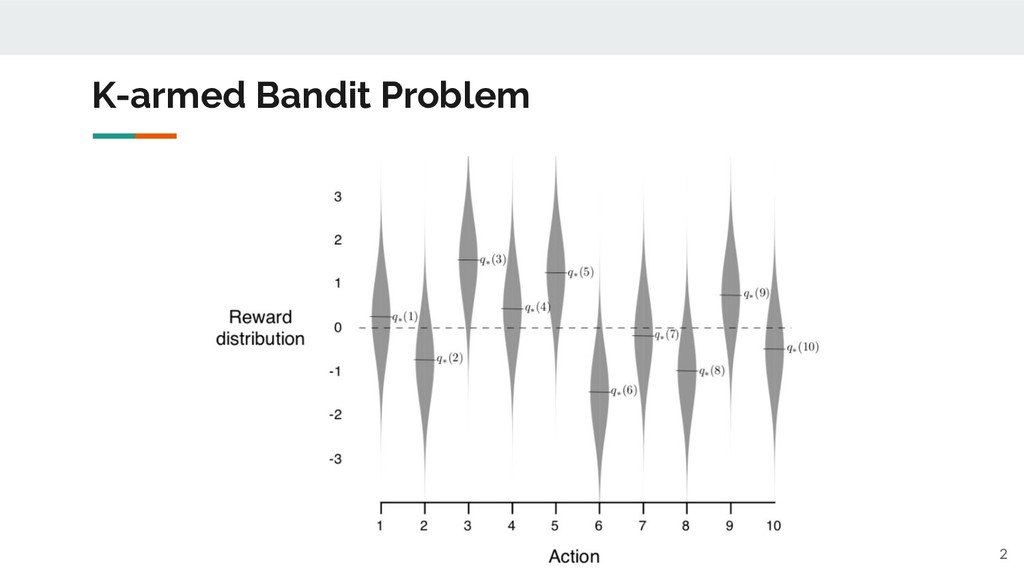
◦ No point of defining the value function v(s) ▪ v(s) : expected value (total rewards) you can get when starting from the state s. ◦ Instead, you need to evaluate the acton-value Q(a) ▪ Q(a) : expected value (immediate reward) you can get when choosing the action a. 3
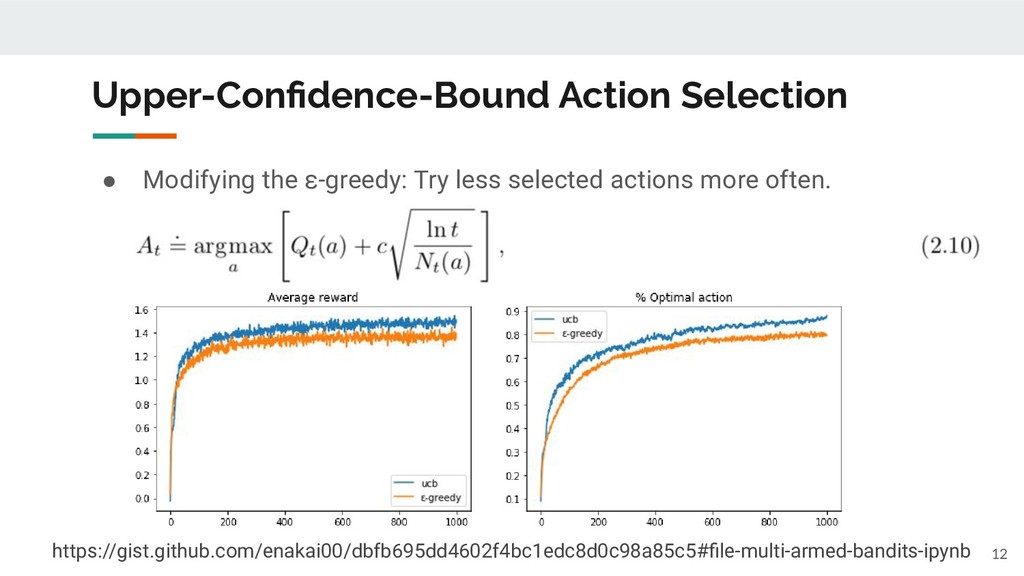
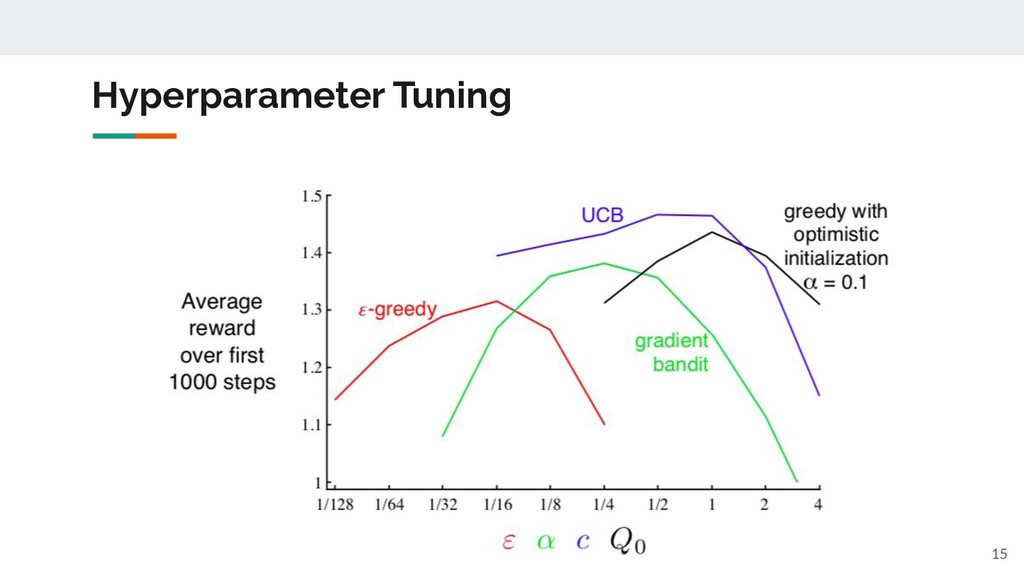
take actions indefinitely, you can get the perfect estimation for Q(a). • When the number of actions are limited, how can you maximize the average reward? ◦ What is the better policy to decide the next action a from the current estimation of Q(a)? 4
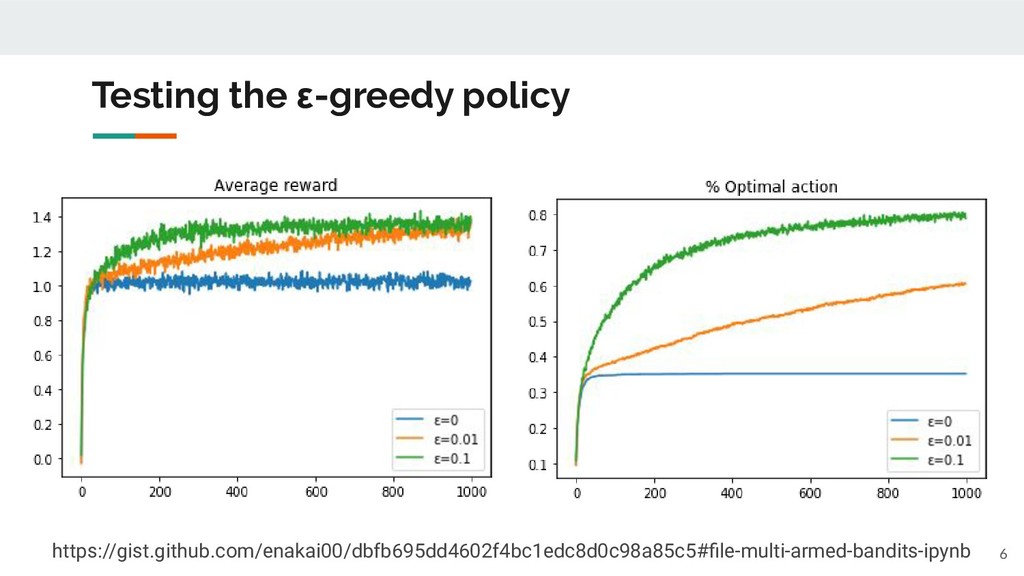
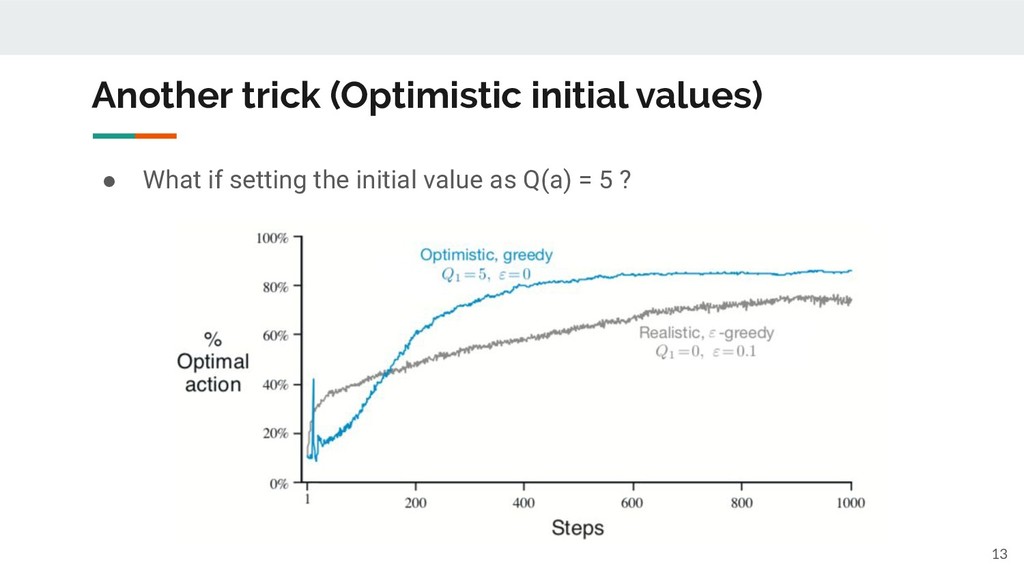
Q(a) is accurate, this is the best policy. ◦ If not, you'd better try different actions to improve the accuracy of Q(a). • ε-greedy policy ◦ With probability ε, choose a random action. 5
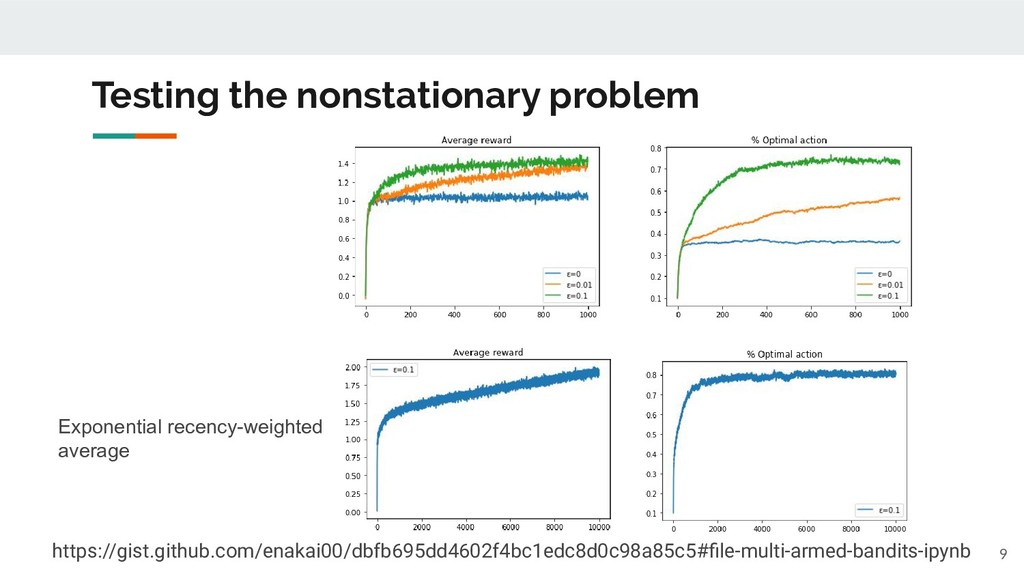
state of environment changes, but you don't have any "hint" about the current state. ◦ What if you have a "hint" about the state? ▪ eg: the color of slot machines changes according to the reward distribution R(a). • The "hint" can be formalized as a state "s" of the environment. ◦ Action-value function and policy can be functions of "s". ▪ Q(a | s) ▪ P(a | Q(s), s) 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}