Incremental and Hierarchical Document Clustering Rui Alberto Cardoso da Encarnação Advisor: Professor Paulo Gomes Department of Informatics Engineering Faculty of Science and Technology University of Coimbra September 2011
documents generation and our ability to use them demands automatic tools Why hierarchical clustering? no need to specify the number of clusters searches at different levels, satisfying different needs Why incremental clustering? document repositories are constantly being updated 3
incremental clustering? What is the best dimensionality reduction technique to overcome the curse of dimensionality? What changes must be done to conceptual clustering algorithms in order to use them with documents? 5
creation of a new document clustering algorithm with these requirements: Hierarchical Incremental Unsupervised Conceptual clustering Minimum performance 6
Clustering is unsupervised High intra-cluster similarity and low inter-cluster similarity Document clustering is the automatic organization of a set of documents into clusters Types of document clustering algorithms 7
cluster at the top and clusters of individual documents at the bottom Agglomerative - starts with single nodes and builds the hierarchy bottom-up, joining one pair in each step Divisive - splits a global node until only remain single nodes Pros: No need to specify the number of clusters Cons: No adjustments and not scalable 10
K (predefined) clusters represented by the centroids Chooses K initial random centroids and assigns documents to the closest. Then new centroids are computed and documents are reassigned until stability Many variants: K-Medoids, Bisecting K-Means Pros: Relatively efficient, find all clusters at once Cons: Need to specify K and sensitivity to initial centroids and outliers 11
clustering to documents was done by Sahoo (2006 and 2009) CLASSIT without changes can’t be used with text Replace Normal distribution by Katz’s distribution TF-IDF can’t be used in an incremental environment Confusion between TF-IDF and TF in distributions 13
of a preliminary version of the algorithm Develop a global framework for incremental document clustering Implementation of the final version of the algorithm Experimentations and evaluation of the algorithm 14
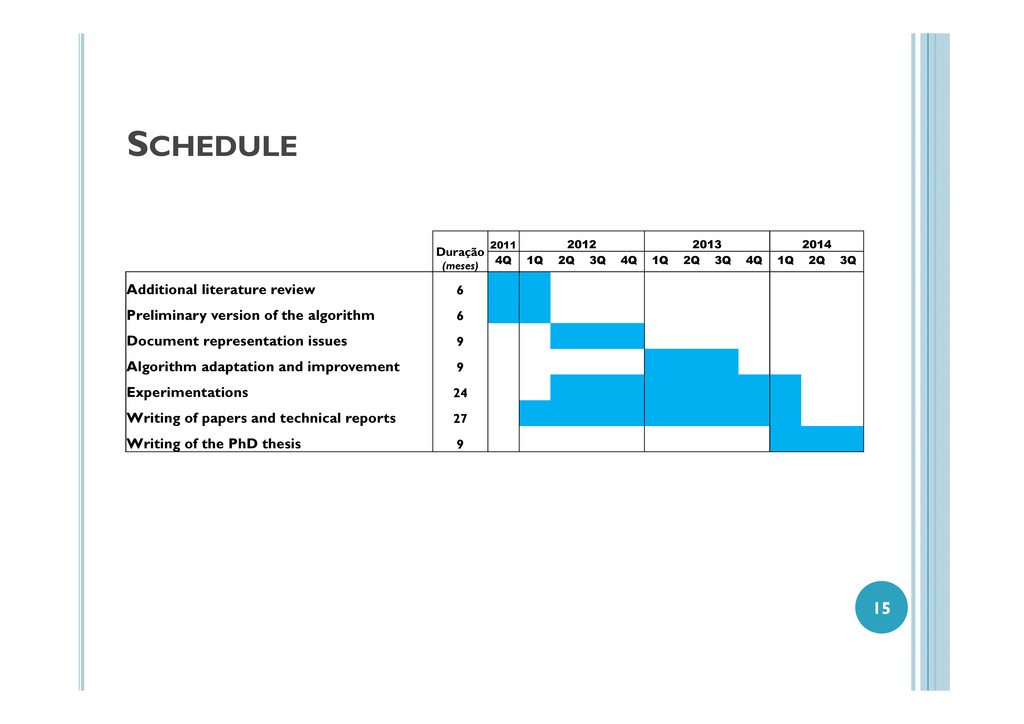
2Q 3Q 4Q 1Q 2Q 3Q 4Q 1Q 2Q 3Q Additional literature review 6 Preliminary version of the algorithm 6 Document representation issues 9 Algorithm adaptation and improvement 9 Experimentations 24 Writing of papers and technical reports 27 Writing of the PhD thesis 9
The adaptation of concept clustering algorithms to texts; A document representation and dimensionality reduction techniques suitable for incremental clustering; Better mechanisms of backtracking and tree reorganization; New measures for evaluate incremental clustering quality; 16
for automatic document organization tools. This work can create a framework for future incremental and hierarchical document clustering research. We do believe that our system can be an invaluable tool to prevent us from staying overwhelmed with documents. 18
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}