Techniques et Procédures sont stockées au format de la “matrice” MITRE ATT&CK. Exemples : ▶ T1566 (Phishing) ▶ T1497 (Virtualization/Sandbox Evasion) ▶ T1041 (Exfiltration over C2 channel) ▶ T1573 (Encrypted channel) 3/12
existe un outil open-source permettant l’extraction de TTPs dans du texte non structuré : Threat Report ATT&CK Mapping (TRAM) ▶ Version bêta, développé par MITRE (https://github.com/mitre-attack/tram) ▶ Basé sur un modèle de régression Problème : Les performances sont mauvaises... ▶ Il n’existe pas de jeu de données annoté de grande taille ! ▶ Les rapports capitalisés par l’ANSSI contiennent une liste de TTPs... mais pas les phrases dans lesquelles l’analyste les a détectées. 5/12
InteLLigEnce Reports) ▶ Projet interne ANSSI, repose sur des principes de NLP. ▶ Inspiré de l’article de recherche TTPDrill: Automatic and Accurate Extraction of Threat Actions from Unstructured Text of CTI Sources, Husari et al., 2017. Le but de DISTILLER est l’extraction de TTPs (format MITRE ATT&CK) à partir de texte brut. 6/12
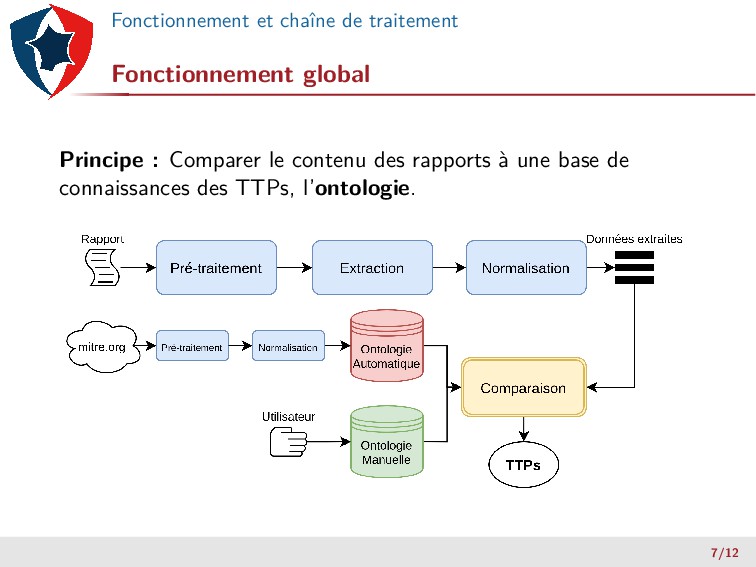
en deux étapes : ▶ Pré-traitement générique (hyphenation, références, espaces,...) ▶ Pré-traitement spécifique : 1 Noms de codes malveillants, de modes opératoires... 2 Règles spécifiques (expressions régulières) 2 Extraction : utilisation de SpaCy. 3 Normalisation : texte en minuscule et “lemmatized”, prise en compte de synonymes, suppression des tokens inutiles. 8/12
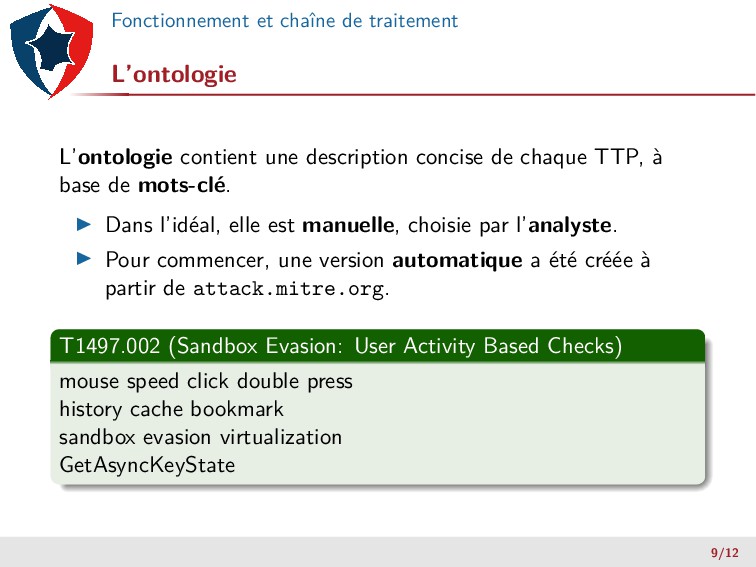
concise de chaque TTP, à base de mots-clé. ▶ Dans l’idéal, elle est manuelle, choisie par l’analyste. ▶ Pour commencer, une version automatique a été créée à partir de attack.mitre.org. T1497.002 (Sandbox Evasion: User Activity Based Checks) mouse speed click double press history cache bookmark sandbox evasion virtualization GetAsyncKeyState 9/12
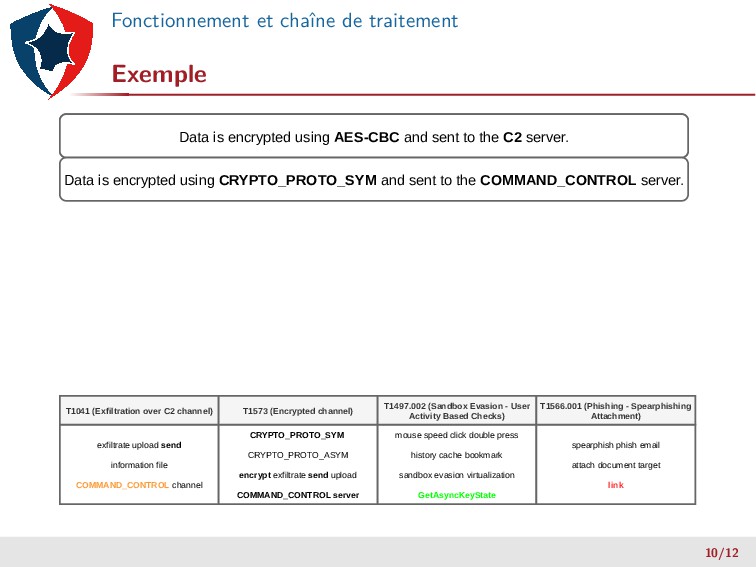
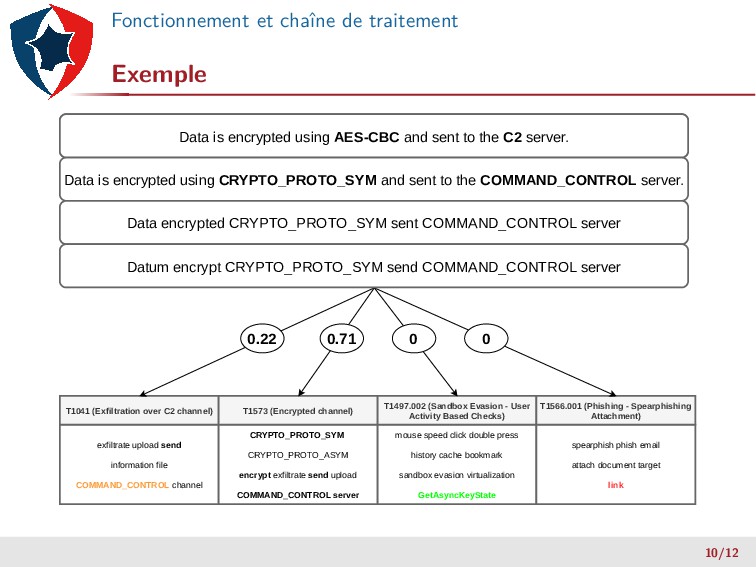
file COMMAND_CONTROL channel T1041 (Exfiltration over C2 channel) CRYPTO_PROTO_SYM CRYPTO_PROTO_ASYM encrypt exfiltrate send upload COMMAND_CONTROL server T1573 (Encrypted channel) mouse speed click double press history cache bookmark sandbox evasion virtualization GetAsyncKeyState T1497.002 (Sandbox Evasion - User Activity Based Checks) spearphish phish email attach document target link T1566.001 (Phishing - Spearphishing Attachment) Data is encrypted using AES-CBC and sent to the C2 server. 10/12
file COMMAND_CONTROL channel T1041 (Exfiltration over C2 channel) CRYPTO_PROTO_SYM CRYPTO_PROTO_ASYM encrypt exfiltrate send upload COMMAND_CONTROL server T1573 (Encrypted channel) mouse speed click double press history cache bookmark sandbox evasion virtualization GetAsyncKeyState T1497.002 (Sandbox Evasion - User Activity Based Checks) spearphish phish email attach document target link T1566.001 (Phishing - Spearphishing Attachment) Data is encrypted using AES-CBC and sent to the C2 server. Data is encrypted using AES-CBC and sent to the C2 server. 10/12
file COMMAND_CONTROL channel T1041 (Exfiltration over C2 channel) CRYPTO_PROTO_SYM CRYPTO_PROTO_ASYM encrypt exfiltrate send upload COMMAND_CONTROL server T1573 (Encrypted channel) mouse speed click double press history cache bookmark sandbox evasion virtualization GetAsyncKeyState T1497.002 (Sandbox Evasion - User Activity Based Checks) spearphish phish email attach document target link T1566.001 (Phishing - Spearphishing Attachment) Data is encrypted using AES-CBC and sent to the C2 server. Data is encrypted using CRYPTO_PROTO_SYM and sent to the COMMAND_CONTROL server. Data is encrypted using AES-CBC and sent to the C2 server. 10/12
file COMMAND_CONTROL channel T1041 (Exfiltration over C2 channel) CRYPTO_PROTO_SYM CRYPTO_PROTO_ASYM encrypt exfiltrate send upload COMMAND_CONTROL server T1573 (Encrypted channel) mouse speed click double press history cache bookmark sandbox evasion virtualization GetAsyncKeyState T1497.002 (Sandbox Evasion - User Activity Based Checks) spearphish phish email attach document target link T1566.001 (Phishing - Spearphishing Attachment) Data is encrypted using AES-CBC and sent to the C2 server. Data is encrypted using CRYPTO_PROTO_SYM and sent to the COMMAND_CONTROL server. Data is encrypted using AES-CBC and sent to the C2 server. Data encrypted CRYPTO_PROTO_SYM sent COMMAND_CONTROL server 10/12
file COMMAND_CONTROL channel T1041 (Exfiltration over C2 channel) CRYPTO_PROTO_SYM CRYPTO_PROTO_ASYM encrypt exfiltrate send upload COMMAND_CONTROL server T1573 (Encrypted channel) mouse speed click double press history cache bookmark sandbox evasion virtualization GetAsyncKeyState T1497.002 (Sandbox Evasion - User Activity Based Checks) spearphish phish email attach document target link T1566.001 (Phishing - Spearphishing Attachment) Data is encrypted using AES-CBC and sent to the C2 server. Data is encrypted using CRYPTO_PROTO_SYM and sent to the COMMAND_CONTROL server. Data is encrypted using AES-CBC and sent to the C2 server. Data encrypted CRYPTO_PROTO_SYM sent COMMAND_CONTROL server Datum encrypt CRYPTO_PROTO_SYM send COMMAND_CONTROL server 10/12
file COMMAND_CONTROL channel T1041 (Exfiltration over C2 channel) CRYPTO_PROTO_SYM CRYPTO_PROTO_ASYM encrypt exfiltrate send upload COMMAND_CONTROL server T1573 (Encrypted channel) mouse speed click double press history cache bookmark sandbox evasion virtualization GetAsyncKeyState T1497.002 (Sandbox Evasion - User Activity Based Checks) spearphish phish email attach document target link T1566.001 (Phishing - Spearphishing Attachment) Data is encrypted using AES-CBC and sent to the C2 server. Data is encrypted using CRYPTO_PROTO_SYM and sent to the COMMAND_CONTROL server. Data is encrypted using AES-CBC and sent to the C2 server. Data encrypted CRYPTO_PROTO_SYM sent COMMAND_CONTROL server Datum encrypt CRYPTO_PROTO_SYM send COMMAND_CONTROL server 0.71 0.22 0 0 10/12
production. ▶ Performances correctes malgré une ontologie automatique. ▶ Interface graphique avec annotations du fichier PDF. ▶ Met l’outil à disposition des analystes. 11/12
de DISTILLER : ▶ La matrice ATT&CK contient environ 430 TTPs... rendant l’ontologie délicate à créer (et à maintenir). ▶ Pas de prise en compte du contexte (différence entre le verbe get et la méthode de requête HTTP GET). ▶ Gestion manuelle des synonymes. ⇒ Recherche d’une solution (éventuellement commerciale) pour l’aide à la création d’ontologie. 12/12
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}