de jeux de données bien connu est souvent utilisé1 dans la recherche et les applications en Machine Learning. 1Núria Macià et al. “Learner excellence biased by data set selection: A case for data characterisation and artificial data sets”. In: Pattern Recognition 46.3 (2013), pp. 1054–1066. 4
données ne reflètent pas toujours les défis et la variété de la donnée ouverte: Code AGB Nom du produit Score environmental 19580 Abricot au sirop léger, appertisé, égoutté 2.46 NAN Abricot au sirop léger, appertisé, non égoutté NAN 21508 Abricot, dénoyauté, cru 2.5 36780 NAN 2.46 25263 Yaourt, lait fermenté ou spécialité laitière, aux fruits 3.61 NAN Yaourt, lait fermenté ou spécialité laitière, aux fruits 2.5 90768 Agneau, collier, cru 2.1 5
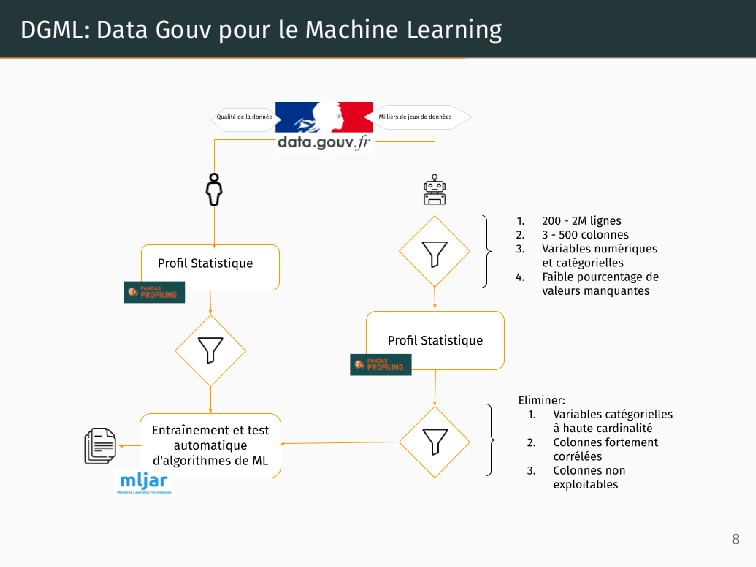
qualité • Format des données • Contenu des données • Besoin important de pre-traitement Manque de communication sur les plateformes de donnée ouverte Manque de catalogues spécialisés en Machine Learning 7
jeu de données pour le Machine Learning Tester des applications existantes (telles que les exemples scikit-learn) sur la donnée ouverte Augmenter le nombre de jeux de données disponibles Renforcer le lien avec la communauté data.gouv.fr Généraliser notre méthodologie à d’autres plateformes de données ouvertes 11
et la recherche en Machine Learning Nous proposons une méthodologie pour identifier les jeux de données adaptés au Machine Learning Nous avons développé DGML, Data Gouv pour le Machine Learning : un catalogue centralisé pour le ML avec la donnée ouverte de data.gouv.fr Merci ! [email protected][email protected] https://datascience.etalab.studio/dgml/ etalab-ia/DGML 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}