Gendarmerie Nationale Services Techniques des Systèmes d’Information de la Sécurité Intérieure Sous-Direction des Systèmes d’Information Datalab MINISTÈRE DE L’INTÉRIEUR Daphné Pertsekos - Jean-Baptiste Delfau
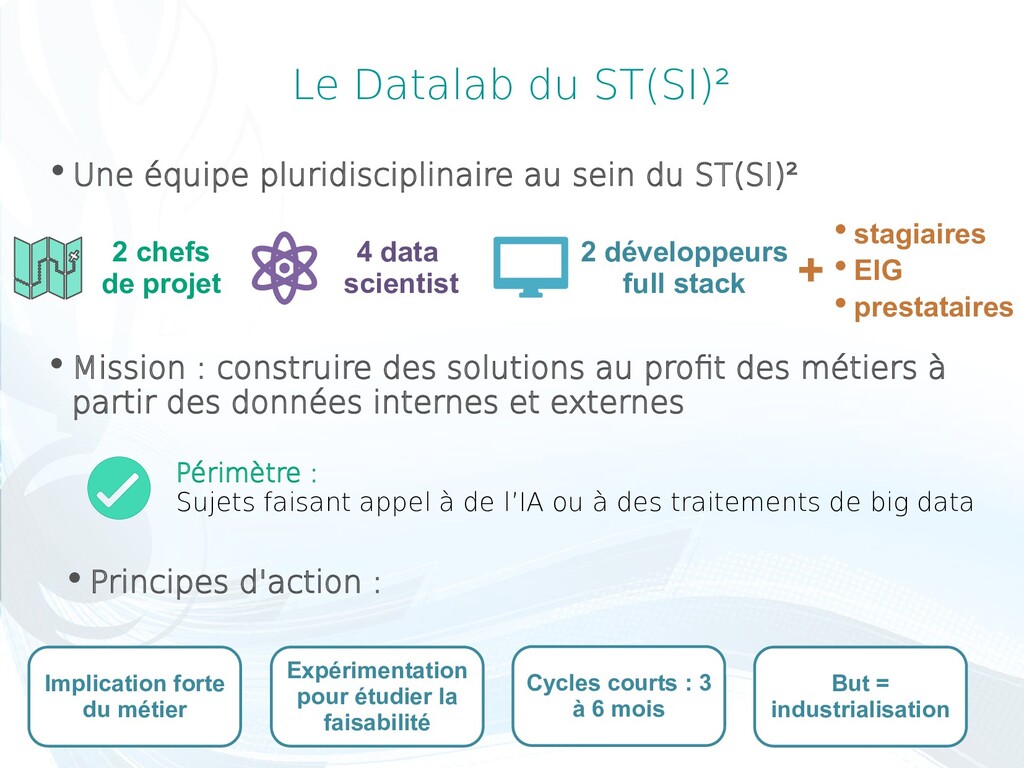
de l’IA ou à des traitements de big data Une équipe pluridisciplinaire au sein du ST(SI)² 4 data scientist 2 développeurs full stack Mission : construire des solutions au proft des métiers à partir des données internes et externes Principes d'action : 2 chefs de projet + stagiaires EIG prestataires Implication forte du métier Expérimentation pour étudier la faisabilité Cycles courts : 3 à 6 mois But = industrialisation
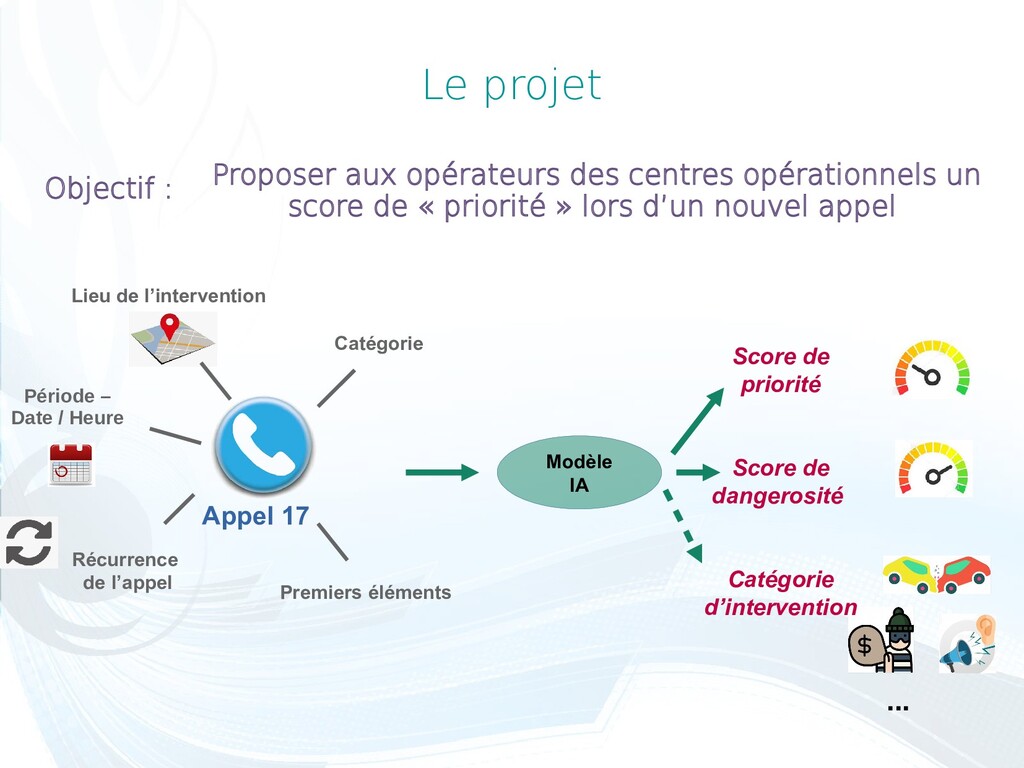
de « priorité » lors d’un nouvel appel Appel 17 Score de priorité Score de dangerosité Catégorie d’intervention Catégorie Modèle IA Récurrence de l’appel Lieu de l’intervention Premiers éléments Objectif : Période – Date / Heure ...
afn de couvrir un maximum de situations rencontrées. Certaines catégories regroupent des interventions de nature relativement diférente. → clustering intra-catégorie afn de déterminer des sous-groupes. Proximité sémantique pour évaluer l’homogénéité d’un échantillon
fournir les labels prédits par l’algo. Taux de dissension : % d’interventions pour lesquels les labels difèrent quand les corgistes ne sont pas infuencés par les propositions de l’algorithme. Taux d’erreurs induites : % d’interventions où le corgiste a suivi la proposition à tort Taux de méfance injustifée : % d’interventions où le corgiste n’a pas suivi l’algorithme à tort CORG POST : 0 POST : 1 LIVE LIVE 0 1 0 1 ALGO 0 TN1 FP2 FN1 TP2 1 TN2 FP1 FN2 TP1 Taux de dissension Taux d’erreurs induites Taux de méfance injustifée TN 2+FP1+FN 1+TP2 ∑interventions FN 1+FP1 ∑interventions FN 2+FP2 ∑interventions
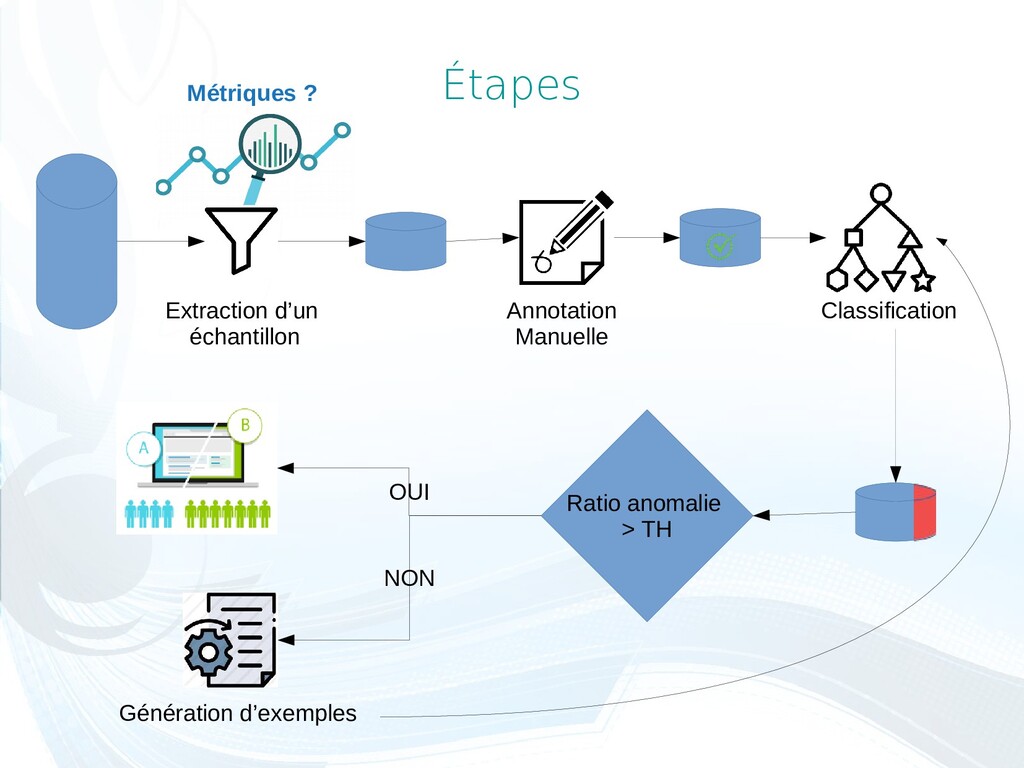
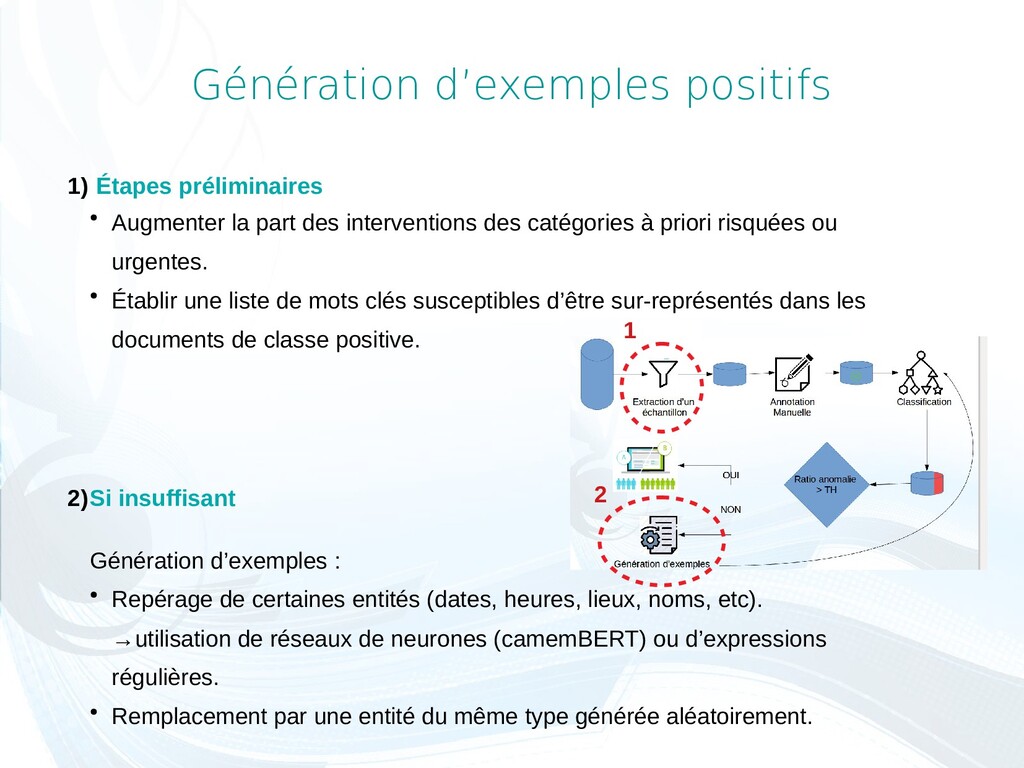
des interventions des catégories à priori risquées ou urgentes. • Établir une liste de mots clés susceptibles d’être sur-représentés dans les documents de classe positive. 2)Si insuffisant Génération d’exemples : • Repérage de certaines entités (dates, heures, lieux, noms, etc). →utilisation de réseaux de neurones (camemBERT) ou d’expressions régulières. • Remplacement par une entité du même type générée aléatoirement. 1 2
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}