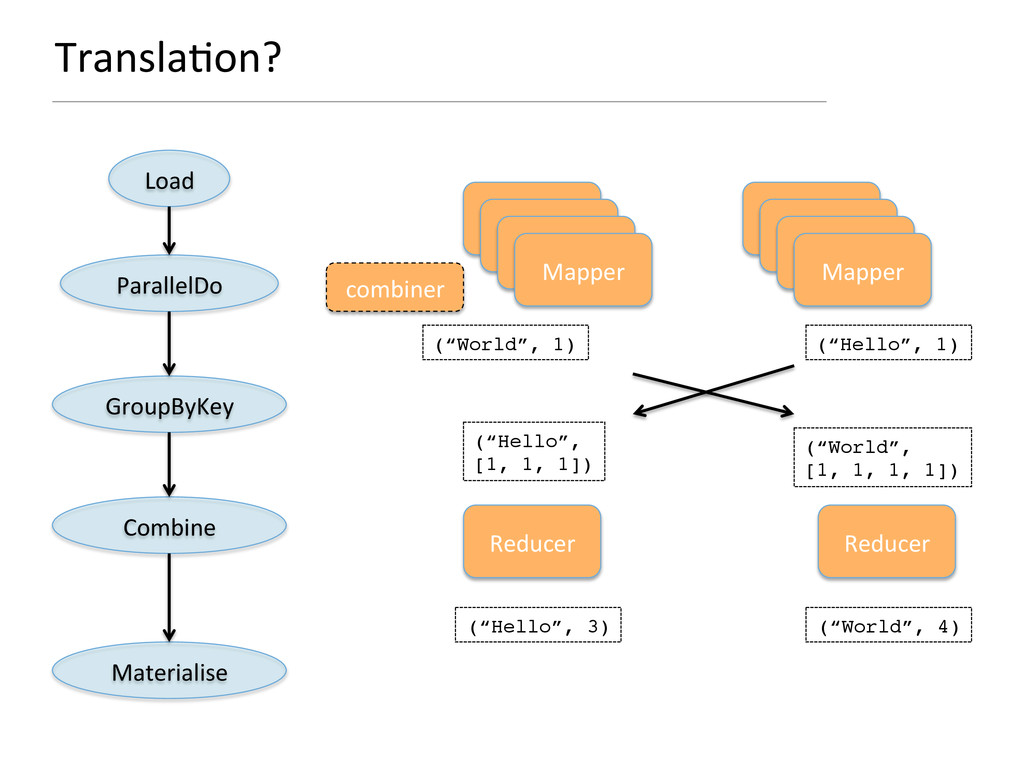
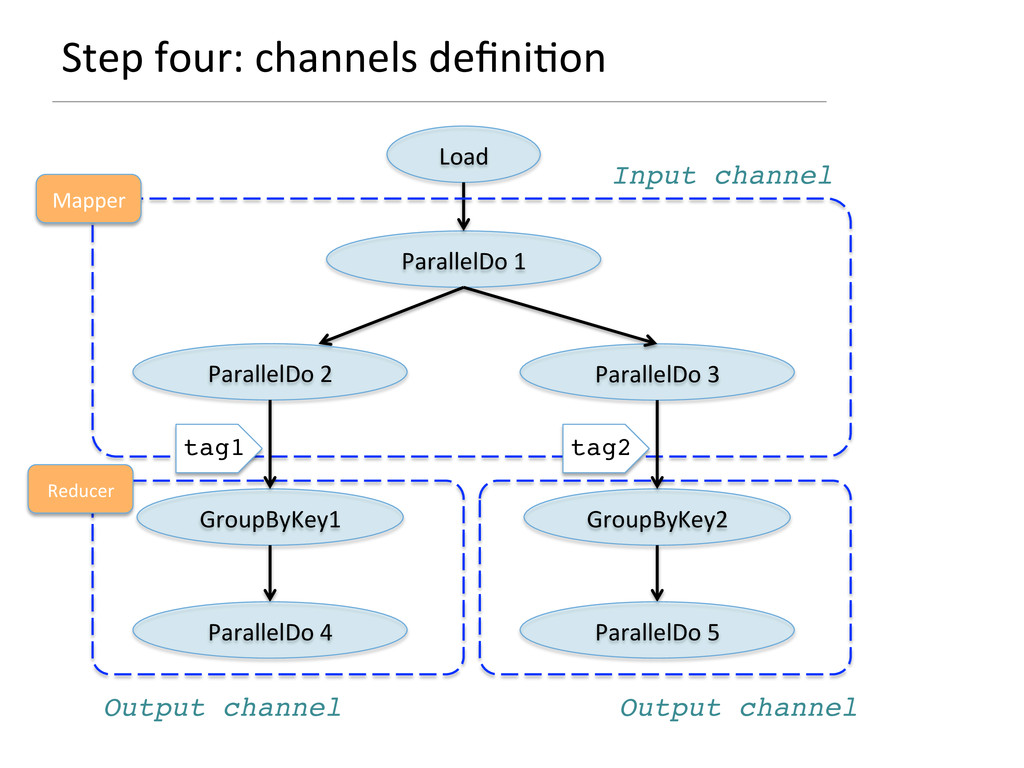
This talk gives a brief overview of the BigData tooling landscape and where Scoobi, a distributed collection Scala library for Hadoop, stands. Then it shows what are the challenges in translating Scoobi abstractions to Hadoop constructs and how Scala, as programming language, and Kiama (http://code.google.com/kiama), as a graph-processing library, can be leveraged to support this translation. In particular:
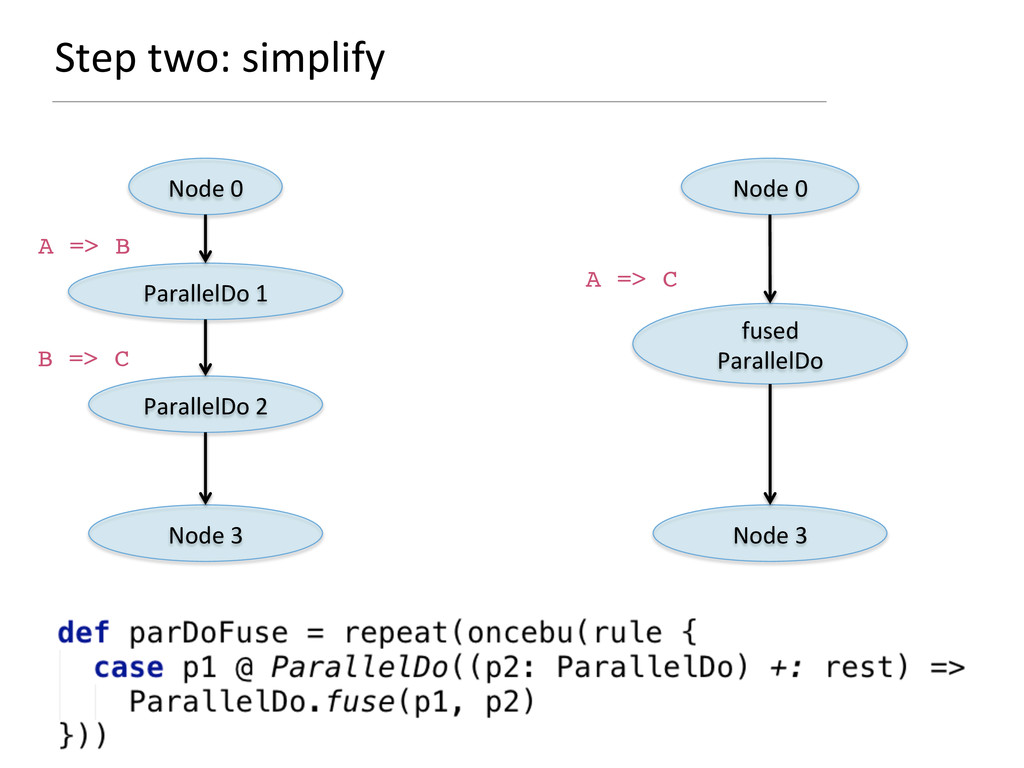
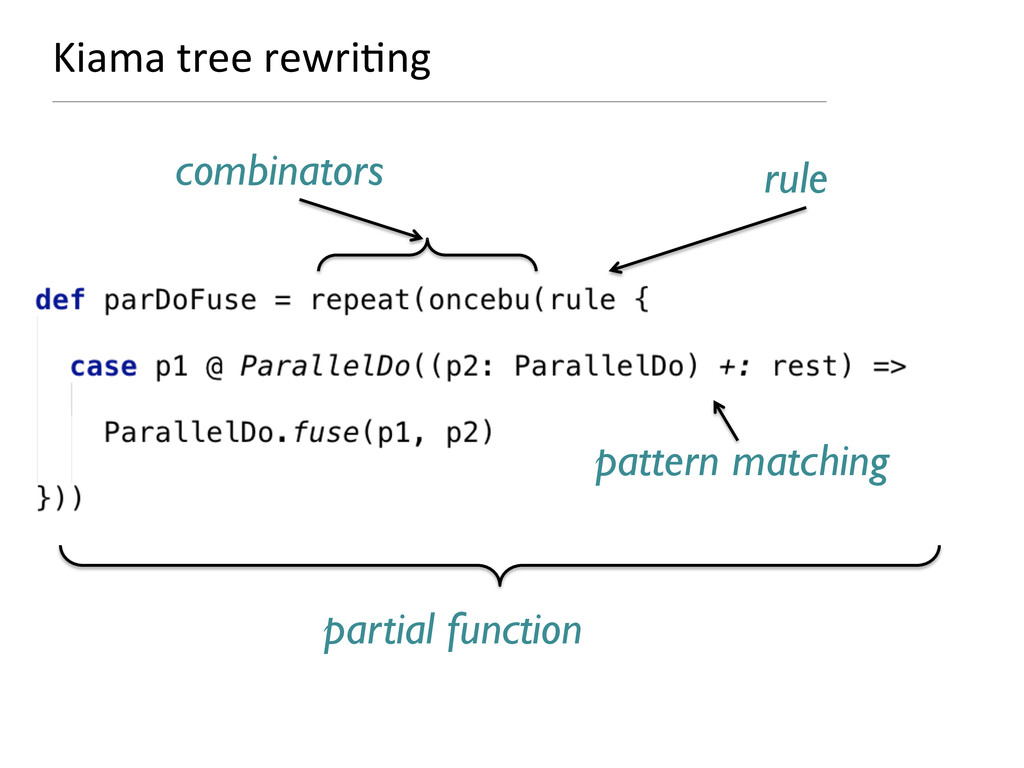
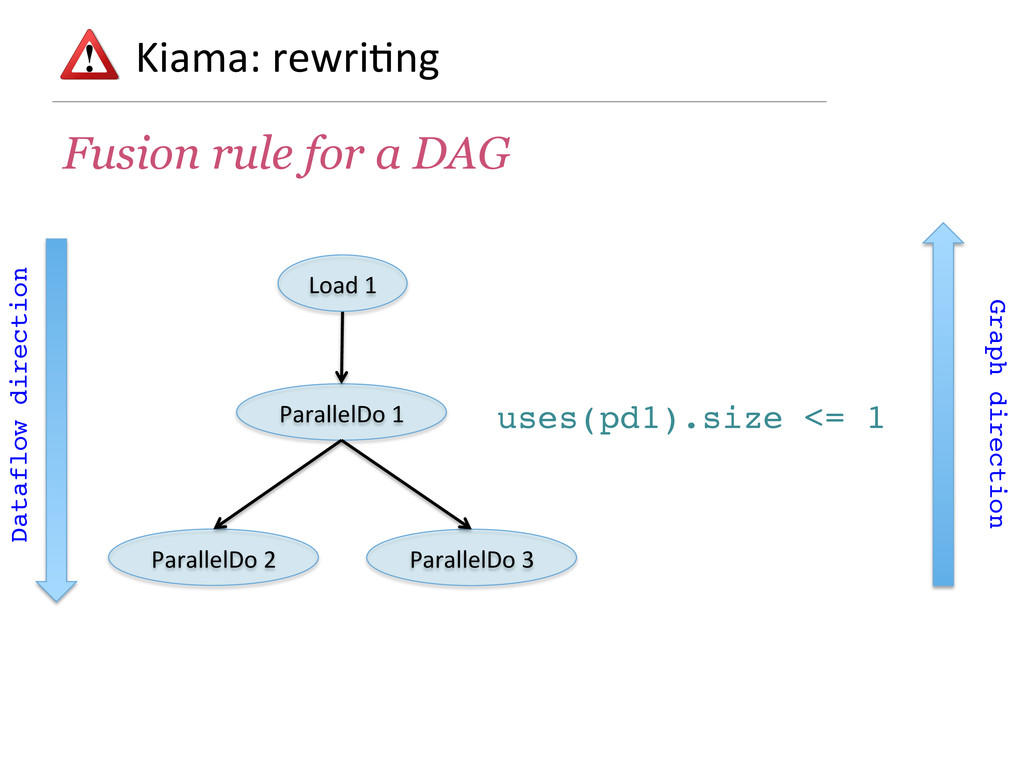
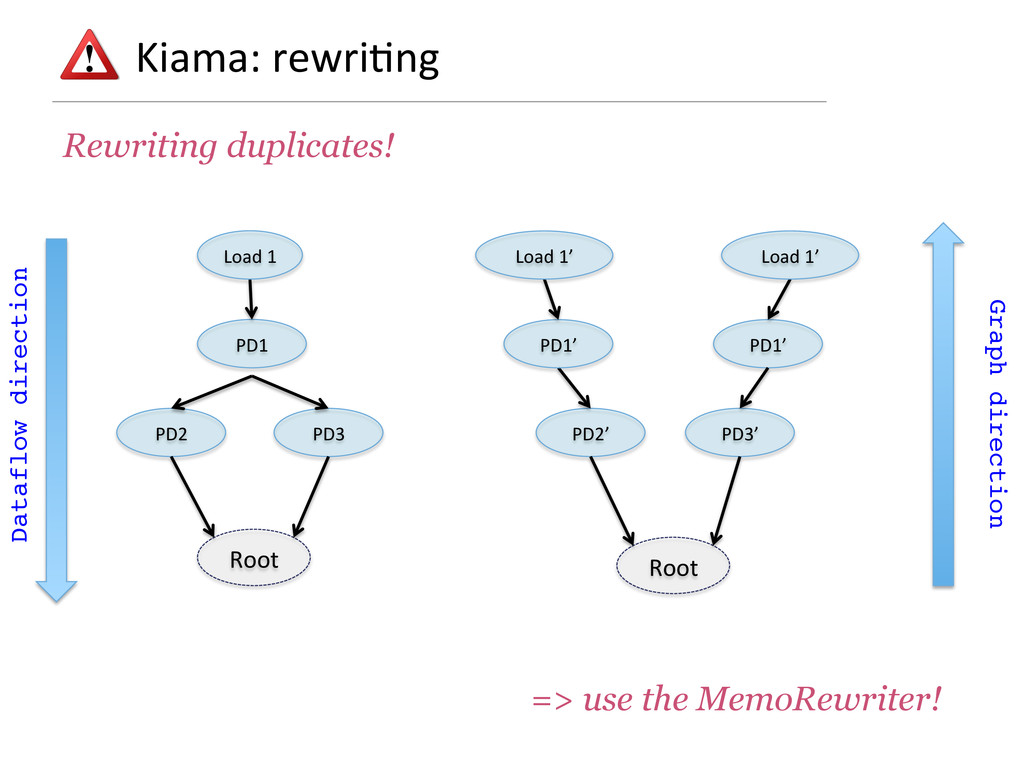
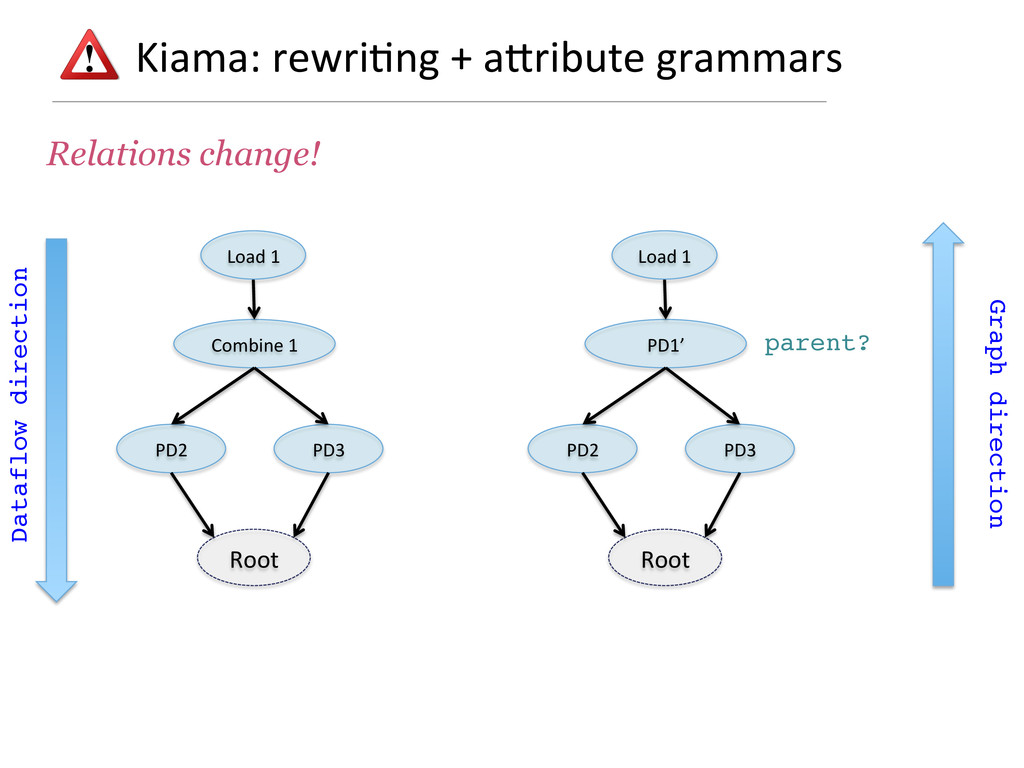
- How rewriting rules based on partial functions are a very succinct way to pre-process the computation graph and to optimise it.
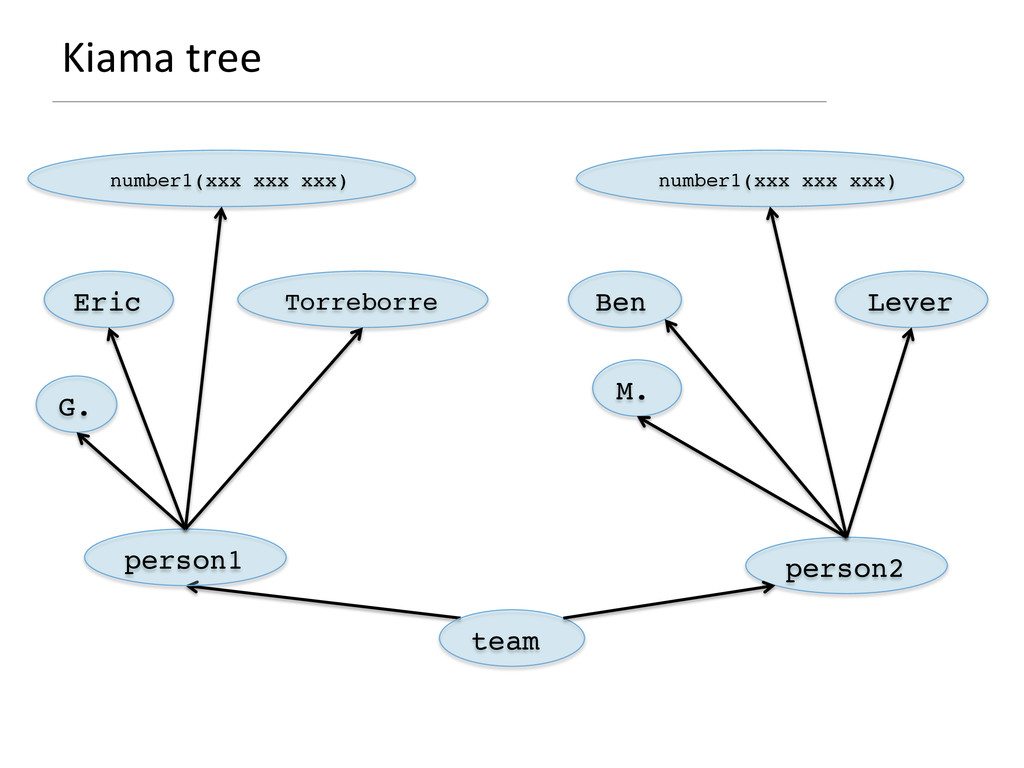
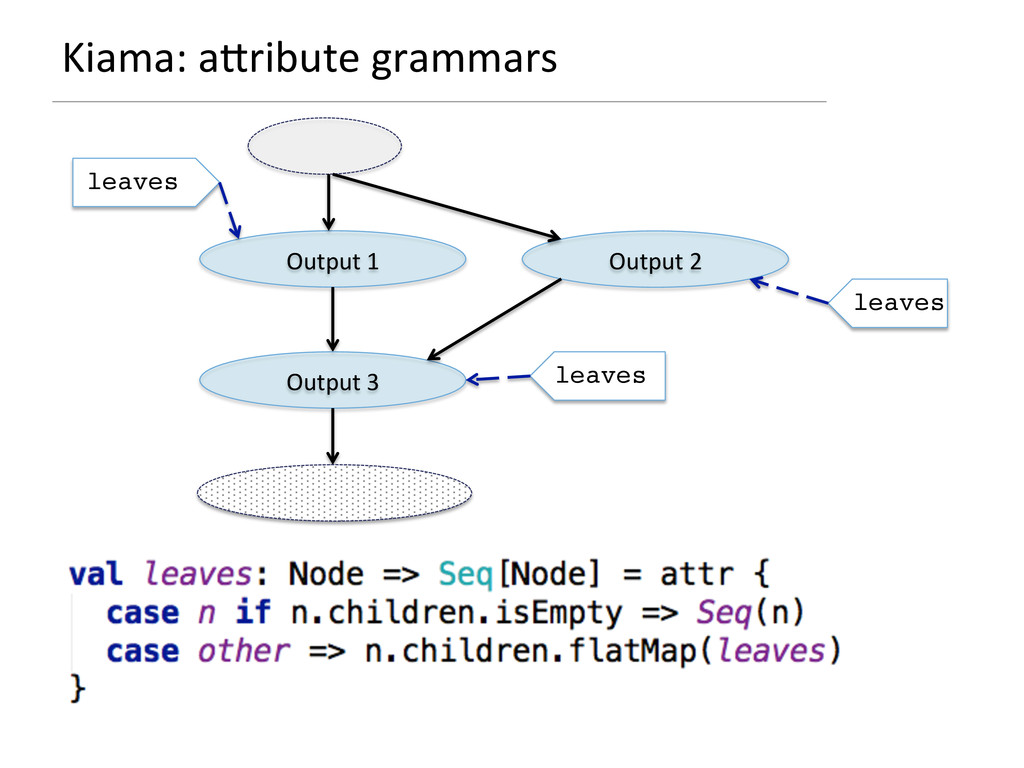
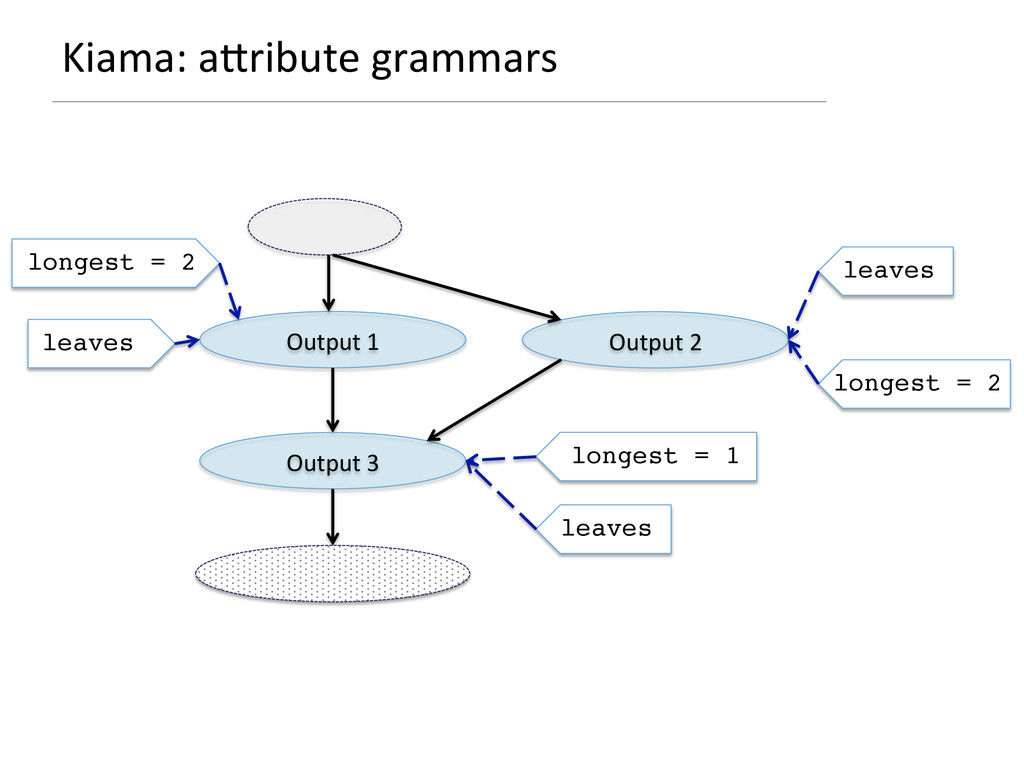
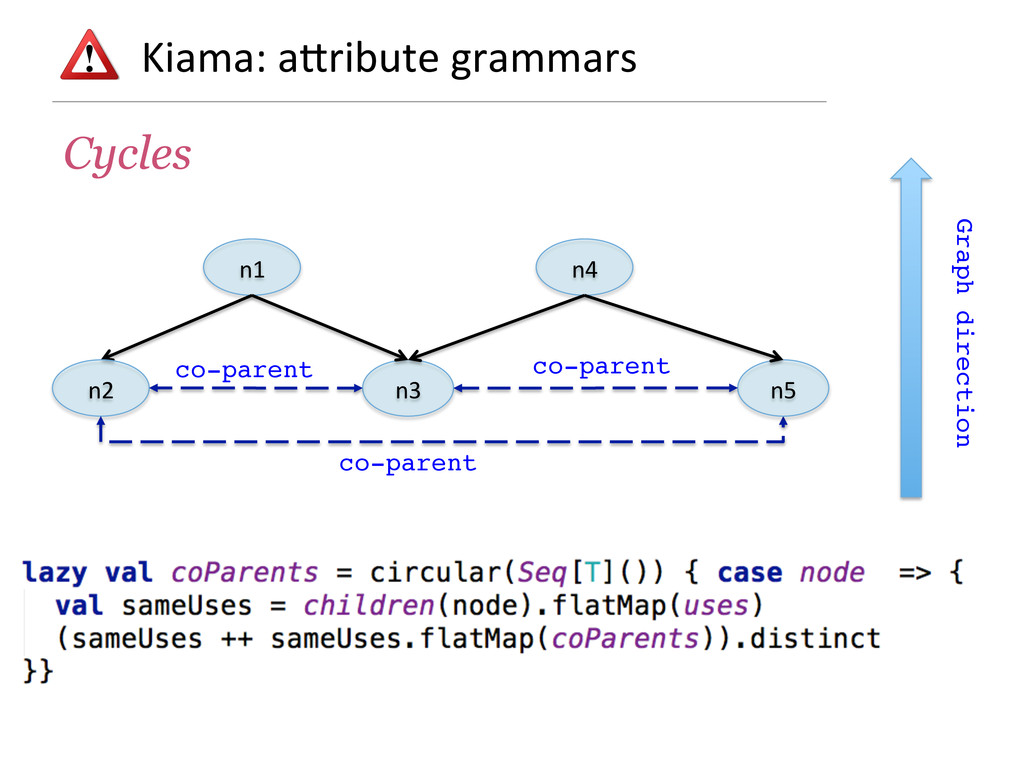
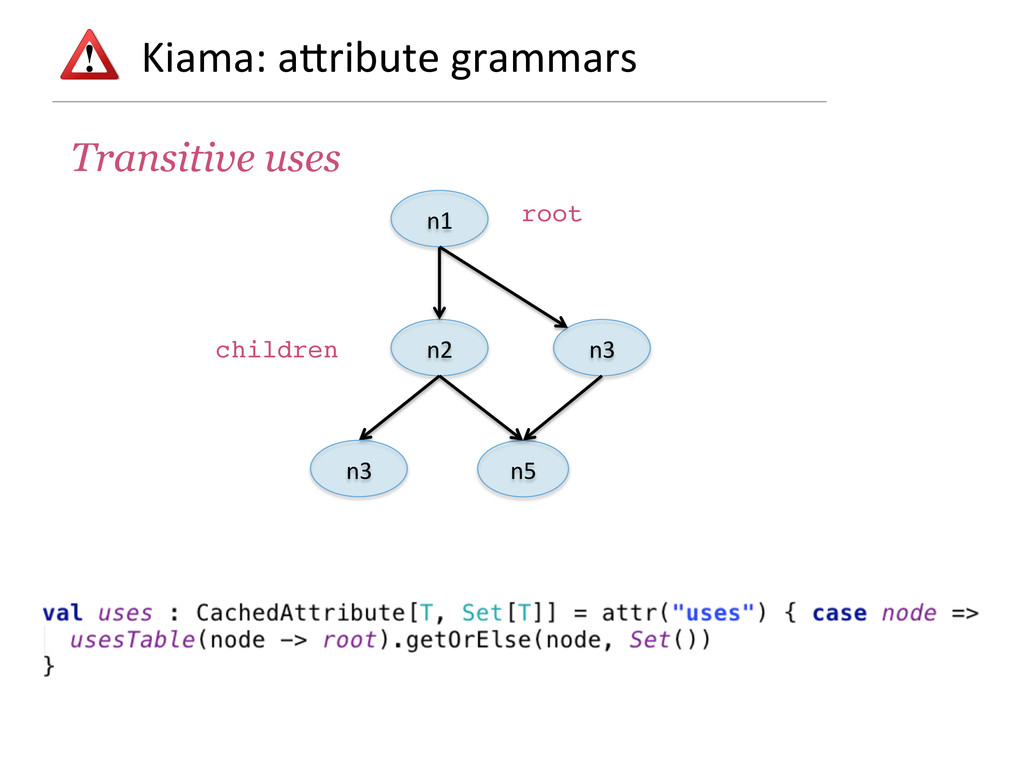
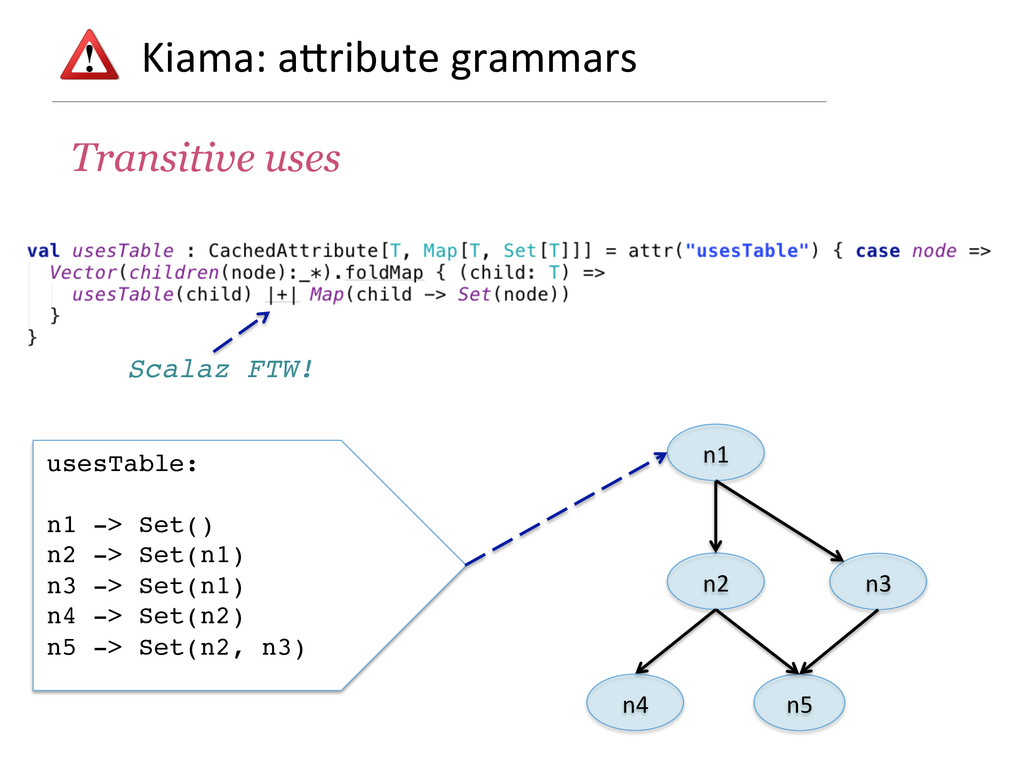
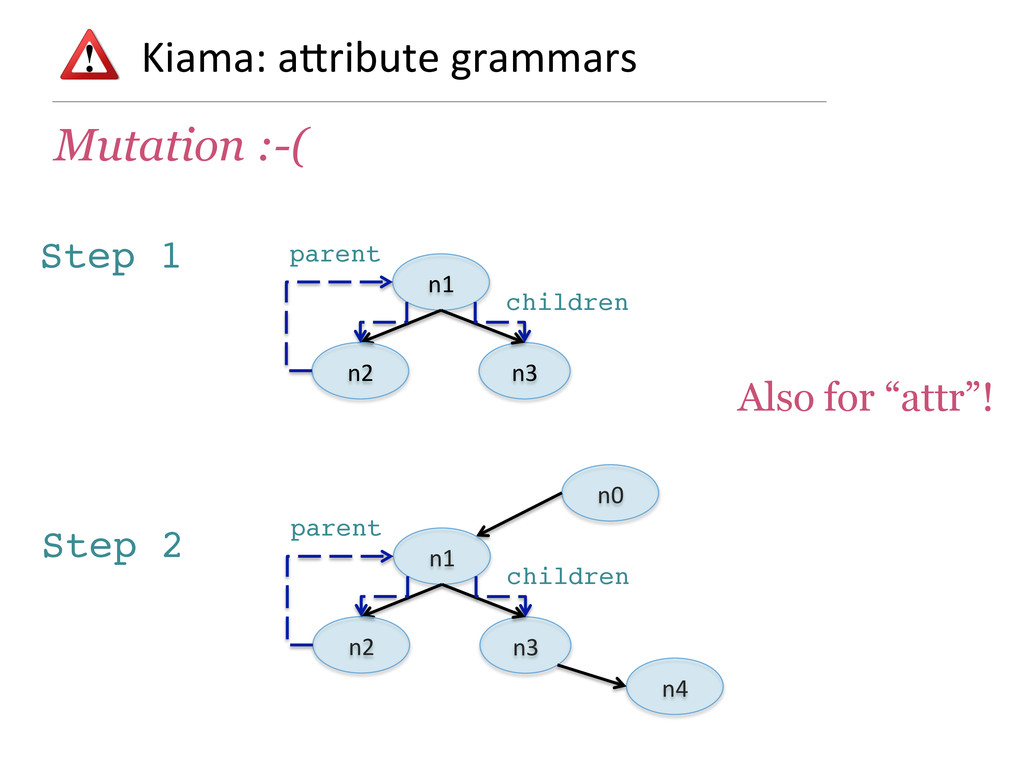
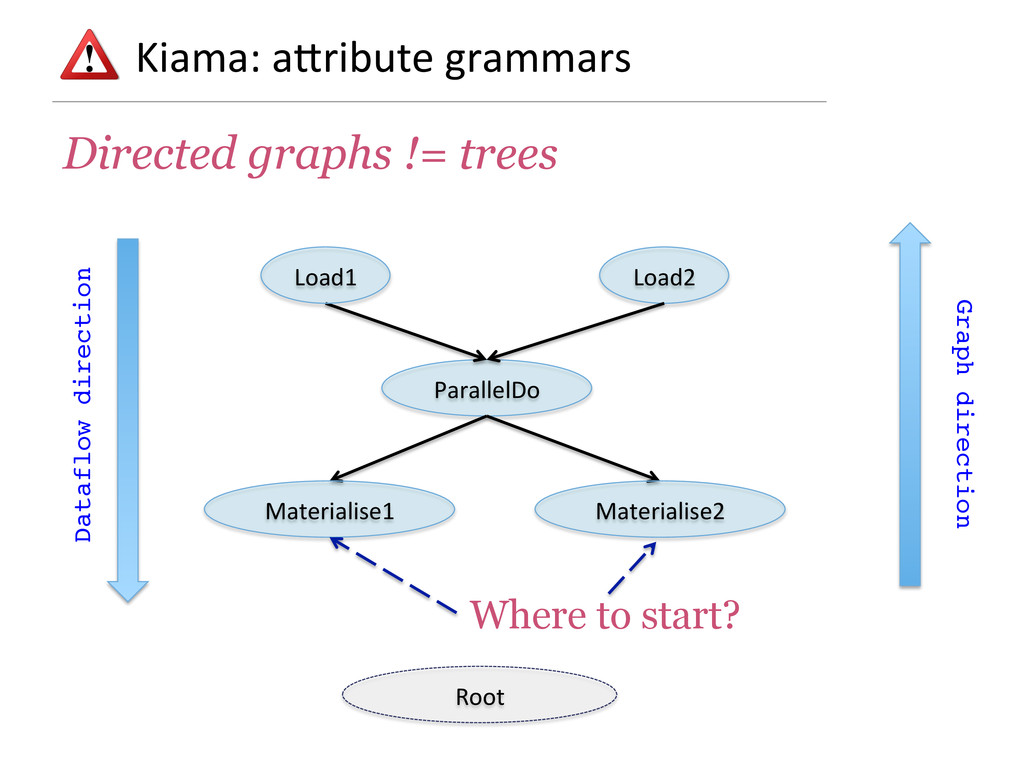
- How attribute grammars can be used to implement general graph traversal algorithms
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![A collection-like DSL String! (Int, Int)! (Int, Iterable[Int])! (Int, Int)!](https://files.speakerdeck.com/presentations/9649cb00b90b0130698a765695d1adda/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
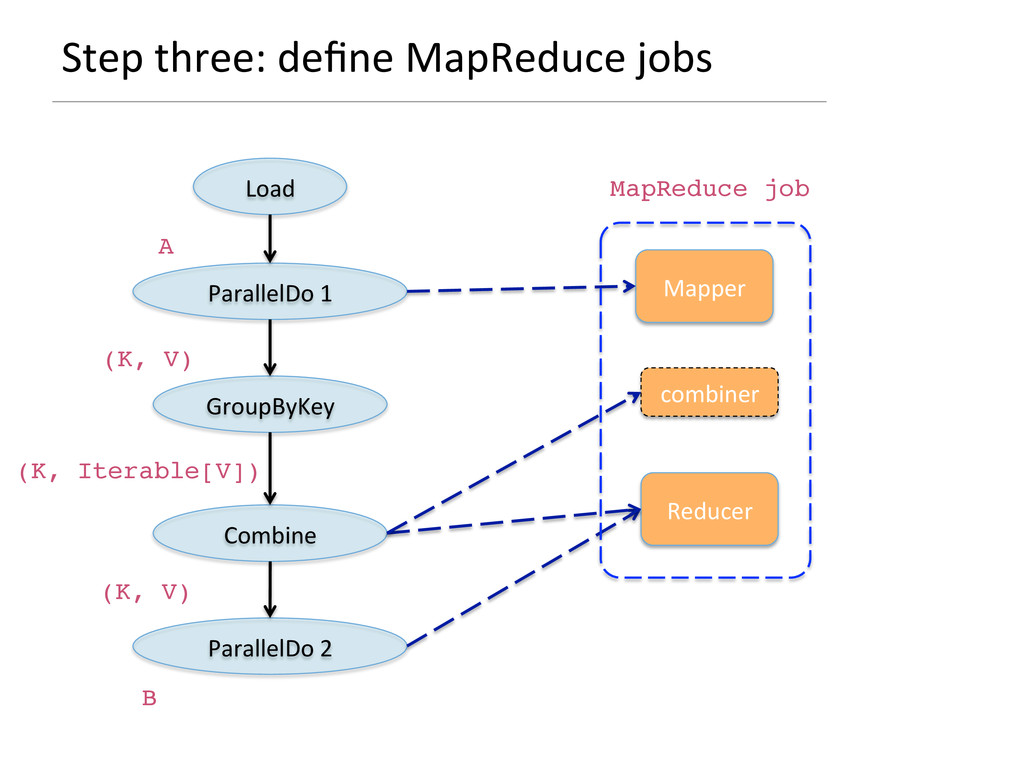{kind=link}
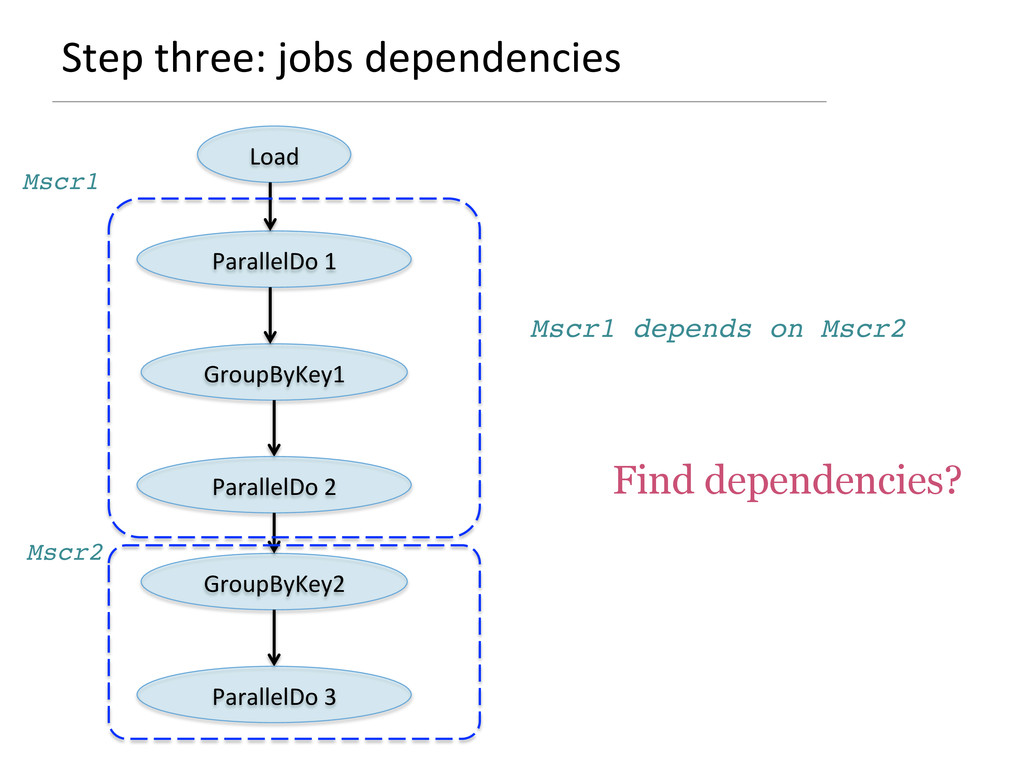{kind=link}
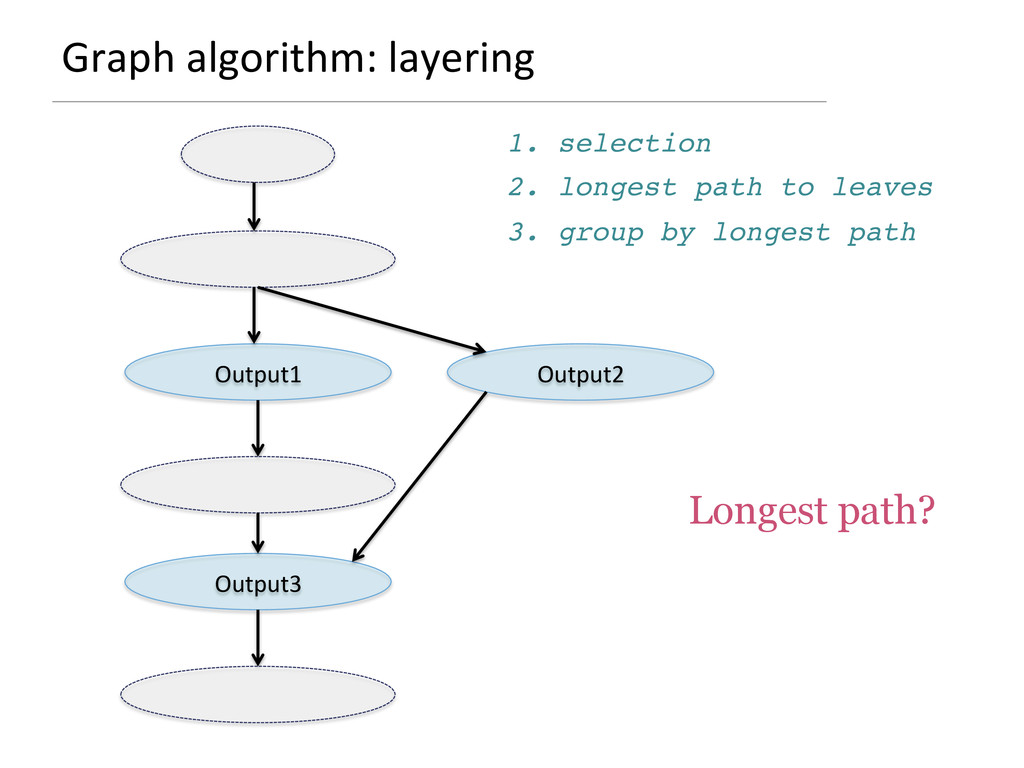{kind=link}
{kind=link}
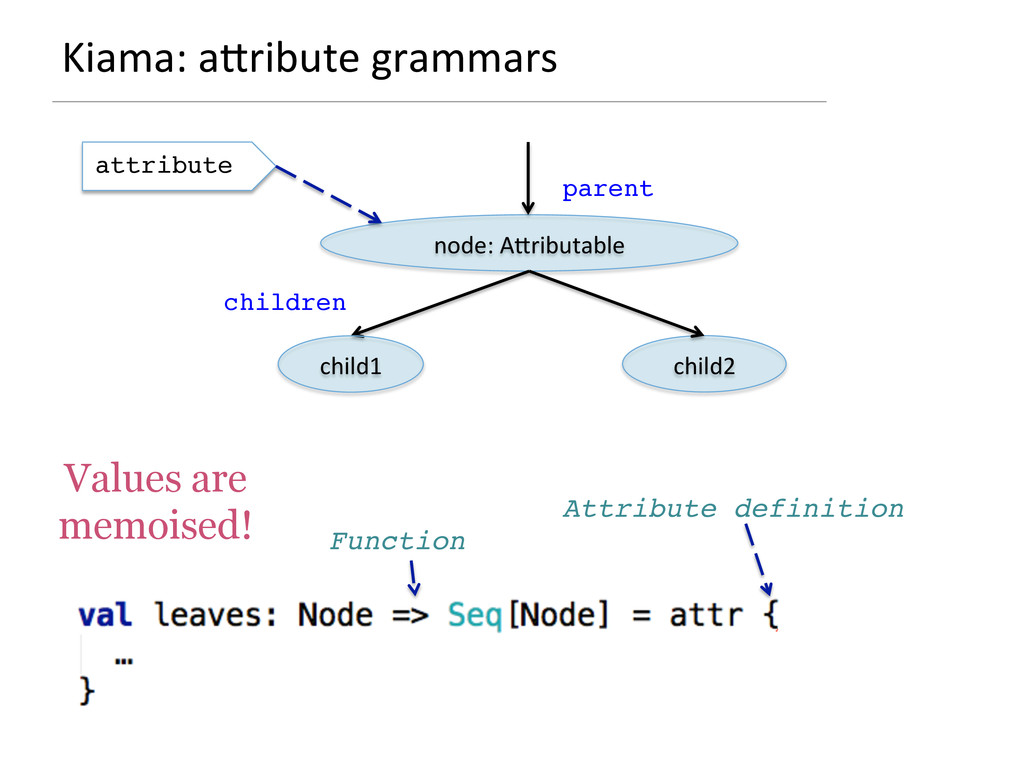{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
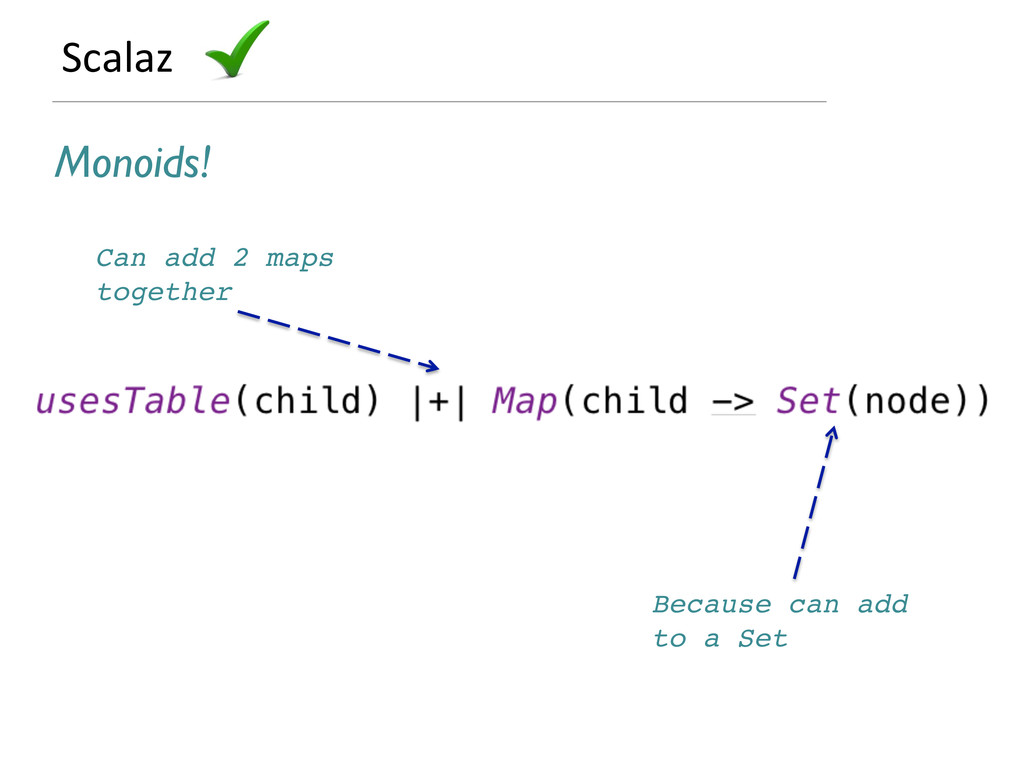
![Scalaz Update of a Map[K, Collection[V]] 1. if the](https://files.speakerdeck.com/presentations/9649cb00b90b0130698a765695d1adda/slide_53.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}