Evans University of Virginia work mostly with Weilin Xu and Yanjun Qi evadeML.org Center for IT-Security, Privacy and Accountability, Universität des Saarlandes 10 July 2017
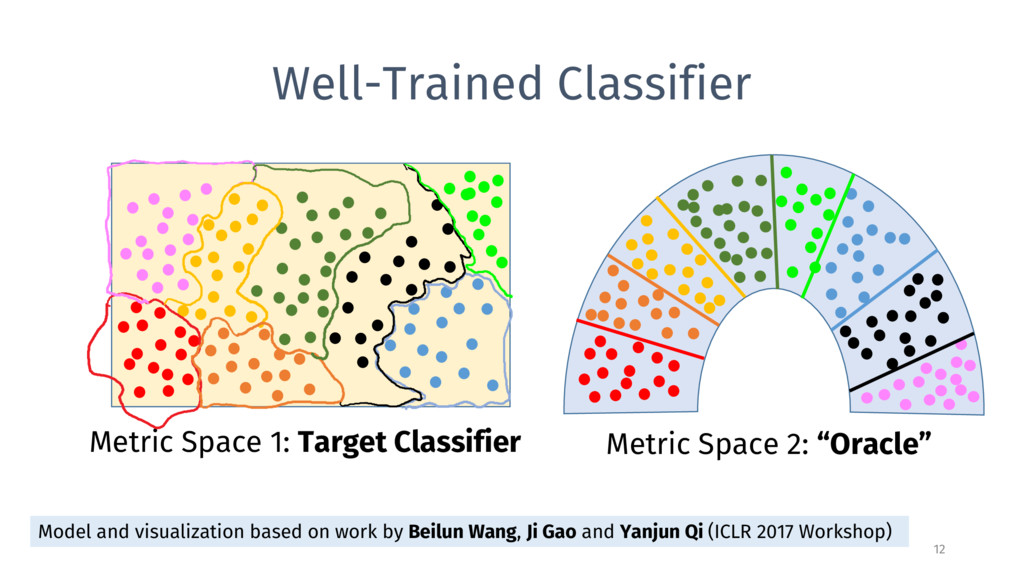
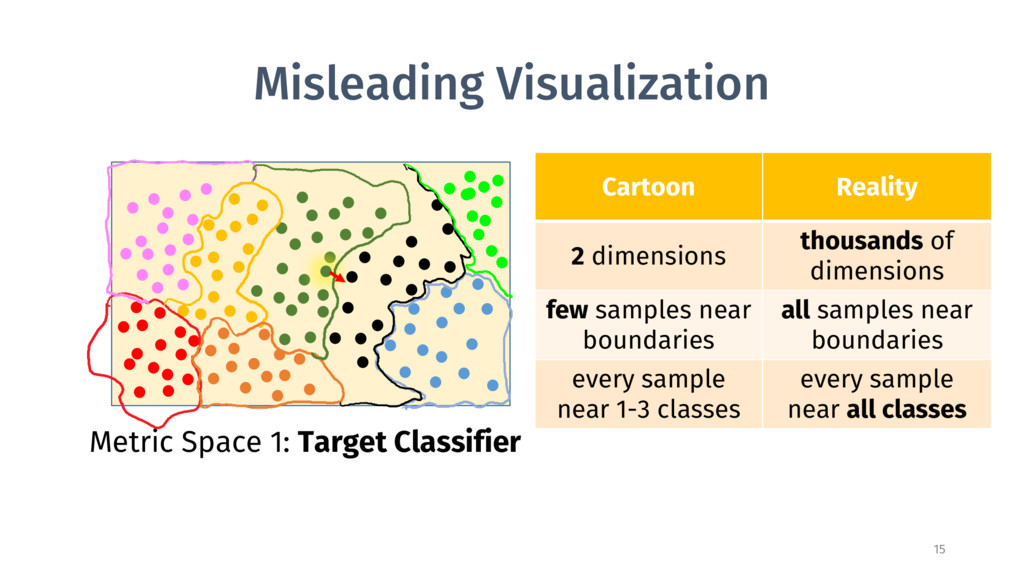
2 dimensions thousands of dimensions few samples near boundaries all samples near boundaries every sample near 1-3 classes every sample near all classes
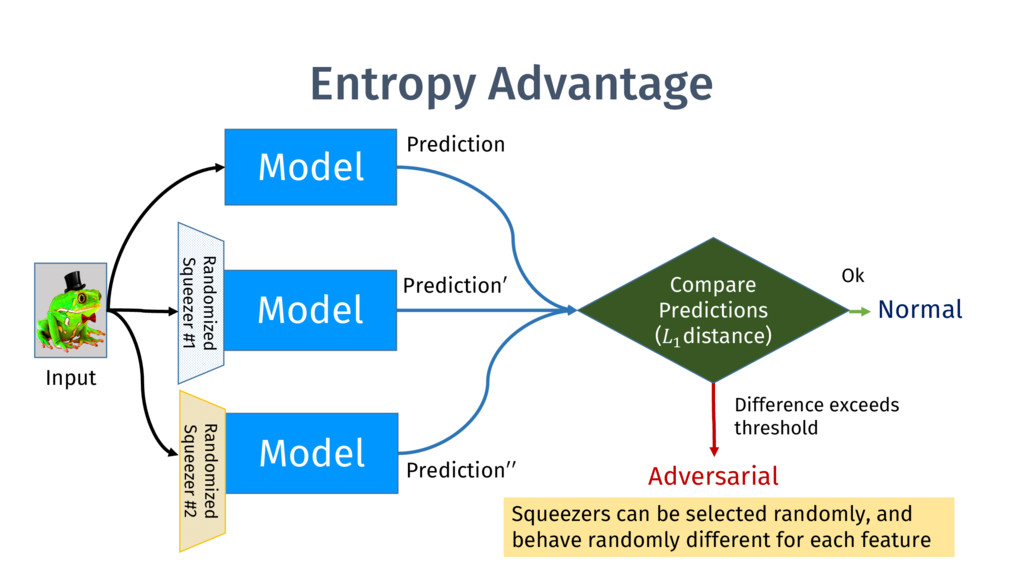
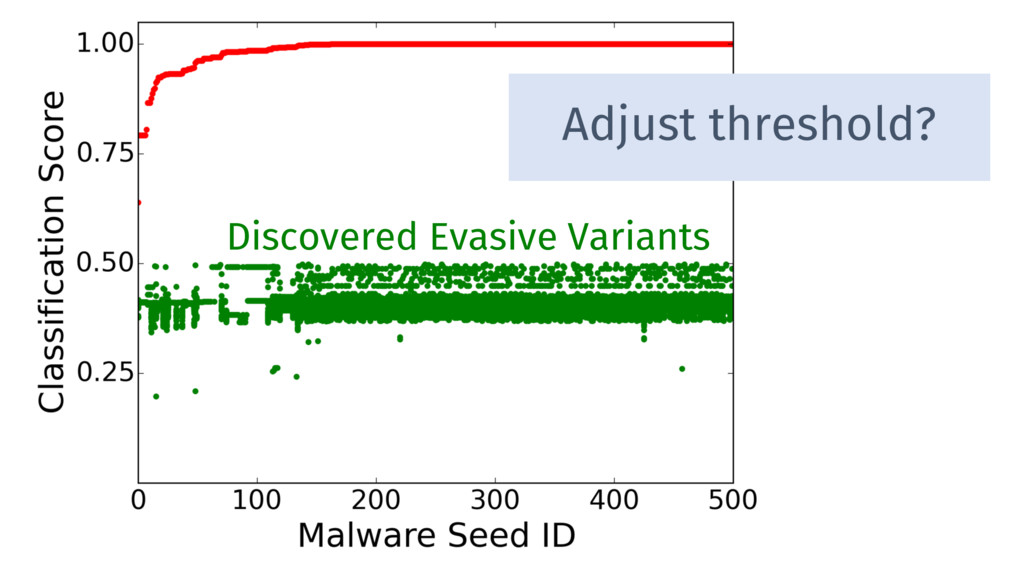
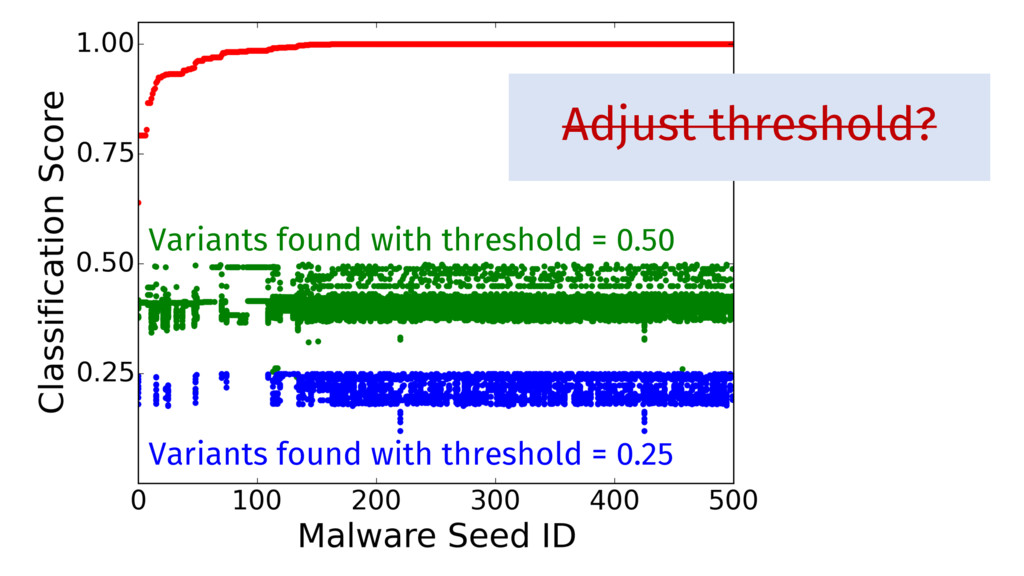
Prediction′′ Compare Predictions Difference exceeds threshold Reject Prediction Ok Input Need filters that do not affect predictions on normal inputs, but that reverse malicious perturbations.
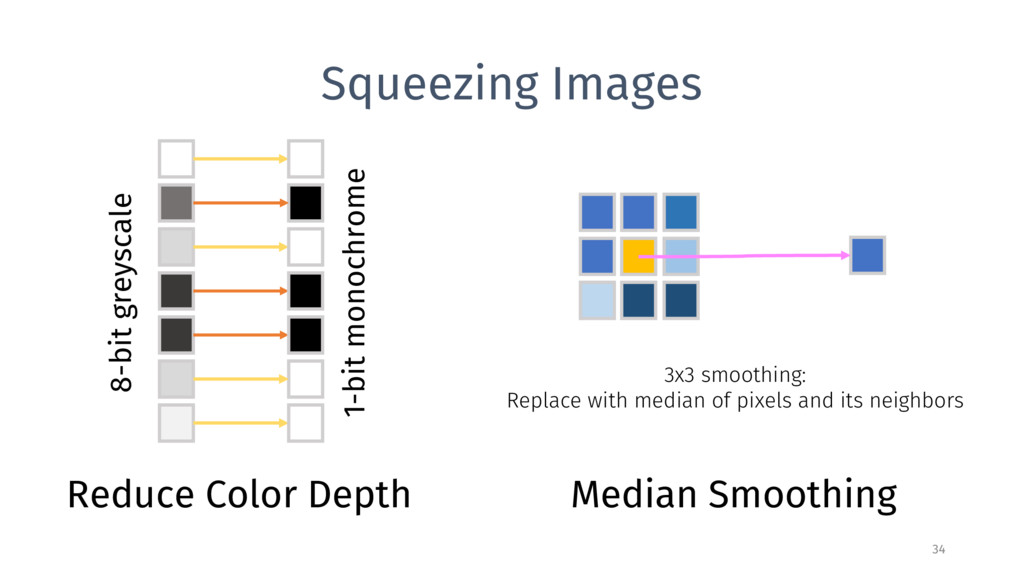
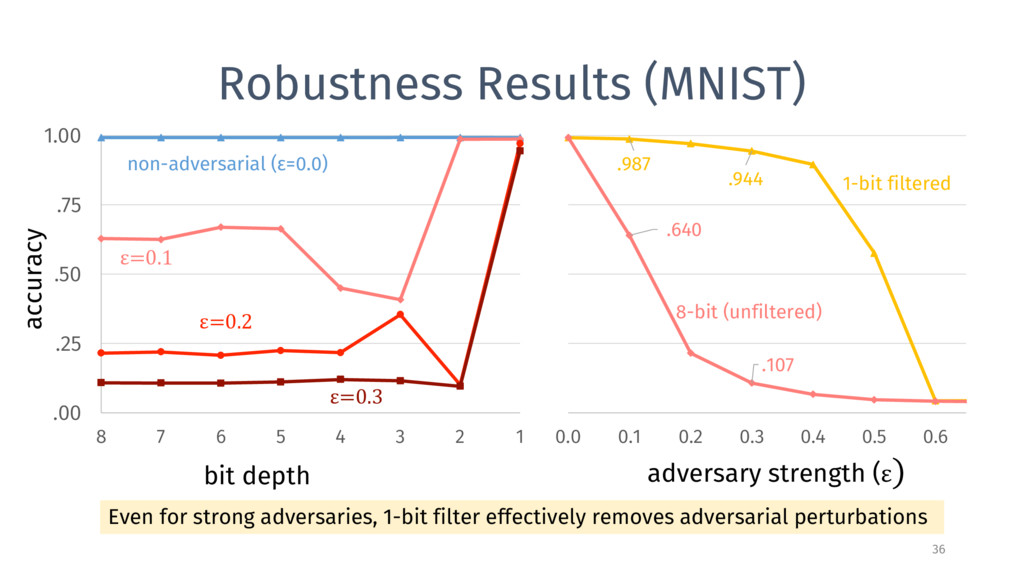
3 2 1 .9930 .9930 .9930 .9930 .9930 .9928 .9926 .9924 Reducing bit depth (all the way to 1) barely reduces model accuracy! Correct on original image, wrong on 1-bit filtered image (19) Wrong on original image, correct on 1-bit filtered image (13) (out of 10 000 MNIST test images) Both wrong, but differently
Examples MNIST C 0.0 D 0.0 9 0.0 CIFAR-10 C 0.0 D 0.0 9 0.0 Nicholas Carlini, David Wagner. Oakland 2017 (Best Student Paper) Adversary suceeds 100% of the time with very small perturbations “Our D attacks on ImageNet are so successful that we can change the classification of an image to any desired label by only flipping the lowest bit of each pixel, a change that would be impossible to detect visually.”
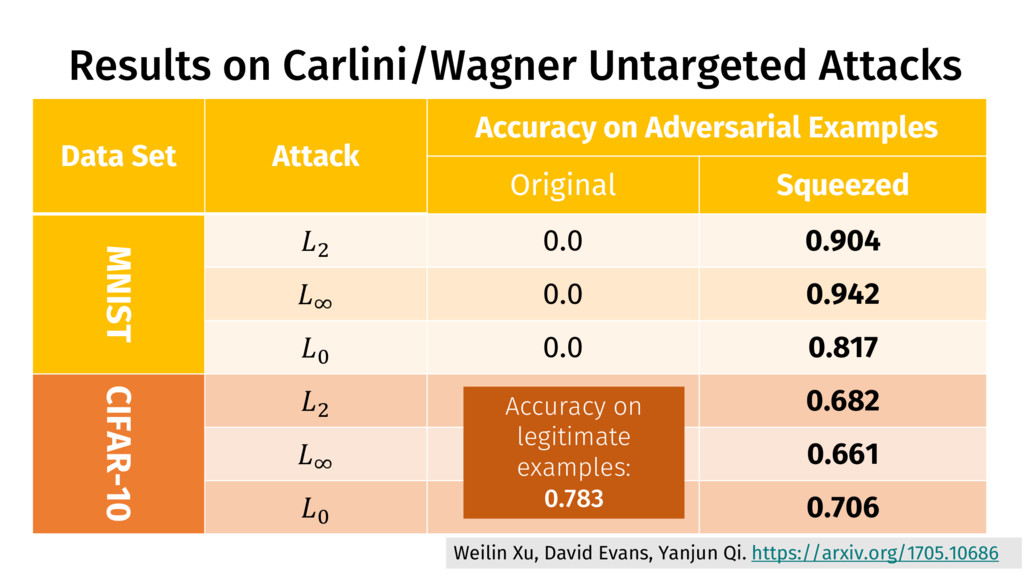
Yanjun Qi. https://arxiv.org/1705.10686 Data Set Attack Accuracy on Adversarial Examples Original Squeezed MNIST C 0.0 0.904 D 0.0 0.942 9 0.0 0.817 CIFAR-10 C 0.0 0.682 D 0.0 0.661 9 0.0 0.706
Yanjun Qi. https://arxiv.org/1705.10686 Data Set Attack Accuracy on Adversarial Examples Original Squeezed MNIST C 0.0 0.904 D 0.0 0.942 9 0.0 0.817 CIFAR-10 C 0.0 0.682 D 0.0 0.661 9 0.0 0.706 Accuracy on legitimate examples: 0.783
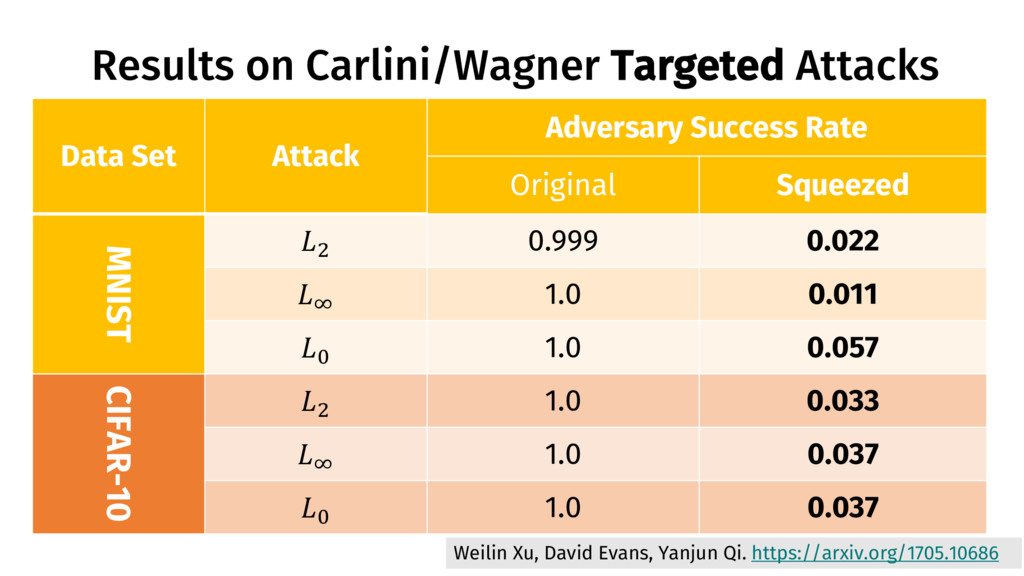
Yanjun Qi. https://arxiv.org/1705.10686 Data Set Attack Adversary Success Rate Original Squeezed MNIST C 0.999 0.022 D 1.0 0.011 9 1.0 0.057 CIFAR-10 C 1.0 0.033 D 1.0 0.037 9 1.0 0.037
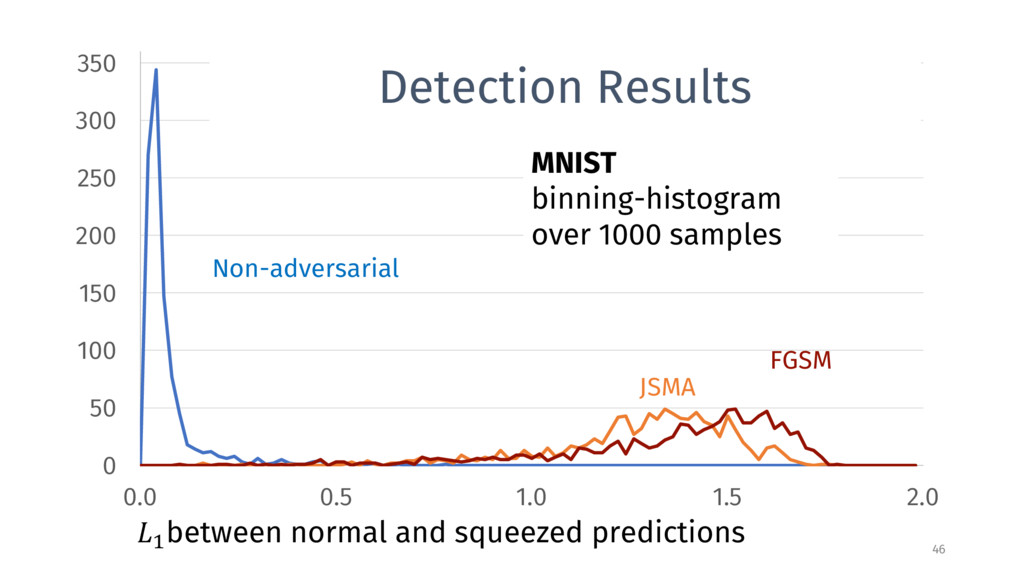
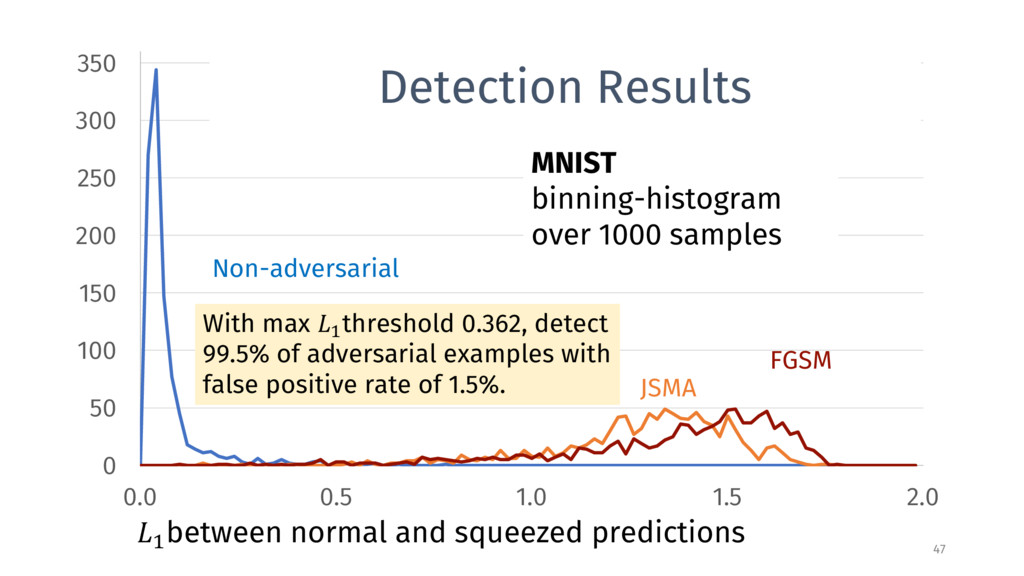
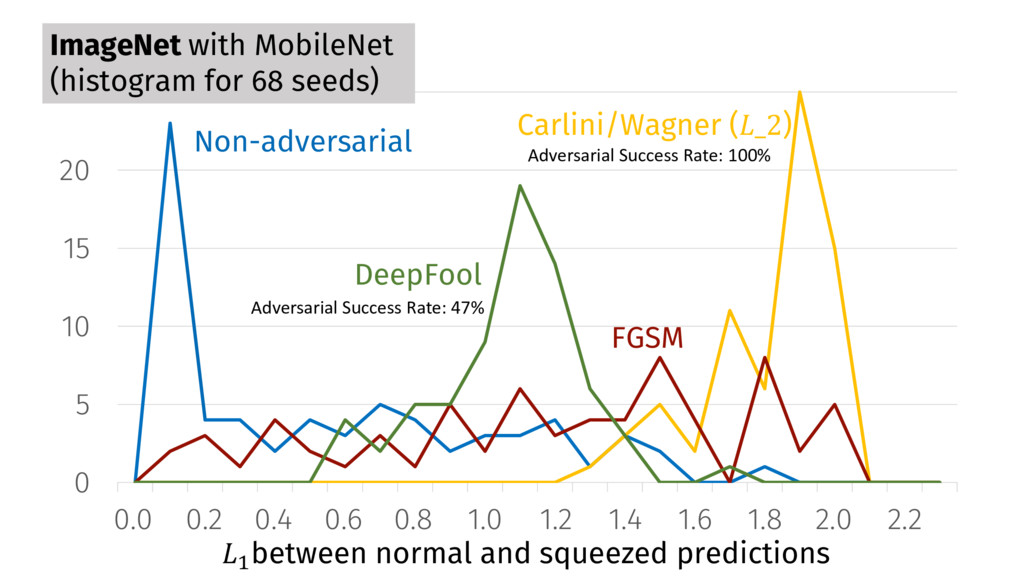
0.5 1.0 1.5 2.0 FGSM Non-adversarial JSMA > between normal and squeezed predictions MNIST binning-histogram over 1000 samples Detection Results With max > threshold 0.362, detect 99.5% of adversarial examples with false positive rate of 1.5%.
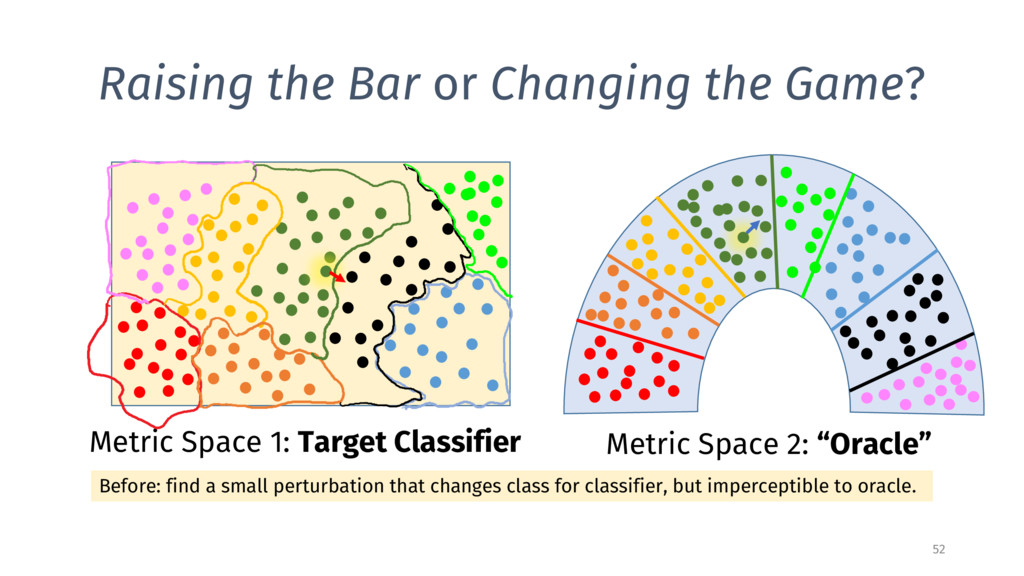
1: Target Classifier Metric Space 2: “Oracle” Before: find a small perturbation that changes class for classifier, but imperceptible to oracle. Now: change class for both original and squeezed classifier, but imperceptible to oracle.
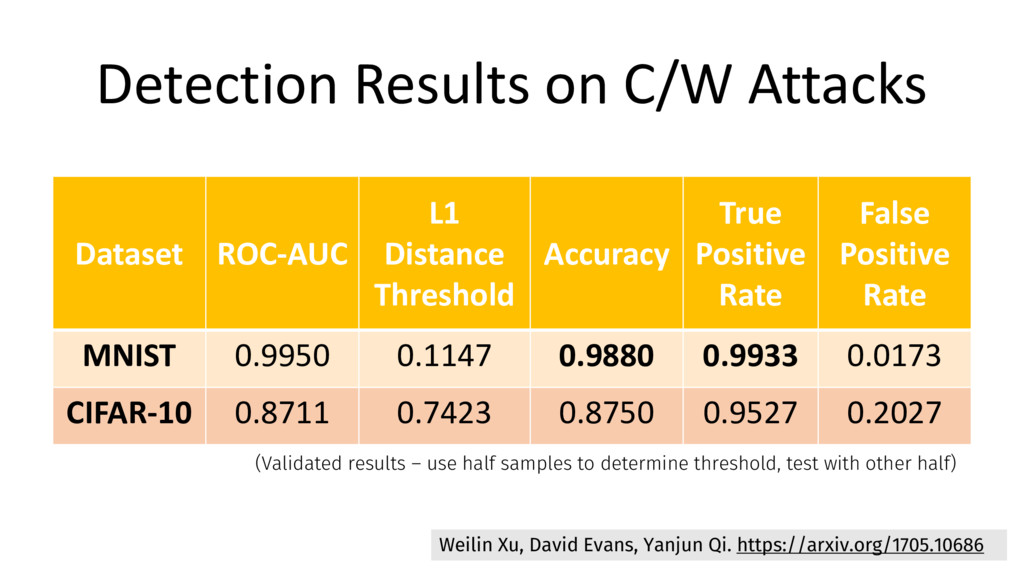
some feature squeezer that accurately detects its adversarial examples. 54 Intuition: if the perturbation is small (in some simple metric space), there is some squeezer that coalesces original and adversarial example into same sample.
Prediction′′ Compare Predictions (> distance) Difference exceeds threshold Adversarial Normal Ok Input Randomized Squeezer #2 Squeezers can be selected randomly, and behave randomly different for each feature
which it is intractable to find effective feature squeezer. Option 2: Redefine adversarial examples so distance is not limited (in simple metric space). 56 focus of rest of the talk
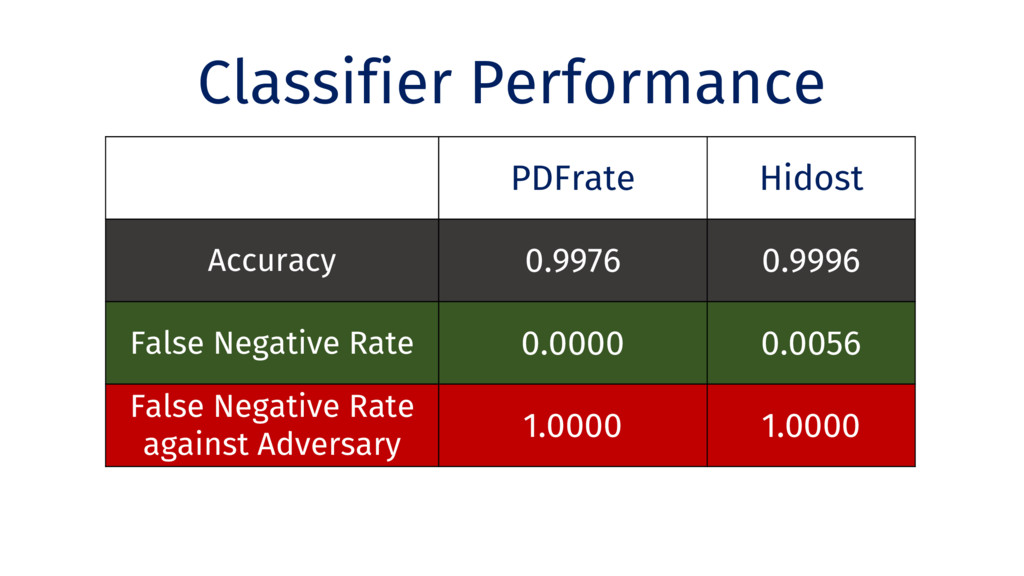
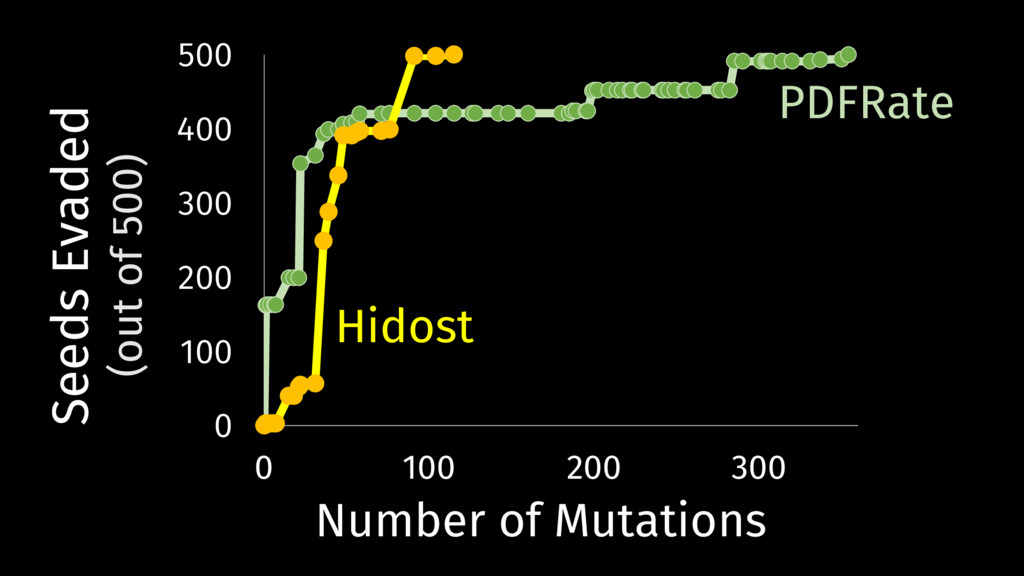
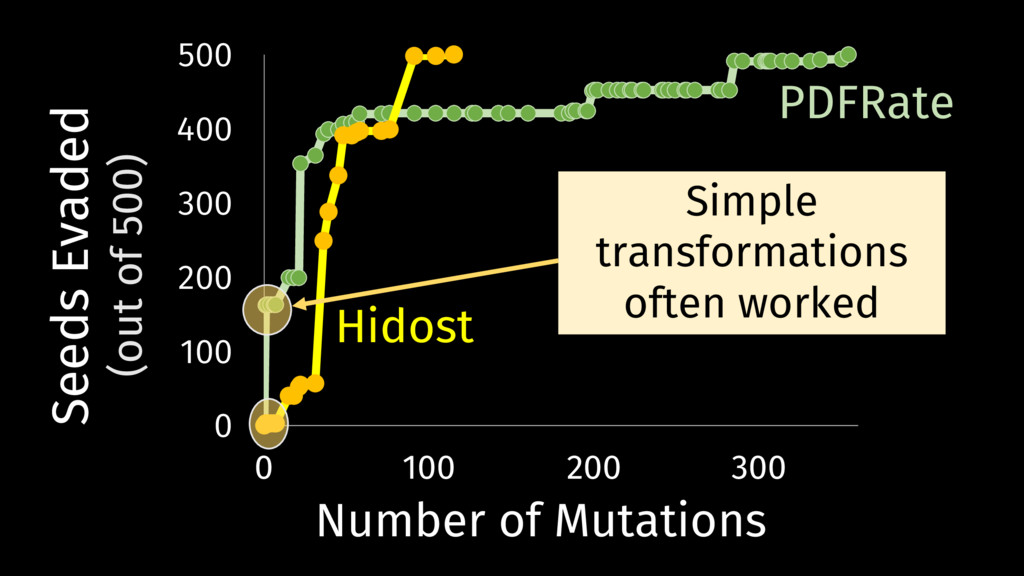
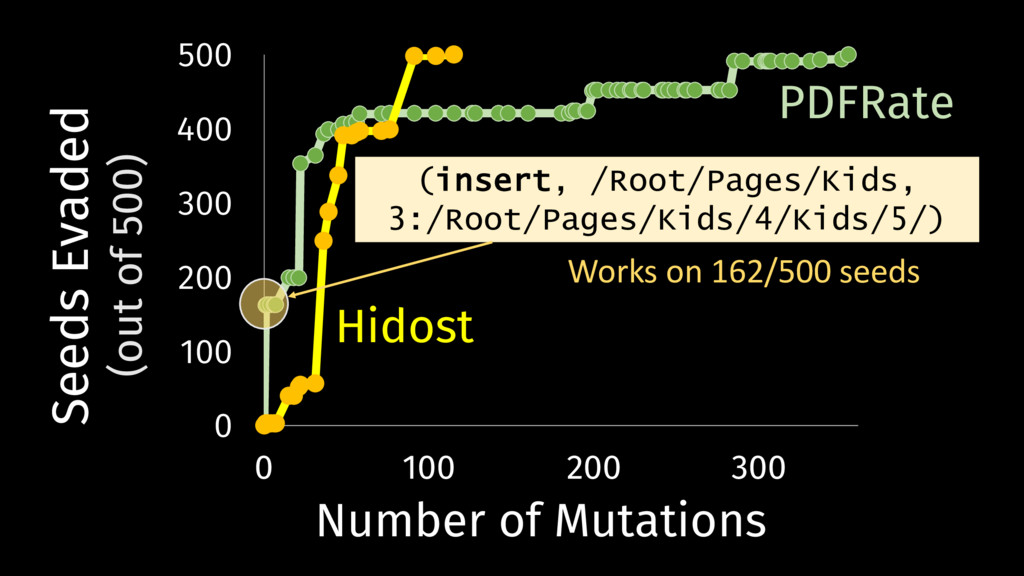
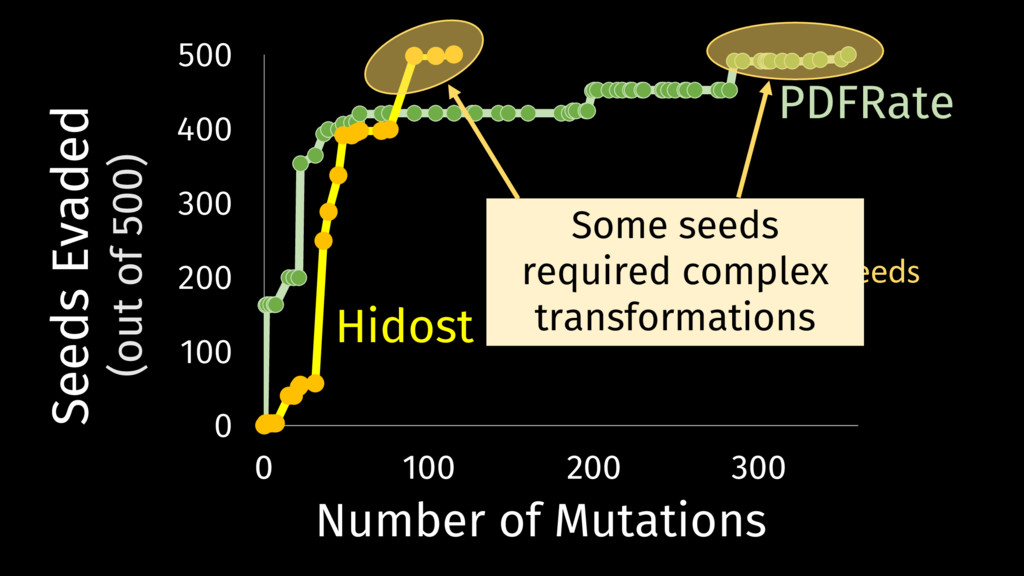
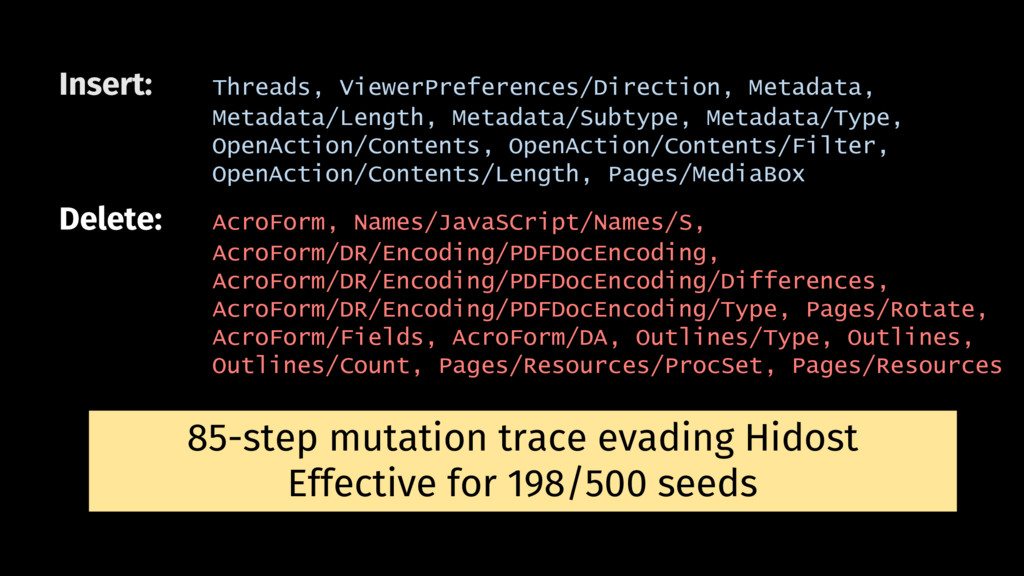
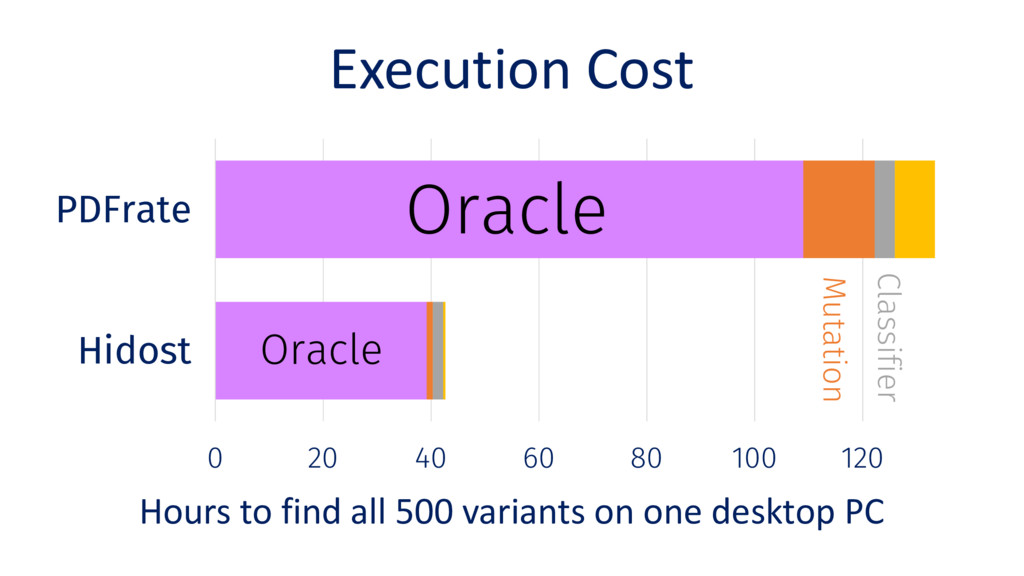
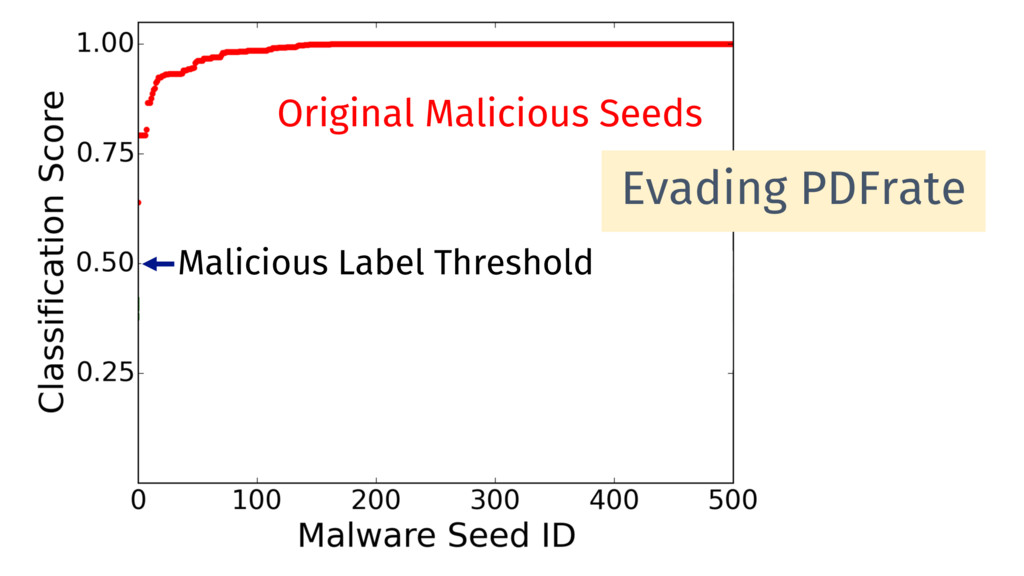
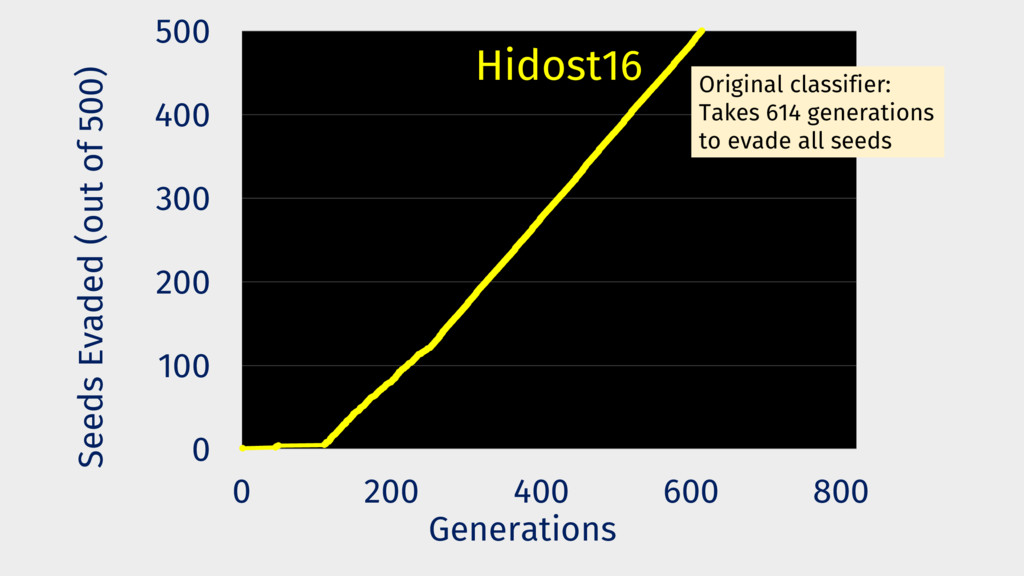
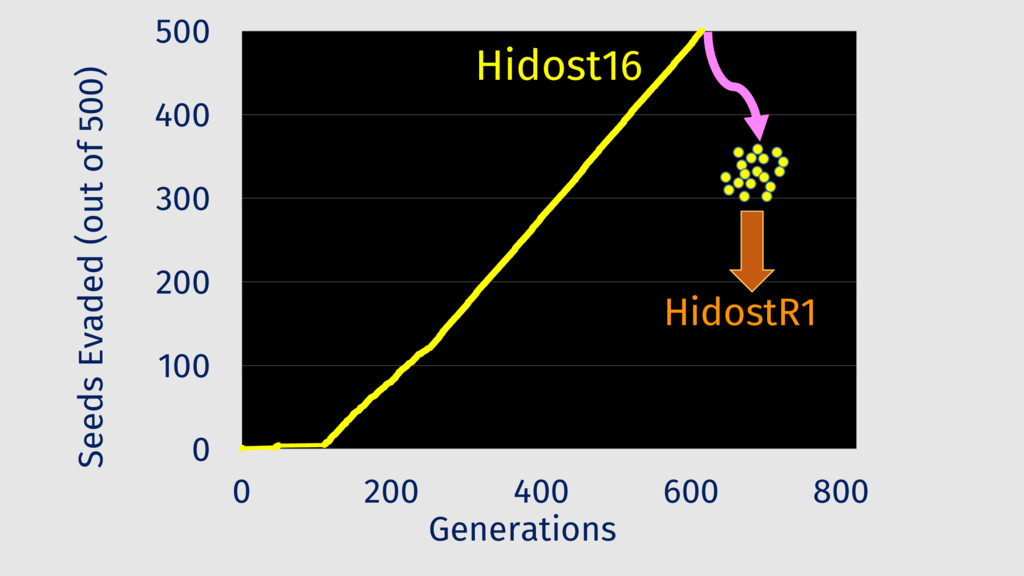
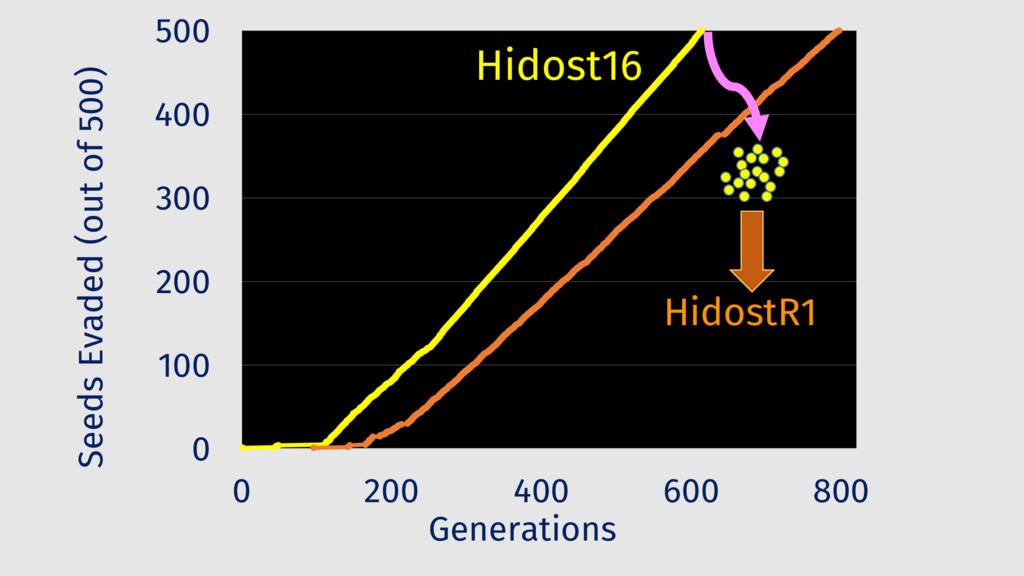
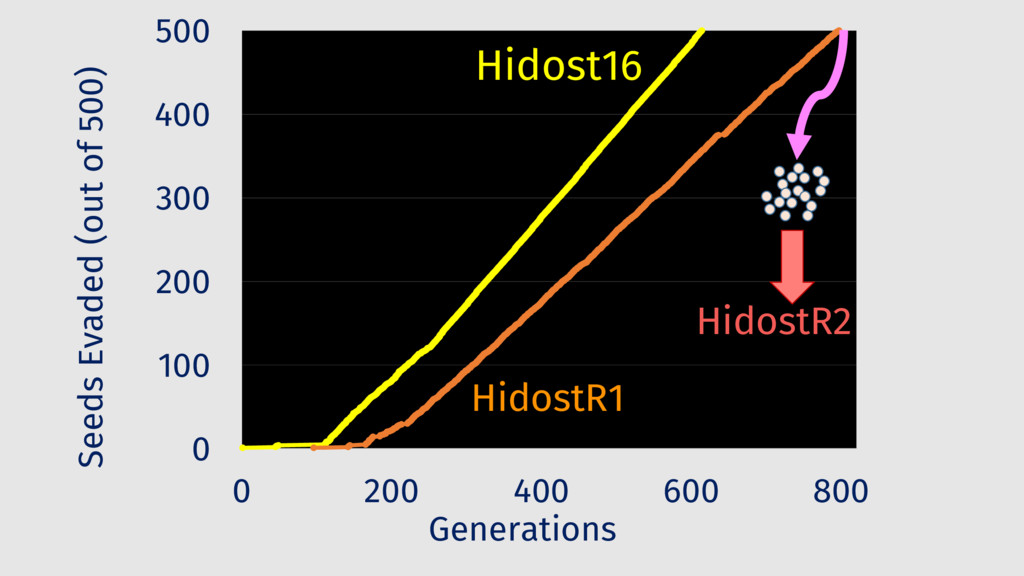
Behavioral signature: malicious if signature matches https://github.com/cuckoosandbox Simulated network: INetSim Cuckoo HTTP_URL + HOST extracted from API traces Advantage: we know the target malware behavior
without understanding vulnerable • Adversaries can exploit unnecessary features Trust Requires Understanding • Good results against test data do not apply to adaptive adversaries but there is hope for building robust ML models!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Adversarial Examples 10 0.007 × [] + = “panda” “gibbon”](https://files.speakerdeck.com/presentations/bbcd3186278f496bacabe2e6fc9a33ae/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
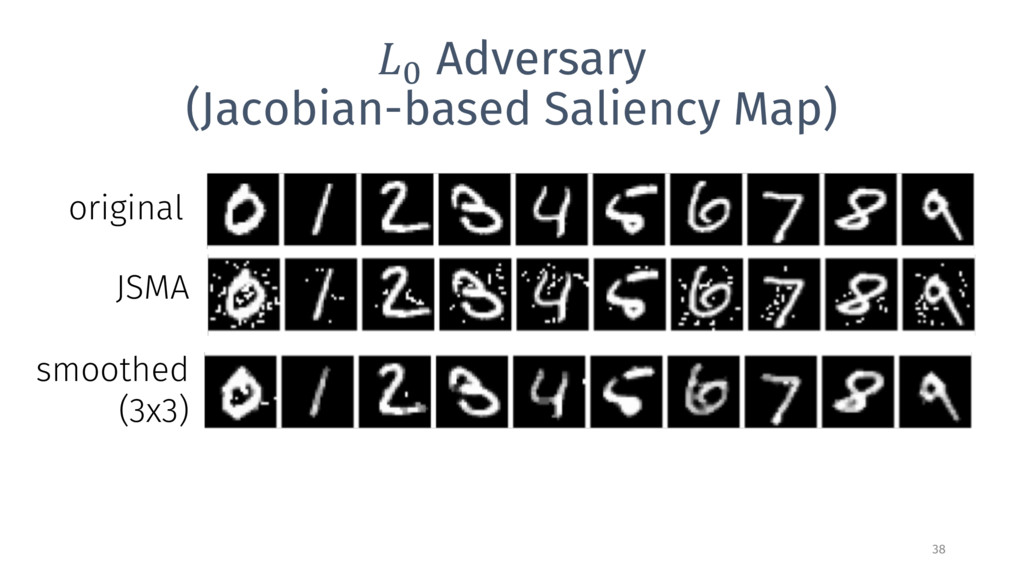{kind=link}
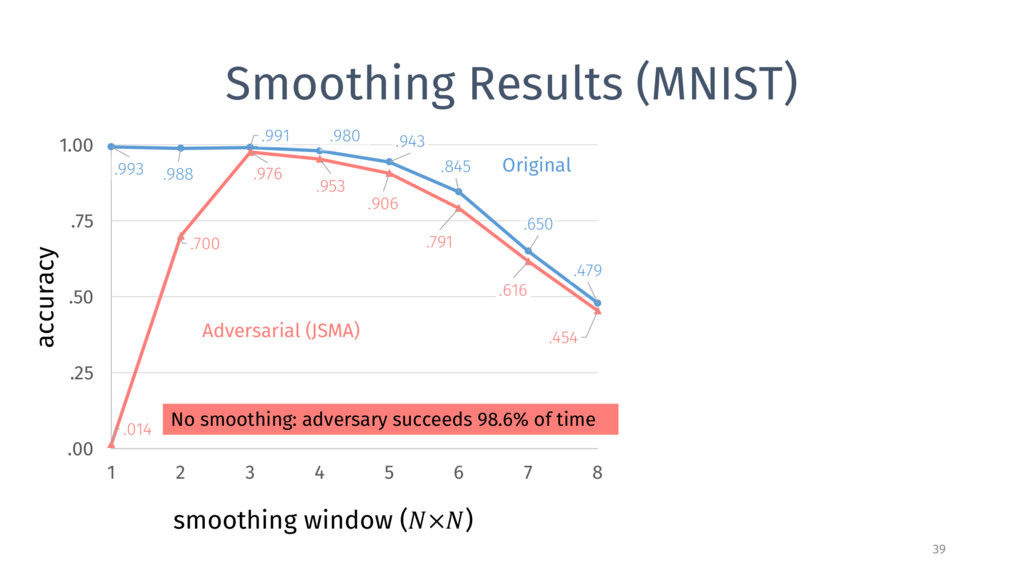{kind=link}
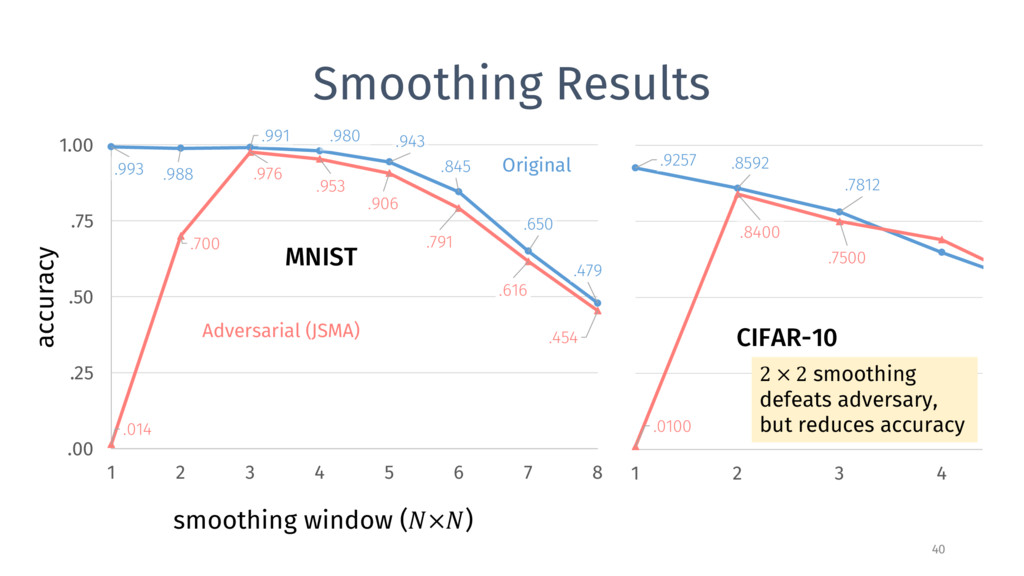{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![David Evans University of Virginia [email protected] EvadeML.org source code, papers](https://files.speakerdeck.com/presentations/bbcd3186278f496bacabe2e6fc9a33ae/slide_107.jpg){kind=link}