No matter what you web application does, it's likely that you can get value from having a background processing framework. With Node.js, there are a number of unique things we can do to handle jobs outside of the request cycle or get high parallelism from our singe event-loop thread. This talk will look at a number of approaches and philosophies to do just that!
Presented at the Feb 2015 NodeSF meetup (http://www.meetup.com/sfnode/events/219155830/)
Supporting Code: https://github.com/evantahler/background_jobs_node
{kind=link}
{kind=link}
{kind=link}
{kind=link}
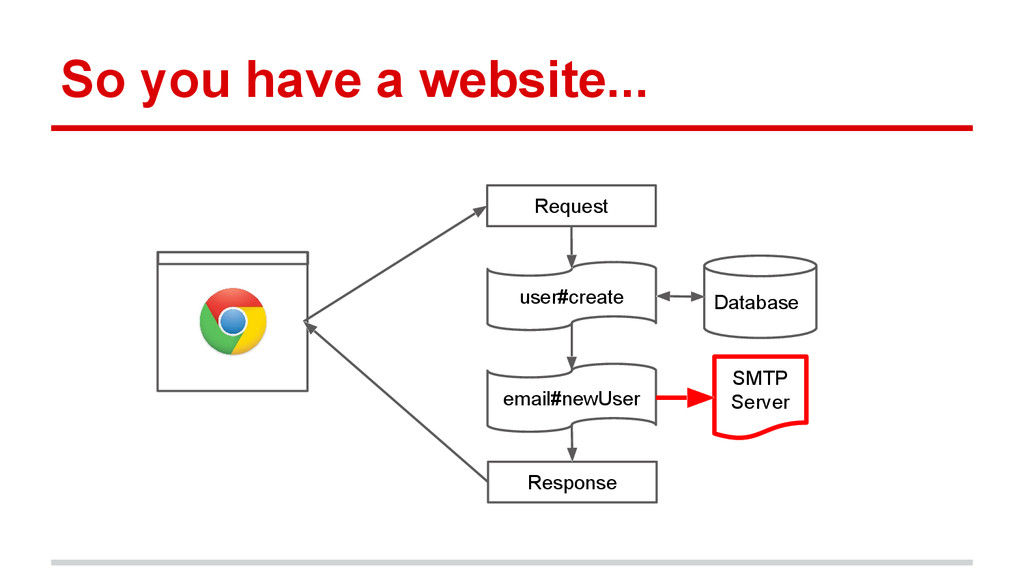{kind=link}
{kind=link}
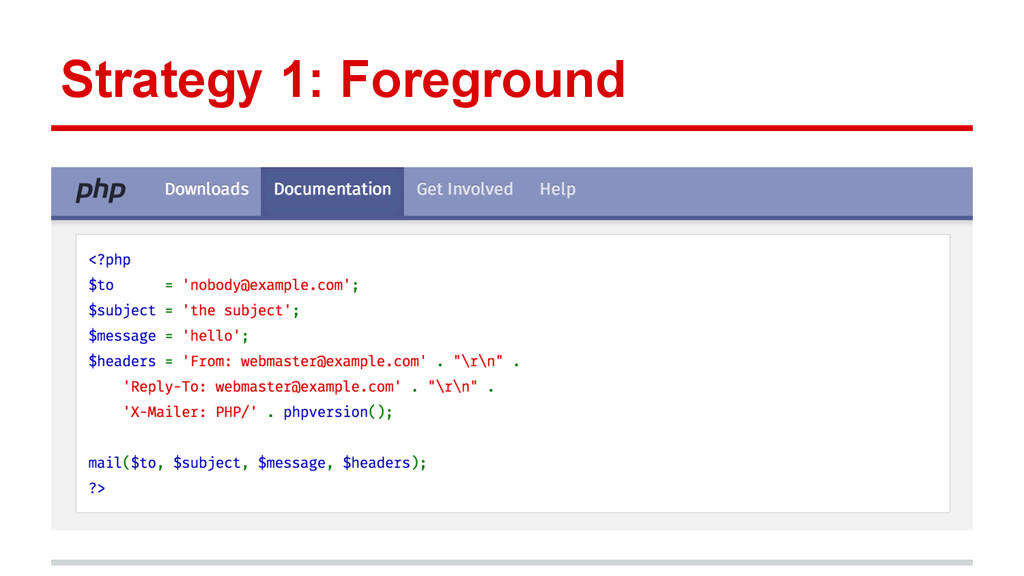{kind=link}
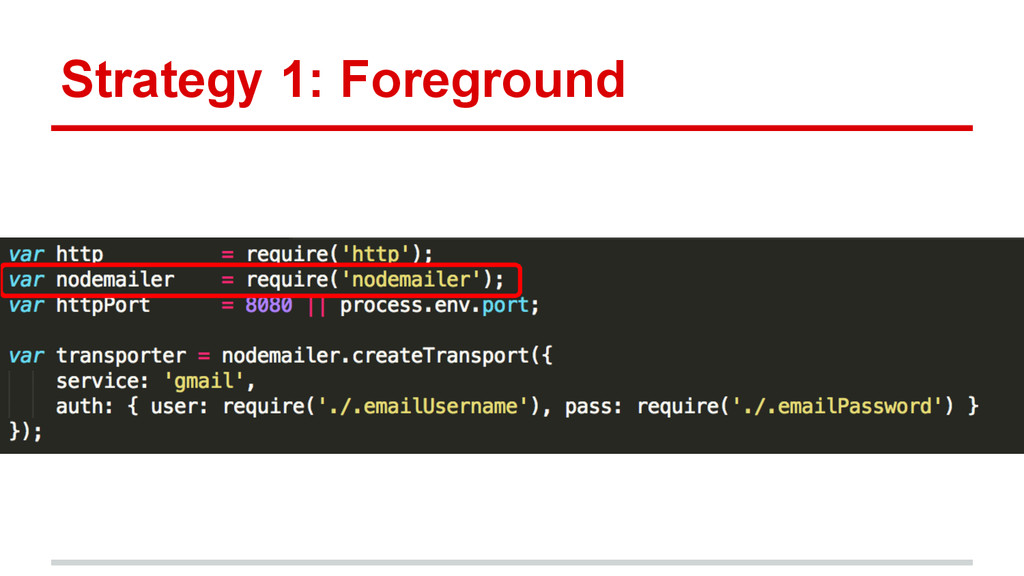{kind=link}
{kind=link}
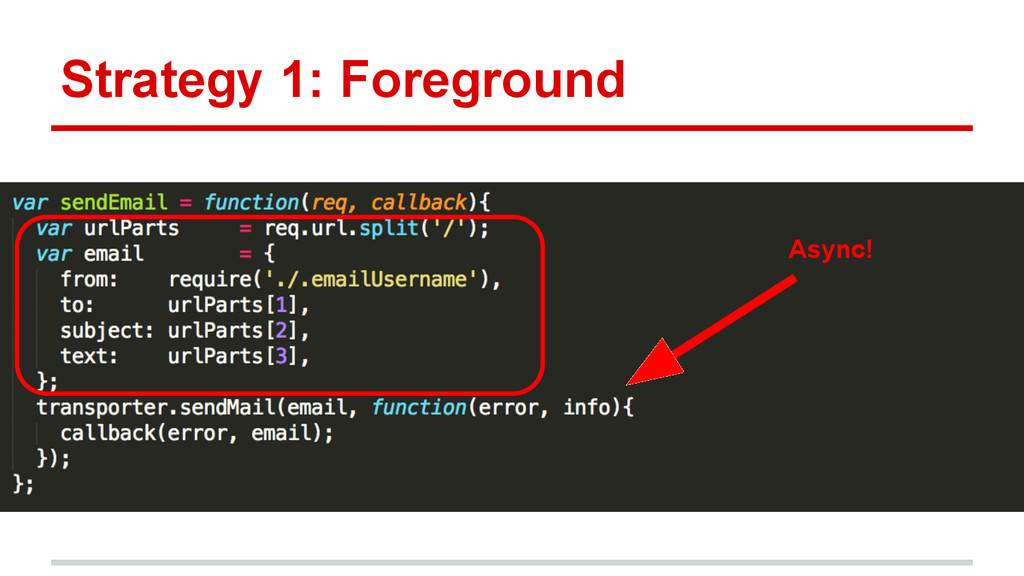{kind=link}
{kind=link}
{kind=link}
{kind=link}
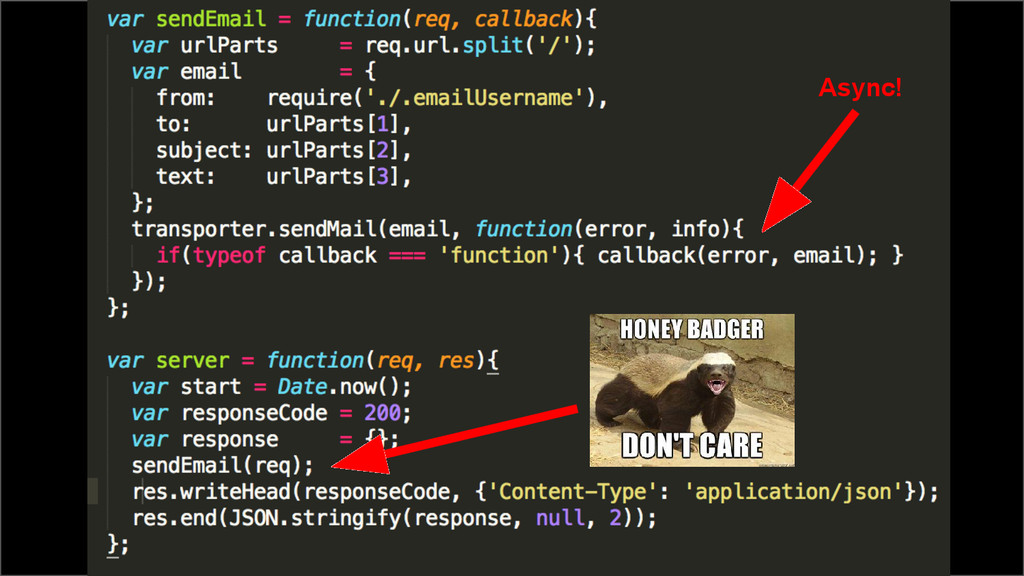{kind=link}
{kind=link}
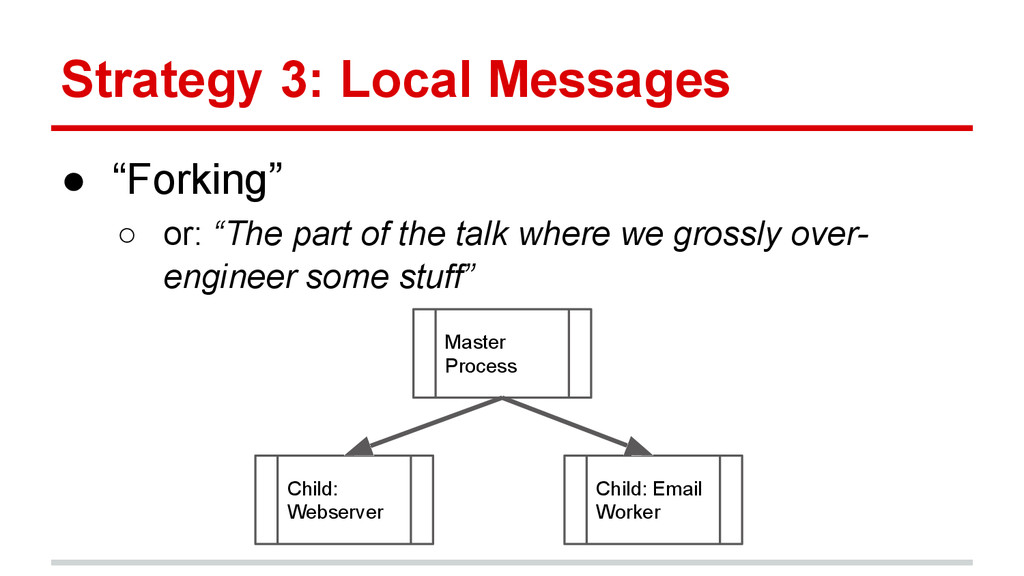{kind=link}
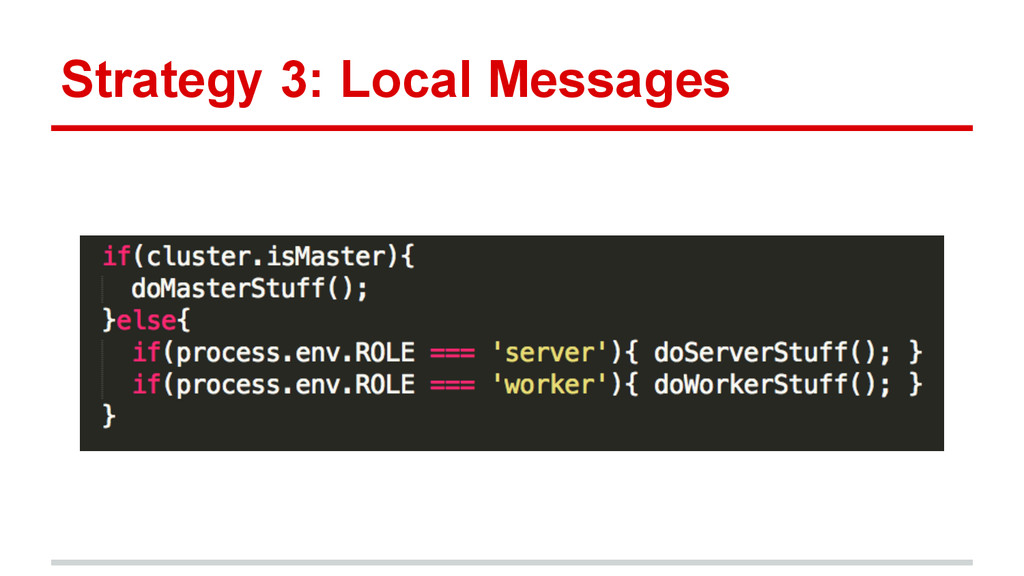{kind=link}
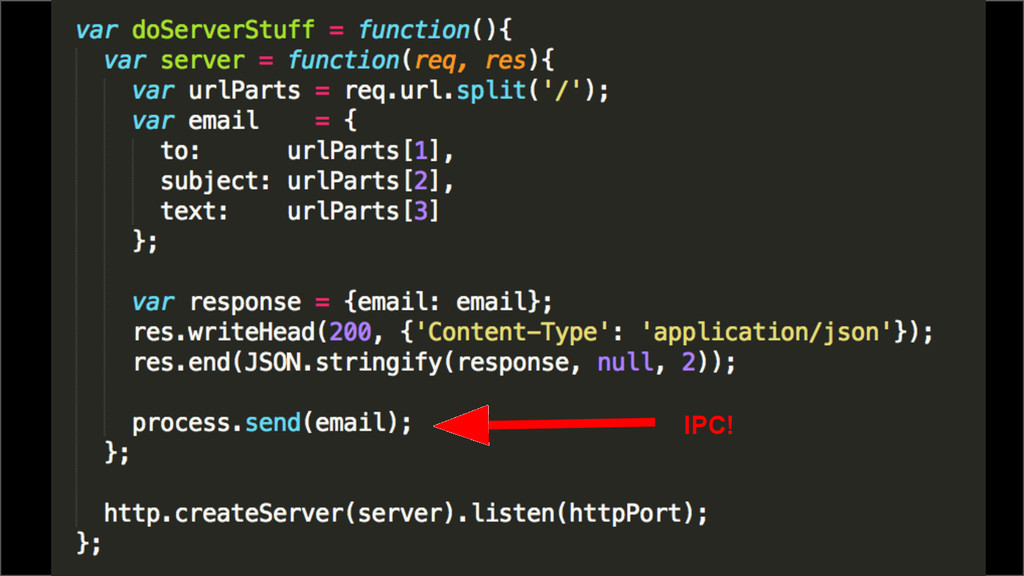{kind=link}
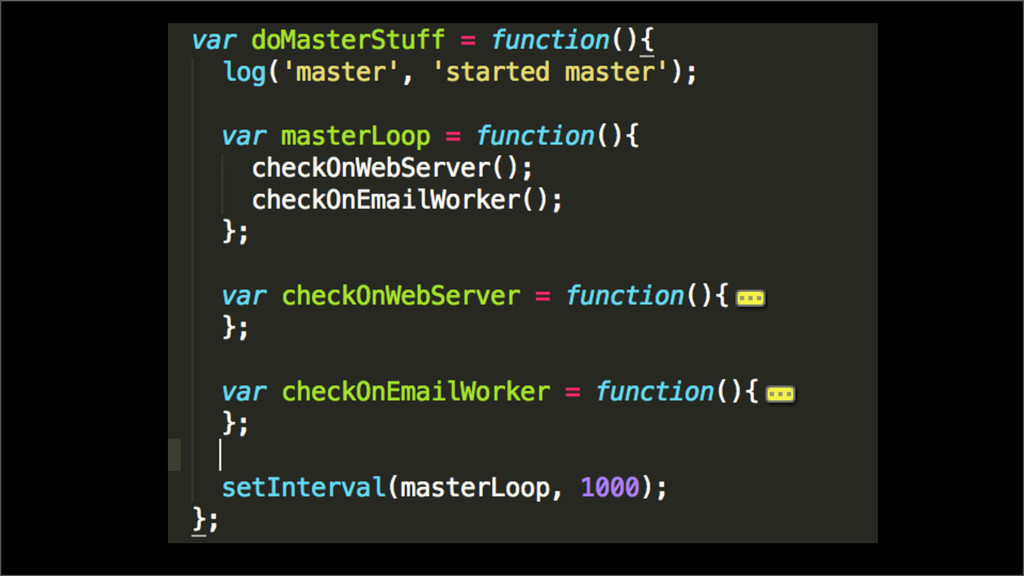{kind=link}
{kind=link}
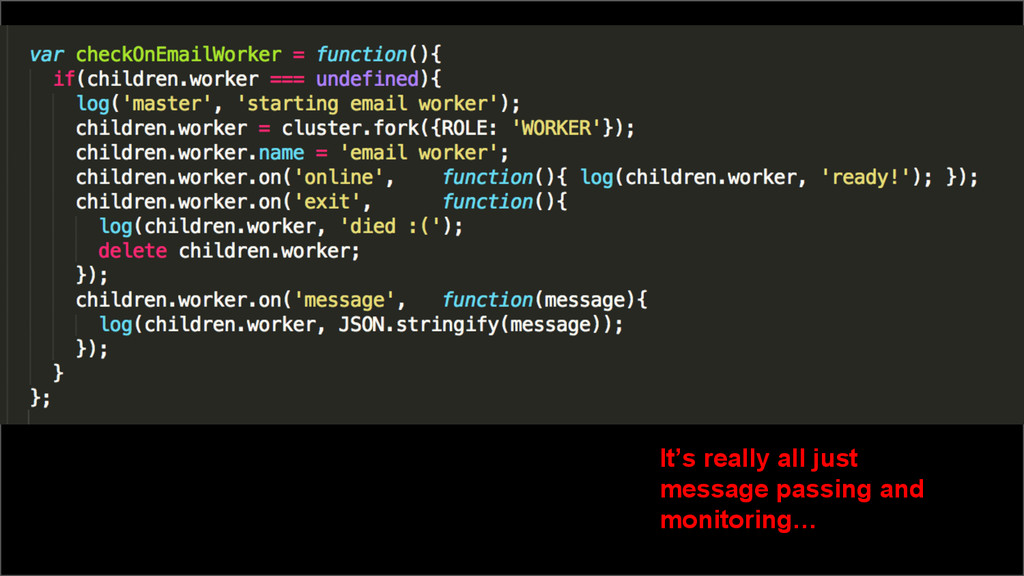{kind=link}
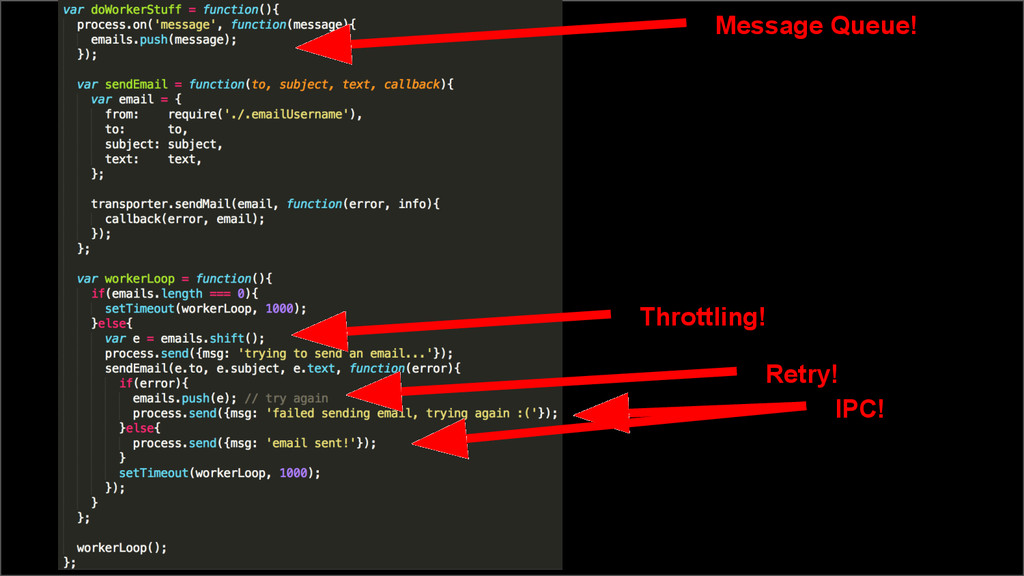{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
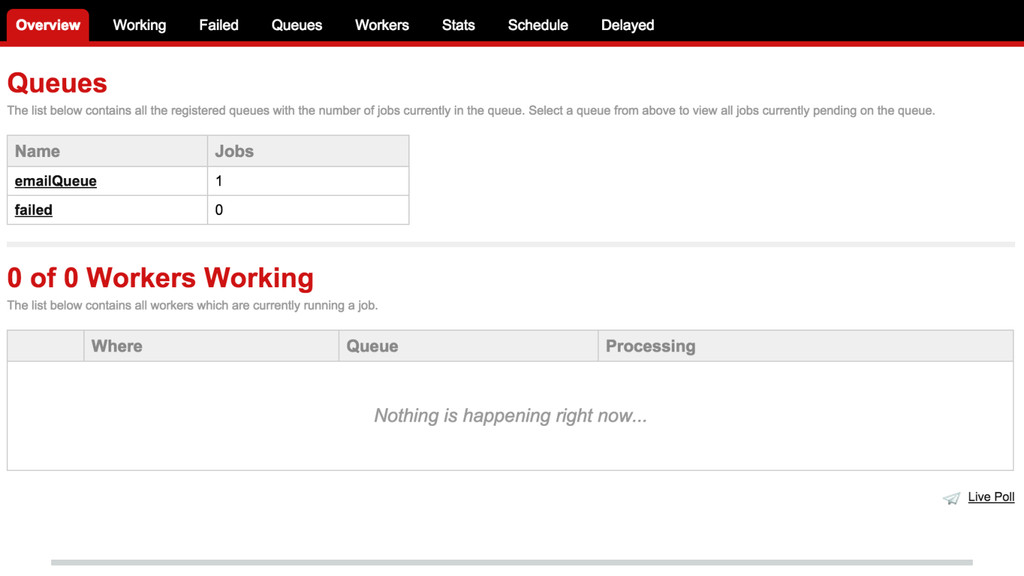{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}