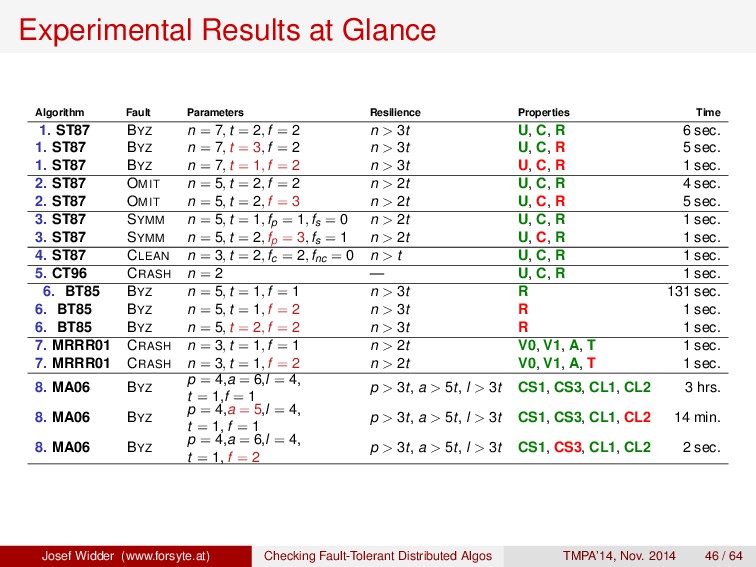
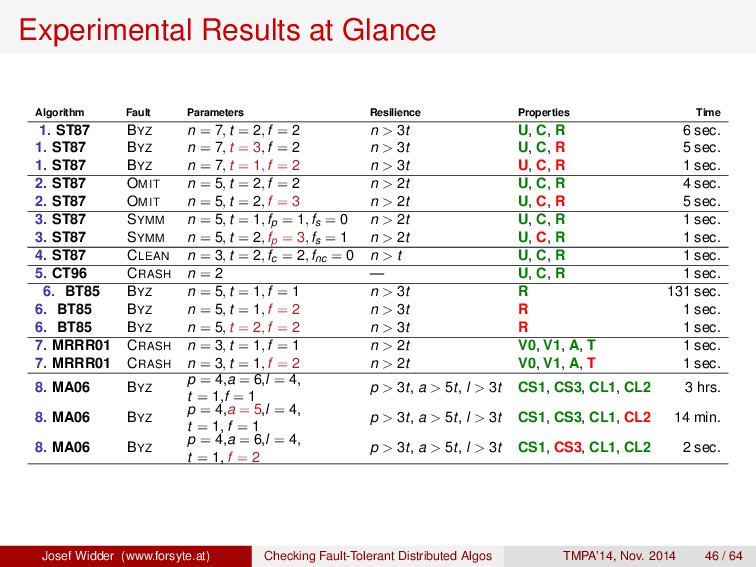
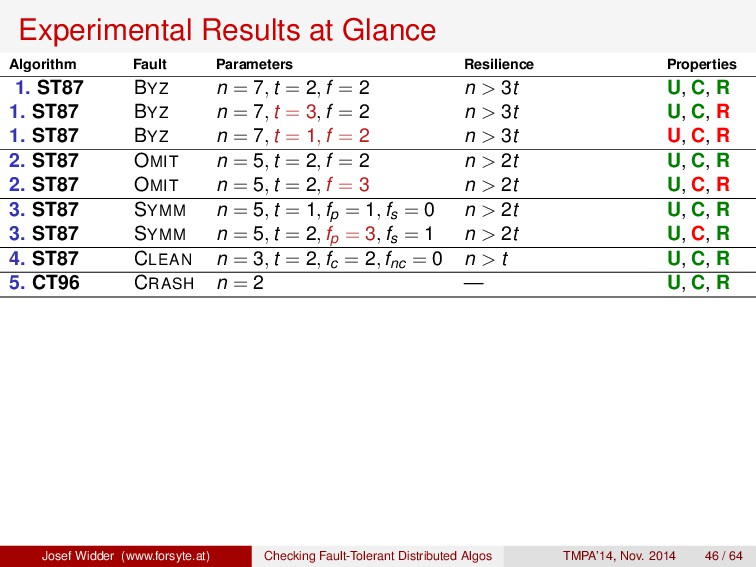
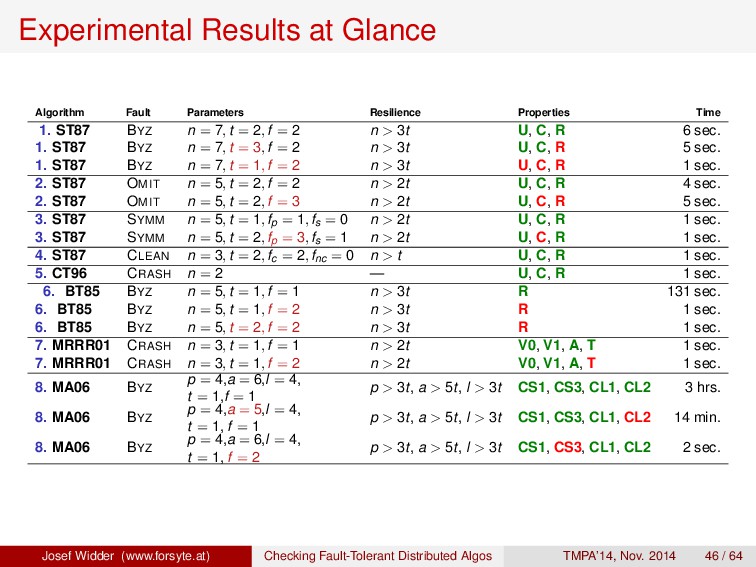
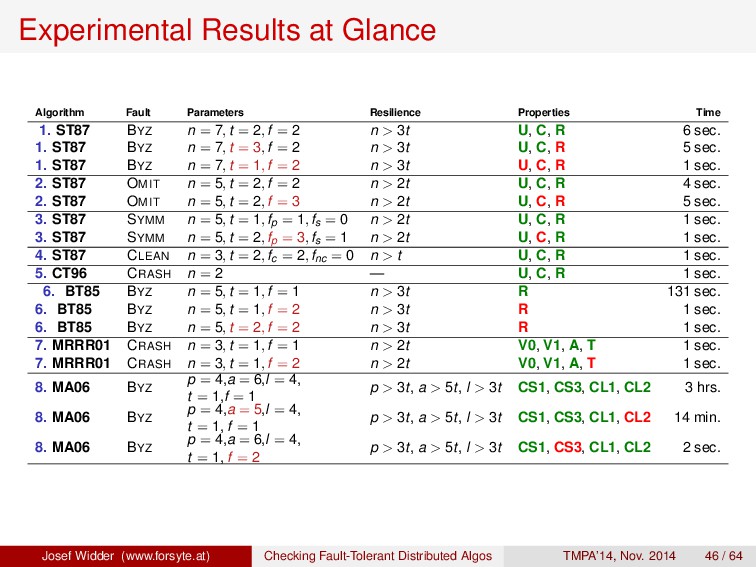
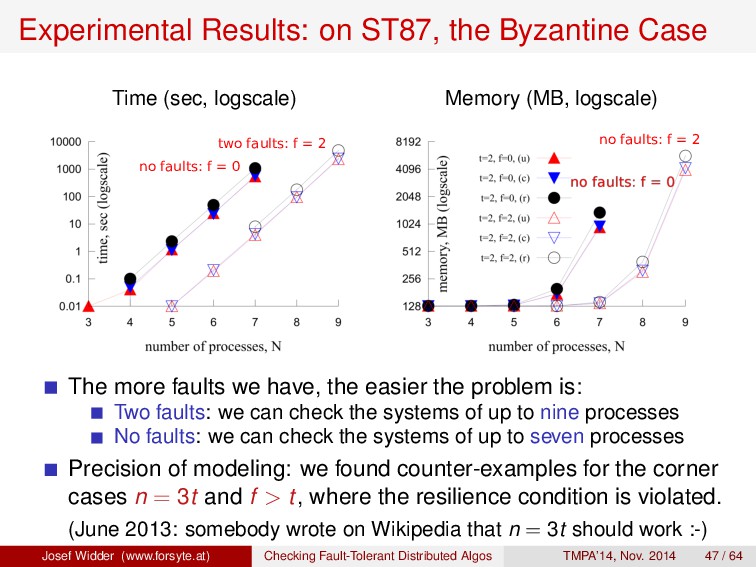
1. ST87 BYZ n = 7, t = 2, f = 2 n > 3t U, C, R 6 sec. 1. ST87 BYZ n = 7, t = 3, f = 2 n > 3t U, C, R 5 sec. 1. ST87 BYZ n = 7, t = 1, f = 2 n > 3t U, C, R 1 sec. 2. ST87 OMIT n = 5, t = 2, f = 2 n > 2t U, C, R 4 sec. 2. ST87 OMIT n = 5, t = 2, f = 3 n > 2t U, C, R 5 sec. 3. ST87 SYMM n = 5, t = 1, fp = 1, fs = 0 n > 2t U, C, R 1 sec. 3. ST87 SYMM n = 5, t = 2, fp = 3, fs = 1 n > 2t U, C, R 1 sec. 4. ST87 CLEAN n = 3, t = 2, fc = 2, fnc = 0 n > t U, C, R 1 sec. 5. CT96 CRASH n = 2 — U, C, R 1 sec. 6. BT85 BYZ n = 5, t = 1, f = 1 n > 3t R 131 sec. 6. BT85 BYZ n = 5, t = 1, f = 2 n > 3t R 1 sec. 6. BT85 BYZ n = 5, t = 2, f = 2 n > 3t R 1 sec. 7. MRRR01 CRASH n = 3, t = 1, f = 1 n > 2t V0, V1, A, T 1 sec. 7. MRRR01 CRASH n = 3, t = 1, f = 2 n > 2t V0, V1, A, T 1 sec. 8. MA06 BYZ p = 4,a = 6,l = 4, t = 1,f = 1 p > 3t, a > 5t, l > 3t CS1, CS3, CL1, CL2 3 hrs. 8. MA06 BYZ p = 4,a = 5,l = 4, t = 1, f = 1 p > 3t, a > 5t, l > 3t CS1, CS3, CL1, CL2 14 min. 8. MA06 BYZ p = 4,a = 6,l = 4, t = 1, f = 2 p > 3t, a > 5t, l > 3t CS1, CS3, CL1, CL2 2 sec. Josef Widder (www.forsyte.at) Checking Fault-Tolerant Distributed Algos TMPA’14, Nov. 2014 46 / 64
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}