Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Scraping: 10 mistakes to avoid @ Breizhcamp 2016
Search
Fabien Vauchelles
March 24, 2016
Science
240
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Scraping: 10 mistakes to avoid @ Breizhcamp 2016
From website, to storage, learn webscraping
#webscraping #tricks
Fabien Vauchelles
March 24, 2016
More Decks by Fabien Vauchelles
See All by Fabien Vauchelles
[StartupCourse/18] Discover Machine Learning
fabienvauchelles
0
92
[StartupCourse/01] Gérer sa carrière @ Polytech Paris Sud 2016
fabienvauchelles
0
69
[StartupCourse/02] Monter Une Startup @ Polytech Paris Sud 2016
fabienvauchelles
0
75
[StartupCourse/03] De l'idée au produit @ Polytech Paris Sud 2016
fabienvauchelles
0
49
Other Decks in Science
See All in Science
「念のためのログ保存」を組織全体でやめるためのポリシーと仕組み作り
i2tsuki
4
250
【論文紹介】Is CLIP ideal? No. Can we fix it?Yes! 第65回 コンピュータビジョン勉強会@関東
shun6211
5
2.5k
人生を変えた一冊「独学大全」のはなし / Self-study ENCYCLOPEDIA: The Book Which Change My Life #独学大全 #EM推し本
expajp
0
170
データベース03: 関係データモデル
trycycle
PRO
1
590
水耕栽培を始める前に知っておきたい植物の科学
grow_design_lab
0
270
検索と推論タスクに関する論文の紹介
ynakano
1
250
機械学習 - SVM
trycycle
PRO
2
1.2k
水耕栽培:古代の知恵から宇宙農業まで
grow_design_lab
0
160
機械学習 - pandas入門
trycycle
PRO
0
650
データベース08: 実体関連モデルとは?
trycycle
PRO
0
1.3k
データベース10: 拡張実体関連モデル
trycycle
PRO
0
1.2k
Cross-Media Technologies, Information Science and Human-Information Interaction
signer
PRO
3
32k
Featured
See All Featured
Faster Mobile Websites
deanohume
310
32k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
63
55k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
930
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
Are puppies a ranking factor?
jonoalderson
1
3.7k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Designing for humans not robots
tammielis
254
26k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
970
Transcript
Fabien VAUCHELLES zelros.com /
[email protected]
/ @fabienv http://bit.ly/breizhscraping (24/03/2016)
FABIEN VAUCHELLES Developer for 16 years CTO of Expert in
data extraction (scraping) Creator of Scrapoxy.io
What is Scraping
“Scraping is to transform human-readable webpage into machine-readable data.” Neo
Why do we do Scraping
EXAMPLES No API ! API with a requests limit Prices
Emails Profiles Train machine learning models Addresses Face recognition
“I used Scraping to create my clients list !” Walter
White
FORGET THE LAW 1.
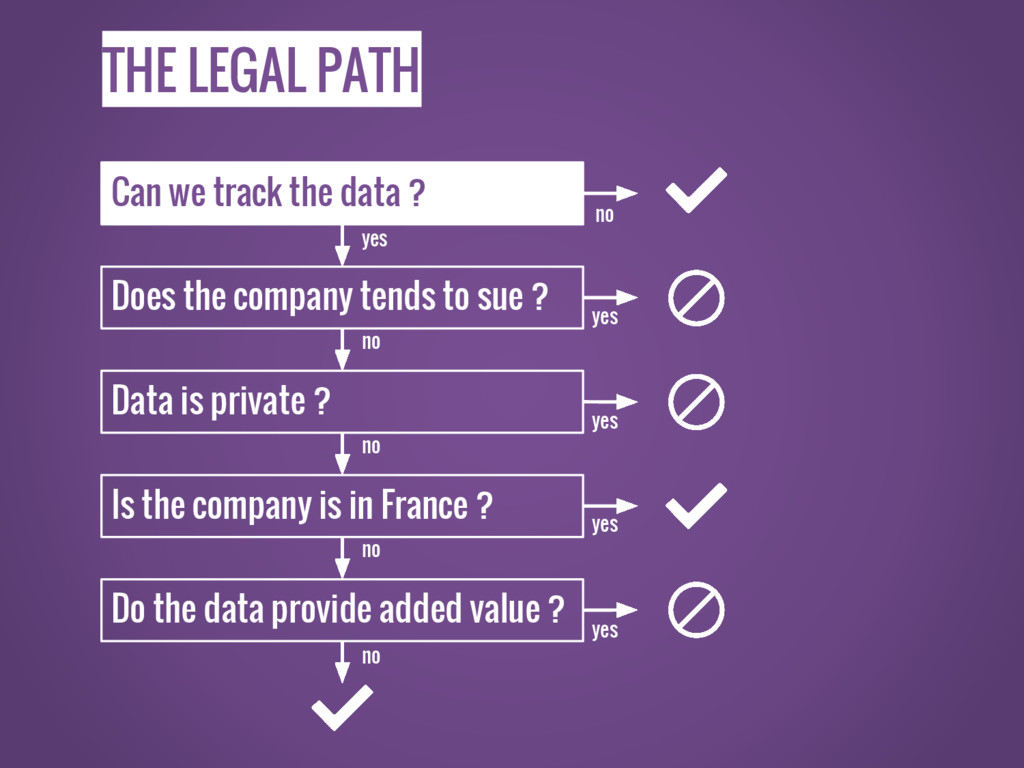
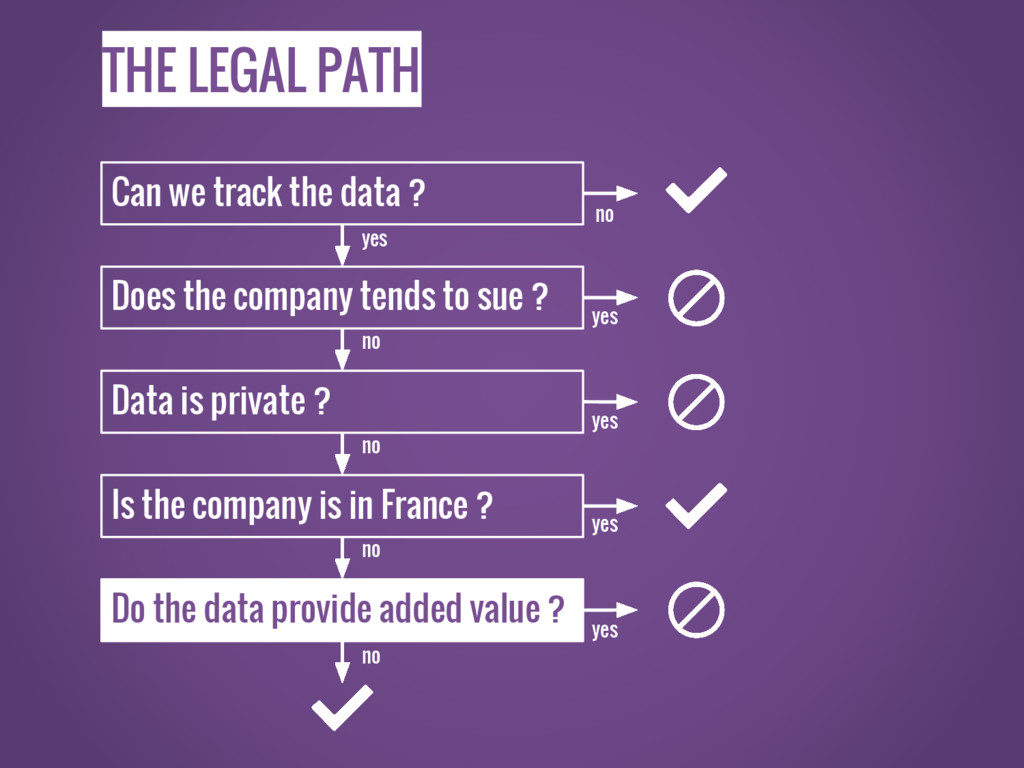
THE LEGAL PATH Can we track the data ? Does
the company tends to sue ? Data is private ? Is the company is in France ? Do the data provide added value ? no yes yes yes yes no no no no yes
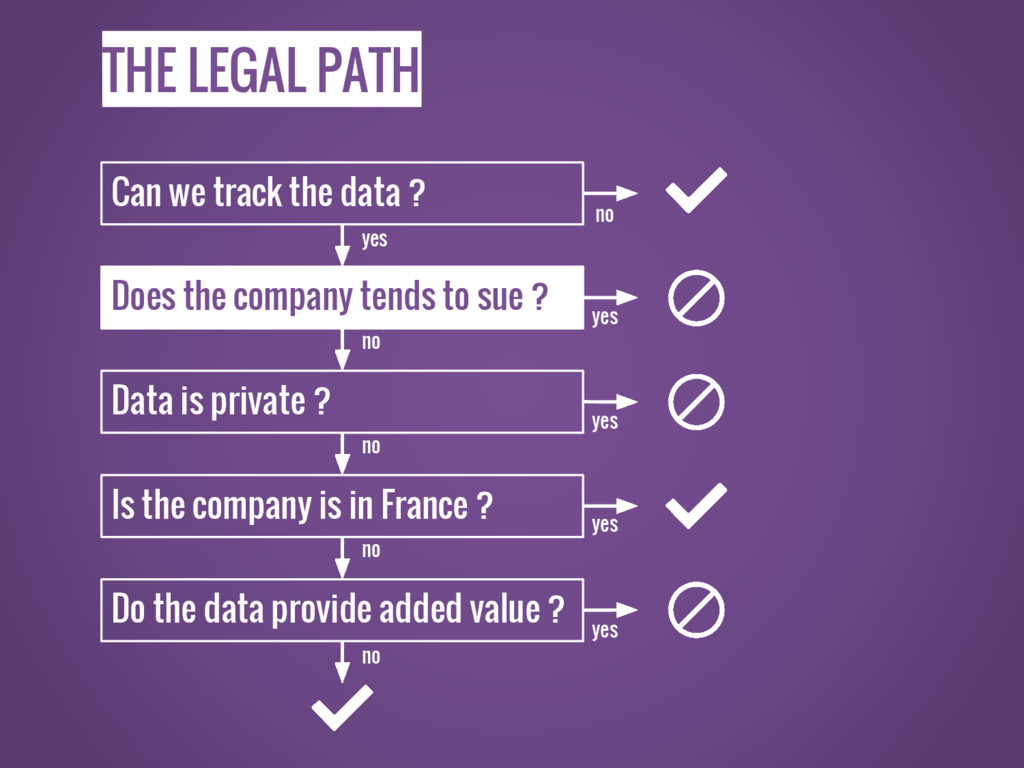
THE LEGAL PATH Can we track the data ? Does
the company tends to sue ? Data is private ? Is the company is in France ? Do the data provide added value ? no yes yes yes yes no no no no yes
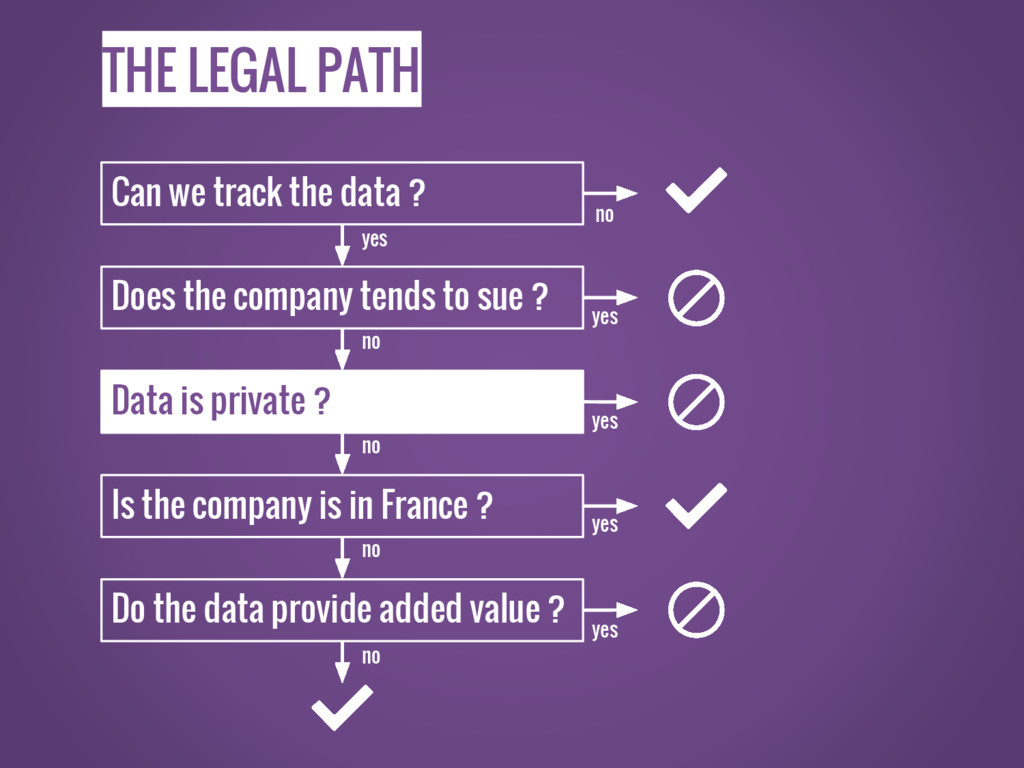
THE LEGAL PATH Can we track the data ? Does
the company tends to sue ? Data is private ? Is the company is in France ? Do the data provide added value ? no yes yes yes yes no no no no yes
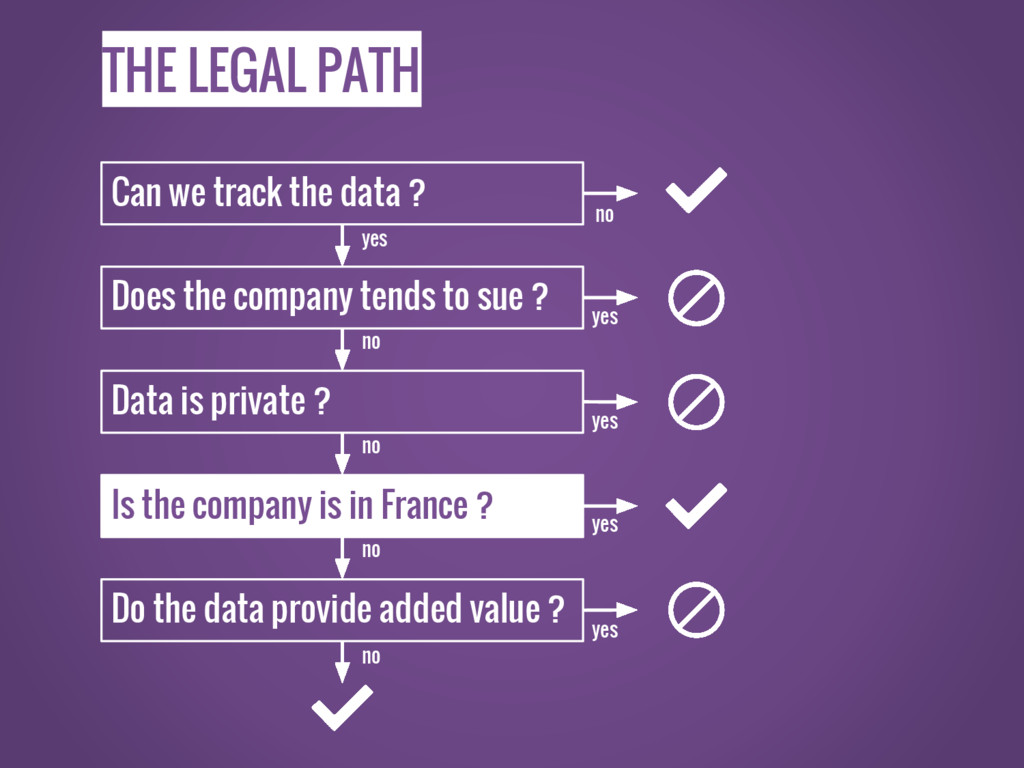
THE LEGAL PATH Can we track the data ? Does
the company tends to sue ? Data is private ? Is the company is in France ? Do the data provide added value ? no yes yes yes yes no no no no yes
THE LEGAL PATH Can we track the data ? Does
the company tends to sue ? Data is private ? Is the company is in France ? Do the data provide added value ? no yes yes yes yes no no no no yes
RUBBER DUCK E-MARKET LET’S STUDY THE
BUILD YOUR OWN SCRIPT 2.
USE A FRAMEWORK Limit concurrents request by site Limit speed
Change user agent Follow redirects Export results to CSV or JSON etc. Only 15 minutes to extract structured data !
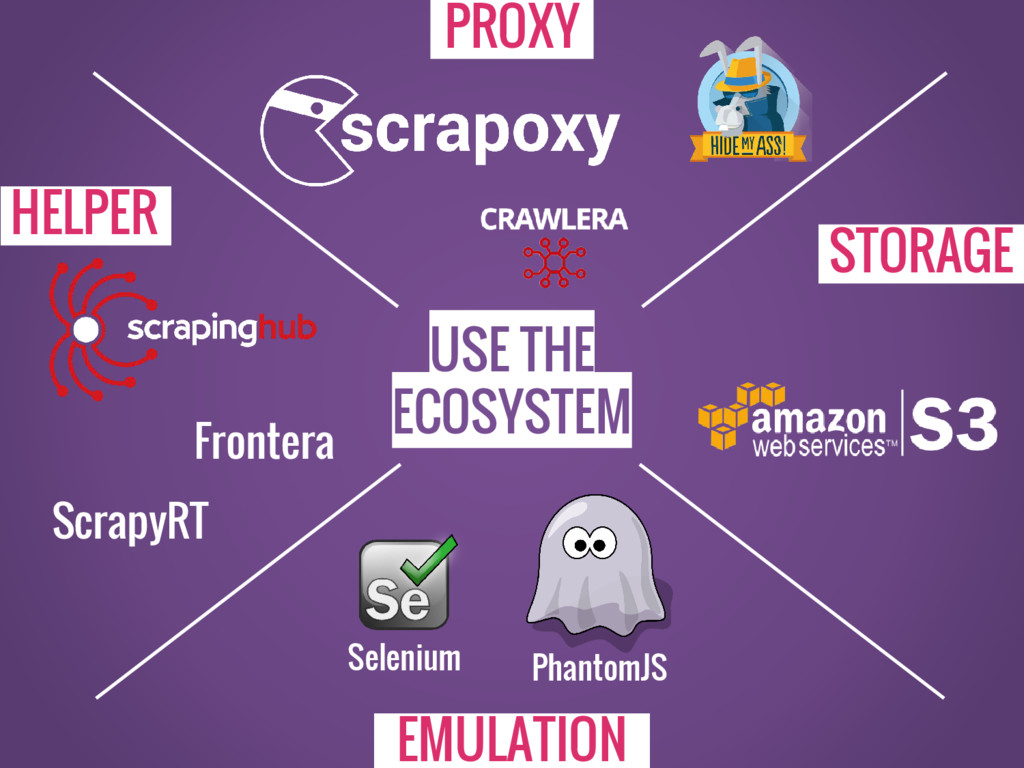
USE THE ECOSYSTEM Frontera ScrapyRT PhantomJS Selenium PROXY EMULATION HELPER
STORAGE
RUSH ON THE FIRST DATA SOURCE 3.
FIND THE EXPORT BUTTON
TAKE TIME TO FIND DATA
How to find a developer on Rennes
#1. GO TO BREIZHCAMP
#2. SCRAP GITHUB
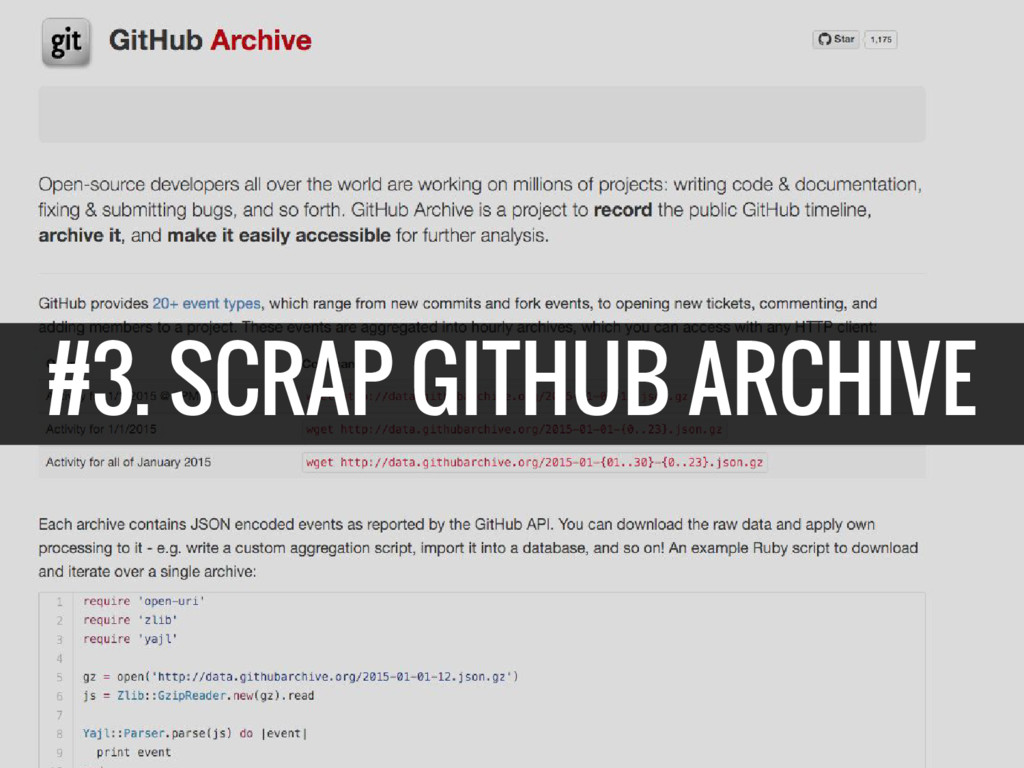
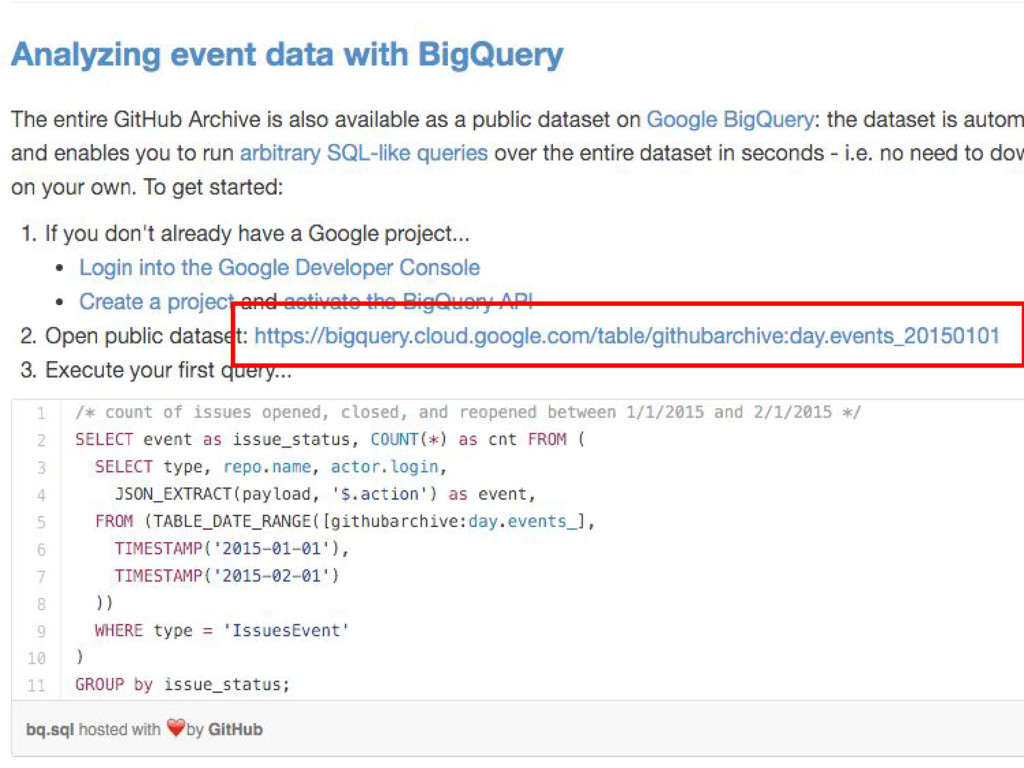
#3. SCRAP GITHUB ARCHIVE
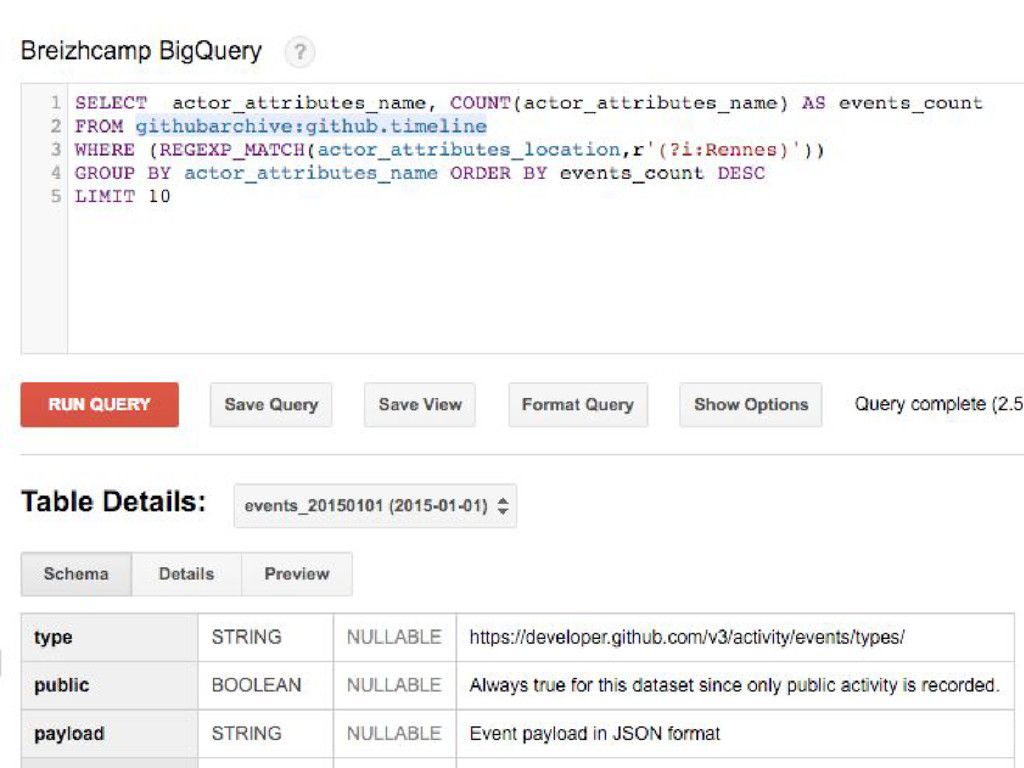
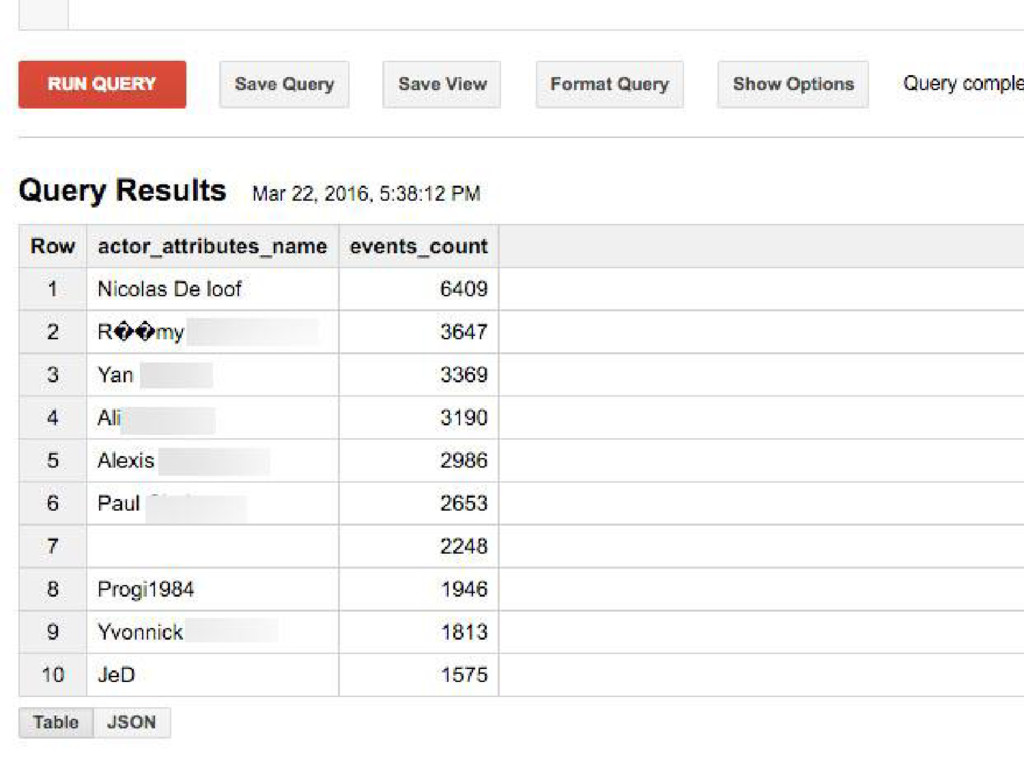
#4. USE GOOGLE BIG QUERY
None
None
None
KEEP THE DEFAULT USER-AGENT 4.
DEFAULT USER-AGENT SCRAPY Scrapy/1.0.3 (+http://scrapy.org) URLLIB2 (Python) Python-urllib/2.1
IDENTIFY AS A DESKTOP BROWSER CHROME Mozilla/5.0 (Macintosh; Intel Mac
OS X 10_11_3)↵ AppleWebKit/537.36 (KHTML, like Gecko)↵ Chrome/50.0.2661.37 Safari/537.36 200 503
SCRAP WITH YOUR DSL ACCESS 5.
BLACKLISTED
What is Blacklisting
TYPE OF BLACKLISTING Change HTTP status (200 -> 503) HTTP
200 but content change (login page) CAPTCHA Longer to respond And many others !
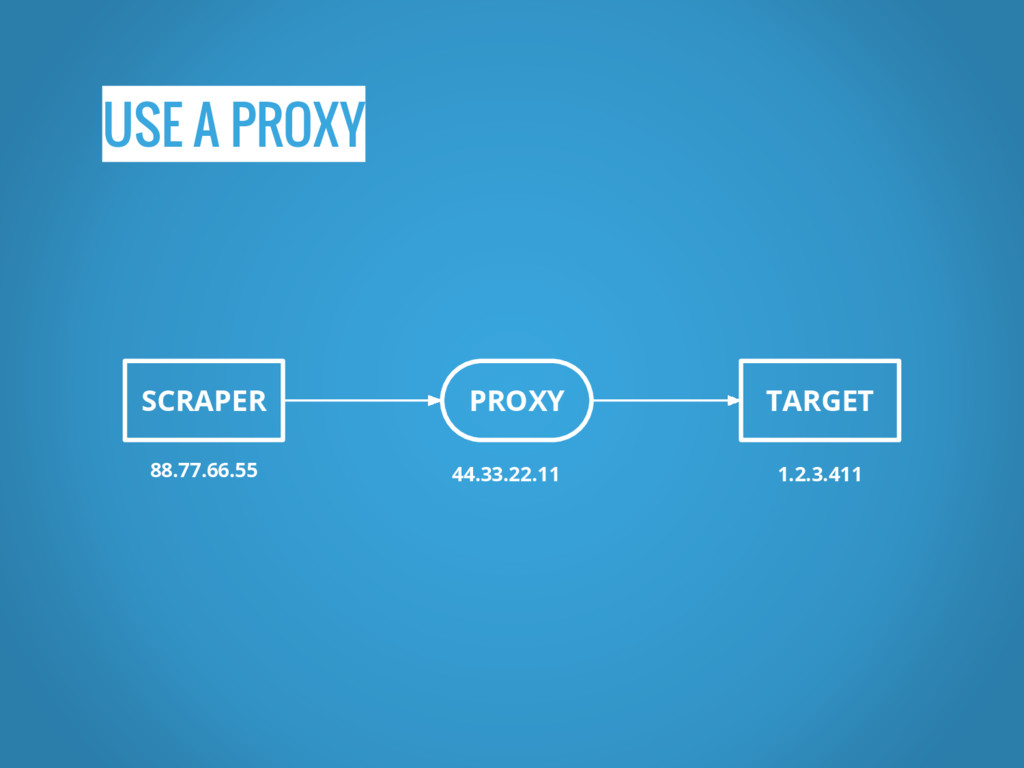
USE A PROXY SCRAPER PROXY TARGET 88.77.66.55 44.33.22.11 1.2.3.411
TYPE OF PROXIES PUBLIC PRIVATE
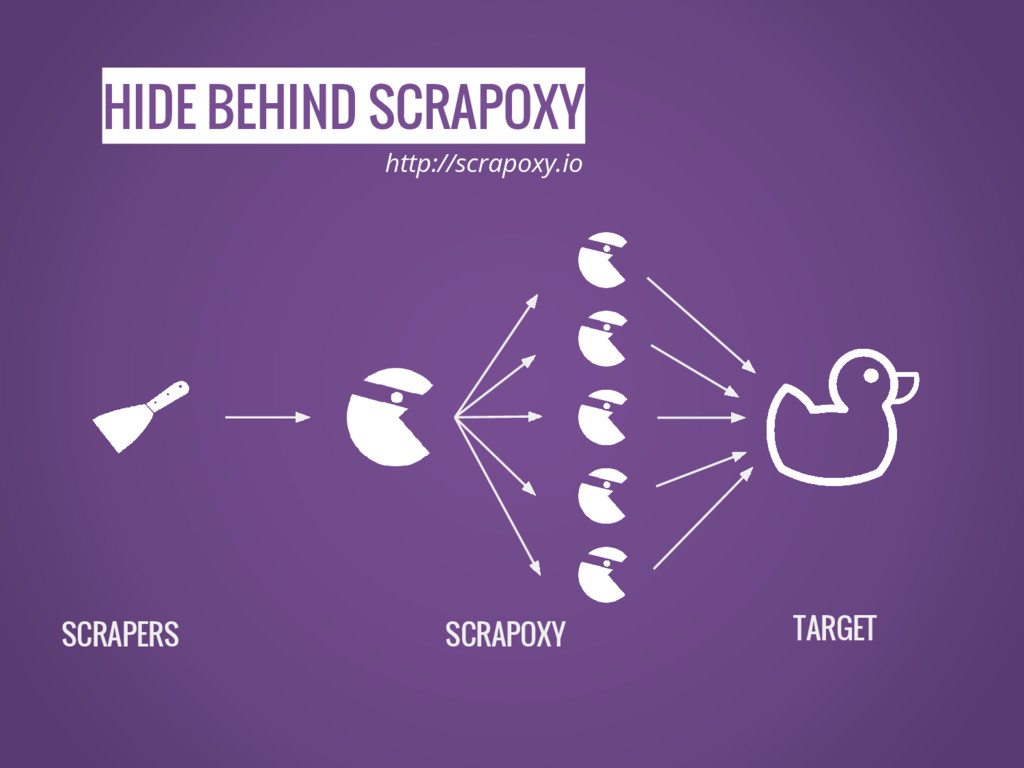
HIDE BEHIND SCRAPOXY SCRAPERS SCRAPOXY TARGET http://scrapoxy.io
TRIGGER ALERTS ON THE REMOTE SITE 6.
STAY OFF THE RADAR
ESTIMATE IP FLOW SCRAPER PROXY TARGET 10 requests / IP
/ minute ✔
ESTIMATE IP FLOW SCRAPER PROXY TARGET 10 requests / IP
/ minute ✔ 20 requests / IP / minute ✔
ESTIMATE IP FLOW SCRAPER PROXY TARGET 10 requests / IP
/ minute ✔ 20 requests / IP / minute ✔ 30 requests / IP / minute X
ESTIMATE IP FLOW The flow is 20 requests / IP
/ minute I want to refresh 200 items every minute I need 200 / 20 = 10 proxies !
MIX UP SCRAPER AND CRAWLER 7.
SCRAPERS ARE NOT CRAWLERS
FOCUS ON ESSENTIAL
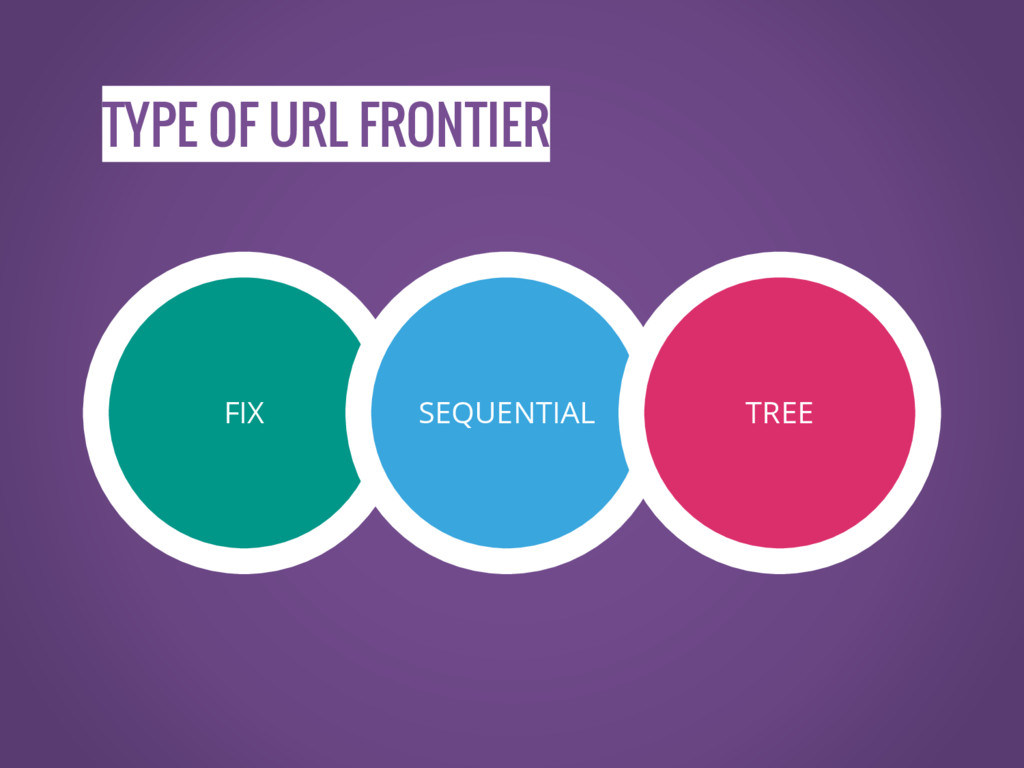
What is the URL frontier
URL frontier is the list of URL to fetch.
TYPE OF URL FRONTIER FIX SEQUENTIAL TREE
STORE ONLY PARSED RESULTS 8.
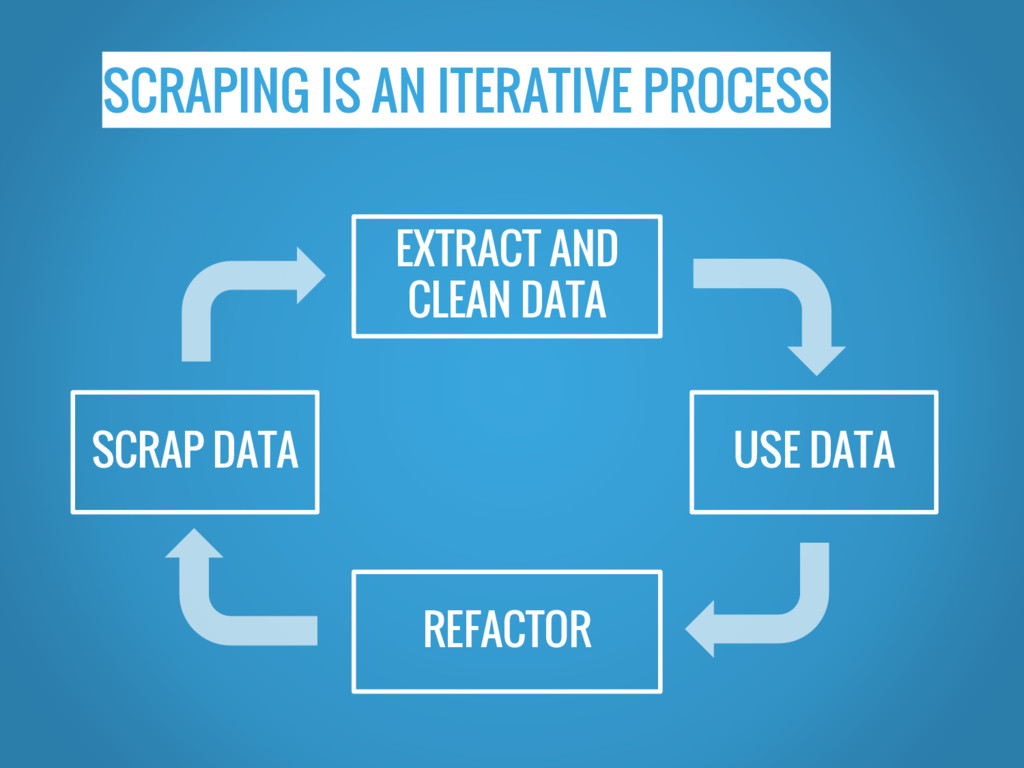
SCRAPING IS AN ITERATIVE PROCESS EXTRACT AND CLEAN DATA SCRAP
DATA USE DATA REFACTOR
SCRAP EVERYTHING... AGAIN ?
STORE FULL HTML PAGE
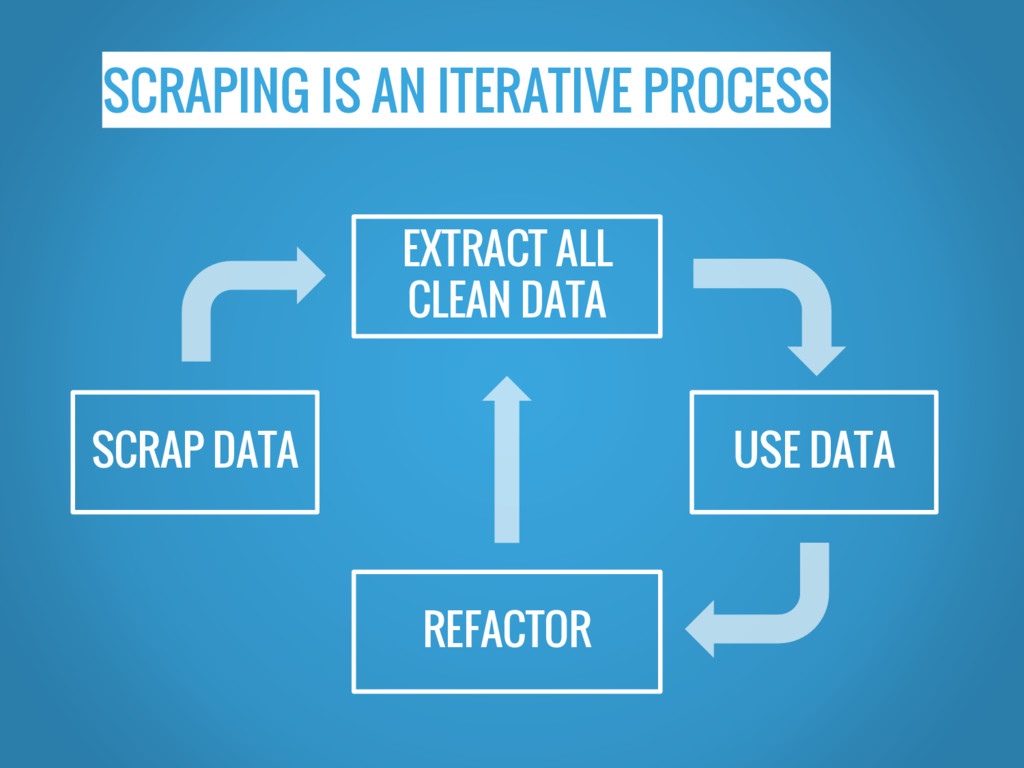
SCRAPING IS AN ITERATIVE PROCESS EXTRACT ALL CLEAN DATA SCRAP
DATA USE DATA REFACTOR
STORE WEBPAGE ONE BY ONE 9.
STORAGE CAN’T MANAGE MILLIONS OF SMALL FILES !
BLOCK IS THE NEW STORAGE
BLOCK IS THE NEW STORAGE
BLOCK IS THE NEW STORAGE
BLOCK IS THE NEW STORAGE
BLOCK IS THE NEW STORAGE
BLOCK IS THE NEW STORAGE
BLOCK IS THE NEW STORAGE
BLOCK IS THE NEW STORAGE
BLOCK IS THE NEW STORAGE
STORE HTML IN 128 MO ZIPPED FILES
PARSING IS SIMPLE ! 10.
PARSERS There is a lot of parsers ! XPATH CSS
REGEX TAGS TAG CLEANER
2 METHODS TO EXTRACT DATA <div class=”parts> <div class=”part experience”>
<div class=”year”>2014</div> <div class=”title”>Data Engineer</div> </div> </div> How to get the job title ?
#1. BY POSITION <div class=”parts> <div class=”part experience”> <div class=”year”>2014</div>
<div class=”title”>Data Engineer</div> </div> </div> /div/div/div[2] (with XPath parser)
#1. BY POSITION <div class=”parts> <div class=”part experience”> <div class=”year”>2014</div>
<div class=”location”>Paris</div> <div class=”title”>Data Engineer</div> </div> </div> /div/div/div[2] (with XPath parser)
#2. BY FEATURE <div class=”parts> <div class=”part experience”> <div class=”year”>2014</div>
<div class=”title”>Data Engineer</div> </div> </div> .experience .title (with CSS parser)
LET’S RECAP !
STEP BY STEP FIND A SOURCE LIMIT THE URL FRONTIER
SCRAP AND STORE PARSE BLOCS
STEP BY STEP FIND A SOURCE LIMIT THE URL FRONTIER
SCRAP AND STORE PARSE BLOCS
STEP BY STEP FIND A SOURCE LIMIT THE URL FRONTIER
SCRAP AND STORE PARSE BLOCS
STEP BY STEP FIND A SOURCE LIMIT THE URL FRONTIER
SCRAP AND STORE PARSE BLOCS
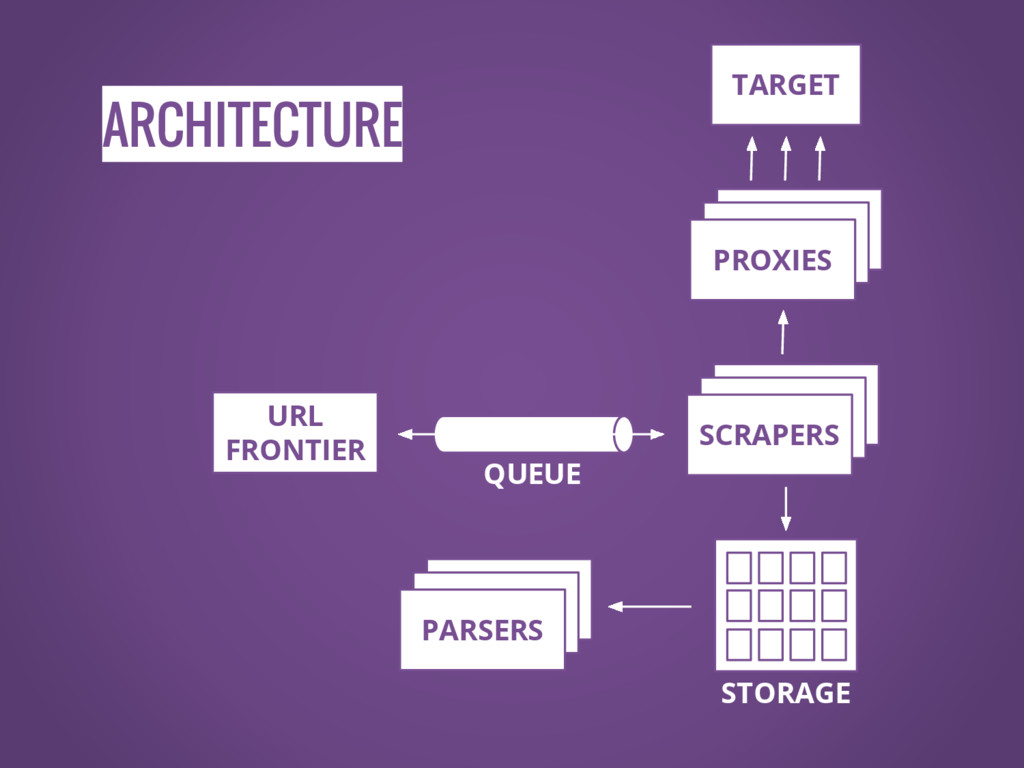
ARCHITECTURE SCRAPERS SCRAPERS SCRAPERS
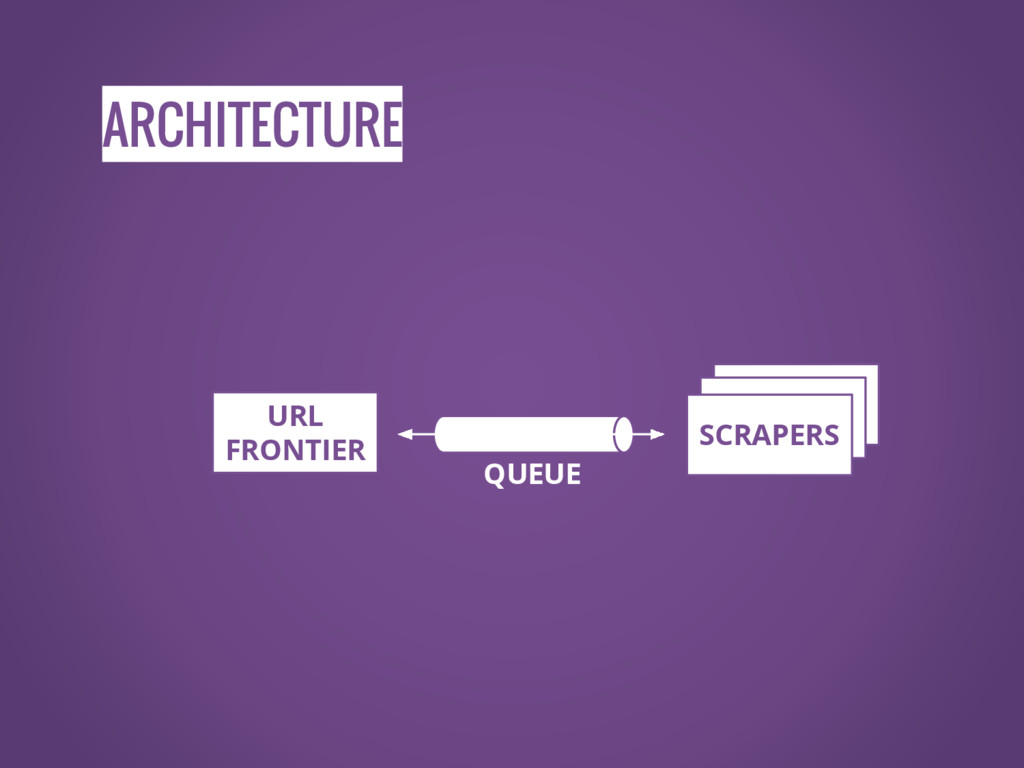
ARCHITECTURE SCRAPERS SCRAPERS SCRAPERS URL FRONTIER QUEUE
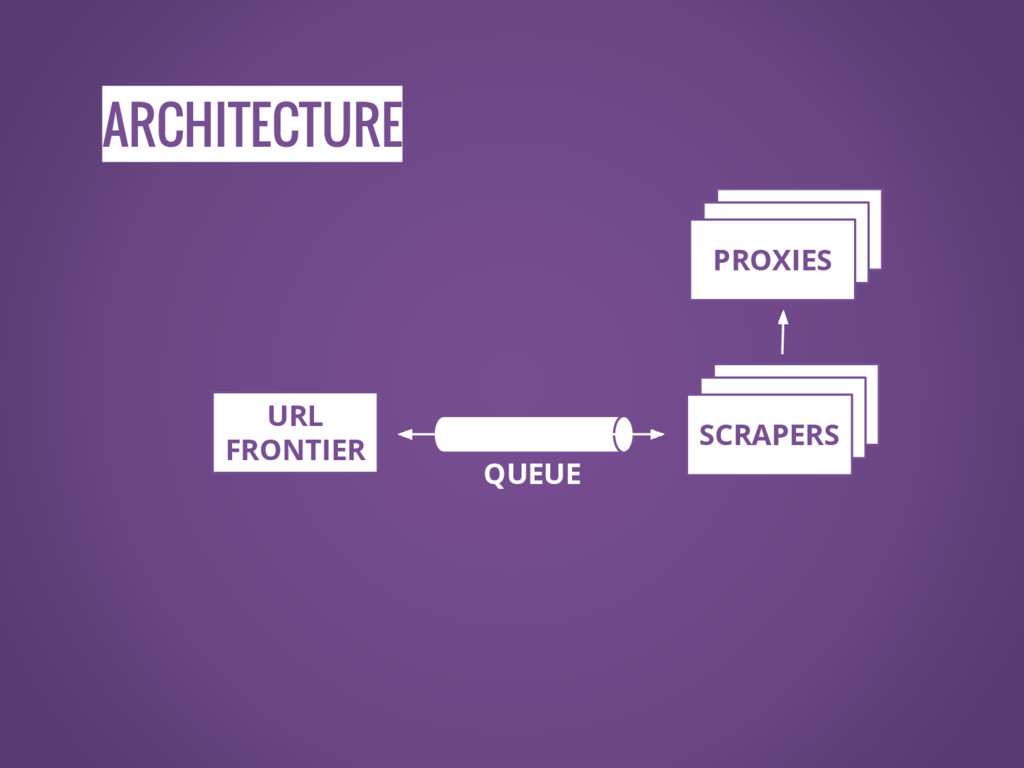
ARCHITECTURE SCRAPERS SCRAPERS SCRAPERS SCRAPERS SCRAPERS PROXIES URL FRONTIER QUEUE
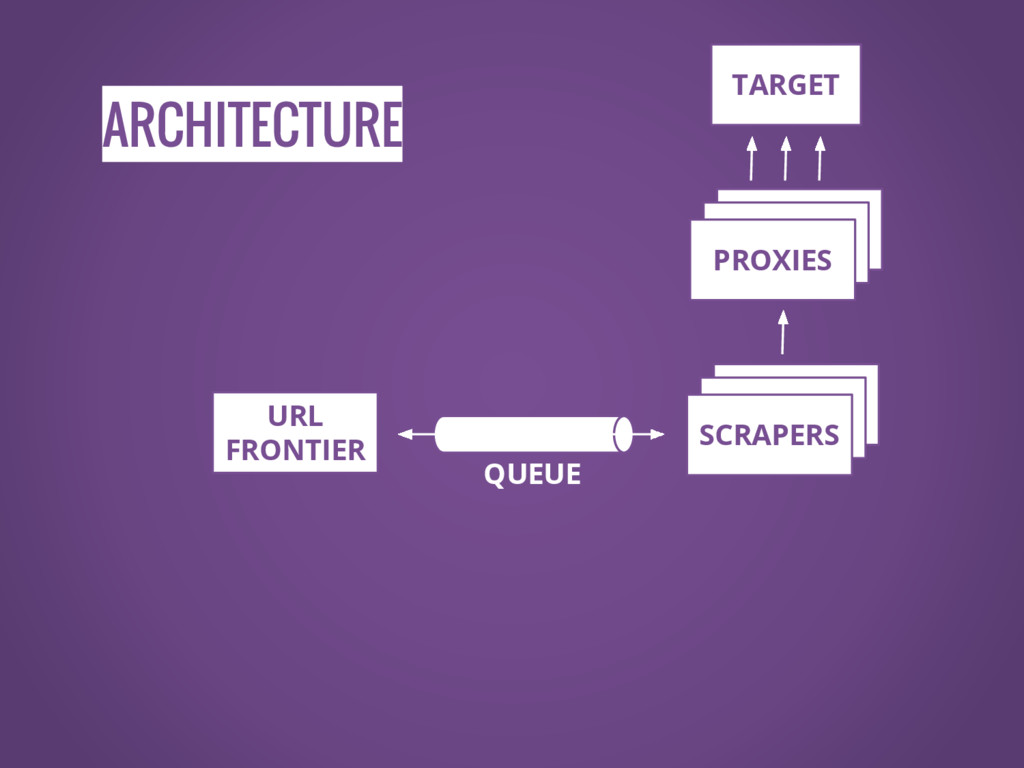
ARCHITECTURE SCRAPERS SCRAPERS SCRAPERS SCRAPERS SCRAPERS PROXIES URL FRONTIER TARGET
QUEUE
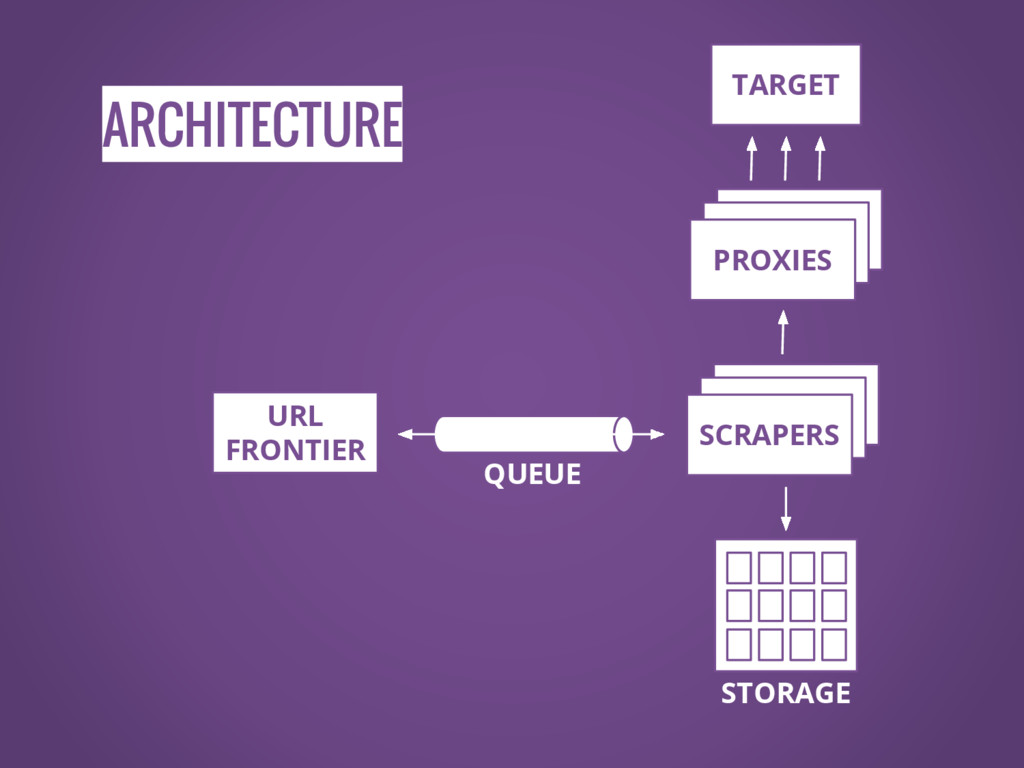
ARCHITECTURE SCRAPERS SCRAPERS SCRAPERS SCRAPERS SCRAPERS PROXIES URL FRONTIER STORAGE
TARGET QUEUE
ARCHITECTURE SCRAPERS SCRAPERS SCRAPERS SCRAPERS SCRAPERS PROXIES URL FRONTIER SCRAPERS
SCRAPERS PARSERS STORAGE TARGET QUEUE
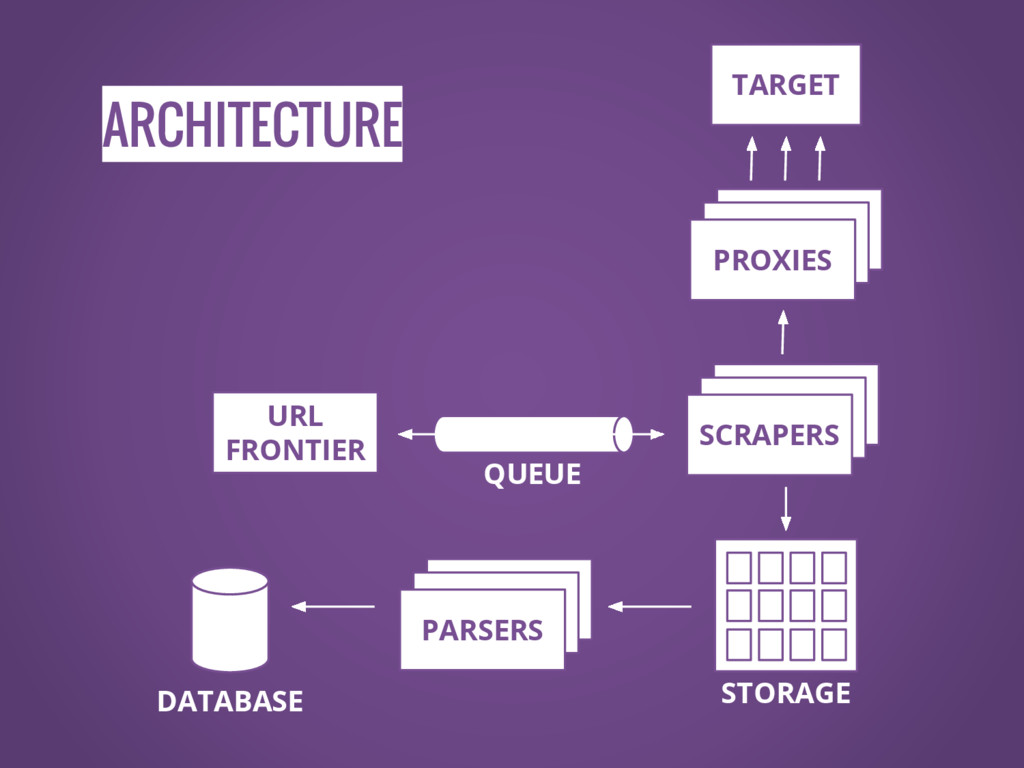
ARCHITECTURE SCRAPERS SCRAPERS SCRAPERS SCRAPERS SCRAPERS PROXIES URL FRONTIER SCRAPERS
SCRAPERS PARSERS STORAGE DATABASE TARGET QUEUE
Fabien VAUCHELLES zelros.com /
[email protected]
/ @fabienv http://bit.ly/breizhscraping The best
opensource proxy for Scraping !
![Fabien VAUCHELLES zelros.com / [email protected] / @fabienv http://bit.ly/breizhscraping (24/03/2016)](https://files.speakerdeck.com/presentations/c16f6de99e2e4d3f96c7ed298240bb4a/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Fabien VAUCHELLES zelros.com / [email protected] / @fabienv http://bit.ly/breizhscraping The best](https://files.speakerdeck.com/presentations/c16f6de99e2e4d3f96c7ed298240bb4a/slide_85.jpg){kind=link}