Me. Engenharia de Produção (Inteligência Computacional em NPLs) - (UNINOVE) • Especialista em Engenharia de Banco de Dados (UNICAMP) • Professor no Mackenzie (Curso Pós-Grad. em Ciência de Dados) • Professor no Grupo Kroton (Curso Pós-Grad. em Gestão Estratégica) • Speaker no Strata Hadoop World Singapore (2016) • Speaker no Spark Summit Europe (2017) • Blogger no Mineração de Dados - http://mineracaodedados.wordpress.com flavioclesio SOBRE NÓS
Software na Movile • Mestre em Engenharia Elétrica • Apache Cassandra MVP (2014/2015 and 2015/2016) • Apache Cassandra Contributor (2015) • Cassandra Summit Speaker (2014 and 2015) • Speaker no Strata Hadoop World Singapore (2016) • Speaker no Spark Summit Europe (2017) Eiti Kimura eitikimura
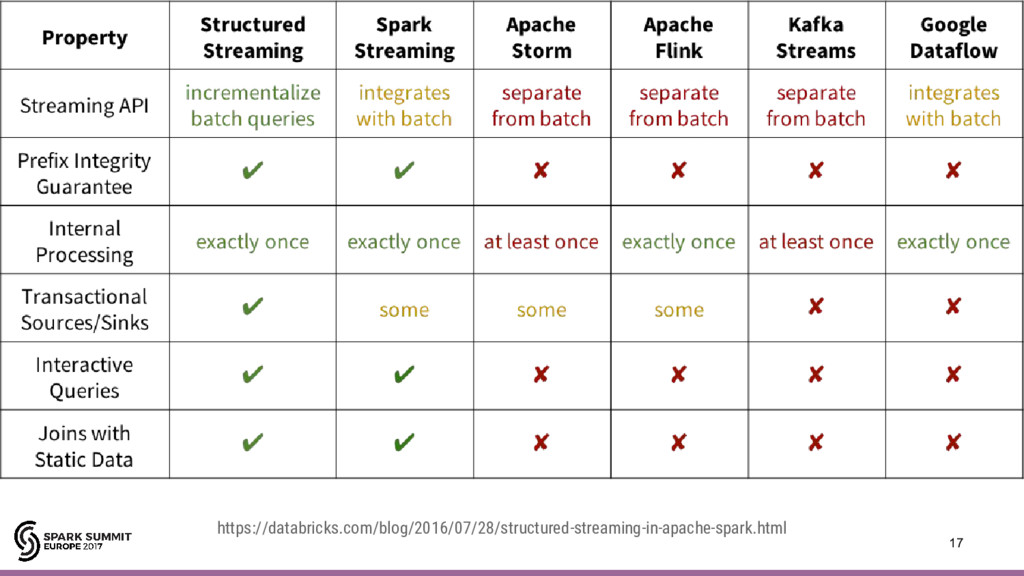
• Desenvolvimento de aplicações contínuas • Junção de dados contínua com conteúdo estático • Integrações com diversas fontes de dados (Kafka) • Tolerante a falhas (check-points) • Tratamento de eventos desordenados (Watermark)
em memória RAM • Footprint de memória pode ser um pesadelo em pipelines de ML intensivos, em especial em hiper-parametrizações pouco seletivas • Com MapReduce alguns algoritmos complexos são inviáveis para a implementação, devido à comunicação entre os nós para monitorar estados intermediários e interações
em produção - https://spark-summit.org/eu-2017/events/lessons-learned-developing-and-managing-massive-300tb-apache-spark-pipelines-in-pr oduction/ BenchML - https://github.com/szilard/benchm-ml Haddop x Spark x Flink - https://data-flair.training/blogs/hadoop-vs-spark-vs-flink-comparison/ Map Reduce Core Paper - https://github.com/eartsar/RIT-BigData/blob/master/docs/Presentation%20PDFs/nips06-mapreducemulticore.pdf Data Intensive Processing MapReduce - https://www.amazon.com/Data-Intensive-Processing-MapReduce-Synthesis-Technologies/dp/1608453421/ Map Reduce Core Paper - https://github.com/eartsar/RIT-BigData/blob/master/docs/Presentation%20PDFs/nips06-mapreducemulticore.pdf Referências 27
Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing: https://www2.eecs.berkeley.edu/Pubs/TechRpts/2011/EECS-2011-82.html Apache Spark officially sets a new record in large-scale sorting - https://databricks.com/blog/2014/11/05/spark-officially-sets-a-new-record-in-large-scale-sorting.html Spark SKLearn- https://github.com/databricks/spark-sklearn Elephas - https://github.com/maxpumperla/elephas Deep Learning Pipelines in Spark - https://github.com/databricks/spark-deep-learning Distributed Keras - https://github.com/cerndb/dist-keras
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![github.com/eitikimura/spark-cases http://bit.ly/apres-devfest-2017 http://bit.ly/playlist-spark-summit OBRIGADO! eitikimura [email protected] [email protected] flavioclesio](https://files.speakerdeck.com/presentations/7a5049a914c44008a9ebf23141330d49/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}