M.e. Engenharia de Produção (Inteligência Computacional) • Blogger em flavioclesio.com • Talks em algumas conferências (Strata Hadoop World, Spark Summit, PAPIS.io, The Developers Conference, e outros) 2 flavioclesio Flávio Clésio
minha experiência e visão em relação ao que eu tenho trabalhado e acompanhado nos últimos anos, bem como via observação direta, consultoria e participação em comunidades. Em outras palavras isso não é ciência, playbook de melhores práticas, BroScience, ou qualquer tipo de ciência. A ideia principal aqui é a troca de experiências dentro da perspectiva de um praticante de ML.
são minhas. Elas não fora revisadas ou mesmo aprovadas pelos meus empregadores sejam eles atuais, passados e futuros. Eu não falo em nome de nenhuma empresa. All views expressed in this presentation are my own. They have not been reviewed or approved by my current, past, or either future employers. I do not speak on behalf of any company.
em inúmeras indústrias, e com mais negócios e organizações dependendo desse tipo de tecnologia, os impactos são muito mais amplificados. Nessa talk vamos falar da indisponibilidade de sistemas de ML dentro da perspectiva técnica, de alguns tipos de falhas em projetos propriamente dito (com um pouco de parte técnica também), e algumas ferramentas que podem ser usadas na detecção e gerenciamento de incidentes. Machine Learning em produção
é sexy... • Infelizmente ainda existem culturas corporativas que não dão segurança psicológica suficiente para a admissão de erros (geralmente se tem uma cultura de apuração de responsabilidades e culpa) • Mentalidade atrasada de que falar sobre uma indisponibilidade pode ser ruim para “branding” corporativo • Muita gente que “morreu” no meio do processo não está mais presente para compartilhar (e.g. empresas que faliram, pessoas demitidas, sistema de regras que entrou no lugar do algoritmo de ML hypado) • Resquícios de mentalidade “macho man” em culturas de engenharia que não querem parecer ou mostrar vulnerabilidade em meio a indisponibilidades
a ser aprendida em qualquer processo de indisponibilidade, mesmo que não seja algo acionável • Para cada lição aprendida, o sistema como um todo fica mais confiável
• Ajustes rápidos, localizados e sem muito processo de reflexão a primeira vista soa produtivo (e.g. “Olha como a pessoa/time X resolveu o problema”) • Entretanto isso pode levar a uma cultura de cultivo de inúmeros problemas dormentes e riscos silenciosos que poderiam ser eliminados com simples postmortem/reporte de incidente • Somente resolver o problema promove uma estagnação de cultura de engenharia ao invés de ter uma reforma continua • Focar apenas em ajustes locais é como ter um problema com mosquitos e ficar batendo neles todos os dias, ao invés de resolver o problema simplesmente drenando o brejo no qual eles se reproduzem.
a empresa tenta resolver um problema de escopo muito amplo com sem uma análise de viabilidade como uma FAANG mesmo tendo menos empregados do que essas empresas têm de engenheiros (Fonte) - Começa como um super projeto e acaba como uma “marcha da morte”. No final geralmente as pessoas são realocadas, ou se demitem ou são demitidas - É apenas meta técnica para RP ou pescar investidores/talentos (ex: Usar ML em <<$NOME_PRODUTO>>) O que pode ajudar: - Definir as expectativas e viabilidade o mais rápido possível - Usar esse tipo de projeto com uma mentalidade muito mais de “aprendizado e potencial inovação” do que de entrega - Na dúvida considere um local de trabalho no qual você possa trazer mais valor para a sua carreira e/ou sociedade
forget“ - Ausência completa de métricas de sucesso dos modelos - Decisões sobre projetos de dados que levam em consideração… “intuição”(?) - “Vanity metrics”, métricas acadêmicas, ou métricas proxy ruins para a indicação de sucesso (nDCG =! $$, Precision/Recall <> $$) O que pode ajudar: - Experimentos com usuários é o padrão ouro (e.g. Bandit, A/B, Concierge Tests, Alpha, Shadow Mode, Early Adopters, etc.) - Trabalho fundacional de educação para mudança de cultura - Entendimento mútuo entre negócios e engenharia
eXtreme Go Horse Methodology (XGH) - Fabuloso mundo do “Sem”: Sem testes, sem logs, sem CI, sem CI, sem Git, sem tracking de experimentos, sem versionamento de dados - Todo trabalho apenas salvo em uma máquina local em um arquivo com o nome “Untitled38.ipynb” O que pode ajudar: - Notebooks são sensacionais para experimentação, mas a não ser que o seu time seja o Netflix colocar em produção é difícil e a manutenção vai cobrar o seu preço depois via débito técnico - Programação em Par e/ou Ensemble/Mobbing entre cientistas de dados e Eng. Software com transferência de conhecimento - Fundamentar para os tomadores de decisão o custo de overhead (ou os riscos) de não ter isso implementado
em um único “canônico-data-cloud-vendor-faz-tudo”... - ou linguagem... - ou ferramenta (e.g. passagem somente de ida para a eternidade em que as pessoas que implementaram esperam estar em um novo emprego antes que alguém decida migrar) O que pode ajudar: - A melhor ferramenta não é aquela que apenas resolve o problema, mas que também faz isso da forma mais eficiente possível - Se uma escolha for inevitável, escolha ecossistemas ao invés preferências pessoais ou familiaridade (ex: RDD) - Diversidade de ferramentas é preferível a “zoológico de tecnologias” - A não ser que o projeto seja em uma FAANG (ou Tesla) ou requerimentos muito específicos (e.g. baixa latência na fase de inferência, modelo embarcado, inferência em mobile, etc) pegue o ecossistema com o melhor conjunto de ferramentas e linguagens que ofereça soluções (ou o caminho delas) para o problema que deve ser resolvido
projeto ou sistema de ML por conta de rigor técnico-acadêmico ao invés de combinar essa visão com uma melhoria de uma experiência de usuário e/ou melhoria de um processo ou de uma perspectiva de negócios - Projetos que moram no “fantástico mundo da avaliação Offline” - Apelo em demasia a implementações que reflitam apenas o estado da arte em detrimento de performance e aspectos práticos - Um apelo a falso senso de rigor que inunda stakeholders com tecnicalidades desnecessárias O que pode ajudar: - O ideal sempre é uma mistura entre o pragmatismo do mundo corporativo com a mentalidade de inovação e descoberta da academia - Expectativas bem definidas entre os stakeholders do projeto e agenda clara de entregáveis/resultados - Experimentação offline é extremamente útil e tem um grande valor, mas não é uma panaceia
Não gera receita/lucro/benefício para o usuário final - Sem relação a qualquer processo de otimização - Sem relação a qualquer tipo de KPI ou OKR - Sem prazo de entrega - Não apresenta qualquer melhoria prática para algum produto ou mesmo remove fricção da experiência de usuário O que pode ajudar: - Ao menos que você esteja trabalhando em algum laboratório de pesquisa ou como “Research Engineer”, fique longe desses projetos - O ideal que as iniciativas de produtos de dados que usam ML sejam o mais próximo possível do negócio (i.e. negócio =$$$) - Em casos extremos considere mudar de projeto. O fato é que projetos não ligados a objetivos de negócios (i.e. negócios =$$$) são fontes de destruição de valor e são redundantes (i.e. redundantes = dispensáveis)
Loop Características: - Viés voltado para o treinamento de modelos ao invés de um viés “pró-produção” - Uma impressão inocente de que treinando um modelo com apenas usando código “forkado” da internet vai encapsular todas as dinâmicas dos dados e do negócio e as suas complexidades inerentes - Uma visão que subestima o contexto de negócio e capacidades do sistema como um todo O que pode ajudar: - Começar um projeto sempre que possível com conjunto de heurísticas, regras e até mesmo com partes com seres humanos no loop e com deployment não apenas tem um feedback mais veloz como também gera momentum - É mais fácil convencer chefes e demais stakeholders com resultados concretos de código em produção do que slides de powerpoint.
invés de código rodando - Muitas PoC e MVPs mas sem nenhum sistema - Muitas incertezas em relação a esse tipo de projeto - Projetos que começam sem proposta de valor ou mesmo análise de viabilidade - Iniciativas que miram previsibilidade e repetição ao invés de exploração, descoberta e oportunismo O que pode ajudar: - Seja paciente e explique as especificidades do campo de ML e IA. A disciplina de gerenciamento de produtos está no mínimo 10 anos atrás de tudo o que conhecemos como produtos modernos de ML/IA. - Se possível, comece com muitas pequenas abordagens (metralhadora) ao invés de um projeto grande (sniper) e escale de acordo com os resultados. Produtos de dados que usam ML não precisam estarem certos o tempo todo, é sobre estar certo uma única vez e escalar. - Tem muita “bola na caçapa” em relação ao universo de problemas que podem ser resolvidos com a tecnologia atual.
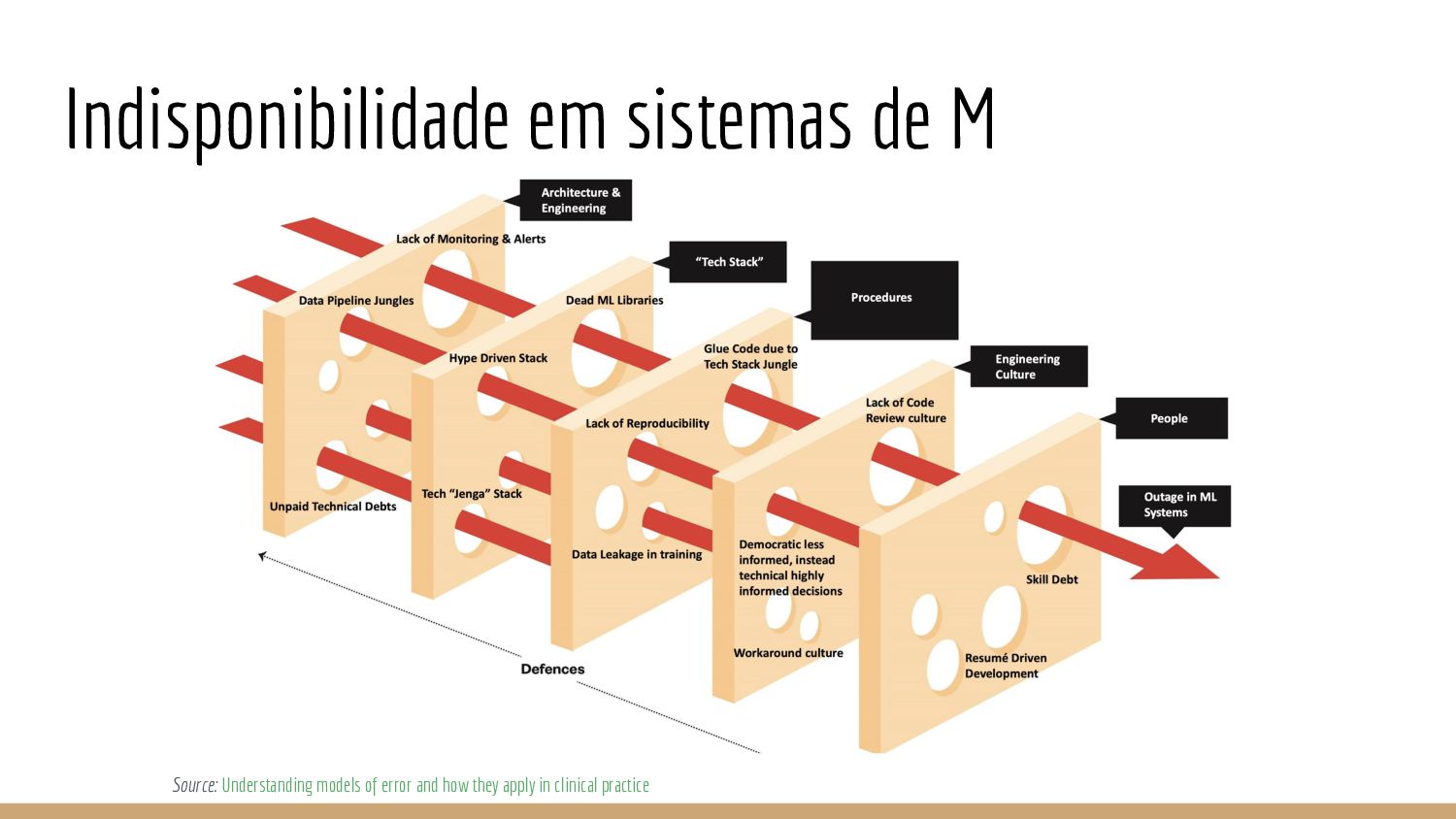
Instrumentalização - Logs / Tracing / APM - Monitoramento - Alarmística - Revisão e melhoria permanente nas “barreiras de defesa” - Pessoas… - Pessoas… - Pessoas… - Cultura de engenharia - Stack de tecnologia - Métodos - Postmortem/Revisão de Incidentes (Incident Reviews) - Importante salientar a cultura de não trabalhar com apuração de culpa e transparência - Revisão permanente nas barreiras de defesa
por diversos motivos dado a inerente complexidade e aspecto multidisciplinar; • Ainda existe um grande desafio de transformação de mentalidade para sair de um modelo em que os erros são ocultados e que se tem apuração de responsabilidade, para um modelo voltado para a discussão de problemas com segurança psicológica e promoção de reformas constantes; • ML/DS em produção é uma disciplina nova (2012) para todas as pessoas: Gerentes de Projeto, Gerentes de Engenharia, Product Owners, Cientistas de Dados, Engenheiros de Software; e • Observabilidade e revisão de processos podem ajudar na prevenção de incidentes mas ferramentas como Postmortems ou revisão de incidentes sem atribuição de culpa são os melhores instrumentos para a criação de uma agenda construtiva que permite uma agenda de melhoria.
incidents: are there holes in the metaphor?.” BMC health services research vol. 5 71. 9 Nov. 2005, doi:10.1186/1472-6963-5-71 • “Hot cheese: a processed Swiss cheese model.” JR Coll Physicians Edinb 44 (2014): 116-21. • Breck, Eric, et al. “What’s your ML Test Score? A rubric for ML production systems.” (2016). • SEC Charges Knight Capital With Violations of Market Access Rule • Machine Learning Goes Production! Engineering, Maintenance Cost, Technical Debt, Applied Data Analysis Lab Seminar Referências
the breakdown of complex systems.” Philosophical Transactions of the Royal Society of London. B, Biological Sciences 327.1241 (1990): 475-484. • Reason, J. “Human error: models and management.” BMJ (Clinical research ed.) vol. 320,7237 (2000): 768-70. doi:10.1136/bmj.320.7237.768 • Morgenthaler, J. David, et al. “Searching for build debt: Experiences managing technical debt at Google.” 2012 Third International Workshop on Managing Technical Debt (MTD). IEEE, 2012. • Alahdab, Mohannad, and Gül Çalıklı. “Empirical Analysis of Hidden Technical Debt Patterns in Machine Learning Soſtware.” International Conference on Product-Focused Software Process Improvement. Springer, Cham, 2019. Referências
and Asymmetric Exposures • Skybrary – Human Factors Analysis and Classification System (HFACS) • CEFA Aviation – Swiss Cheese Model • A List of Post-mortems • Richard Cook – How Complex Systems Fail • Airbus – Hull Losses • Number of flights performed by the global airline industry from 2004 to 2020 Referências
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}