In Unternehmen werden Datenanalysen intensiv genutzt, um aus Geschäftsdaten wertvolle Einsichten zu gewinnen. Warum nutzen wir als SoftwareentwicklerInnen Datenanalysen dann nicht auch für unsere eigenen Daten?
In diesem Vortrag stelle ich Vorgehen und Best Practices von Software Analytics vor. Wir sehen uns die dazugehörigen Open-Source-Werkzeuge an, mit denen sich Probleme in der Softwareentwicklung zielgerichtet analysieren und kommunizieren lassen.
Im Praxisteil mit Jupyter, pandas, jQAssistant, Neo4j & Co. erarbeiten wir gemeinsam wertvolle Einsichten aus Datenquellen wie Git-Repositories, Performancedaten, Qualitätsberichten oder auch direkt aus dem Java-Programmcode. Wir suchen nach besonders fehleranfälligem Code, erschließen No-Go-Areas in Altanwendungen und priorisieren Aufräumarbeiten entlang wichtiger Programmteile.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Wir laden einen Datenexport aus einem Git-Repository. In [4]: log](https://files.speakerdeck.com/presentations/d7fa8b96d4164afb8e10e9036eee8d1c/slide_49.jpg){kind=link}
![Wir sehen uns Basisinfos über den Datensatz an. In [5]:](https://files.speakerdeck.com/presentations/d7fa8b96d4164afb8e10e9036eee8d1c/slide_50.jpg){kind=link}
{kind=link}
![Wir sehen uns nur die jüngsten Änderungen an. In [13]:](https://files.speakerdeck.com/presentations/d7fa8b96d4164afb8e10e9036eee8d1c/slide_52.jpg){kind=link}
![Wir wollen nur Java-Code verwenden. In [16]: java = recent[recent['filename'].str.endswith(".java")]](https://files.speakerdeck.com/presentations/d7fa8b96d4164afb8e10e9036eee8d1c/slide_53.jpg){kind=link}
{kind=link}
![Wir zählen die Anzahl der Änderungen je Datei. In [21]:](https://files.speakerdeck.com/presentations/d7fa8b96d4164afb8e10e9036eee8d1c/slide_55.jpg){kind=link}
![Wir holen Infos über die Code-Zeilen hinzu... In [24]: cloc](https://files.speakerdeck.com/presentations/d7fa8b96d4164afb8e10e9036eee8d1c/slide_56.jpg){kind=link}
![...und verschneiden diese mit den vorhandenen Daten. In [37]: hotspots](https://files.speakerdeck.com/presentations/d7fa8b96d4164afb8e10e9036eee8d1c/slide_57.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
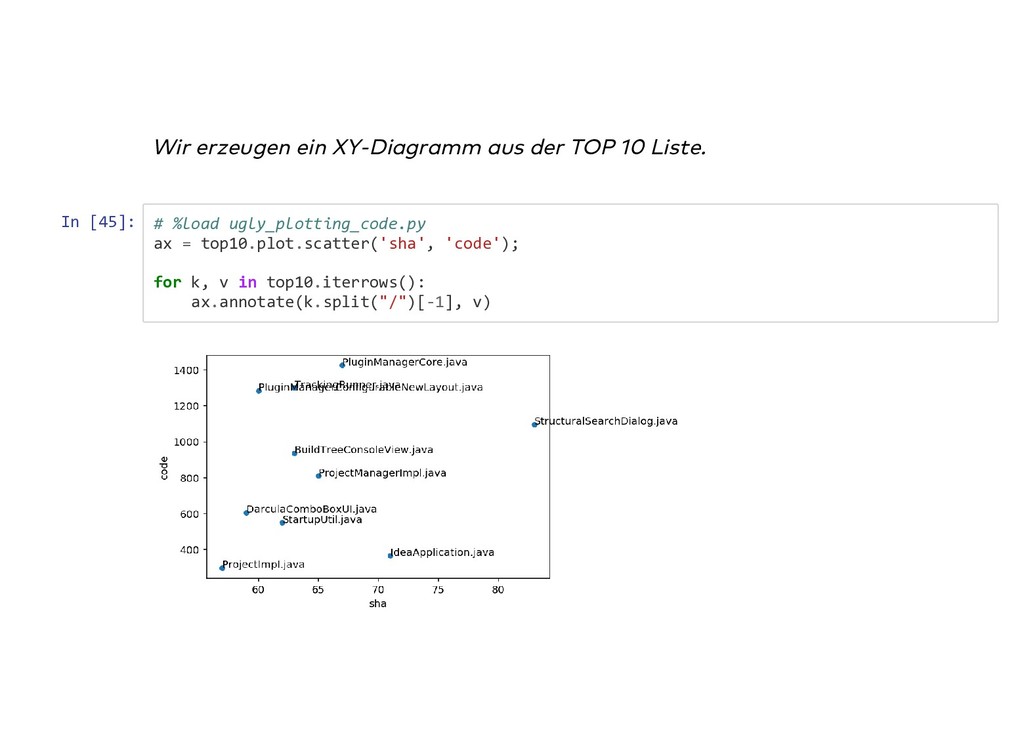{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Danke! Fragen? Danke! Fragen? Markus Harrer innoQ Deutschland GmbH [email protected]](https://files.speakerdeck.com/presentations/d7fa8b96d4164afb8e10e9036eee8d1c/slide_67.jpg){kind=link}