Artificial intelligence (AI) has been transformed by machine learning (ML) methodologies due to ML’s advantage in scalability in cloud and vast choices of open-source as well as commercial, off-the-shelf (COTS) solutions. However, the complexity of ML puts AI at the center of discussion regarding decision fairness or transparency, ethics, as well as reliability. As these concerns impact feasibility and adoptions of AI in enterprises, there is a need for generalized guidelines or approaches to evaluate ML model performance in the context of these concerns
This talk will provide a framework that can help determine the performance, fairness and transparency through ML model characterization. Methods and approaches to model characterization will be proposed. After this talk, audiences will have a better understanding in: 1. How to evaluate and understand the limit of ML model built by data science team; 2. Functional knowledge in relevant model key performance metrics (KPI) that helps decision makers in model validation, adoption or deployment. 3. For ML practitioners and engineers, common practices in fields for dealing with data class imbalance or sampling bias.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
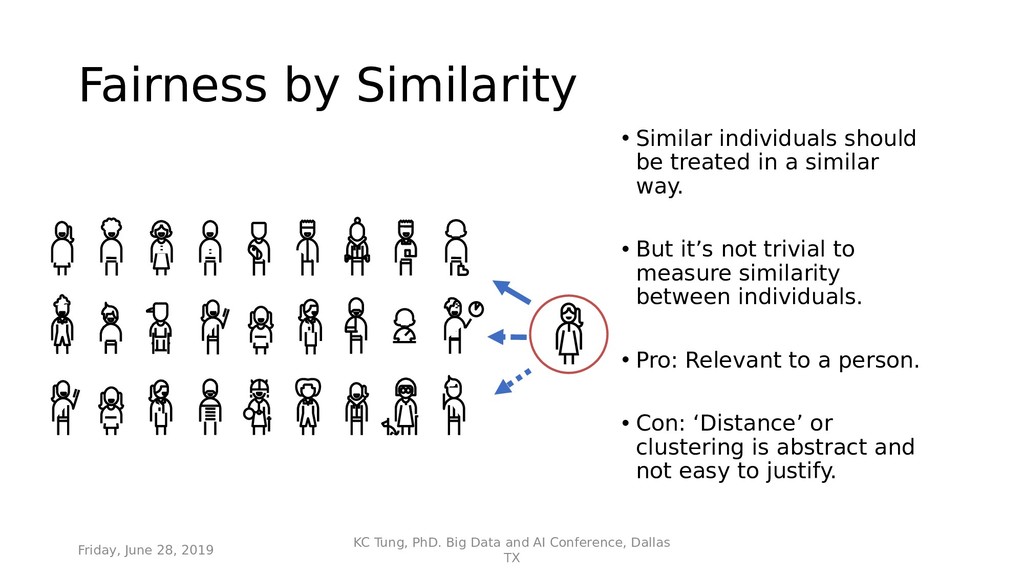{kind=link}
{kind=link}
{kind=link}
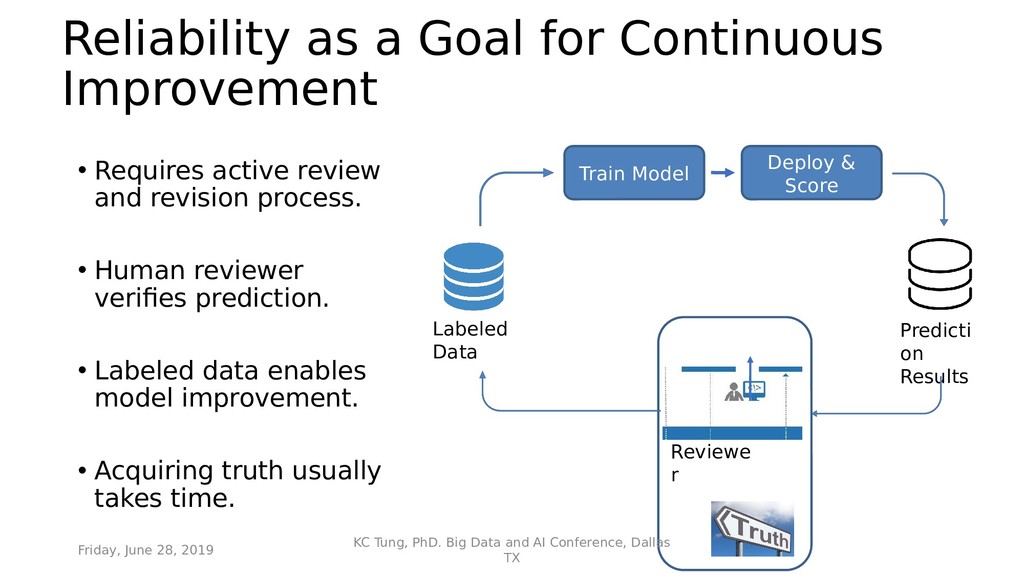{kind=link}
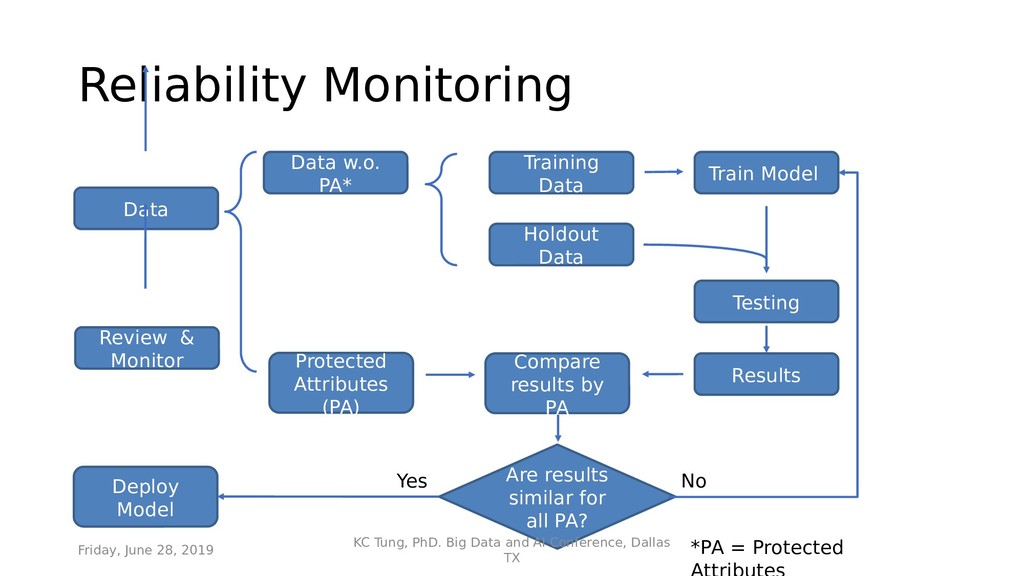{kind=link}
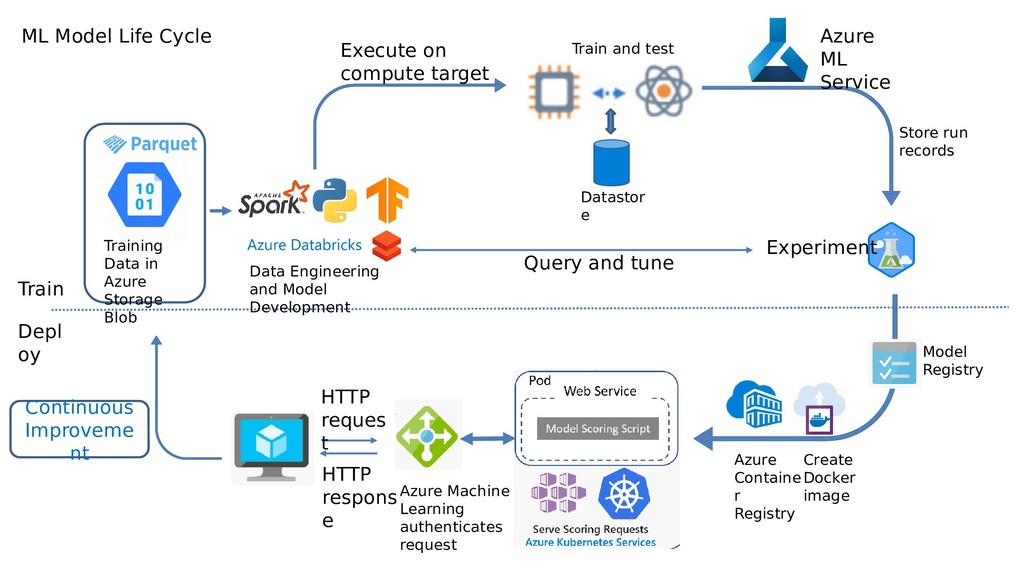{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}