Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データベースの雑な話 in 栃木ゆるIT勉強会@小山
Search
Origamium
January 17, 2025
Programming
0
96
データベースの雑な話 in 栃木ゆるIT勉強会@小山
Origamium
January 17, 2025
Tweet
Share
Other Decks in Programming
See All in Programming
CSC307 Lecture 10
javiergs
PRO
1
660
atmaCup #23でAIコーディングを活用した話
ml_bear
1
160
AIエージェント、”どう作るか”で差は出るか? / AI Agents: Does the "How" Make a Difference?
rkaga
4
2k
CSC307 Lecture 02
javiergs
PRO
1
780
AWS re:Invent 2025参加 直前 Seattle-Tacoma Airport(SEA)におけるハードウェア紛失インシデントLT
tetutetu214
2
120
16年目のピクシブ百科事典を支える最新の技術基盤 / The Modern Tech Stack Powering Pixiv Encyclopedia in its 16th Year
ahuglajbclajep
5
1k
izumin5210のプロポーザルのネタ探し #tskaigi_msup
izumin5210
1
140
AIで開発はどれくらい加速したのか?AIエージェントによるコード生成を、現場の評価と研究開発の評価の両面からdeep diveしてみる
daisuketakeda
1
2.5k
ノイジーネイバー問題を解決する 公平なキューイング
occhi
0
110
Fluid Templating in TYPO3 14
s2b
0
130
Apache Iceberg V3 and migration to V3
tomtanaka
0
180
余白を設計しフロントエンド開発を 加速させる
tsukuha
7
2.1k
Featured
See All Featured
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
66
37k
Test your architecture with Archunit
thirion
1
2.2k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
1
58
Chasing Engaging Ingredients in Design
codingconduct
0
120
GitHub's CSS Performance
jonrohan
1032
470k
AI: The stuff that nobody shows you
jnunemaker
PRO
2
280
How to build a perfect <img>
jonoalderson
1
4.9k
VelocityConf: Rendering Performance Case Studies
addyosmani
333
24k
Docker and Python
trallard
47
3.7k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
130
ラッコキーワード サービス紹介資料
rakko
1
2.3M
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
9.9k
Transcript
データベースの雑な話 B-TreeだけじゃないDBのあれこれ
お願い • スライドの写真撮影はOKです • 「私」の撮影はご遠慮ください
自己紹介 • アークリスプ / 尾上折紙(おのうえ おりがみ) ◦ 本名ではない ▪ あらゆるサービスに偽名で登録している
◦ Lisperだった時期がありそのような名前になった ◦ arcというlisp方言があって… ◦ Twitterの名前はコロコロ変わる • React+TypeScriptでフロントエンドエンジニアをやっている ◦ 現職ではPHPも書いている ▪ むしろこっちがメインでは???? ◦ rustたまに書くけど難しい • 転職をポンポンしてたら経歴が汚れまくって書類面接で落ちまくるようになりかなり ヘコむ
_人人人人人人人人人人人人人人人人_ > 突然DB自作したくなってきた <  ̄Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y ̄
DBの話 • DBにはいろいろあるが、雑に3個に大別される ◦ RDBMS ▪ MySQL、PostgreSQL、SQLiteとか ▪ いわゆる普通のデータベースシステム ◦
NoSQL ▪ DynamoDB、MongoDB、Redisとか ▪ 水平にスケールしやすいがクセが強い事が多い ◦ NewSQL ▪ AWS Aurora、GCP Spanner ▪ 業務などの実運用で RDBMSのようなものを使いたいとなると候補に上がりやすい • Aurora MySQLとAurora PostgreSQLはそれぞれ「互換」というだけで中身は別物
• 作るのならやはりRDBMSだろうという気持ちに • しかし何も知らない ◦ だいたいB-Treeとかいうアルゴリズムで作られているという雑な認識 ▪ 大学でデータベースの講義をとったのにこの程度の理解という残念な状態 ◦ MySQLとかPostgreSQLの実装を見に行ったが案の定複雑かつ大規模
▪ 何も知らない状態で見に行っても何が何やってるのかわからず困惑 ◦ 勉強しようにもDB関連の本はほぼすべてが「使う」ことが目的 ◦ 初手で詰む
None
None
ありました • Rustで簡単なRDBMSの実装の紹介 • 小さいので取っ掛かりとしてかなり良かった ◦ SQL文の解釈などはやらない ◦ データの保存と取り出しのみ(語弊がある言い方) ◦
Rustなので型が頑健で理解しやすい • 書籍にすべてのコードが載ってはいないのでGithubを見に行って往復
B-Treeがすべてではないことを知る • そもそもB-Treeは基本形なだけであって実際にはB-Treeを拡張したアルゴリズム を使うこともある ◦ MySQLはB+Treeという亜種を使っている • データ表現の方法でしかない • ディスクやメモリ、キャッシュの扱いをちゃんとしないといけない
◦ 結構大変 ◦ 今回はこのあたりの話です
そもそもどうやってデータは持ち出されるのか • データの読み書きは基本的にOSのファイルシステムが管理する ◦ ファイルシステムは固定長のサイズでデータをストレージからとってくる ◦ ブロックサイズという ◦ ext4の場合はデフォルトが 4096byteで設定されてる
▪ 変更できるが、実質1024byte, 2048byte, 4096byteの3種類のどれかから選ぶしかない ◦ このブロックサイズを基本としてデータは取りに行かれる
データの読み書きはものすごく遅い • HDDへのアクセス時間は10~20msぐらいかかる • SSDでも100~200μsぐらい • メインメモリなら100ns ◦ つまりメモリにないものを HDDから読み込もうとするとアクセスするだ
けで10万倍の時間がかかる ◦ SSDならかなりマシになるとはいえそれでも遅い • もっと言えばL1 cacheは1.33~4nsぐらい • ということでストレージへのアクセスの遅さを隠蔽したい ms: 10^-3秒 μs: 10^-6秒 ns: 10^-9秒
キャッシュは王様 • すべてのデータをメモリが持ち続けるのは現 実的ではない ◦ 揮発するし ◦ 容量少ないし • よくアクセスされるデータはメモリに持ってお
いてなるべくストレージにはアクセスしない • キャッシュヒット率を上げる
キャッシュの方法 • OSに任せる ◦ OSの違いやバージョンによってキャッシュの仕方が全然違くて挙動が変わると言ったことが起こり 得る ◦ 大半のシステムならこれでいいが、 DBにおいては不都合 •
自分で実装する ◦ すべてを管理できる ◦ 最適なアルゴリズムを選択できる ◦ メモリの位置などの調節も可能(アラインメント) ▪ アラインメントは結構大事で、読み込みたいデータがメモリ上でデータが連続しているのが理 想的 ▪ 断片化しているとプロセッサはメモリに複数回問い合わせないといけなくなる
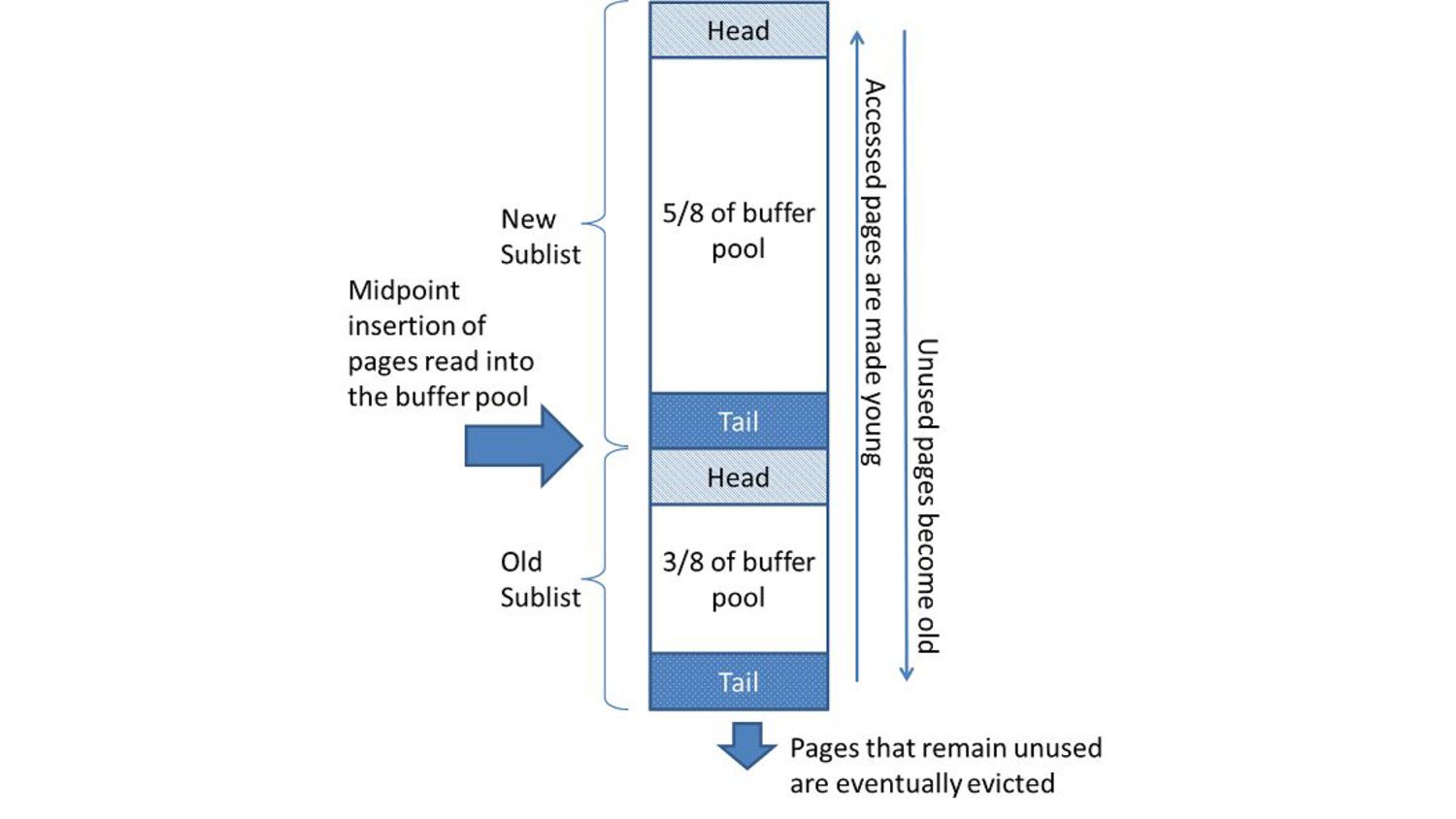
キャッシュの方法 • LRU (Least Recently Used) ◦ いろいろなRDBMSが採用している ◦ 最近もっとも使用されてない値を捨てる
(evictionする)方式 ◦ 実装は多種多様で、それぞれの DBでどのように実装されているかがかなり異なる ▪ ほとんどLRUと名乗っているだけで実質亜種みたいな感じになってる ◦ MySQLの実装例を紹介します • 他にも色々あるがあとで紹介します
None
LRU • LRUは簡単に見えるが実際に使用していくと数々の問題が出てくる ◦ ランダムアクセスが基本となるクエリには強いかもしれないが、シーケンシャルアクセスには極端に 弱い ◦ シーケンシャルなアクセスをした途端キャッシュのすべてがそのデータで埋め尽くされるといったこ とになりかねない ◦
それを踏まえたうえで別のアルゴリズムを選択するか、拡張していくことをしなければいけない ◦ DBのキャッシュというのは地獄 ◦ ちなみに、他のアルゴリズムには MRU、CLOCK、Q2とかがあります
ストレージの最適化 • キャッシュは大事だが、そもそもDBは主としてストレージのデータを扱う • ストレージへのアクセスは必須なので、ストレージも最適化の必要がある • SSDなら大丈夫なんてことはない
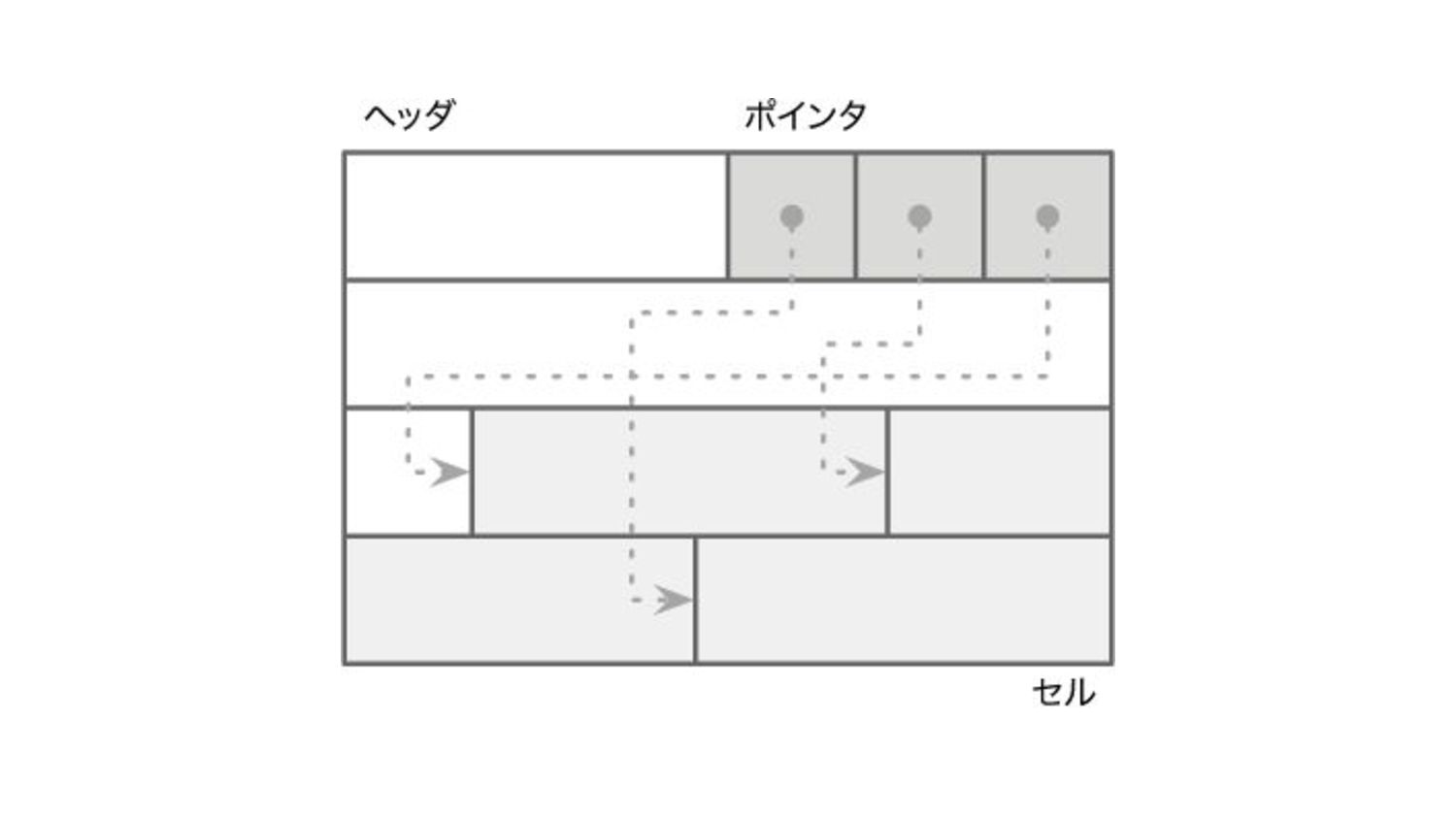
スロット化ページ • ディスク上のデータレイアウトを考える • フラグメンテーションは避けたい ◦ HDDメインの時代にはデフラグなんてことをやってましたね • 保存したいデータ型はいろいろある ◦
固定長: integer, float, double, char… ◦ 可変長: text, blob • これらを効率的に格納するために、スロット化ページを利用する
スロット化ページ • 大まかには、ディスク上にポインタ(実データ位置の情報)とレコードの位置を決定 する • 可変長レコードの保存も簡単にするために、ページを固定長のセグメントに分割す る ◦ 固定長に分割する以上、たとえば 64Byteのセグメントに1Byteしか入らなかったら63Byteの容量が
無駄になる • ページの追加は単にデータを追記すればよい • 削除の際はページを書き直してレコードを移動することで領域を回収
None
まとめ • ここまで紹介したものはかなりざっくりした解説 • 小さな実装では複雑にはならないが… ◦ →実際はもっとややこしいことになっている • 実際にはストレージの故障に備えてバックアップをすることや、ログの保存もやる ◦
マルチスレッド化でLRUなどのキャッシュまわりは大胆に複雑になる ◦ 分散ストレージを採用すれば … ◦ 分散合意アルゴリズム (Paxos, Raftなど)… ◦ クラスター化… ◦ 沼
None
ここ小山市でシェアハウスやる(宣伝タイム) • 小山駅徒歩8分(Google Maps調べ) • 音響設備がなぜか整っている ◦ アンプだけで100万円ぐらいぶっこんだ ◦ 簡易Dolby
Atmos環境 ◦ 将来的には音響部屋にスピーカーを 16台設置するつもり • 現行のゲーム機全部ある ◦ PS5 Proも導入しました • 家賃4万円前後 ◦ ギーク割で5000円安くなる https://geekhouseoyama.vercel.app/
シアター12の様子
参考文献 • MySQL docs - https://dev.mysql.com/ • PostgreSQLの新しいバッファ戦略 - https://www.postgresql.jp/sites/default/files/2016-12/20040510143054.tanida_
buffering_040511-1.pdf • 計算の高速化のために必要なこと:メモリの観点 - https://qiita.com/zacky1972/items/25e8157a7593398c9730 • 詳説 データベース - ストレージエンジンと分散データシステムの仕組み(オライリー ・ジャパン) ◦ 画像の引用をさせていただきました • AWSとGCPのドキュメンテーション
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}