*src, uint8_t *dst, int width, int height) { int x = blockIdx.x * blockDim.x + threadIdx.x; int y = blockIdx.y * blockDim.y + threadIdx.y; if (x < width && y < height) dst[y + x * height] = src[x + y * width]; } xとyを逆にするだけ 29
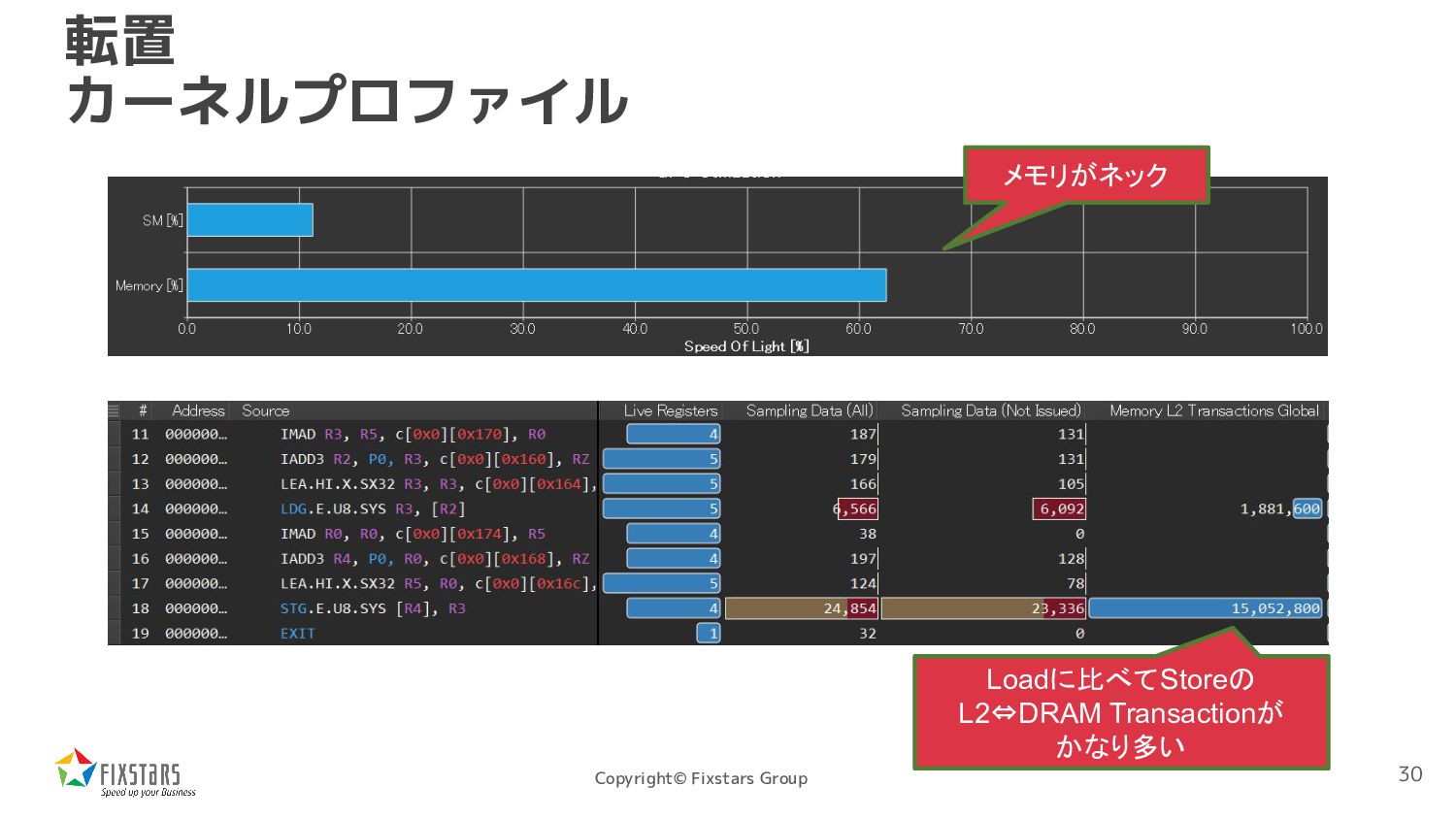
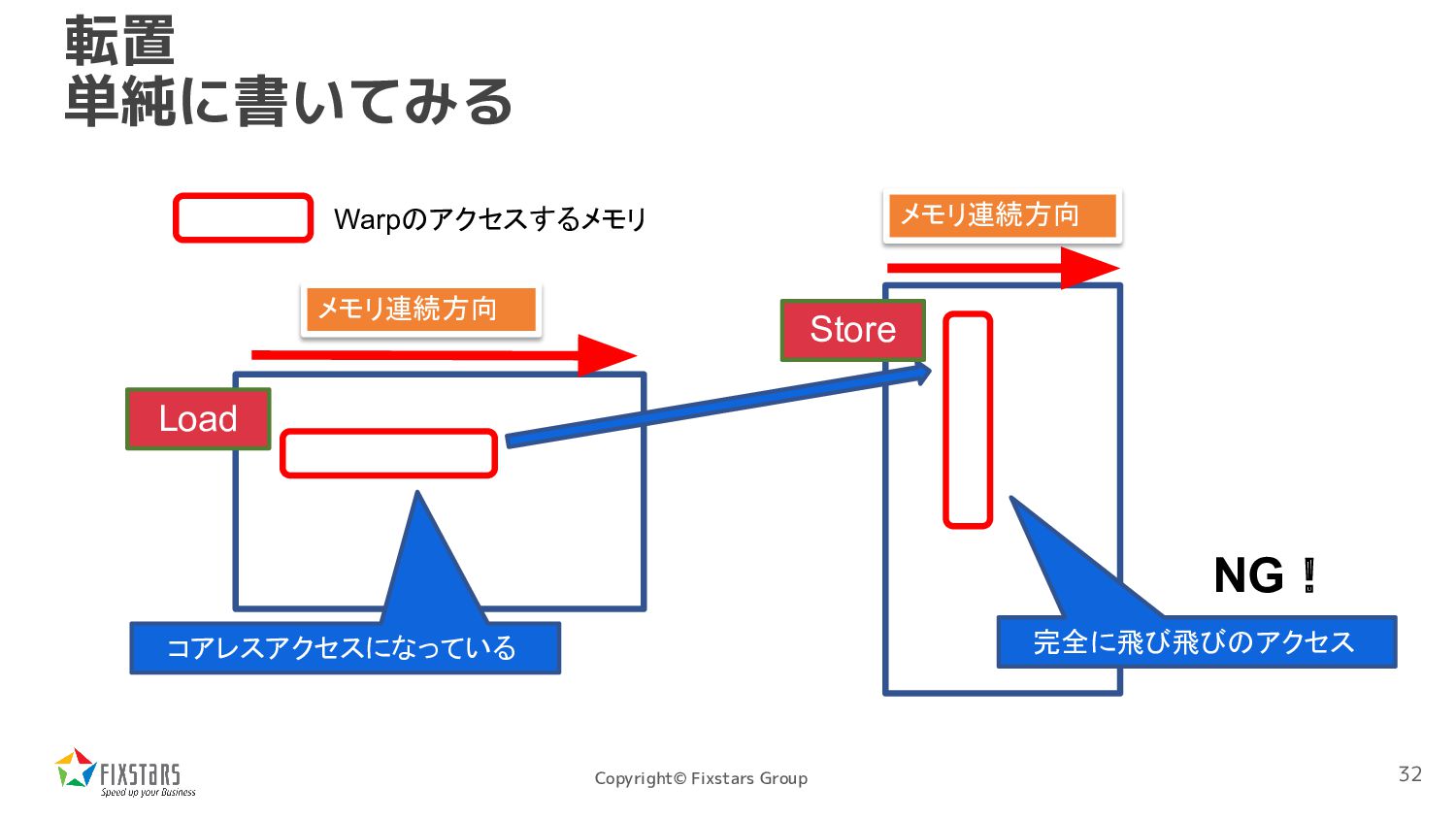
*src, uint8_t *dst, int width, int height) { int x = blockIdx.x * blockDim.x + threadIdx.x; int y = blockIdx.y * blockDim.y + threadIdx.y; if (x < width && y < height) dst[y + x * height] = src[x + y * width]; } 書き込みが全くコアレスアクセス になっていない 31
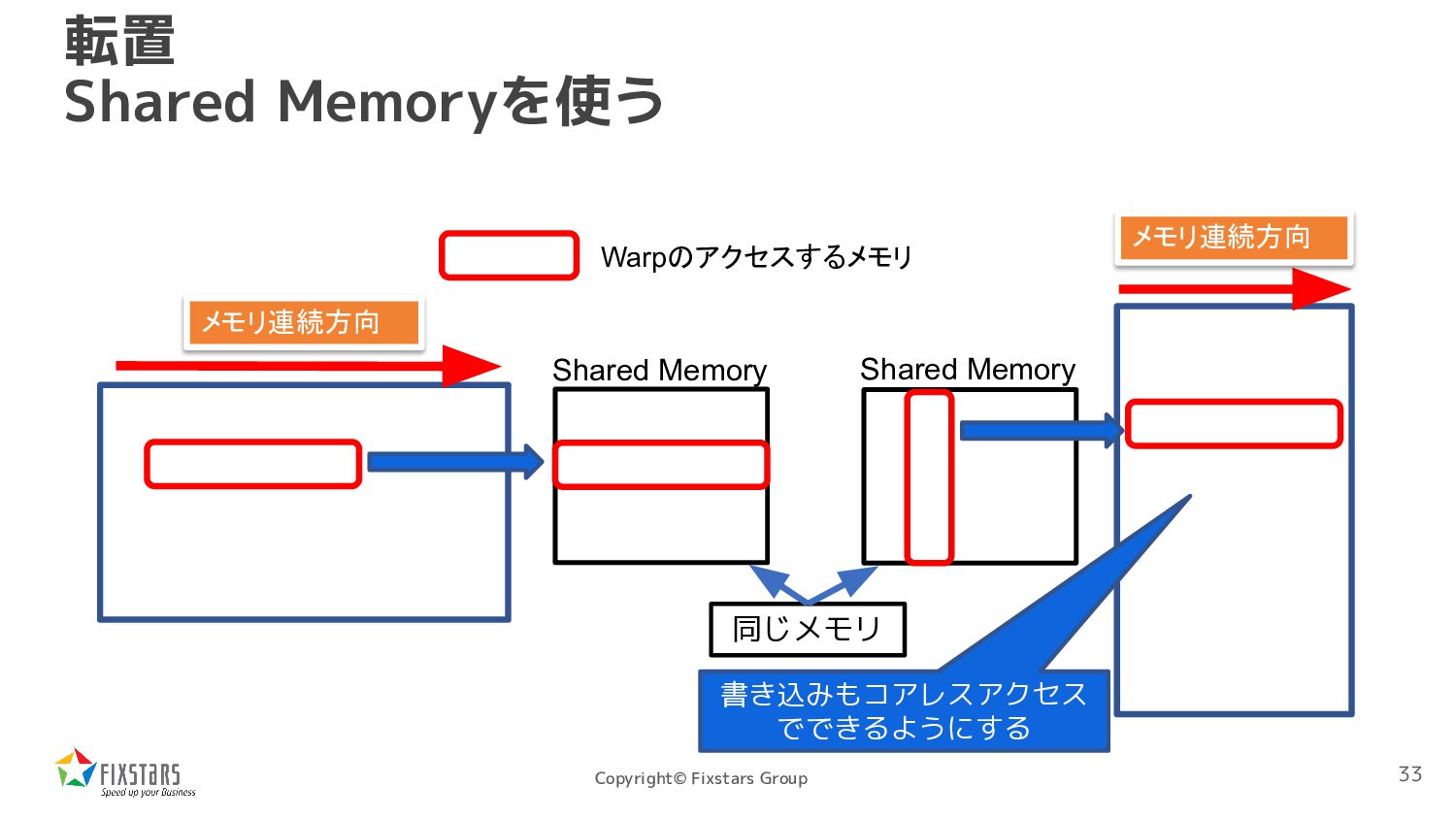
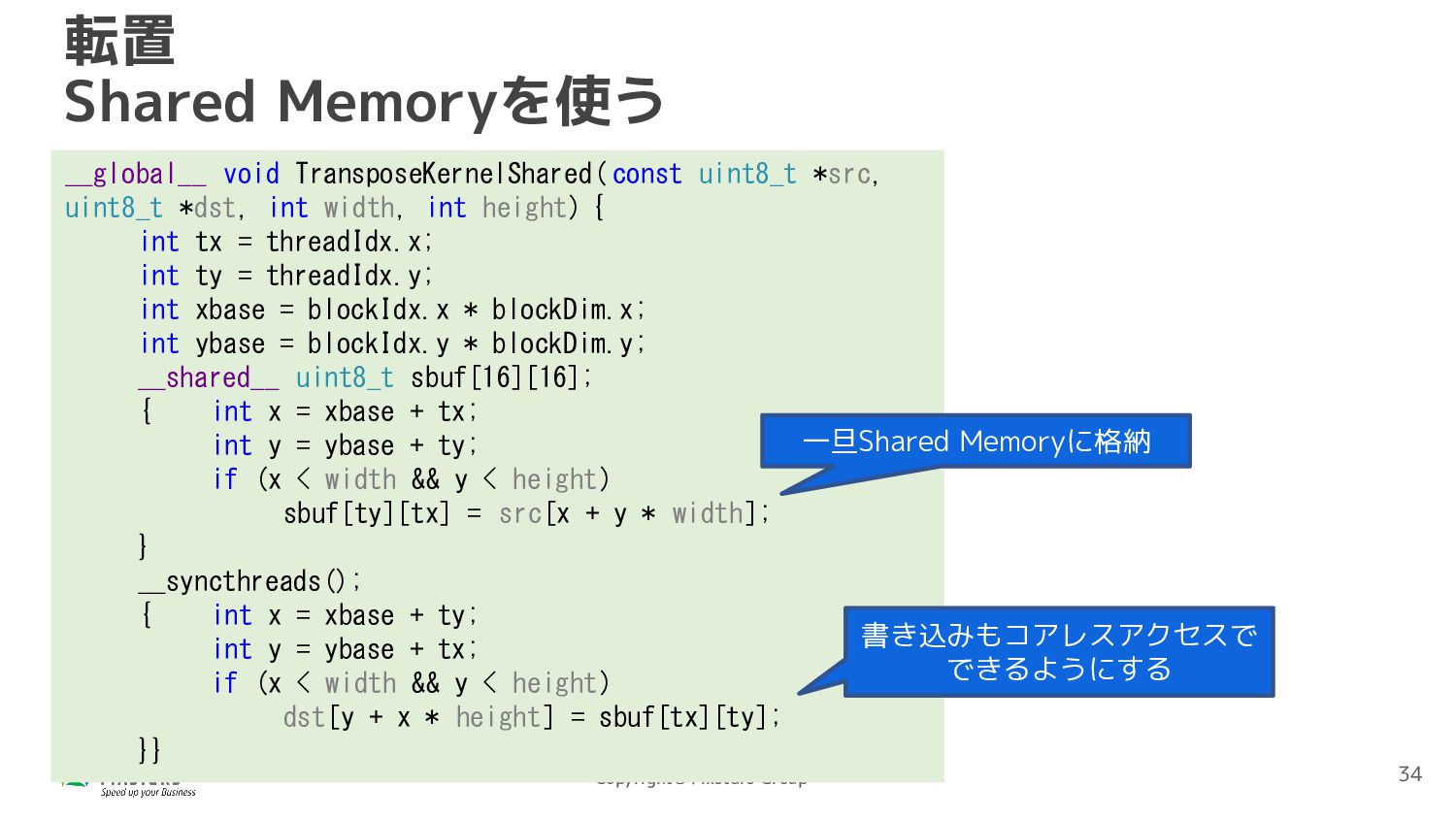
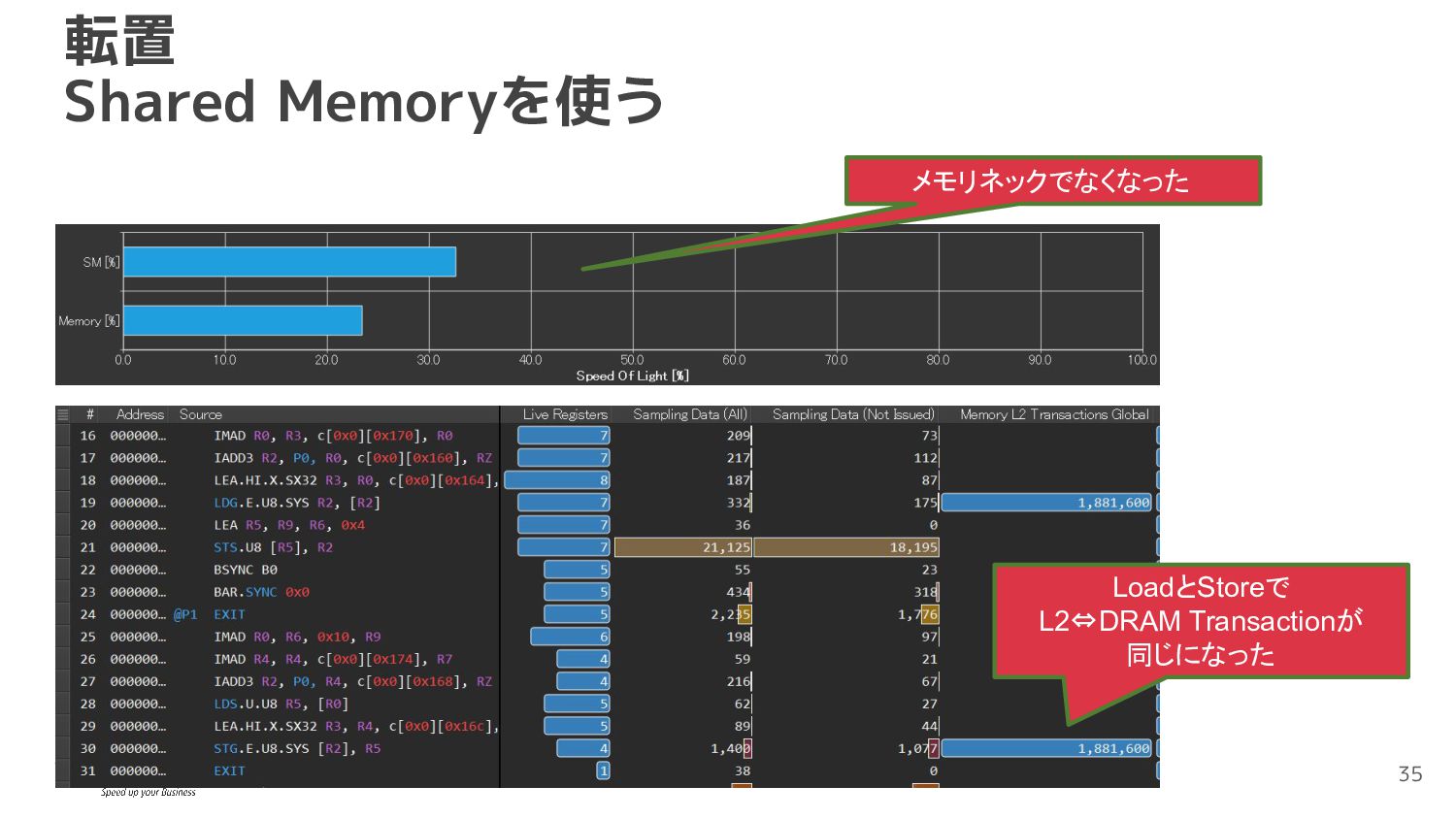
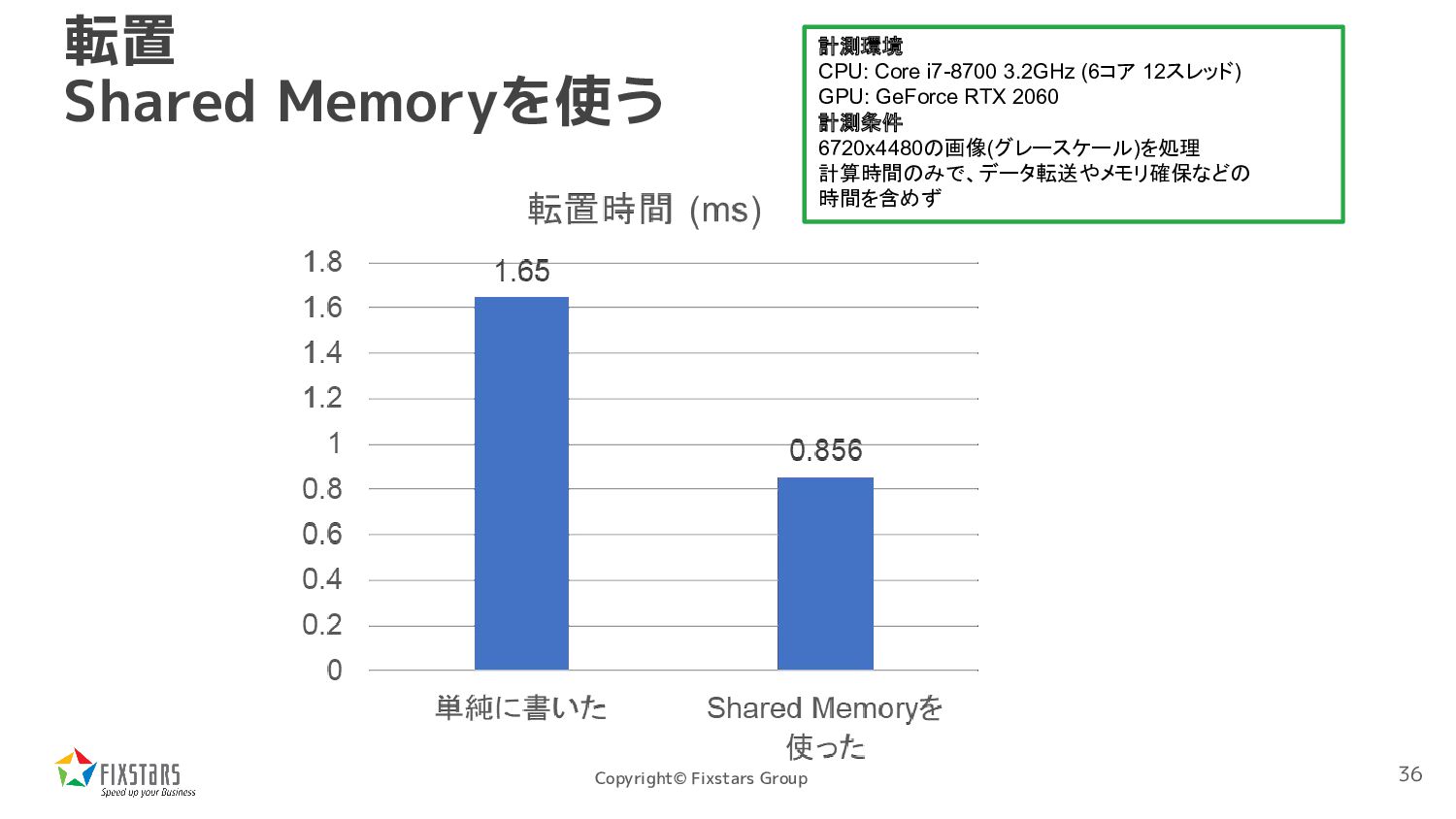
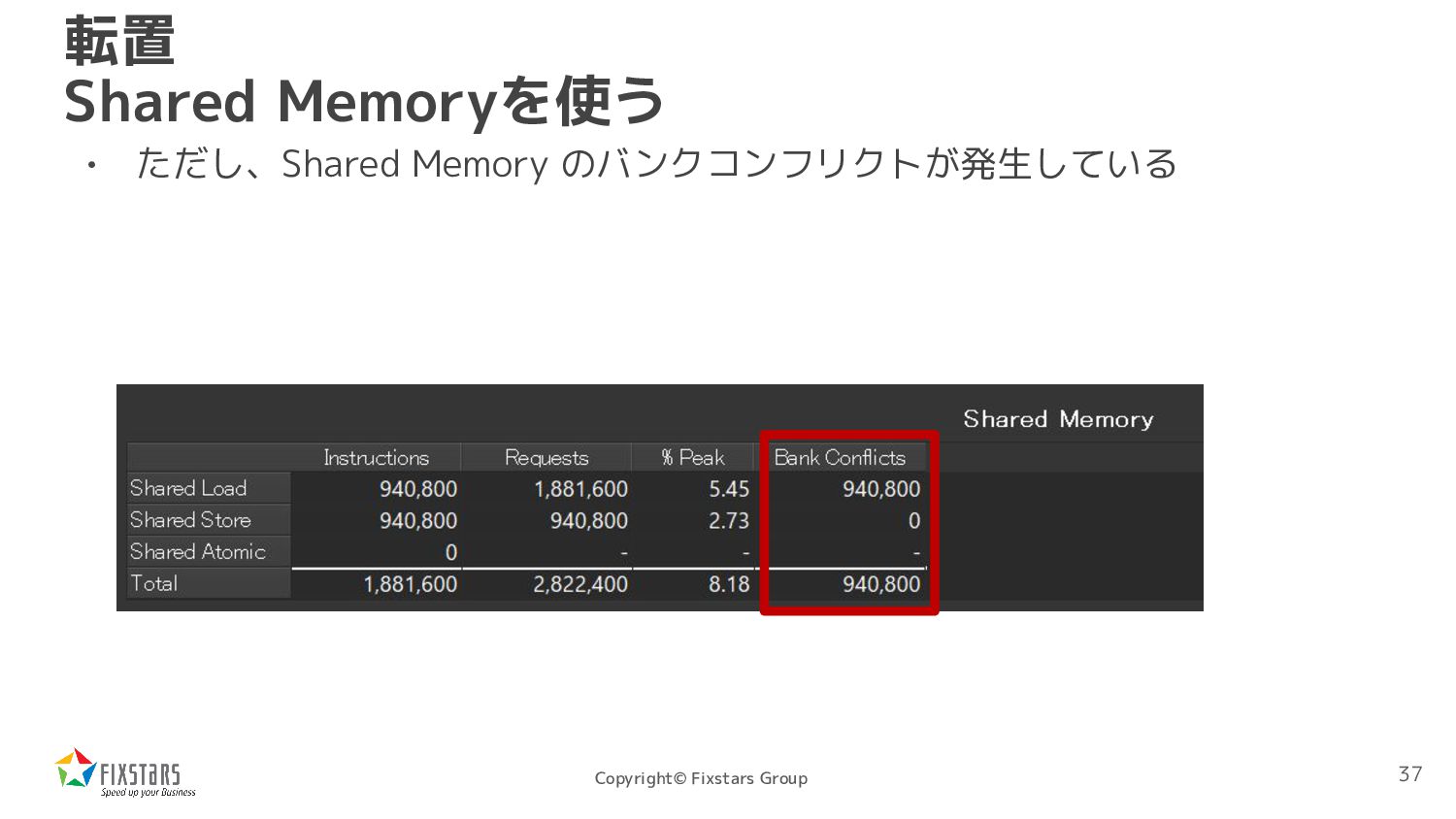
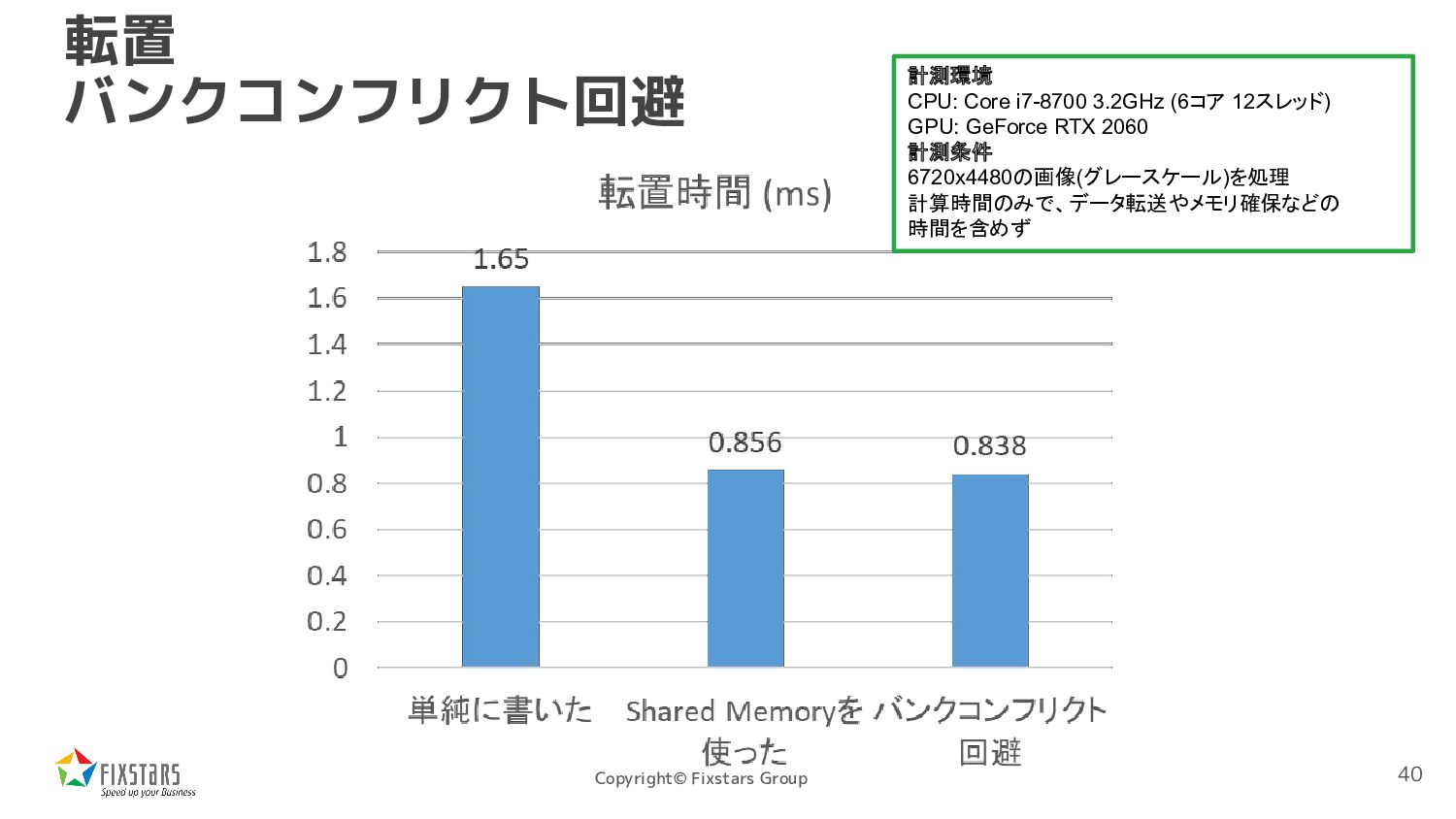
*dst, int width, int height) { int tx = threadIdx.x; int ty = threadIdx.y; int xbase = blockIdx.x * blockDim.x; int ybase = blockIdx.y * blockDim.y; __shared__ uint8_t sbuf[16][16]; { int x = xbase + tx; int y = ybase + ty; if (x < width && y < height) sbuf[ty][tx] = src[x + y * width]; } __syncthreads(); { int x = xbase + ty; int y = ybase + tx; if (x < width && y < height) dst[y + x * height] = sbuf[tx][ty]; }} 転置 Shared Memoryを使う 書き込みもコアレスアクセスで できるようにする 一旦Shared Memoryに格納 34
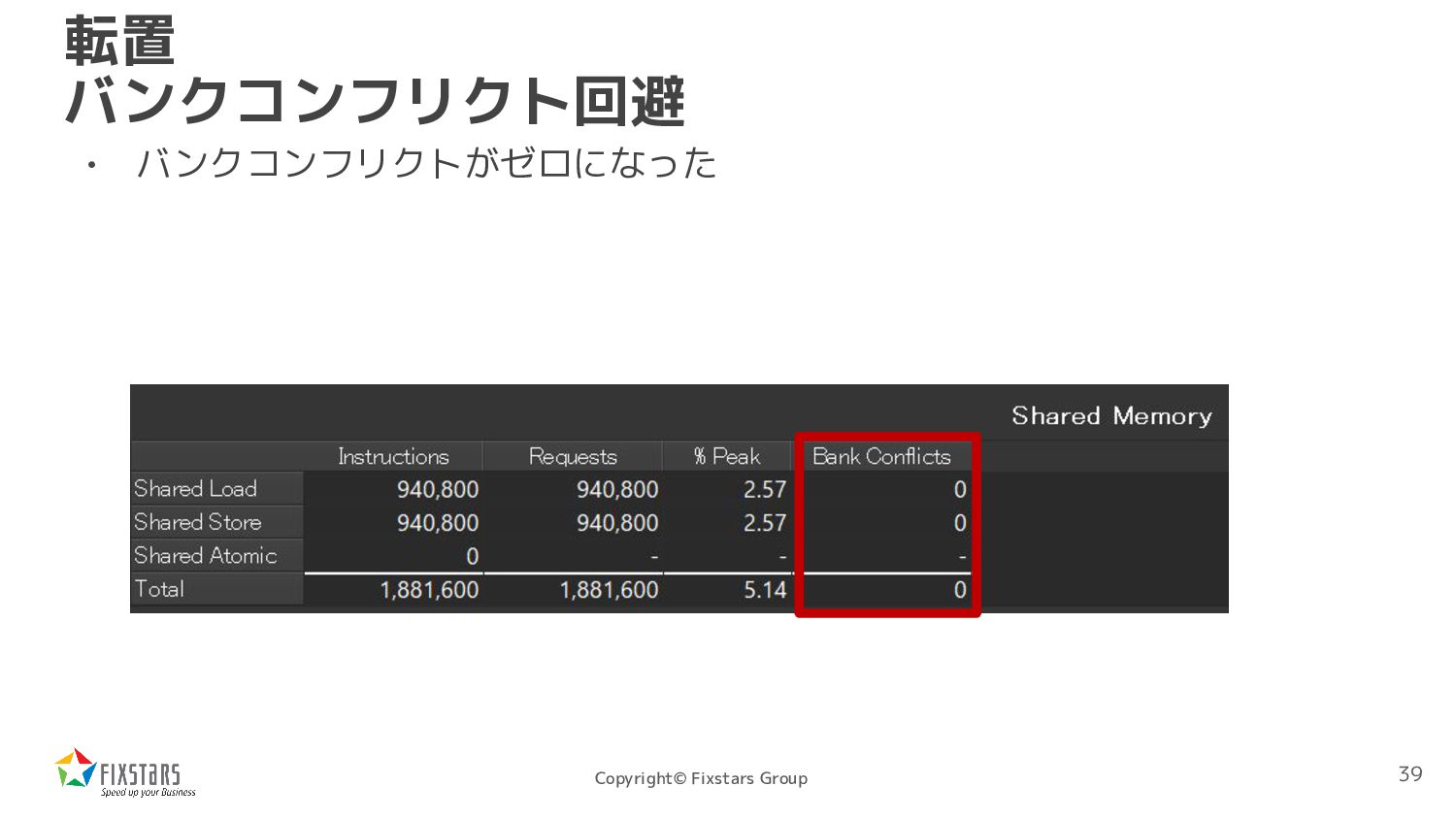
*dst, int width, int height){ int tx = threadIdx.x; int ty = threadIdx.y; int xbase = blockIdx.x * blockDim.x; int ybase = blockIdx.y * blockDim.y; __shared__ uint8_t sbuf[16][16+4]; { int x = xbase + tx; int y = ybase + ty; if (x < width && y < height) sbuf[ty][tx] = src[x + y * width]; } __syncthreads(); { int x = xbase + ty; int y = ybase + tx; if (x < width && y < height) dst[y + x * height] = sbuf[tx][ty]; }} 転置 バンクコンフリクト回避 パディングを追加 Shared Memoryのバンクは 4バイトインターリーブされているので、 4バイトパディングを追加する 38
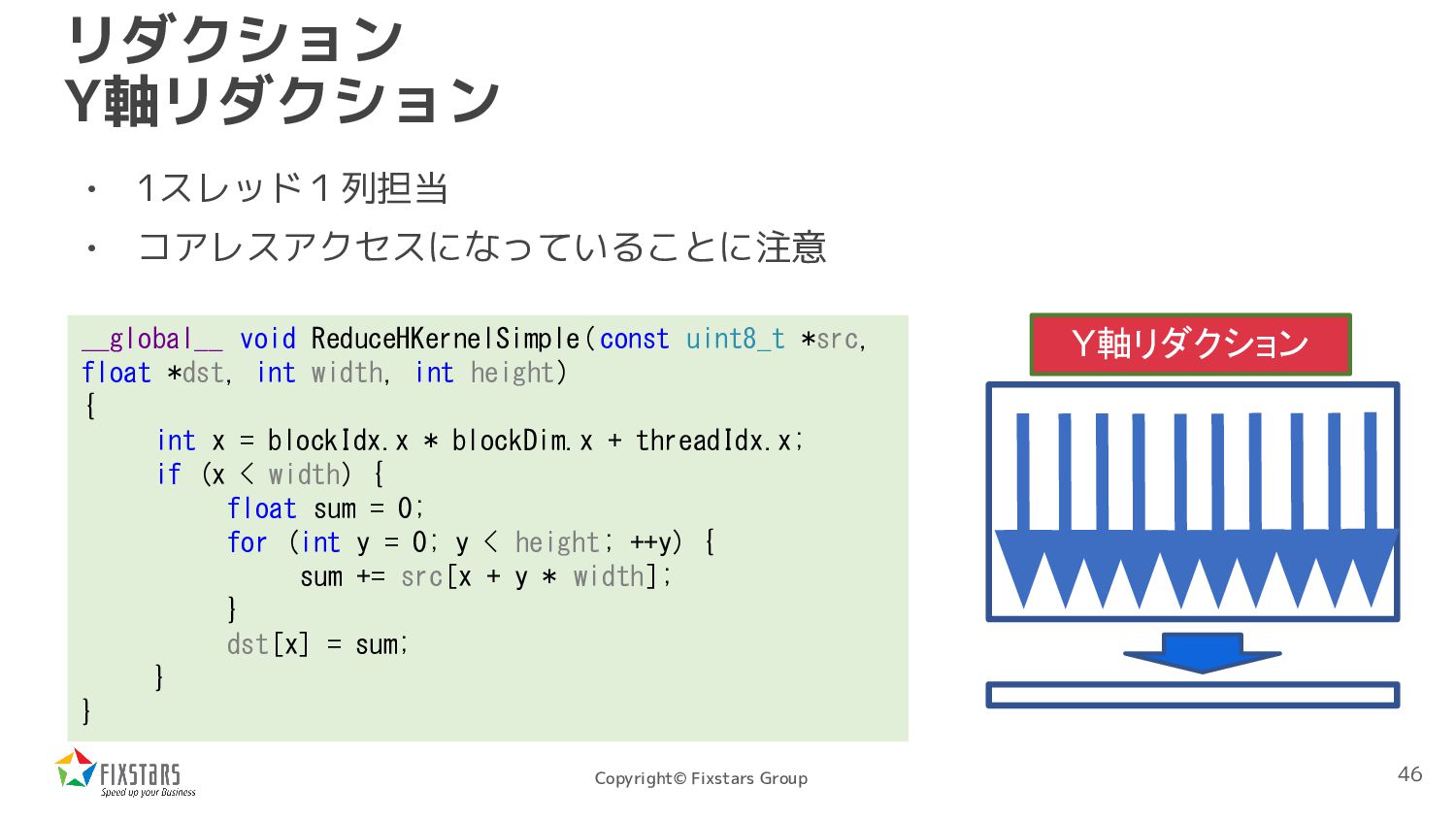
void ReduceHKernelSimple( const uint8_t *src, float *dst, int width, int height) { int x = blockIdx.x * blockDim.x + threadIdx.x; if (x < width) { float sum = 0; for (int y = 0; y < height; ++y) { sum += src[x + y * width]; } dst[x] = sum; } } Y軸リダクション 46
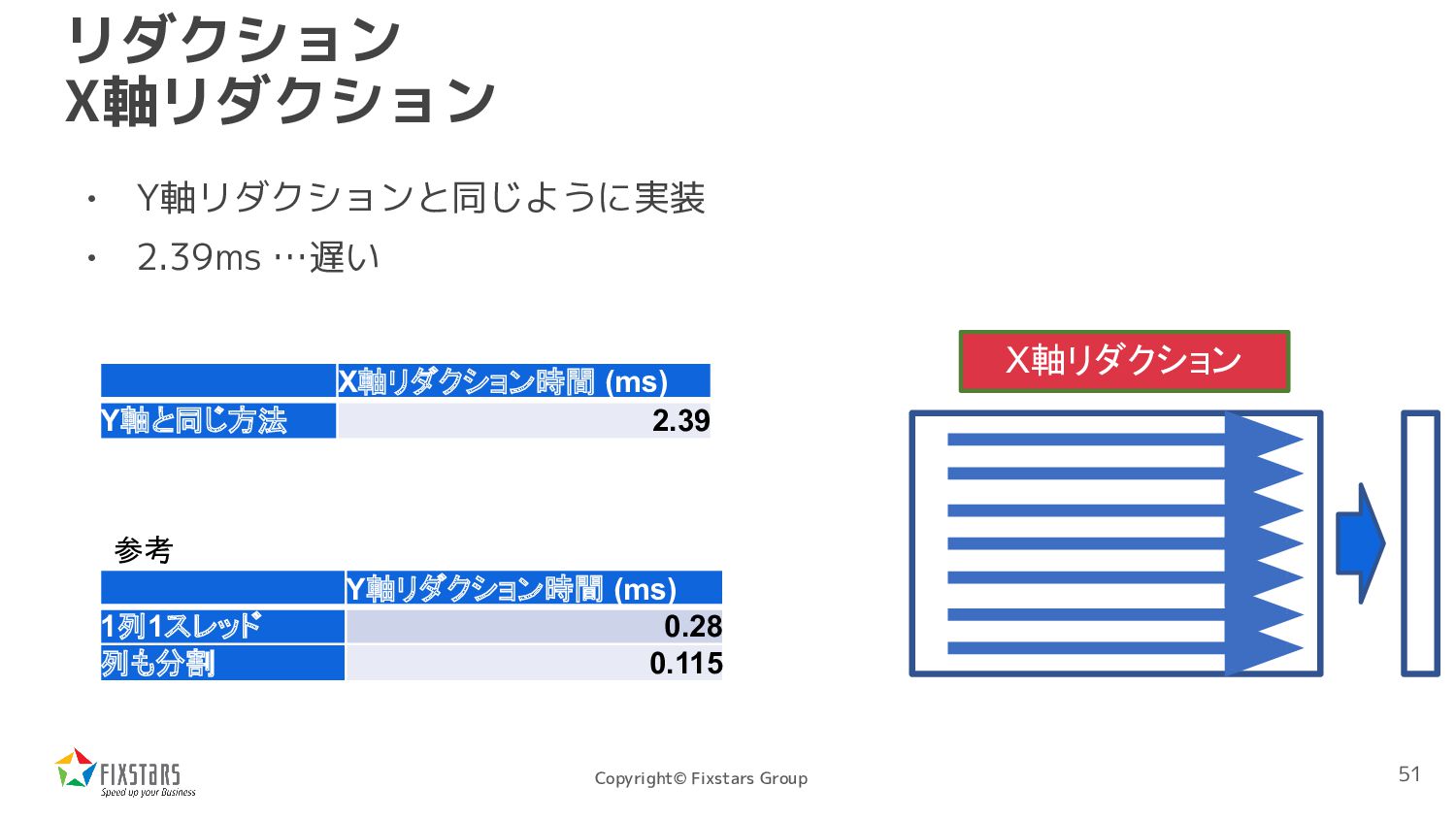
ReduceWKernelSimple( const uint8_t *src, float *dst, int width, int height) { int y = blockIdx.x * blockDim.x + threadIdx.x; int x = blockIdx.y * 128; if (y < height) { float sum = 0; for (int xend = min(x + 128, width); x < xend; ++x) { sum += src[x + y * width]; } atomicAdd(&dst[y], sum); } } 50
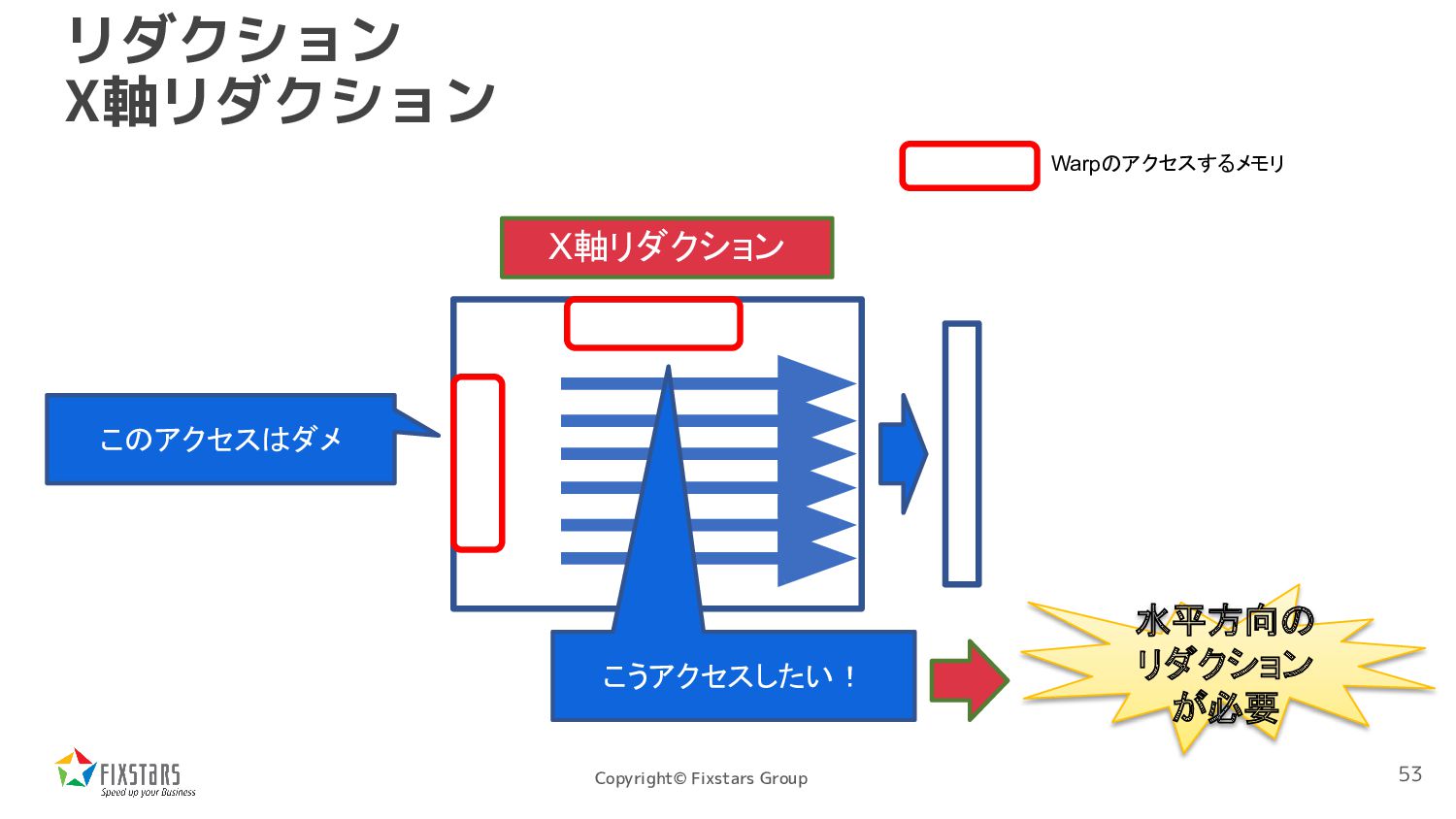
*src, float *dst, int width, int height) { int y = blockIdx.x * blockDim.x + threadIdx.x; int x = blockIdx.y * 128; if (y < height) { float sum = 0; for (int xend = min(x + 128, width); x < xend; ++x) { sum += src[x + y * width]; } atomicAdd(&dst[y], sum); } } このアクセスが全く コアレスアクセスでない 52
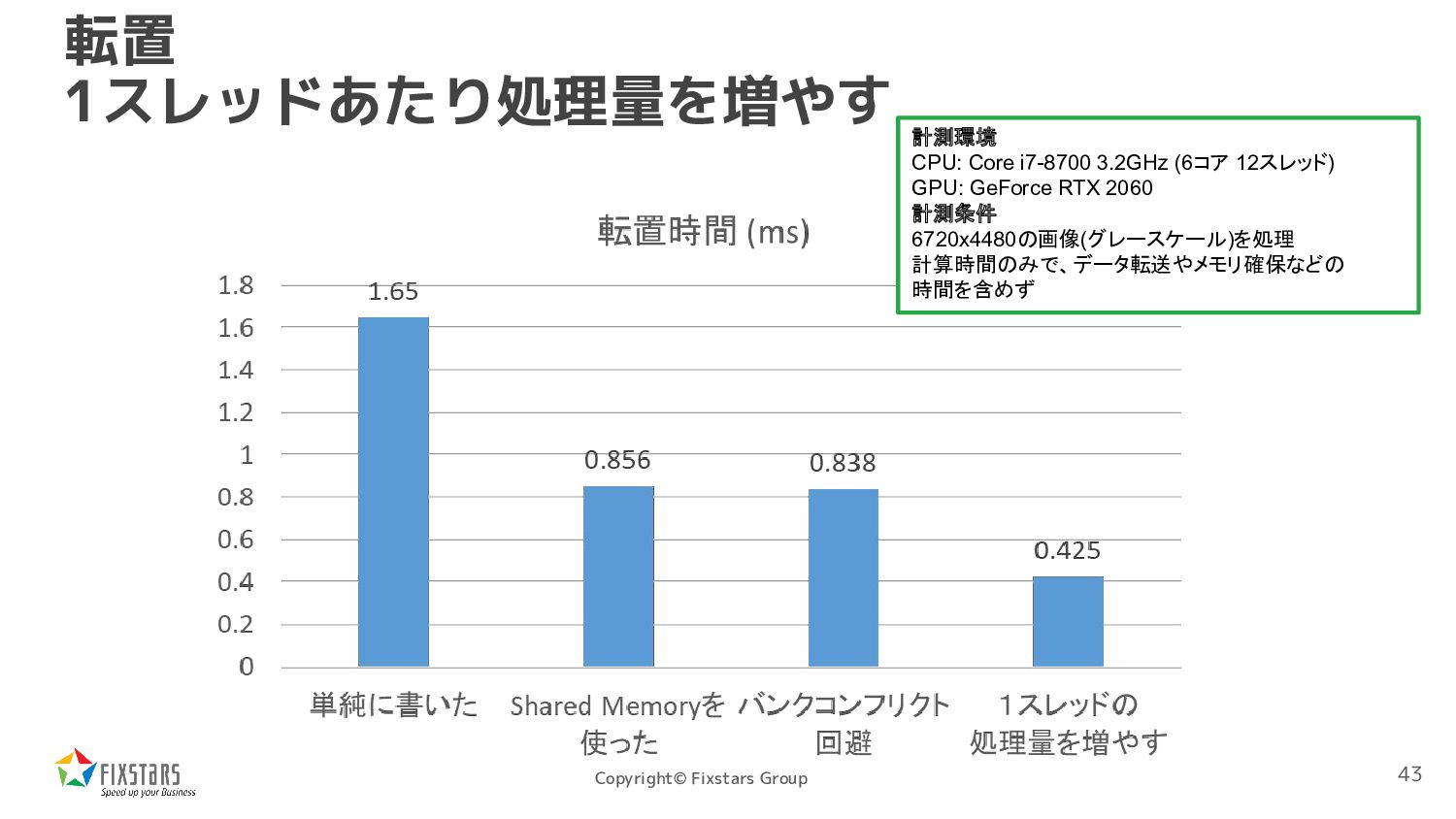
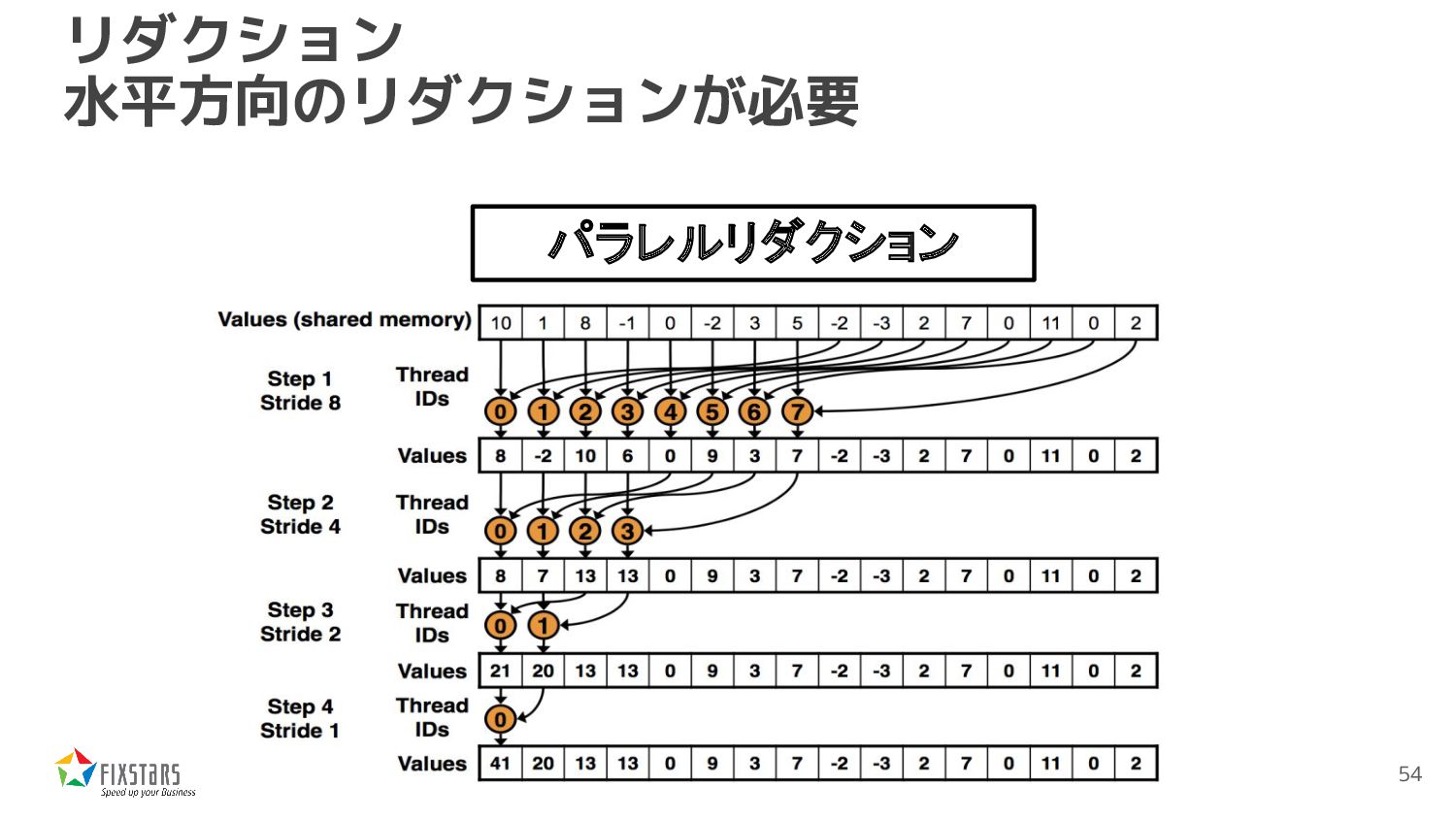
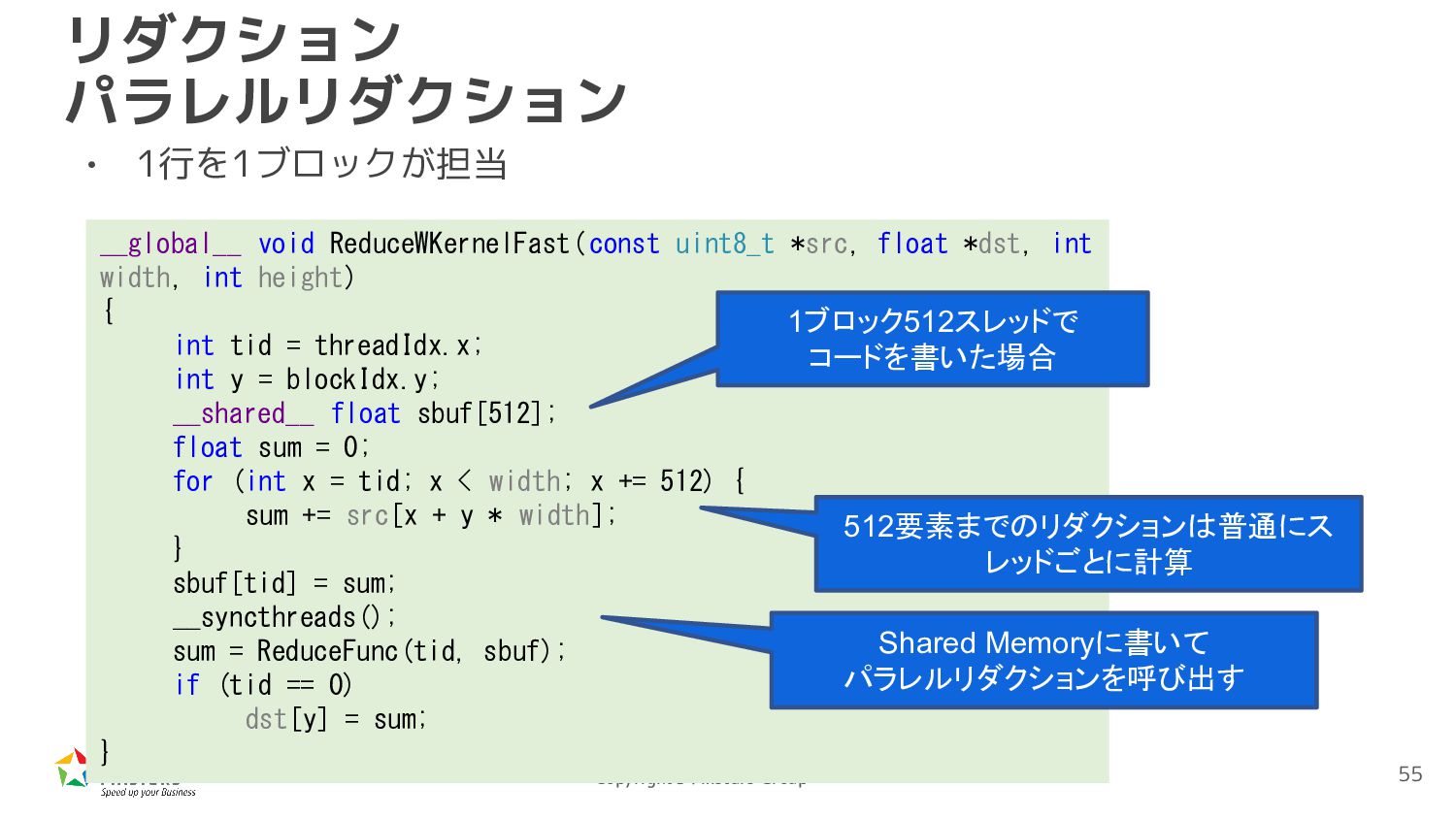
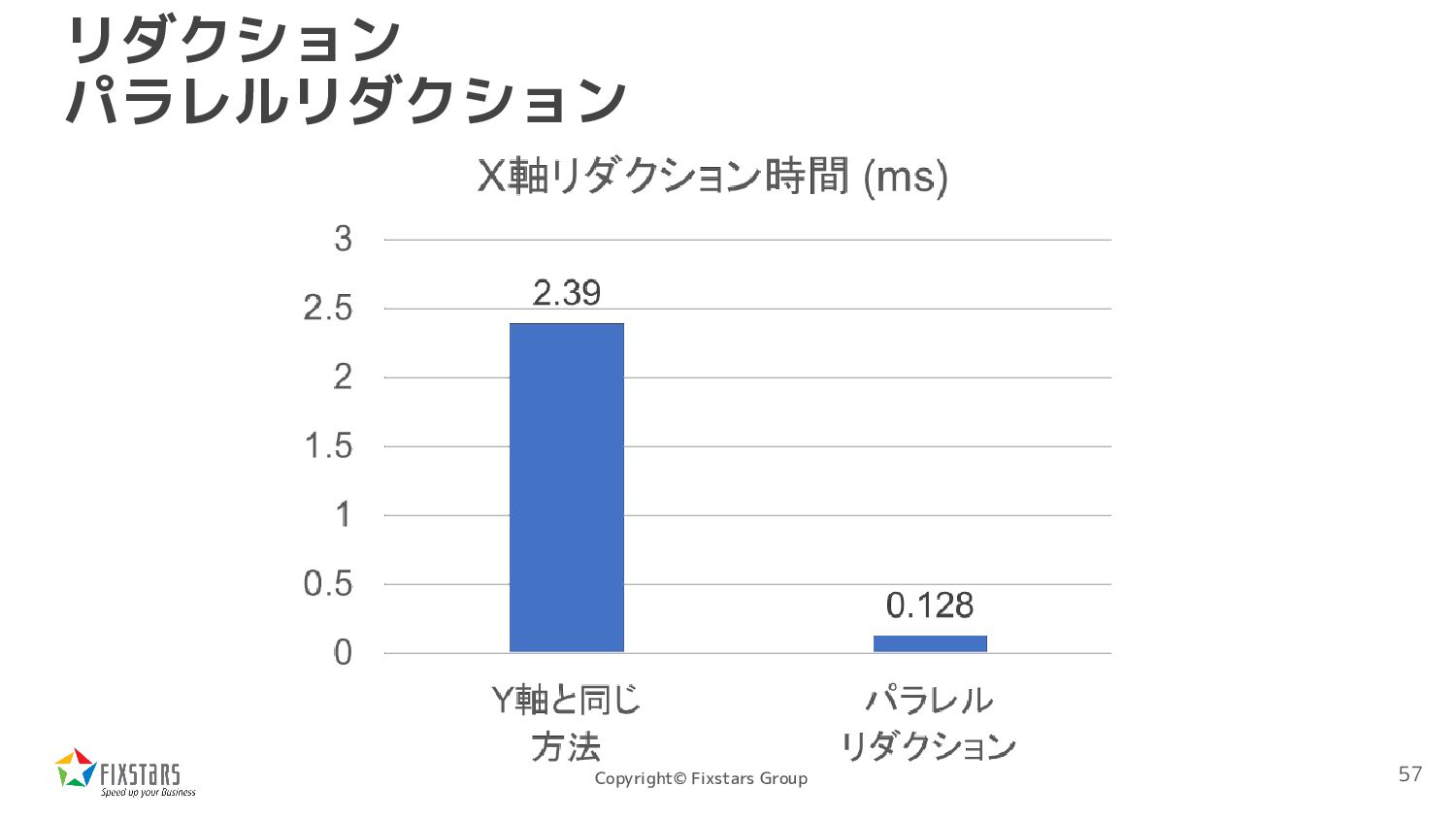
const uint8_t *src, float *dst, int width, int height) { int tid = threadIdx.x; int y = blockIdx.y; __shared__ float sbuf[512]; float sum = 0; for (int x = tid; x < width; x += 512) { sum += src[x + y * width]; } sbuf[tid] = sum; __syncthreads(); sum = ReduceFunc(tid, sbuf); if (tid == 0) dst[y] = sum; } 512要素までのリダクションは普通にス レッドごとに計算 1ブロック512スレッドで コードを書いた場合 Shared Memoryに書いて パラレルリダクションを呼び出す 55
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Copyright © Fixstars Group Thank you! お問い合わせ窓口 : [email protected]](https://files.speakerdeck.com/presentations/11bd01b8dbf046bcb69c1dd68c8525f6/slide_58.jpg){kind=link}