Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Jetson活用セミナー ROS2自律走行実現に向けて
Search
株式会社フィックスターズ
April 01, 2022
Programming
530
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Jetson活用セミナー ROS2自律走行実現に向けて
2021年11月4日開催「Jetson活用セミナー ROS2自律走行実現に向けて ~自律移動ロボット用-自己位置推定のCUDA高速化~」セミナー資料です
株式会社フィックスターズ
April 01, 2022
More Decks by 株式会社フィックスターズ
See All by 株式会社フィックスターズ
コンピュータービジョンセミナー5 / 3次元復元アルゴリズム Multi-View Stereo の CUDA高速化
fixstars
0
1.2k
Kaggle_スコアアップセミナー_DFL-Bundesliga_Data_Shootout編/Kaggle_fixstars_corporation_20230509
fixstars
1
1.2k
実践的!FPGA開発セミナーvol.21 / FPGA_seminar_21_fixstars_corporation_20230426
fixstars
0
1.6k
量子コンピュータ時代のプログラミングセミナー / 20230413_Amplify_seminar_shift_optimization
fixstars
0
1.2k
実践的!FPGA開発セミナーvol.18 / FPGA_seminar_18_fixstars_corporation_20230125
fixstars
0
1k
実践的!FPGA開発セミナーvol.19 / FPGA_seminar_19_fixstars_corporation_20230222
fixstars
0
1.1k
実践的!FPGA開発セミナーvol.20 / FPGA_seminar_20_fixstars_corporation_20230329
fixstars
0
950
量子コンピュータ時代のプログラミングセミナー / 20230316_Amplify_seminar _route_planning_optimization
fixstars
0
920
量子コンピュータ時代のプログラミングセミナー / 20230216_Amplify_seminar _production_planning_optimization
fixstars
0
800
Other Decks in Programming
See All in Programming
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
510
Even G2とAWSで推しのエージェントを召喚しよう!
har1101
1
170
symfony/aiとlaravel/boost
77web
0
130
使用 Meilisearch 建立新聞搜尋工具
johnroyer
0
150
えっ!!コードを読まずに開発を!?
hananouchi
0
220
Go言語とトイモデルで学ぶTransformerの気持ち / fukuokago23-transformer
monochromegane
0
110
継続モナドとリアクティブプログラミング
yukikurage
3
610
鹿野さんに聞く!『TypeScriptコードレシピ集』で磨く実践力
tonkotsuboy_com
4
1.1k
ソフトウェア設計に溶けるインフラ ― AWS CDK のインフラ認識論
konokenj
2
550
AI駆動開発を妨げる技術的負債の解消アプローチ / ai-refactoring-approach
minodriven
17
9.1k
ビデオ通話が繋がる0.2秒で何が起きているのか
supurazako
2
150
アルゴリズムは何を圧縮しているのか ─ Haskell から育った「圧縮代数」というメンタルモデル
naoya
16
3.5k
Featured
See All Featured
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
230
Fireside Chat
paigeccino
42
4k
A Modern Web Designer's Workflow
chriscoyier
698
190k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
The browser strikes back
jonoalderson
0
1.4k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
180
Done Done
chrislema
186
16k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Transcript
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation Copyright © Fixstars
Corporation Jetson活用セミナー ROS2自律走行実現に向けて 自律移動ロボット用-自己位置推定のCUDA高速化
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 本日のアジェンダ • フィックスターズ会社紹介
• 会社概要と各種サービス • テクニカルセッション • ros1_brigeを用いた搬送ロボットメカナムローバーのROS2対応 • 自己位置推定アルゴリズムamclの高速化(プロファイリング、CUDA化) • Q&A 2
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 発表者紹介 • 山田真介
(Shinsuke Yamada) • ディレクター • 博士 (工学) • 主に自動運転関係のプロジェクトマネジメントを担当 • 深層学習における量子化 • 車両運動制御プログラムの高速化 • 坂本浩平 (Kohei Sakamoto) • シニアエンジニア • プロトタイプ自律ロボットのアルゴリズム開発や CUDA 高速化、自動運転システム の構築を担当 • 高速化に興味 • アルゴリズム/SIMD/CUDA/高速コード実装 3
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation Copyright © Fixstars
Corporation フィックスターズのご紹介
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 5 フィックスターズは、コンピュータの性能を最大限に引き出し大量データの高速処理を実現する、 高速化のエキスパート集団です。
低レイヤ ソフトウェア技術 アルゴリズム 実装力 各産業・研究 分野の知見 フィックスターズの強み
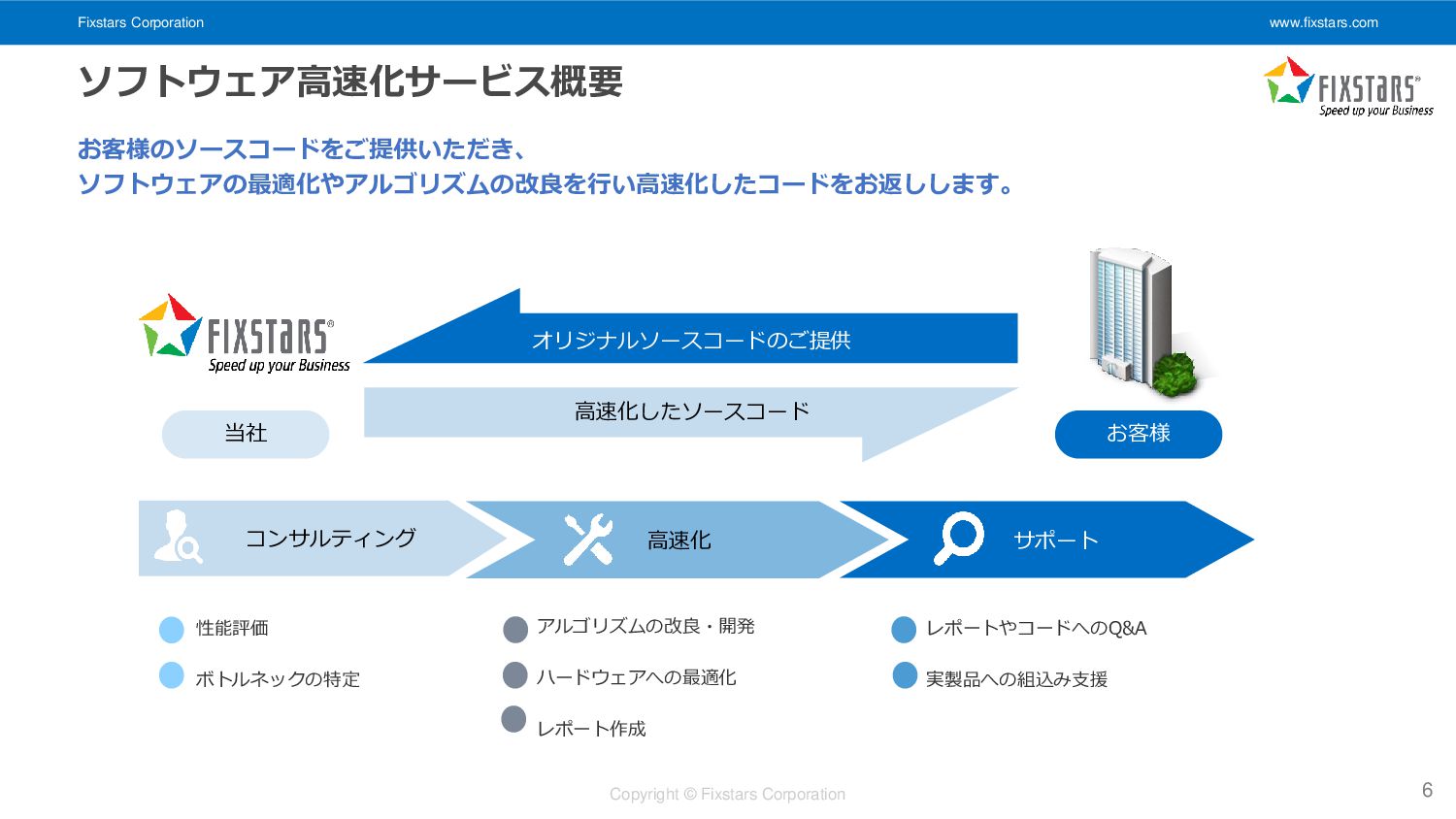
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ソフトウェア高速化サービス概要 6 お客様のソースコードをご提供いただき、
ソフトウェアの最適化やアルゴリズムの改良を行い高速化したコードをお返しします。 当社 お客様 オリジナルソースコードのご提供 高速化したソースコード コンサルティング 高速化 サポート 性能評価 ボトルネックの特定 アルゴリズムの改良・開発 ハードウェアへの最適化 レポート作成 レポートやコードへのQ&A 実製品への組込み支援
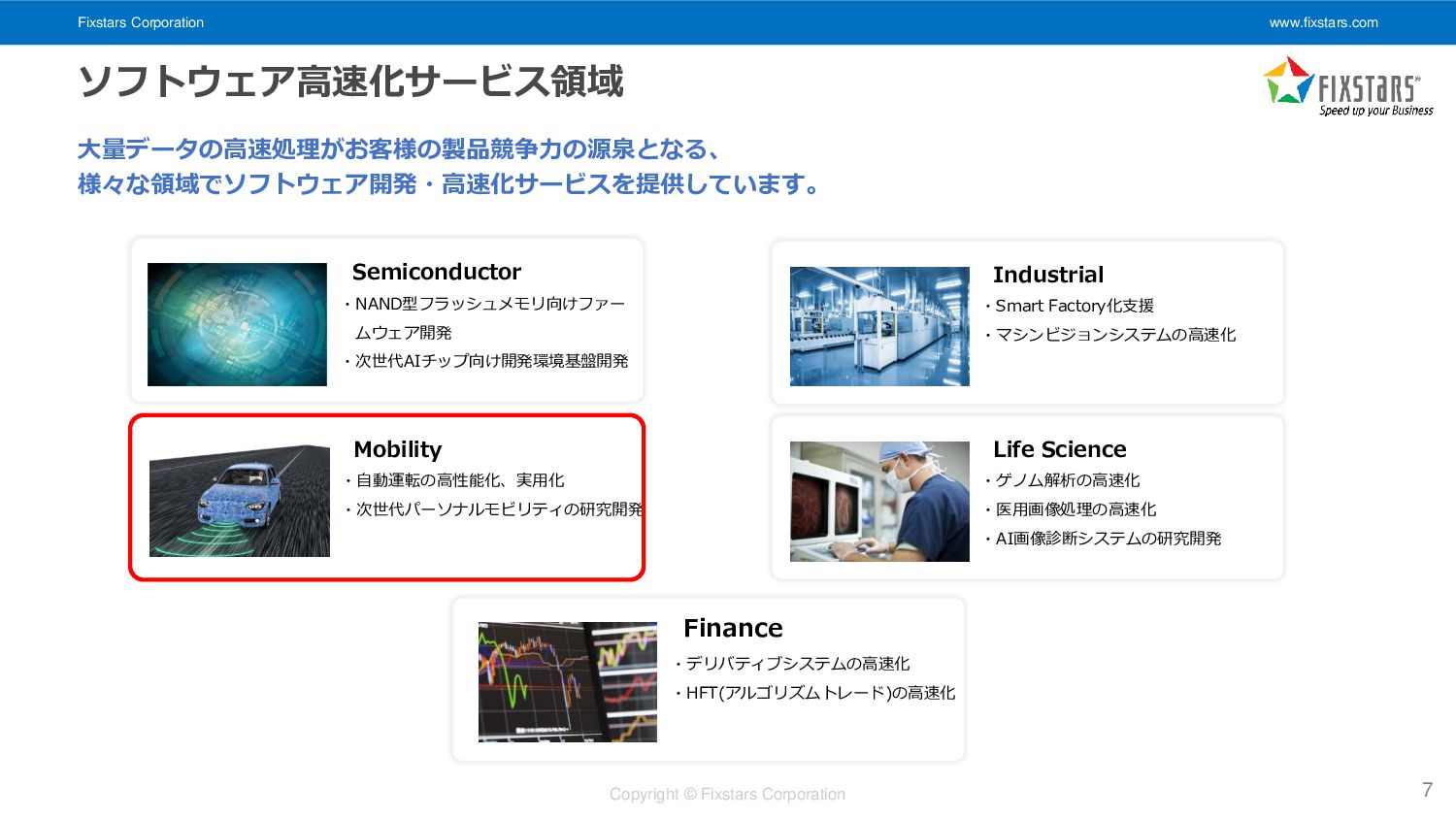
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 7 ソフトウェア高速化サービス領域 大量データの高速処理がお客様の製品競争力の源泉となる、
様々な領域でソフトウェア開発・高速化サービスを提供しています。 ・NAND型フラッシュメモリ向けファー ムウェア開発 ・次世代AIチップ向け開発環境基盤開発 Semiconductor ・デリバティブシステムの高速化 ・HFT(アルゴリズムトレード)の高速化 Finance ・自動運転の高性能化、実用化 ・次世代パーソナルモビリティの研究開発 Mobility ・ゲノム解析の高速化 ・医用画像処理の高速化 ・AI画像診断システムの研究開発 Life Science ・Smart Factory化支援 ・マシンビジョンシステムの高速化 Industrial
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation Fixstars Autonomous Technologies
8 高速化技術のフィックスターズと豊田通商グループのネクスティ エレクトロニクスによる合弁会社 並列化・最適化・機械学習・コンピュータビジョン技術を駆使し、自動運転社会の実現を加速する 会社名: Fixstars Autonomous Technologies 設立:2018年2月1日 資本金:3,000万円 (株)フィックスターズ 66.6% (株)ネクスティ エレクトロニクス 33.4% 所在地:東京都港区芝浦3-1-1 代表取締役会長 : 蜂須賀 利幸 代表取締役社長:羽田 哲
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 画像処理・アルゴリズム開発サービス 9 •
お客様の課題 • 高度な画像処理、深層学習等のアルゴリズム開発を行える人材が社内に限られている • 考案中のアルゴリズムで機能要件は満たせそうだが、ターゲット機器上で性能要件まで クリアできるか不安 • 研究開発の成果が製品化にうまく結びつかない • 弊社の支援内容 • 課題に応じたアルゴリズム調査 • 深層学習ネットワーク精度改善、推論高速化手法調査 • 論文調査、実装 https://www.cs.toronto.edu/~frossard/post/vgg16/
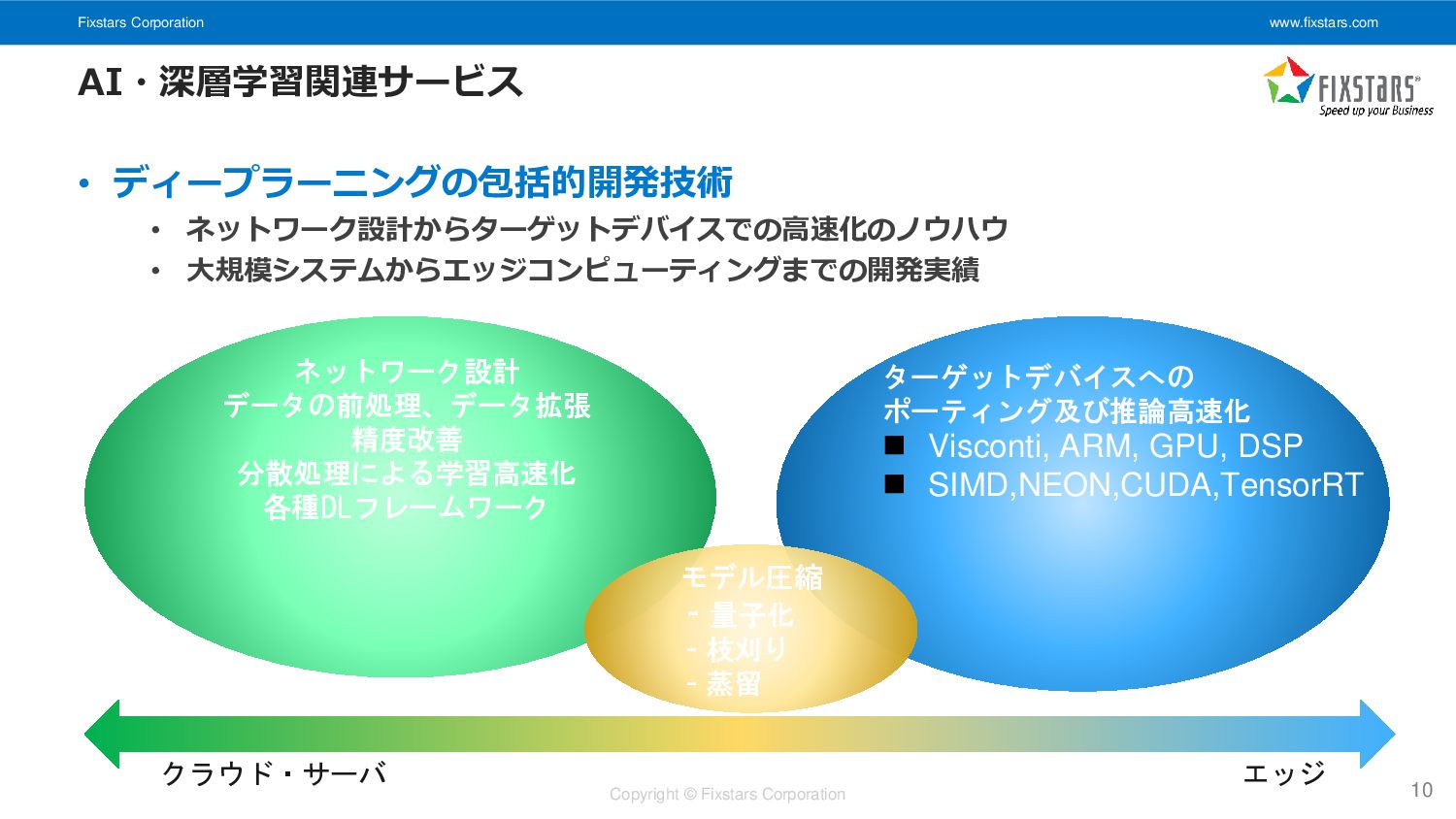
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation AI・深層学習関連サービス 10 •
ディープラーニングの包括的開発技術 • ネットワーク設計からターゲットデバイスでの高速化のノウハウ • 大規模システムからエッジコンピューティングまでの開発実績 ネットワーク設計 データの前処理、データ拡張 精度改善 分散処理による学習高速化 各種DLフレームワーク クラウド・サーバ エッジ モデル圧縮 - 量子化 - 枝刈り - 蒸留 ターゲットデバイスへの ポーティング及び推論高速化 ◼ Visconti, ARM, GPU, DSP ◼ SIMD,NEON,CUDA,TensorRT
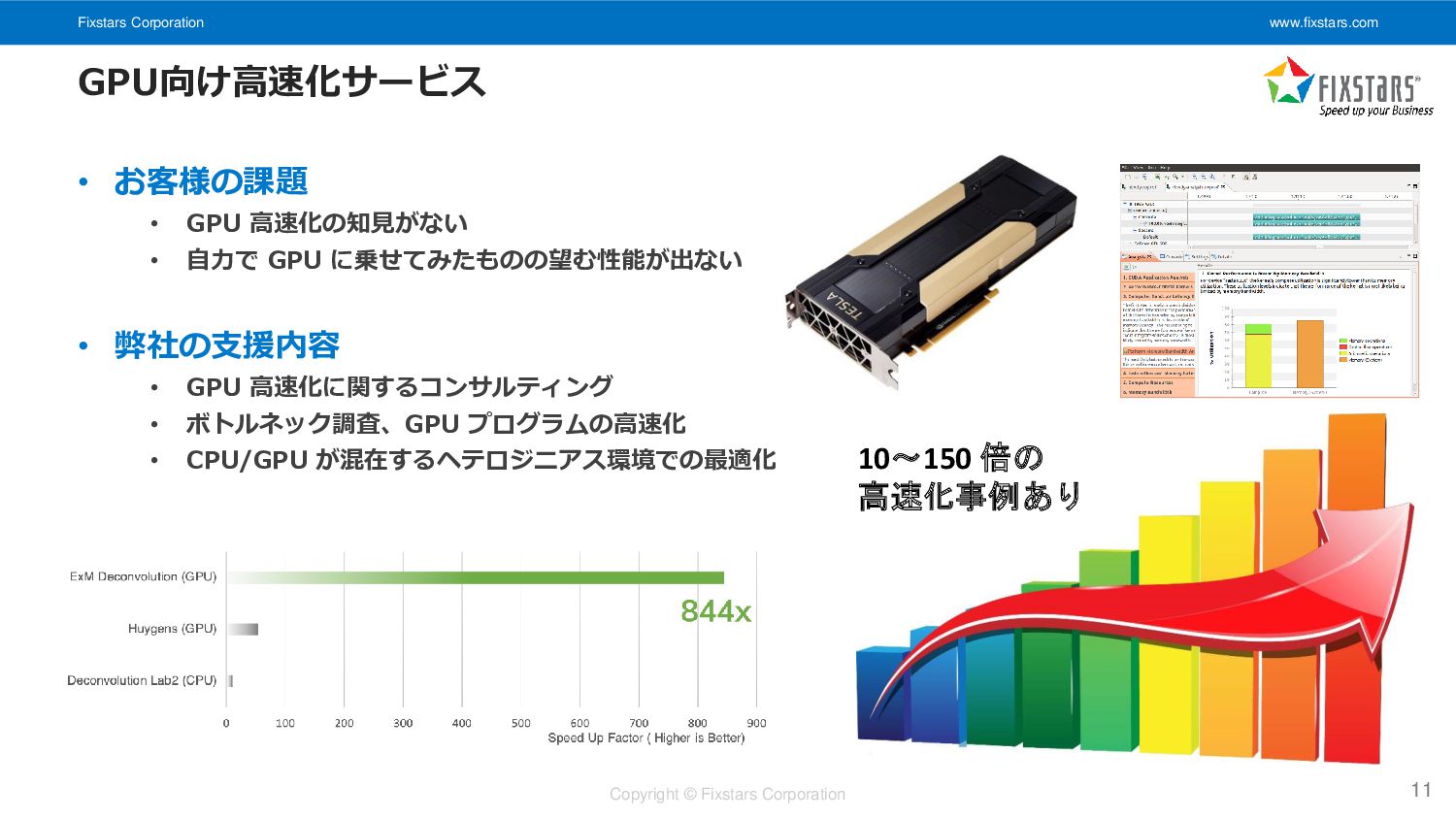
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation GPU向け高速化サービス 11 •
お客様の課題 • GPU 高速化の知見がない • 自力で GPU に乗せてみたものの望む性能が出ない • 弊社の支援内容 • GPU 高速化に関するコンサルティング • ボトルネック調査、GPU プログラムの高速化 • CPU/GPU が混在するヘテロジニアス環境での最適化 10~150 倍の 高速化事例あり
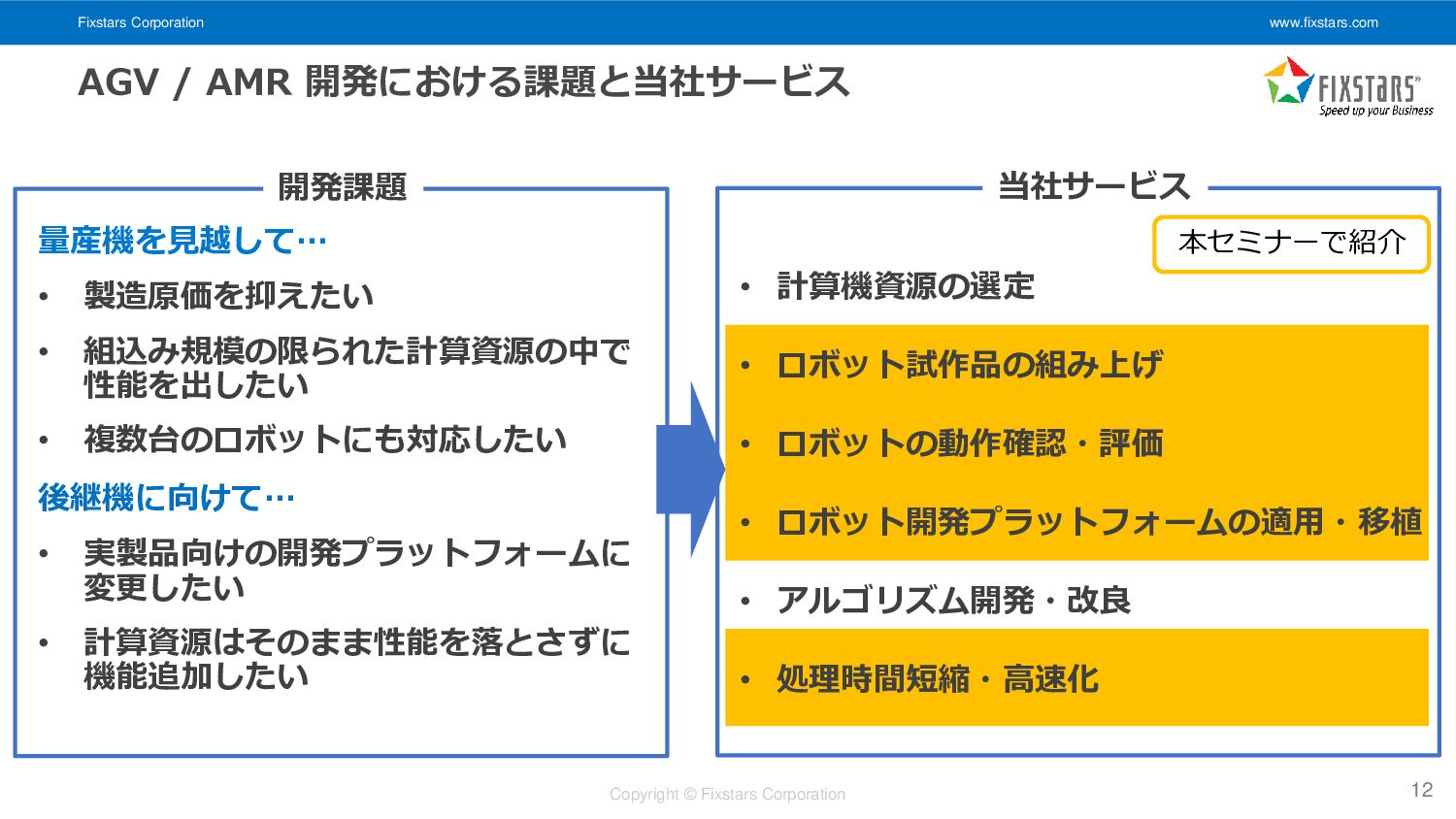
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation AGV / AMR
開発における課題と当社サービス 12 量産機を見越して… • 製造原価を抑えたい • 組込み規模の限られた計算資源の中で 性能を出したい • 複数台のロボットにも対応したい 後継機に向けて… • 実製品向けの開発プラットフォームに 変更したい • 計算資源はそのまま性能を落とさずに 機能追加したい • 計算機資源の選定 • ロボット試作品の組み上げ • ロボットの動作確認・評価 • ロボット開発プラットフォームの適用・移植 • アルゴリズム開発・改良 • 処理時間短縮・高速化 開発課題 当社サービス 本セミナーで紹介
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation Copyright © Fixstars
Corporation テクニカルセッション
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation Copyright © Fixstars
Corporation 1. はじめに
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 1. はじめに 「ROS2上でナビゲーション処理を行う車両型ロボット開発環境を整備し、ROS2のナ
ビゲーション処理を高速化したい」という動機から、今回、以下のような取り組みを行 った。 • メカナムローバーのROS2対応 • ros1_bridgeによってROS1資産を活用しながらのROS2対応 • 自己位置推定パッケージamclのCUDA高速化 • ROS2ノードのプロファイリング(perf、NVIDIA Nsight Systems) • amclのCUDA実装およびプロファイリング(nvprof、NVIDIA Visual Profiler) 15
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation Copyright © Fixstars
Corporation 2. メカナムローバーの ROS2対応
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2. メカナムローバーのROS2対応 アウトライン
• 2.1 メカナムローバーとは • 2.2 メカナムローバーのROS対応状況 • 2.3 メカナムローバーのROS2対応 17
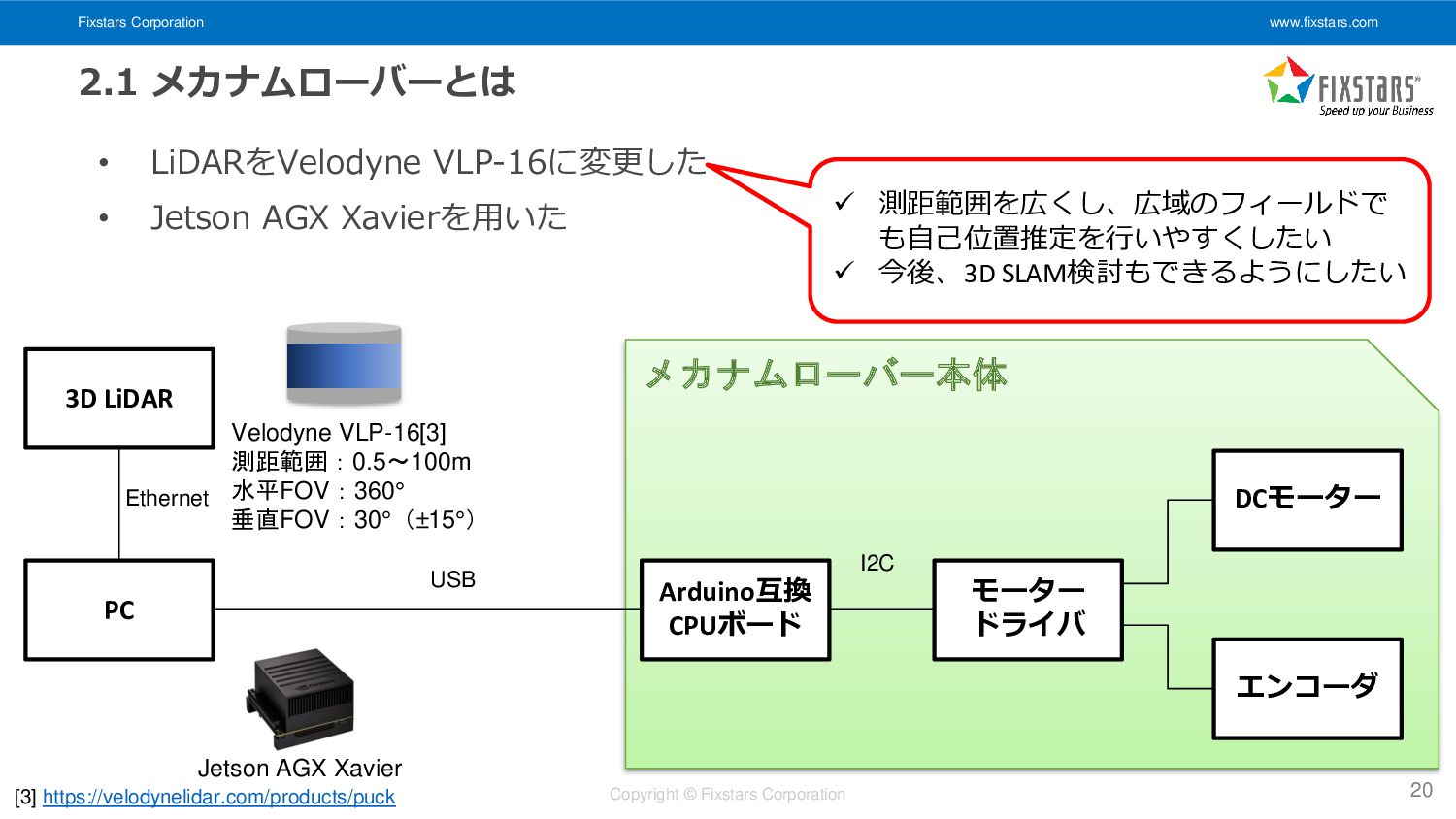
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.1 メカナムローバーとは •
ヴイストン株式会社が販売する4輪のメカナムホイールを搭載した全方位移動台車ロ ボット[1] • 可搬重量約40kg、最高速度1.3m/s • 2021/11/1時点でROS1に対応 • 今回の一連の取り組みではメカナムローバーVer2.0を用いた 18 [1] https://www.vstone.co.jp/products/wheelrobot/ver2.0.html
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.1 メカナムローバーとは •
ハード構成は以下の通り(購入時オプションよって構成が異なる)。 19 PC Arduino互換 CPUボード モーター ドライバ 2D LiDAR DCモーター エンコーダ [2] https://www.hokuyo-aut.co.jp/search/single.php?serial=17 USB USB I2C URG-04LX-UG01[2] 測距範囲:0.02~5.6m 走査角度:240° メカナムローバー本体
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.1 メカナムローバーとは •
LiDARをVelodyne VLP-16に変更した • Jetson AGX Xavierを用いた 20 PC Arduino互換 CPUボード モーター ドライバ 3D LiDAR DCモーター エンコーダ [3] https://velodynelidar.com/products/puck Ethernet USB I2C メカナムローバー本体 Velodyne VLP-16[3] 測距範囲:0.5~100m 水平FOV:360° 垂直FOV:30°(±15°) ✓ 測距範囲を広くし、広域のフィールドで も自己位置推定を行いやすくしたい ✓ 今後、3D SLAM検討もできるようにしたい Jetson AGX Xavier
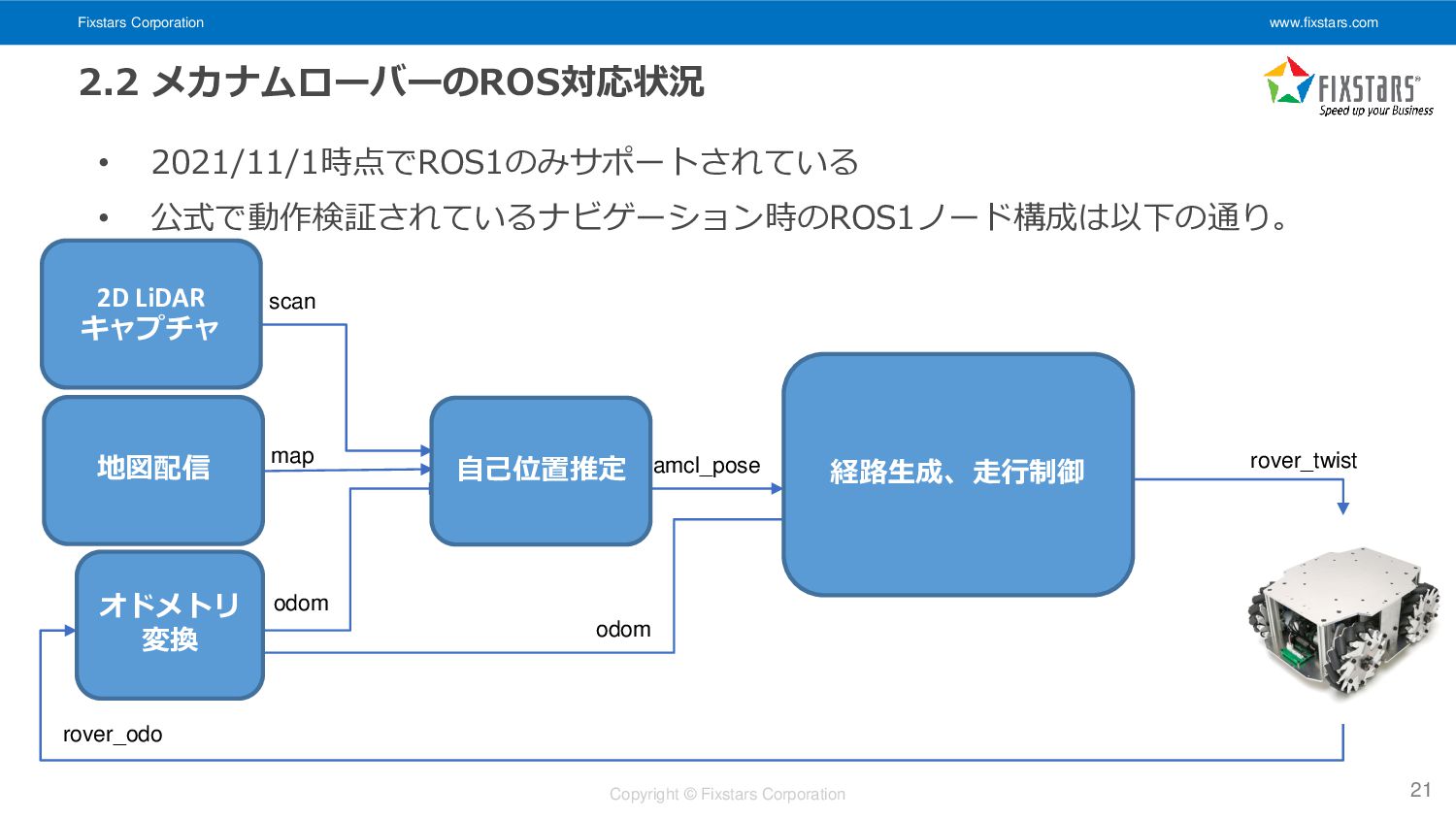
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.2 メカナムローバーのROS対応状況 •
2021/11/1時点でROS1のみサポートされている • 公式で動作検証されているナビゲーション時のROS1ノード構成は以下の通り。 21 amcl urg_node pub_odom move_base dwa_local_ planner map odom rover_odo rover_twist map_server scan odom amcl_pose 経路生成、走行制御 自己位置推定 地図配信 2D LiDAR キャプチャ オドメトリ 変換
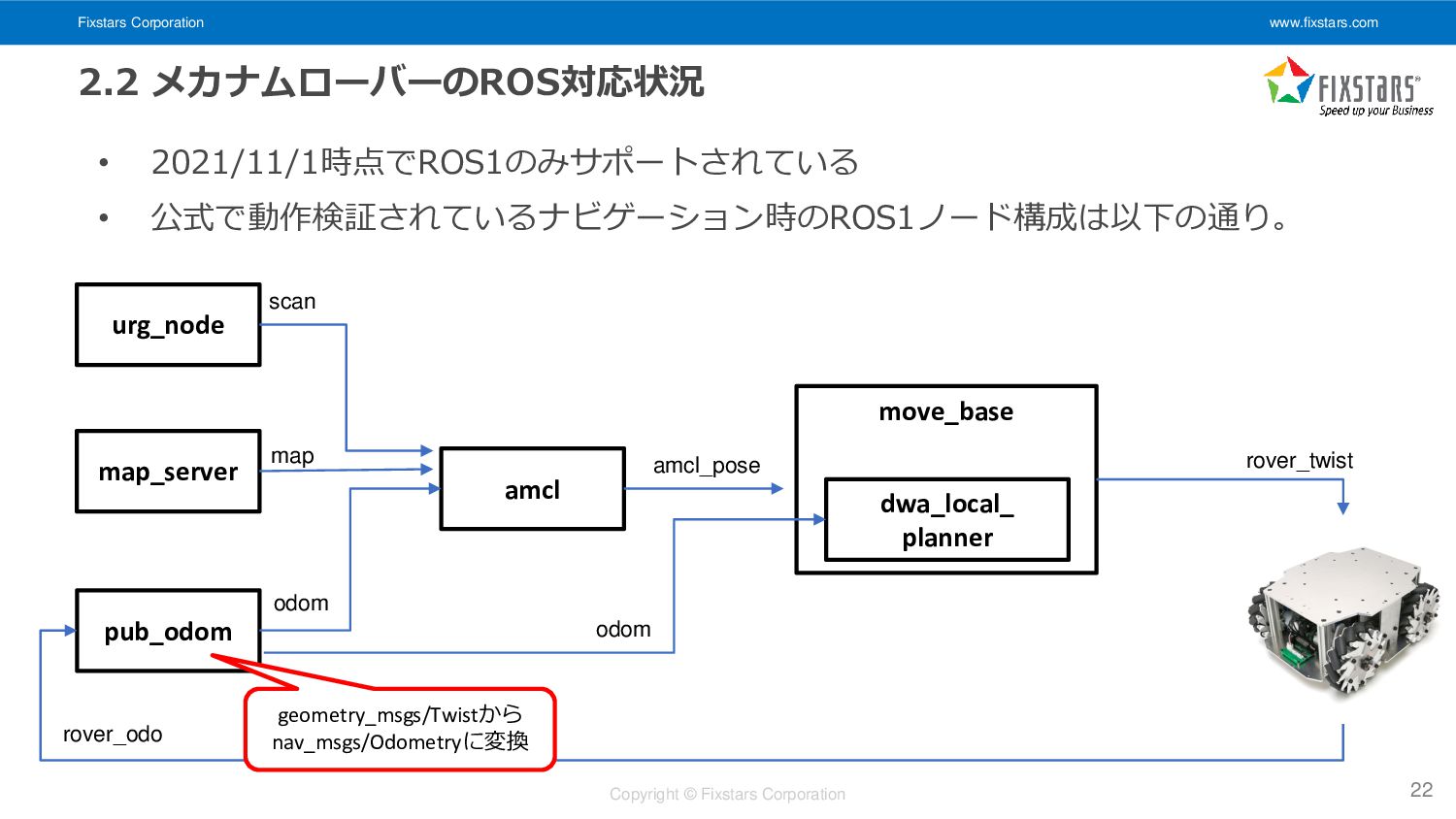
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.2 メカナムローバーのROS対応状況 •
2021/11/1時点でROS1のみサポートされている • 公式で動作検証されているナビゲーション時のROS1ノード構成は以下の通り。 22 amcl urg_node pub_odom move_base dwa_local_ planner map odom rover_odo rover_twist map_server scan odom amcl_pose geometry_msgs/Twistから nav_msgs/Odometryに変換
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.2 メカナムローバーのROS対応状況 •
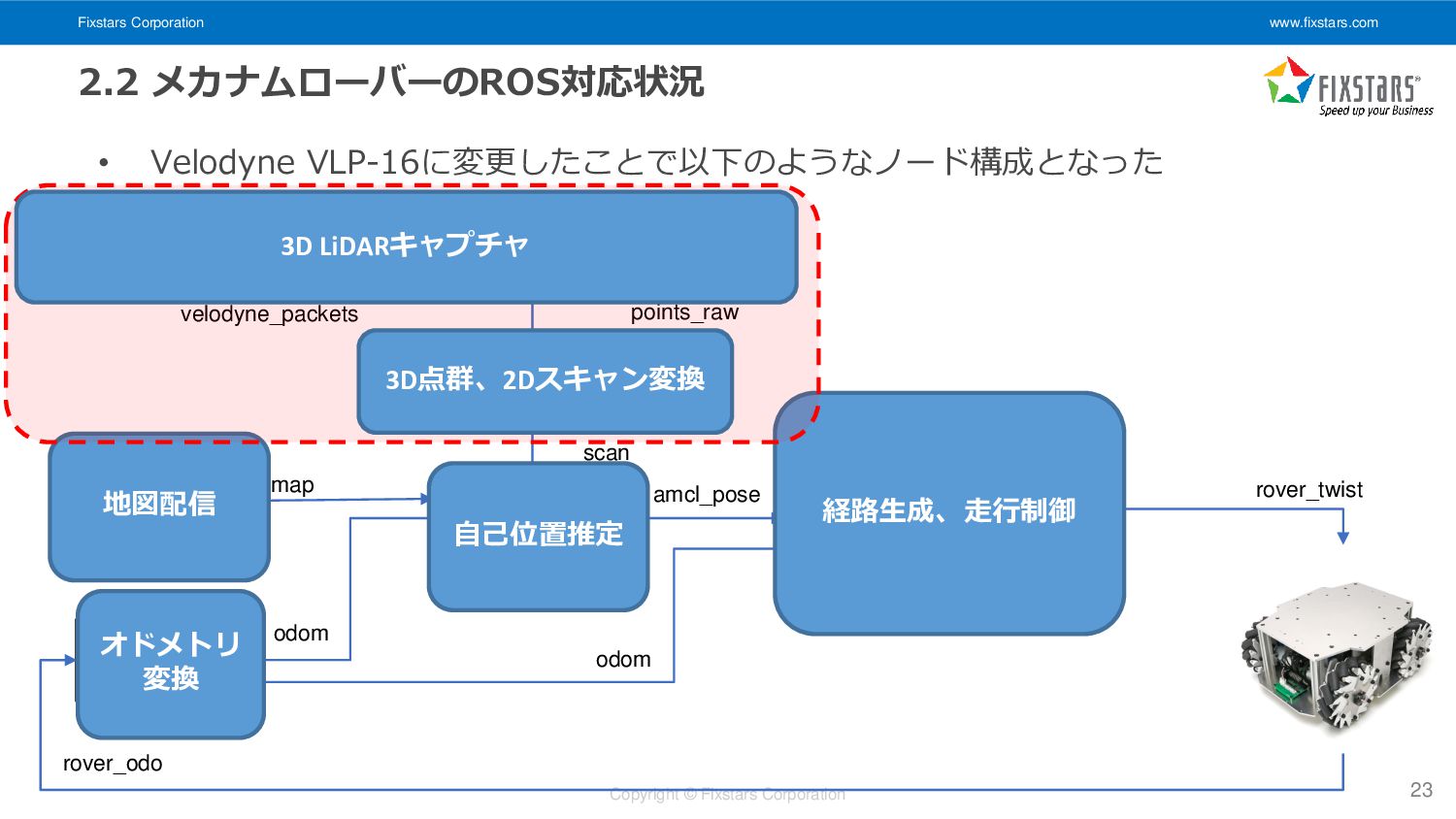
Velodyne VLP-16に変更したことで以下のようなノード構成となった 23 amcl velodyne_driver pub_odom move_base dwa_local_ planner map odom rover_odo rover_twist map_server odom amcl_pose velodyne_pointcloud pointcloud_to_ laserscan velodyne_packets scan points_raw 経路生成、走行制御 自己位置推定 地図配信 オドメトリ 変換 3D LiDARキャプチャ 3D点群、2Dスキャン変換
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.2 メカナムローバーのROS対応状況 •
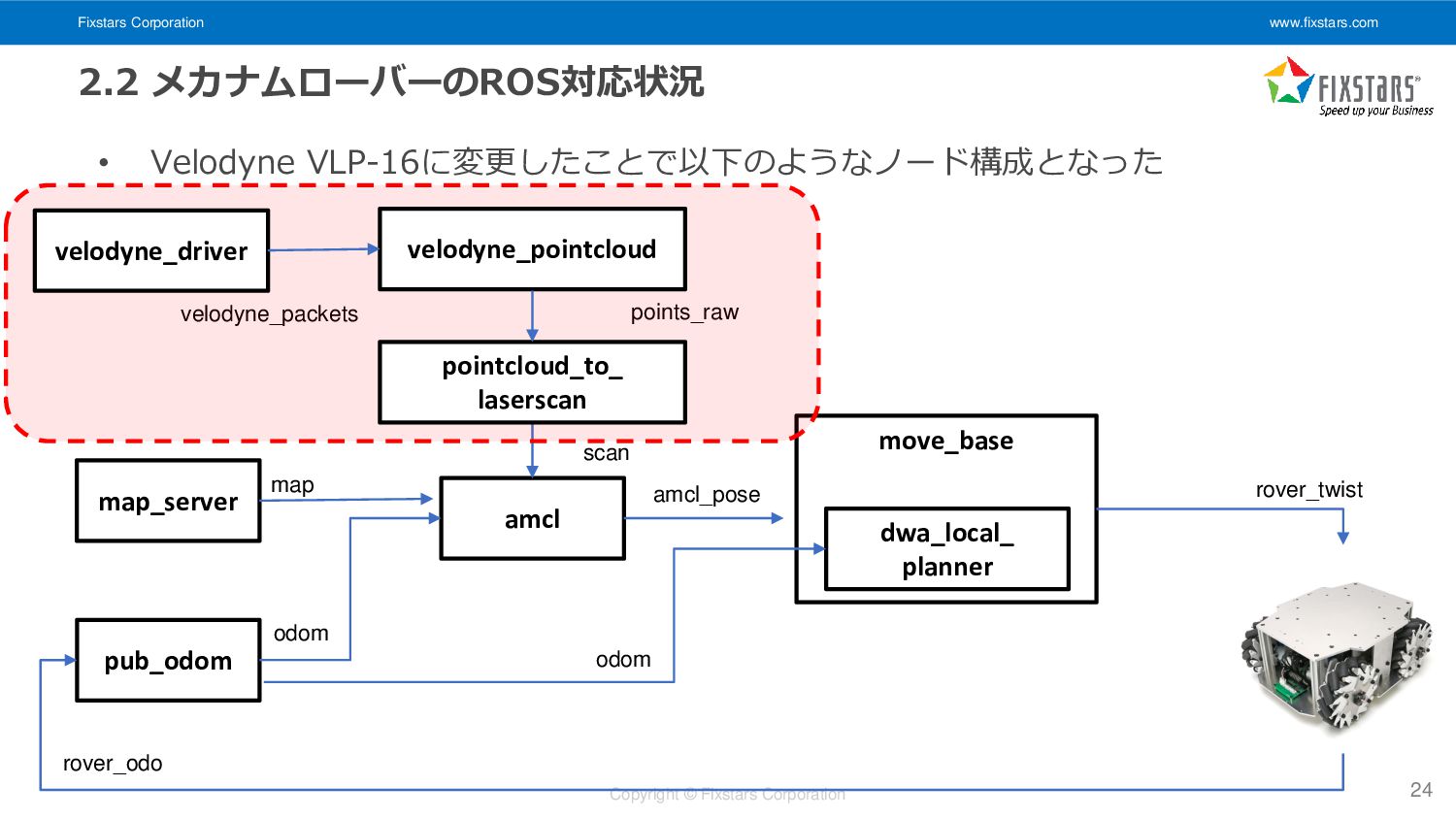
Velodyne VLP-16に変更したことで以下のようなノード構成となった 24 amcl pub_odom move_base dwa_local_ planner map odom rover_odo map_server odom amcl_pose velodyne_packets scan points_raw velodyne_driver velodyne_pointcloud pointcloud_to_ laserscan rover_twist
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.2 メカナムローバーのROS対応状況 •
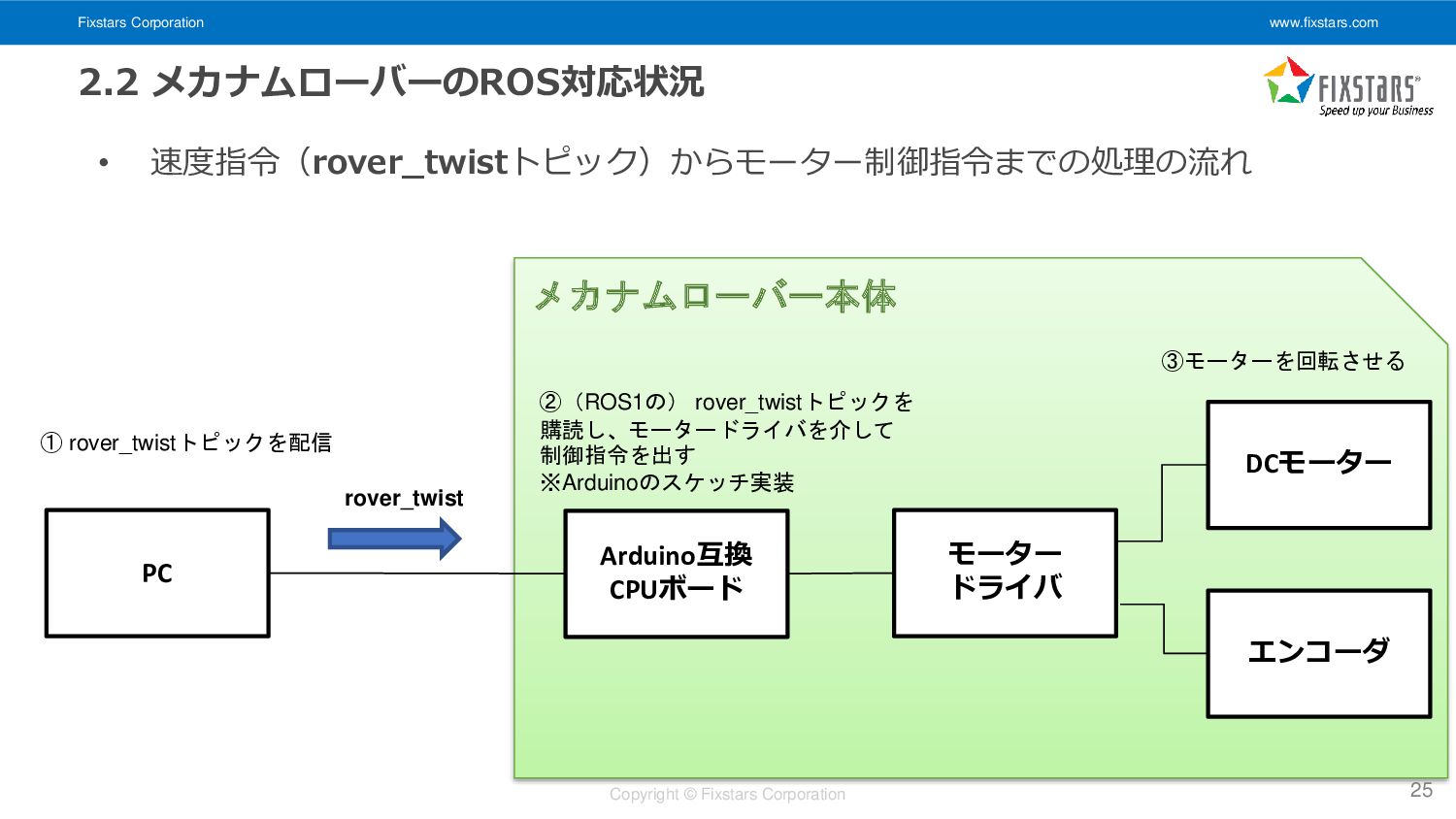
速度指令(rover_twistトピック)からモーター制御指令までの処理の流れ 25 PC Arduino互換 CPUボード モーター ドライバ DCモーター エンコーダ ① rover_twistトピックを配信 ②(ROS1の) rover_twistトピックを 購読し、モータードライバを介して 制御指令を出す ※Arduinoのスケッチ実装 rover_twist ③モーターを回転させる メカナムローバー本体
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.2 メカナムローバーのROS対応状況 •
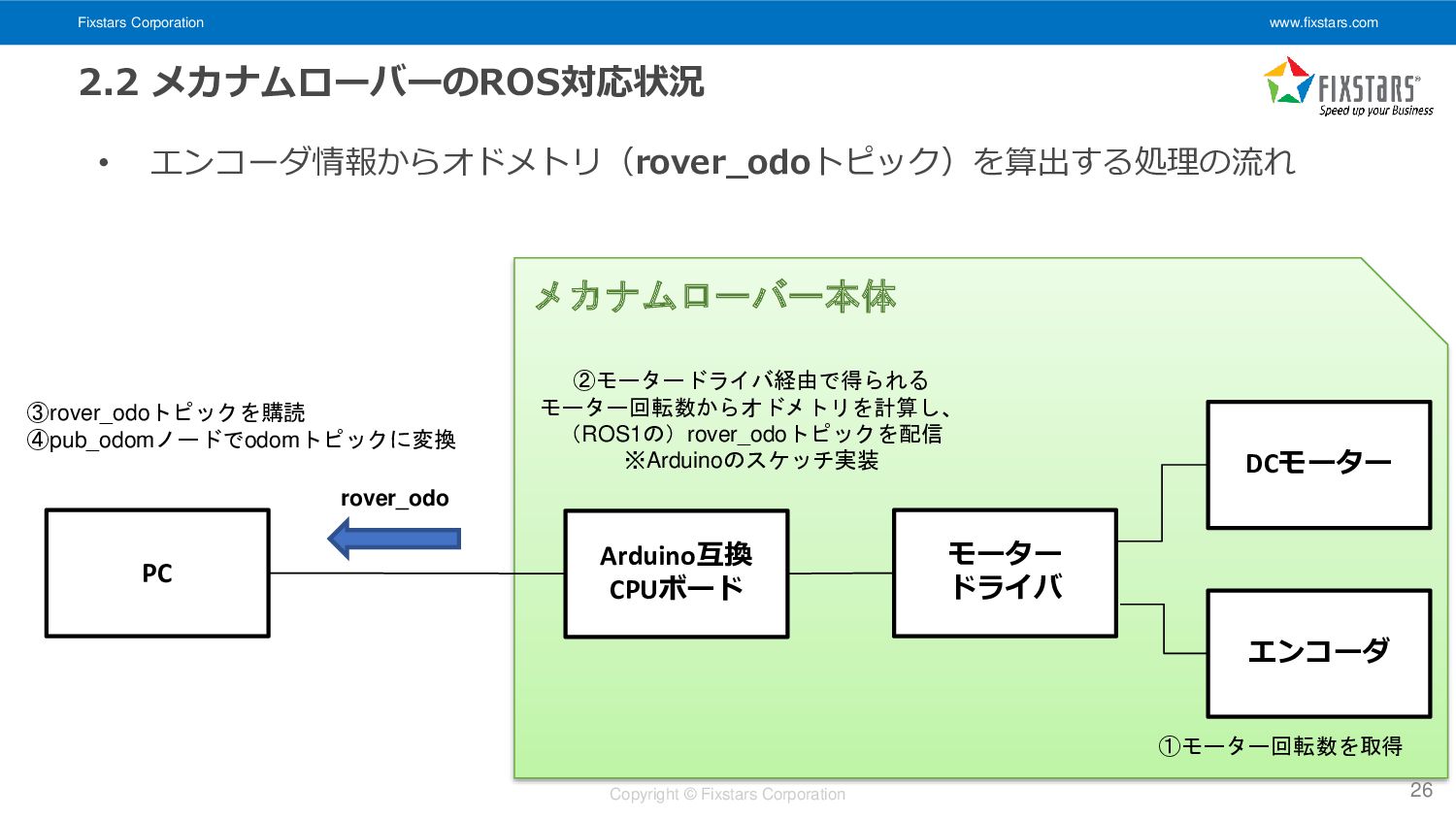
エンコーダ情報からオドメトリ(rover_odoトピック)を算出する処理の流れ 26 PC Arduino互換 CPUボード モーター ドライバ DCモーター エンコーダ ③rover_odoトピックを購読 ④pub_odomノードでodomトピックに変換 ②モータードライバ経由で得られる モーター回転数からオドメトリを計算し、 (ROS1の)rover_odoトピックを配信 ※Arduinoのスケッチ実装 rover_odo ①モーター回転数を取得 メカナムローバー本体
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.3 メカナムローバーのROS2対応 •
今回、以下のような方針でROS2対応を行った • メカナムローバーのROS2対応のファーストステップとして「amclを用いた自己位 置推定まで」を行う(=ナビゲーションまではやらない) • ros1_bridge[4]を用いることで既存のROS1資産を使いつつ、センサ関連や自己位 置推定処理をROS2化する • 自己位置推定に関連する主な処理をROS2 Galactic上で動作させる • Galacticより前のROS2ディストリビューションでは使いたい機能が使えないことが 多かったため 27 [4] https://github.com/ros2/ros1_bridge
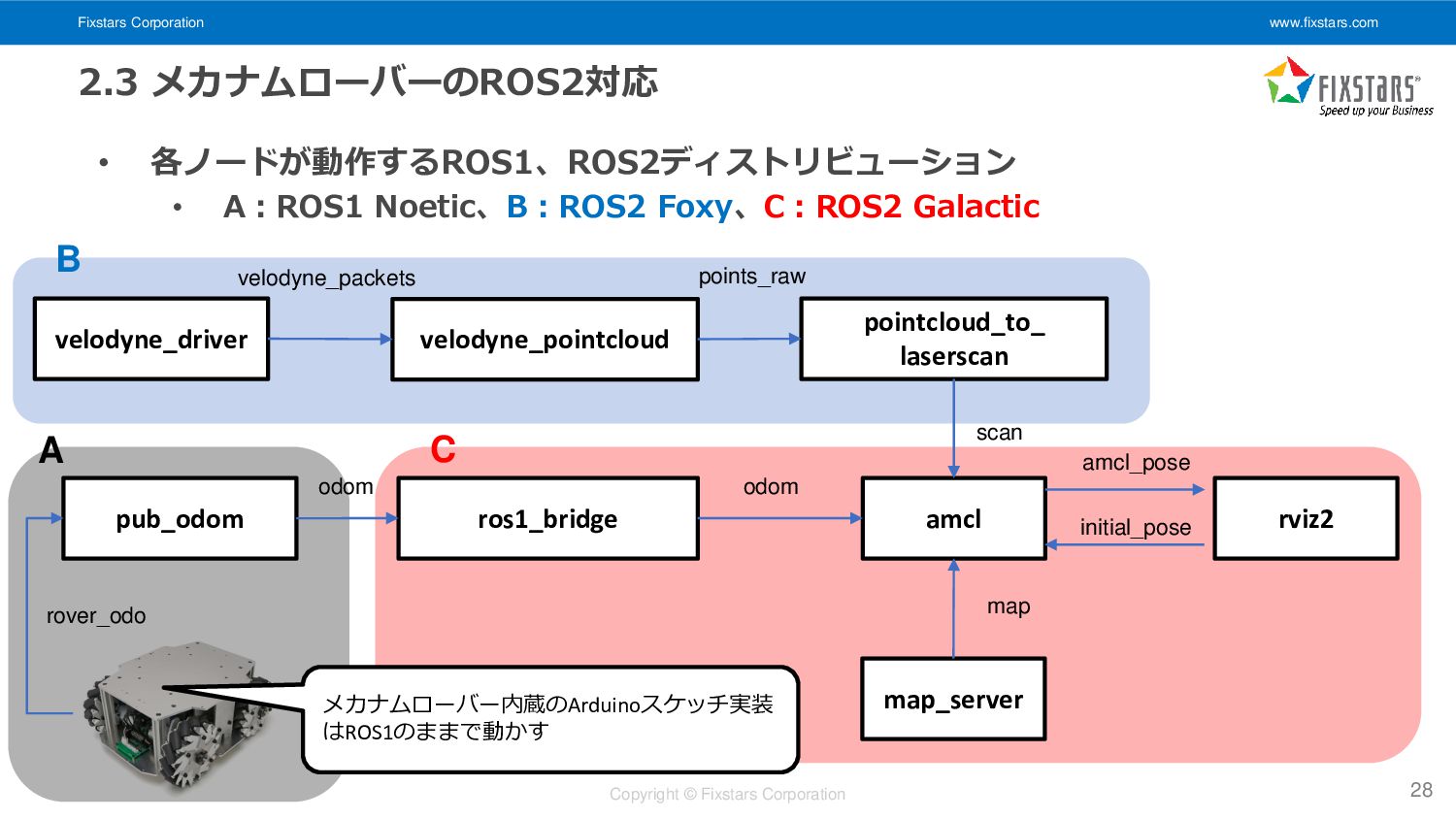
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.3 メカナムローバーのROS2対応 •
各ノードが動作するROS1、ROS2ディストリビューション • A:ROS1 Noetic、B:ROS2 Foxy、C:ROS2 Galactic 28 amcl velodyne_driver pub_odom map odom rover_odo map_server odom amcl_pose velodyne_pointcloud pointcloud_to_ laserscan scan ros1_bridge initial_pose rviz2 velodyne_packets points_raw メカナムローバー内蔵のArduinoスケッチ実装 はROS1のままで動かす A C B
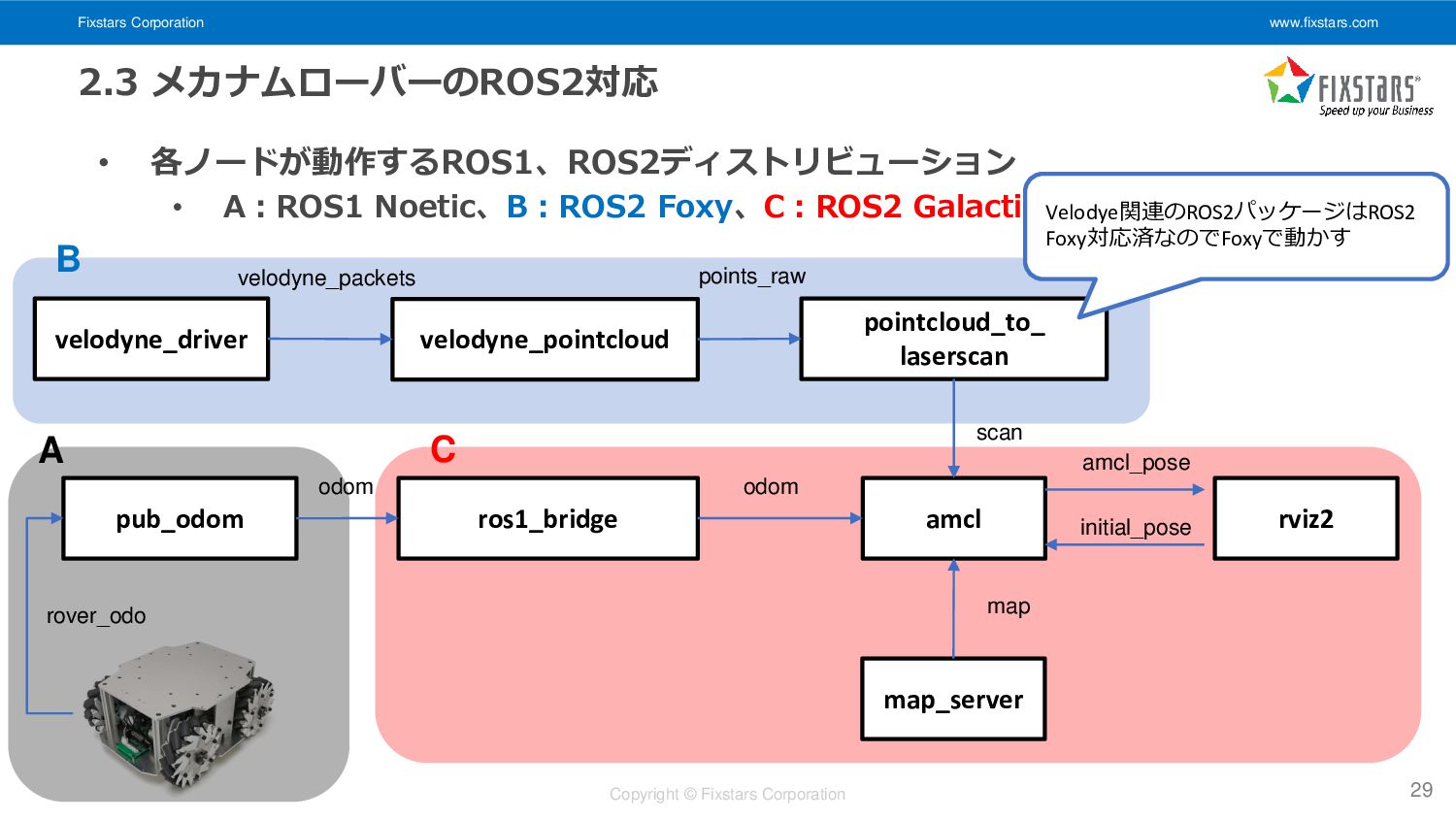
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.3 メカナムローバーのROS2対応 •
各ノードが動作するROS1、ROS2ディストリビューション • A:ROS1 Noetic、B:ROS2 Foxy、C:ROS2 Galactic 29 amcl velodyne_driver pub_odom map odom rover_odo map_server odom amcl_pose velodyne_pointcloud pointcloud_to_ laserscan scan ros1_bridge initial_pose rviz2 velodyne_packets points_raw Velodye関連のROS2パッケージはROS2 Foxy対応済なのでFoxyで動かす A C B
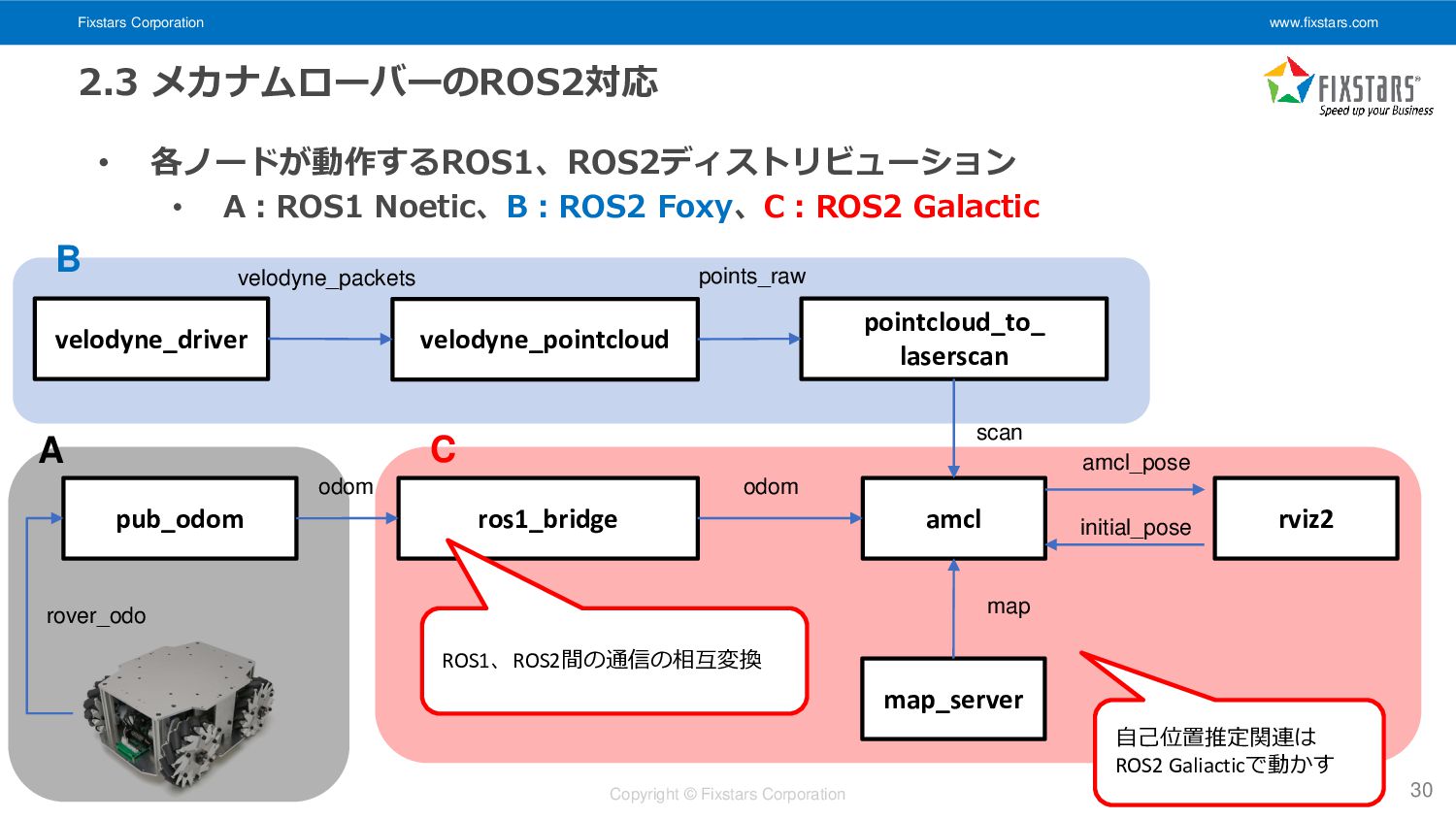
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.3 メカナムローバーのROS2対応 •
各ノードが動作するROS1、ROS2ディストリビューション • A:ROS1 Noetic、B:ROS2 Foxy、C:ROS2 Galactic 30 amcl velodyne_driver pub_odom map odom rover_odo map_server odom amcl_pose velodyne_pointcloud pointcloud_to_ laserscan scan ros1_bridge initial_pose rviz2 velodyne_packets points_raw ROS1、ROS2間の通信の相互変換 自己位置推定関連は ROS2 Galiacticで動かす A C B
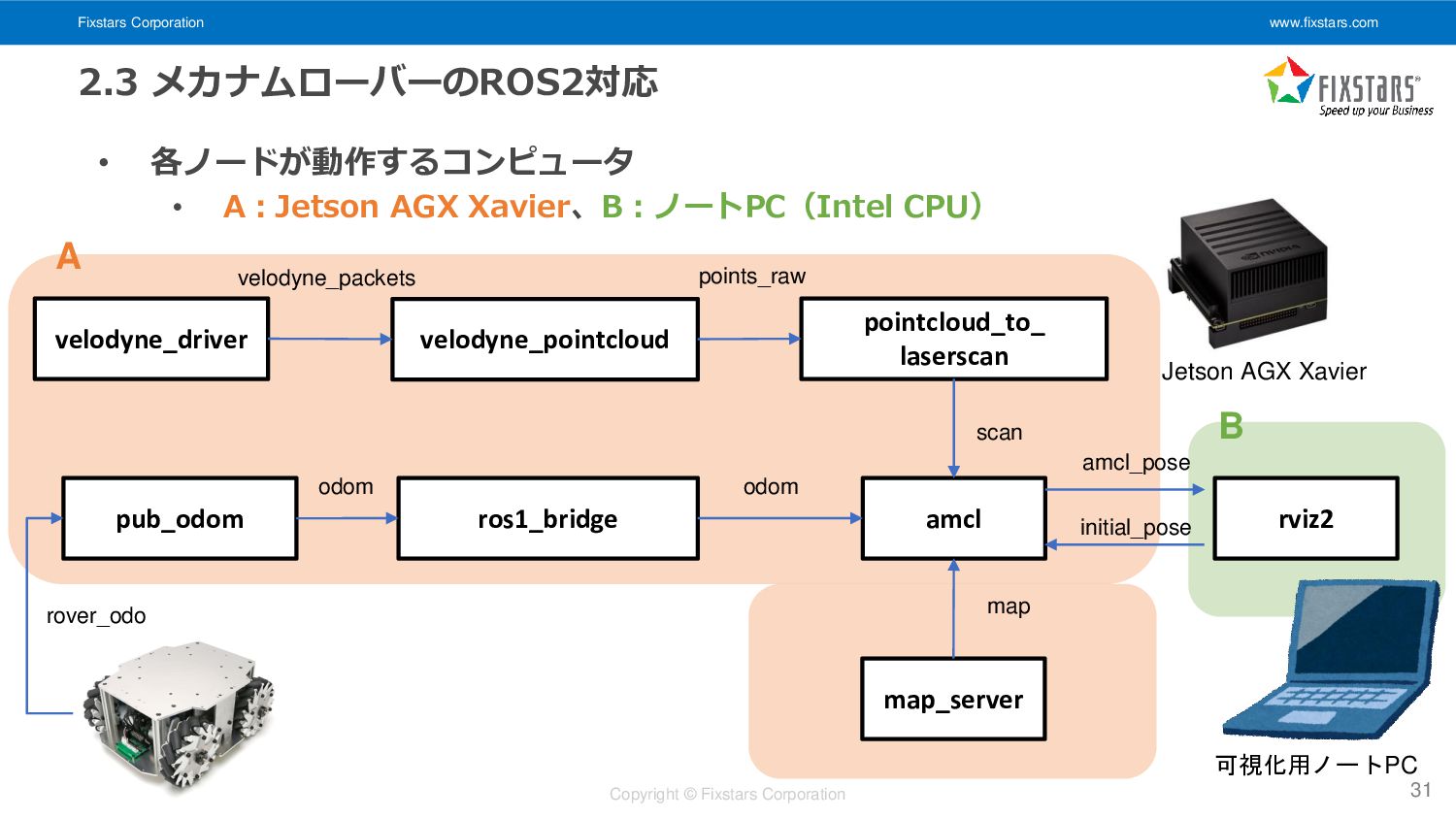
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.3 メカナムローバーのROS2対応 •
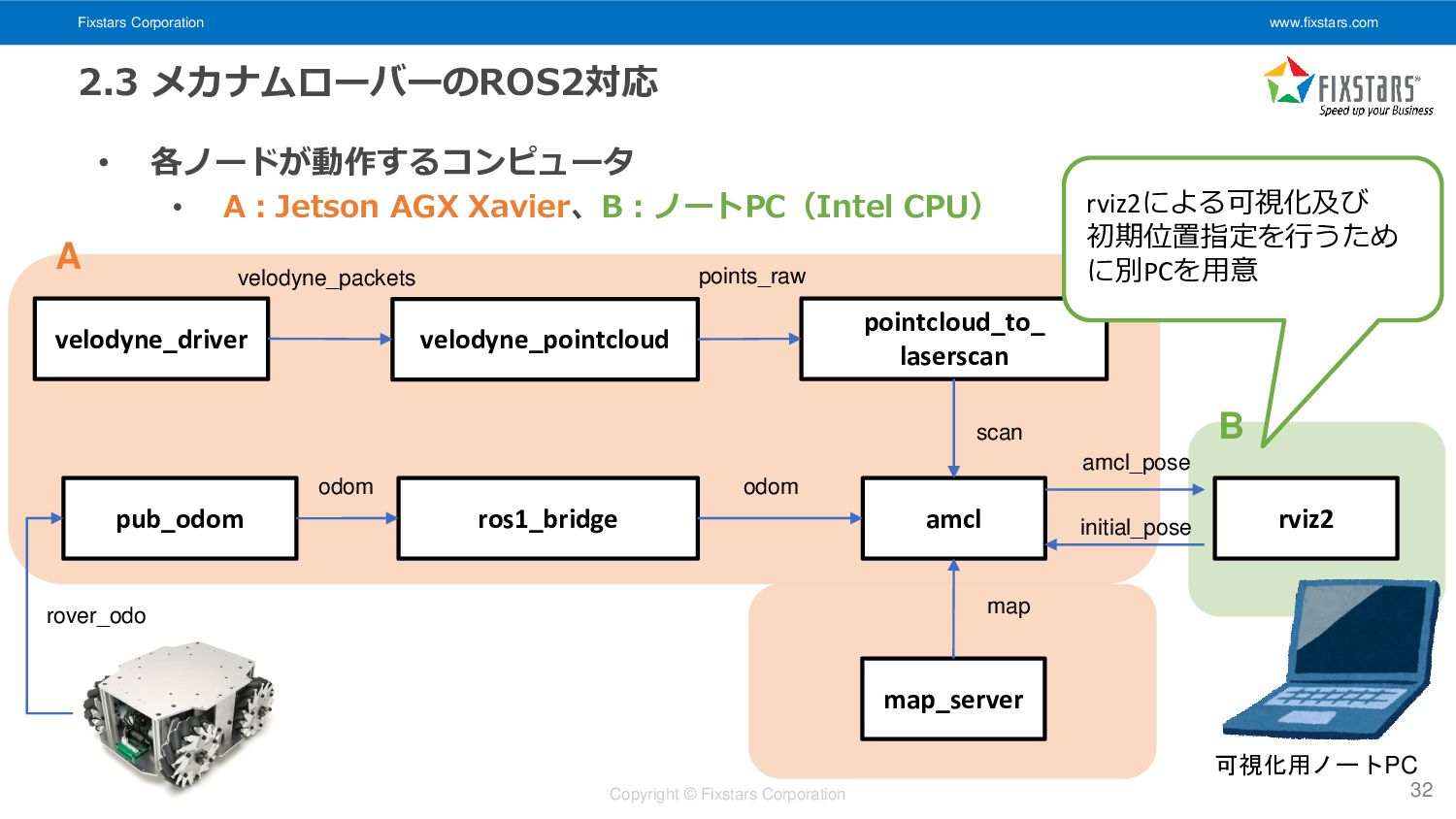
各ノードが動作するコンピュータ • A:Jetson AGX Xavier、B:ノートPC(Intel CPU) 31 amcl velodyne_driver pub_odom map odom rover_odo map_server odom amcl_pose velodyne_pointcloud pointcloud_to_ laserscan scan ros1_bridge initial_pose rviz2 velodyne_packets points_raw Jetson AGX Xavier 可視化用ノートPC A B
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.3 メカナムローバーのROS2対応 •
各ノードが動作するコンピュータ • A:Jetson AGX Xavier、B:ノートPC(Intel CPU) 32 amcl velodyne_driver pub_odom map odom rover_odo map_server odom amcl_pose velodyne_pointcloud pointcloud_to_ laserscan scan ros1_bridge initial_pose rviz2 velodyne_packets points_raw rviz2による可視化及び 初期位置指定を行うため に別PCを用意 可視化用ノートPC A B
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.3 メカナムローバーのROS2対応 •
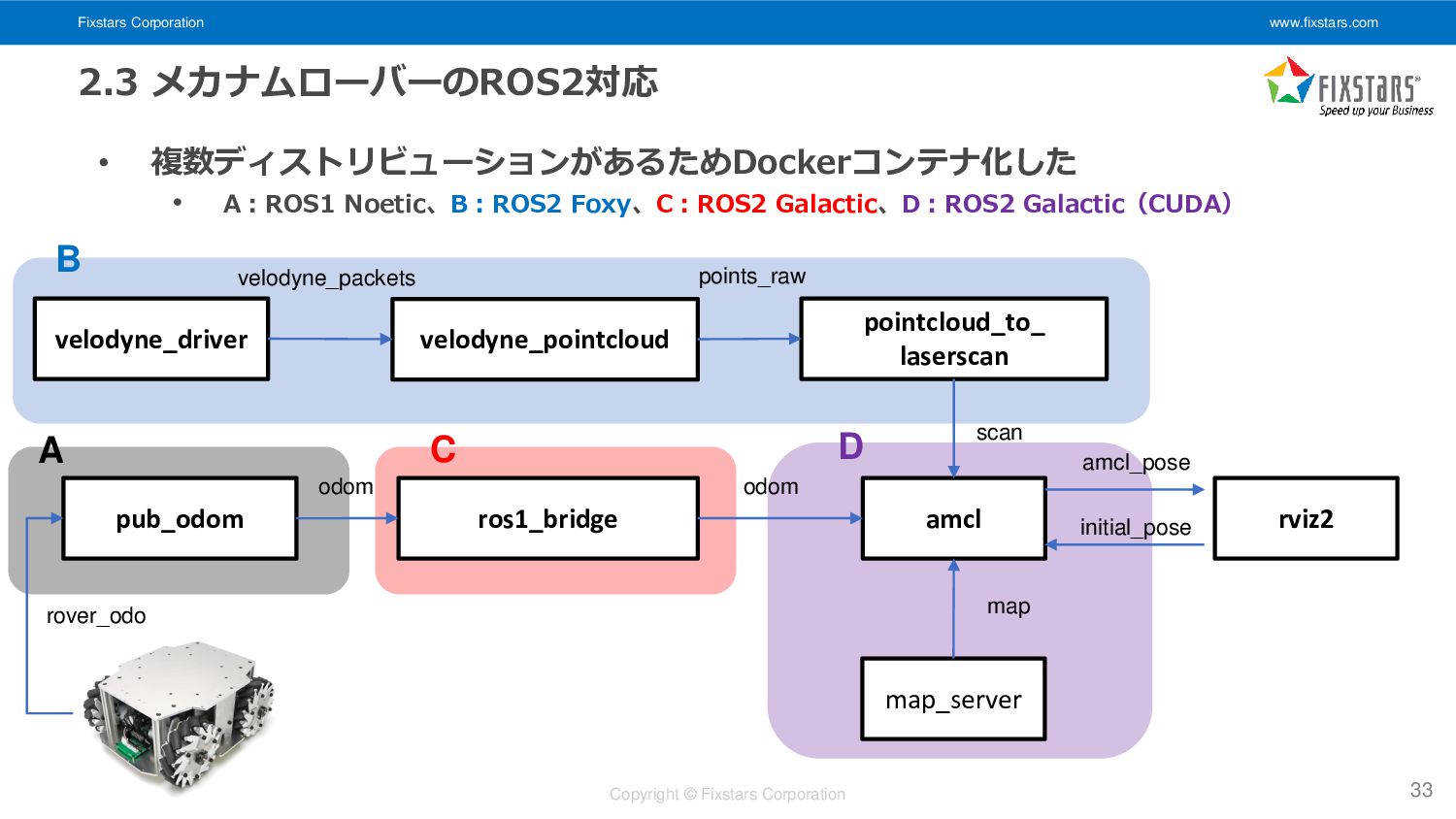
複数ディストリビューションがあるためDockerコンテナ化した • A:ROS1 Noetic、B:ROS2 Foxy、C:ROS2 Galactic、D:ROS2 Galactic(CUDA) 33 amcl velodyne_driver pub_odom map odom rover_odo map_server odom amcl_pose velodyne_pointcloud pointcloud_to_ laserscan scan ros1_bridge initial_pose rviz2 velodyne_packets points_raw A C B D
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.3 メカナムローバーのROS2対応 このDocker環境を構築するにあたり、以下のようなハマりポイントがあった
• 扱うDockerコンテナが多いため手順が煩雑 • 背景:様々なROS1、ROS2ディストリビューションが混在するため • 対応:docker-composeを使うことで簡単に起動できるようした • Jetson AGX Xavier、ノートPC間でROS2の通信ができない • 課題 • 今回のハードウェア構成では、有線LAN、Wi-Fiといった複数のNICを同時に使用す るが、 CycloneDDS側で複数NICを適切にハンドリングしてくれない • 対応 • CycloneDDS設定で明示的にNICを設定することで対応[5] 34 [5] http://www.robotandchisel.com/2020/08/12/cyclonedds/ export CYCLONEDDS_URI="<CycloneDDS><Domain><General><NetworkInterfaceAddress>wlan0</NetworkInterfaceAddress></General></Domain></CycloneDDS>" 設定例(wlan0となっている箇所はネットワークインターフェース名)
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.3 メカナムローバーのROS2対応 Jetson
AGX Xavier上で動作するCUDA、ROS2 Galactic環境構築 • 課題 • ROS2公式のDockerイメージ (ros:galactic)[6]だとROS2 Galacticは使えるが、 CUDAを使えない • NGC(NVIDIA GPU CLOUD)配布のDockerイメージ(nvcr.io/nvidia/l4t-base)[7] だとCUDAは使えるが、Ubuntu 18.04ベースであるため、ROS2 Galacticをソースコ ードから入れる必要あり[8] 35 [6] https://hub.docker.com/_/ros [7] https://ngc.nvidia.com/catalog/containers/nvidia:l4t-base [8] https://docs.ros.org/en/galactic/Installation/Ubuntu-Development-Setup.html
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.3 メカナムローバーのROS2対応 Jetson
AGX Xavier上で動作するCUDA、ROS2 Galactic環境構築 • 今回の対応 • NGC配布Dockerイメージ(nvcr.io/nvidia/l4t-base)をベースにROS2 Galacticを インストールしたDockerイメージ(dustynv/ros:galactic-ros-base-l4t-r32.6.1) [9]を活用 • amclおよび依存ROS2パッケージをソースコードからビルド • ROS2 Galacticをソースコードからインストールしている都合上、aptでROS2 Galacticパッケージのインストールができないため 36 [9] https://github.com/dusty-nv/jetson-containers
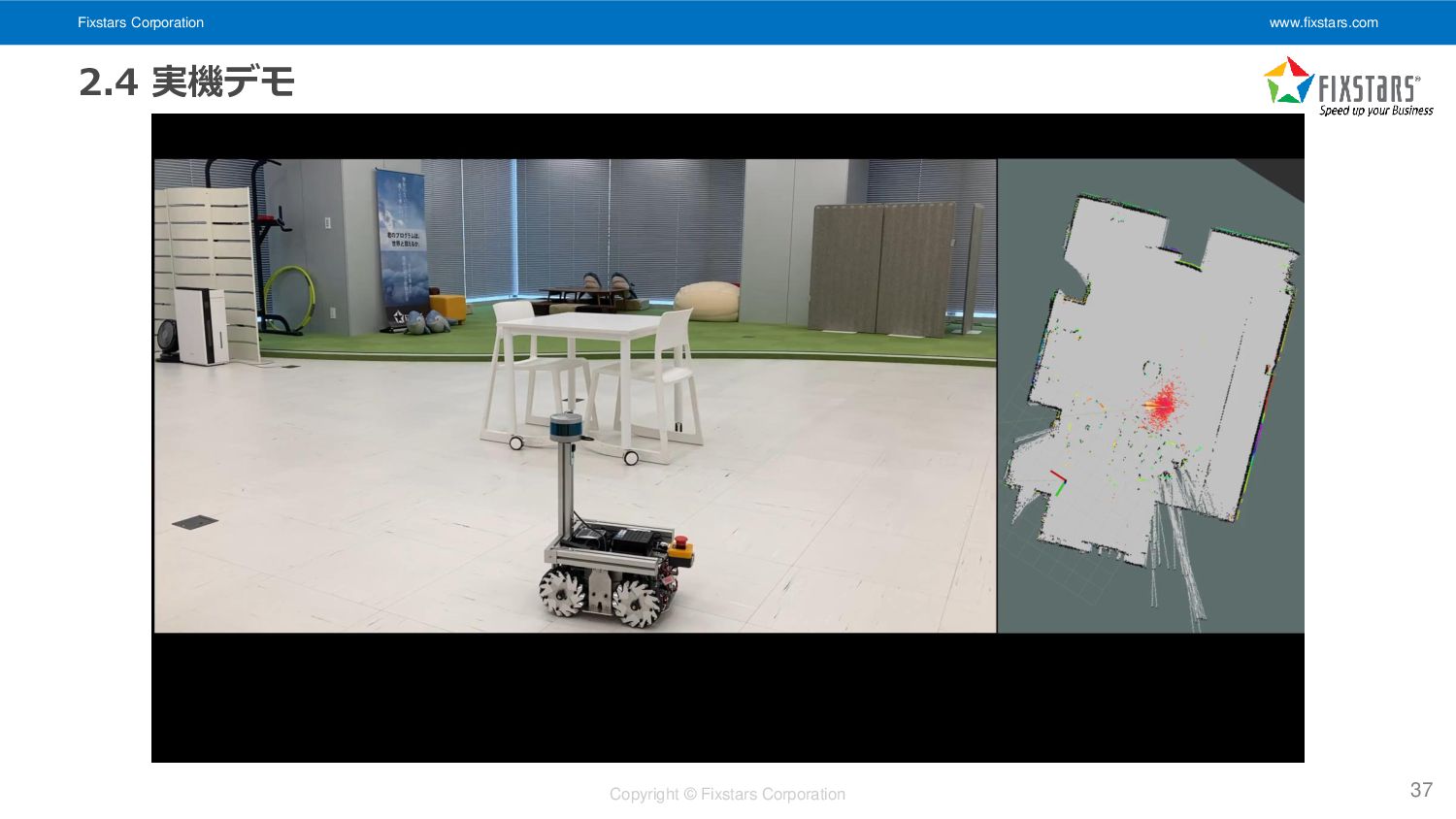
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 2.4 実機デモ 37
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation Copyright © Fixstars
Corporation 3. amclパッケージの CUDA高速化
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3. amclパッケージのCUDA高速化 アウトライン
• 3.1 背景 • 3.2 amcl とは • 3.3 amcl のプロファイリング • 3.4 amcl の CUDA 化による高速化 39
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.1 背景 •
ナビゲーション処理に関わるROS2パッケージをCUDA実装することで、処理の高速 化およびCPU負荷低減を実現したい • 以下の理由から今回はamclパッケージ(自己位置推定処理)[10]に着目した • パーティクル毎に処理が独立しており、並列度が高く、GPUと相性がよい(amclの アルゴリズム詳細は後述) • GPUにオフロードできれば自己位置推定精度を改善するためにパーティクル数を増や しやすい • navigation2でもGPU、CPU高速化対象アルゴリズムの候補として挙がっている • https://github.com/ros-planning/navigation2/issues/1391 • https://github.com/ros-planning/navigation2/issues/1781 • https://navigation.ros.org/2021summerOfCode/projects/multithreading.html 40 [10] https://github.com/ros-planning/navigation2/tree/galactic/nav2_amcl
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.2 amcl とは
• Adaptive Monte Carlo Localization • 自己位置推定アルゴリズム • 内界センサ、外界センサの情報からロボットの現在位置を推定する • 特徴 • パーティクルフィルタをベースとしたアルゴリズム • 位置姿勢の候補とその尤度をパーティクルで表現する • パーティクルの散布範囲と数を動的に変更する • 自己位置が不確かな場合大域的リセットを行う 41 赤い点群: パーティクル 外周の点群: LiDAR によるスキャン
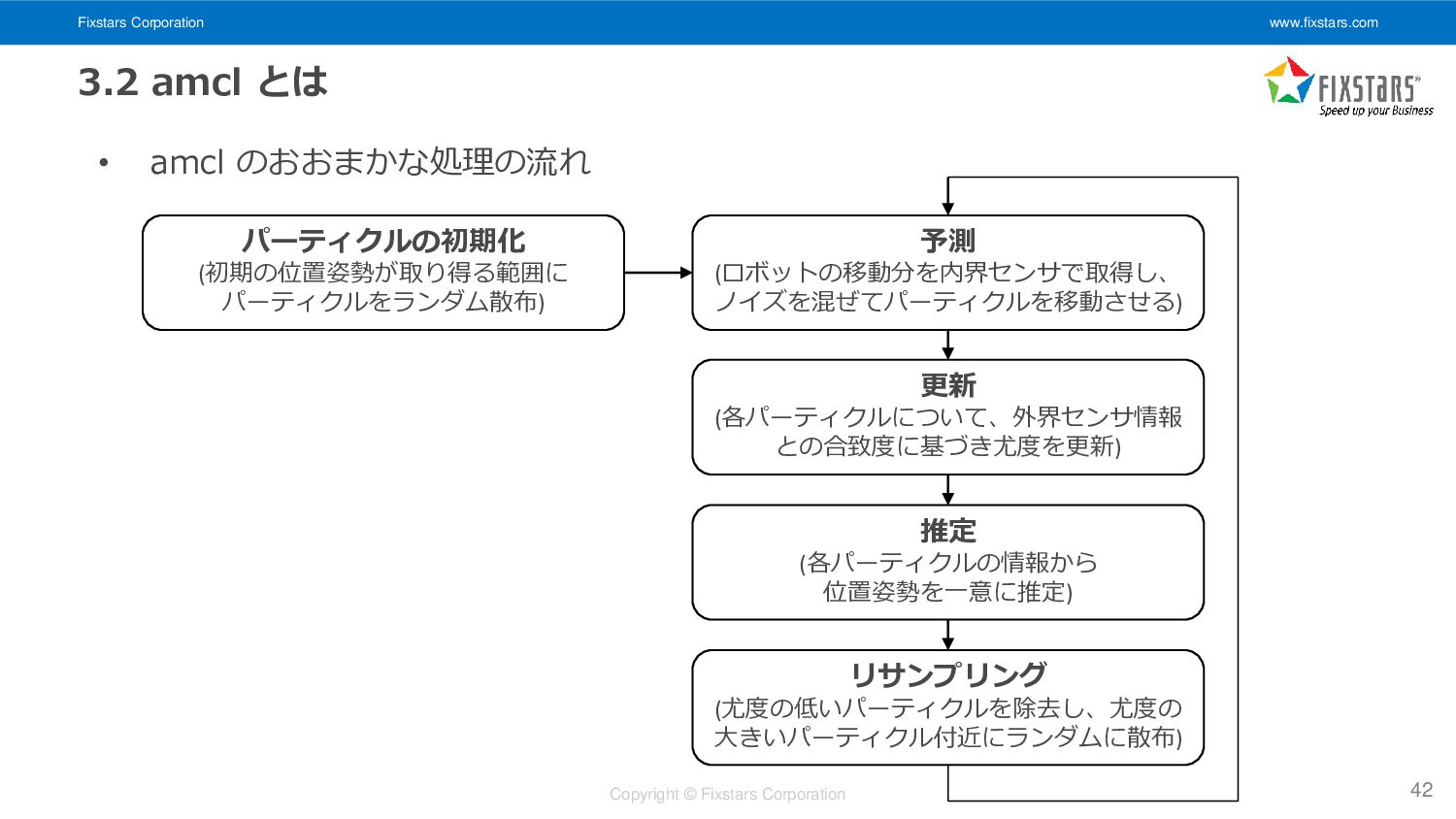
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.2 amcl とは
• amcl のおおまかな処理の流れ 42 パーティクルの初期化 (初期の位置姿勢が取り得る範囲に パーティクルをランダム散布) 予測 (ロボットの移動分を内界センサで取得し、 ノイズを混ぜてパーティクルを移動させる) 更新 (各パーティクルについて、外界センサ情報 との合致度に基づき尤度を更新) 推定 (各パーティクルの情報から 位置姿勢を一意に推定) リサンプリング (尤度の低いパーティクルを除去し、尤度の 大きいパーティクル付近にランダムに散布)
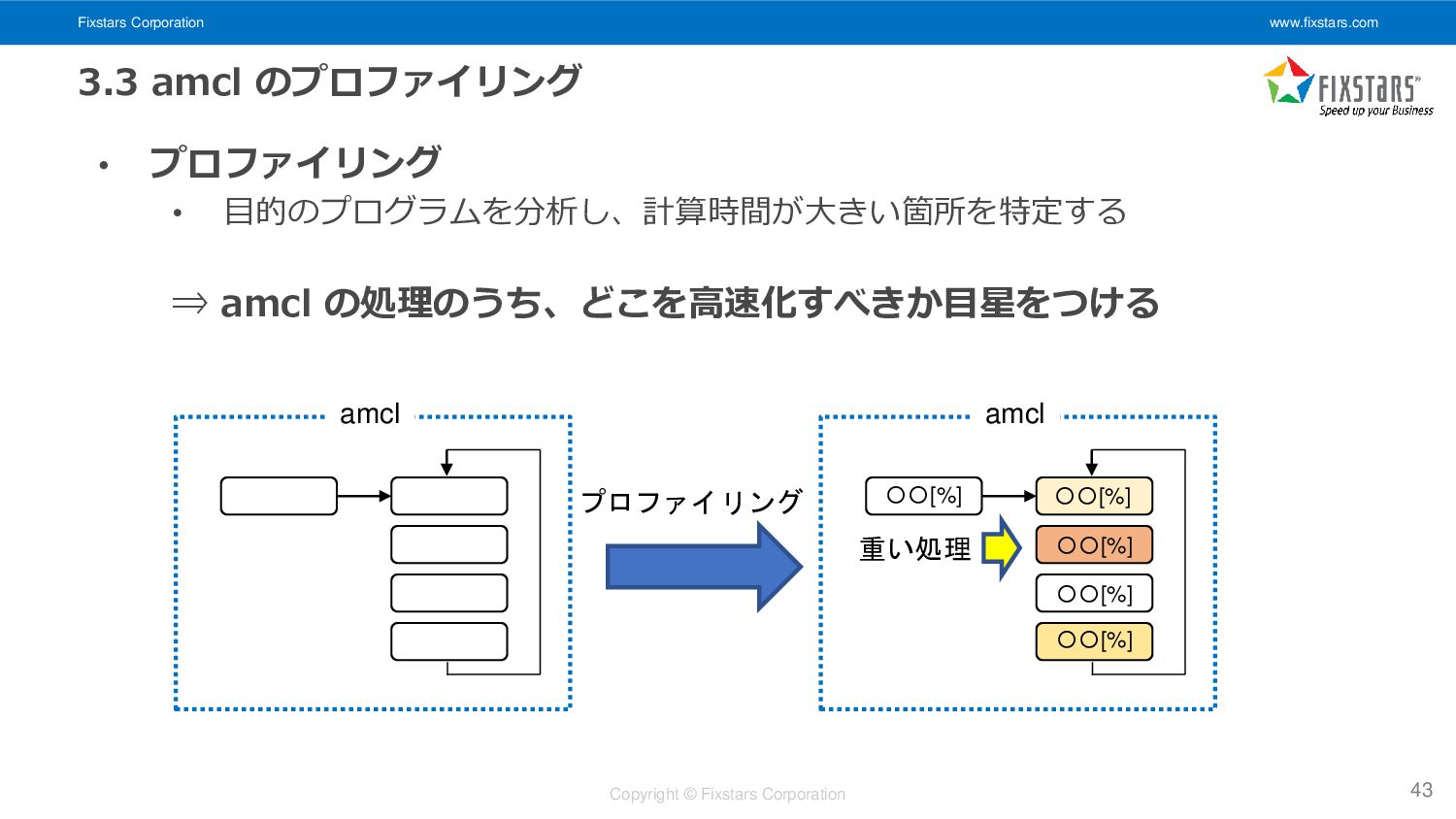
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.3 amcl のプロファイリング
• プロファイリング • 目的のプログラムを分析し、計算時間が大きい箇所を特定する ⇒ amcl の処理のうち、どこを高速化すべきか目星をつける 43 amcl プロファイリング amcl 〇〇[%] 〇〇[%] 〇〇[%] 〇〇[%] 〇〇[%] 重い処理
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.3 amcl のプロファイリング
• 実際に amcl のプロファイリングを実施 • 説明内容 • 3.3.1 プロファイリングの実行環境 • 3.3.2 プロファイリング時のノード構成 • 3.3.3 プロファイリング方法 • 3.3.4 プロファイリング結果 44
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.3.1 プロファイリングの実行環境 •
ハードウェア • NVIDIA® Jetson AGX Xavier™ • CPU: ARMv8 Processor rev 0 (v8l)、64bit 8コア • GPU: NVIDIA Volta™, CUDAコア512基 • RAM: 32GB • 動作モード: 30W 8コア • 動作周波数(Max) … CPU: 1.2GHz、GPU: 905 MHz • ソフトウェア • NVIDIA® JetPack SDK 4.6 (L4T 32.6.1) (*) • OS: Ubuntu18.04 • CUDA: 10.2 • コンパイラ: gcc version 7.5.0 (Ubuntu/Linaro 7.5.0-3ubuntu1~18.04) 45 (*) JetPack : Jetson用の開発キット.L4T 32.6.1を含む L4T (NVIDIA® Jetson™ Linux Driver Package) : Jetson向けのサポートパッケージ
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.3.1 プロファイリングの実行環境 •
ROS2の動作環境 • ROSディストリビューション : ROS2 Galactic • 2021年11月現在の最新バージョン • Dockerコンテナ内にROS2環境を構築 • Linux 18.04 (L4T 32.6.1) 上にROS2 Galacticをビルドしたコンテナ[11]を使用 46 Galactic Geochelone リリース: 2021/5/23 [11] https://github.com/dusty-nv/jetson-containers Jetson AGX Xavier Linux 18.04 (L4T 32.6.1) Docker コンテナ (L4T 32.6.1) ROS2 Galactic ハードウェア ホストOS ゲストOS アプリケーション
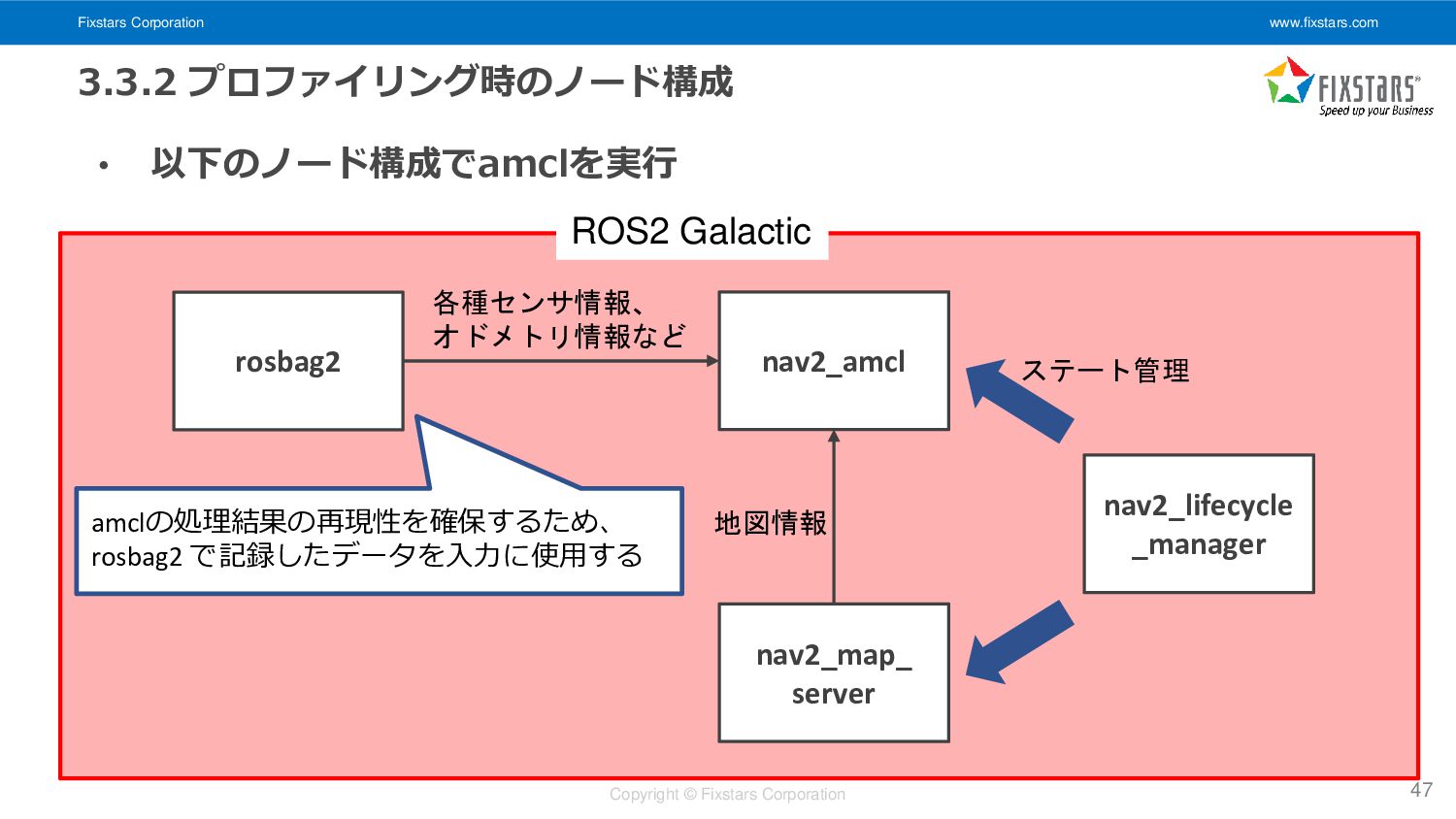
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.3.2 プロファイリング時のノード構成 •
以下のノード構成でamclを実行 47 nav2_amcl nav2_map_ server nav2_lifecycle _manager rosbag2 ROS2 Galactic 各種センサ情報、 オドメトリ情報など 地図情報 ステート管理 amclの処理結果の再現性を確保するため、 rosbag2 で記録したデータを入力に使用する
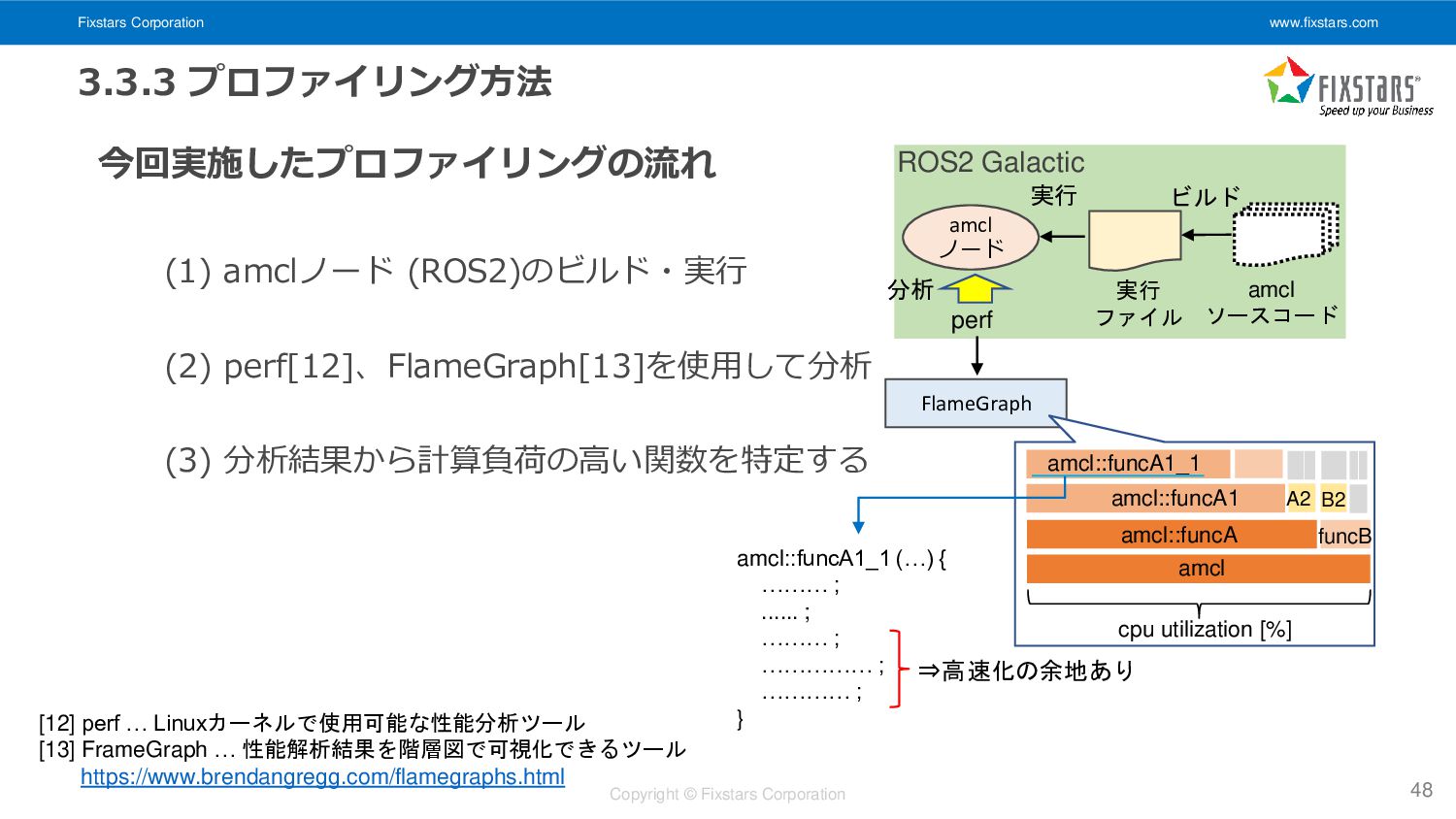
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.3.3 プロファイリング方法 今回実施したプロファイリングの流れ
(1) amclノード (ROS2)のビルド・実行 (2) perf[12]、FlameGraph[13]を使用して分析 (3) 分析結果から計算負荷の高い関数を特定する 48 [12] perf … Linuxカーネルで使用可能な性能分析ツール [13] FrameGraph … 性能解析結果を階層図で可視化できるツール https://www.brendangregg.com/flamegraphs.html amcl::funcA1_1 (…) { ……… ; ...... ; ……… ; …………… ; ………… ; } ⇒高速化の余地あり ビルド amcl ノード 実行 amcl ソースコード 実行 ファイル ROS2 Galactic FlameGraph 分析 perf amcl::funcA1_1 amcl::funcA1 cpu utilization [%] amcl::funcA funcB amcl A2 B2
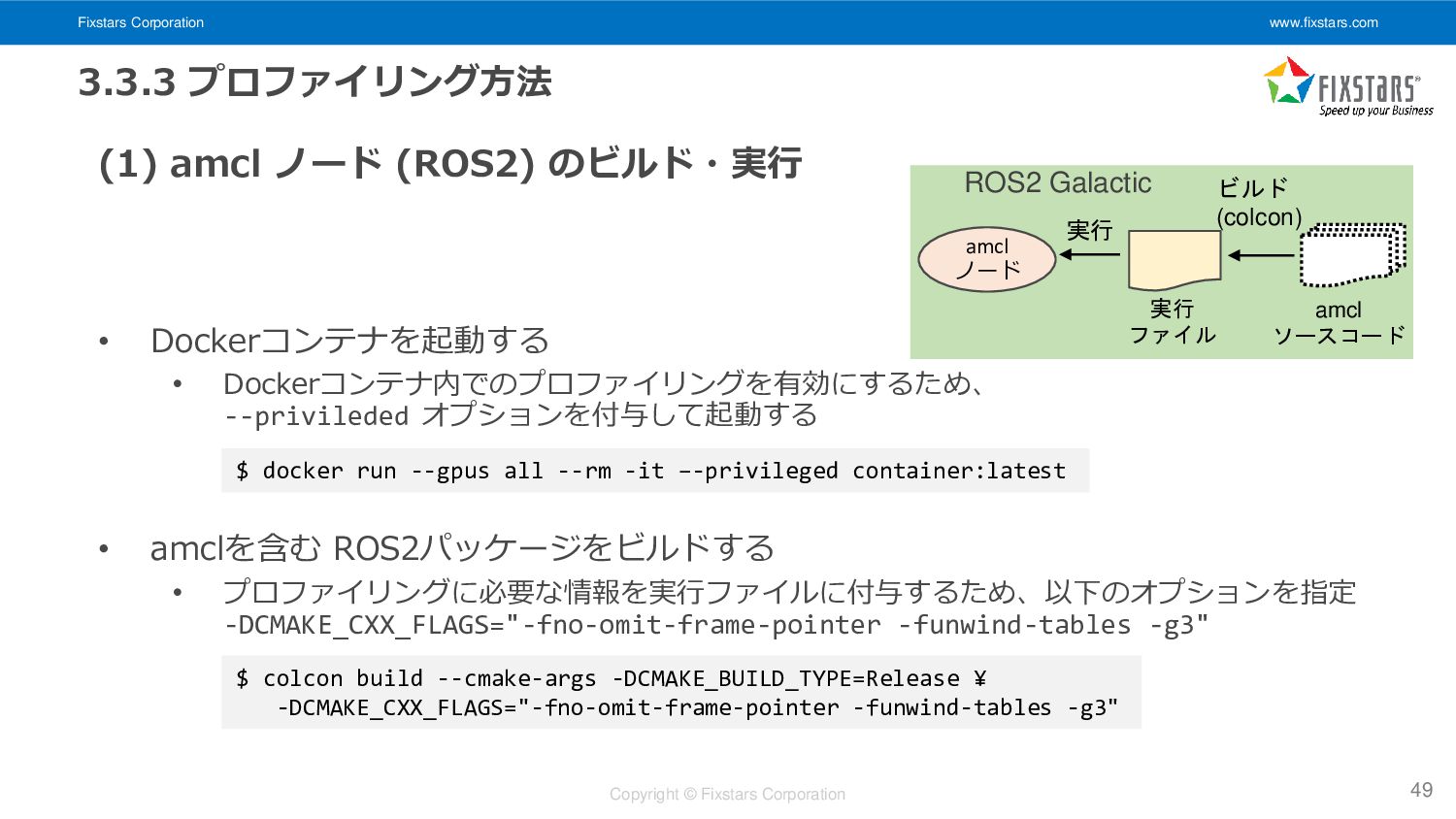
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.3.3 プロファイリング方法 (1)
amcl ノード (ROS2) のビルド・実行 • Dockerコンテナを起動する • Dockerコンテナ内でのプロファイリングを有効にするため、 --privileded オプションを付与して起動する • amclを含む ROS2パッケージをビルドする • プロファイリングに必要な情報を実行ファイルに付与するため、以下のオプションを指定 -DCMAKE_CXX_FLAGS="-fno-omit-frame-pointer -funwind-tables -g3" 49 $ docker run --gpus all --rm -it –-privileged container:latest $ colcon build --cmake-args -DCMAKE_BUILD_TYPE=Release ¥ -DCMAKE_CXX_FLAGS="-fno-omit-frame-pointer -funwind-tables -g3" ビルド (colcon) amcl ノード 実行 amcl ソースコード 実行 ファイル ROS2 Galactic
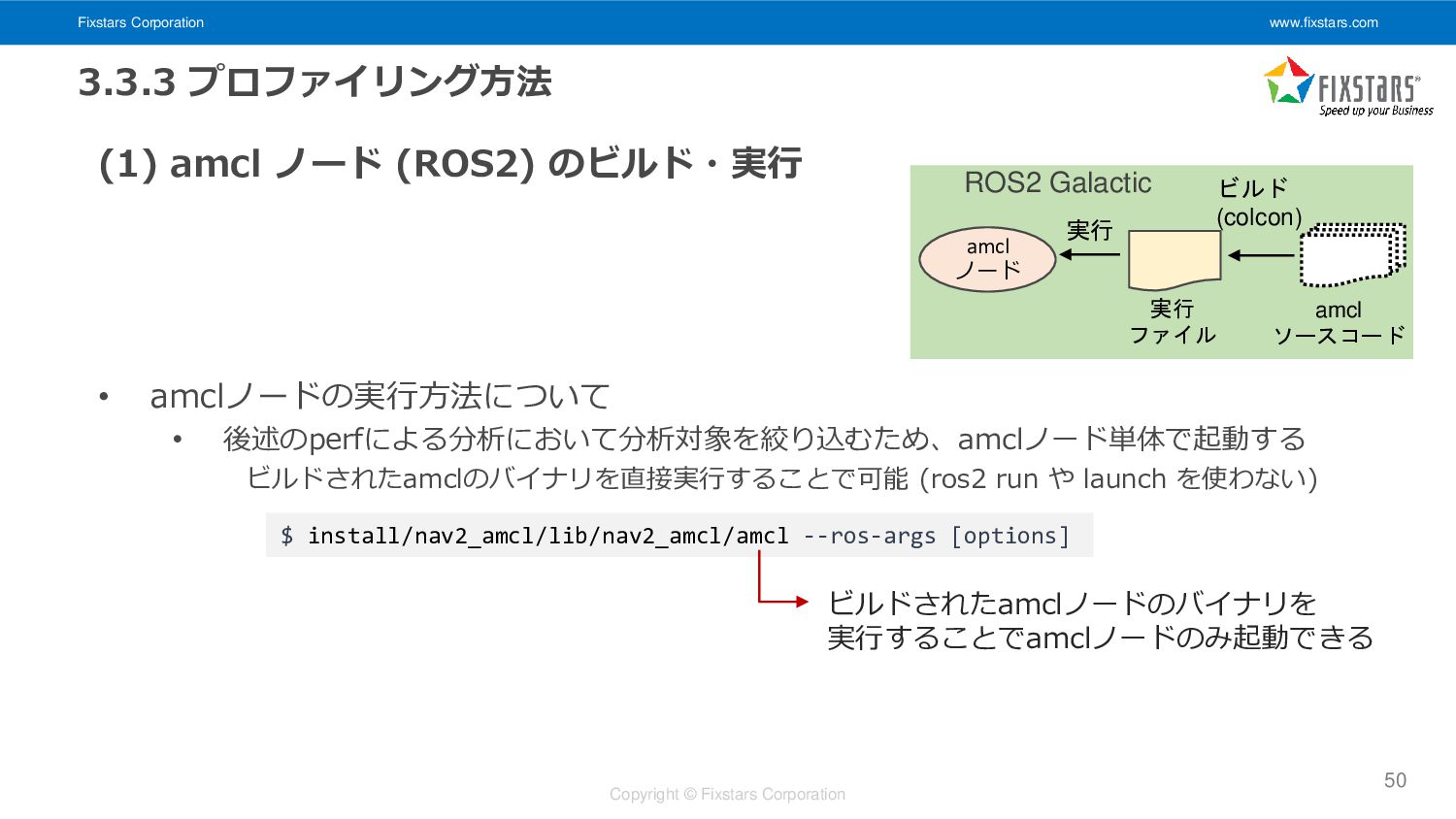
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.3.3 プロファイリング方法 (1)
amcl ノード (ROS2) のビルド・実行 • amclノードの実行方法について • 後述のperfによる分析において分析対象を絞り込むため、amclノード単体で起動する ビルドされたamclのバイナリを直接実行することで可能 (ros2 run や launch を使わない) 50 $ install/nav2_amcl/lib/nav2_amcl/amcl --ros-args [options] ビルド (colcon) amcl ノード 実行 amcl ソースコード 実行 ファイル ROS2 Galactic ビルドされたamclノードのバイナリを 実行することでamclノードのみ起動できる
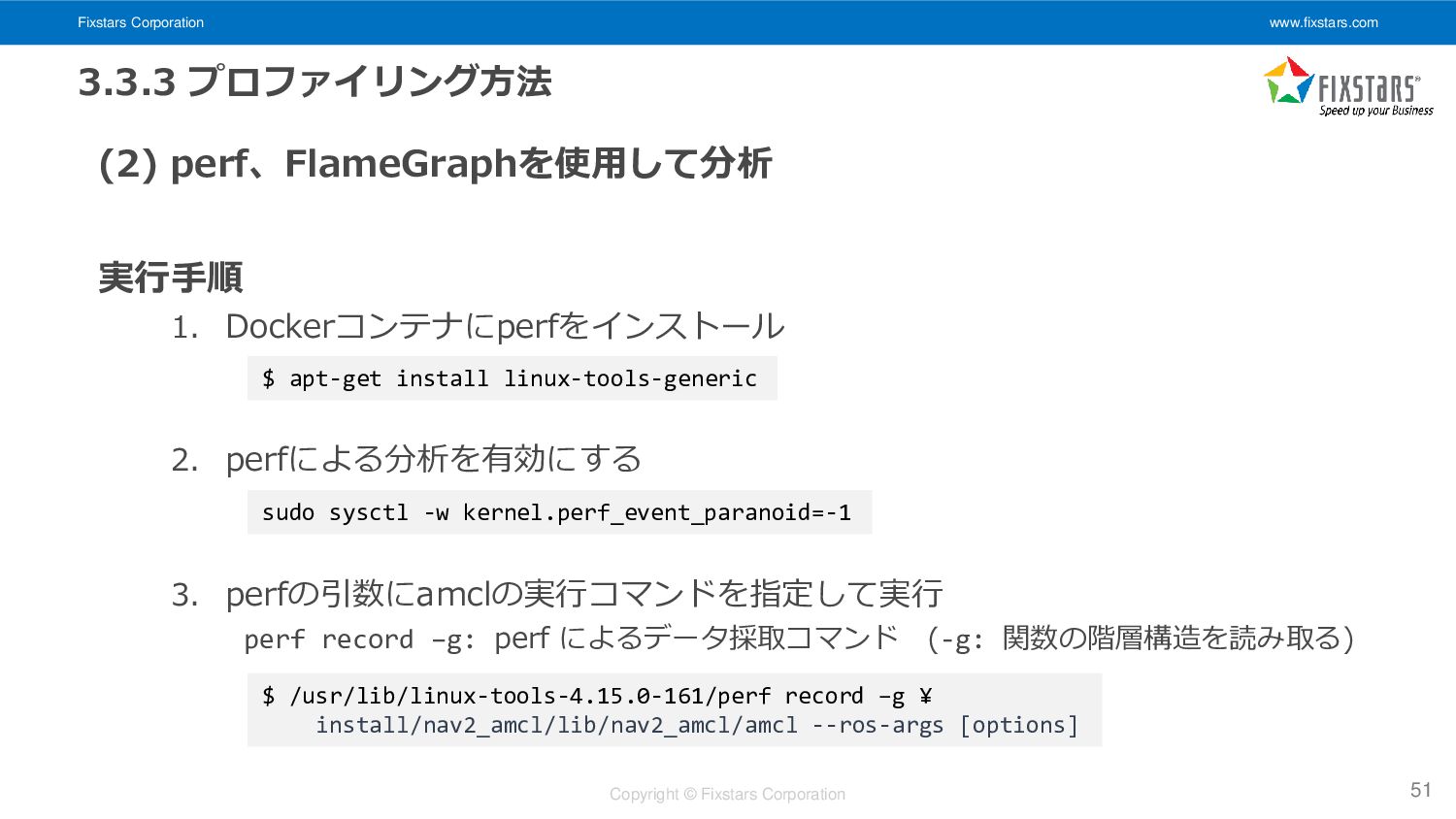
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.3.3 プロファイリング方法 (2)
perf、FlameGraphを使用して分析 実行手順 1. Dockerコンテナにperfをインストール 2. perfによる分析を有効にする 3. perfの引数にamclの実行コマンドを指定して実行 perf record –g: perf によるデータ採取コマンド (-g: 関数の階層構造を読み取る) 51 $ apt-get install linux-tools-generic $ /usr/lib/linux-tools-4.15.0-161/perf record –g ¥ install/nav2_amcl/lib/nav2_amcl/amcl --ros-args [options] sudo sysctl -w kernel.perf_event_paranoid=-1
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.3.3 プロファイリング方法 (2)
perf、FlameGraphを使用して分析 実行手順 4. FlameGraphのスクリプト[14]を使用し、 perfの分析結果を可視化 52 $ perf script | ./stackcollapse-perf.pl ¥ | ./flamegraph.pl > output.svg FrameGraph [14] https://github.com/brendangregg/FlameGraph
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.3.3 プロファイリング方法 (3)
分析結果から計算負荷の高い関数を特定する • FlameGraphから計算負荷が高い関数を特定する • FlameGraphにより、関数構造と処理負荷の比率が分かる • タイマの埋め込みにより処理時間を計測する • FlameGraphで判明した処理負荷の大きい関数周辺に タイマを埋め込み、具体的な処理時間を計測する 53 処理負荷 関数の呼び出し順序
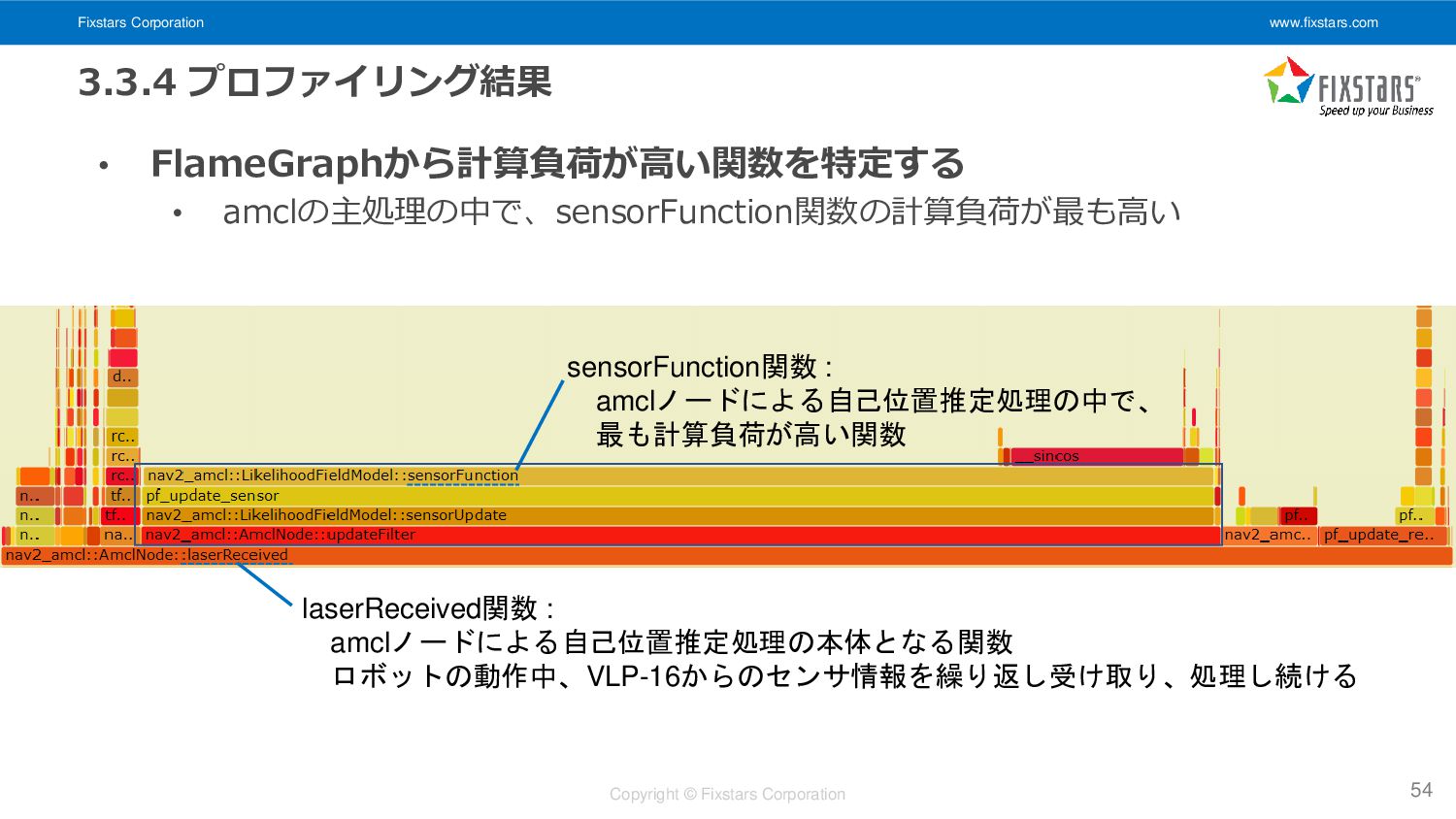
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.3.4 プロファイリング結果 •
FlameGraphから計算負荷が高い関数を特定する • amclの主処理の中で、sensorFunction関数の計算負荷が最も高い 54 laserReceived関数 : amclノードによる自己位置推定処理の本体となる関数 ロボットの動作中、VLP-16からのセンサ情報を繰り返し受け取り、処理し続ける sensorFunction関数 : amclノードによる自己位置推定処理の中で、 最も計算負荷が高い関数
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.3.4 プロファイリング結果 •
タイマの埋め込みにより処理時間を計測する 55 laserReceived: 41.761 msec getOdomPose: 0.083 msec shouldUpdateFilter: 0.016 msec odometryUpdate: 2.504 msec updateFilter (≒ sensorFunction): 33.179 msec pf_update_resample: 4.875 msec publishParticleCloud: 0.472 msec getMaxWeightHyp: 0.526 msec publishAmclPose: 0.128 msec calculateMaptoOdomTransform: 0.194 msec sendMapToOdomTransform: 0.175 msec odometryUpdate 6% updateFilter 79% pf_update_resample 12% laserReceived関数処理時間内訳 getOdomPose shouldUpdateFilter odometryUpdate updateFilter pf_update_resample publishParticleCloud getMaxWeightHyp publishAmclPose calculateMaptoOdomTransform sendMapToOdomTransform
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.4 amclのCUDA化による高速化 アウトライン
• 3.4.1 NaiveなCUDA化処理の実装 • 3.4.2 CUDA実行モデル • 3.4.2 CUDA化処理プロファイリング • 3.4.3 CUDA化処理最適化 • 3.4.4 Jetson上における性能測定の留意点 56
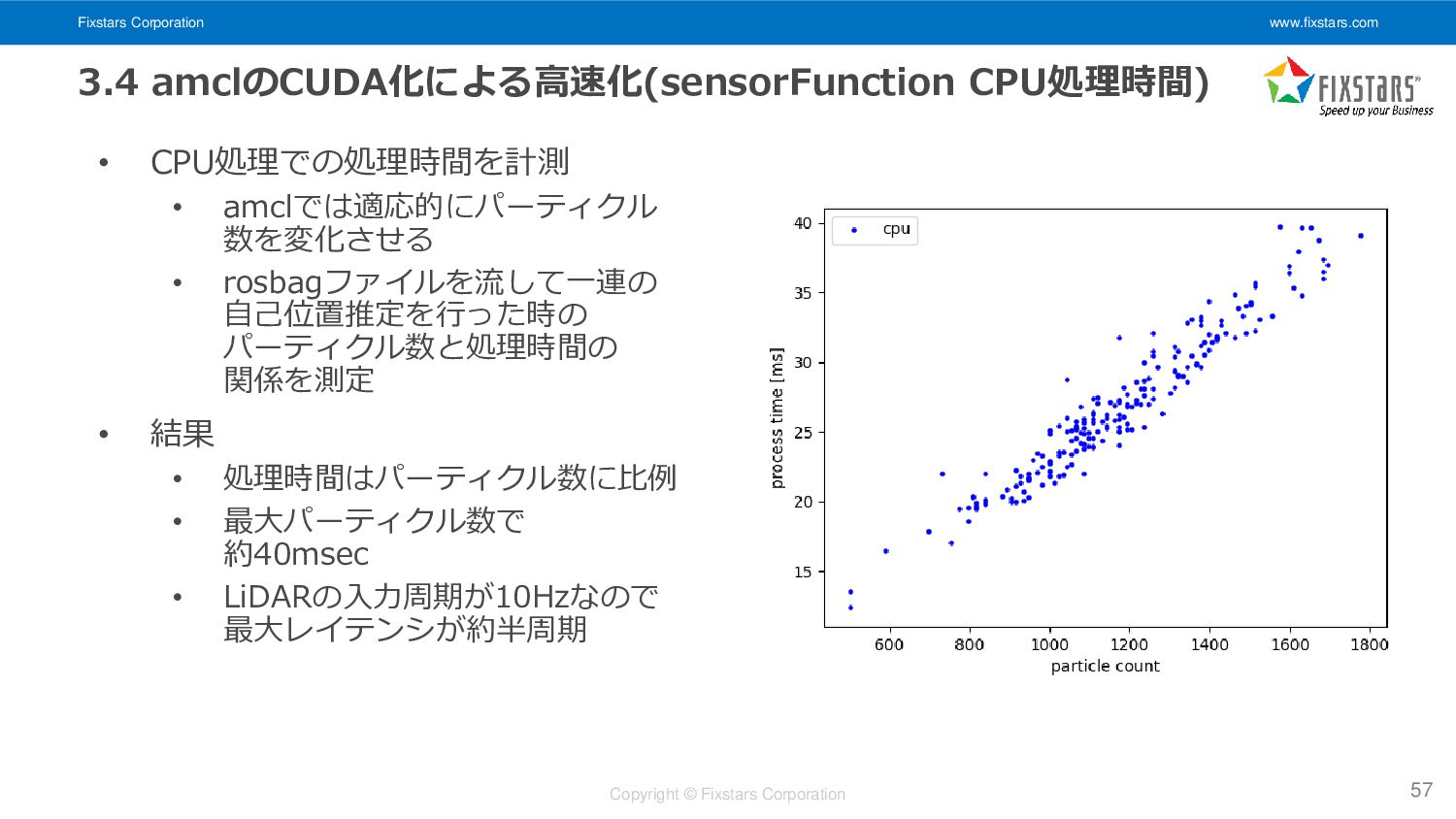
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.4 amclのCUDA化による高速化(sensorFunction CPU処理時間)
• CPU処理での処理時間を計測 • amclでは適応的にパーティクル 数を変化させる • rosbagファイルを流して一連の 自己位置推定を行った時の パーティクル数と処理時間の 関係を測定 • 結果 • 処理時間はパーティクル数に比例 • 最大パーティクル数で 約40msec • LiDARの入力周期が10Hzなので 最大レイテンシが約半周期 57
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.4.1 NaiveなCUDA化処理の実装 –
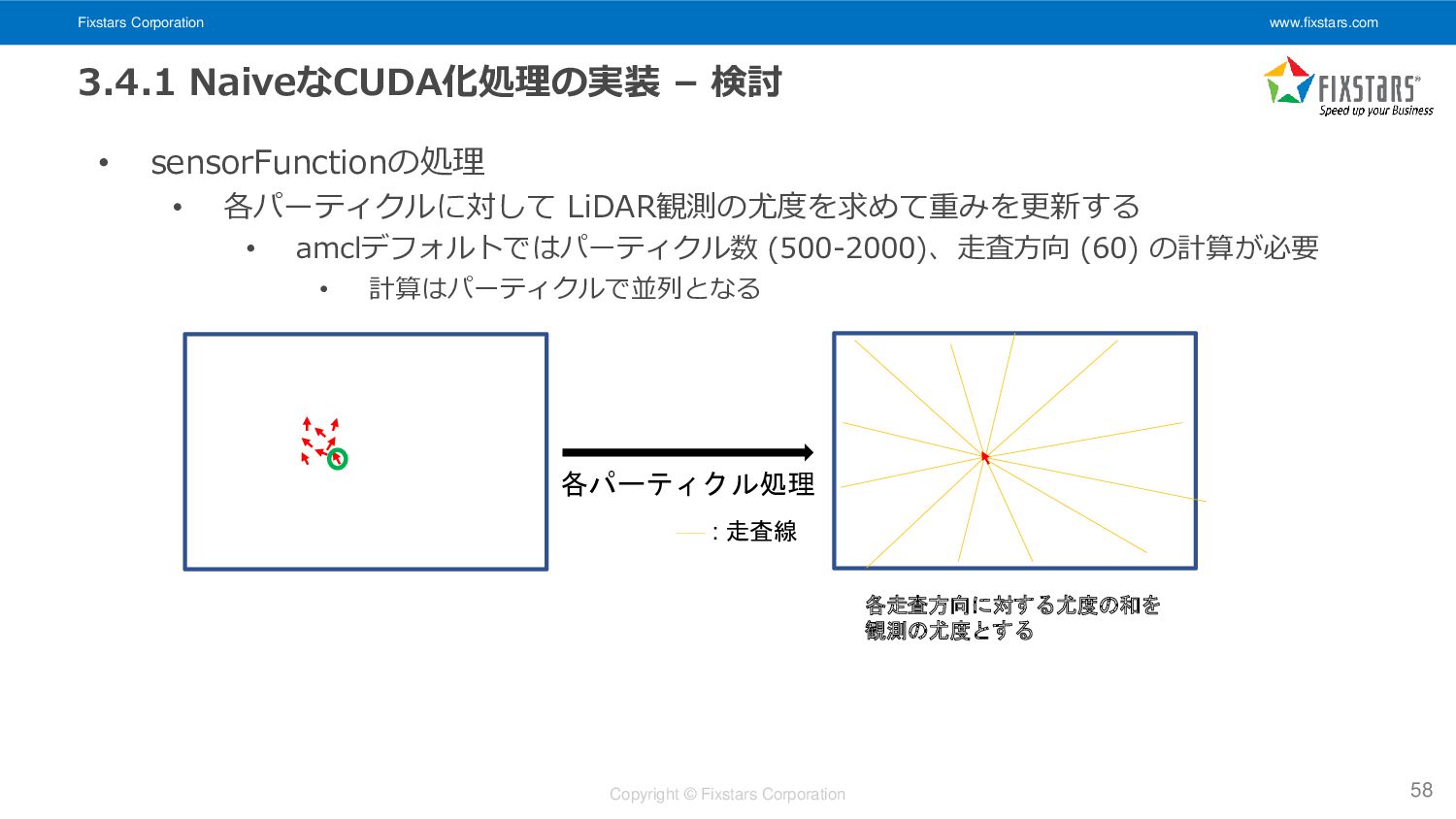
検討 • sensorFunctionの処理 • 各パーティクルに対して LiDAR観測の尤度を求めて重みを更新する • amclデフォルトではパーティクル数 (500-2000)、走査方向 (60) の計算が必要 • 計算はパーティクルで並列となる 58 各パーティクル処理 各走査方向に対する尤度の和を 観測の尤度とする : 走査線
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.4.1 NaiveなCUDA化処理の実装 –
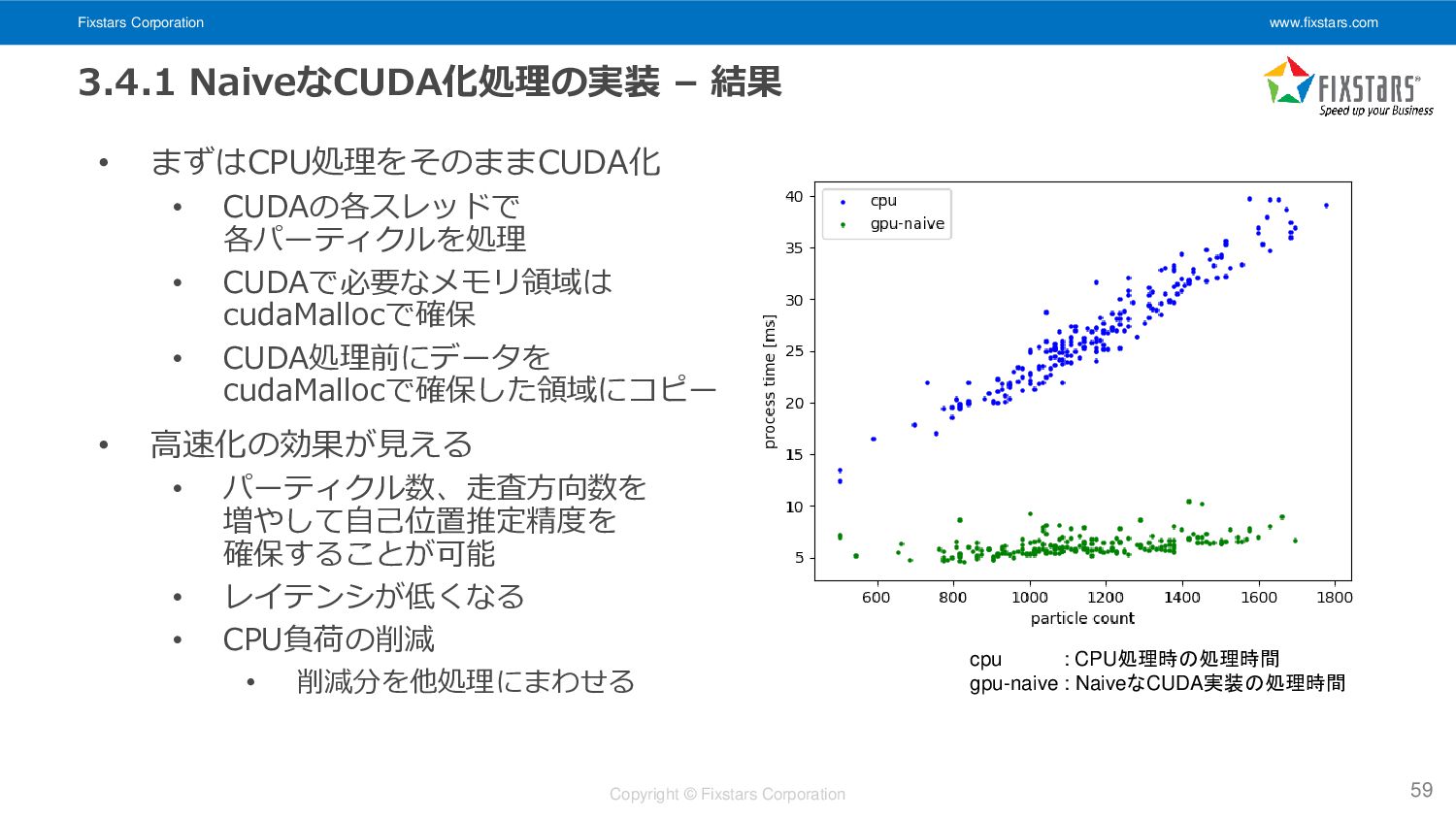
結果 • まずはCPU処理をそのままCUDA化 • CUDAの各スレッドで 各パーティクルを処理 • CUDAで必要なメモリ領域は cudaMallocで確保 • CUDA処理前にデータを cudaMallocで確保した領域にコピー • 高速化の効果が見える • パーティクル数、走査方向数を 増やして自己位置推定精度を 確保することが可能 • レイテンシが低くなる • CPU負荷の削減 • 削減分を他処理にまわせる 59 cpu : CPU処理時の処理時間 gpu-naive : NaiveなCUDA実装の処理時間
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.4.2 CUDA実行モデル 60
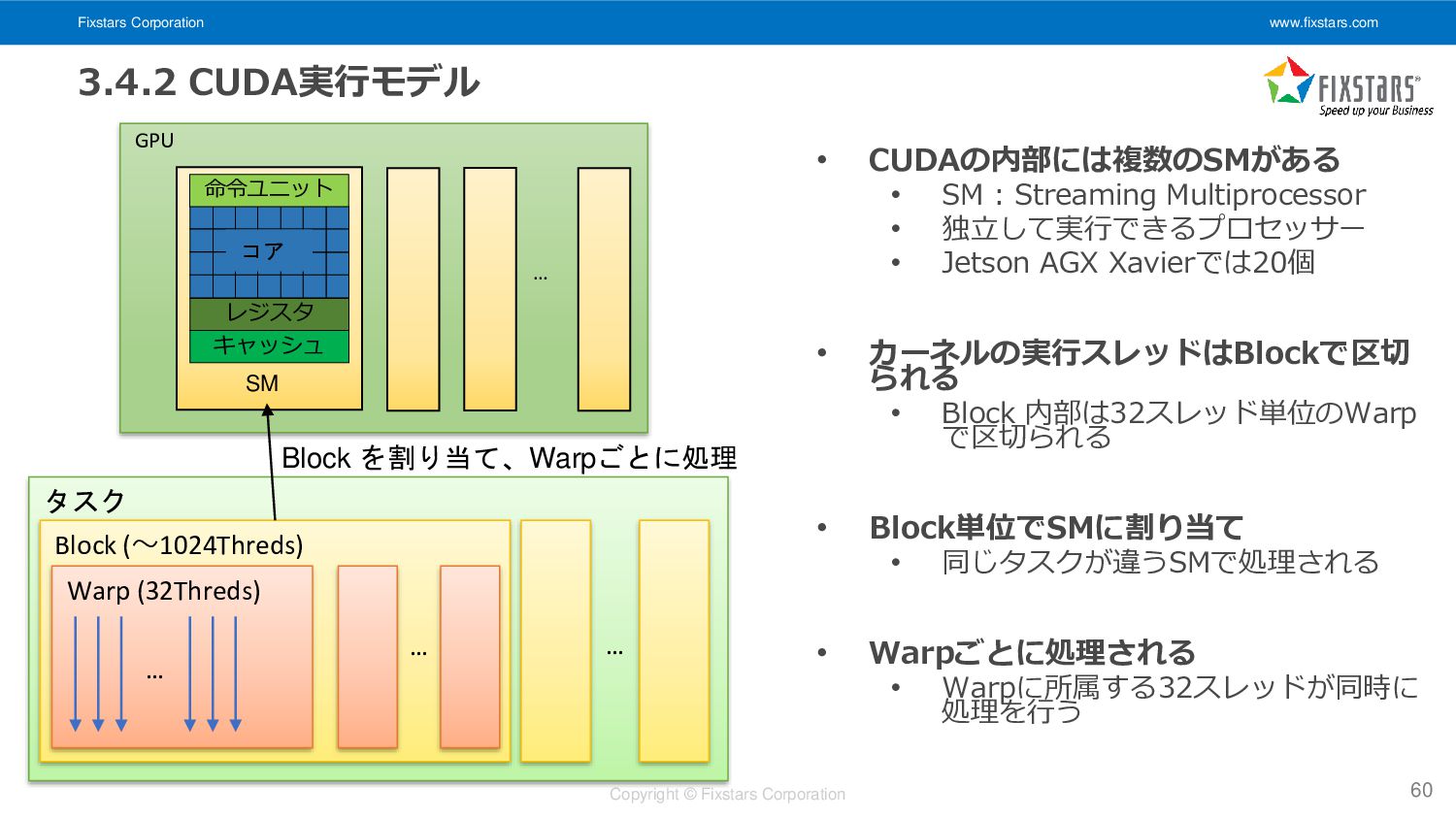
Warp (32Threds) … Block (~1024Threds) … タスク … GPU コア レジスタ キャッシュ 命令ユニット SM … • CUDAの内部には複数のSMがある • SM : Streaming Multiprocessor • 独立して実行できるプロセッサー • Jetson AGX Xavierでは20個 • カーネルの実行スレッドはBlockで区切 られる • Block 内部は32スレッド単位のWarp で区切られる • Block単位でSMに割り当て • 同じタスクが違うSMで処理される • Warpごとに処理される • Warpに所属する32スレッドが同時に 処理を行う Block を割り当て、Warpごとに処理
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.4.3 CUDAプログラムのプロファイリング •
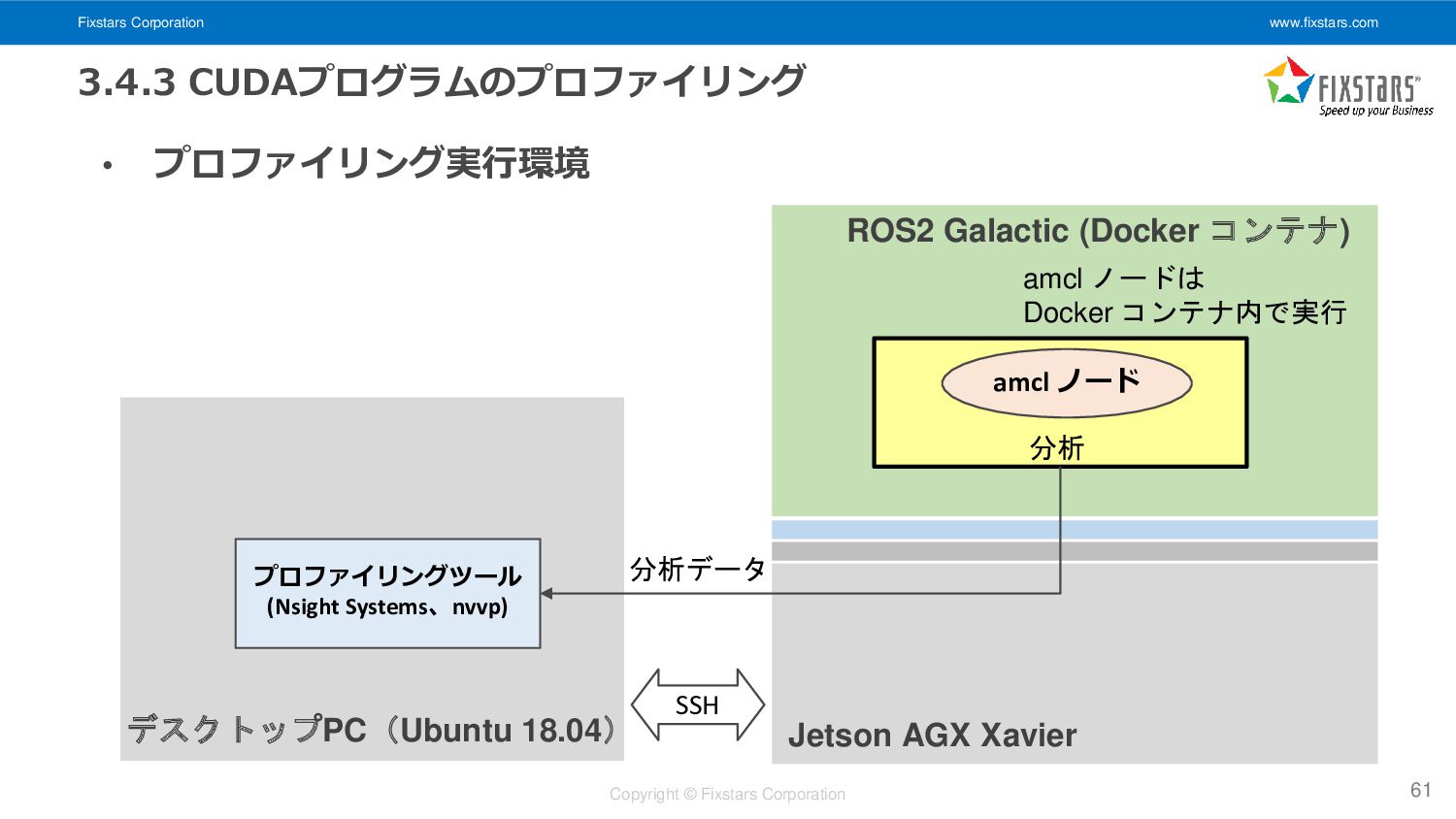
プロファイリング実行環境 61 Jetson AGX Xavier ROS2 Galactic (Docker コンテナ) デスクトップPC(Ubuntu 18.04) プロファイリングツール (Nsight Systems、nvvp) SSH 分析データ amcl ノードは Docker コンテナ内で実行 amcl ノード 分析
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation amcl ノード ROS2
Galactic 3.4.3 CUDAプログラムのプロファイリング • NVIDIA® Nsight™ Systems • NVIDIA社製のプロファイリングツール • プロファイリング結果をGUIで可視化 • GPU、CPUの処理どちらも分析可能 • GPUはCUDA API/カーネル実行時間をプロファイリング可能 62 Nsight Systems (分析) 分析 Nsight Systems (可視化) デスクトップPC Jetson AGX Xavier
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.4.3 CUDAプログラムのプロファイリング •
NVIDIA® Nsight™ Systems 実行手順 ① Jetson上でDockerコンテナを起動 Nsight Systems プロファイリングで使う一時ディレクトリをマウント ② Dockerコンテナ上で環境変数を設定 ③ Dockerコンテナ上で実行 ④ デスクトップPC上で Nsight Systems を立ち上げ Jetson に SSH 接続し docker 内で実行したプロセスを指定してプロファイリング 63 $ docker run --gpus all --rm -it --privileged --shm-size=1024m ¥ -v /opt/nvidia:/opt/nvidia -v /tmp/nvidia:/tmp/nvidia cuda-galactic:root LD_PRELOAD=“/opt/nvidia/nsight_systems/libToolsInjectionProxy64.so” ¥ install/nav2_amcl/lib/nav2_amcl/amcl --ros-args [options] export CUDA_INJECTION64_PATH="/opt/nvidia/nsight_systems/libToolsInjection64.so“ export QUADD_INJECTION_PROXY="OSRT, $QUADD_INJECTION_PROXY"
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation • NVIDIA Visual
Profiler (nvvp) • NVIDIA社製のプロファイリングツール • CUDA カーネル内部のプロファイリング結果をGUIで可視化 • nvprof • NVIDIA社製のプロファイリングツール • プロファイリングのメトリクス取得 amcl ノード ROS2 Galactic 3.4.3 CUDAプログラムのプロファイリング 64 nvprof 分析 nvvp Linux 18.04 デスクトップPC Jetson AGX Xavier
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.4.3 CUDAプログラムのプロファイリング •
nvvp 実行手順 ① Jetson上でDockerコンテナ起動 ② Dockerコンテナ上でnvprof実行 ③ 生成したプロファイル結果をscpコマンド等でデスクトップPCにコピー ④ デスクトップPCでnvvpを起動してプロファイリング結果を可視化 65 $ docker run --gpus all --rm -it --privileged --shm-size=1024m cuda-galactic:root nvprof --analysis-metrics -o amcl_cuda.nvvp ¥ ../install/nav2_amcl/lib/nav2_amcl/amcl --ros-args [params] sudo /usr/local/cuda/bin/nvvp ¥ -vm /usr/lib/jvm/java-8-openjdk-amd64/bin/java amcl_cuda.nvvp
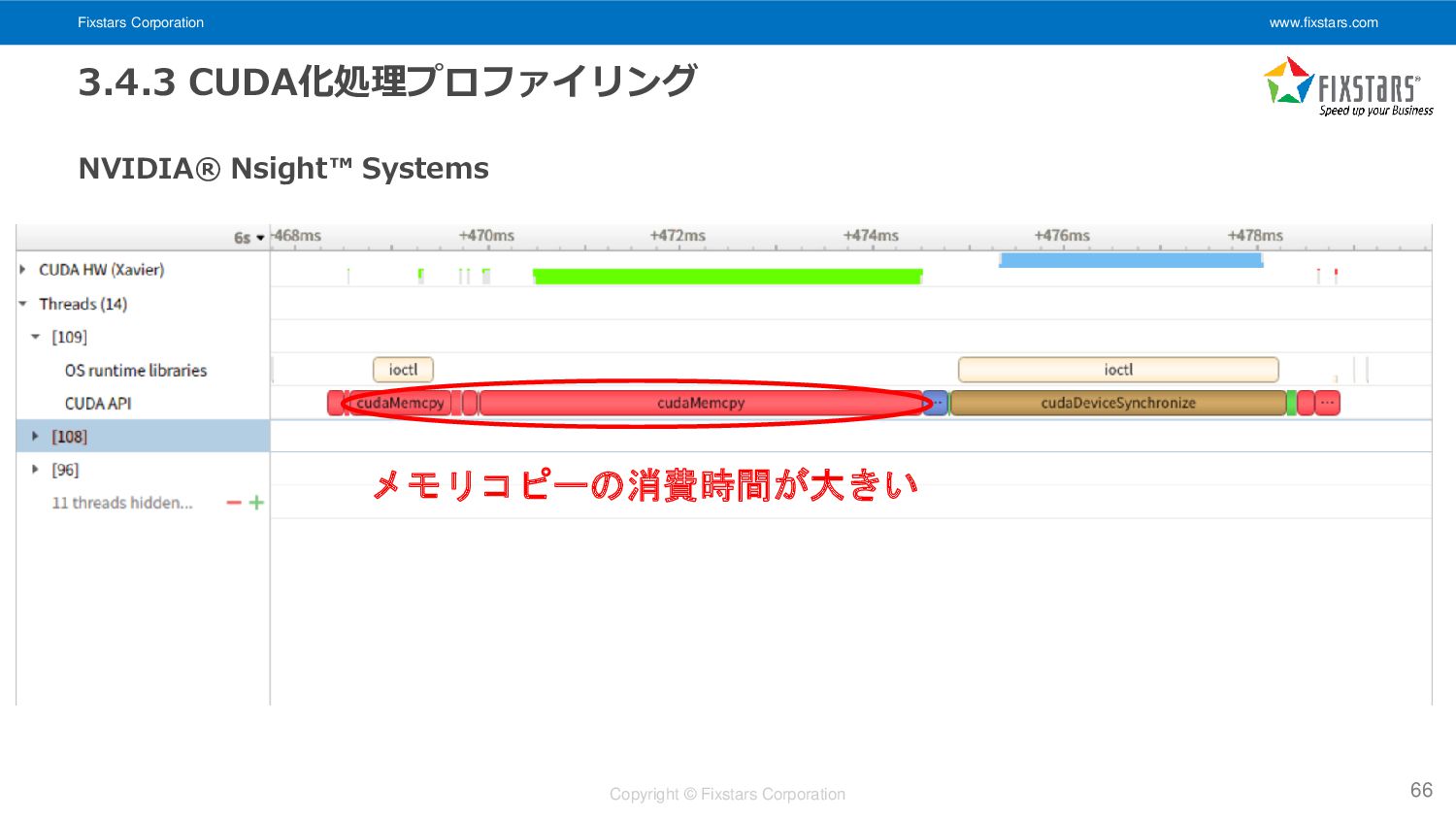
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.4.3 CUDA化処理プロファイリング 66
NVIDIA® Nsight™ Systems メモリコピーの消費時間が大きい
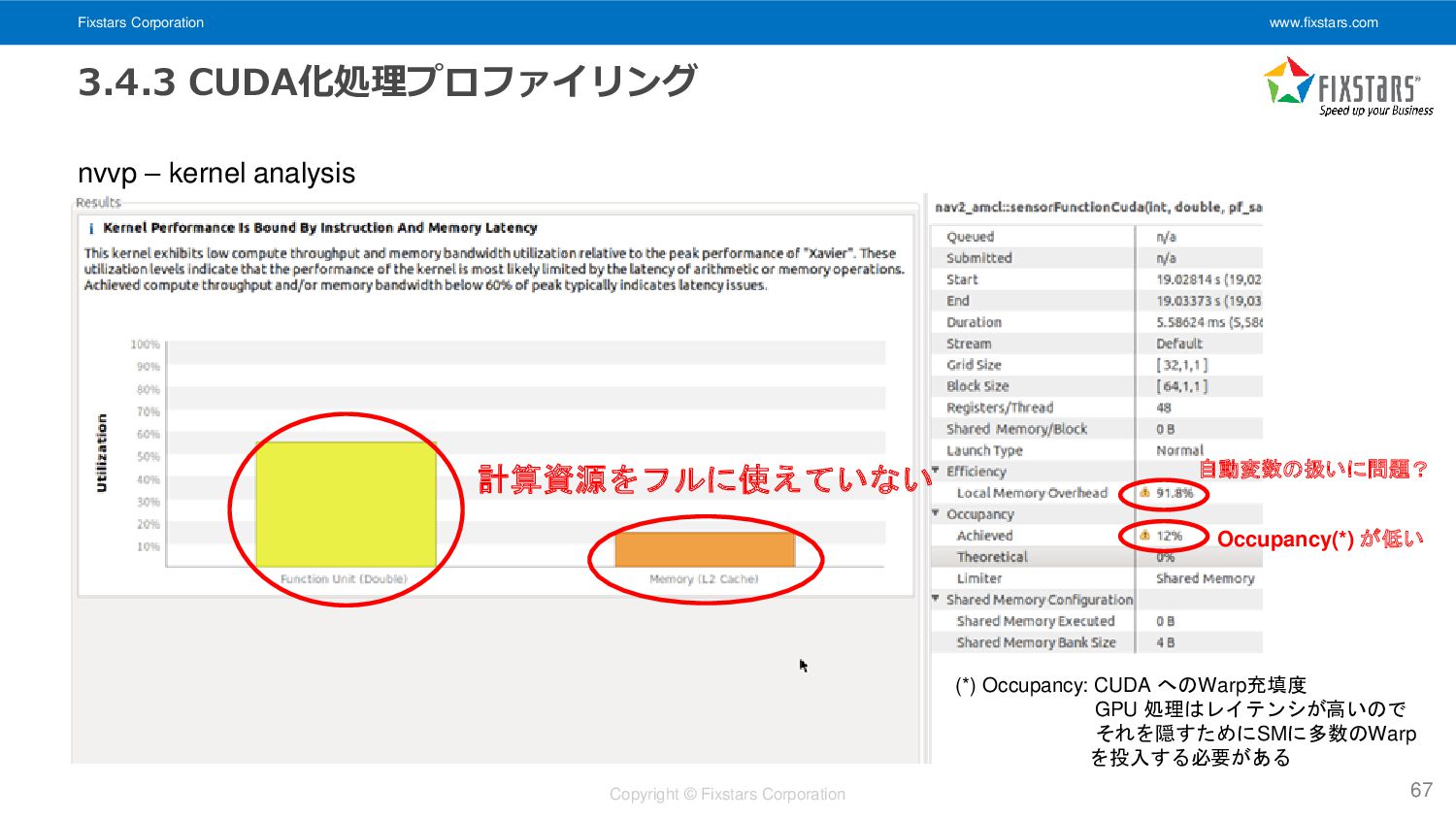
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.4.3 CUDA化処理プロファイリング 67
nvvp – kernel analysis 自動変数の扱いに問題? Occupancy(*) が低い 計算資源をフルに使えていない (*) Occupancy: CUDA へのWarp充填度 GPU 処理はレイテンシが高いので それを隠すためにSMに多数のWarp を投入する必要がある
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.4.3 CUDA化処理プロファイリング 68
nvvp – latency analysis nvvp – compute analysis Divergence に問題を抱えたコードが存在 Divergence(*) に問題を抱えた箇所がある パーティクル数が1280以下だと SM を全部(20 個)使い切らない (*) Divergence: 命令を実行したスレッドの割合。条件分岐があると一部のスレッドしか 実行を行わないことがあり、実行を行わないスレッドが多いほどこの値が低くなる
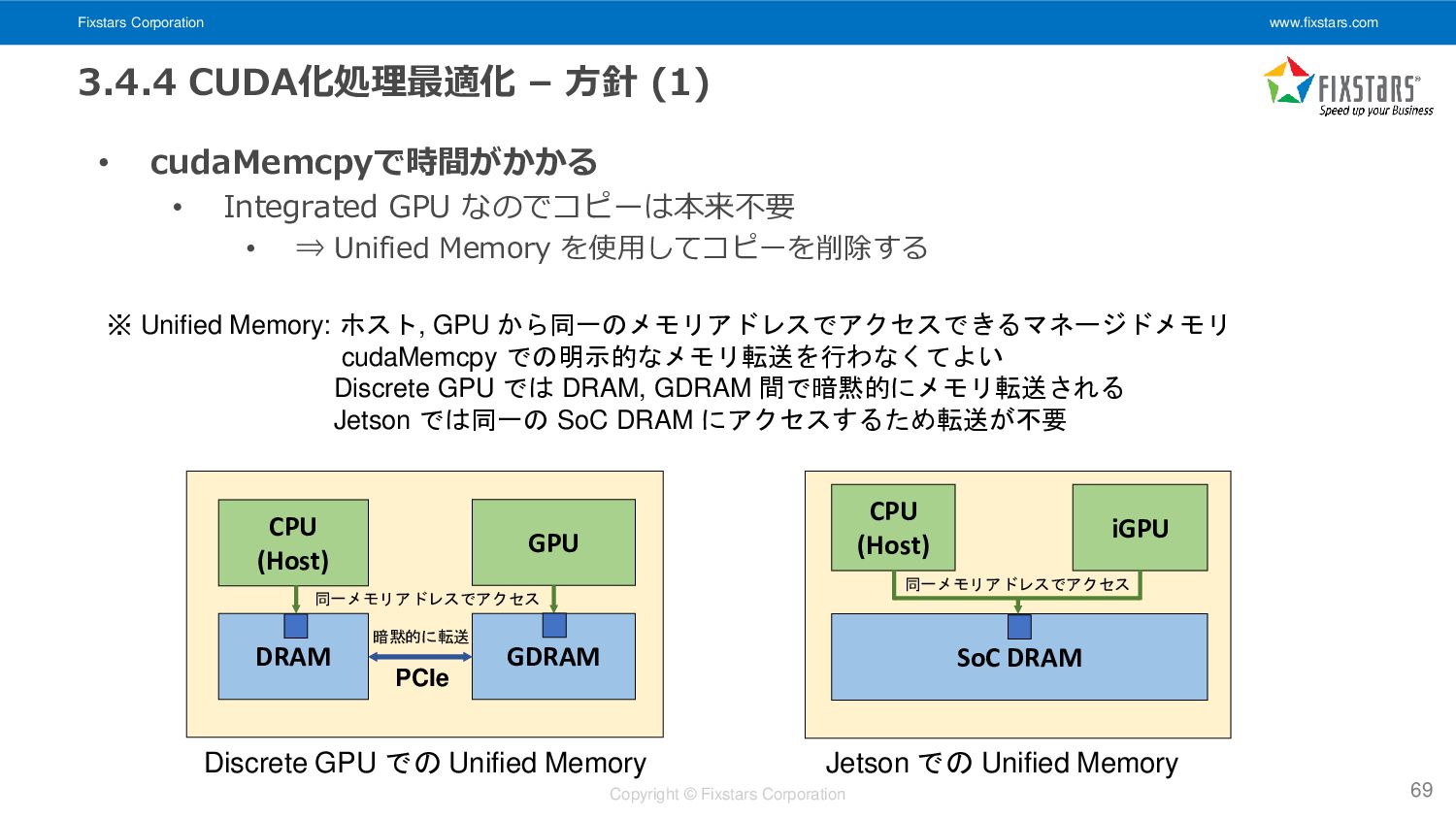
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation • cudaMemcpyで時間がかかる •
Integrated GPU なのでコピーは本来不要 • ⇒ Unified Memory を使用してコピーを削除する 3.4.4 CUDA化処理最適化 – 方針 (1) 69 CPU (Host) GPU DRAM GDRAM PCIe CPU (Host) iGPU SoC DRAM Jetson での Unified Memory Discrete GPU での Unified Memory ※ Unified Memory: ホスト, GPU から同一のメモリアドレスでアクセスできるマネージドメモリ cudaMemcpy での明示的なメモリ転送を行わなくてよい Discrete GPU では DRAM, GDRAM 間で暗黙的にメモリ転送される Jetson では同一の SoC DRAM にアクセスするため転送が不要 暗黙的に転送 同一メモリアドレスでアクセス 同一メモリアドレスでアクセス
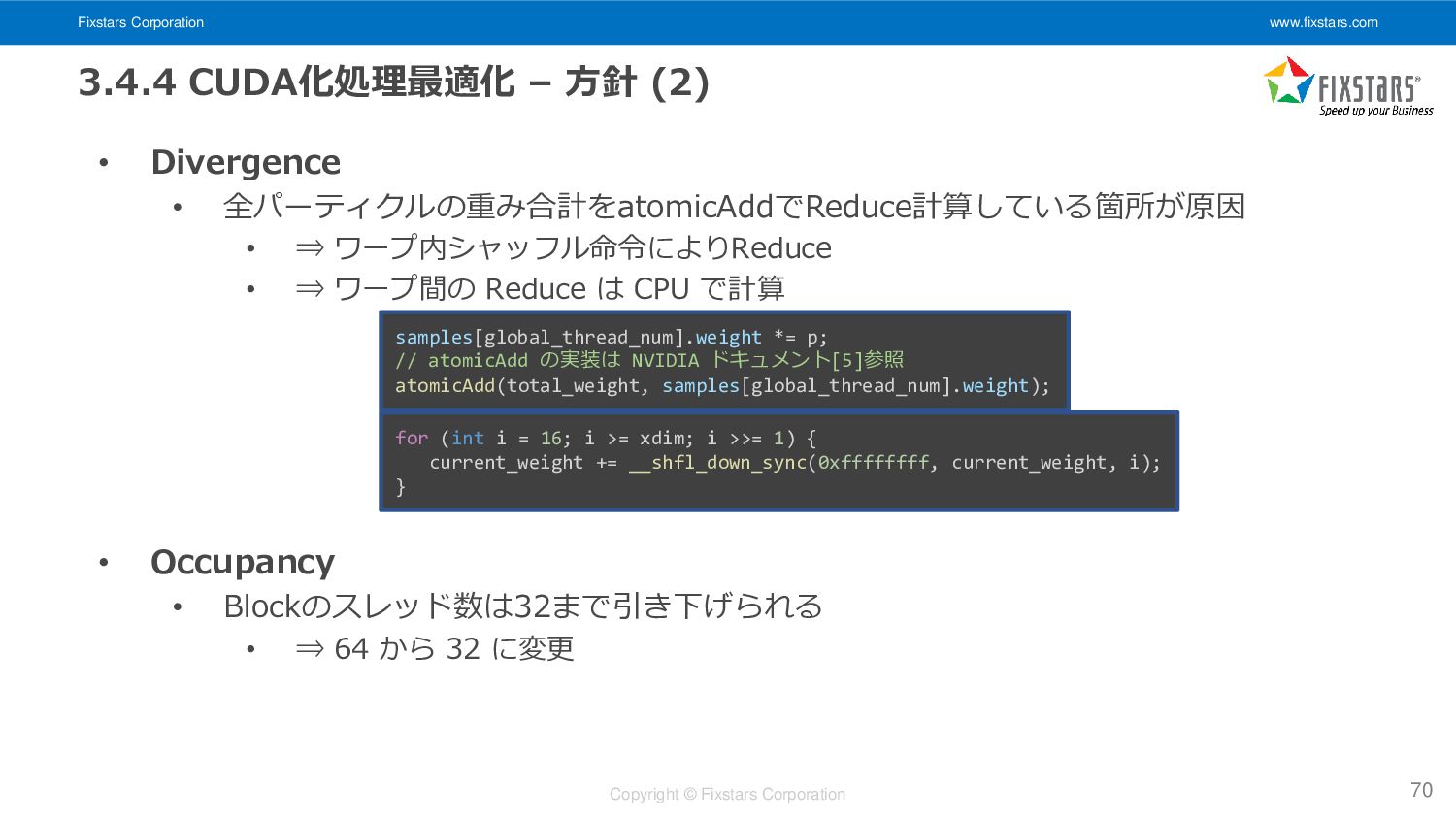
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.4.4 CUDA化処理最適化 –
方針 (2) • Divergence • 全パーティクルの重み合計をatomicAddでReduce計算している箇所が原因 • ⇒ ワープ内シャッフル命令によりReduce • ⇒ ワープ間の Reduce は CPU で計算 • Occupancy • Blockのスレッド数は32まで引き下げられる • ⇒ 64 から 32 に変更 70 samples[global_thread_num].weight *= p; // atomicAdd の実装は NVIDIA ドキュメント[5]参照 atomicAdd(total_weight, samples[global_thread_num].weight); for (int i = 16; i >= xdim; i >>= 1) { current_weight += __shfl_down_sync(0xffffffff, current_weight, i); }
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.4.4 CUDA化処理最適化 –
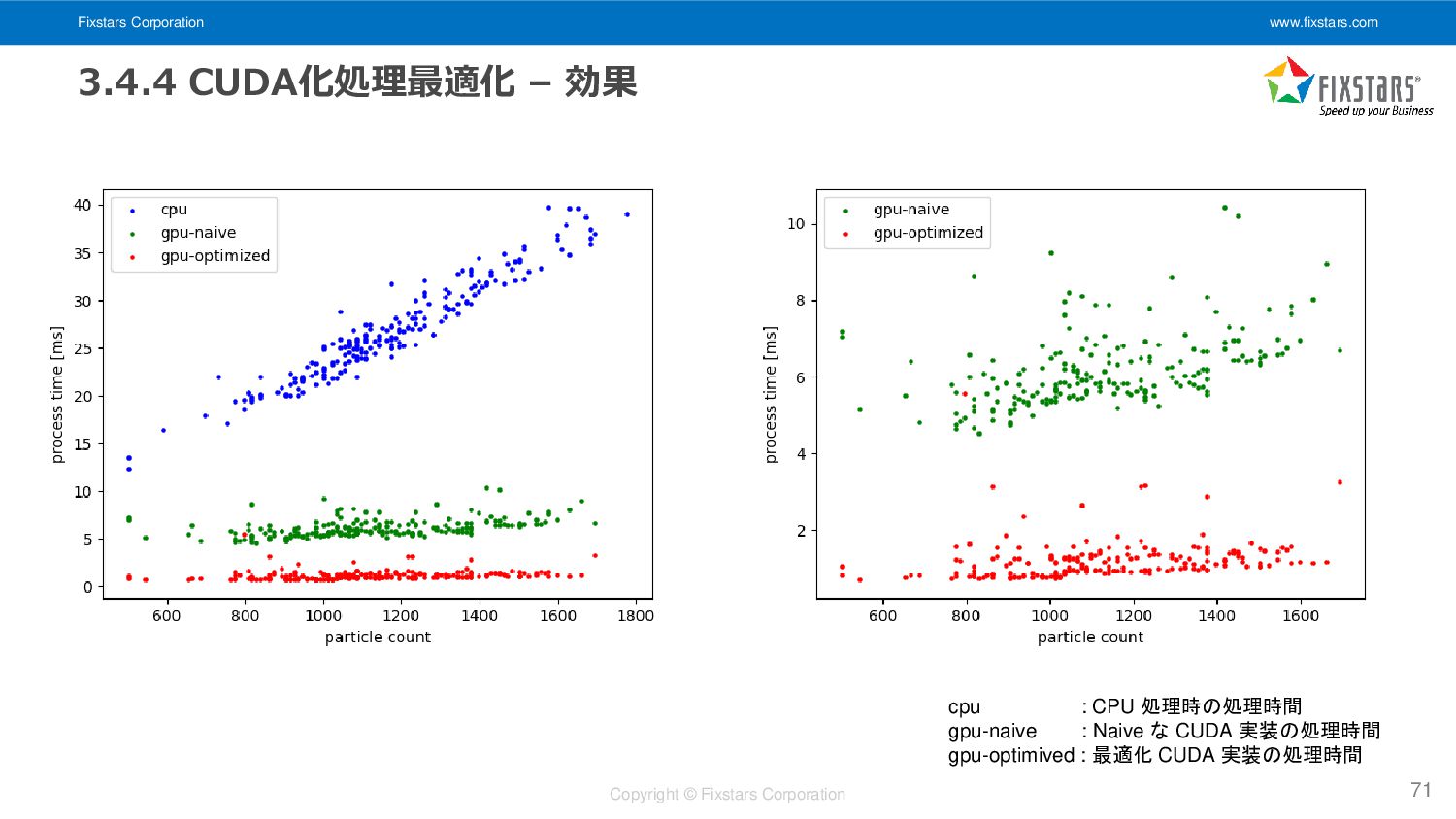
効果 71 cpu : CPU 処理時の処理時間 gpu-naive : Naive な CUDA 実装の処理時間 gpu-optimived : 最適化 CUDA 実装の処理時間
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.4.4 CUDA化処理最適化 –
プロファイリング 72 NVIDIA® Nsight™ Systems cudaMemcpy は消えている CUDAカーネルの実行時間も短い
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.4.4 CUDA化処理最適化 –
プロファイリング 73 nvvp – kernel analysis 演算ユニットはほぼ使い切っている メモリ帯域はまだまだ空きがある メモリの使用効率はよくない Occupancy は低いが 演算ユニットを使い切っているので 影響は低い
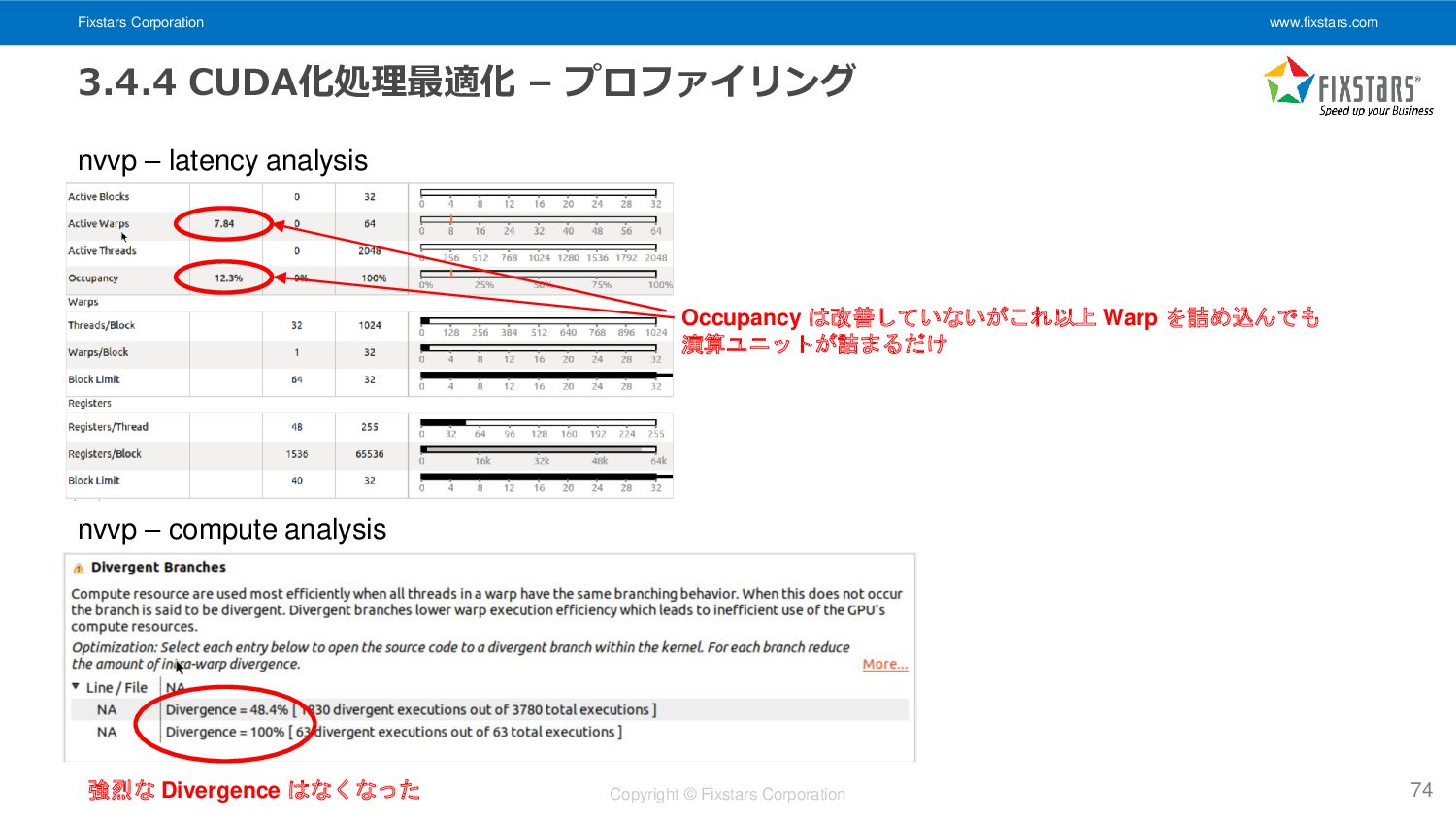
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.4.4 CUDA化処理最適化 –
プロファイリング 74 nvvp – compute analysis 強烈な Divergence はなくなった nvvp – latency analysis Occupancy は改善していないがこれ以上 Warp を詰め込んでも 演算ユニットが詰まるだけ
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.4.4 CUDA処理最適化 –
さらなる検討 • 演算ユニットの負荷削減 • ⇒ 演算強度を軽減する (double -> float) • Occupancy改善 • ⇒ 内側のループ (各パーティクル内の処理) も並列処理する • メモリ使用効率、Divergence軽減 • ランダムアクセスが必要なアルゴリズムのため難度が高い ただし他の処理と比較して十分高速なため、これ以上の最適化は効果が薄い 75
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 3.4.5 Jetson上における性能測定の留意点 •
Jetsonにはいくつかの性能モードがあるので測定時には性能モードをあわせる • 下記例ではモード3 (30W、8 CPU) • CPU/GPU動作周波数を固定する • デフォルトだと、処理負荷、CPU温度に応じて動的に動作周波数が変わり、処理時間 がばらつく • jetson_clocksコマンドで動作周波数を固定する • 同時にファンも最大まで回しておく 参考 : NVIDIA 公式ドキュメント 76 $ sudo /usr/bin/jetson_clocks --fan $ sudo /usr/sbin/nvpmodel -m 3
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 4 今後の課題 •
メカナムローバーでの ROS2 navigationによる自律走行 • amcl高速化によるnavigationへの効果測定 • navigation2内の他パッケージのCUDA高速化 • amclのさらなるCUDA高速化 • オドメトリ更新 • リサンプリング (KD木構築のCUDA化が必要) 77
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation Copyright © Fixstars
Corporation Q&A time
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation フィックスターズでは仲間を募集しています! さまざまな専門性を持つエンジニアを募集しています 詳細は
https://www.fixstars.com/ja/recruit/ まで 79
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation Thank You お問い合わせ窓口
:
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}