Engineer @ Databricks: Data and AI • My past: large scale data & compute • Based in 🍻 ⛰ 🥨 • Built up AWS Tech Evangelism in Central Europe • SW architect, data scientist, published author etc.
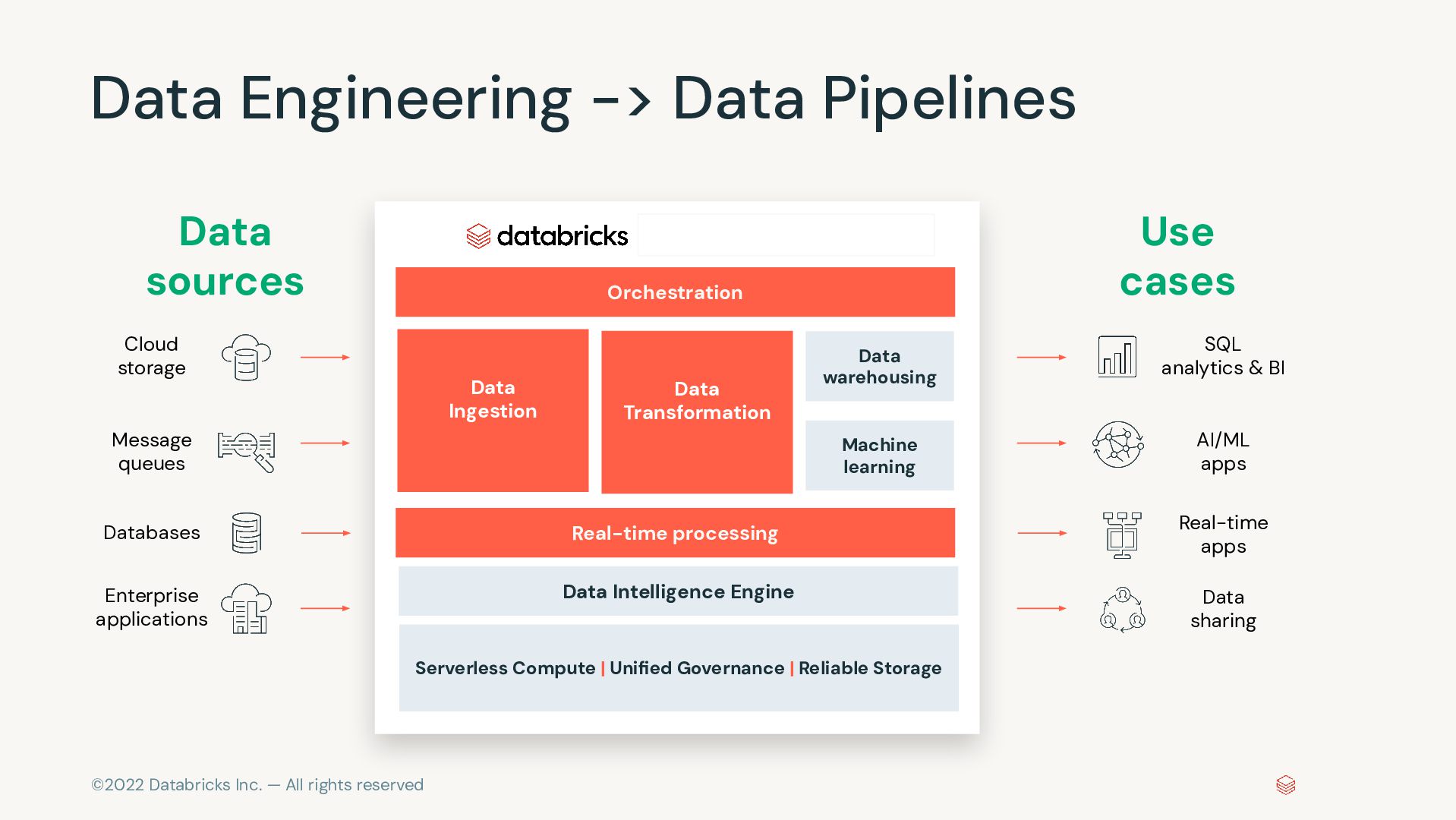
Data Pipelines Data Intelligence Platform Orchestration Data Ingestion Data sources Cloud storage Message queues Databases Enterprise applications Serverless Compute | Unified Governance | Reliable Storage Use cases SQL analytics & BI AI/ML apps Real-time apps Data sharing Data warehousing Machine learning Real-time processing Data Transformation Data Intelligence Engine
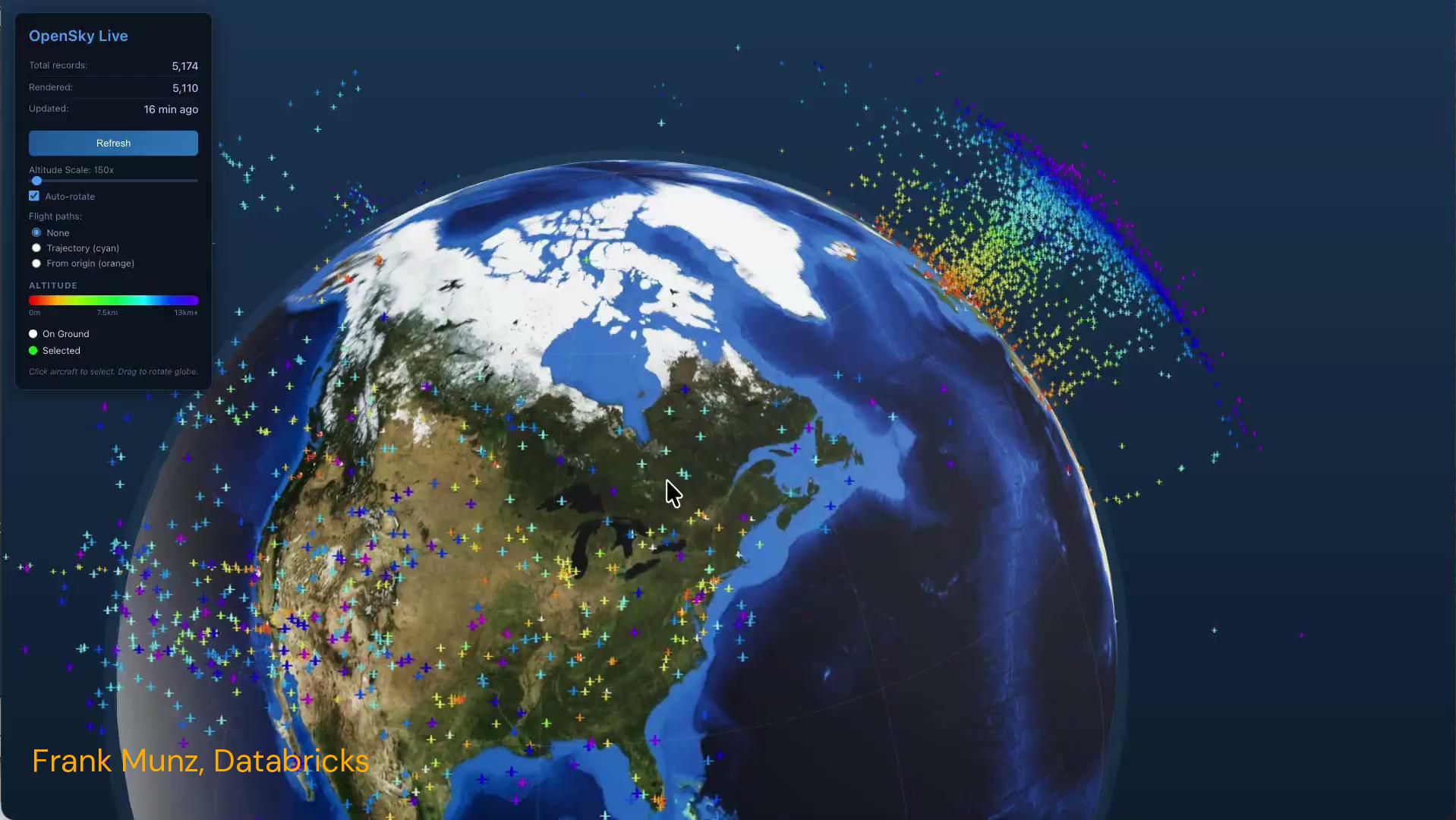
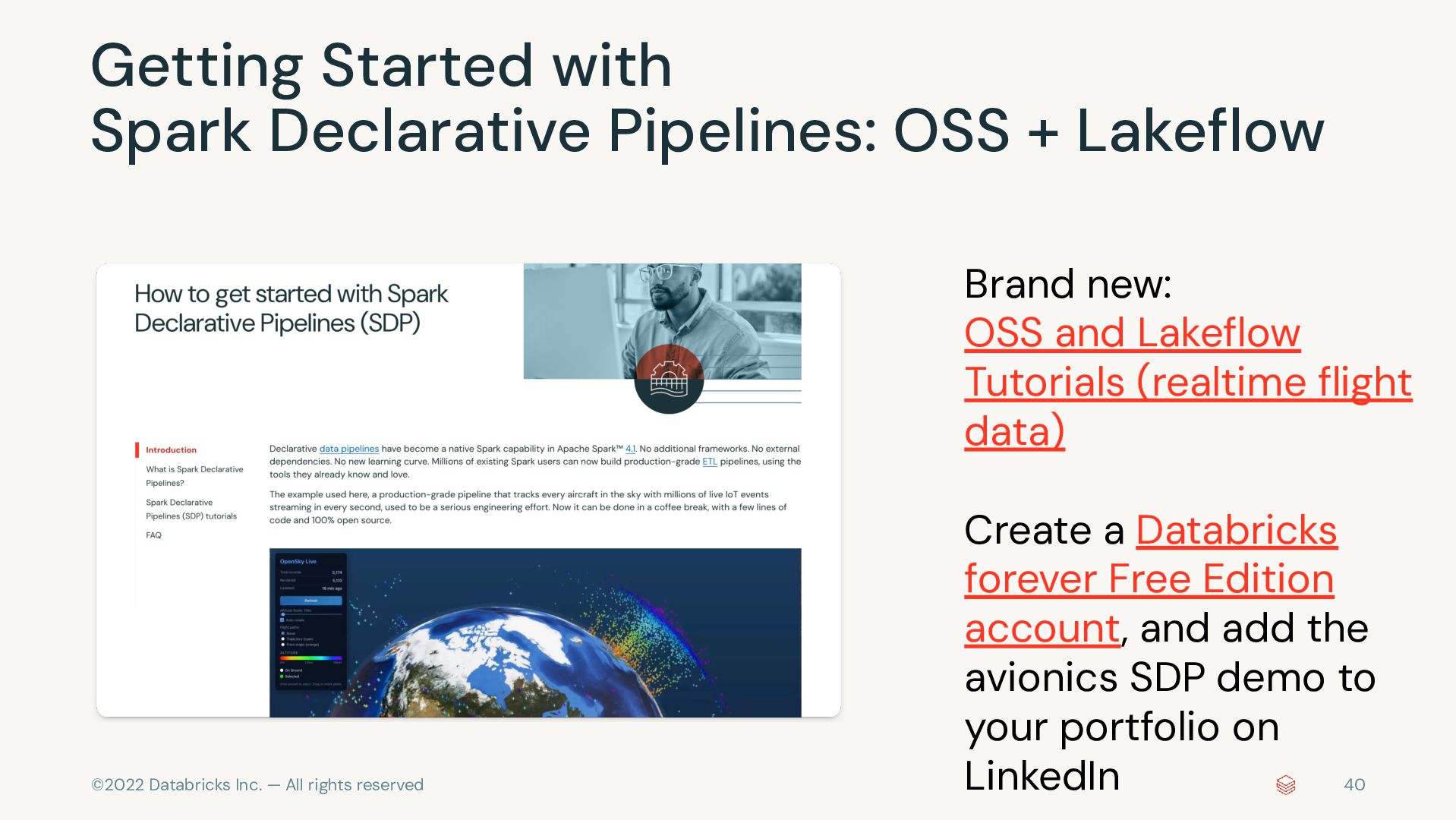
with Spark Declarative Pipelines: OSS + Lakeflow Brand new: OSS and Lakeflow Tutorials (realtime flight data) Create a Databricks forever Free Edition account, and add the avionics SDP demo to your portfolio on LinkedIn
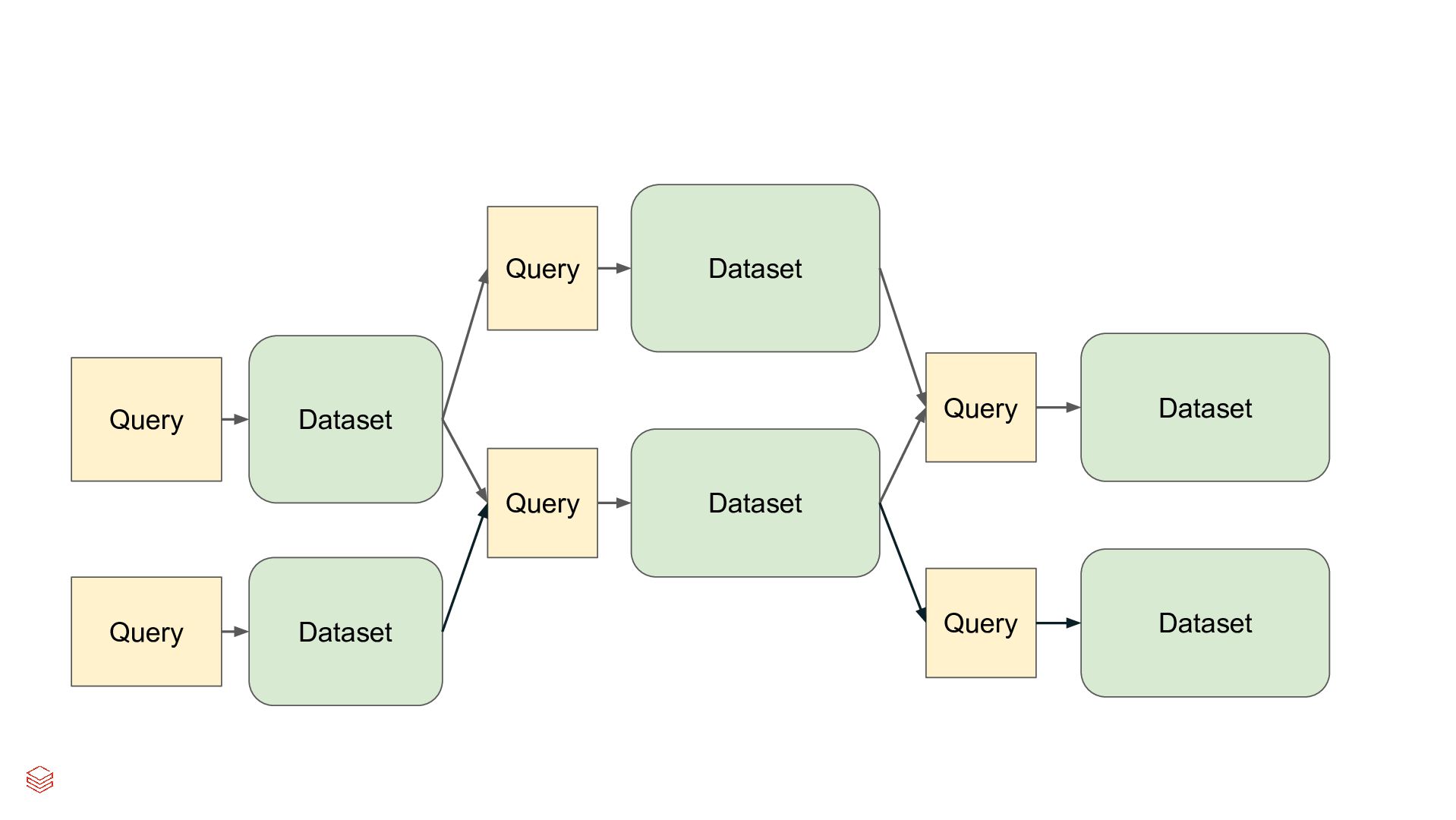
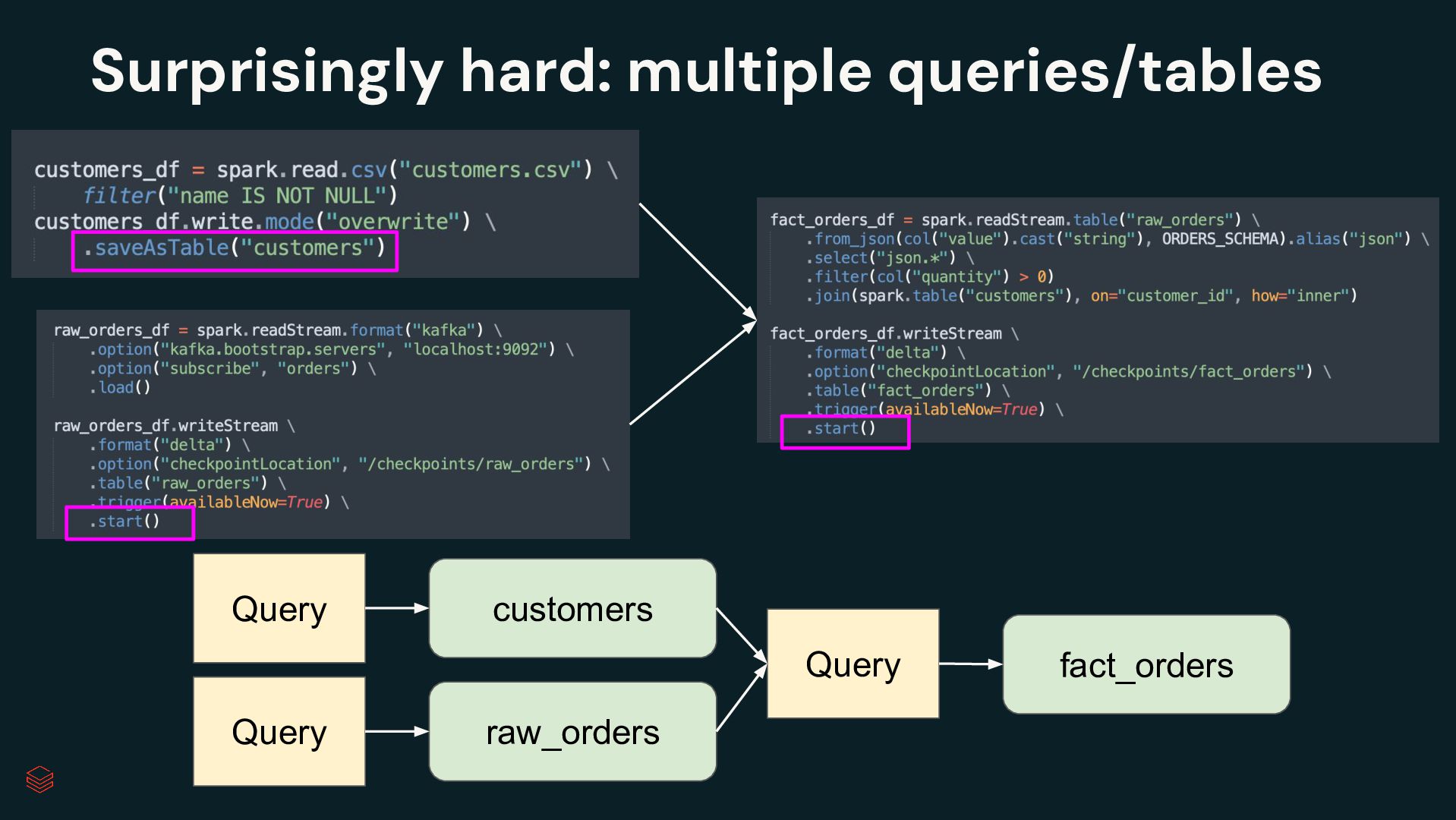
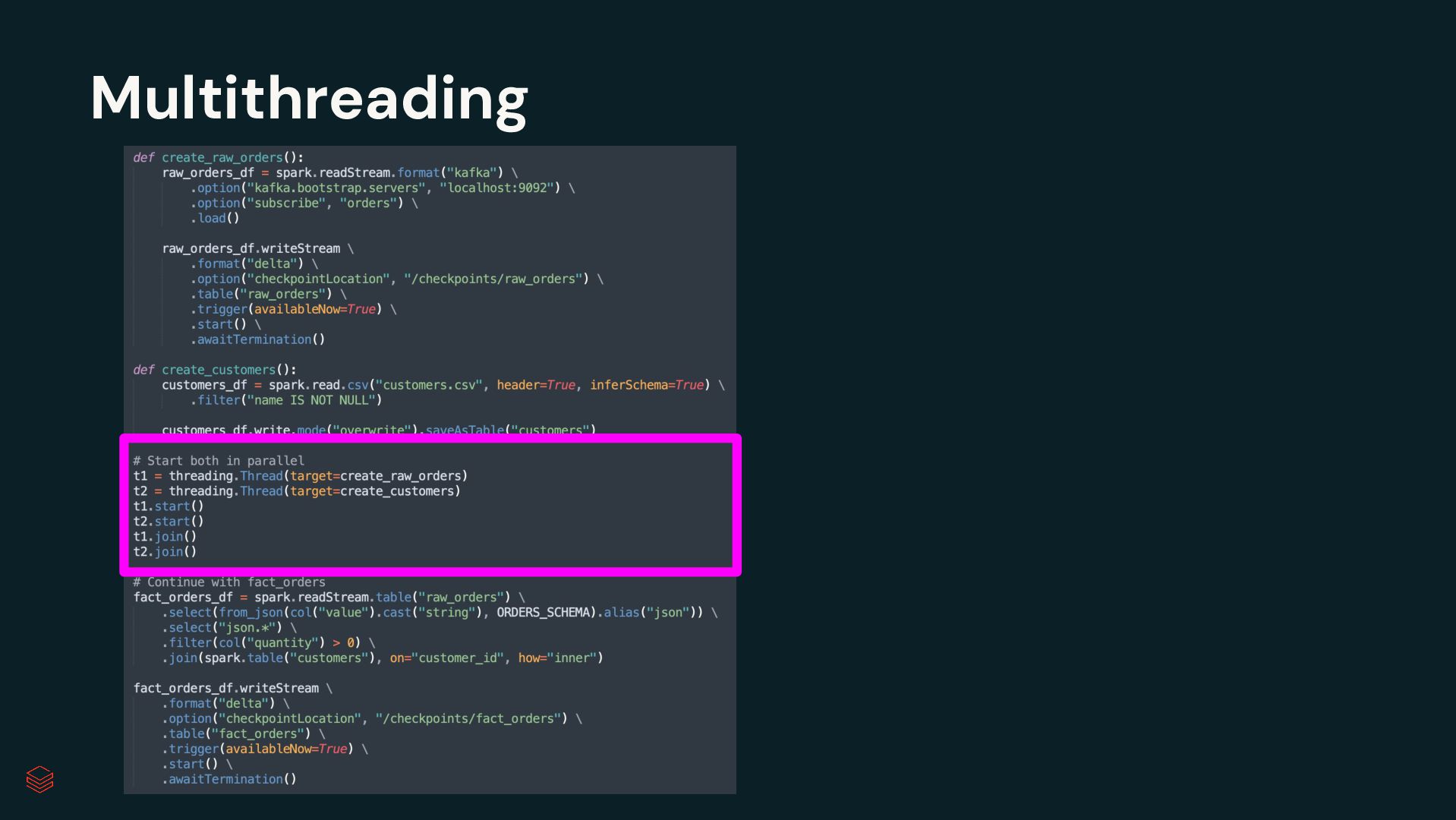
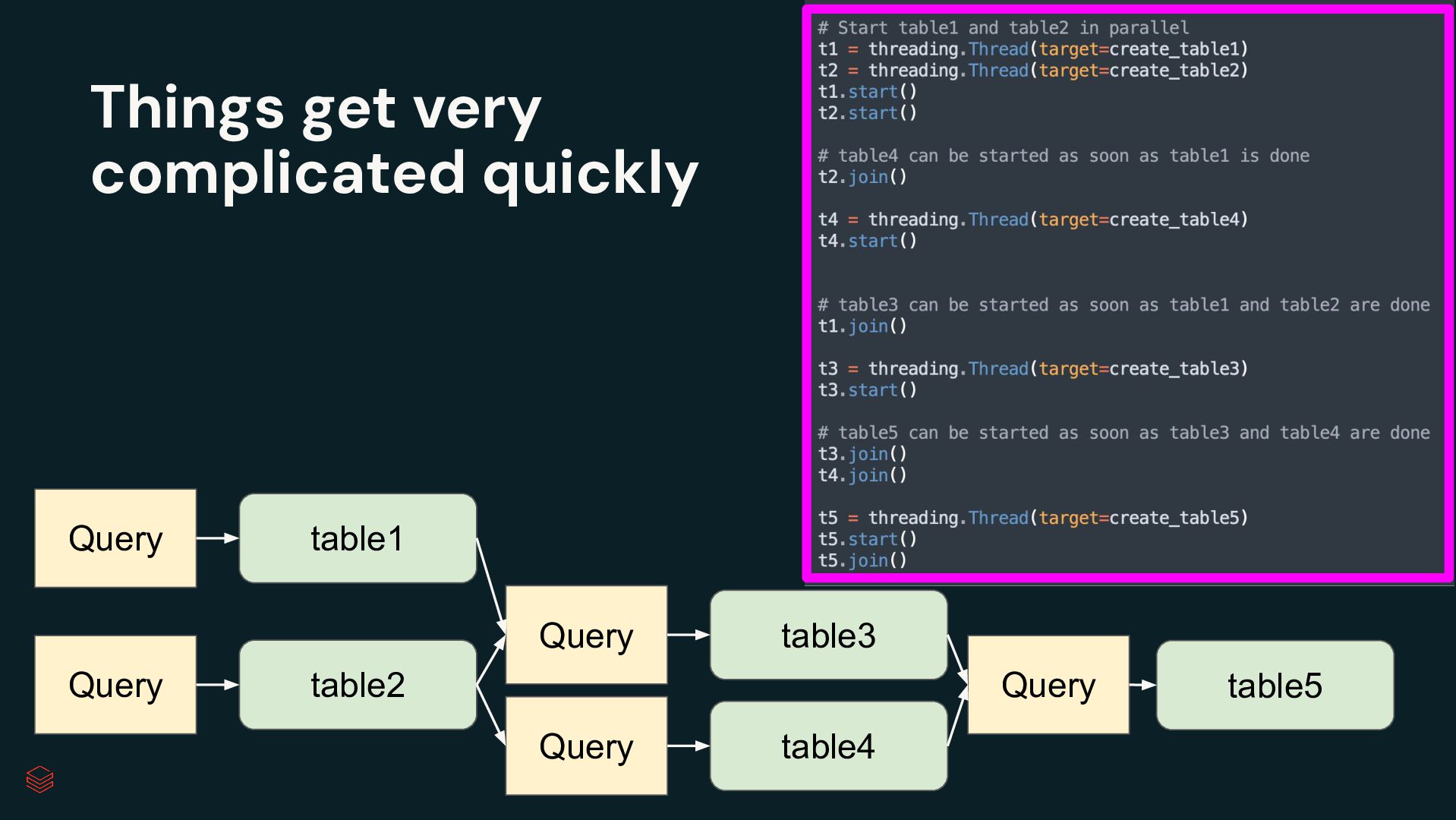
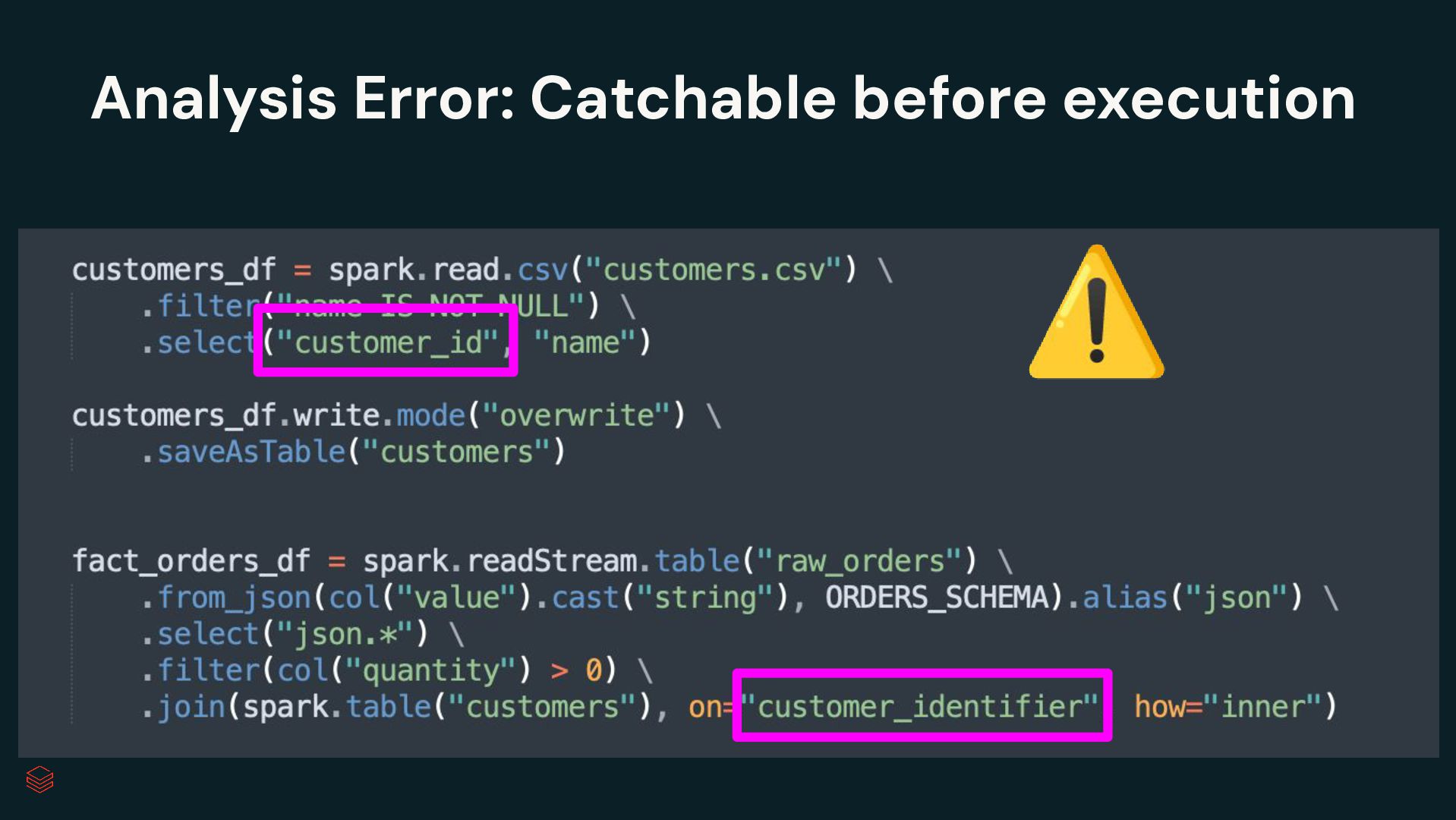
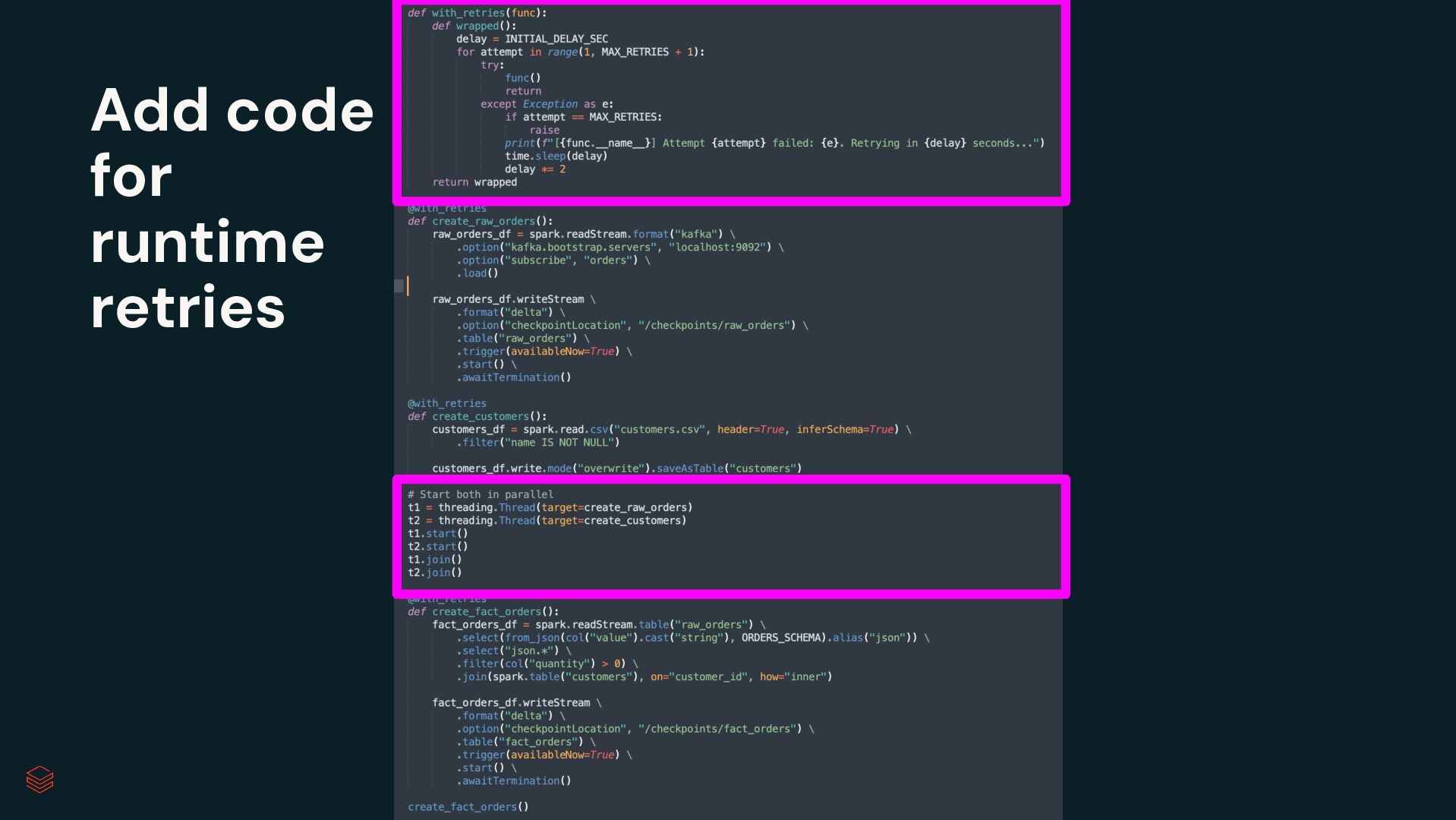
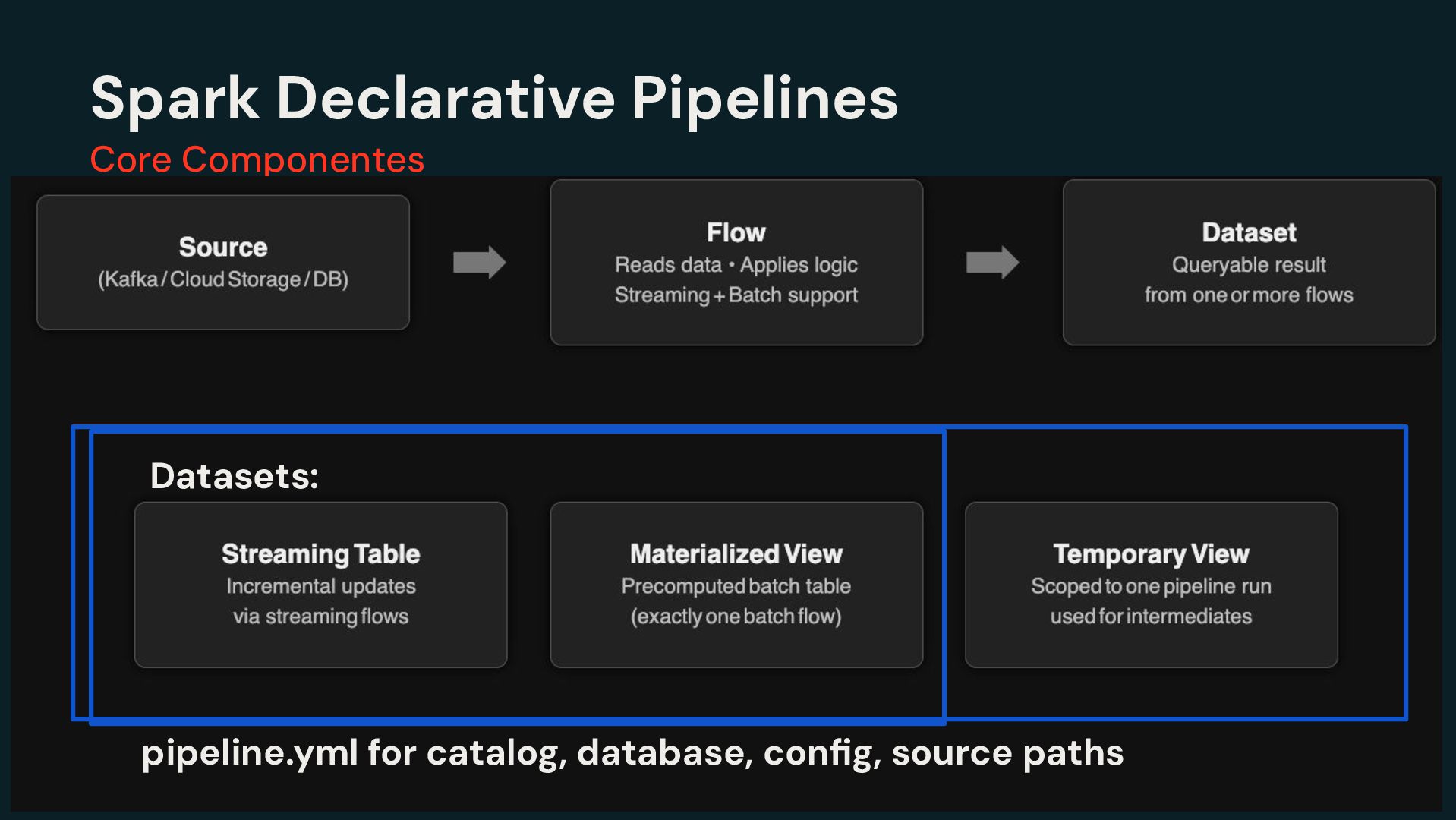
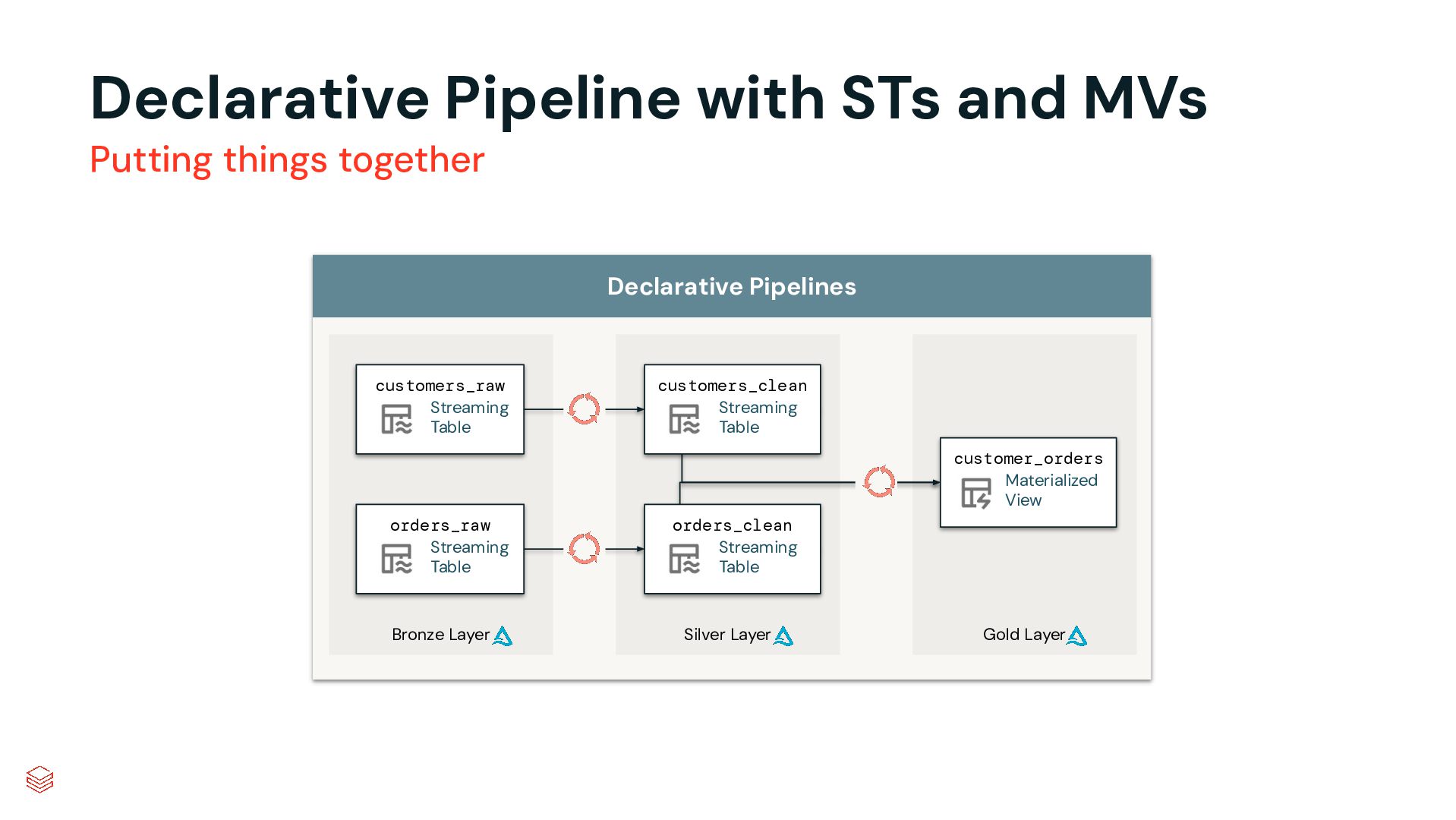
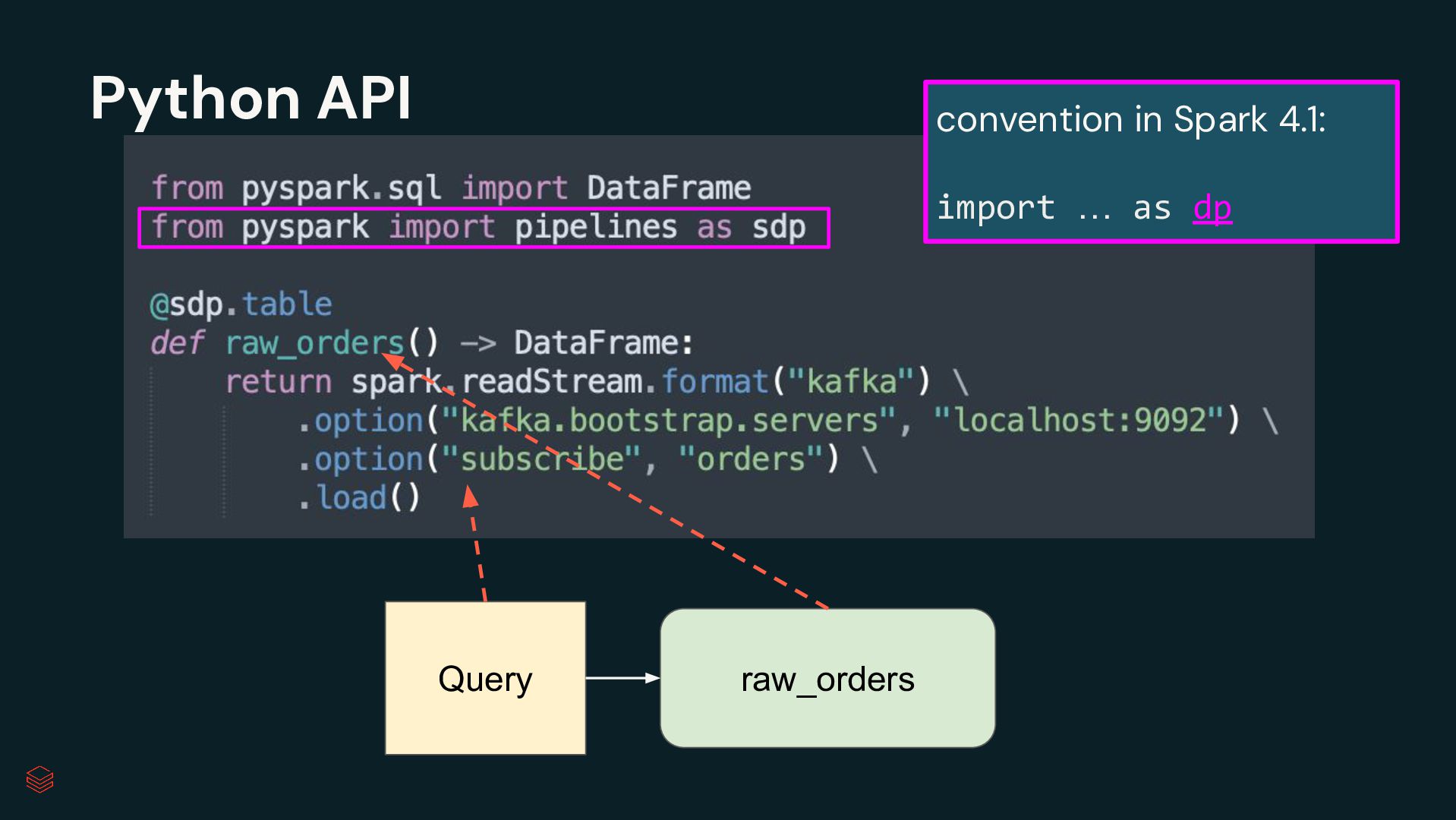
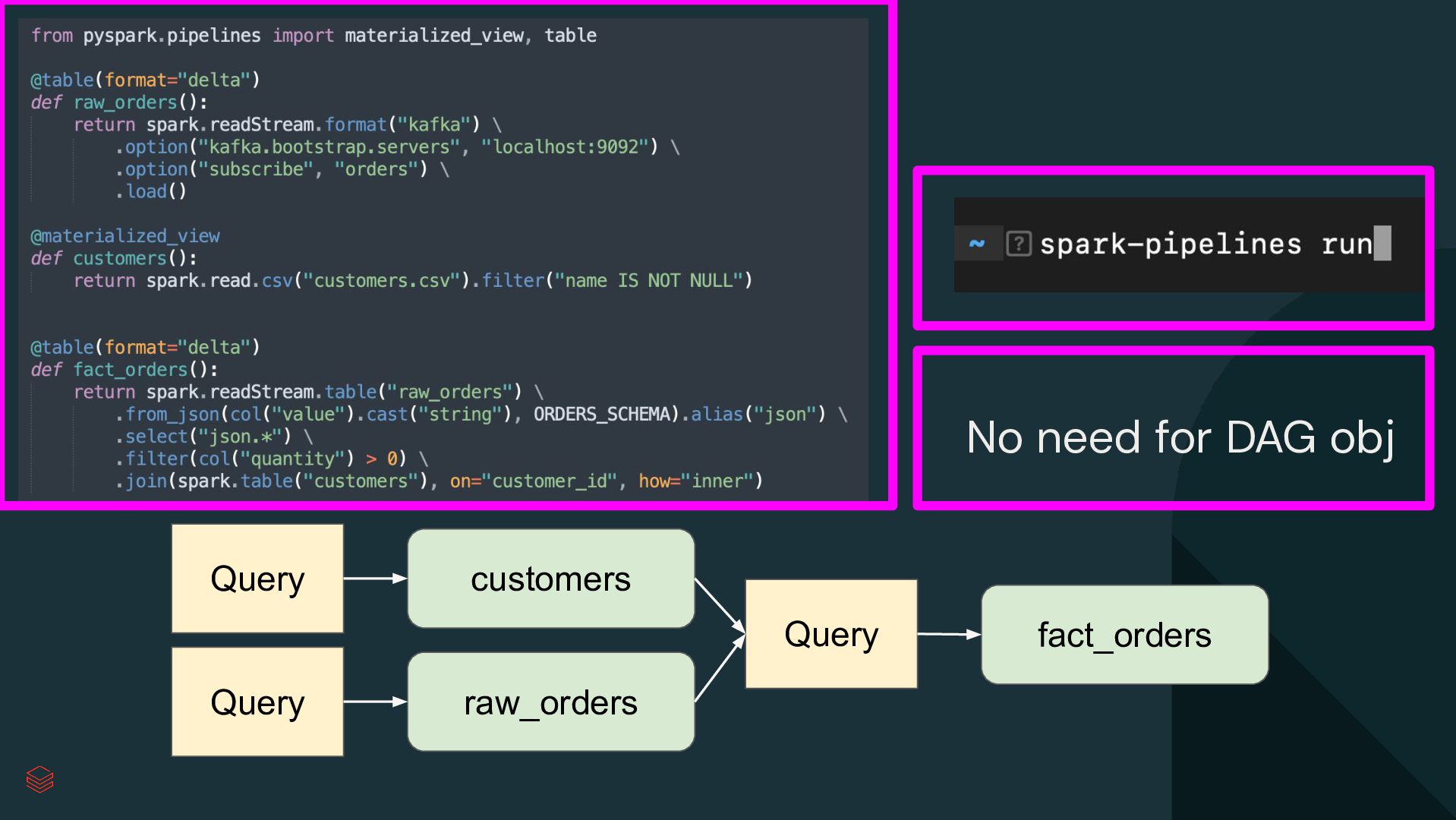
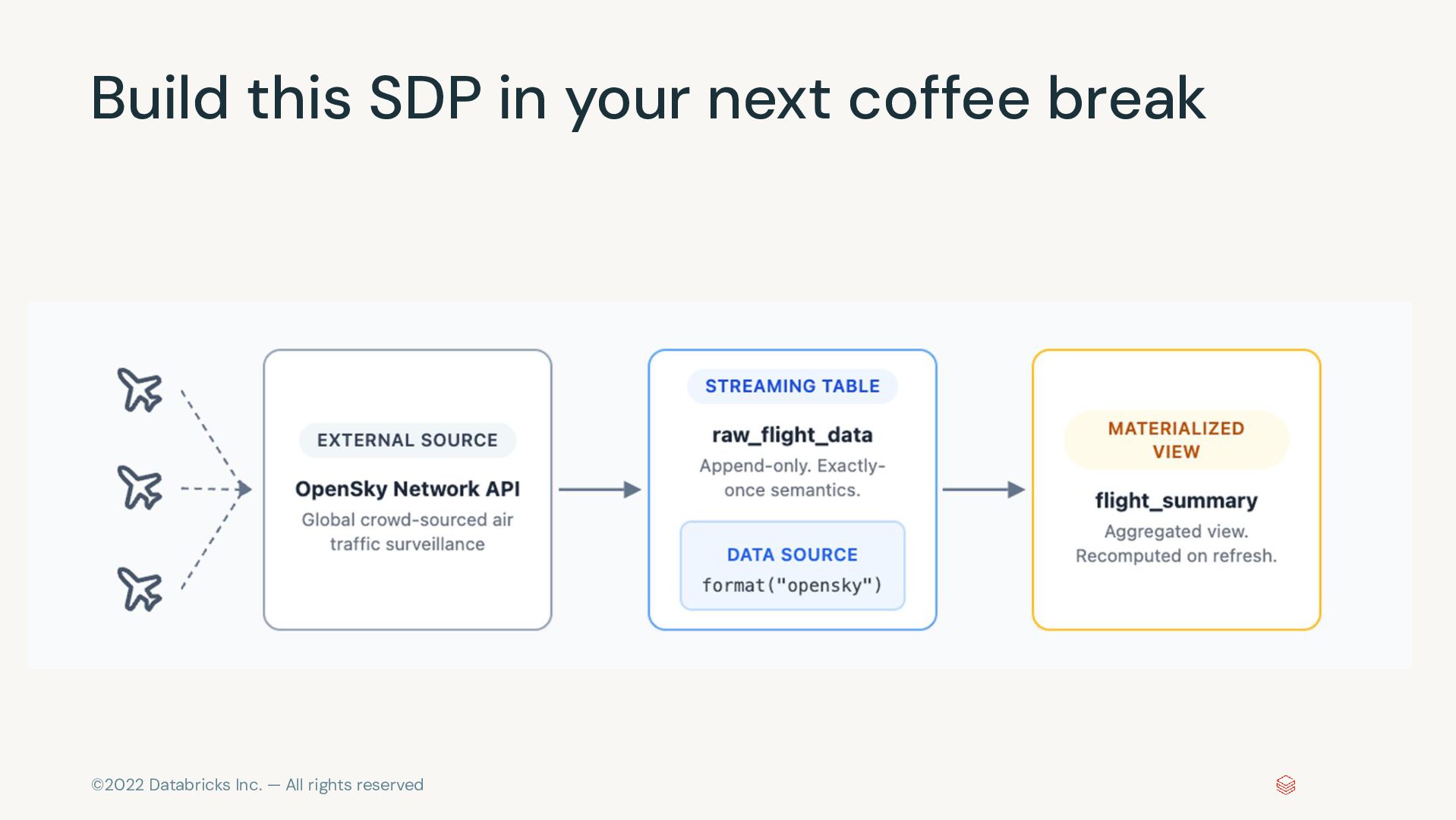
Pipelines Efficiently clean, transform and join data Build batch and streaming pipelines with a declarative approach Automated pipeline configuration with reduces maintenance burden Simplified pipeline development Reliable production infrastructure Fully compatible with the open source Spark Declarative Pipelines Built on an open standard
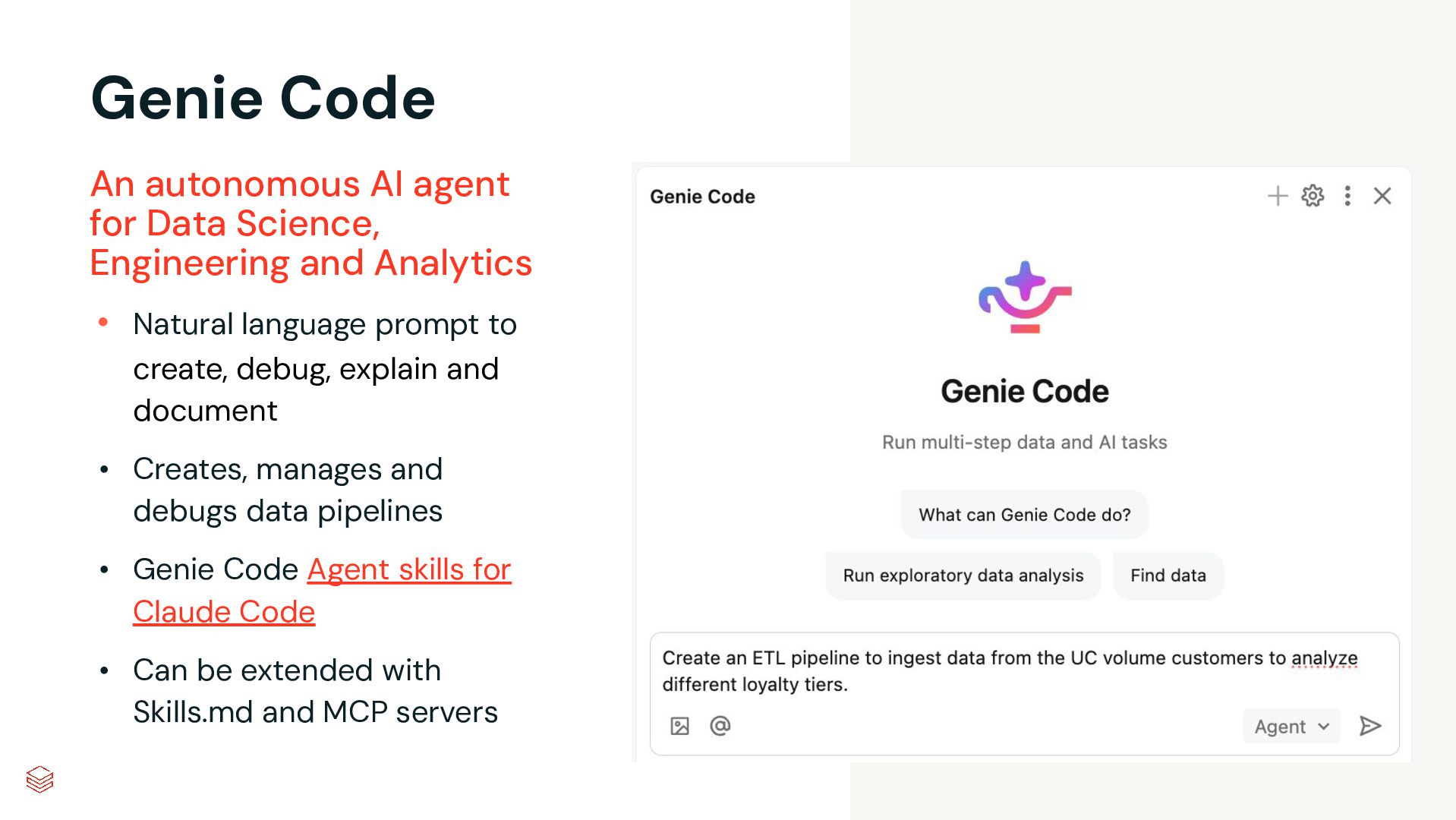
and document • Creates, manages and debugs data pipelines • Genie Code Agent skills for Claude Code • Can be extended with Skills.md and MCP servers An autonomous AI agent for Data Science, Engineering and Analytics
video demo: Use Genie Code to create a complete SDP pipeline from a prompt. With Auto Loader, JSON ingestion, and medallion architecture. Genie Code Step by Step Guide
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
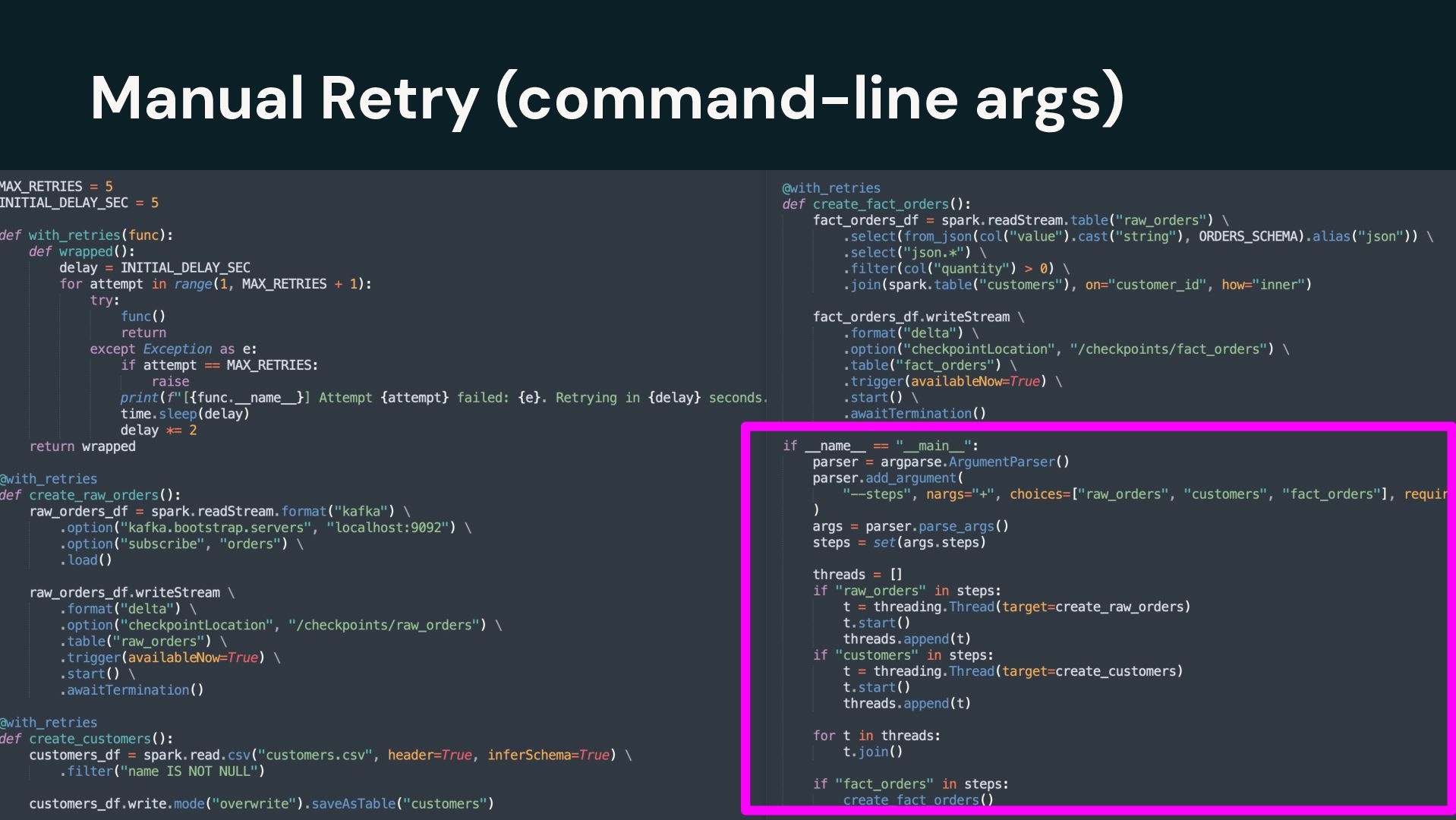{kind=link}
{kind=link}
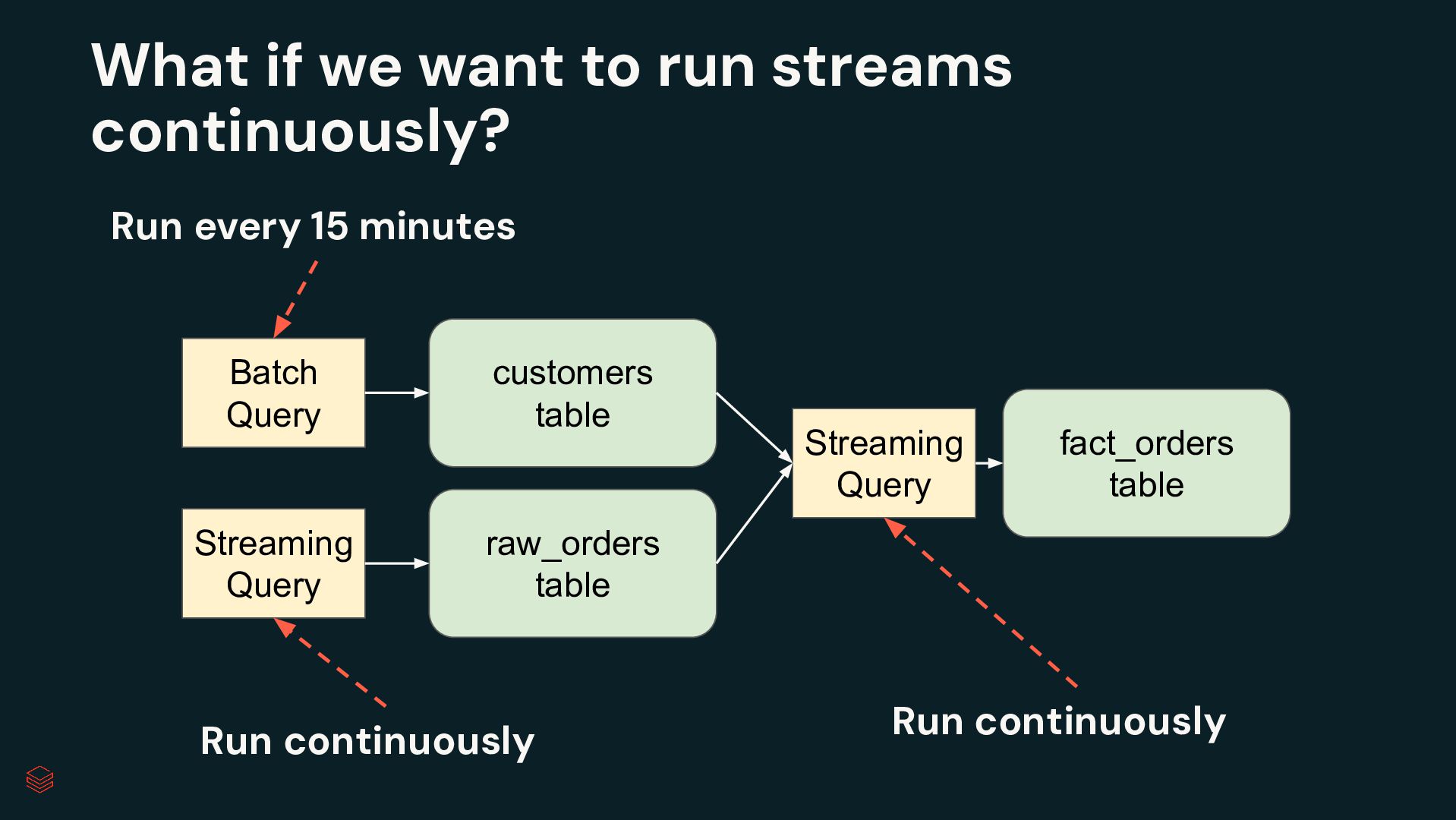{kind=link}
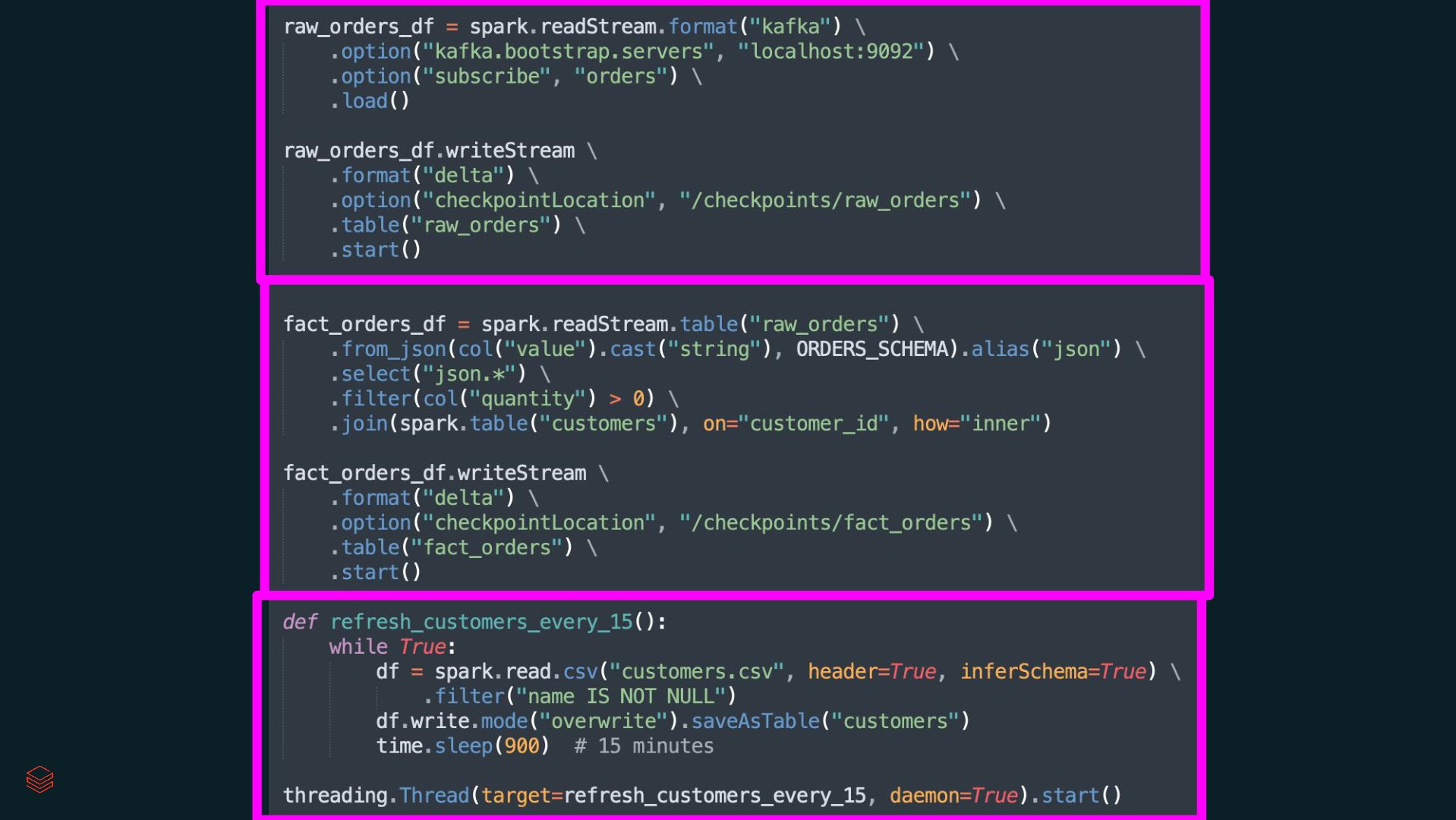{kind=link}
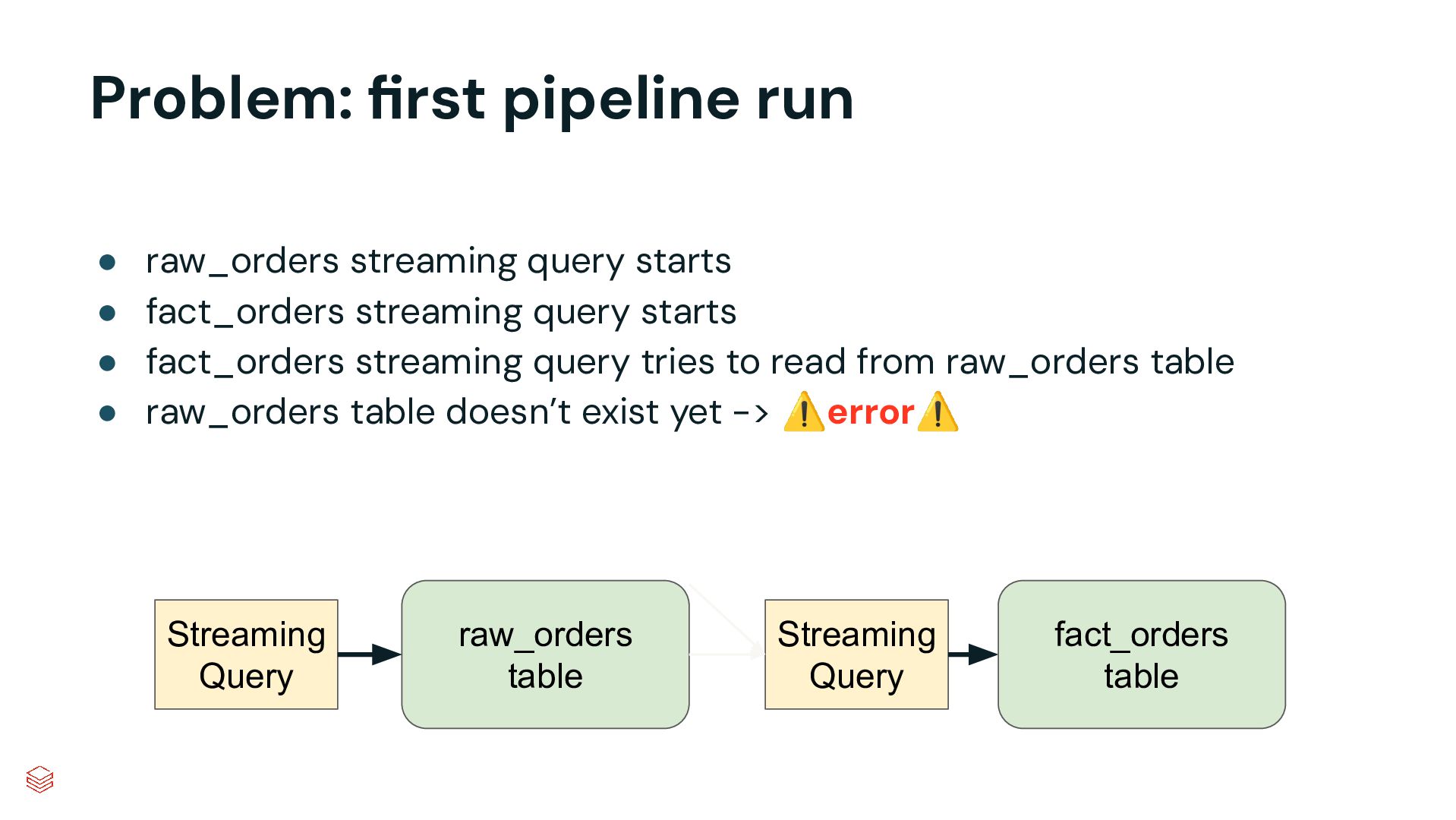{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}