For talk at Pittsburgh Tech Fest 2013.
Regular expressions are very commonly used to process and validate text data. Unfortunately, they suffer from various limitations. I will discuss the limitations and illustrate how using grammars instead can be an improvement. I will make the examples concrete using parsing libraries in a couple of representative languages, although the ideas are language-independent. (I'll try to squeeze in, say, Ruby, Python, JavaScript, Scala.)
I will emphasize ease of use, since one reason for the overuse of regular expressions is that they are so easy to pull out of one's toolbox.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Readability: second example /\A # match string begin [a-zA-Z]+ #](https://files.speakerdeck.com/presentations/a3510c40b0130130237876e801e6da2c/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
![Regexes do not report errors usefully Success: $ perl/extract_parts.pl ’[email protected]’](https://files.speakerdeck.com/presentations/a3510c40b0130130237876e801e6da2c/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Modularized regex: Scala object PrettyRegexMatcher { val user = """[a-zA-Z]+"""](https://files.speakerdeck.com/presentations/a3510c40b0130130237876e801e6da2c/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
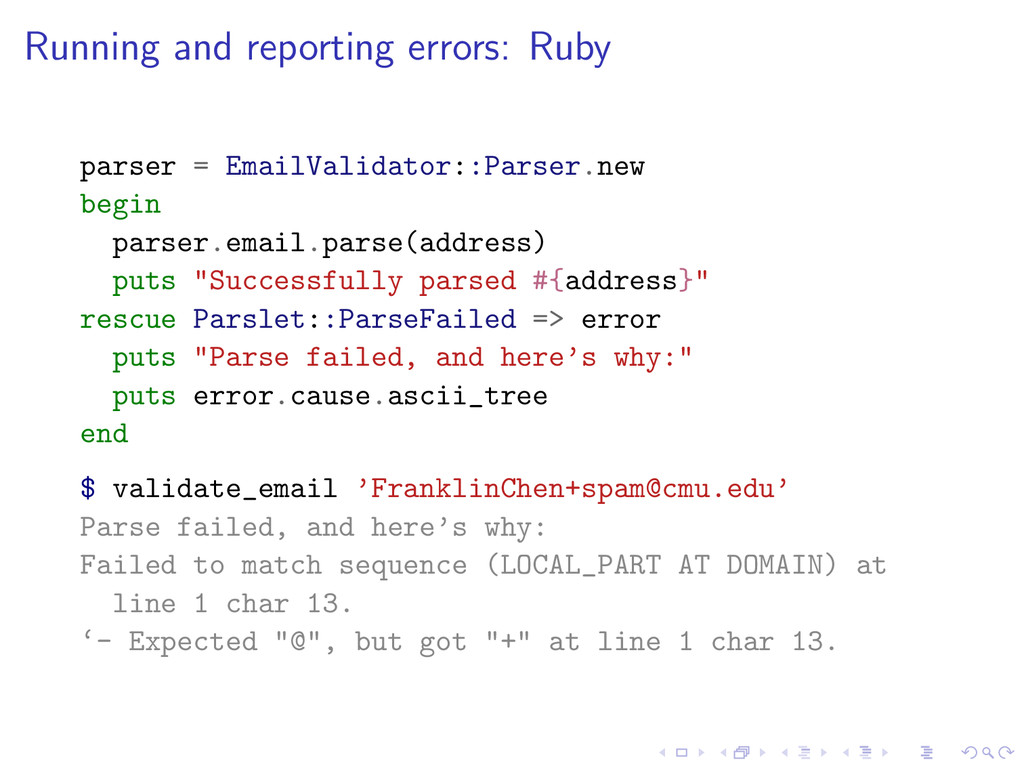{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Fancier toy JSON parser: Scala def value: Parser[ToyJSON] = obj](https://files.speakerdeck.com/presentations/a3510c40b0130130237876e801e6da2c/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}