CFML勉強会 #7(https://cfml.connpass.com/event/264017/) で発表した資料を公開します。
異質性を持った処置効果を推定する手法について、EconMLで実装されている手法を中心にまとめました。
EconMLに実装されていない手法にもいくつか触れています。Double Machine Learningについては、理論的背景まで含めて詳しめに説明しています。
過去に公開したこちらの資料をアップデートしたものになります。
https://speakerdeck.com/fullflu/heterogeneous-treatment-effect-estimation-using-econml-double-machine-learning-doubly-robust-learning-and-meta-learners
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![当日回答しきれなかった質問について [1] 勉強会当日の質疑で回答しきれなかった質問について、こちらで回答いたします • > DMLの g(x, w) は Y](https://files.speakerdeck.com/presentations/e539193ec6f44ffd8d4b152fa5e37e0e/slide_5.jpg){kind=link}
![当日回答しきれなかった質問について [2] 勉強会当日の質疑で回答しきれなかった質問について、こちらで回答いたします • > econml って実際に実務で用いられたことありますか? ◦ ないです!( EconML](https://files.speakerdeck.com/presentations/e539193ec6f44ffd8d4b152fa5e37e0e/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
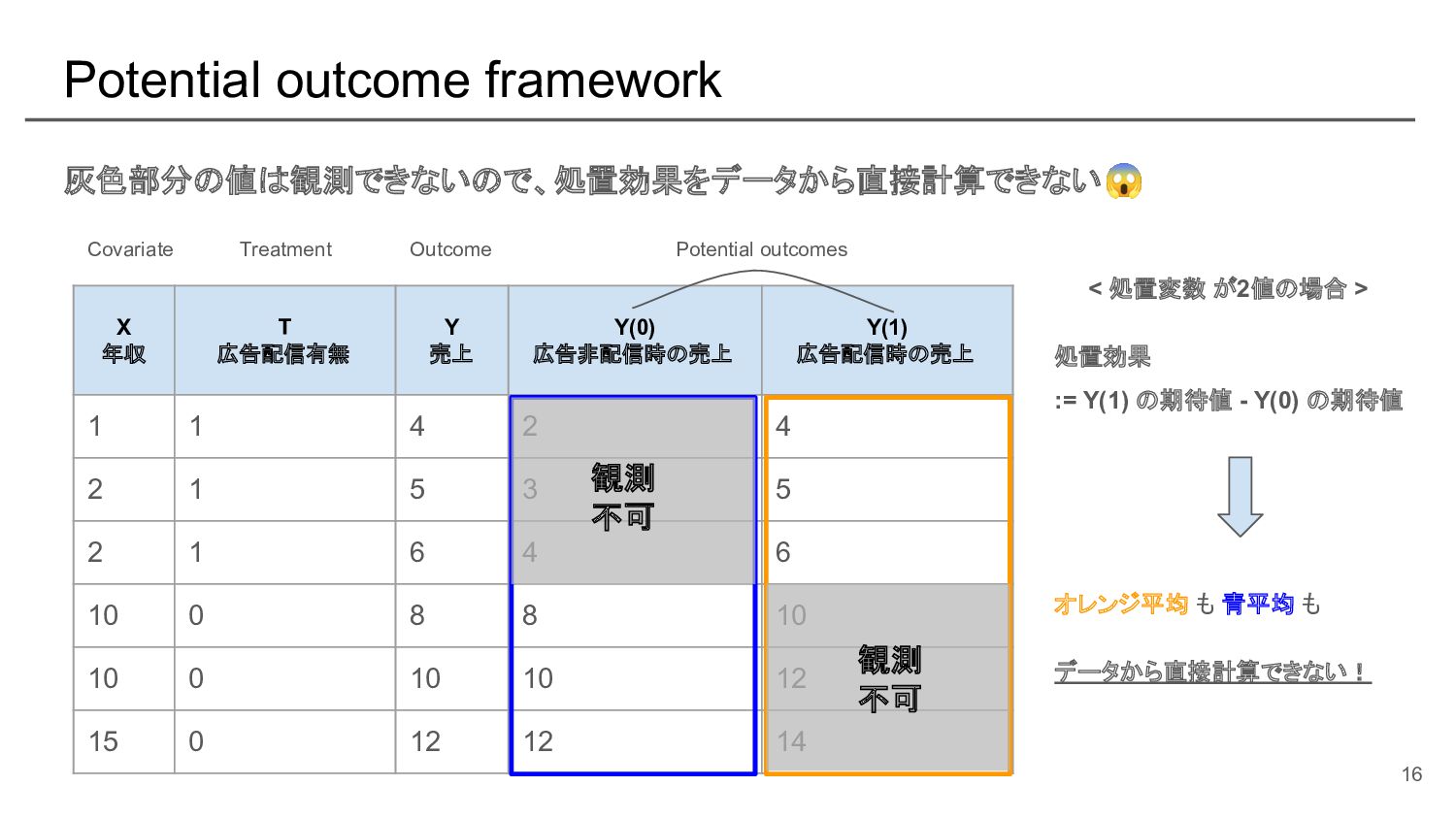{kind=link}
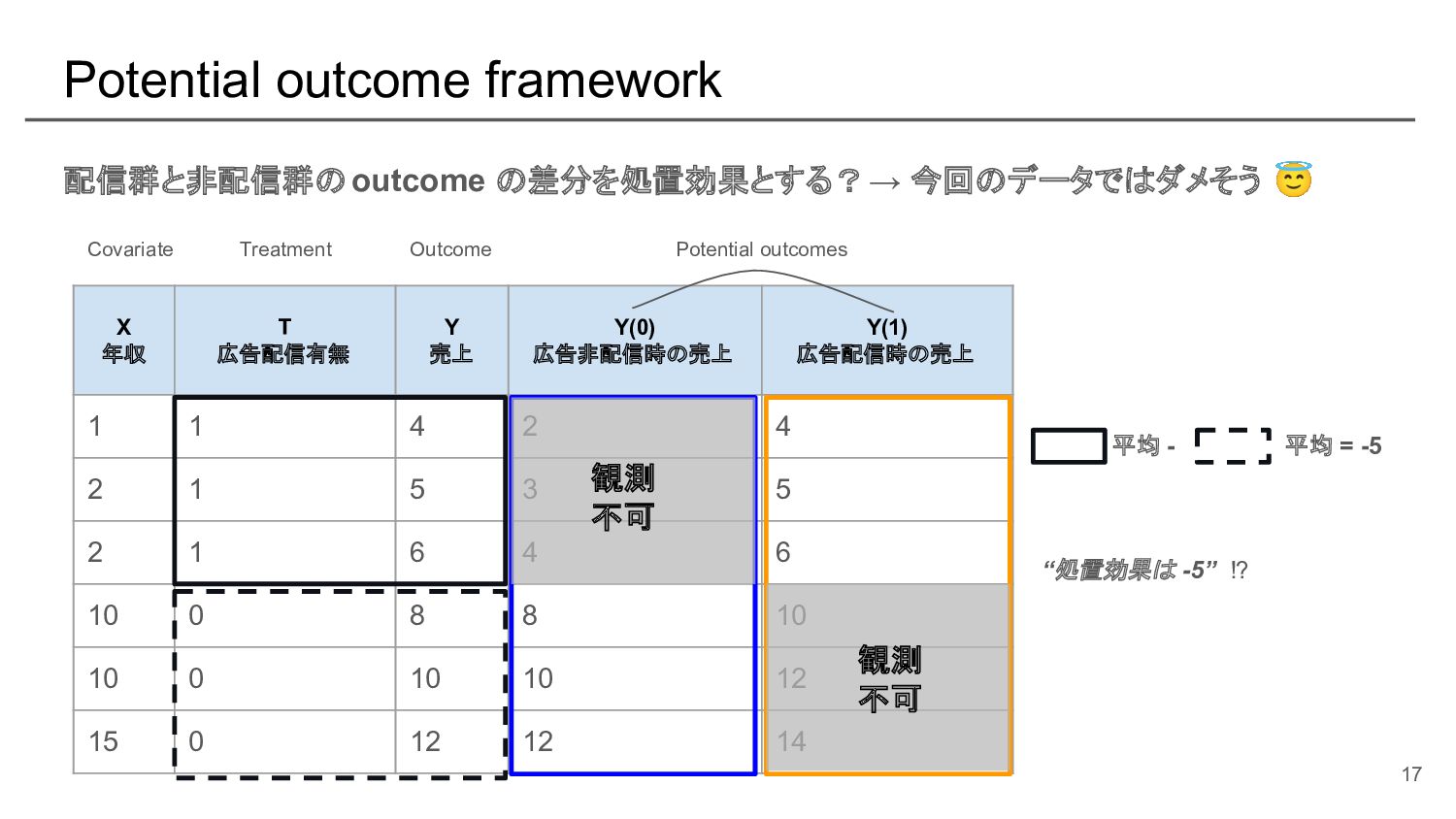{kind=link}
{kind=link}
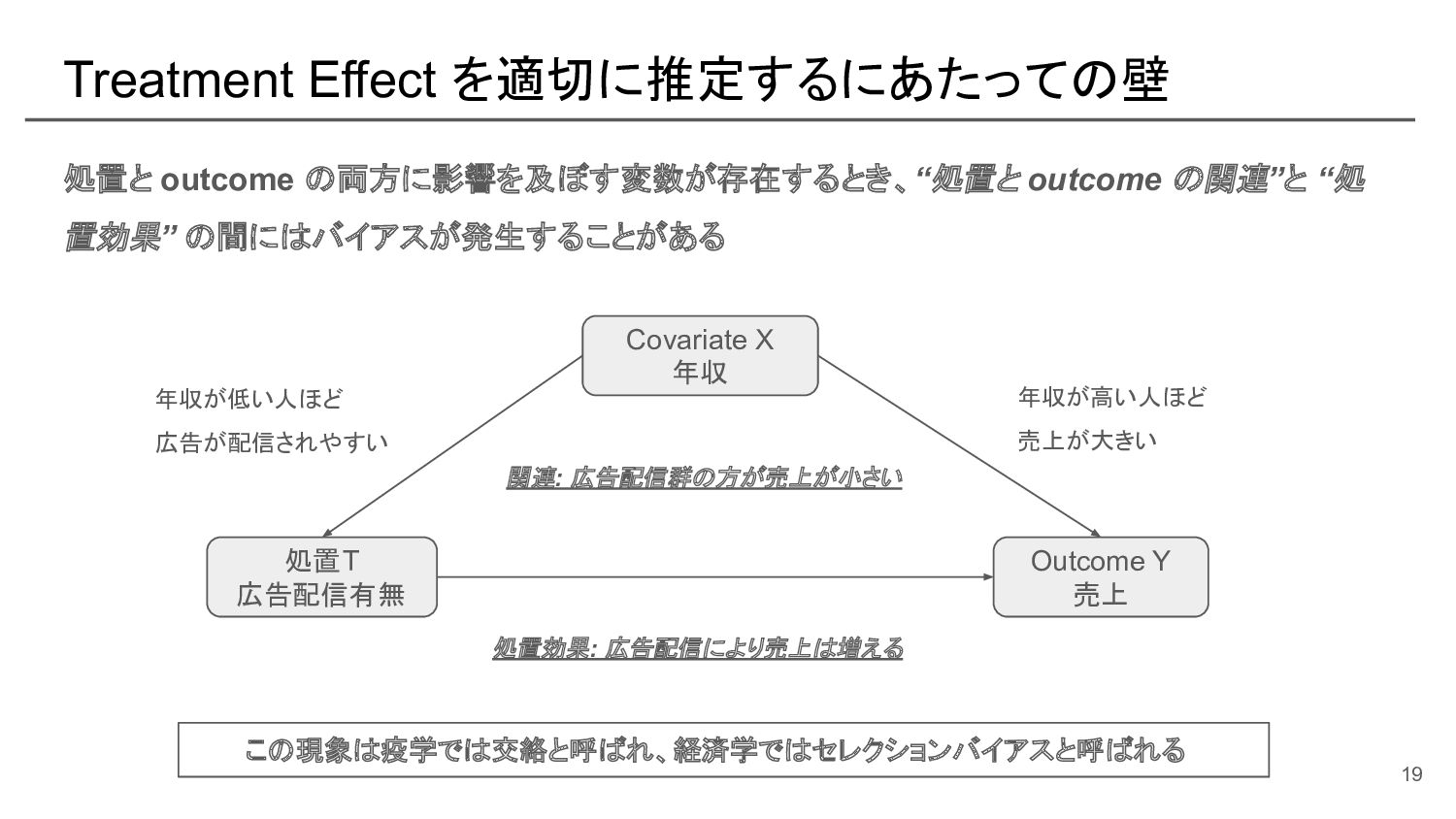{kind=link}
{kind=link}
![実験をするか、観察データを使うか • [実験]: 処置をランダムに割り当てるランダム化比較実験をすること • [観察データ]: 実験をせずに集めたデータ 21](https://files.speakerdeck.com/presentations/e539193ec6f44ffd8d4b152fa5e37e0e/slide_20.jpg){kind=link}
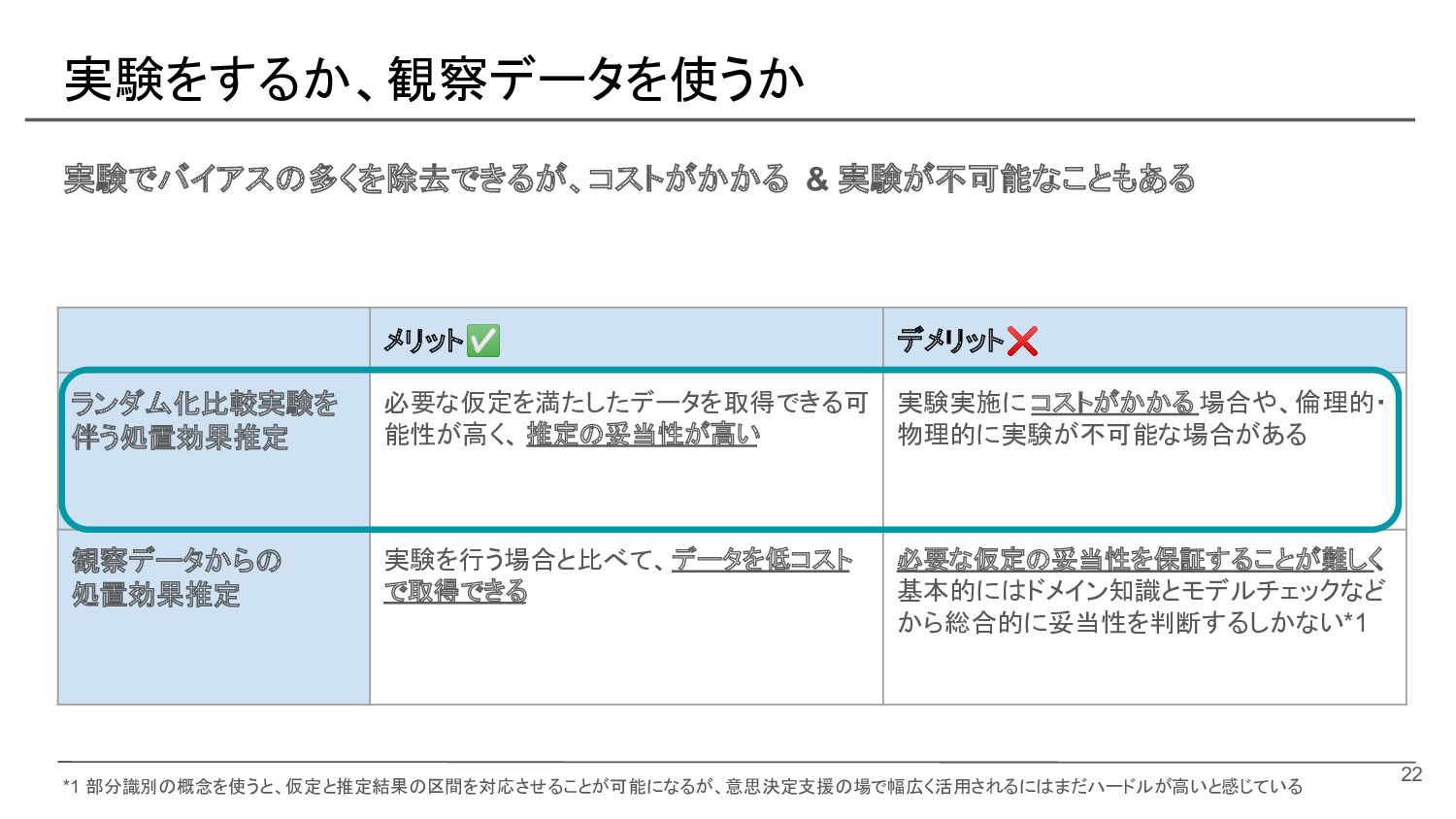{kind=link}
{kind=link}
{kind=link}
![[再掲] 第1部のゴール: 問題設定の理解 今回の発表やEconMLが ・1時点の観察データ(時系列・パネルデータではない)に対して ・処置効果推定のために必要な様々な仮定が成立していることを仮定した上で ・Heterogeneous treatment effect (HTE)](https://files.speakerdeck.com/presentations/e539193ec6f44ffd8d4b152fa5e37e0e/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MetaLearners [参考] S-Learner の概要図 table of {X, T, Y} 学習](https://files.speakerdeck.com/presentations/e539193ec6f44ffd8d4b152fa5e37e0e/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![37 [参考] 2-fold DRL の概要図 τ(x, 0, t) table of](https://files.speakerdeck.com/presentations/e539193ec6f44ffd8d4b152fa5e37e0e/slide_36.jpg){kind=link}
![38 [参考] 2-fold DRL の概要図 τ(x, 0, t) table of](https://files.speakerdeck.com/presentations/e539193ec6f44ffd8d4b152fa5e37e0e/slide_37.jpg){kind=link}
![39 [参考] 2-fold DRL の概要図 τ(x, 0, t) table of](https://files.speakerdeck.com/presentations/e539193ec6f44ffd8d4b152fa5e37e0e/slide_38.jpg){kind=link}
![40 [参考] 2-fold DRL の概要図 τ(x, 0, t) table of](https://files.speakerdeck.com/presentations/e539193ec6f44ffd8d4b152fa5e37e0e/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[再掲] 第2部のゴール: HTE推定手法の理解 ・EconML に実装されている HTE の推定手法の概要がわかる(Double Machine Learning の詳細は第3部)](https://files.speakerdeck.com/presentations/e539193ec6f44ffd8d4b152fa5e37e0e/slide_46.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
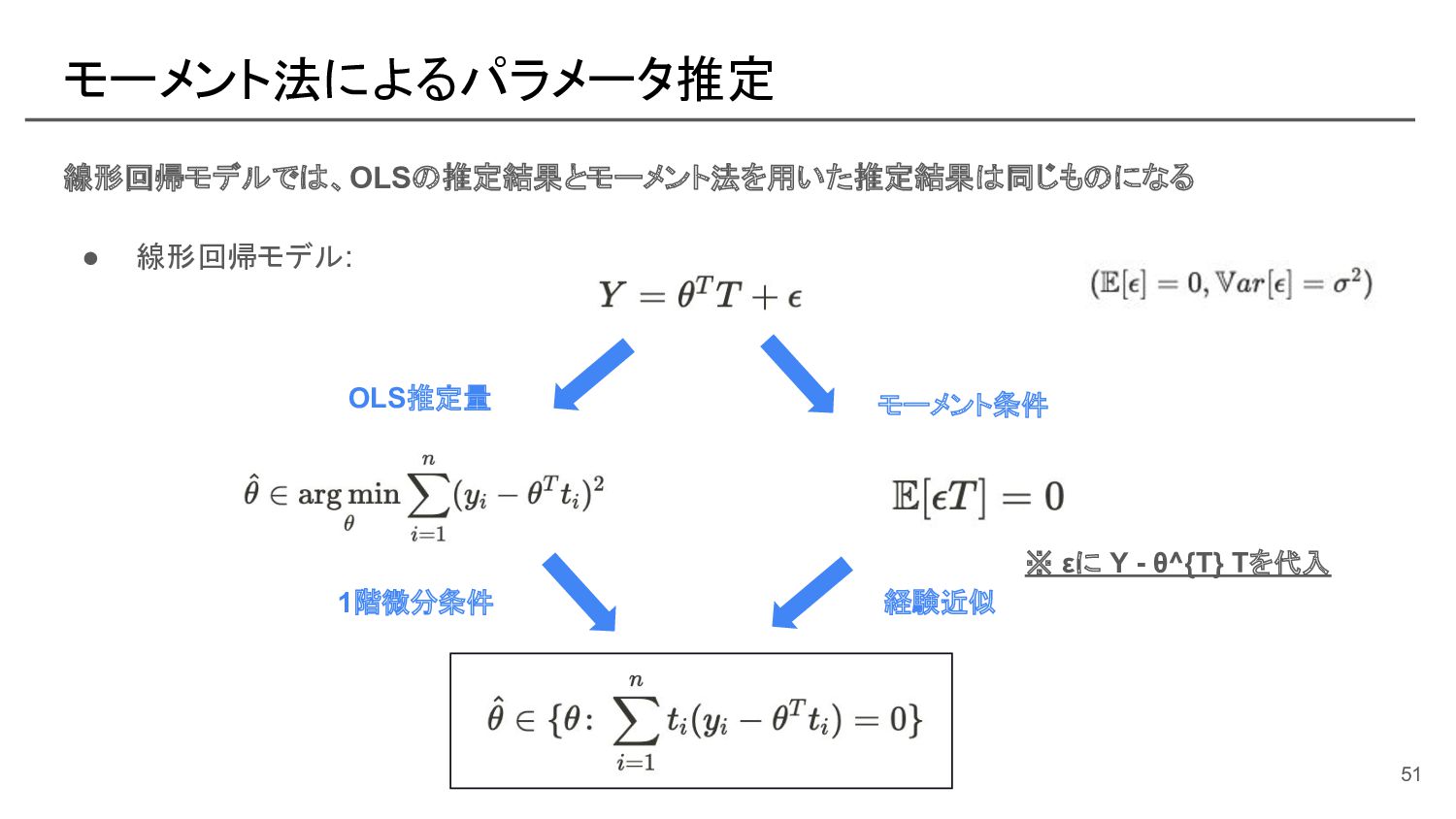
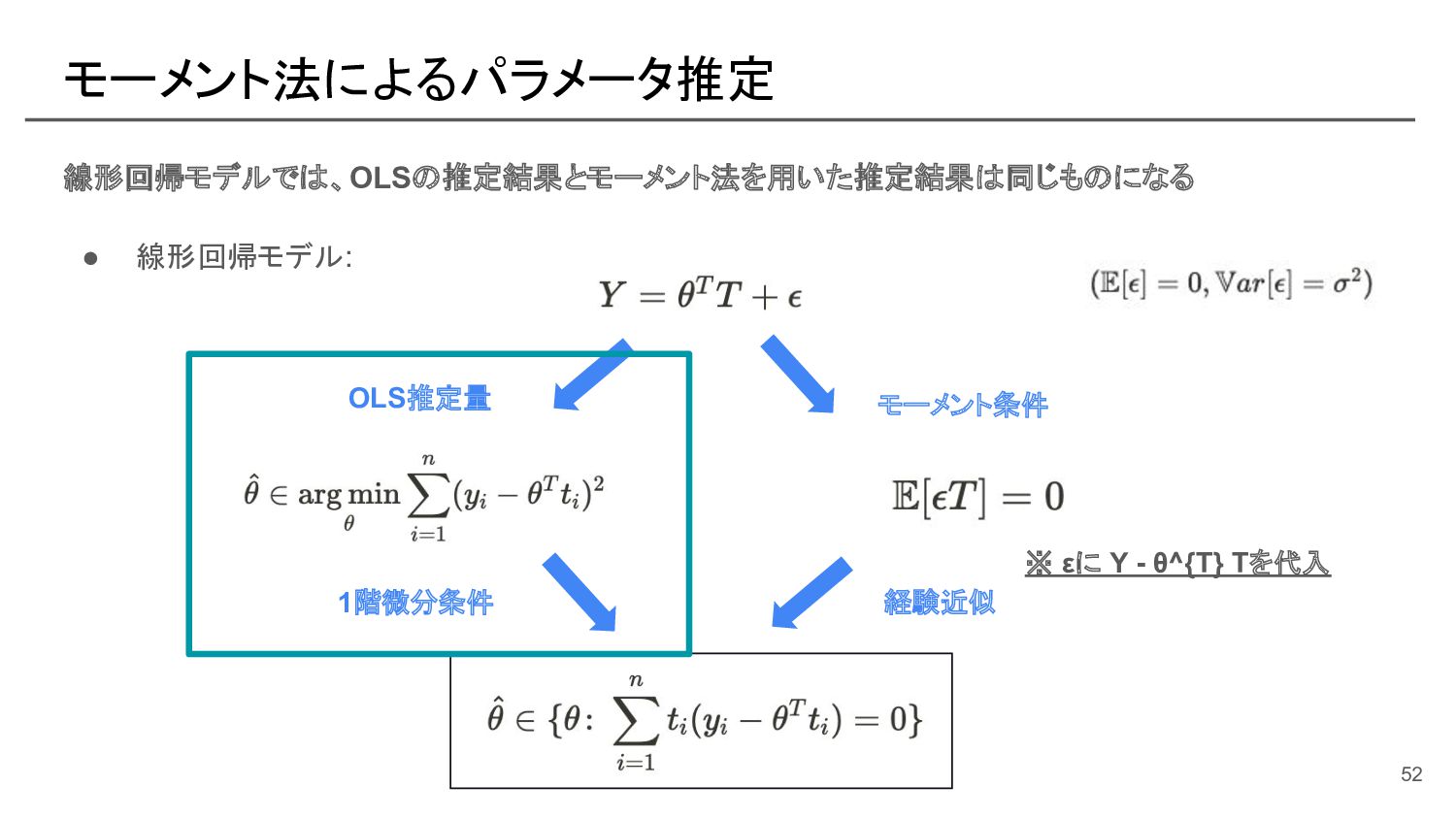
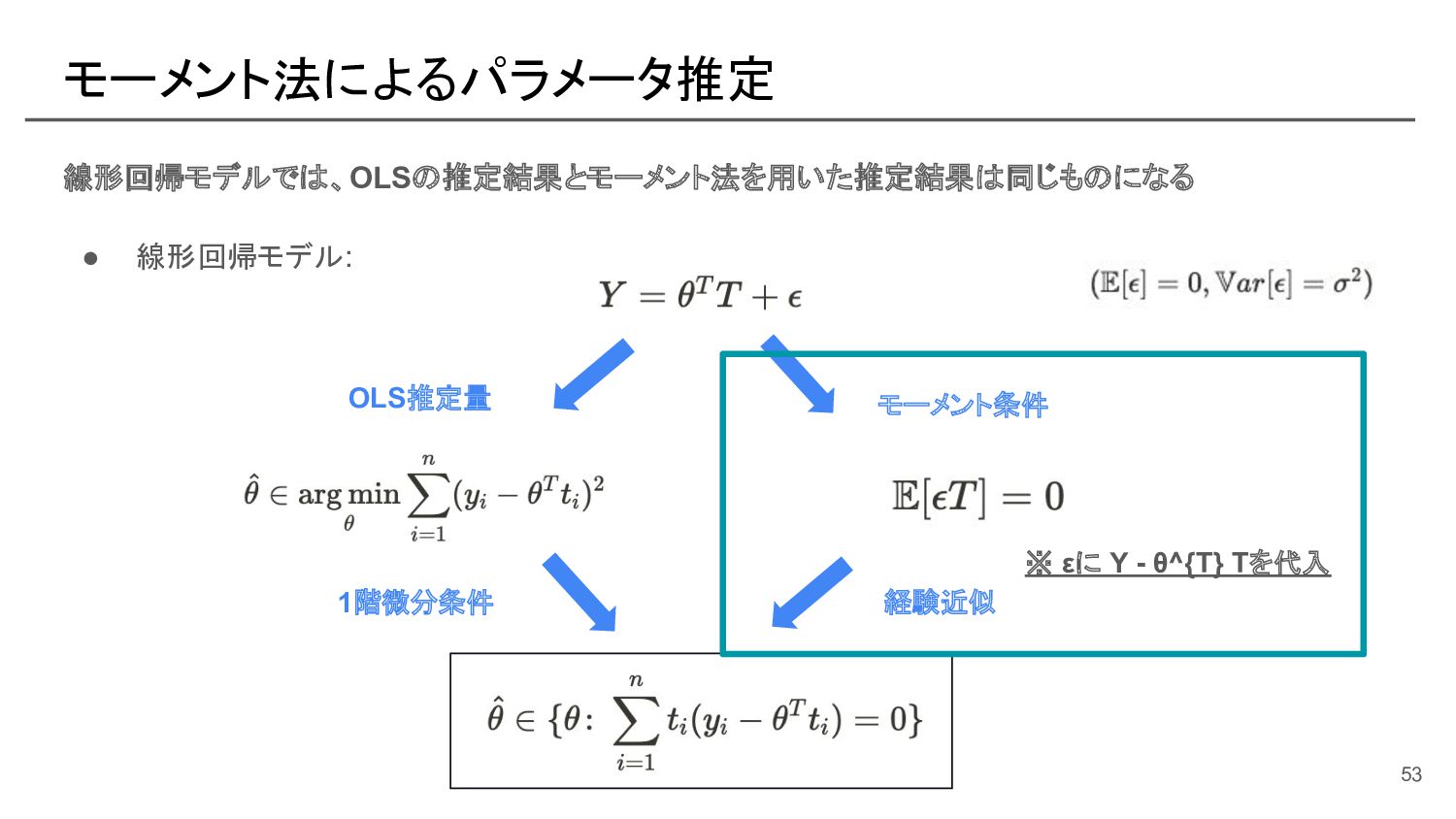
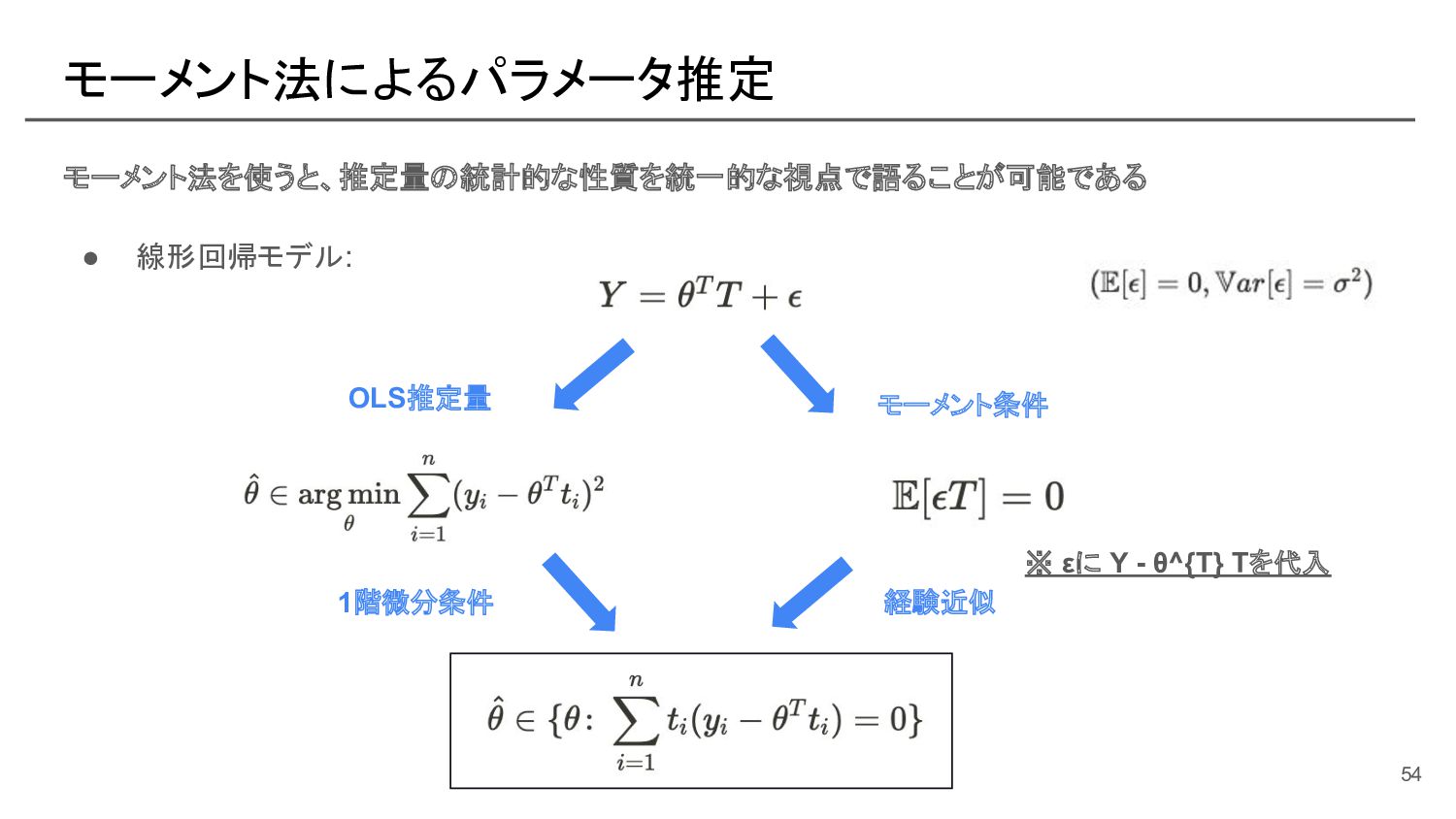
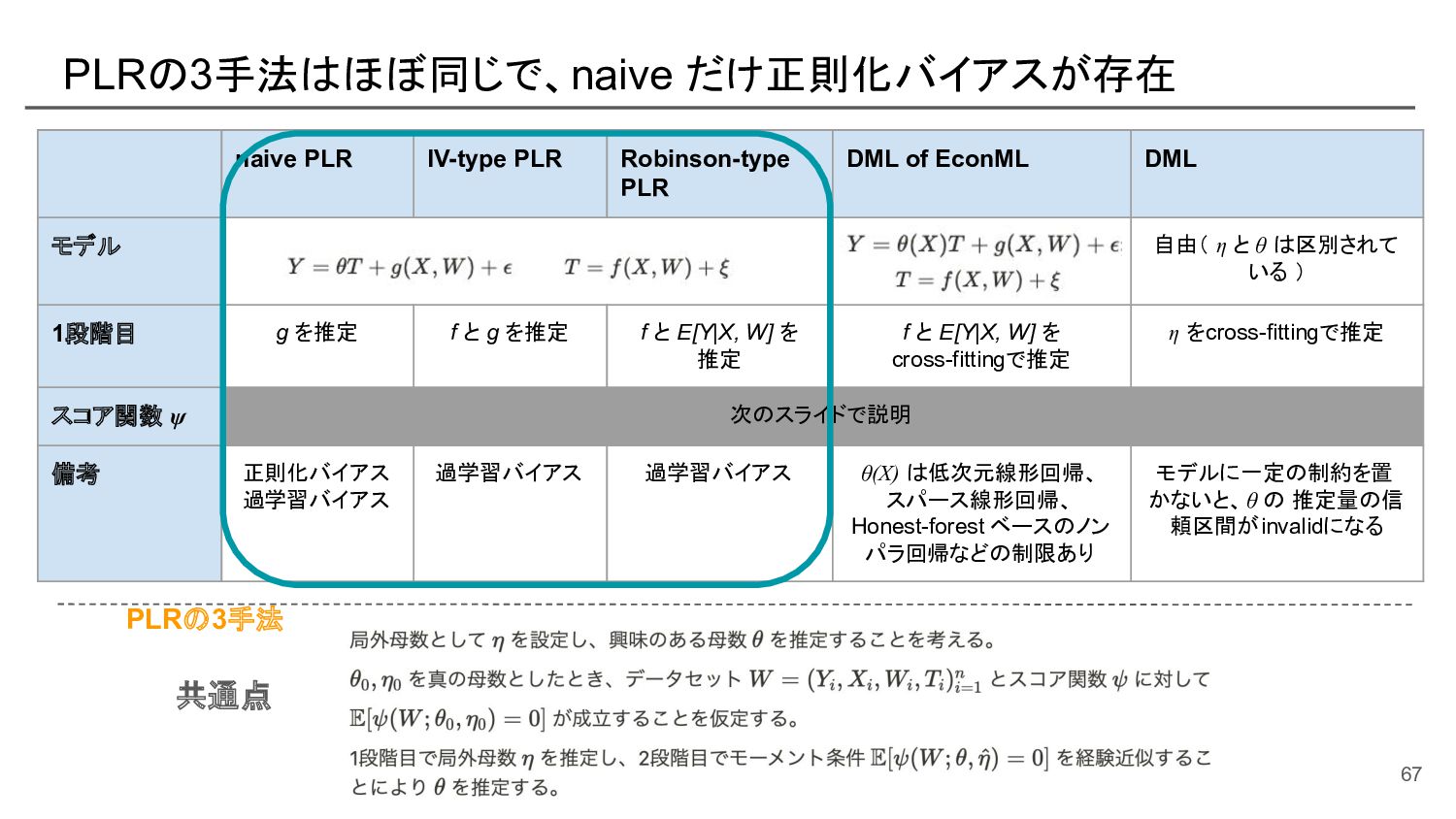
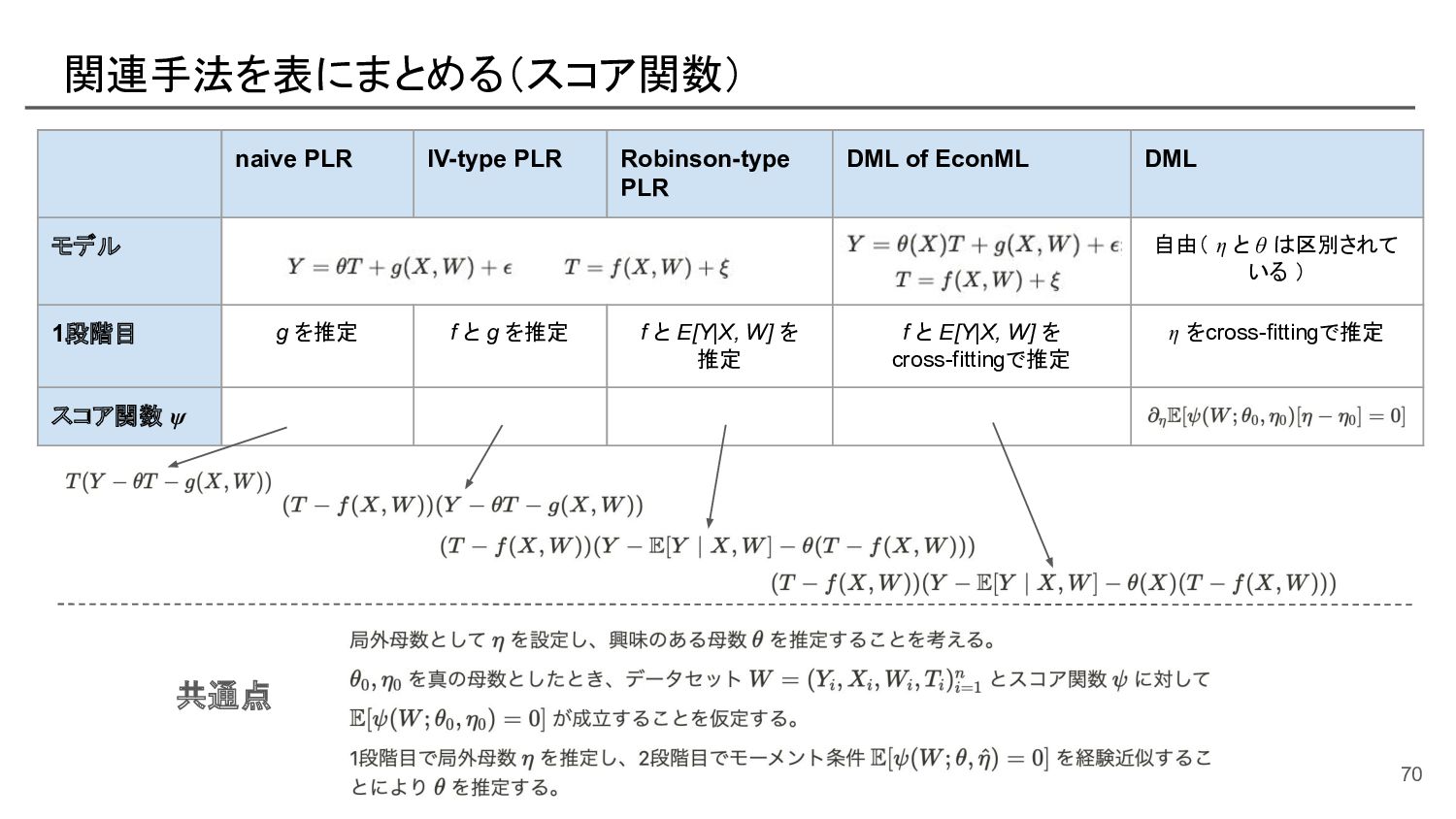
![部分線形モデルにおける naive なパラメータ推定 [参考]: モーメント法の式展開 この部分を スコア関数と呼ぶ 57](https://files.speakerdeck.com/presentations/e539193ec6f44ffd8d4b152fa5e37e0e/slide_56.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
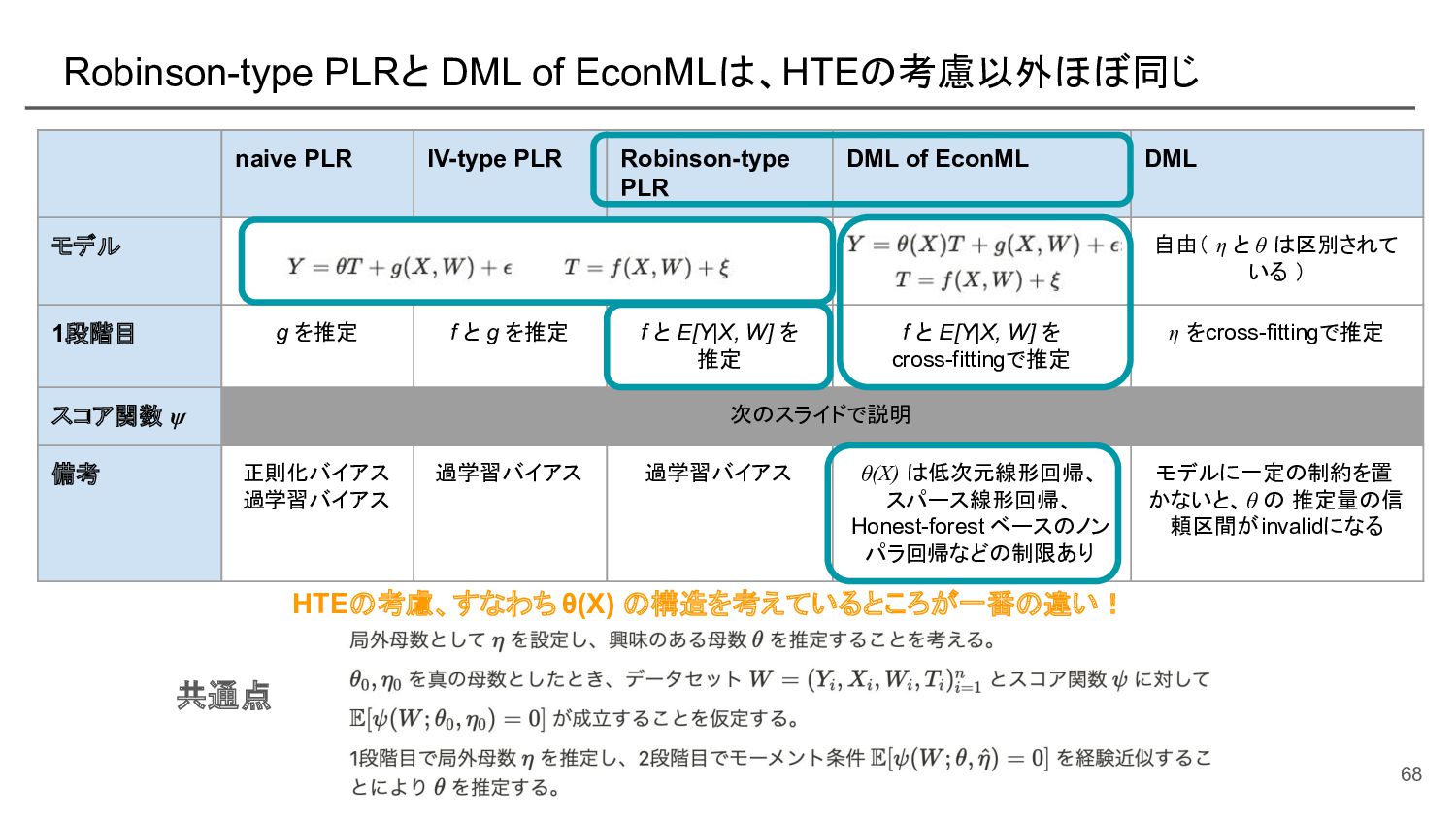
![Robinson の手法による部分線形モデルのパラメータ推定 残差回帰(によってXとWについて周辺化して、Tの処置効果にフォーカス) • 部分線形モデル: 興味のないXやWについてはノンパラなgでモデリング • [Robinsonの手法]: XとWからYとTを予測するモデルを作成し、YとTの残差同士の回帰を行うこと で、部分線形モデルのパラメータ](https://files.speakerdeck.com/presentations/e539193ec6f44ffd8d4b152fa5e37e0e/slide_61.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
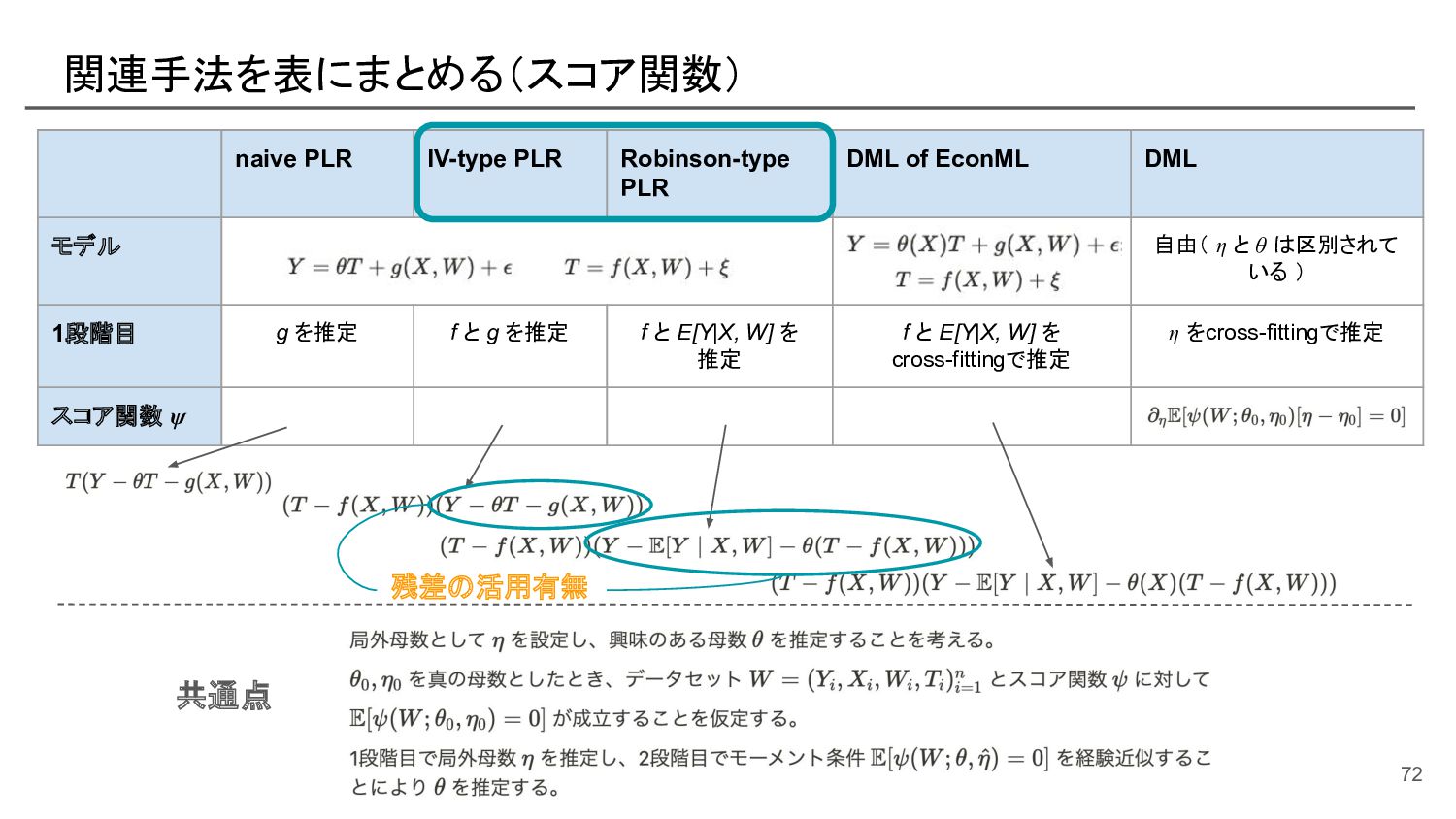{kind=link}
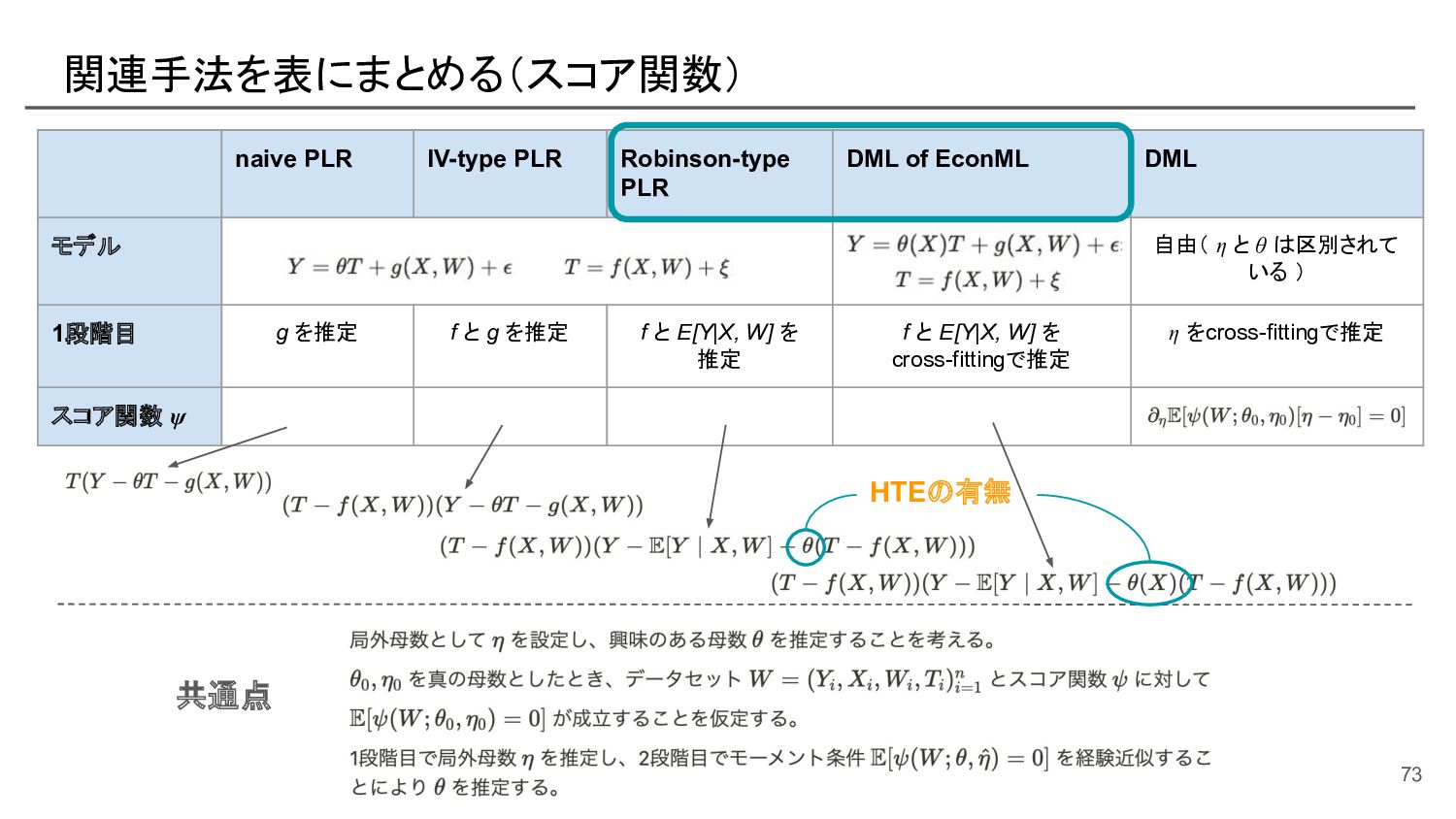{kind=link}
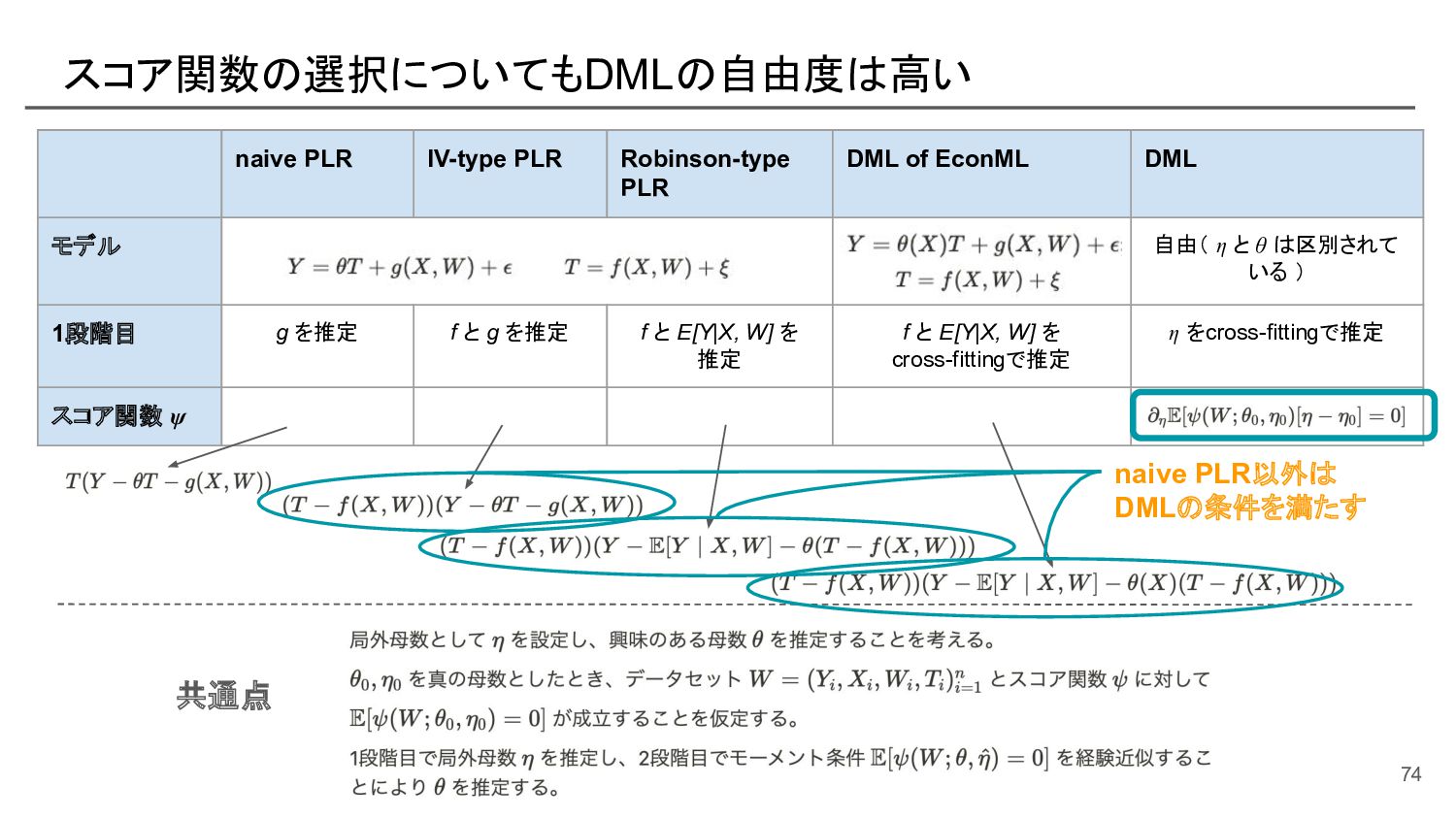{kind=link}
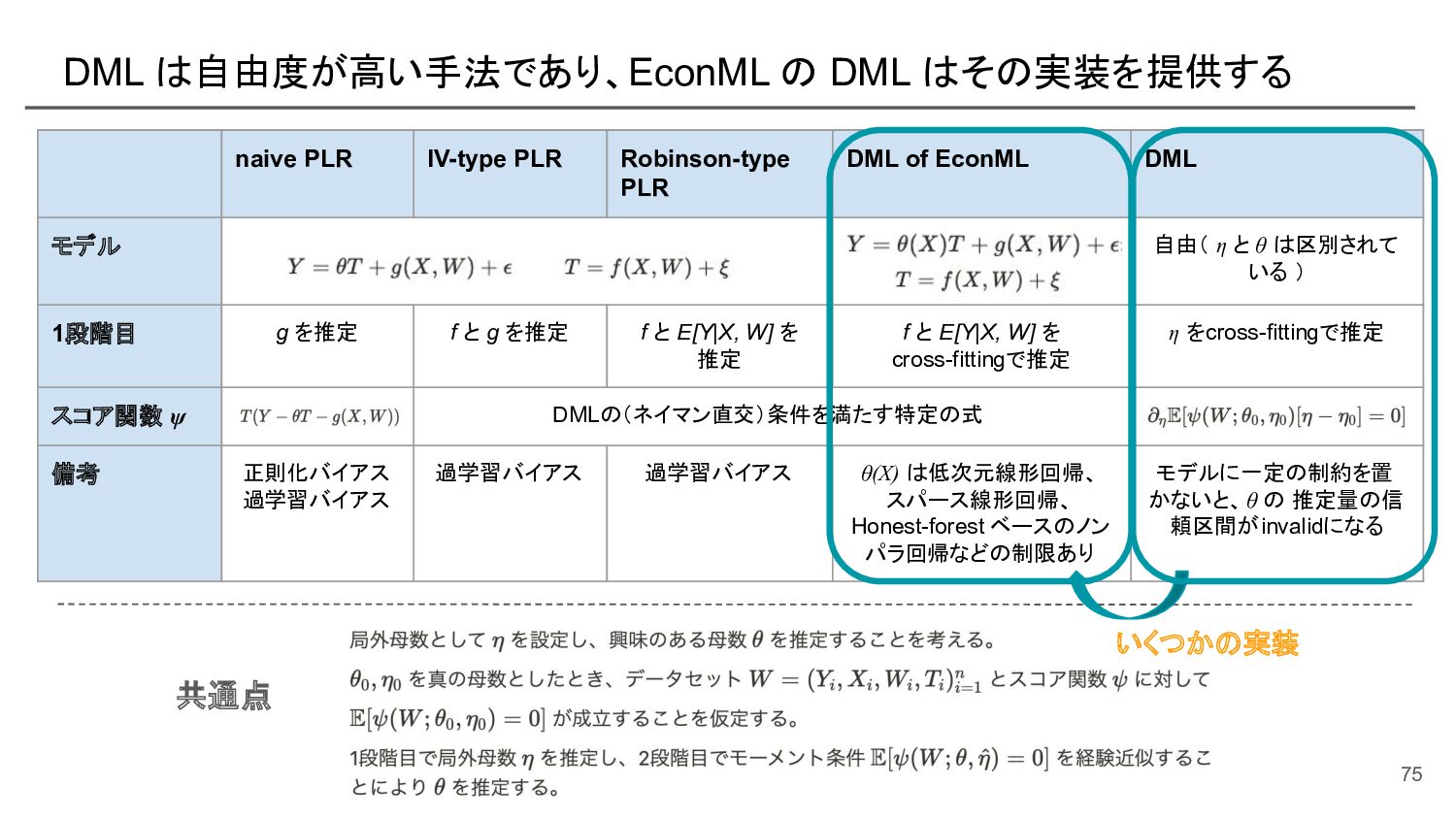{kind=link}
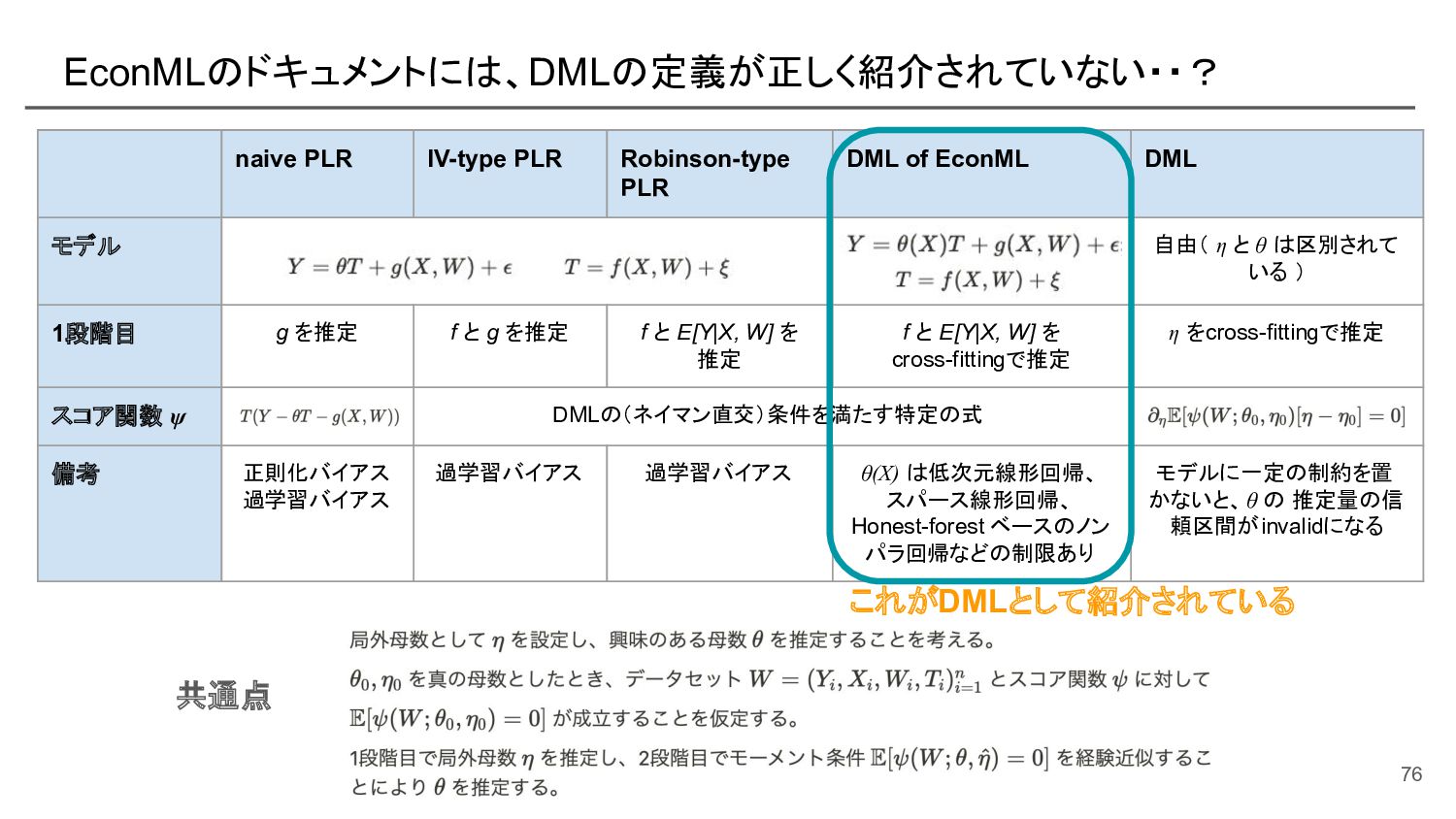{kind=link}
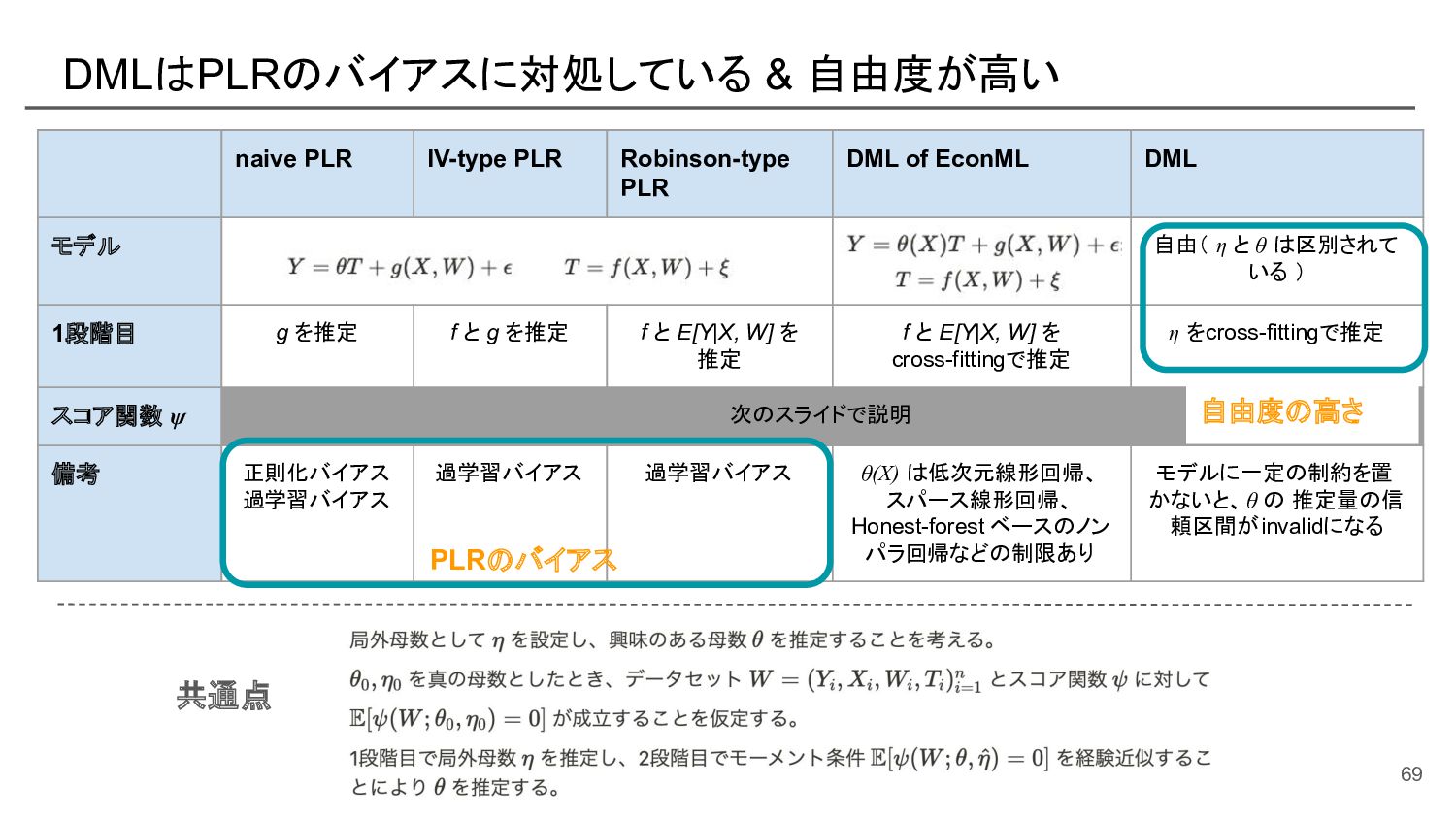
![[再掲] 第3部のゴール ・部分線形モデルのパラメータ推定の手続きがわかる ・Double Machine Learning の定義に触れ、自由度の高さを実感できる ・EconML が実装している Double](https://files.speakerdeck.com/presentations/e539193ec6f44ffd8d4b152fa5e37e0e/slide_76.jpg){kind=link}
{kind=link}
![[再掲] EconMLを使う場合のHTE推定手法のまとめ ✅ HTE推定の初手として、従来の線形回帰モデルの推定結果を使うのは good ❌ モデルの表現力は poor であり、結果にバイアスが乗っているかも。表現力の高いモデルを検討しよう ✅](https://files.speakerdeck.com/presentations/e539193ec6f44ffd8d4b152fa5e37e0e/slide_78.jpg){kind=link}
![[再掲] DML は自由度が高い手法であり、EconML の DML はその実装を提供 共通点 naive PLR IV-type](https://files.speakerdeck.com/presentations/e539193ec6f44ffd8d4b152fa5e37e0e/slide_79.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
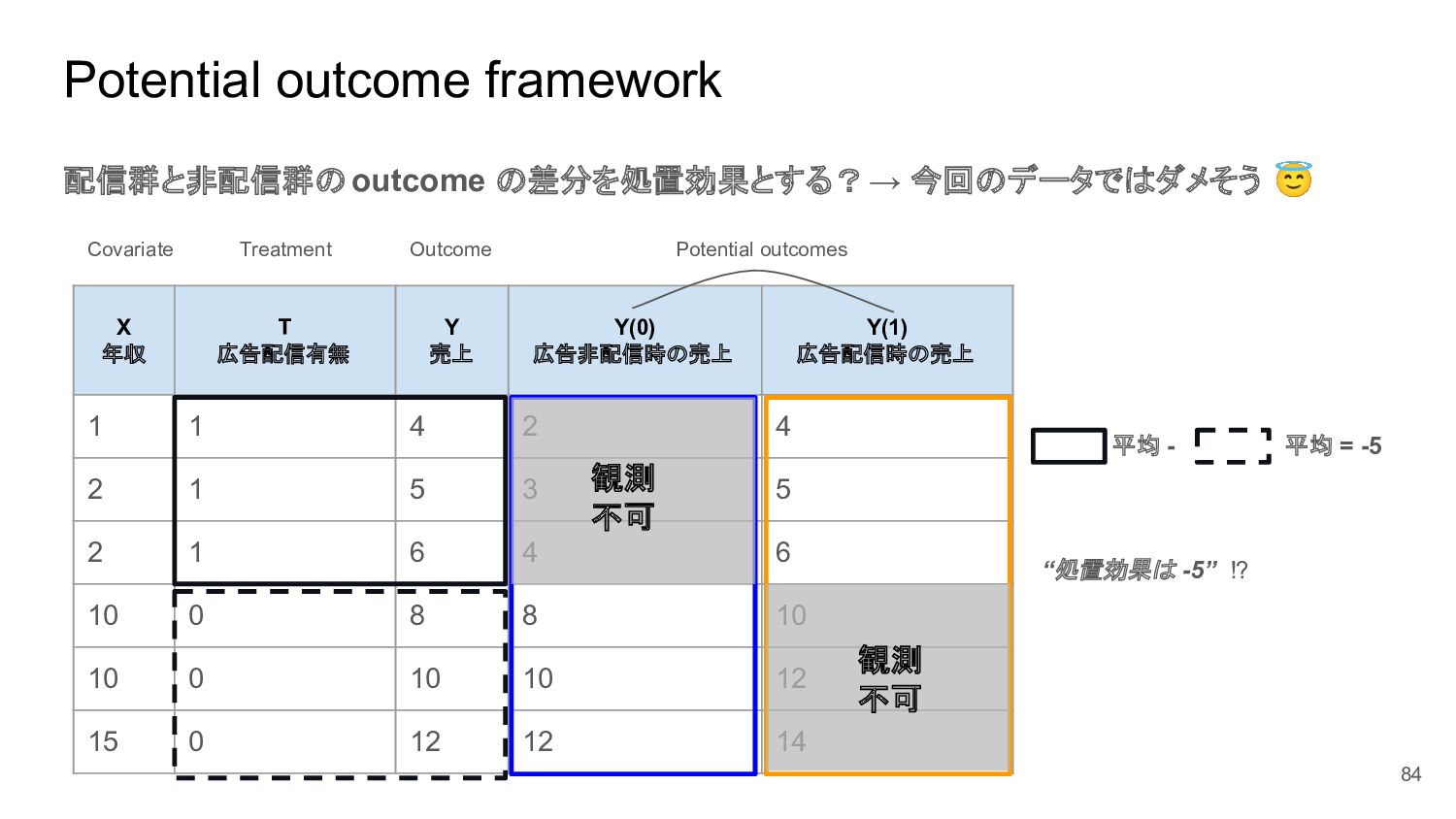{kind=link}
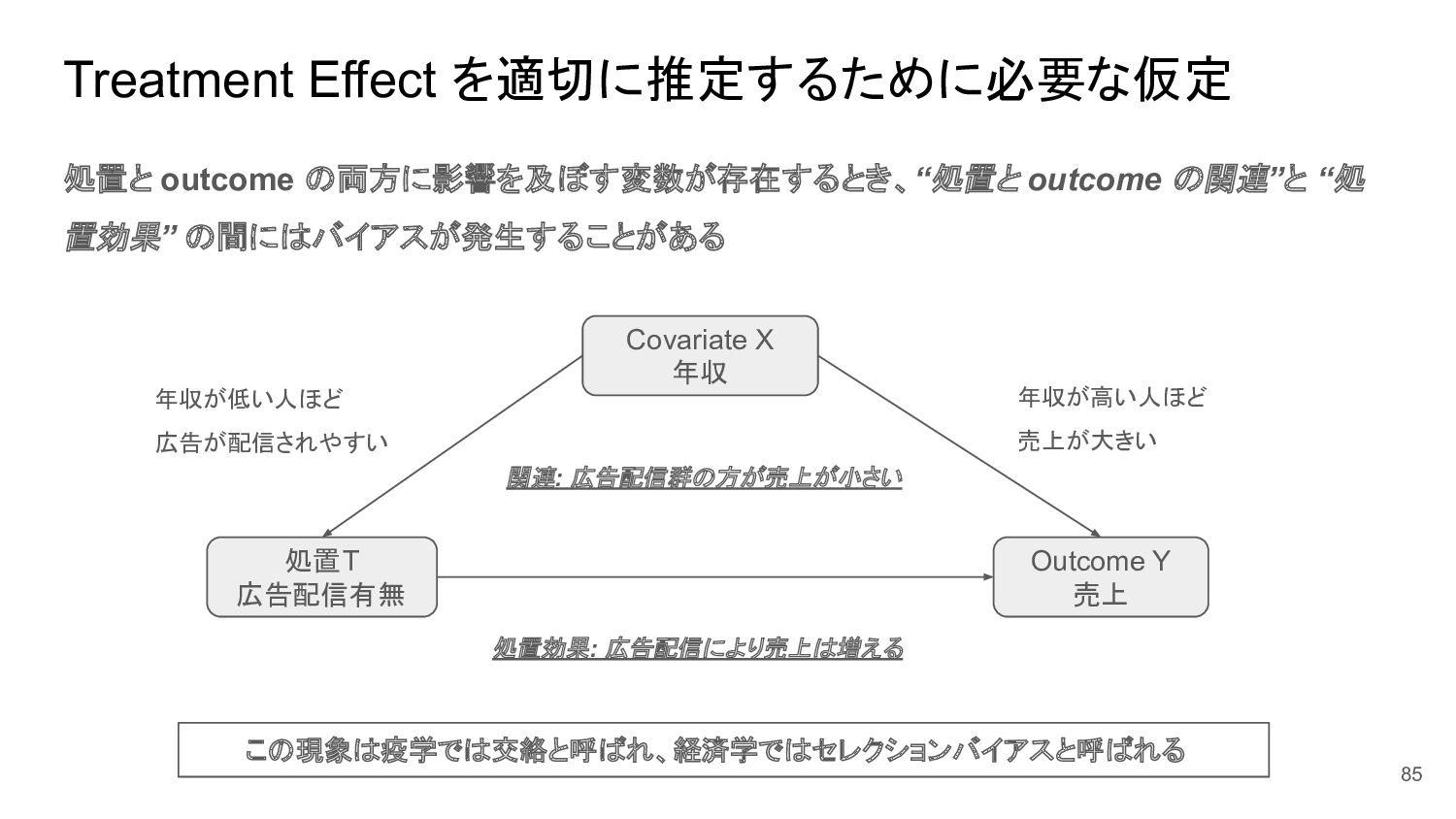{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
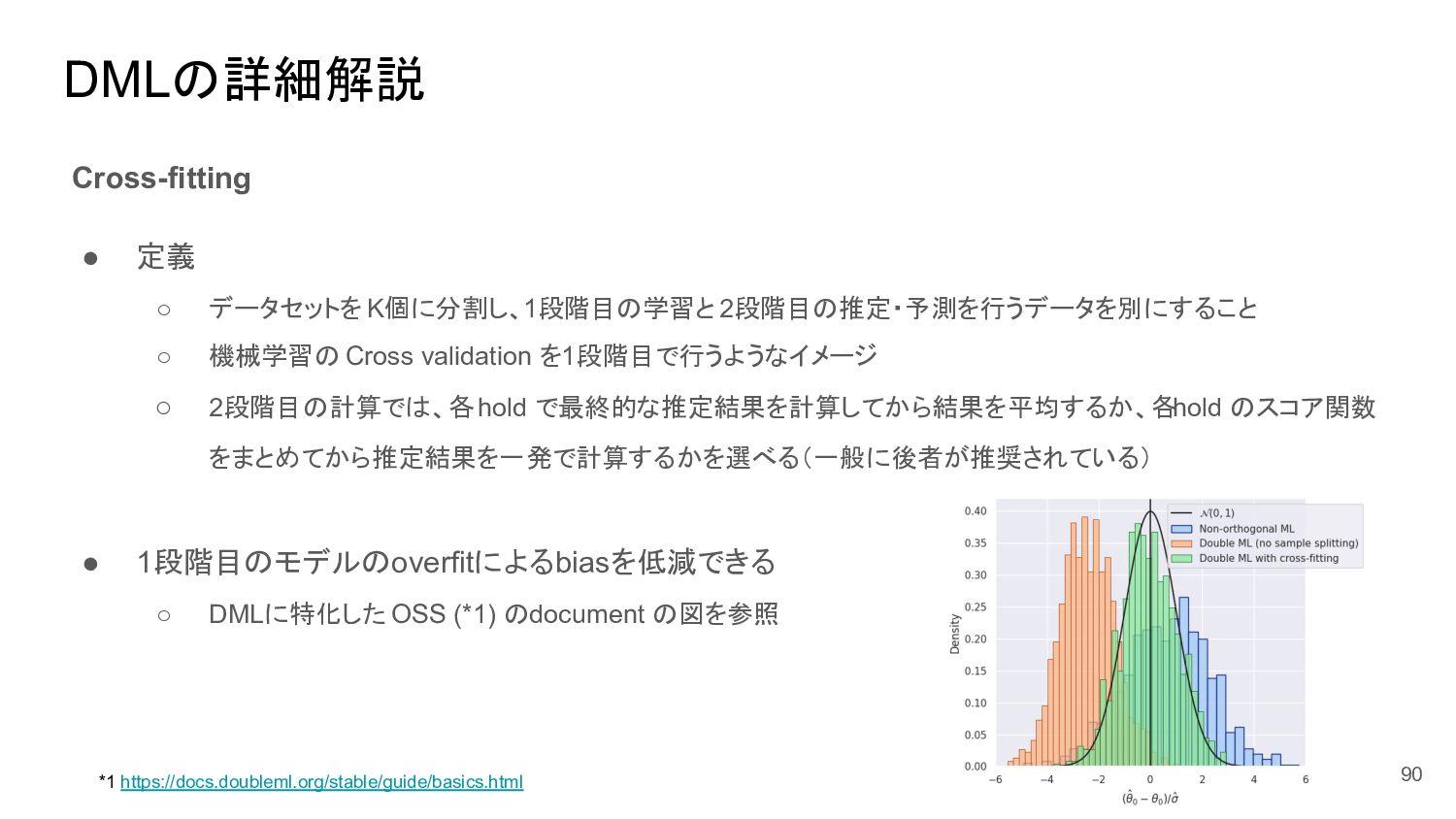{kind=link}
{kind=link}