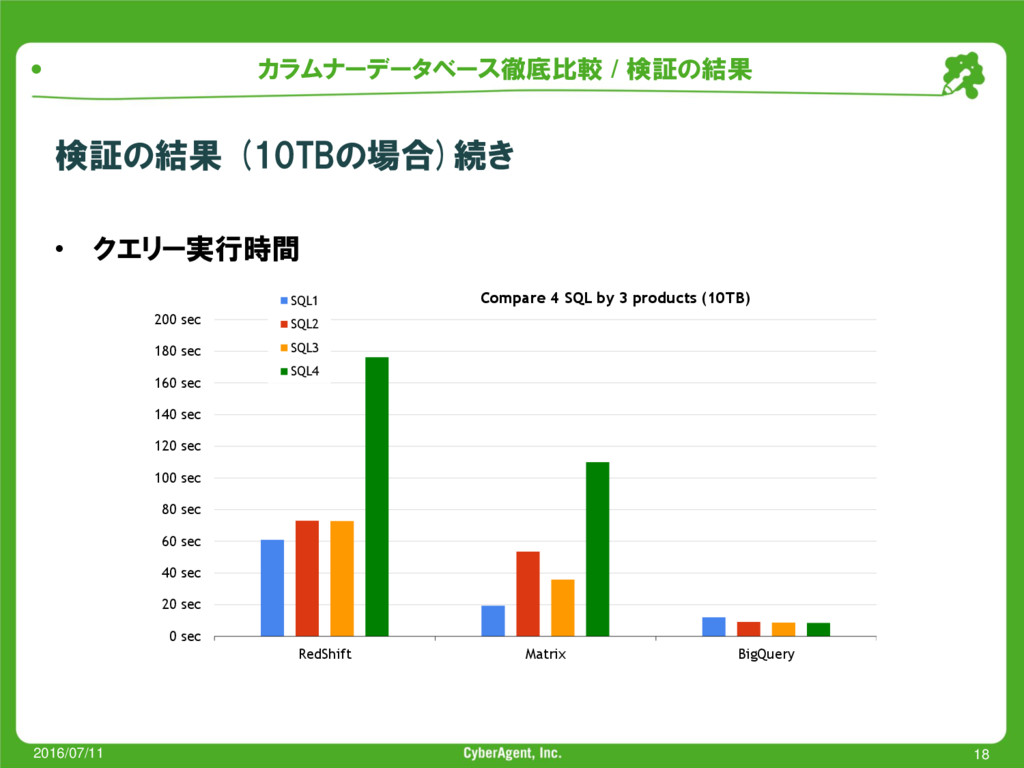
種類 Query説明 1.5TB LIKEで前方一致を行うクエリー 例: SELECT DISTINCT id FROM table WHERE str LIKE 'string%' 10TB① GROUPを行ってcountを行うクエリー 例: SELECT id,count(*) FROM table GROUP BY idx 10TB② GROUP BYされたサブクエリーをさらにサブクエリーするクエリー 例: SELECT id,count() FROM (SELECT id, count() as count FROM table GROUP BY id ORDER BY count DESC LIMIT x) as table WHERE column = column GROUP BY id,count 10TB③ サブクエリーによるテーブル2つをJOINしてWHEREをかけたクエリー 例: SELECT id FROM(SELECT id,count() as count FROM table GROUP BY count DESC LIMIT x) as table,(SELECT id,count() as count FROM table GROUP BY count DESC LIMIT x) as table WHERE table.id = table.id 10TB④ min,count関数を使ったGROUP BYのクエリー 例: SELECT min(id),count(*) FROM table WHERE column = 'string' GROUP BY id ORDER BY count DESC
{kind=link}
{kind=link}
{kind=link}
{kind=link}
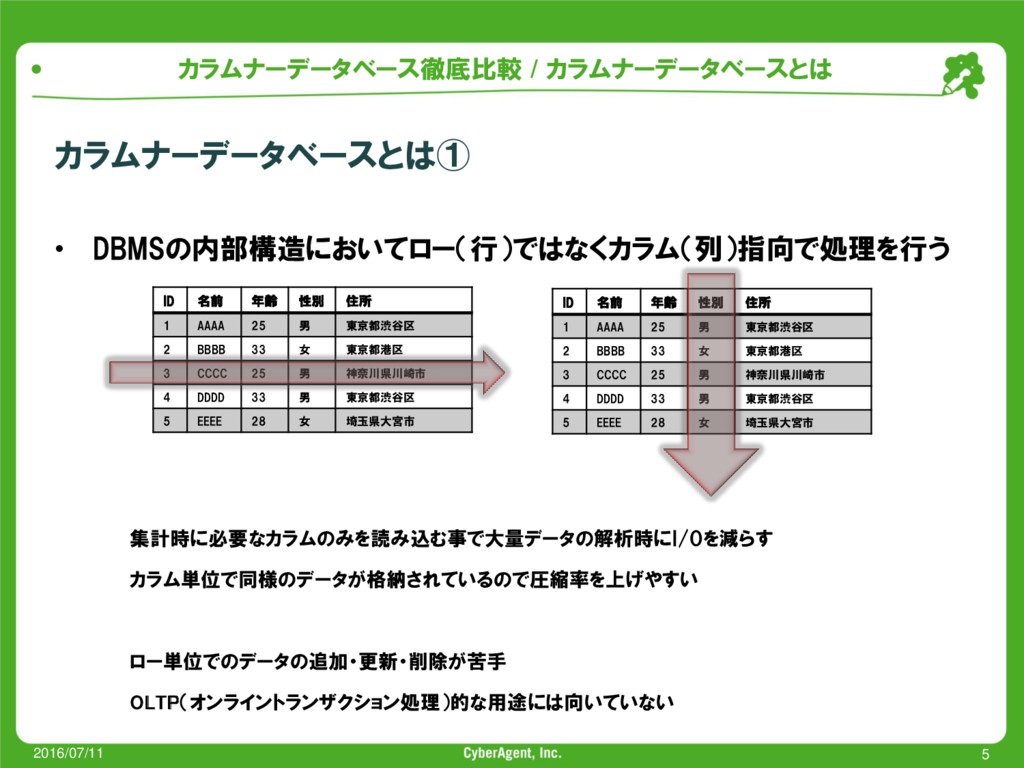{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
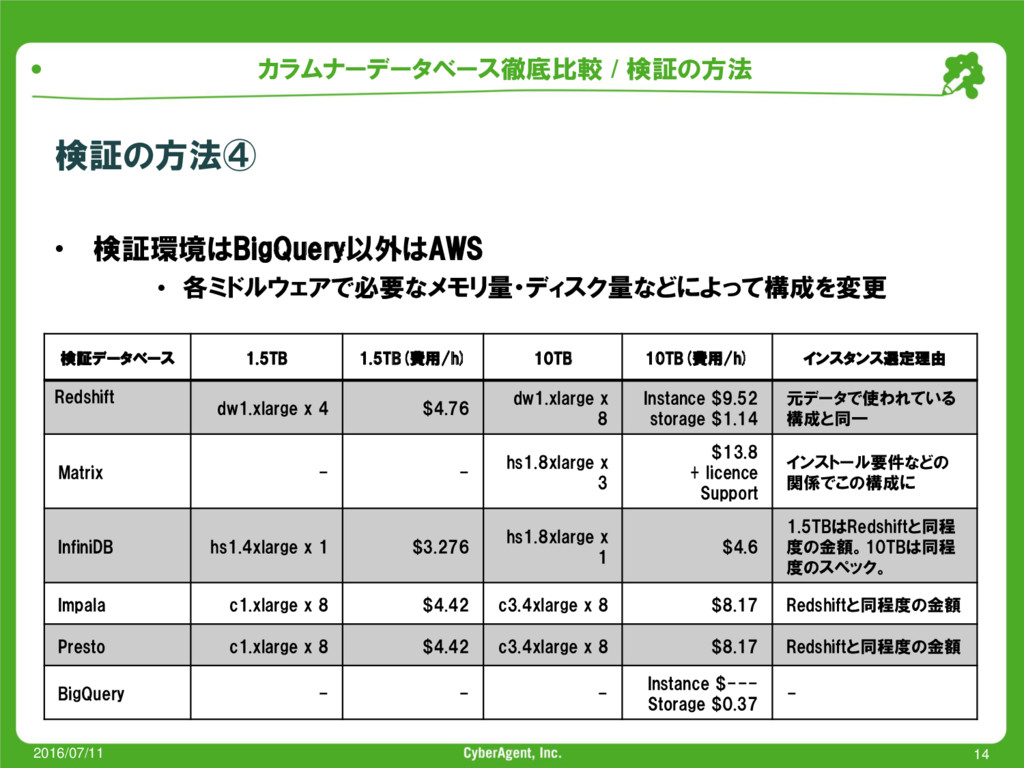{kind=link}
{kind=link}
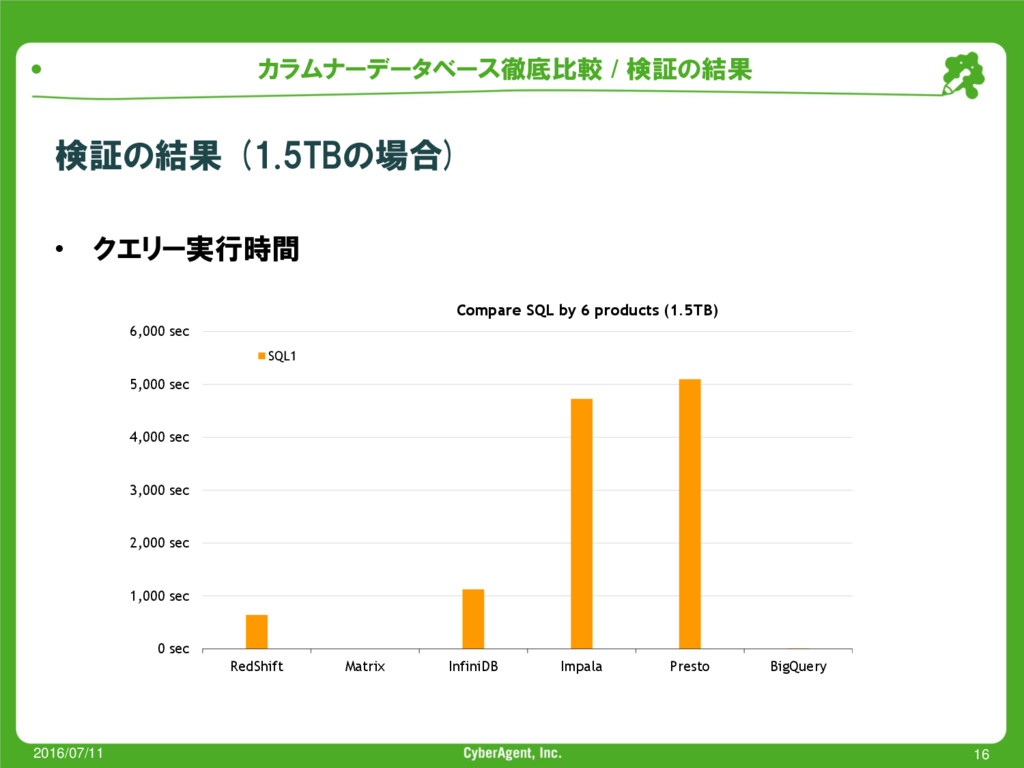{kind=link}
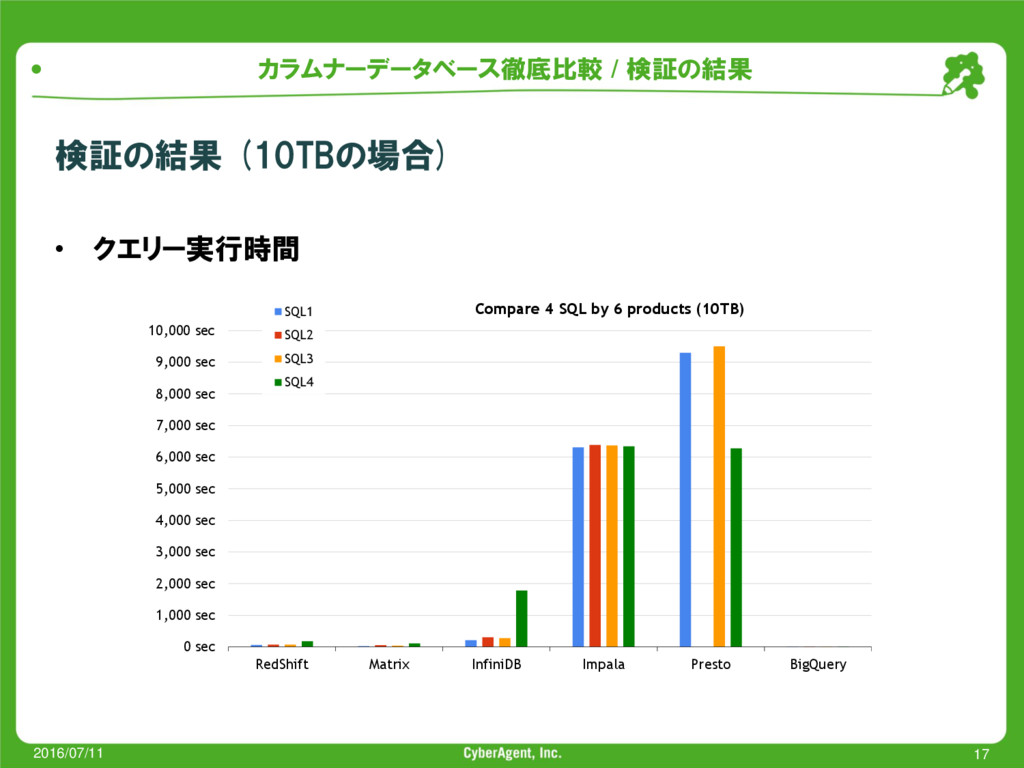{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}