Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
サイバーエージェント アドテクスタジオの次世代データ分析基盤紹介
Search
Fumihide Nario
July 14, 2016
Technology
1.3k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
サイバーエージェント アドテクスタジオの次世代データ分析基盤紹介
db tech showcase Tokyo 2016
Fumihide Nario
July 14, 2016
More Decks by Fumihide Nario
See All by Fumihide Nario
Google BigQuery × Amazon Redshift
fumihide
1
3.2k
カラムナーデータベース徹底比較
fumihide
2
1.5k
Other Decks in Technology
See All in Technology
AI駆動開発におけるQAエンジニアの役割事例 〜AI駆動開発の現場から〜
kobayashiyorimitsu
0
400
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
1
2.5k
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
0
3.5k
「ちゃんとやっている」は独りよがりだった ― 不安に寄り添うインシデント対応へ / Towards incident response that addresses anxieties
chmikata
1
3.6k
Claude Codeとハーネスについて考えてみる
oikon48
18
8.8k
勉強会企画をアプリで構造化してみた 〜そこで見えた、AIとの付き合い方〜 / I've structured a study group plan using an app.
pauli
0
330
AIに「使われる」時代のSaaS戦略 〜既存WebAPIのMCPサーバー化における開発ノウハウ〜
ekispert_api
0
300
ローカルLLMとLINE Botの組み合わせ その3 / LINE DC Generative AI Meetup #8
you
PRO
0
120
Claude Code 珍プレー好プレー
shinyasaita
0
280
完全自律ロボットを作りたくて、先に開発を自律させた話(ROS Japan UG #63 LT)
rryz09
0
400
生成AIの活用/high_school2026
okana2ki
0
110
CIで使うClaude
iwatatomoya
0
160
Featured
See All Featured
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
Navigating Weather and Climate Data
rabernat
0
280
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
GitHub's CSS Performance
jonrohan
1033
470k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
56k
How to train your dragon (web standard)
notwaldorf
97
6.7k
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
350
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
Transcript
サイバーエージェント アドテクスタジオの 次世代データ分析基盤紹介 @db tech showcase Tokyo 2016 2016 July
13th CyberAgent, Inc. All Rights Reserved
Agenda ・自己紹介 ・サイバーエージェント、アドテクスタジオについて ・共通基盤構想前の紹介 ・共通基盤構想 Hadoop編 ・共通基盤構想 Log編 ・将来の展望
自己紹介 Fumihide Nario 2011年5月よりサイバーエージェントグループのSGE管轄にて インフラやソーシャルゲームの開発を担当 2014年4月からアドテク本部にて 多数の広告プロダクトのサーバー、ミドルウェア、データベースなどの構築、運 用からデータ分析基盤などインフラ全般を担当 https://speakerdeck.com/fumihide https://www.facebook.com/fumihide.nario
@FumihideNario
株式会社サイバーエージェント
株式会社サイバーエージェント 1998年の創業以来、インターネットを軸に事業を展開し 現在では代表的なサービスである「Ameba」をはじめ、 スマートフォン向けに多数のコミュニティサービスやゲームを提供しています。
株式会社サイバーエージェント
アドテクスタジオ アドテクノロジーのスペシャリストが集う場所 アドテクスタジオとは、サイバーエージェントグループのアドテクノロジー分野に おけるサービス開発を行うエンジニアの横断組織です。 当社ではアドテクノロジー分野におけるサービスを多数提供しています。 これまでは、各子会社を通じサービス開発をしていましたが、 開発効率の向上、各サービスの技術力および精度強化を目的に、 アドテクノロジーにかかわるサービスの開発部門の横断組織として、 「アドテクスタジオ」を設立しました。 開発体制を強化するほか、エンジニアの技術力向上をサポートする環境づくり
や、新たな制度の導入などを行っています。 https://adtech.cyberagent.io/ より抜粋
アドテクスタジオ … and more
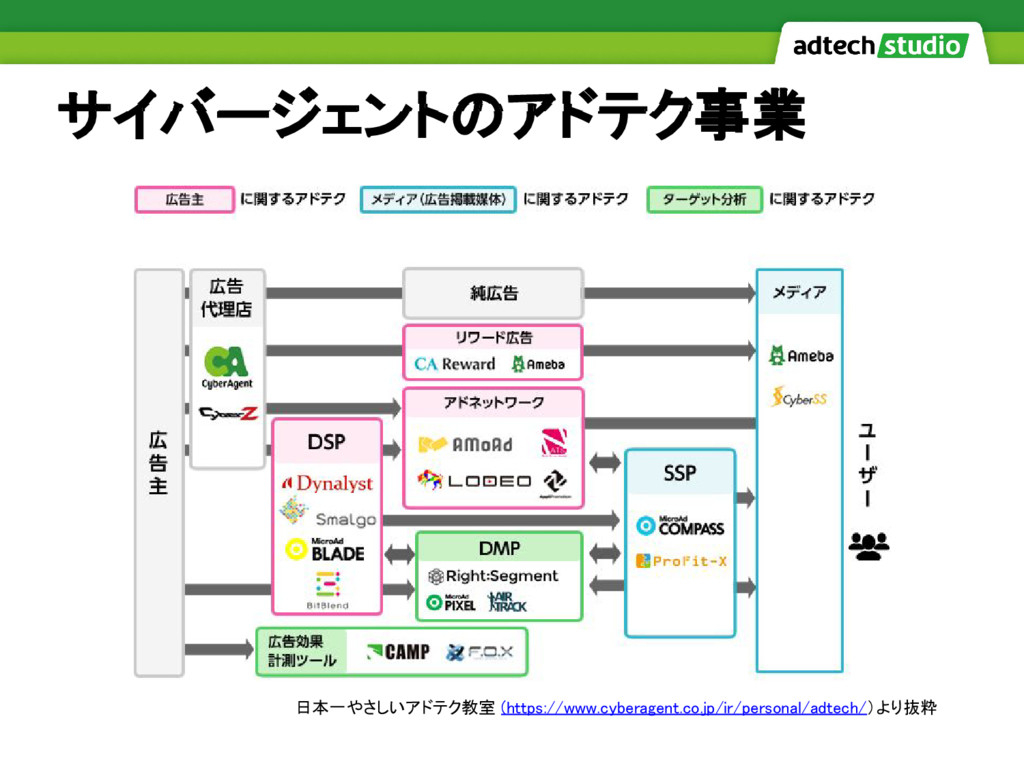
サイバージェントのアドテク事業 日本一やさしいアドテク教室 (https://www.cyberagent.co.jp/ir/personal/adtech/)より抜粋
アドテクスタジオのインフラ環境 弊社がデータセンターにて管理している オンプレミス環境・プライベートクラウド環境 ※プライベートクラウドにはOpenStackを採用 Amazon Web Services環境 ※DirectConnectでデータセンターと接続 Google Cloud
Platform環境 ※VPNでデータセンターと接続 ※Interconnectでの接続を予定
共通基盤構想前の環境
これまでの分析 各プロダクトで必要に応じて環境を構築して分析 ・プログラムによる分析 ・Hadoopを利用したMapReduce処理やSpark処理による分析 ・Amazon Redshiftを利用した分析 ・BigQueryを利用した分析 将来的にPBクラスのデータの分析基盤が 必要となるプロダクトが現れた(2015年) しかも…2ヶ月にはリリース
Hadoop環境① 仕様を検討した結果HBaseが必要ということがわかり 急遽HBaseCon2015に参加したり 複数のディストリビューションを比較した結果 MapR Technologies社のMapR M7の導入を決めました。 以下はプレスリリースにも出していますが採用のポイントです。 各々を別システムとして持つ必要が無いため、データの移動も不要で運用性が高い。 業界スタンダードのNFSインターフェース
やHBaseアプリケーション・インターフェースを備えるため、使 い易く、かつベンダーロックインされない。 NFSインターフェースを持ち、ランダムリード・ライト可能なMapRファイルシステムにより、データの出し 入れが容易となりNASとしても活用可能 。 MapRファイルシステムの優れたパフォーマンスによりハードウェアリソースが最小限で済み、コスト効 果が高い。
Hadoop環境② MapR環境のハードウェア H/W:HP社 SL4540 Gen8 HDD:6TB x 60Disks(Data領域) 1Serverあたり0.36PBのデータをストア可能
・Google BigQueryを利用した分析 各サーバーのログをFluentdを経由してBigQueryにロード BigQuery 必要に応じたアドホック分析 ・Streaming insertすることでほぼリアルタイムで確認が可能 ・他のDWHからの移行ではなくBigQueryを利用する上で新規で作成 ・基本的にスキーマに変更が少なくJOINも少ない
・Amazon Redshiftを利用した分析 各サーバーのログをFluentdを経由してRedshiftにロード Redshift 多角度からの分析を定常的に行う環境で利用 ・ログのスキーマ変更が多い、人が実際にSQLを実行する機会も多く、JOINも多様される ・小さいインスタンスタイプも含め100Node以上利用(2015年10月時点)
Matrix ・Redshiftの元になっているactian社のMatrixを採用し利用が進んでいます 各サーバーのログをMaprFSにストアしMatrixの各NodeにNFS Mountした上で並列ロード Redshiftとの比較 ・S3からのロードができない、JSONまわりの一部関数など一部Redshiftにしかない機能がある ・マネージドサービスではないので運用面はハードウェア含めて必要 ・インスタンスタイプに縛られずハードウェアが選定できる ・元々Redshiftではコスト面からデータ量を減らしていたりししたが オンプレミスで用意することで必要なだけデータをロードできるようになった。
・インスタンス費用を気にして使わないときに停める必要がなくなった ・データもMapRFS側に保存することでS3のコストを削減
Matrix環境のハードウェア H/W:Huawei社 FusionServer RH2288H V3 CPU:Xeon E5-2667 v3 x 2
SSD:1.6TB x 24Disks Memory:16GB x 24(pcs)=384GB Matrix環境
各プロダクトで必要に応じて環境を構築して分析 ・プログラムによる分析 ・Hadoopを利用したMapReduce処理やSpark処理による分析 ・Amazon Redshiftを利用した分析 ・BigQueryを利用した分析 +MapR(MapRFS, MapRDB etc)という選択肢が増えた 振り返ってみると・・・
+Matrixという選択肢が増えた
振り返ってみると・・・ ところが…自由に選択できる結果 ・他のプロダクトのノウハウが活かせなくなり、管理・運用が複雑になっていた ・バージョンアップが手軽にできず、古いバージョンのまま動き続けていた ・それぞれのデータの形式が異なり、共通化が難しくなっていた ・1時間に1回や1日に1回しか利用しないサーバーを常に起動させていることにより リソースの無駄使いが発生していた 各プロダクトで自由に決められる選択肢が増えた!
共通基盤構想 Hadoop編
共通化プロジェクト始動 例えば Hadoop環境の共通化前の状況 Distribution:Apache Hadoop,CDH,MapR Resource Management:Yarn,MR1,Mesos 共通化する上で考えるポイント ・安定稼働できる(冗長化) ・物理コストが低い(ハードウェア、ライセンス)
・運用コストが低い(構築、運用) ・移行コストが低い(動作させる既存ジョブ) ・マルチテナントに対応できる(プロダクト単位で制限)
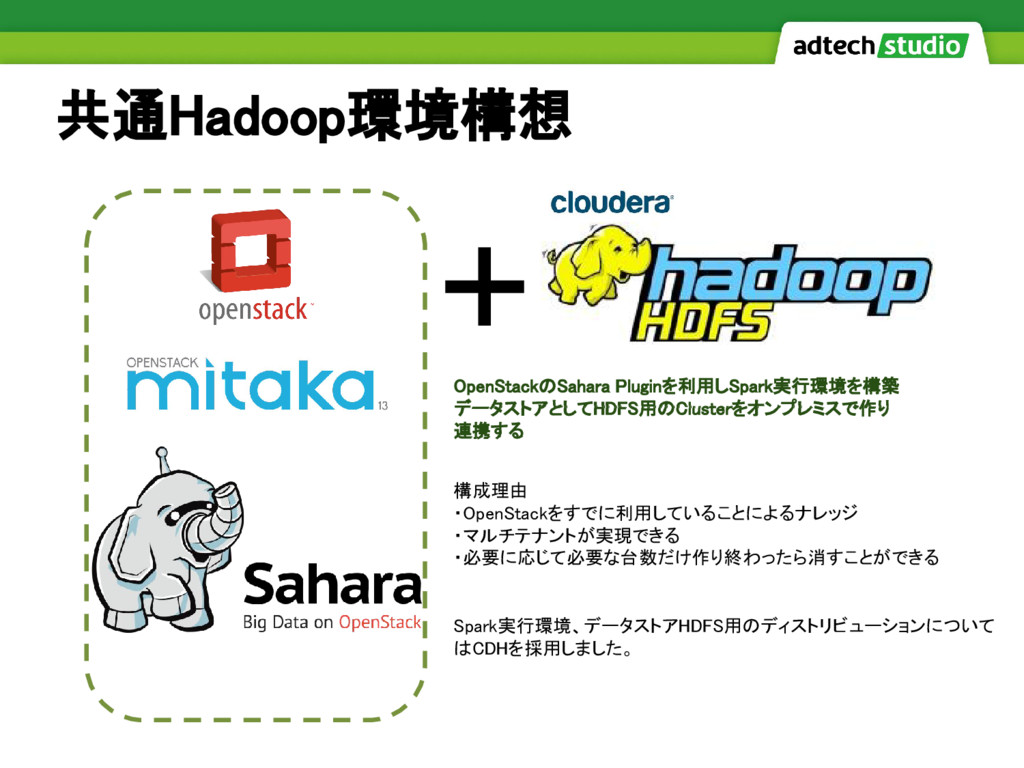
共通Hadoop環境構想 +
OpenStack sahara ・Openstack上でEMRのような データ処理サービスを実現できるコンポーネント ・Dashboard も提供されており Hadoop 環境を容易に構築することができる ・各種ベンダーの Hadoop
環境が plugin で提供されている CDH / MapR / Ambari / etc … ・共通 Hadoop 環境では最新の OpenStack Mitaka を採用
OpenStack sahara ただし・・・・苦労する点も多い ・そもそも日本での事例がほぼ無いので情報が少ない ・各種ベンダーの plugin は最新の version に対応していない ・そもそも各種ベンダーのサポート対象外のものも・・・
・基本的な設定しかサポートされていない 例えば MapR のセキュアクラスタや CDH の Kerberos 対応とか不可能
OpenStack sahara このままだと sahara は使えない・・・・・ので 共通 Hadoop 環境で使えるようにするために、各種 plugin を独自にカスタマイズ
しています。 ・MapR の Secure Cluster に対応 ・CDH の最新 version に対応 (5.7.1) ※plugin は 5.5.0 までしかない ・CDH の Kerberos 対応などなど
共通Hadoop環境構想 OpenStackのSahara Pluginを利用しSpark実行環境を構築 データストアとしてHDFS用のClusterをオンプレミスで作り 連携する + 構成理由 ・OpenStackをすでに利用していることによるナレッジ ・マルチテナントが実現できる ・必要に応じて必要な台数だけ作り終わったら消すことができる
Spark実行環境、データストアHDFS用のディストリビューションについて はCDHを採用しました。
ディストリビューション検討 考えるポイント ・安定稼働できる(冗長化) ・物理コストが低い(ハードウェア、ライセンス) ・運用コストが低い(構築、運用) ・移行コストが低い(動作させる既存ジョブ) ・マルチテナントに対応できる(プロダクト単位で制限) MapR ・C/C++での実装のため動作が安定している ・冗長構成可能(ライセンス必要)
・Sahara Pluginも最新版で比較的容易にカスタム可能 ・マルチテナントは標準のSecure ClusterとTicketで実現可能 ・既存環境からの移行コストが高い(MapRのJARと衝突する)
CDH ・冗長構成可能(ライセンス不要) ・Sahara Pluginでカスタムして動かすのは難易度が高い ・マルチテナントはkerberos認証を利用して可能 ・既存環境からの移行コストが低い ディストリビューション検討 様々な既存の環境から共通環境へのスムーズな移行を優先した結果、CDHを採用 考えるポイント ・安定稼働できる(冗長化)
・物理コストが低い(ハードウェア、ライセンス) ・運用コストが低い(構築、運用) ・移行コストが低い(動作させる既存ジョブ) ・マルチテナントに対応できる(プロダクト単位で制限)
Spark実行環境用OpenStackスペック H/W: Huawei X6800 (4U Chassis) x 12 Huawei XH620
x 96 CPU Xeon E5-2680 v3 12(Core) x 2(HT) x 2(CPU) x96(Node)=Total 4608Core MEM DDR4 RDIMM 16G x 16(pcs) x 96(Node) = Total Memory 24.5TB LOCAL DISK SSD NETWORK 10G Network, Aggregation 40G Switch
Spark実行環境用OpenStack Flavor インスタンスタイプ 6Core (MEM 28.8GB SSD 50GB) 12Core (MEM
57.6GB SSD 100GB) 24Core (MEM 115.2GB SSD 200GB)
Command Line Tool 実際に利用する事を考えると手動でClusterの起動・停止や 都度Jarファイルを新しいClusterにもってきてspark-submit なんて事はしたくないですよね? Jarファイル等を置くClient用のサーバーはSaharaではなく 通常のOpenstackインスタンスとして構築(Dockerを利用) Clusterの起動・停止については、python-saharaclientをラップし hadoopまわりの設定を書き換える機能を追加した
独自のコマンドをgolangで作成しています。 例) fennec list Cluster一覧表示 fennec create -i CLUSTER_NAME Cluster構築&Hadoop接続設定 fennec reconfigure -i CLUSTER_NAME Cluster情報をもとにHadoop接続再設定 fennec delete -i CLUSTER_NAME Clusterの削除
選択の自由度があがった結果として顕在化した問題点 他のプロダクトのノウハウが活かせなくなり、管理・運用が複雑になっていた バージョンアップが手軽にできず、古いバージョンのまま動き続けていた それぞれのデータの形式が異なり、共通化が難しくなっていた 1時間に1回や1日に1回しか利用しないサーバーを常に起動させていることにより リソースの無駄使いが発生していた 選択の自由度があがった結果として顕在化した問題点 他のプロダクトのノウハウが活かせなくなり、管理・運用が複雑になっていた バージョンアップが手軽にできず、古いバージョンのまま動き続けていた それぞれのデータの形式が異なり、共通化が難しくなっていた
1時間に1回や1日に1回しか利用しないサーバーを常に起動させていることにより リソースの無駄使いが発生していた 選択の自由度があがった結果として顕在化した問題点 他のプロダクトのノウハウが活かせなくなり、管理・運用が複雑になっていた バージョンアップが手軽にできず、古いバージョンのまま動き続けていた それぞれのデータの形式が異なり、共通化が難しくなっていた 1時間に1回や1日に1回しか利用しないサーバーを常に起動させていることにより リソースの無駄使いが発生していた 選択の自由度があがった結果として顕在化した問題点 他のプロダクトのノウハウが活かせなくなり、管理・運用が複雑になっていた バージョンアップが手軽にできず、古いバージョンのまま動き続けていた それぞれのデータの形式が異なり、共通化が難しくなっていた 1時間に1回や1日に1回しか利用しないサーバーを常に起動させていることにより リソースの無駄使いが発生していた 実際、問題は解決できたのか? 実はMapRからCDHに変更したことで、構築が終わっていない部分がありテスト段階なんです・・・。 今後各プロダクトのHadoop環境については、段階的に Sahara環境への移行を進めていく予定です。 振り返り
共通基盤構想 Log編
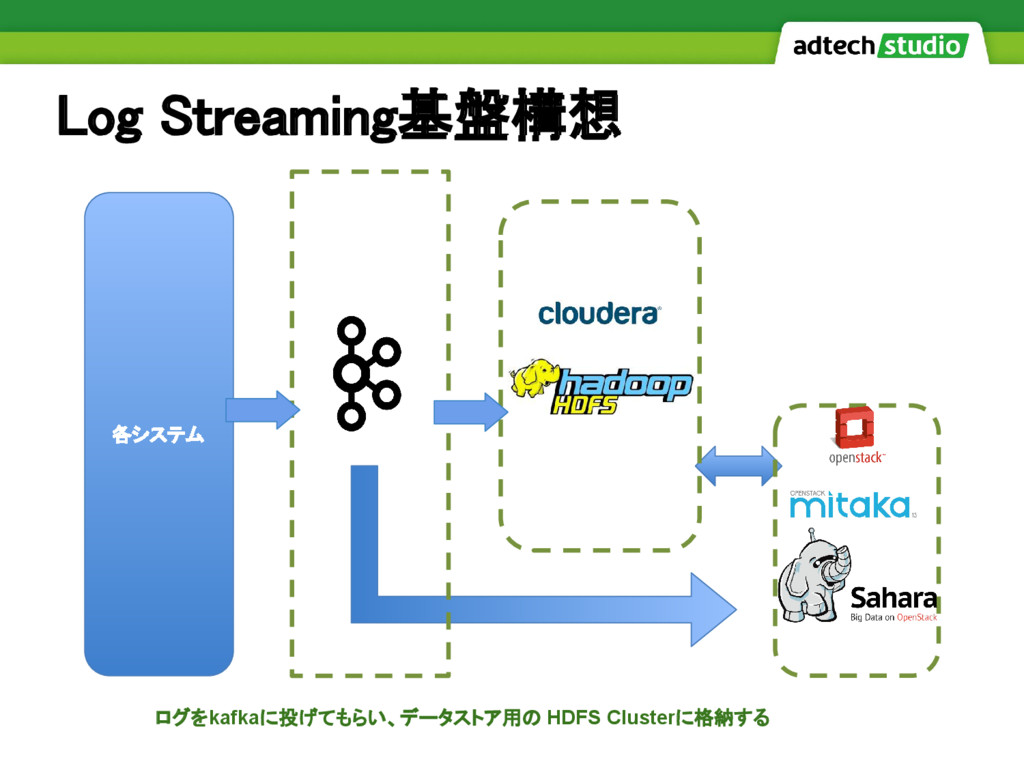
それぞれのデータの形式が異なり、共通化が難しくなっていた サーバーのローカルに一度出力したログをfluentdで一定間隔で送り付ける方式が多数で インスタンスのダウン時にログが取り出せない問題 Log Format問題 そうだ、Log Streaming基盤を作ろう!
Log Streaming基盤構想 各システム ログをkafkaに投げてもらい、データストア用の HDFS Clusterに格納する
将来の展望
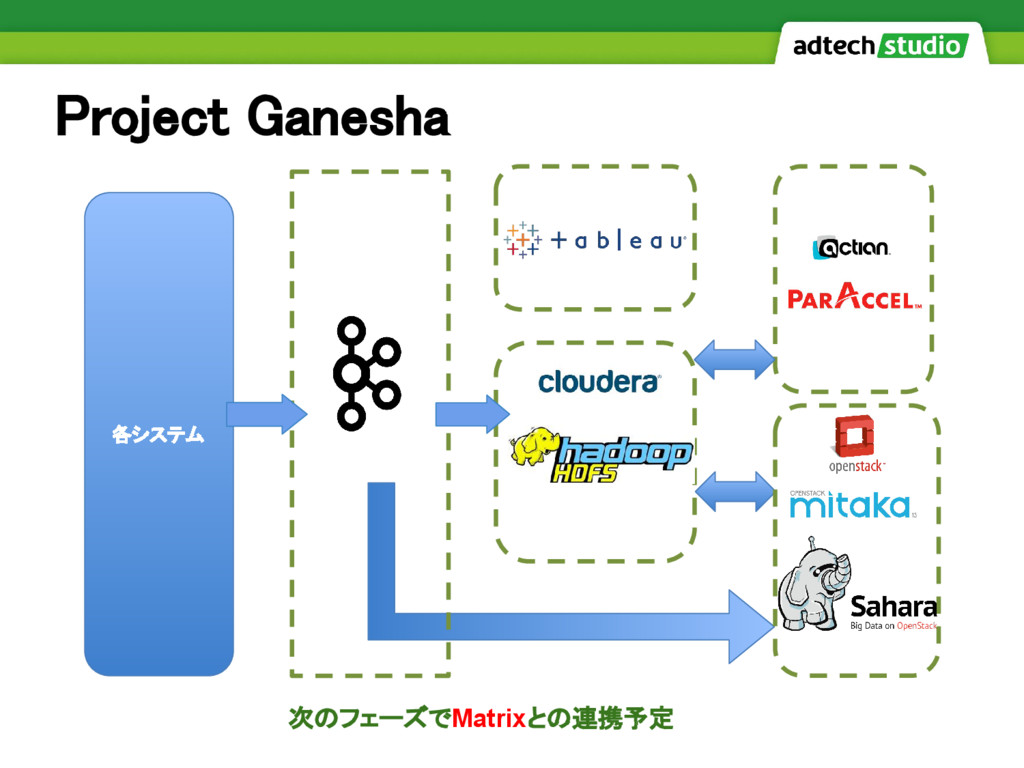
Project Ganesha 各システム 次のフェーズでMatrixとの連携予定
Project Ganesha 今後の提供予定 サービス監視 個々の監視+サービスとしての監視 DataFlow データ並列処理モデル MetaStore データの対応情報を管理 Schema
Registry スキーマ管理 Docker環境
サイバーエージェント アドテクスタジオ Tech Blog 始めました! https://adtech.cyberagent.io/techblog/ 一緒にアドテクスタジオを盛り上げてくれる方 絶賛募集中です https://www.cyberagent.co.jp/recruit/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}