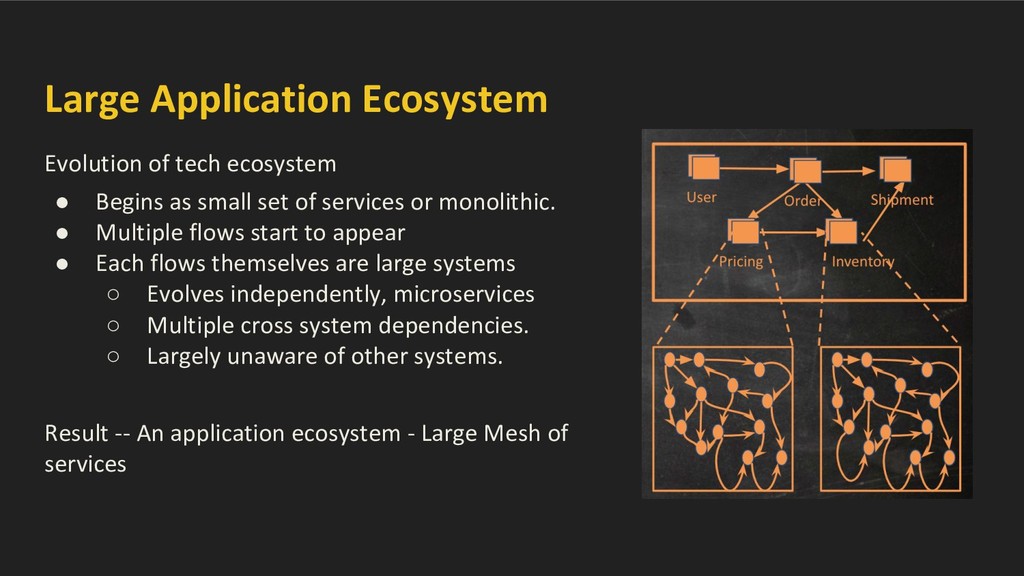
small set of services or monolithic. • Multiple flows start to appear • Each flows themselves are large systems ◦ Evolves independently, microservices ◦ Multiple cross system dependencies. ◦ Largely unaware of other systems. Result -- An application ecosystem - Large Mesh of services
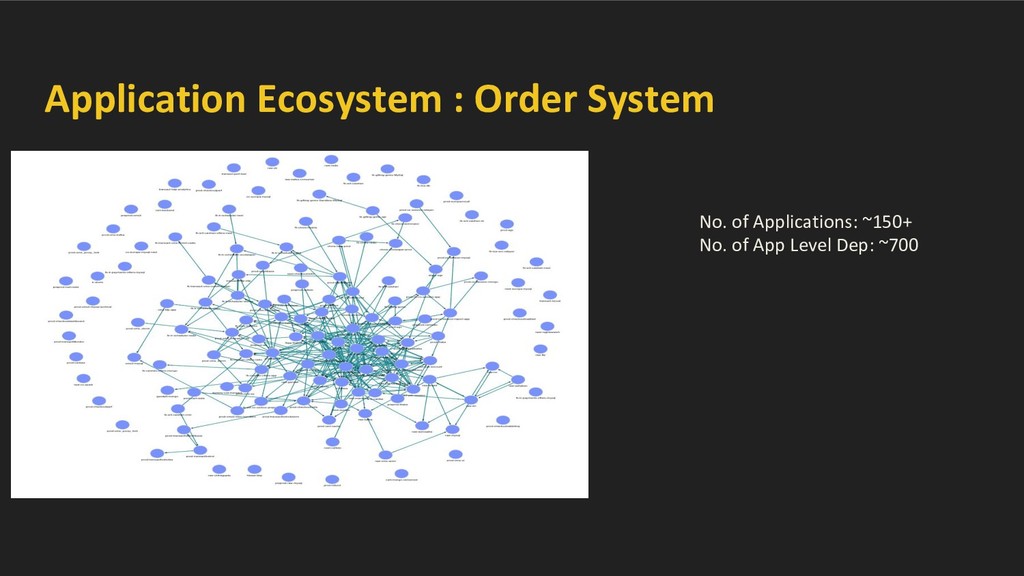
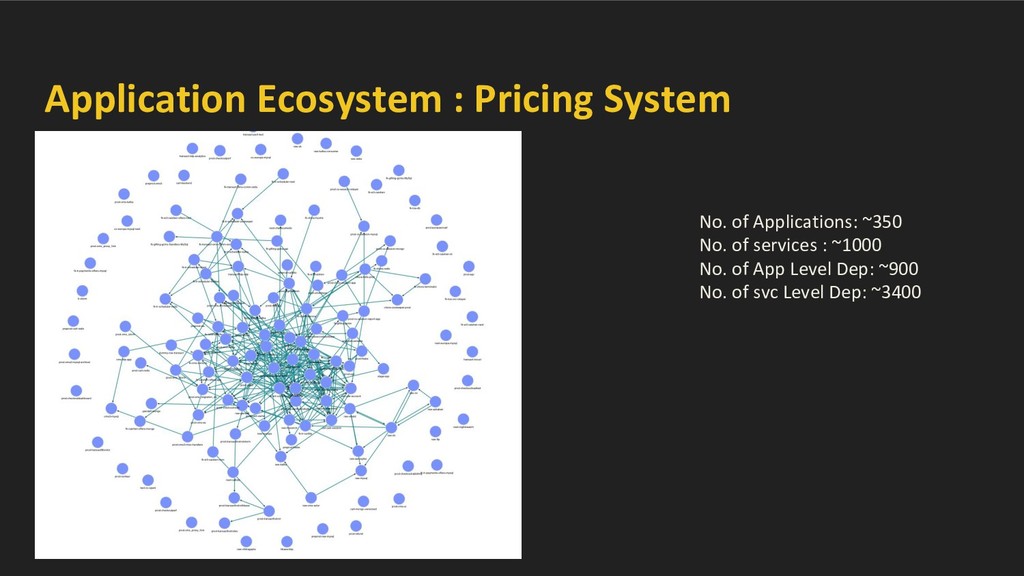
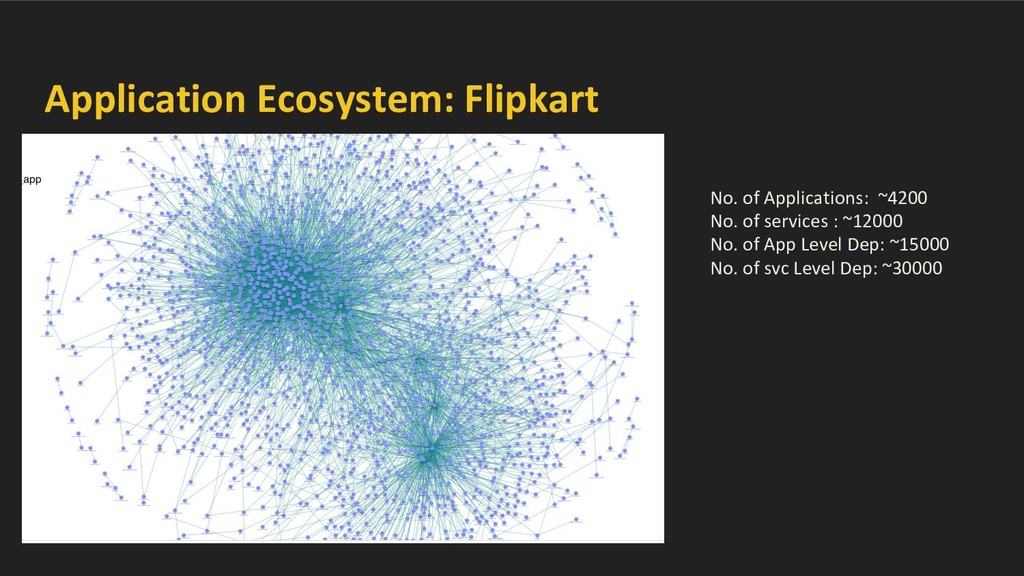
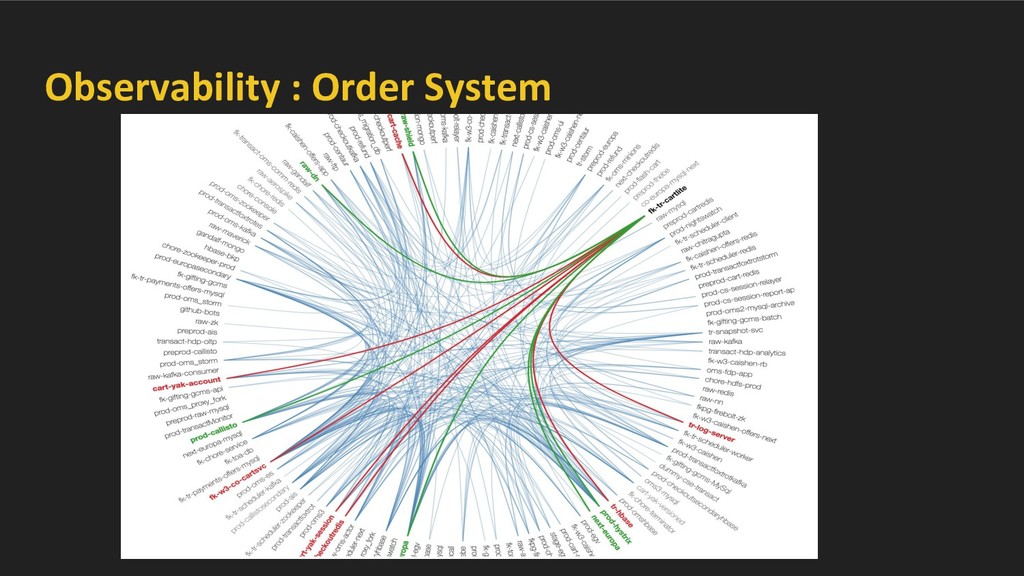
large mesh of services. Challenges - • Observability ◦ Service interactions and their evolution. ◦ Service and data abstractions. ◦ Chains of microservices. ◦ Runtime behavior and failure analysis/impact • Handling Failures ◦ Scale - small / large - wide spread disasters ◦ Impact - Financial, Legal/Compliance, Reputation etc. ◦ Business continuity even in face of large disasters -- BCP charter ▪ BCP Flows - business flow to sustain with wide variety of disasters. ▪ Work with tech teams to ensure BCP flows are adhered. ▪ Provide tooling to ensure BCP.
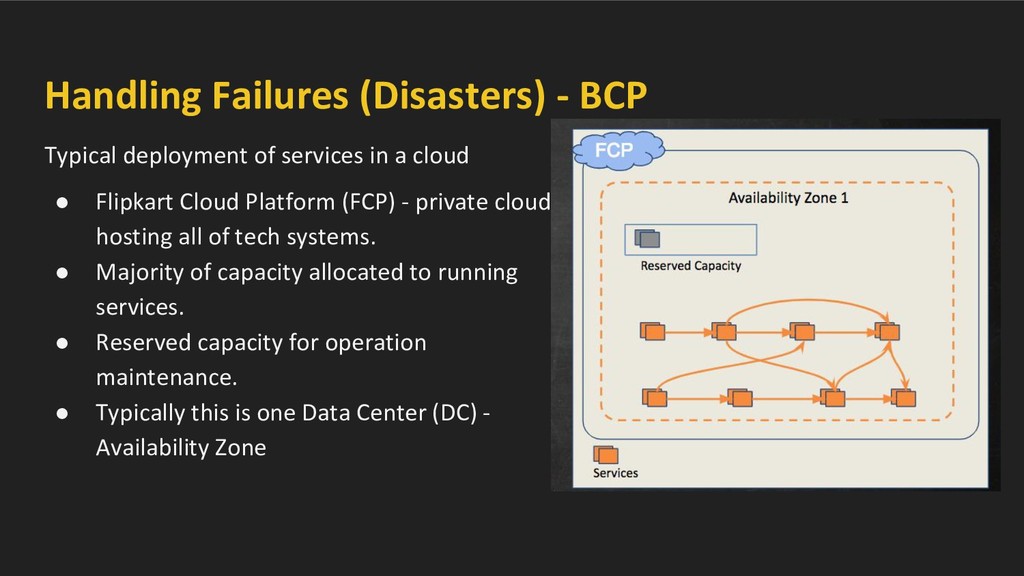
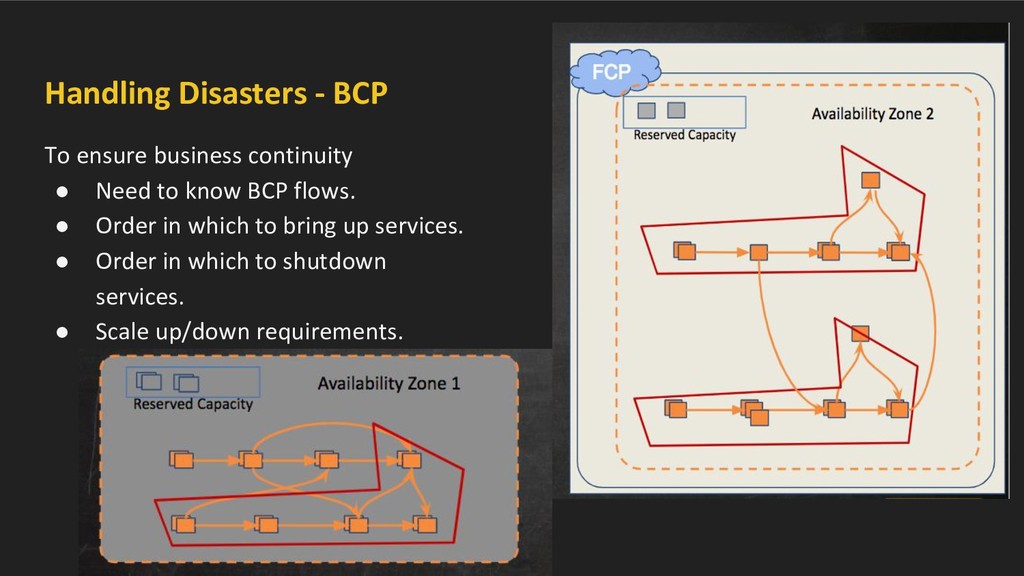
a cloud • Flipkart Cloud Platform (FCP) - private cloud hosting all of tech systems. • Majority of capacity allocated to running services. • Reserved capacity for operation maintenance. • Typically this is one Data Center (DC) - Availability Zone
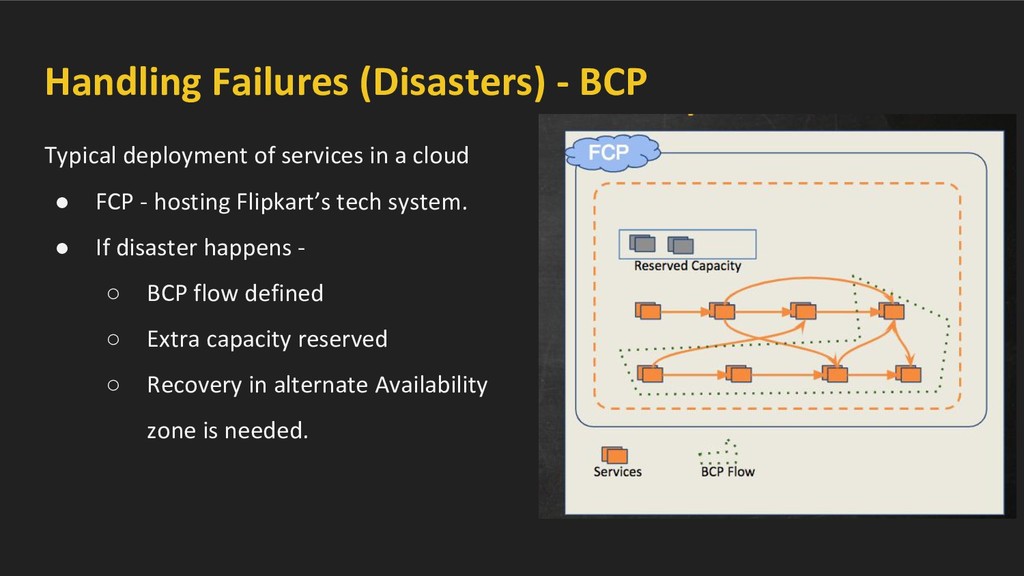
a cloud • FCP - hosting Flipkart’s tech system. • If disaster happens - ◦ BCP flow defined ◦ Extra capacity reserved ◦ Recovery in alternate Availability zone is needed.
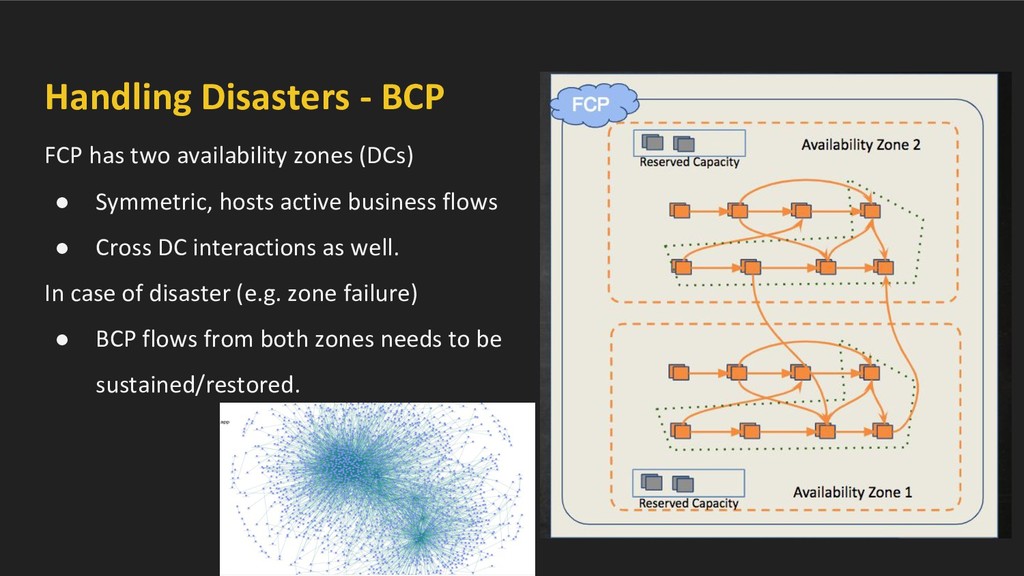
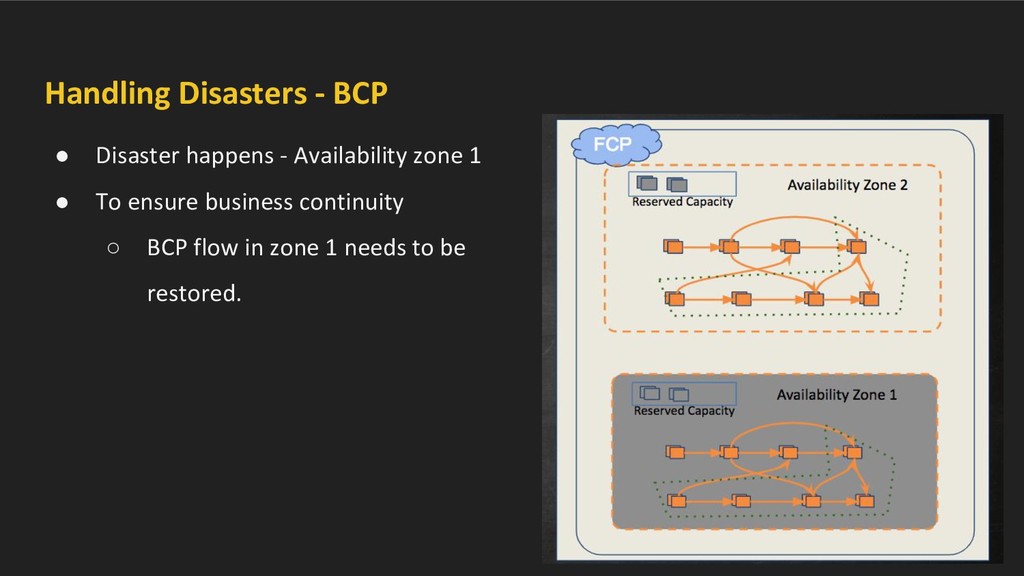
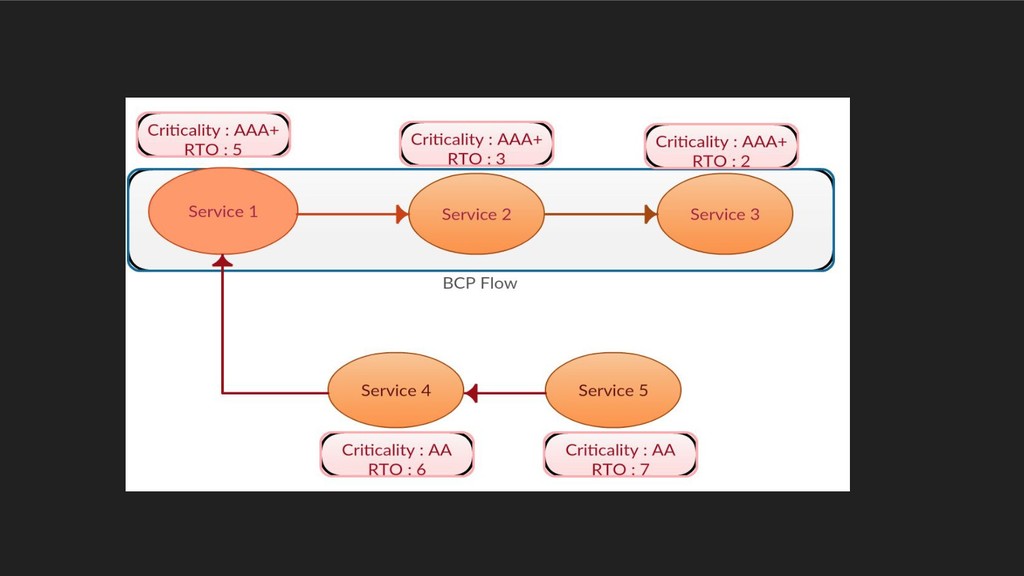
• Symmetric, hosts active business flows • Cross DC interactions as well. In case of disaster (e.g. zone failure) • BCP flows from both zones needs to be sustained/restored.
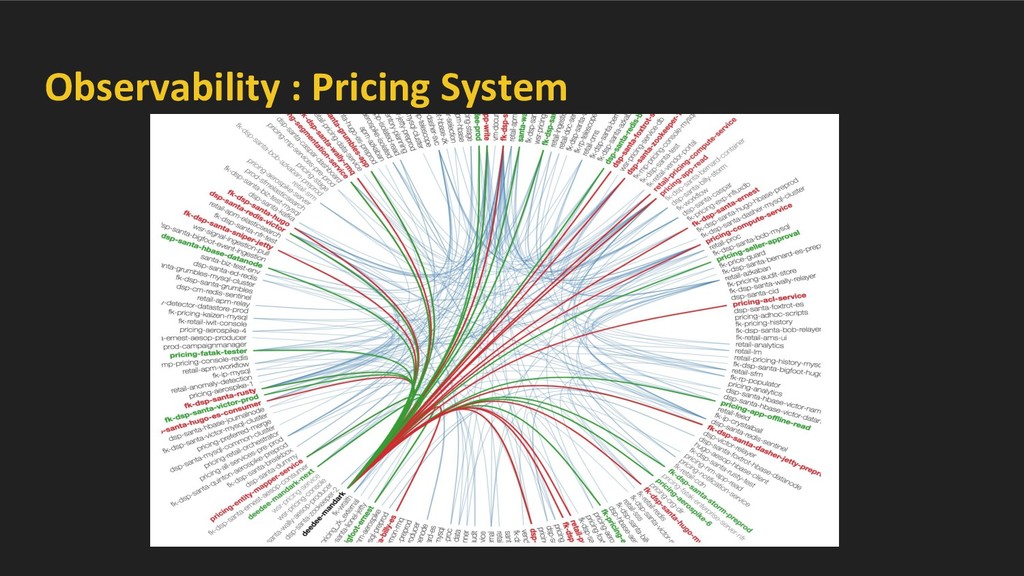
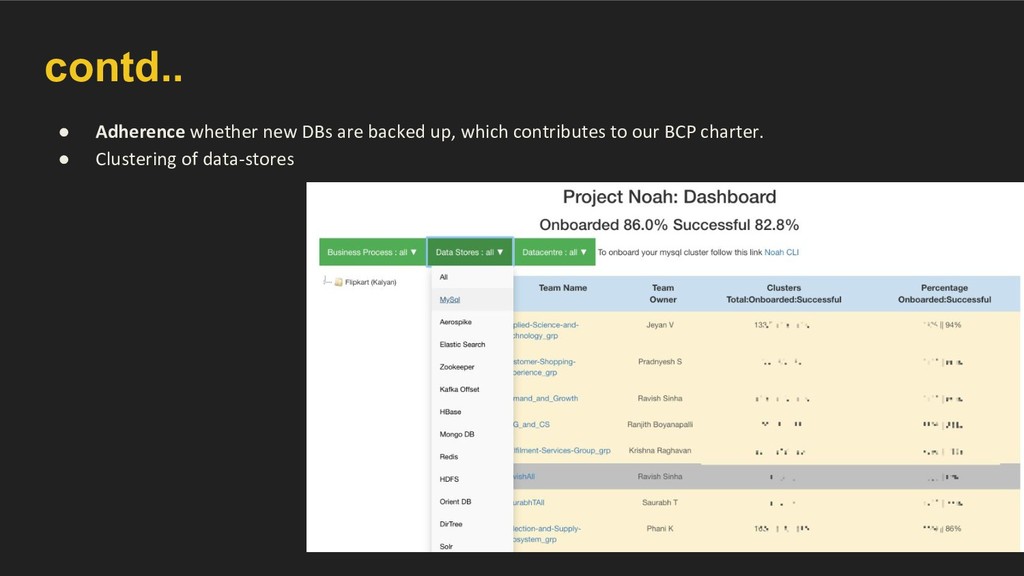
manner. ◦ By analysing network traffic and stitching it with higher level service-details. ◦ Intelligent data-store cluster recognition. • Once this core layer has been built, enable domain specific data enrichment on top of this core layer.
something off the shelf: ◦ No other open-source product available. ◦ Flipkart has its own private cloud, with its own constructs, it was better to build something from scratch. ◦ Flexibility to enable multiple business use-cases on top of bases layer. ◦ We did study products like Netflix Vizceral and Microsoft’s Service Map. • Factors Influenced our choices: ◦ Did not want application intrusion. ◦ Running network data collection agent on Motherships instead on Virtual Machines. ◦ Have control of the environments in which our agent is running. ◦ Availability of information from multiple infra components to stitch and present it.
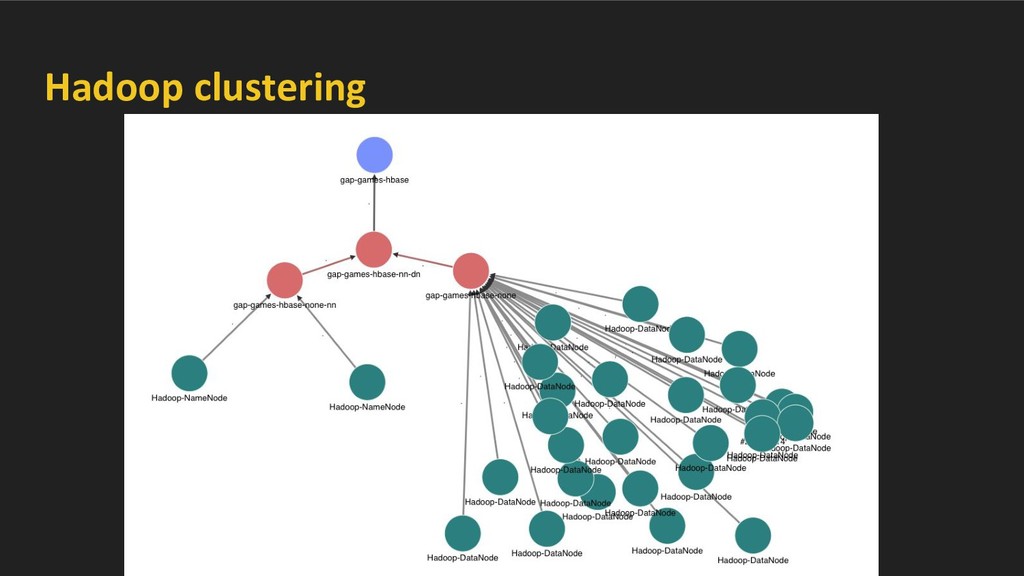
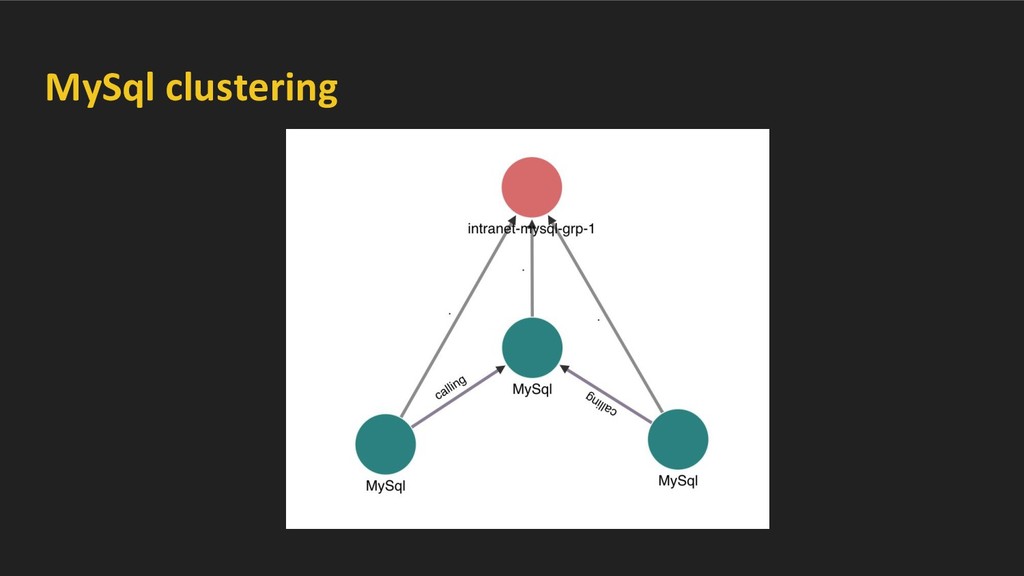
using port scan. • Cluster data-stores on the basis of services running on VMs and network topology. • We cluster Hadoop, MySql, ElasticSearch, Redis, Aerospike, MongoDB and many more.
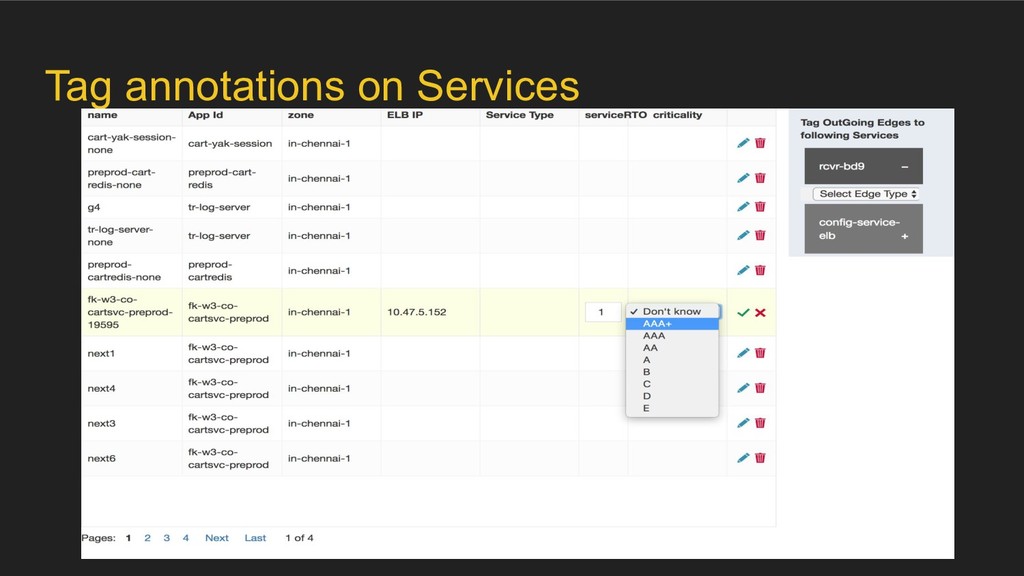
service-graph layer. • Overlay definition - a set of possible annotations over the graph nodes and edges • Meeseeks provides APIs to ◦ Create / register custom overlay ◦ Annotate the base Meeseeks graph with custom overlay data ◦ Query based on the annotations
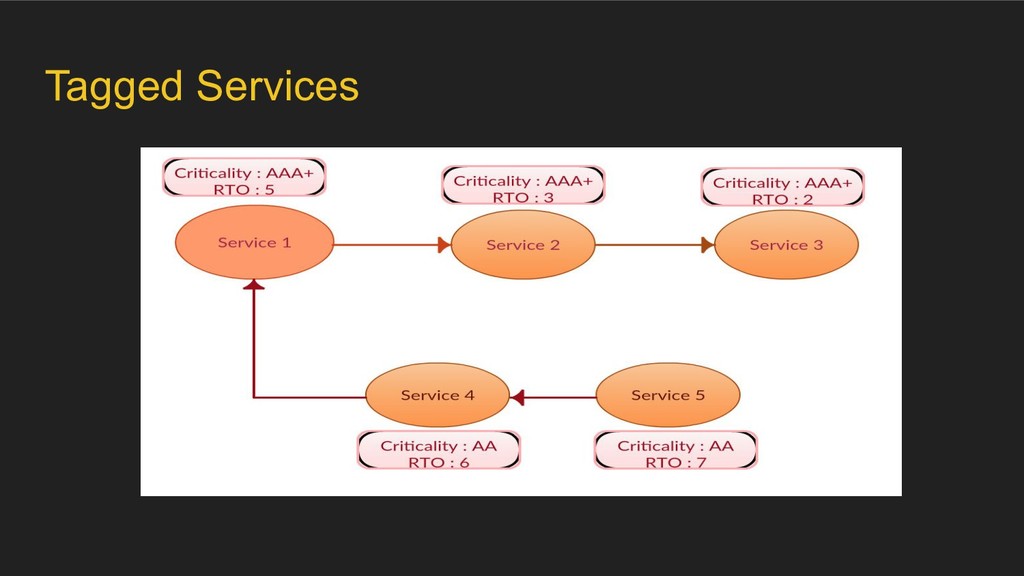
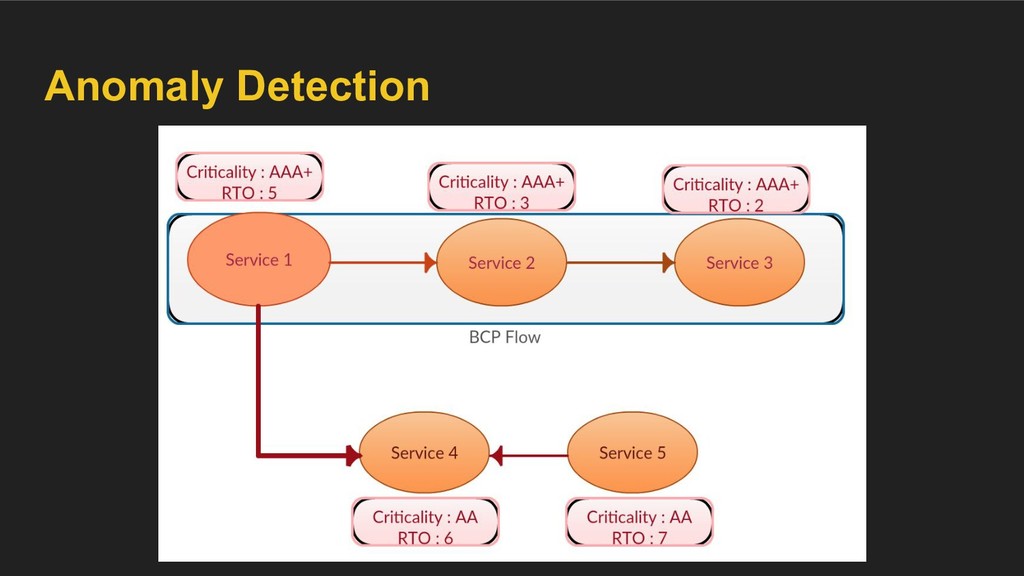
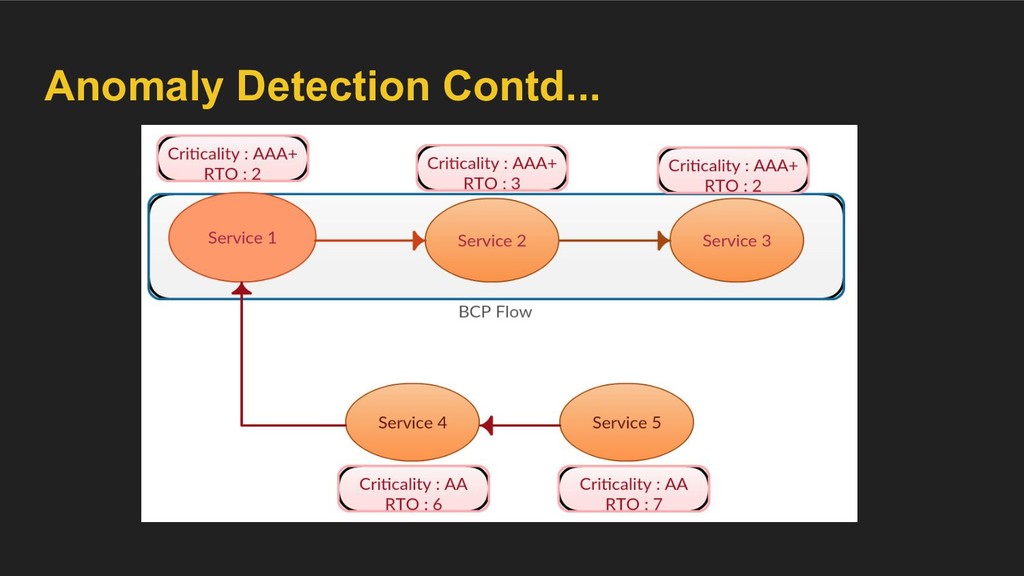
event to the Backup/DR infrastructure ◦ Validate schedules configured for recovery point objective etc. • BCP overlay ◦ Tag services with a certain “criticality level” and a recovery time objective for the same in case of a disaster ◦ Tag edges as “essential”, “optional” etc. ◦ Detect anomalies.
and boot order in case of disaster. • Cleaning the clutter of services: ◦ Architects use it to reduce the number of microservices, to remove unwanted dependencies between their services to clean their micro-svc ecosystem. • Verification: Surface violations in run-time interactions, which go against desired design.
▪ Netfilter connection tracking information ◦ ERSPAN encapsulated SYN duplicated to a processor host via a GRE tunnel ▪ Support available in network devices • Additional Overlays like, Data-Backup & System health • Enable construct like service-orchestration. • Make it open-source.
Network monitoring tools to form real-time network topologies. • Enrich this data to build service topologies. • Use data overlay constructs to manage/evolve domains like BCP. • Use above overlay data to solve various domain specific challenges.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}