on a unique mission • What we do? ◦ Keep services running, scale them and make them reliable • How we do it? ◦ A mix of proactive and reactive engineering to make our services better • Why do we do it? ◦ Users expect speed, reliability and correct operation of services Site Reliability Engineering
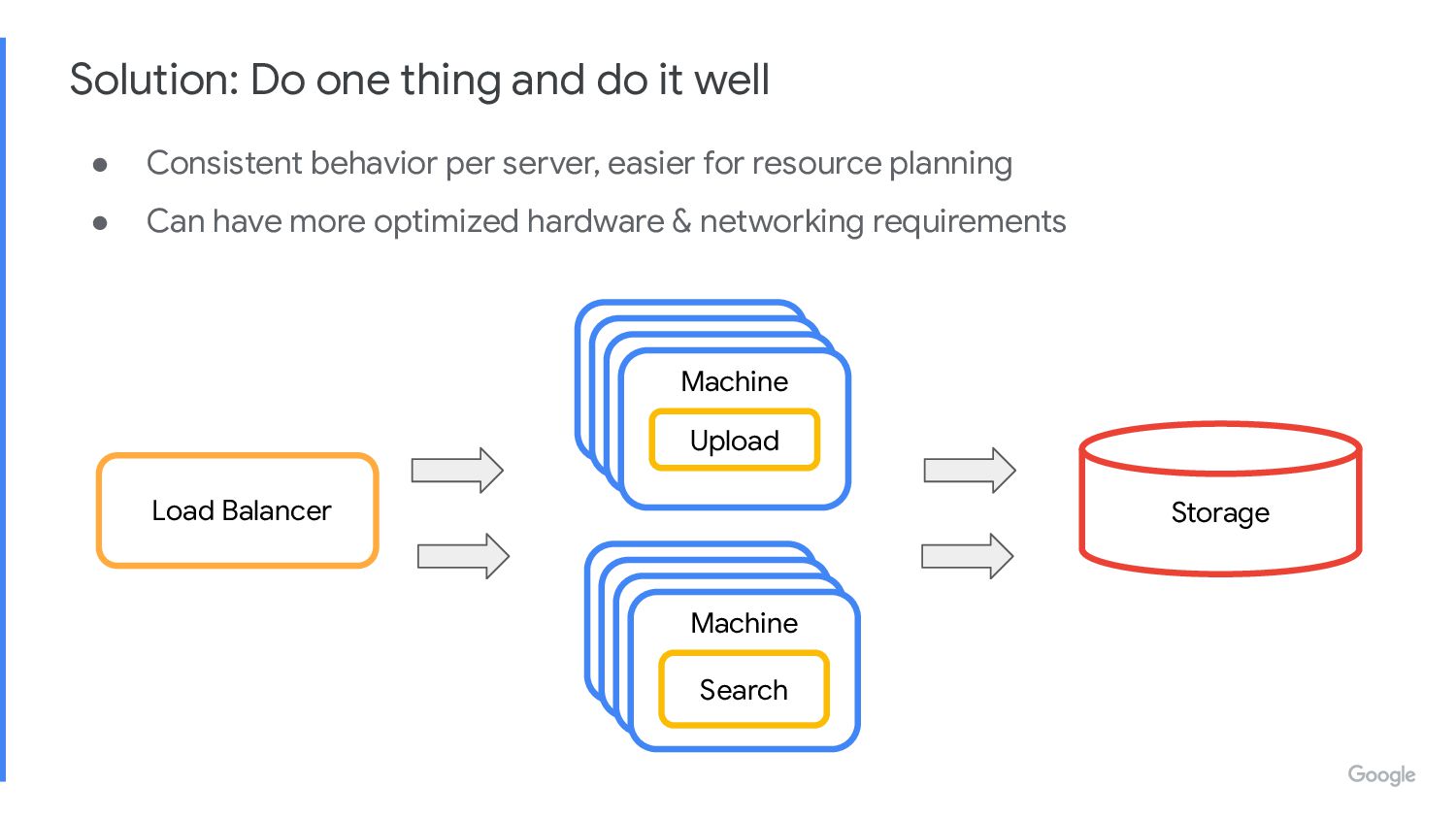
◦ Long duration of requests ◦ Variable payload as images sizes / type might vary ◦ Optional: Image processing might work better on different hardware e.g. GPU • Image Serving Operation: ◦ Relatively High QPS ◦ Short duration of requests ◦ Optimized for latency instead of throughput • Mix of requests can change, hard plan for capacity and operation of server Limitation: Doing different things at the same time
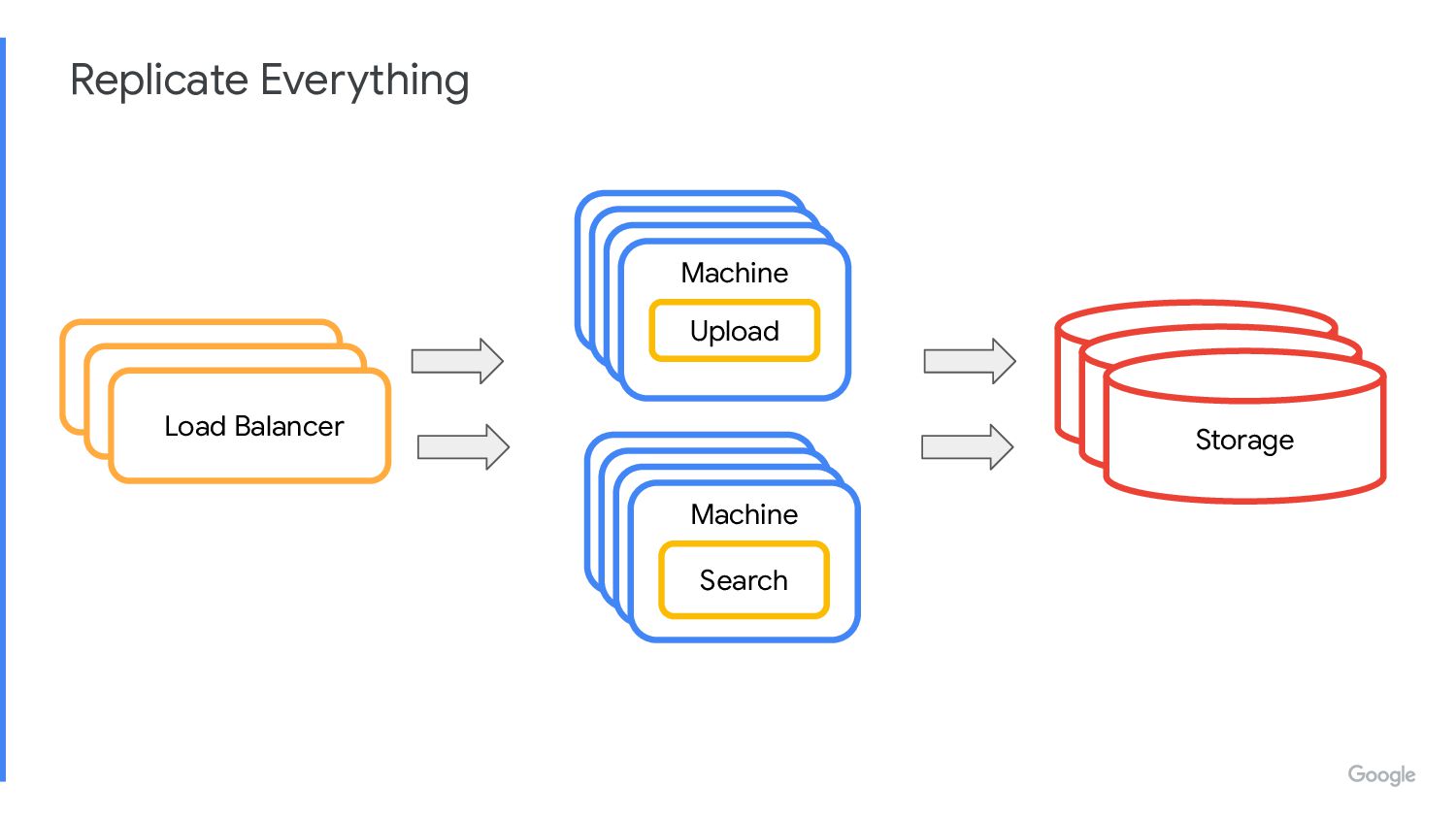
function can scale horizontally • Work out the hardware requirements for each function ◦ CPU, network, disk accesses, RAM ◦ Sanity check expected concurrent connections, etc • Look for ways to improve ◦ Any single points of failure or other weaknesses? ◦ Is it efficient in terms of resources? ◦ How can the design accommodate change? ◦ Is there a better/simpler design? Iterate on the design
high scalable systems. • As your service grows, what will start to fail and how will that show itself? • What failure modes can you prevent before they start? • How can you keep serving and growing your service in spite of failures? Considering Failure Modes
of failures • Hardware failures: ◦ Server ◦ Network Switch ◦ Disk / Storage • Ensure multiple failure domains, no single point of failure • Build software to handle failovers properly Component Failures
your service crash ◦ Deliberate attack ◦ Just bad luck • No great solutions, but possible mitigations: ◦ Rate limiting request per user ◦ Limiting the size of the request per user ◦ Pro-actively blocking untrustworthy users ◦ Fuzz testing to ensure bad inputs are handled properly Query Of Death
avoid changes that are applied instantaneously everywhere • Slow rollouts with proper canaring ◦ Binaries ◦ Configurations • Rate limiting administrative commands • Avoid multiple changes in more than one zones Avoid Global Change
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}