Presentation from GDG DevFest Ukraine 2018 - the biggest community-driven Google tech conference in the CEE.
Learn more at: https://devfest.gdg.org.ua
__
In this session we will share practical “battle stories”. Real ones, lots of them. This will be a retrospective of >1 year journey, over the course of which Nimses engineers were adopting Google Cloud Platform services such as:
Google Kubernetes Engine
Google Cloud Datastore
Google Cloud Spanner
Google BigQuery
Google Cloud SQL
Cloud Pub/Sub
Cloud Dataflow -Cloud Dataproc
Nimses (http://http://nimses.com) is a location-based social mobile platform that turns every minute of user’s time into a unit of value. Each minute of a person's life within Nimses generates a single unit of digital currency called Nim. Nimses users can spend Nims to interact with each other and make purchases from local vendors, based on geolocation. Nimses helps people and businesses to connect with each other in a meaningful way, with value of each action measured in Nims.
As of today over 5 million people are using Nimses across 20 countries.
In July 2017 Nimses has decided to migrate all of it's services into Google Cloud Platform. The main driver was rapid growth of user base that elevated requirements for infrastructure scalability and data storage to seemingly unreachable levels.
Together with Google Cloud team Nimses engineers were able to migrate main application services into Google Kubernetes Engine in a matter of few weeks. Later on Nimses has gradually taped on other platform services (Datastore, BigQuery, Dataflow), allowing the team to analyze large amounts of data and develop new features faster.
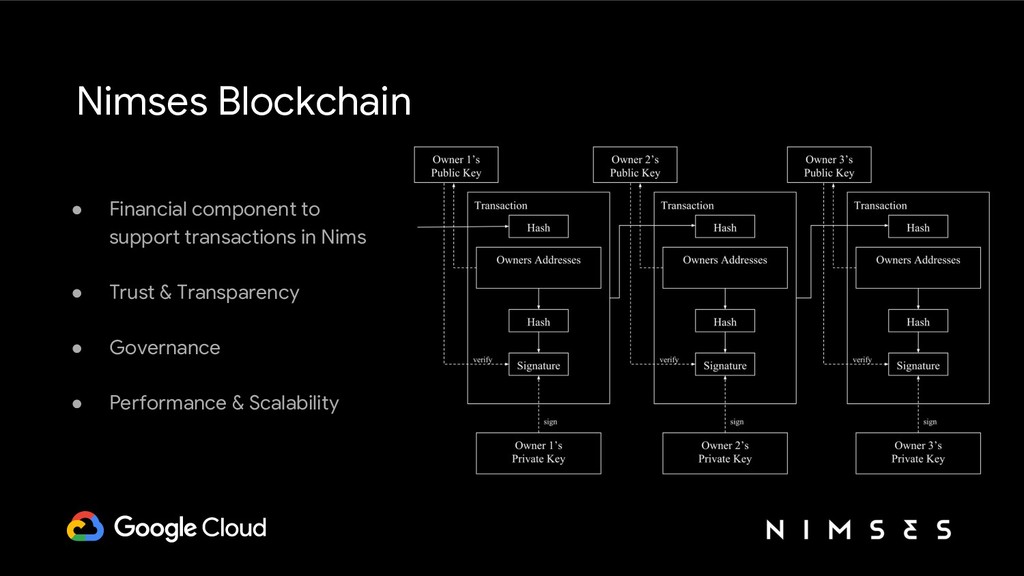
Most recently Nimses has launched Nimses Blockchain (https://nimses.com/posts/blockchain-beta/) payment platform, with ledger of transactions powered by Google Cloud Spanner.
{kind=link}
{kind=link}
![Who are we? Dmitriy Novakovskiy Cloud Sales Engineer @Google [email protected]](https://files.speakerdeck.com/presentations/3a839a6daf7640e88f2471dc4e84ff64/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}