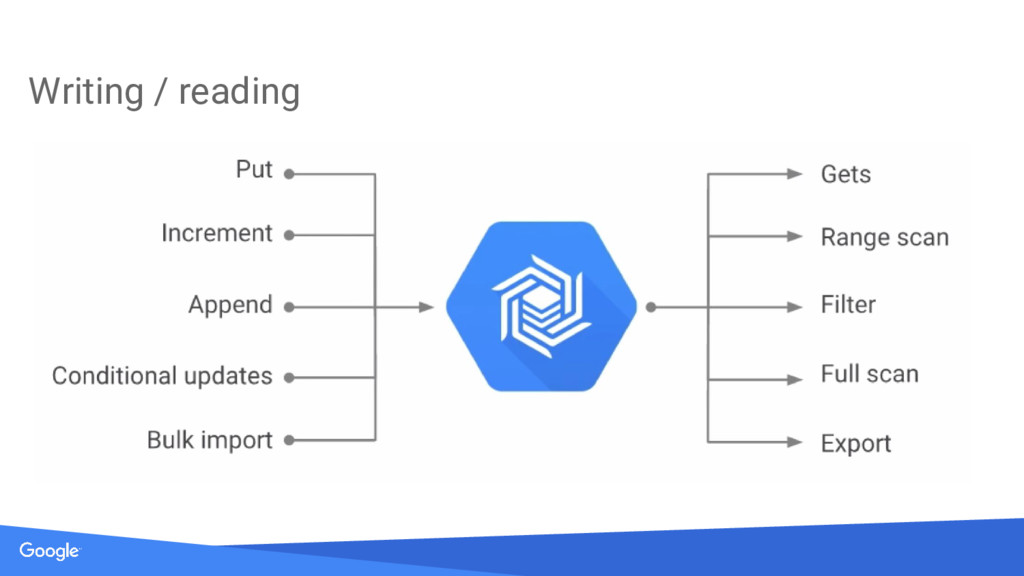
non erat sem Motivation Variety of structured/semi-structured data • URL content and associated metadata (contents, crawl metadata, links, anchors, pagerank, etc.) • Geographic locations (physical entities: shops, restaurants, etc.; roads, satellite image data, user annotations, etc.) Scalable system for dealing with high volume and high velocity • Concurrent support for services supporting billions of users • Petabyte-scale data size
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
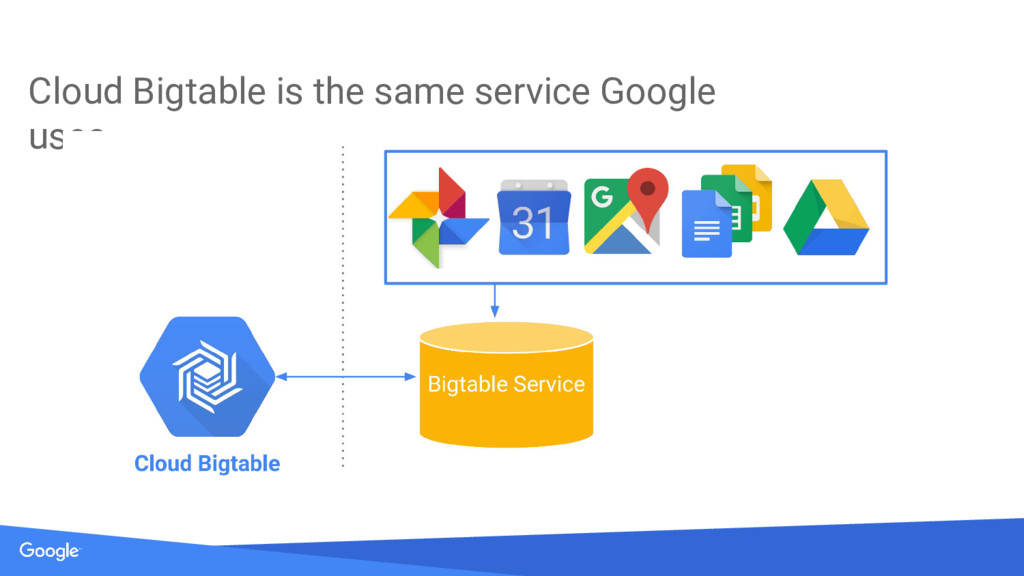{kind=link}
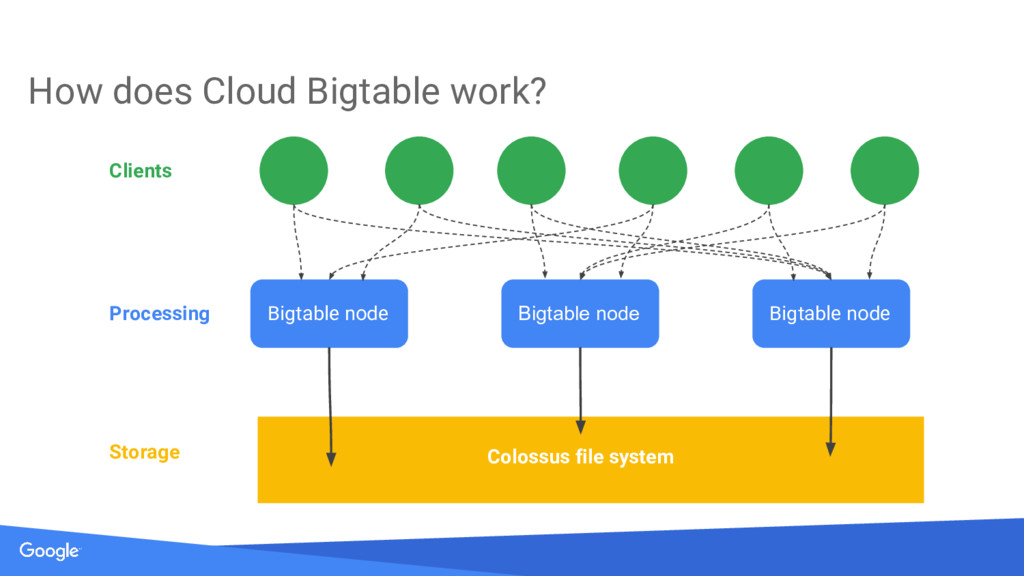{kind=link}
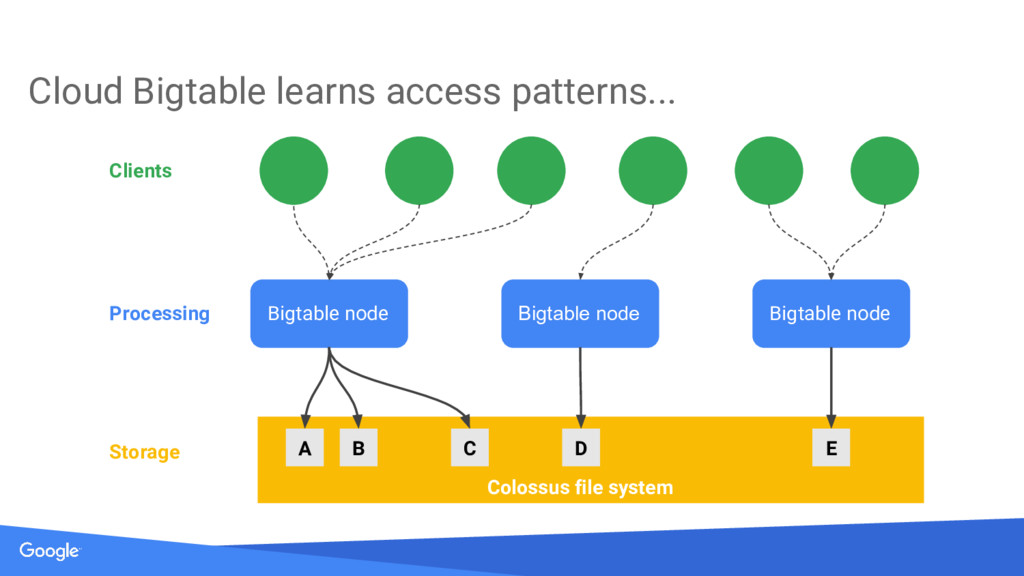{kind=link}
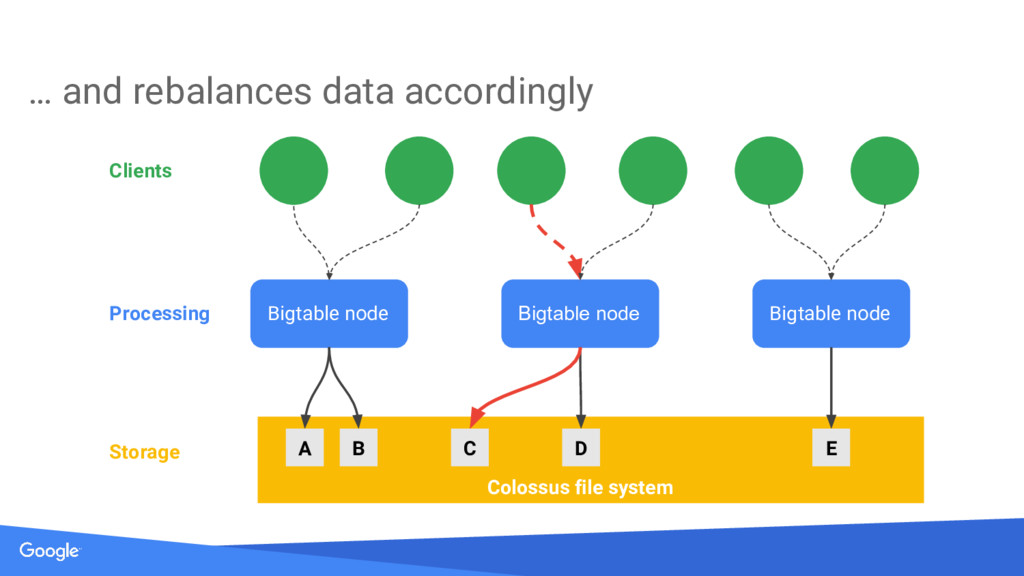{kind=link}
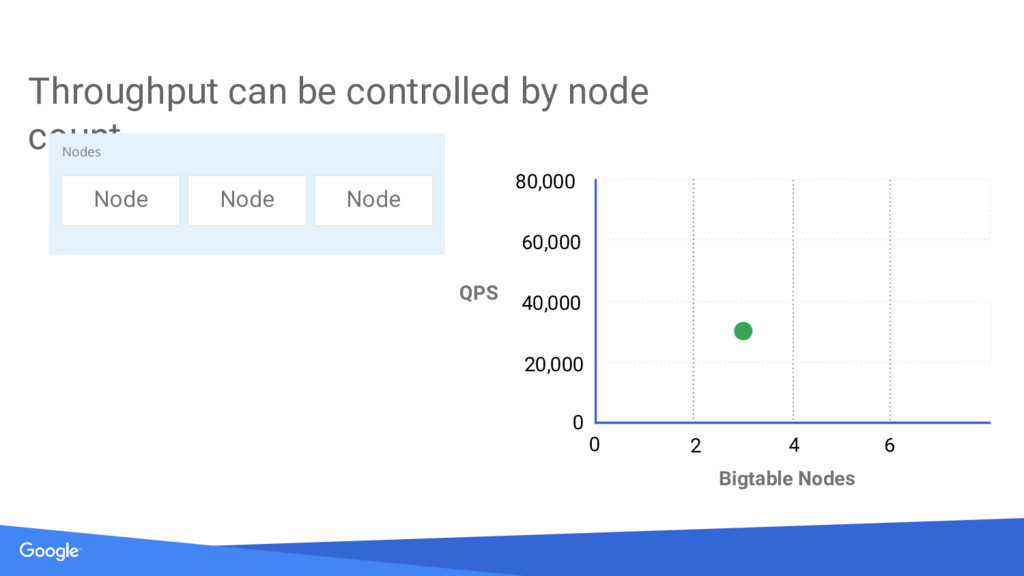{kind=link}
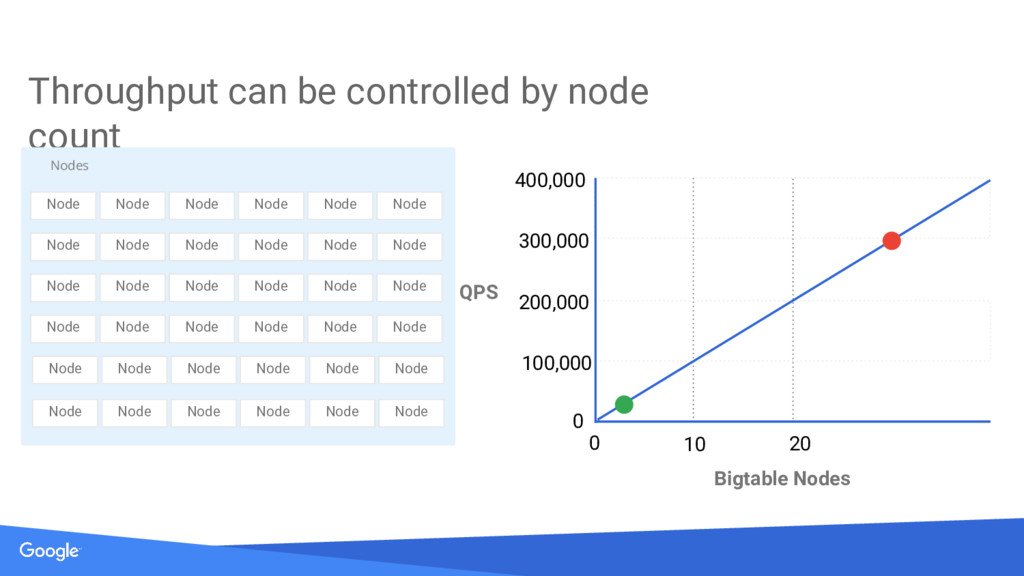{kind=link}
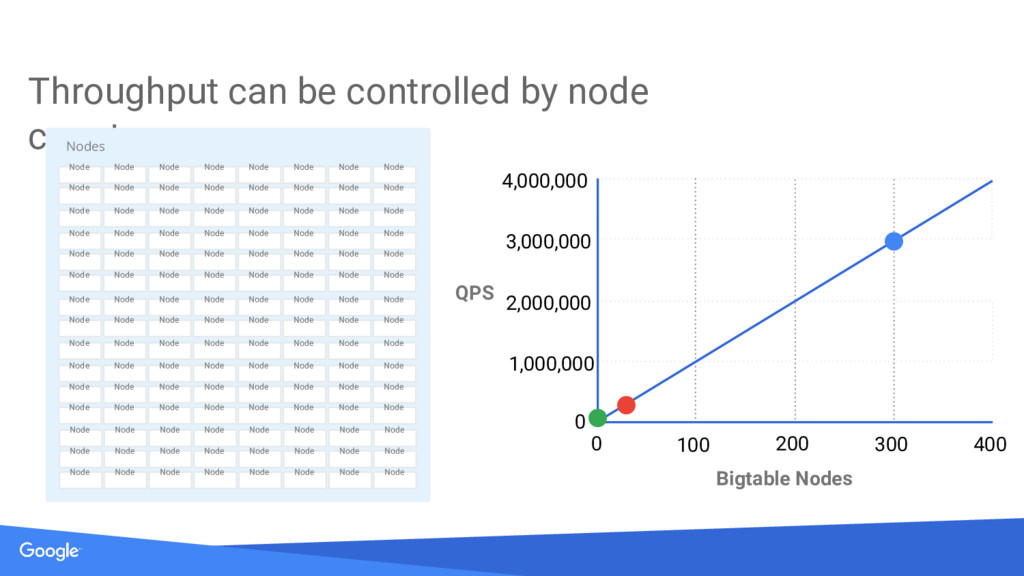{kind=link}
{kind=link}
{kind=link}
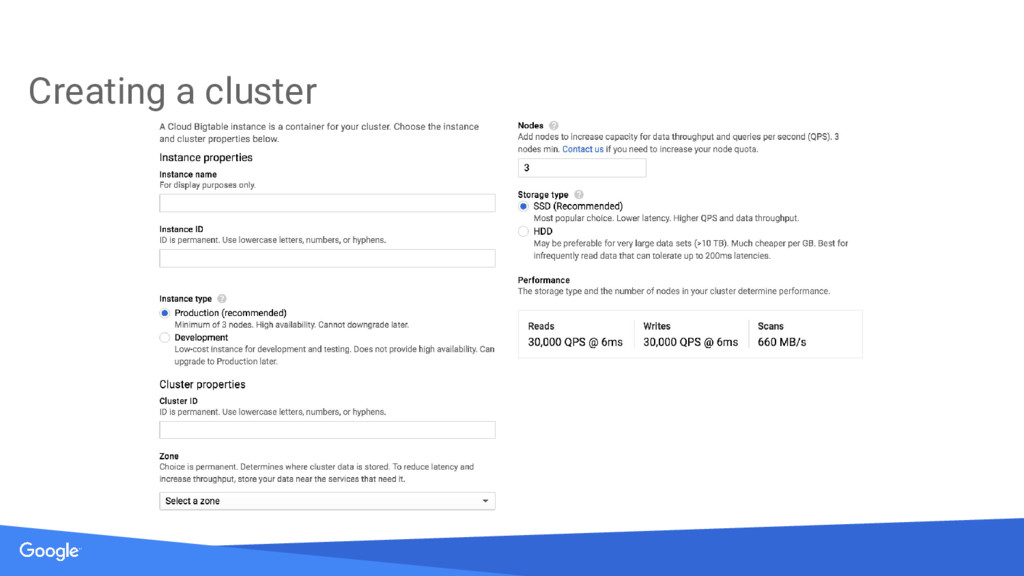{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}