“microservice-based web app” because it’s essentially a new phrase coined by some marketing drone for something that is already in existence. ! Back in my day (you can tell that I’m a curmudgeon from that phrase, right?) we called it a “service-oriented architecture,” or SOA for short. ! In essence, we’re talking about an application that uses services rather than local procedures. In other words, we’re running code on a separate computer, accessed over a network, so that we can spread out the workload. ! In theory, this is a Very Good Thing because we’re not overloading a single computer, but allowing a highly-distributed network of computers to take on various parts of the application.
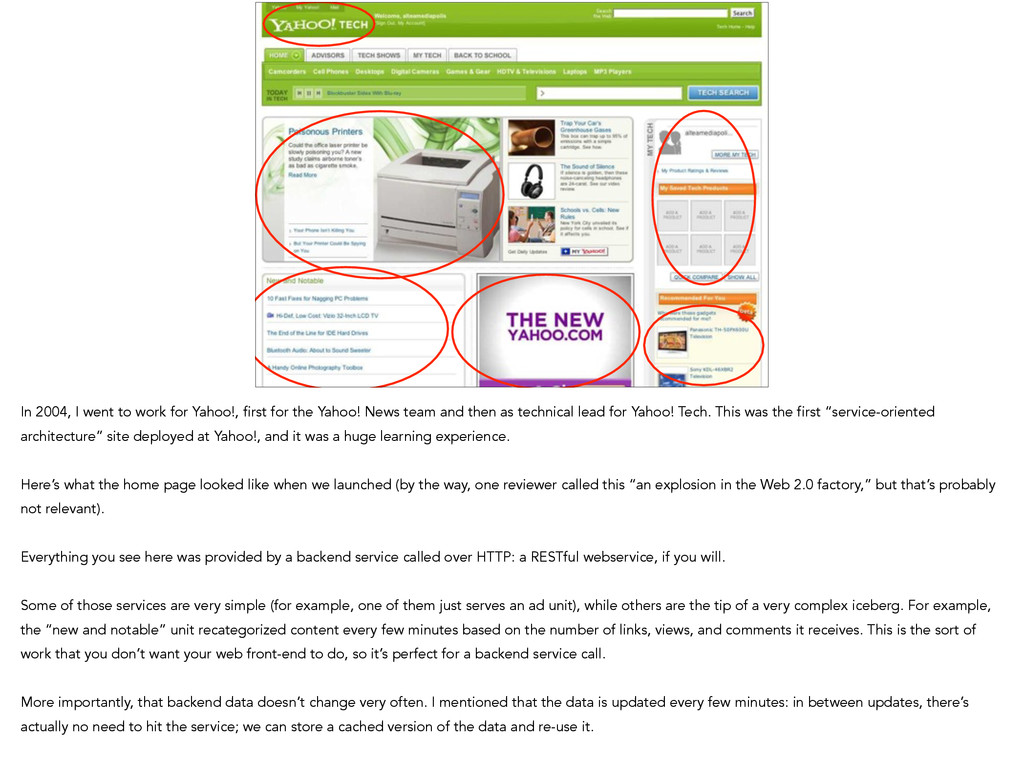
the Yahoo! News team and then as technical lead for Yahoo! Tech. This was the first “service-oriented architecture” site deployed at Yahoo!, and it was a huge learning experience. ! Here’s what the home page looked like when we launched (by the way, one reviewer called this “an explosion in the Web 2.0 factory,” but that’s probably not relevant). ! Everything you see here was provided by a backend service called over HTTP: a RESTful webservice, if you will. ! Some of those services are very simple (for example, one of them just serves an ad unit), while others are the tip of a very complex iceberg. For example, the “new and notable” unit recategorized content every few minutes based on the number of links, views, and comments it receives. This is the sort of work that you don’t want your web front-end to do, so it’s perfect for a backend service call. ! More importantly, that backend data doesn’t change very often. I mentioned that the data is updated every few minutes: in between updates, there’s actually no need to hit the service; we can store a cached version of the data and re-use it. !
storage (caching) of web documents, such as HTML pages and images, to reduce bandwidth usage, server load, and perceived lag. A web cache stores copies of documents passing through it; subsequent requests may be satisfied from the cache if certain conditions are met.” When we first built Yahoo! Tech, we did not include any web caching. We thought it might be premature optimization, and we wanted to know what benefits it was giving. ! When we did our first load testing on the site, we achieved a max throughput of about .6 requests/second without caching (per server). ! We turned on the cache, and performance immediately improved to about 50 requests/second. ! At that point, we were sold.
• Code on demand (optional) • Uniform interface I’m not going to go into a ton of detail on what is REST, nor will I get involved in some of the, er, excitable arguments around it. Let’s walk through these various components of the architectural style, however, just to refresh our memories. ! Client-server: separate the interface from the server Stateless: no client context stored on the server between requests Cacheable: clients can cache responses, so servers need to be clear on what can and cannot be cached Layered system: a client cannot tell if it is connecting directly to the server, or through an intermediary; in other words, caches and proxies must be transparent (but only to the layers above them). Code on demand: the server can transmit code that is executed on the client (JavaScript) Uniform interface: URLs, URIs, and a standard method for identifying them.
defined by the HTTP 1.2 standard. For those of you that haven’t kept up with your required reading HTTP 1.2 is an update of the standard specification for HTTP: it does not change the protocol, but clarifies a lot of the ambiguity in the 1.1 spec, and makes standard some behaviors that have long been common on the web.
• Connection: • ETag:! • Expires:! • If-Match: • If-None-Match: • If-Range: • Pragma: • Vary: • Warning: This looks like a lot; we’re not going to go over all of these in detail, but focus on a few that are important.
of this is really, really tedious, but it’s also important. I’ll leave this link here so you can find it and bookmark it. All the details are there, but it can really impact the performance of your web application.
• no-transform • must-revalidate • proxy-revalidate • max-age={seconds} • s-maxage={seconds} public - content may be cached private - content is for a specific user and may NOT be cached no-cache - do not cache this no-store - contains authenticated data and may not be stored no-transform - some proxies will convert content (for example, between TIFF and JPEG); this directive tells the proxies to not do that must-revalidate - tells the proxy to discard the data after it expires proxy-revalidate - same thing, but to private caches max-age - content is stale after {seconds} s-maxage - overrides max-age and Expires: values; forces revalidation at expiration
by the HTTP standard, and is often not consistent across a cluster. • Error-prone and can be used to track users who refuse cookies. • Turn them off; don’t use them
a date/time rather than delta seconds (Cache-Control: max-age=S) • Mostly used for compatibility with HTTP 1.0; Cache- Control: is more semantically rich.
posts, aggregated data such as ratings or reviews (“likes”). • Uncacheable: secure, private, personal data such as user login information, credit card info, etc. Data that must change rapidly—stock quotes, for example, or health monitoring systems.
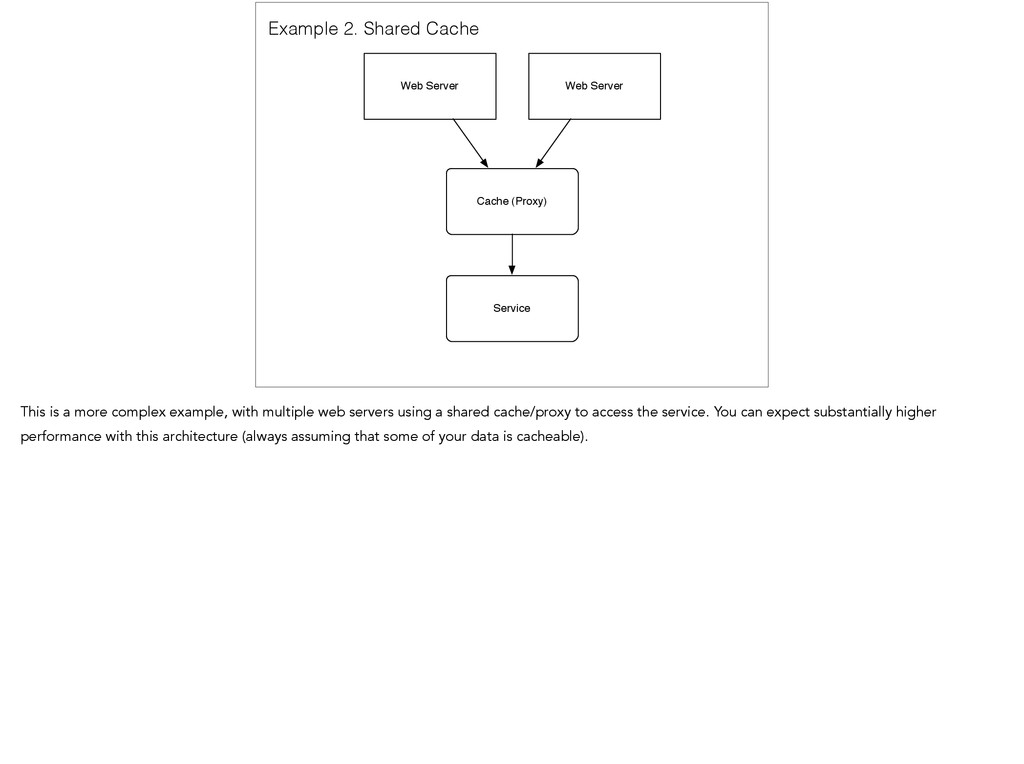
Cache This is a more complex example, with multiple web servers using a shared cache/proxy to access the service. You can expect substantially higher performance with this architecture (always assuming that some of your data is cacheable).
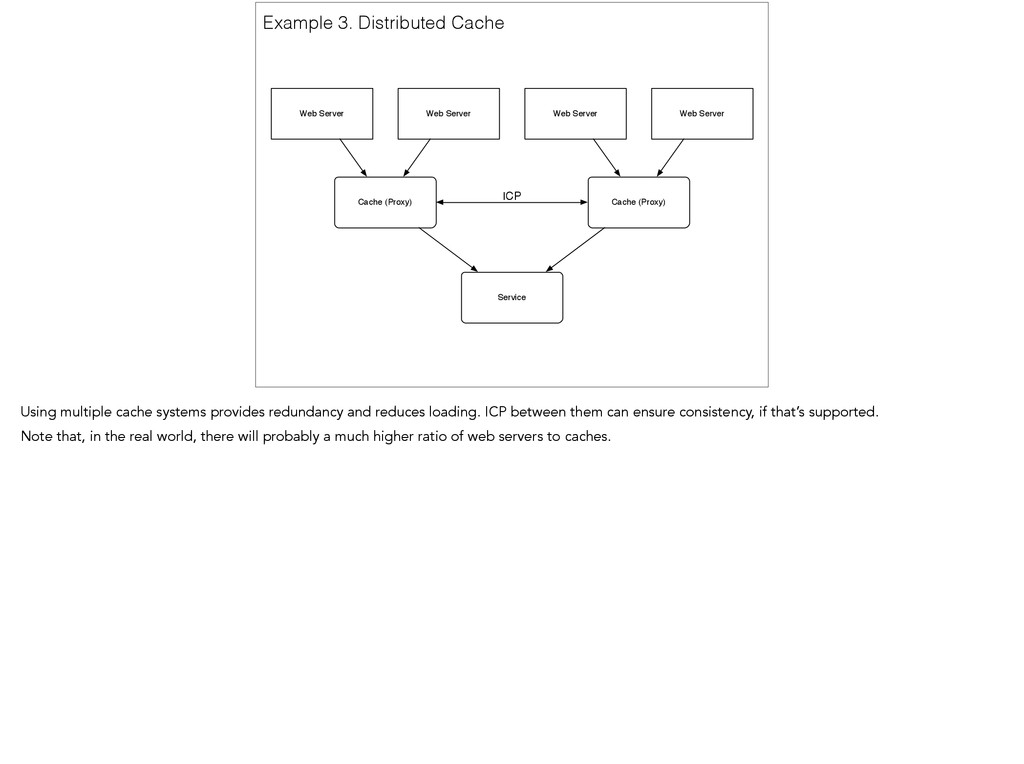
(Proxy) Web Server ICP Example 3. Distributed Cache Using multiple cache systems provides redundancy and reduces loading. ICP between them can ensure consistency, if that’s supported. Note that, in the real world, there will probably a much higher ratio of web servers to caches.
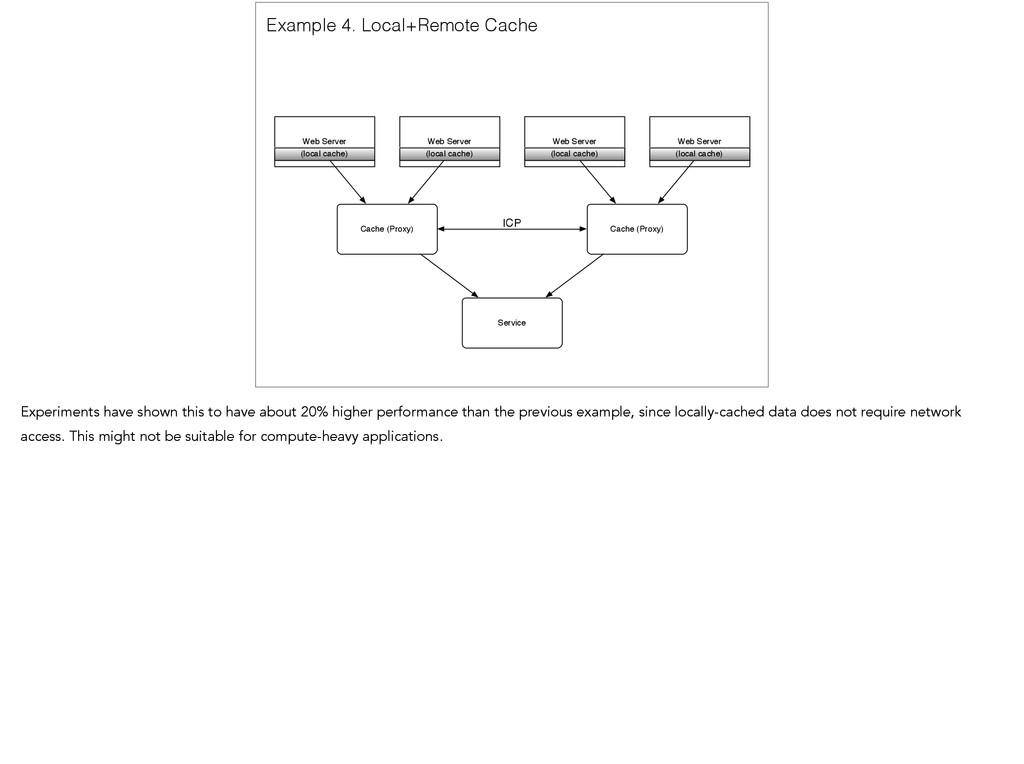
(Proxy) Web Server ICP (local cache) (local cache) (local cache) (local cache) Example 4. Local+Remote Cache Experiments have shown this to have about 20% higher performance than the previous example, since locally-cached data does not require network access. This might not be suitable for compute-heavy applications.
standard • Single-threaded • Can be tricky to configure (a multitude of options) but very high-performance • Implements ICP (Internet Cache Protocol) for distributed and hierarchical caches
system. • Not transparent, but can build transparency. • Most are simple key/value stores • Requires writing code Understand that anything done manually is not transparent itself; however, it can be used to build a transparent layer in an application stack.
service. • Internal methods query the data store (memcached, Redis) first and use stored data if possible. • If data is not in the cache, fetch it from the backend service and store it in the cache. All of this can be hidden under a data retrieval interface so that the application developer doesn’t need to know about it
tested, etc. • Requires code maintenance if the underlying data model is changed. • Not standardized like HTTP for specifying age, freshness of data (i.e., not a generic solution, but a custom one)
(CDN) that holds static content on the “edges” of the Internet • Akamai is the biggest, but there are others: LimeLight, Microsoft Azure, Amazon CloudFront • Stores static content in multiple data centers • Content like JavaScript, CSS, images, and other media By storing content close to the end user, it reduces latency and removes load from the main provider
the HTML page. • <script> <style> <img> etc. tags reference static content on the CDN • User’s browsers loads (and often stores) the static content locally, because it’s served with a Cache- Control: max-age=32767 header. For large, content-heavy sites, as much as 90% of their traffic is served by the CDN. CDNs also improve reliability because most of them are serviced by multiple providers
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] @glenc http://glencampbell.co http://developer.rackspace.com](https://files.speakerdeck.com/presentations/db8921c00c5a013224d31eb14f30e1c6/slide_35.jpg){kind=link}