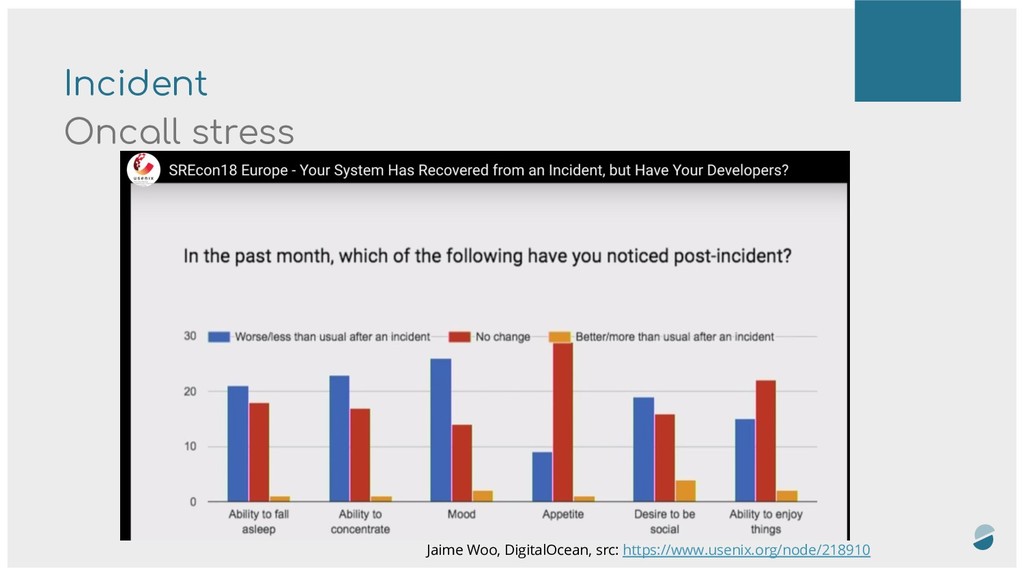
Incident management is a very stressful and complex moment for a SRE, handle them correctly implies a rigorous organisation.
Feedback on what we have learnt and what we live daily at Synthesio.
We've going to talk about time management, fatigue, blameless culture, priorization, postmortems ...
This presentation is a non-technical presentation but for engineers / technicians, mostly devops / SRE that can benefit from our feedback to improve their daily organisation.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}