* low priority updates * intensive calculations * big data queues * preparing hot caches * indexing updates * logging use message/task queues for long running operations:
organize queues into priority workers * scale workers using AWS auto scaling - send custom alerts using AWS CloudWatch API * it’s all about priorities Amazon SQS
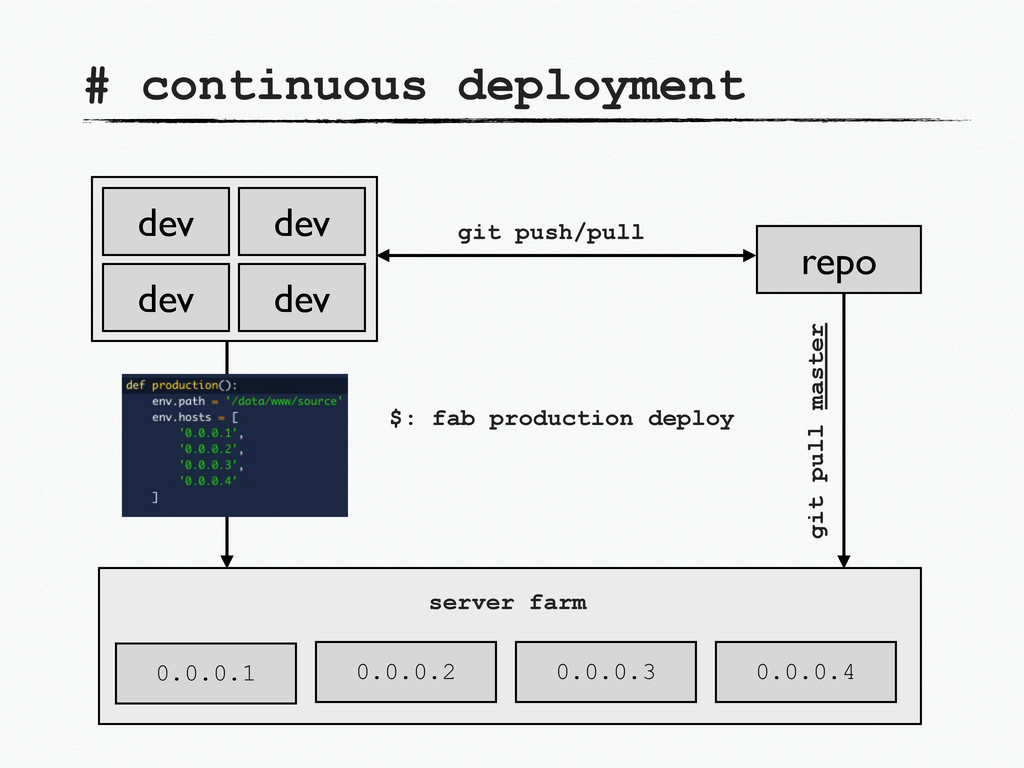
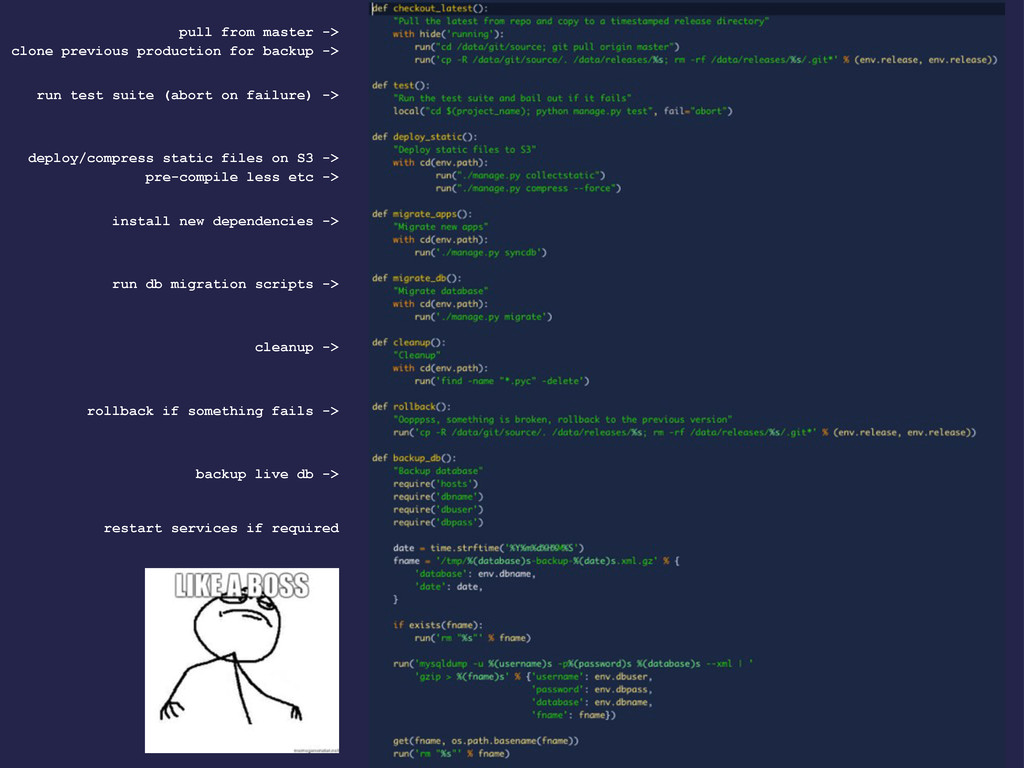
-> deploy/compress static files on S3 -> install new dependencies -> run db migration scripts -> cleanup -> rollback if something fails -> clone previous production for backup -> backup live db -> pre-compile less etc -> restart services if required
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![# questions? challenges? ? @goldstein aka leonidas tsementzis leotsem [at]](https://files.speakerdeck.com/presentations/4f99a57978ef2a001f012e62/slide_39.jpg){kind=link}
![# thank you @goldstein aka leonidas tsementzis leotsem [at] gmail.com](https://files.speakerdeck.com/presentations/4f99a57978ef2a001f012e62/slide_40.jpg){kind=link}